Sie nutzen OpenClaw für Ihren täglichen Workflow, aber beim Blick auf die monatliche API-Rechnung zucken Sie zusammen – 300 $, 500 $ oder sogar über 600 $?
Das liegt nicht an Ihnen, sondern am Architekturdesign von OpenClaw. Nicht optimierte OpenClaw-Instanzen senden bei jeder Aufgabe Unmengen an "unnötigem Inhalt" an das AI-Modell und verbrauchen so sinnlos Token.
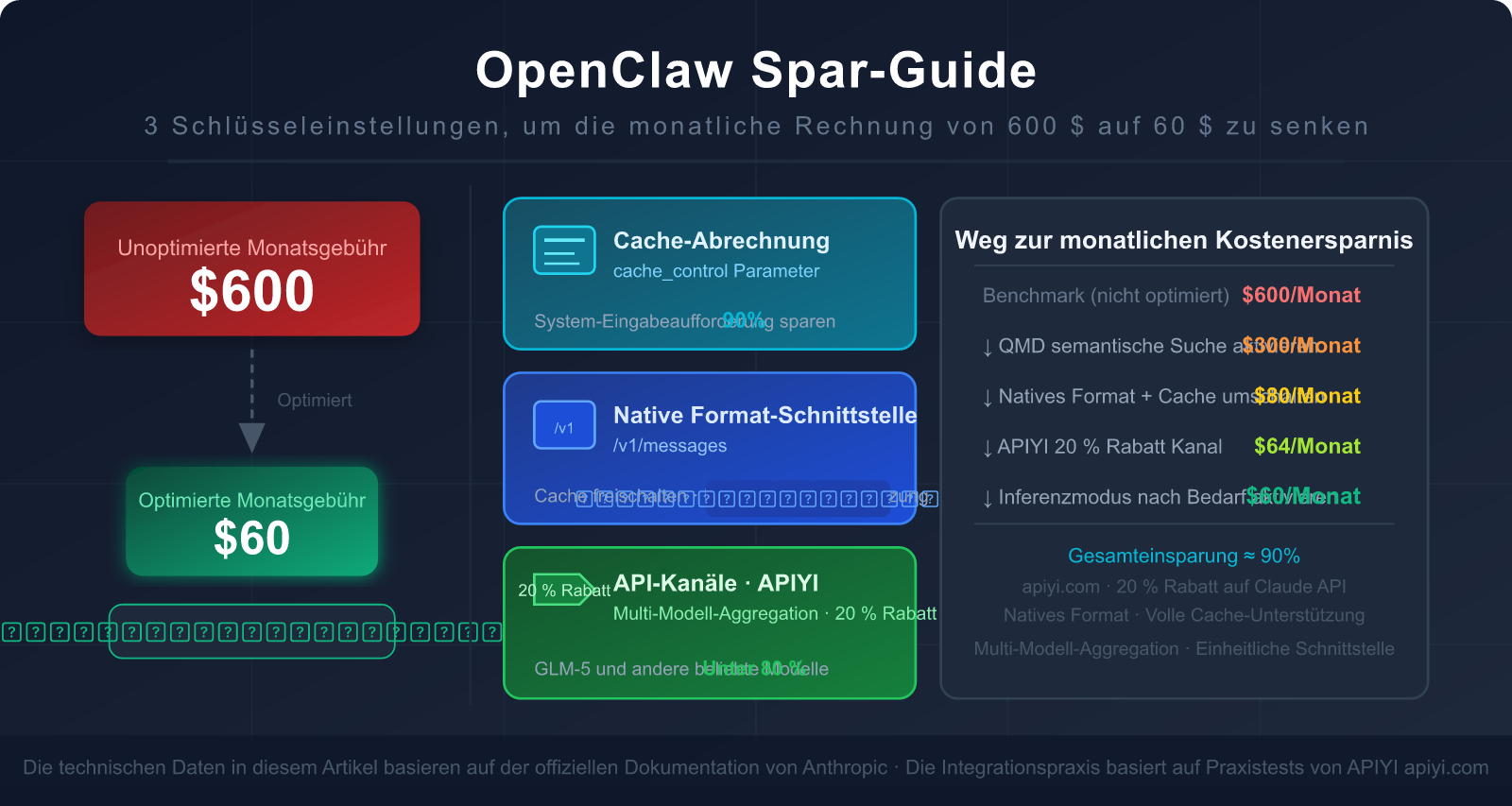
Die gute Nachricht: Mit ein paar entscheidenden Einstellungen lässt sich die Rechnung um 80-90 % senken. Der effektivste Trick, den kaum jemand kennt: Nutzen Sie das native Claude-Format statt des OpenAI-Kompatibilitätsmodus.
In diesem Artikel analysieren wir die Ursachen für den hohen Token-Verbrauch von OpenClaw und zeigen Ihnen Schritt für Schritt, wie Sie die richtigen Schnittstellen wählen, Caching konfigurieren und den passenden API-Kanal wählen, um Ihre monatliche Rechnung von 600 $ auf 60 $ zu drücken.
I. Warum OpenClaw so viele Tokens verbraucht: 3 Kernursachen
Ursache 1: Der gesamte Gesprächsverlauf wird bei jeder Anfrage erneut gesendet
Dies ist die am häufigsten übersehene Ursache, hat aber die größte Auswirkung.
OpenClaw folgt im Design dem Prinzip des „vollständigen Kontextes“: Jedes Mal, wenn eine Anfrage an das KI-Modell gesendet wird, werden alle historischen Nachrichten seit Beginn des Gesprächs mitgeschickt. Nur so kann das Modell „behalten“, was zuvor getan oder gesagt wurde.
Ein Beispiel:
Runde 1: Nutzer sendet 50 Tokens, KI antwortet 200 Tokens → 250 Tokens gesendet
Runde 2: Nutzer sendet 50 Tokens, KI antwortet 200 Tokens → 500 Tokens gesendet (inkl. Runde 1)
Runde 3: Nutzer sendet 50 Tokens, KI antwortet 200 Tokens → 750 Tokens gesendet (inkl. Runde 1+2)
...
Runde 10: Tatsächlich kommen nur 250 Tokens hinzu, aber die gesendete Menge beträgt bereits 2.500 Tokens.
In einem OpenClaw-Workflow, der komplexe Aufgaben verarbeitet, führt dieser „Schneeballeffekt“ dazu, dass der Token-Verbrauch exponentiell ansteigt. Der Kontextverlauf macht in der Regel 40–50 % des gesamten Token-Verbrauchs aus.
Ursache 2: Der System-Prompt wird jedes Mal neu gesendet
Der System-Prompt von OpenClaw definiert die Identität des Agents, seine Kompetenzbereiche, die Liste der verfügbaren Tools, Verhaltensregeln und andere Kerninhalte. Dieser umfasst normalerweise zwischen 5.000 und 10.000 Tokens.
Das Kernproblem: Dieser riesige System-Prompt wird bei jedem einzelnen API-Aufruf vollständig mitgesendet.
Angenommen, Sie bearbeiten täglich 50 Aufgaben mit OpenClaw und der System-Prompt umfasst jeweils 8.000 Tokens:
Täglicher System-Prompt-Verbrauch = 50 × 8.000 = 400.000 Tokens
Monatlicher Verbrauch ≈ 12.000.000 Tokens (nur für den System-Prompt!)
Basierend auf dem Input-Preis von Claude 3.5 Sonnet (3 $ / Million Tokens) würde allein der System-Prompt monatlich 36 $ kosten. Gesprächsinhalte und Output sind hierbei noch gar nicht eingerechnet.
Ursache 3: Der Reasoning-Modus lässt die Tokens um das 10- bis 50-fache ansteigen
Wenn OpenClaw auf komplexe Aufgaben stößt, aktiviert es die „Chain-of-Thought“ oder den „Reasoning-Modus“ (Schlussfolgerungsmodus). Dieser Modus lässt die KI erst „nachdenken, bevor sie spricht“, was die Ausgabequalität erhöht – allerdings um den Preis eines massiv ansteigenden Token-Verbrauchs.
Merkmale des Reasoning-Token-Verbrauchs:
- Der Denkprozess erzeugt eine große Menge an Zwischen-Tokens (oft unsichtbar, aber kostenpflichtig).
- Der Reasoning-Prozess für komplexe Aufgaben kann 10.000 bis 50.000 Tokens erzeugen.
- Ohne Kontrolle können wenige komplexe Aufgaben das gesamte Tagesbudget aufzehren.
| Token-Verbrauchsszenario | Standardmodus | Reasoning-Modus | Multiplikator |
|---|---|---|---|
| Einfache Q&A-Aufgaben | ~500 Tokens | ~2.000 Tokens | 4-fach |
| E-Mail-Verarbeitungsworkflow | ~2.000 Tokens | ~15.000 Tokens | 7,5-fach |
| Code-Analyse-Aufgaben | ~5.000 Tokens | ~80.000 Tokens | 16-fach |
| Komplexe mehrstufige Recherche | ~10.000 Tokens | ~200.000 Tokens | 20-fach+ |
🎯 Schnelldiagnose: Wenn Ihre OpenClaw-Rechnung ungewöhnlich hoch ist, prüfen Sie zuerst die Nutzung des Reasoning-Modus in den Token-Logs.
Das Deaktivieren des Reasoning-Modus für nicht essenzielle Aufgaben ist eine der effektivsten Maßnahmen zur Kosteneinsparung.
Auch der Wechsel zu einem passenderen Modell kann die Kosten drastisch senken – über den API-Proxy-Dienst APIYI (apiyi.com) können Sie schnell zwischen verschiedenen Modellen wechseln und diese testen.
Anteil der drei Hauptursachen am Verbrauch
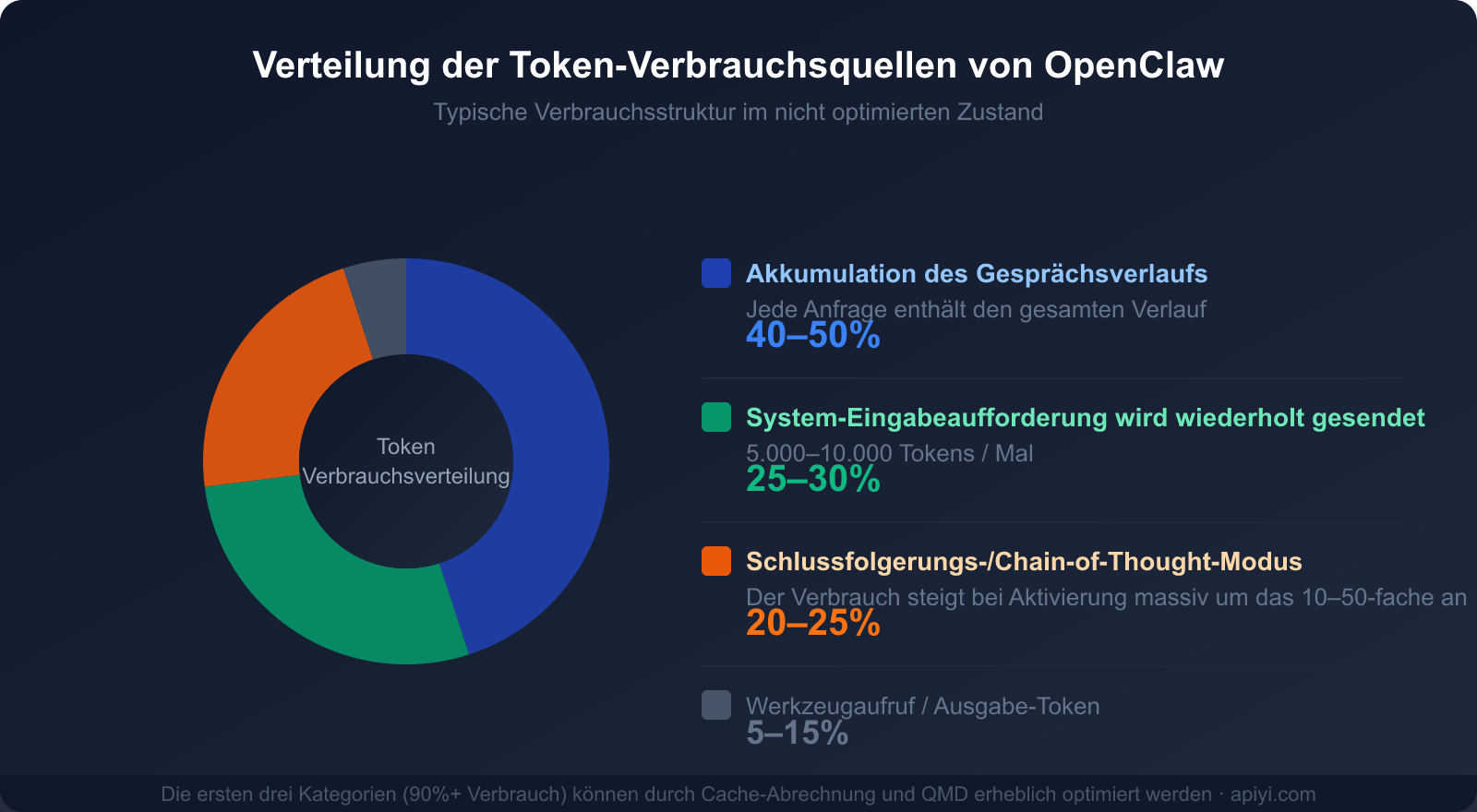
Das Verständnis dieser drei Hauptverbrauchsquellen ist die Voraussetzung für eine effektive Sparstrategie:
| Verbrauchsquelle | Anteil am Gesamtverbrauch | Optimierbar? | Wichtigste Optimierungsmethoden |
|---|---|---|---|
| Gesprächsverlauf (Kontext-Akkumulation) | 40-50 % | ✅ Hochgradig optimierbar | Caching, regelmäßige Bereinigung, QMD |
| Wiederholtes Senden des System-Prompts | 25-30 % | ✅ Hochgradig optimierbar | Prompt Caching (spart bis zu 90 %) |
| Reasoning- / Chain-of-Thought-Modus | 20-25 % | ✅ Nach Bedarf | Nur für komplexe Aufgaben aktivieren |
| Tool-Aufrufe und Output | 5-15 % | ⚡ Begrenzt optimierbar | Verschlankung der Tool-Beschreibungen |
II. Die am meisten unterschätzte Spar-Geheimwaffe: Claude Prompt Caching
Was ist Claude Prompt Caching?
Das Prompt Caching von Claude ist eine native Funktion, die Anthropic Ende 2024 eingeführt hat. Die Kernlogik dahinter: Häufig wiederholte Inhalte werden serverseitig zwischengespeichert. Bei nachfolgenden Aufrufen wird direkt aus dem Cache gelesen, anstatt den Text erneut zu verarbeiten.
Der Preis für das Lesen aus dem Cache: Nur 10 % des normalen Input-Preises (90 % Ersparnis).
Das bedeutet: Wenn Sie jedes Mal einen System Prompt von 8.000 Tokens senden, werden bei aktiviertem Caching und einem Cache-Treffer nur 800 Tokens berechnet. Für OpenClaw-Nutzer, die täglich Dutzende von Anfragen senden, kann diese Optimierung hunderte Dollar pro Monat einsparen.
Das vollständige Preissystem für Caching
| Cache-Typ | Gebührenmultiplikator | Gültigkeitsdauer | Anwendungsfall |
|---|---|---|---|
| Normaler Input-Token | 1× Basispreis | Kein Cache | Jedes Mal neue Verarbeitung |
| Cache-Schreiben (erstmalig) | 1,25× | 5 Min. TTL | Aufbau des Caches |
| Cache-Schreiben (langfristig) | 2× | 1 Std. TTL | Szenarien mit sehr häufigen Aufrufen |
| Cache-Lesen (Hit) | 0,1× (90 % Ersparnis) | Innerhalb der Gültigkeit | Wiederholte Anfragen |
Beispiel für die tatsächliche Ersparnis:
Szenario: OpenClaw System-Prompt mit 8.000 Tokens
50 Aufrufe pro Tag, davon 48 Cache-Treffer (Hits)
Ohne Cache: 50 × 8.000 = 400.000 Tokens
Kosten = 400.000 × $3/1M = $1,20/Tag = $36/Monat
Mit Cache: 2 Schreibvorgänge: 2 × 8.000 × 1,25 = 20.000 Tokens = $0,06
48 Treffer: 48 × 8.000 × 0,1 = 38,400 Tokens = $0,12
Kosten pro Tag ≈ $0,18 → pro Monat ≈ $5,40
Ersparnis: $36 - $5,40 = $30,60/Monat (nur für den System Prompt)
Ersparnisquote: 85 %
So aktivieren Sie das Caching in OpenClaw
Die Aktivierung des Caching hat eine zwingende Voraussetzung: Sie müssen das Anthropic Native Format Interface (/v1/messages) verwenden und nicht den OpenAI-Kompatibilitätsmodus (/v1/chat/completions).
Richtige Konfiguration (Beispiel mit Python SDK):
import anthropic
# Es muss das native Anthropic SDK verwendet werden, nicht das OpenAI SDK
client = anthropic.Anthropic(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1" # APIYI unterstützt das native Anthropic-Format
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
system=[
{
"type": "text",
"text": "Du bist ein professioneller KI-Assistent...[8000 Tokens System-Prompt]",
"cache_control": {"type": "ephemeral"} # ← Entscheidend: Markiert diesen Inhalt für das Caching
}
],
messages=[
{"role": "user", "content": "Hilf mir, meine heutigen E-Mails zu sortieren"}
]
)
Technische Einschränkungen des Caches:
- Maximal 4 Cache-Breakpoints (
cache_controlMarkierungen) möglich. - Sonnet-Serie: Mindestgröße für Cache-Inhalte ≥ 1.024 Tokens.
- Opus / Haiku 4.5: Mindestgröße für Cache-Inhalte ≥ 4.096 Tokens.
- Unterstützte Modelle: Claude Opus 4, Sonnet 4.6, Sonnet 4.5, Sonnet 4, Sonnet 3.7, Haiku 4.5, Haiku 3.5, Haiku 3 etc.
🎯 Wichtiger Hinweis: APIYI (apiyi.com) unterstützt Aufrufe im nativen Anthropic-Format vollständig, einschließlich des Parameters
cache_control. Wenn Sie Claude-Modelle bei APIYI im nativen Format aufrufen, profitieren Sie gleichzeitig von der Cache-Abrechnung (bis zu 90 % Ersparnis) + dem APIYI-Rabatt von 20 %. Dieser kombinierte Effekt ist enorm.
III. Wichtige Erkenntnis: Warum der OpenAI-Kompatibilitätsmodus keine Tokens spart
Dies ist die häufigste Falle, in die OpenClaw-Nutzer tappen.
Die essenziellen Unterschiede der Interface-Formate
Viele KI-Tools von Drittanbietern und API-Proxy-Dienste bieten einen OpenAI-Kompatibilitätsmodus an – das heißt, sie nutzen das /v1/chat/completions-Format von OpenAI, um Nicht-OpenAI-Modelle wie Claude aufzurufen.
Oberflächlich betrachtet ist dies praktisch, da man "einen Code für alle Modelle" verwenden kann. Es gibt jedoch einen entscheidenden Nachteil:
Im /v1/chat/completions-Format gibt es keinen Platz für den Parameter cache_control – da dies eine exklusive native Funktion von Anthropic ist.
Wenn Sie Claude über das OpenAI-kompatible Format aufrufen:
- Wird Ihre Anfrage in das OpenAI-Format umgewandelt.
- Der API-Proxy-Dienst wandelt sie dann wieder in das native Anthropic-Format um.
- Aber die
cache_control-Information geht bereits im ersten Schritt verloren. - Die Claude-Server erhalten eine Anfrage ohne Cache-Markierung und berechnen jedes Mal den vollen Token-Preis.
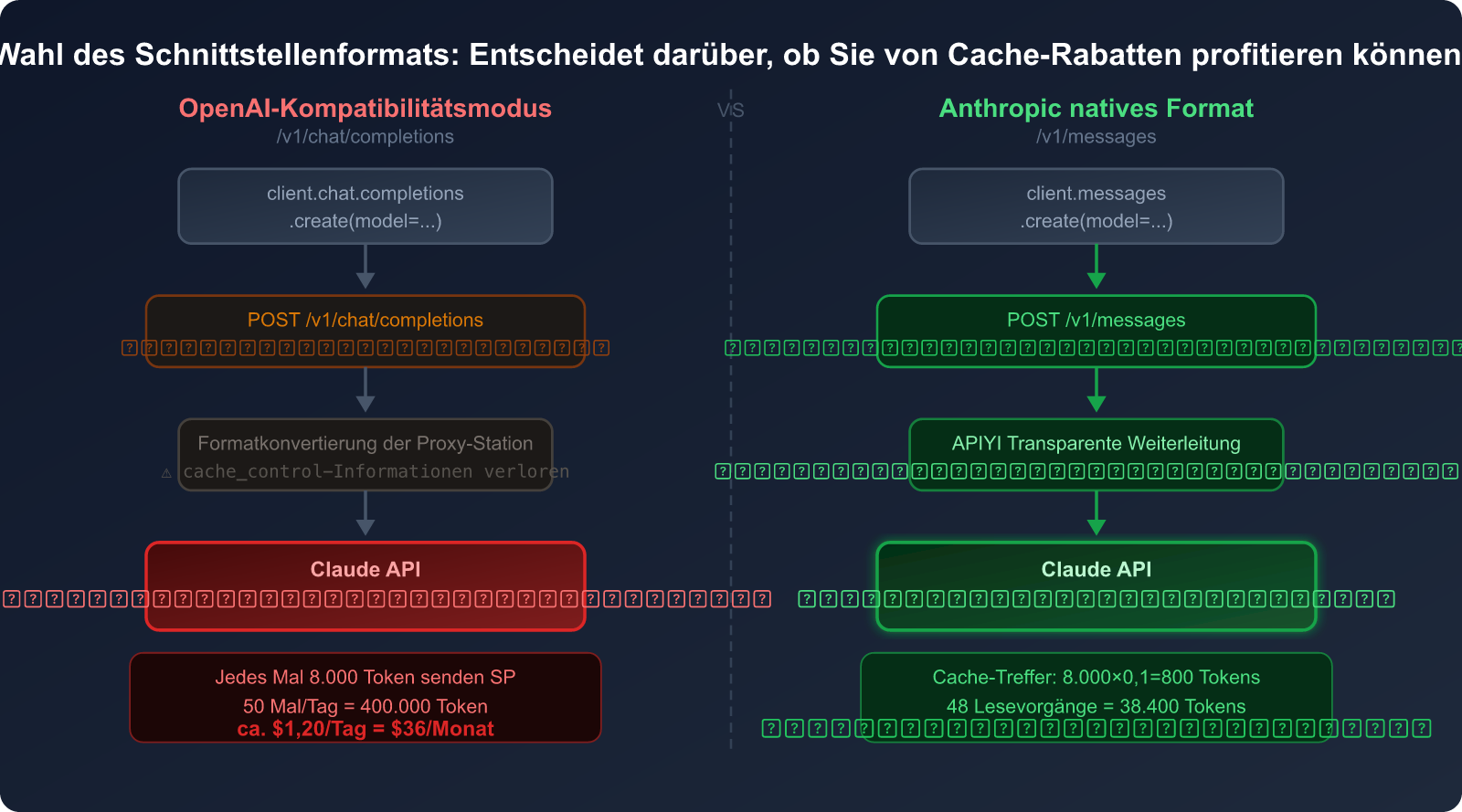
Vergleich: OpenAI-Kompatibilitätsmodus vs. Anthropic Native Format
| Vergleichsdimension | OpenAI-Kompatibilitätsmodus | Anthropic Native Format |
|---|---|---|
| Interface-Pfad | /v1/chat/completions |
/v1/messages |
| Claude Cache-Unterstützung | ❌ Nicht unterstützt | ✅ Volle Unterstützung |
cache_control Parameter |
❌ Feld existiert nicht | ✅ Unterstützt 4 Breakpoints |
| System Prompt Abrechnung | 💸 Voller Preis (1×) | 💰 Cache-Lesepreis (0,1×) |
| Code-Komplexität | Niedrig (universeller Code) | Mittel (Anthropic SDK nötig) |
| Spareffekt (Hochfrequenz) | 0 % | Bis zu 90 % |
Zusätzliche Probleme bei Nicht-Original-API-Deployments
Neben dem Interface-Format gibt es eine weitere Verwechslungsgefahr: Modelle mit gleichem Namen bei Cloud-Anbietern sind nicht gleichbedeutend mit der Original-API.
Beispiel GLM-5 (Zhipu AI):
- Original-API von z.ai: Unterstützt die eigenentwickelte Cache-Abrechnungsfunktion von Zhipu.
- GLM-5 bei Alibaba Cloud / Tencent Cloud: Nutzt das API-Gateway des Cloud-Anbieters und verfügt nicht über die Cache-Funktion des Herstellers.
Dies ist kein Problem von GLM-5 selbst, sondern ein allgemeines Merkmal von Drittanbieter-Deployments: Cloud-Anbieter stellen beim Hosting von Modellen meist nur Standard-Chat-APIs zur Verfügung und leiten herstellerspezifische Funktionen (wie Cache-Abrechnung) nicht durch.
Analogie: Es ist wie der Kauf eines Produkts über einen inoffiziellen Händler – man erhält oft nicht den speziellen Kundenservice des Originalherstellers.
Tatsächliche Auswirkungen:
Szenario: 50 Aufrufe pro Tag, System-Prompt 6.000 Tokens
Original-API (mit Cache):
Schreiben: 2 × 6.000 × 1,25 = 15.000 Tokens
Lesen: 48 × 6.000 × 0,1 = 28.800 Tokens
Äquivalenter Verbrauch ≈ 43.800 Tokens/Tag
Drittanbieter-API (ohne Cache):
Vollpreis: 50 × 6.000 = 300.000 Tokens/Tag
Unterschied: Der Verbrauch ohne Cache ist 6,85-mal höher als mit Cache.
4. Vergleich der Original-APIs: So wählen Sie die beste Anbindung für OpenClaw
Vergleich der vier Anbindungslösungen
| Anbindungslösung | Preis (relativ zum Originalpreis) | Caching-Unterstützung | Multi-Modell-Unterstützung | Anwendungsszenario |
|---|---|---|---|---|
| Offizielle Anthropic API | 100 % (Originalpreis) | ✅ Vollständig | ❌ Nur Claude | Ausreichendes Budget, reine Claude-Nutzer |
| APIYI (Natives Anthropic-Format) | 80 % (20 % Rabatt) | ✅ Vollständig | ✅ Mehrere Modelle | Empfohlen: Kostenersparnis + Flexibilität |
| Allgemeiner API-Proxy-Dienst (OpenAI-kompatibel) | 85–95 % variabel | ❌ Nicht unterstützt | ✅ Mehrere Modelle | Wenn Claude-Caching nicht benötigt wird |
| Cloud-Anbieter (keine Original-Bereitstellung) | 90–110 % variabel | ❌ Nicht unterstützt | ❌ Einzelnes Modell | Szenarien mit speziellen Compliance-Anforderungen |
Die doppelte Sparlogik von APIYI
Der Vorteil von APIYI bei Claude-Modellen liegt darin, dass sowohl das native Anthropic-Format als auch ein Preisnachlass von 20 % unterstützt werden.
Die Kombination dieser beiden Punkte bedeutet:
Normaler Nutzer (Originalpreis + OpenAI-kompatibel, kein Caching):
Monatlicher System Prompt Token-Verbrauch: 12.000.000 Tokens
Kosten = 12.000.000 × $3/1M = $36
APIYI-Nutzer (20 % Rabatt + natives Format + Caching):
Tatsächlich abgerechnete Tokens ≈ 1.440.000 Tokens (nach Caching)
Kosten = 1.440.000 × $3 × 0,8 / 1M = $3,46
Gesamtersparnis = ($36 - $3,46) / $36 ≈ 90 %
🎯 Empfehlung zur Auswahl: Wenn Sie OpenClaw nutzen und hauptsächlich Claude als Modell wählen,
empfehlen wir dringend die Anbindung über APIYI (apiyi.com) im nativen Anthropic-Format.
Der Basisrabatt von 20 % kombiniert mit den 90 % Ersparnis durch Caching kann Ihre Rechnung um insgesamt 85–90 % senken.
Zudem unterstützt APIYI weitere Modelle wie GLM-5 oder GPT, sodass Sie jederzeit flexibel vergleichen können.
5. OpenClaw Spar-Guide: 5 sofort umsetzbare Schritte
Schritt 1: Wechsel zum nativen Anthropic-Format
Dies ist der wichtigste Schritt, da er darüber entscheidet, ob Sie von der Caching-Abrechnung profitieren können.
Konfiguration in OpenClaw:
Suchen Sie in der Modellkonfiguration von OpenClaw (config.json) das Feld models.providers und fügen Sie APIYI als Anbieter hinzu. Entscheidend ist, das Feld api auf "anthropic-messages" zu setzen, um das native Format und damit das Caching zu aktivieren:
{
"models": {
"providers": {
"apiyi": {
"baseUrl": "https://api.apiyi.com",
"apiKey": "sk-IHR_TOKEN_HIER",
"api": "anthropic-messages",
"headers": {
"anthropic-version": "2023-06-01",
"anthropic-beta": ""
},
"models": [
{
"id": "claude-sonnet-4-6",
"name": "claude-sonnet-4-6",
"reasoning": false,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 16384
},
{
"id": "claude-sonnet-4-6-thinking",
"name": "claude-sonnet-4-6-thinking",
"reasoning": false,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 16384
}
]
}
}
}
}
Wichtige Konfigurationshinweise:
"api": "anthropic-messages"← Entscheidend: Legt die Verwendung des nativen/v1/messages-Formats fest, anstatt des kompatiblen/v1/chat/completions-Formats."baseUrl": "https://api.apiyi.com"← Die Basis-URL von APIYI (das/v1muss hier nicht angehängt werden, OpenClaw erledigt das automatisch)."anthropic-version": "2023-06-01"← Der Versions-Header der Anthropic API; ohne diesen schlägt die Anfrage fehl.contextWindow: 200000← Claude Sonnet 4.6 unterstützt ein Kontextfenster von 200K.
Prüfen, ob das Caching aktiv ist:
Überprüfen Sie die Felder cache_read_input_tokens und cache_creation_input_tokens in den API-Response-Headern oder Logs. Wenn dort Werte erscheinen, ist das Caching aktiv:
# Cache-Antwort validieren
response = client.messages.create(...)
# Usage-Feld prüfen
print(response.usage)
# Beispiel-Ausgabe:
# Usage(
# input_tokens=150, # Neu hinzugefügte Tokens in diesem Aufruf
# cache_creation_input_tokens=8000, # Erstmaliges Schreiben in den Cache (Abrechnung mit 1,25×)
# cache_read_input_tokens=0, # Späterer Cache-Treffer (Abrechnung mit 0,1×)
# output_tokens=300
# )
🎯 Anbindung: Nachdem Sie sich bei APIYI (apiyi.com) registriert und einen API-Schlüssel erhalten haben,
setzen Sie einfach diebase_urlaufhttps://api.apiyi.com/v1, um das native Anthropic-Format zu nutzen.
Es sind keine weiteren Code-Änderungen nötig, und die Claude-Caching-Abrechnung wird sofort wirksam.
Schritt 2: Cache-Breakpoints sinnvoll setzen
Die Position der Cache-Breakpoints (cache_control) ist entscheidend. Sie sollten Inhalte cachen, die "groß und statisch" sind:
# Best Practice: System-Eingabeaufforderung + Tool-Definitionen cachen
response = client.messages.create(
model="claude-sonnet-4-6",
system=[
{
"type": "text",
"text": SYSTEM_PROMPT, # Haupt-System-Prompt mit 5.000-10.000 Tokens
"cache_control": {"type": "ephemeral"} # Breakpoint 1
},
{
"type": "text",
"text": TOOL_DEFINITIONS, # Liste der Tools (oft ebenfalls sehr umfangreich)
"cache_control": {"type": "ephemeral"} # Breakpoint 2
}
],
messages=conversation_history, # Dialogverlauf (nicht cachen, da er sich ständig ändert)
...
)
Kernpunkte der Caching-Strategie:
- ✅ Geeignet für Cache: System-Eingabeaufforderungen, Tool-Definitionen, große statische Dokumente, RAG-abgerufene Dokumentinhalte.
- ❌ Nicht geeignet: Aktuelle Benutzernachrichten, dynamisch generierte Inhalte, Daten, die sich bei jedem Aufruf ändern.
- ⚠️ Reihenfolge beachten: Caching basiert auf Präfix-Matching. Statische Inhalte müssen am Anfang der Nachrichtenfolge stehen.
Schritt 3: QMD aktivieren, um die Kontextlänge zu reduzieren
QMD (Quick Memory Database) ist die lokale semantische Suchfunktion von OpenClaw. So funktioniert es:
Herkömmliche Methode:
Jedes Mal wird der [gesamte Dialogverlauf] gesendet → Hoher Token-Verbrauch
QMD-Methode:
Lokale Vektordatenbank wird aufgebaut → Suche nach den relevantesten Verlaufsfragmenten
Nur die [3-5 relevantesten Einträge] werden gesendet → Spart 60-97 % der Tokens
Tatsächlicher Spareffekt von QMD: Laut offizieller OpenClaw-Dokumentation kann QMD eine Token-Ersparnis von 60–97 % erzielen, abhängig vom Umfang des Verlaufs und dem Aufgabentyp.
Aktivierung (in der OpenClaw-Oberfläche):
- Settings → Memory → Enable QMD
- Speicherpfad für QMD festlegen (lokal, Daten werden nicht hochgeladen)
- Relevanz-Schwellenwert einstellen (empfohlen: über 0,7, um Rauschen im Verlauf zu vermeiden)
Schritt 4: Das richtige Modell für den jeweiligen Aufgabentyp wählen
Nicht jede Aufgabe benötigt das leistungsstärkste Modell. Die richtige Modellzuordnung ist der Schlüssel zur Kostenkontrolle:
Strategie zur Aufgaben-Klassifizierung:
Einfache Aufgaben (Terminerinnerungen, Formatkonvertierung, einfache Suche)
→ Nutzen Sie Claude Haiku 4.5 (am schnellsten, am günstigsten)
→ Kostet etwa 1/5 des Sonnet-Preises
Mittelschwere Aufgaben (E-Mail-Bearbeitung, Dateiorganisation, Code-Review)
→ Nutzen Sie Claude Sonnet 4.6 (ausgewogen)
→ Erfolgsrate 86,9 % (Platz 1 im PinchBench)
Komplexe Aufgaben (Architekturanalyse, mehrstufige Recherche, komplexe Logik)
→ Nutzen Sie Claude Opus 4.6 (stärkste Argumentationskraft)
→ Aktivieren Sie den Reasoning-Modus nur, wenn er wirklich benötigt wird
Schritt 5: Regelmäßiges Bereinigen des Kontextes
Der Dialogverlauf ist eine der größten Quellen für Token-Verbrauch (40–50 %). Empfehlungen:
- Maximale Kontext-Runden festlegen: Nach 15–20 Runden den Verlauf automatisch zusammenfassen und bereinigen.
- Manuelle Bereinigung nach Abschluss: Vor dem Start einer neuen Aufgabe den Kontext zurücksetzen.
- Sitzungskomprimierung von OpenClaw nutzen: Lange Verläufe durch KI in Zusammenfassungen komprimieren lassen.
Zusammenfassung der Optimierungseffekte
Basierend auf einem durchschnittlichen OpenClaw-Nutzer (nicht optimierte monatliche Kosten ca. $300–$600) sind dies die erwarteten Ergebnisse nach Umsetzung der fünf Schritte:
| Optimierungsschritt | Ziel der Einsparung | Erwartete Ersparnis | Schwierigkeitsgrad |
|---|---|---|---|
| 1. Wechsel zum nativen Anthropic-Format | Doppelte Abrechnung des System Prompts | 85–90 % (SP-Anteil) | ⭐ Niedrig (nur base_url ändern) |
| 2. Cache-Breakpoints setzen | Tool-Definitionen + statische Dokumente | 80–90 % (Tool-Anteil) | ⭐⭐ Niedrig bis Mittel |
| 3. QMD aktivieren | Dialogverlauf-Tokens | 60–97 % (Verlaufs-Anteil) | ⭐⭐ Niedrig bis Mittel |
| 4. Modell-Klassifizierung | Gesamte Token-Kosten | 30–70 % (Preisdifferenz) | ⭐⭐⭐ Mittel |
| 5. Kontext-Bereinigung | "Schneeballeffekt" des Verlaufs | 20–40 % (langfristig) | ⭐ Niedrig |
🎯 Prioritätsempfehlung: Schritt 1 (Wechsel zum nativen Format) und Schritt 3 (QMD aktivieren) bieten den höchsten Ertrag bei einfachster Umsetzung.
Wir empfehlen, diese beiden Schritte zuerst durchzuführen, was die Rechnung meist sofort um 60–80 % senkt.
Über APIYI (apiyi.com) erfordert Schritt 1 lediglich die Änderung einer Zeile in derbase_urlund ist in weniger als 5 Minuten erledigt.
6. Praxis-Konfiguration: Vollständiges Beispiel für OpenClaw + APIYI + Claude-Caching
Hier ist ein vollständiges, optimiertes Konfigurationsbeispiel für OpenClaw, das die meisten Benutzer direkt übernehmen können:
import anthropic
# Verwendung des nativen Anthropic-Formats über APIYI
client = anthropic.Anthropic(
api_key="sk-your-apiyi-key", # APIYI-Key (erhältlich nach Registrierung auf apiyi.com)
base_url="https://api.apiyi.com/v1"
)
# Definition der System-Eingabeaufforderung (große Inhalte, ideal für Caching)
SYSTEM_PROMPT = """
Du bist ein professioneller KI-Assistent, der auf der OpenClaw-Plattform läuft.
Zu deinen Aufgaben gehören: Terminverwaltung, E-Mail-Bearbeitung, Dateiorganisation, Unterstützung bei der Code-Entwicklung...
[Normalerweise detaillierte Anweisungen mit 5.000–10.000 Token]
"""
# Definition der Tool-Liste (ebenfalls große, statische Inhalte, ideal für Caching)
TOOL_DEFINITIONS = """
Verfügbare Tools: calendar_api, email_api, file_system, code_runner...
[Detaillierte Tool-Beschreibungen, normalerweise 2.000–5.000 Token]
"""
def call_openclaw_with_cache(conversation_history: list, user_message: str):
"""Optimierter OpenClaw-API-Aufruf mit aktiviertem Caching"""
response = client.messages.create(
model="claude-sonnet-4-6", # Platz 1 im PinchBench
max_tokens=4096,
# System-Eingabeaufforderung: Cache-Breakpoints markieren
system=[
{
"type": "text",
"text": SYSTEM_PROMPT,
"cache_control": {"type": "ephemeral"} # Cache-Breakpoint 1
},
{
"type": "text",
"text": TOOL_DEFINITIONS,
"cache_control": {"type": "ephemeral"} # Cache-Breakpoint 2
}
],
# Konversationsverlauf + neue Nachricht
messages=[
*conversation_history, # Historische Nachrichten (nicht gecacht, da sie sich jedes Mal ändern)
{"role": "user", "content": user_message}
]
)
# Token-Verbrauch ausgeben (zur Überwachung der Optimierungseffekte)
usage = response.usage
print(f"Eingabe-Token: {usage.input_tokens}")
print(f"Cache-Erstellung: {usage.cache_creation_input_tokens}")
print(f"Cache-Treffer: {usage.cache_read_input_tokens}")
print(f"Ausgabe-Token: {usage.output_tokens}")
return response.content[0].text
🎯 Schnelleinstieg: Ersetzen Sie den
api_keyim obigen Code durch den Key, den Sie nach der Registrierung bei APIYI (apiyi.com) erhalten haben. Ohne weitere Änderungen können Sie sofort die Kombination aus nativem Anthropic-Format, Caching-Abrechnung und den Rabatten von APIYI nutzen.
Häufig gestellte Fragen (FAQ)
Q: Unterstützt APIYI wirklich das native Anthropic-Format (/v1/messages)?
Ja, APIYI (apiyi.com) unterstützt beide Schnittstellenformate gleichzeitig:
- Natives Anthropic-Format:
/v1/messages(unterstützt Caching-Abrechnung) - OpenAI-kompatibles Format:
/v1/chat/completions(praktisch für universellen Code)
Für Claude-Modelle wird dringend empfohlen, das native Anthropic-Format zu verwenden, um von der Caching-Abrechnung zu profitieren. Verwenden Sie einfach das anthropic Python SDK und leiten Sie die base_url auf APIYI um.
🎯 Besuchen Sie APIYI (apiyi.com), um ein Konto zu registrieren. In der Konsole finden Sie Beispielcodes für beide Formate.
Q: Reicht eine Cache-TTL von 5 Minuten aus? Wann benötige ich eine 1-stündige TTL?
Das hängt von Ihrer Aufruffrequenz ab:
- Wenn Ihre OpenClaw-Aufrufe in Abständen von weniger als 5 Minuten erfolgen (z. B. kontinuierliche Aufgabenbearbeitung), reicht die standardmäßige 5-Minuten-TTL aus.
- Wenn die Intervalle zwischen 5 Minuten und einer Stunde liegen (z. B. Pause nach einer Aufgabenstapel-Verarbeitung), sollten Sie eine 1-stündige TTL in Betracht ziehen (die Kosten für das Schreiben sind doppelt so hoch, aber die Trefferquote ist besser).
- Bei Intervallen von mehr als einer Stunde ist Caching weniger sinnvoll, da der Cache meist neu geschrieben werden muss.
Q: Welche Spartipps gibt es für die Nutzung von GLM-5 oder anderen chinesischen Modellen?
Die Caching-Funktion von GLM-5 erfordert den Aufruf über die native API von Zhipu AI (z.ai). Drittanbieter-Bereitstellungen wie auf Alibaba Cloud unterstützen dies oft nicht direkt.
APIYI unterstützt ebenfalls GLM-5 und andere lokale Modelle zu Preisen, die oft mehr als 20 % unter dem Standardpreis liegen. Dies ist ideal, um in der Testphase verschiedene Modelle über eine einheitliche Schnittstelle zu vergleichen. Sobald Sie das passende Modell gefunden haben, können Sie entscheiden, ob Sie bei APIYI bleiben oder direkt zum Hersteller wechseln.
Q: Ich nutze bereits einen anderen API-Proxy-Dienst. Wie schwierig ist der Wechsel zu einer Plattform, die das native Format unterstützt?
Der Migrationsaufwand ist sehr gering. Sie müssen lediglich zwei Parameter in Ihrem Code anpassen:
# Vor der Migration (OpenAI-kompatibles Format)
from openai import OpenAI
client = OpenAI(api_key="sk-xxx", base_url="Adresse des alten Proxy-Dienstes")
response = client.chat.completions.create(model="claude-sonnet-4-6", ...)
# Nach der Migration (Natives Anthropic-Format mit Caching-Unterstützung)
import anthropic
client = anthropic.Anthropic(
api_key="sk-neuer-APIYI-Key", # ← Durch APIYI-Key ersetzen
base_url="https://api.apiyi.com/v1" # ← Durch APIYI-Adresse ersetzen
)
response = client.messages.create(model="claude-sonnet-4-6", ...)
# Fügen Sie dann cache_control im system-Parameter hinzu, um Caching zu aktivieren
Der Hauptaufwand besteht darin, chat.completions.create in messages.create zu ändern. Das Nachrichtenformat weist geringfügige Unterschiede auf (die role/content-Struktur bleibt gleich, aber system ändert sich von einem String zu einer Liste von Objekten). Die Migration ist normalerweise innerhalb eines halben Tages abgeschlossen.
Q: Wie überprüfe ich, ob meine OpenClaw-Instanz Caching erfolgreich nutzt?
Der direkteste Weg: Beobachten Sie bei zwei aufeinanderfolgenden Aufrufen das usage-Objekt in der API-Antwort:
- Erster Aufruf:
cache_creation_input_tokenshat einen Wert (Cache wird geschrieben). - Zweiter Aufruf:
cache_read_input_tokenshat einen Wert (Cache-Treffer).
Wenn die cache_read_input_tokens beim zweiten Aufruf der Token-Anzahl Ihrer System-Eingabeaufforderung entsprechen, ist das Caching vollständig aktiv.
Q: Muss der Reasoning-/Thinking-Modus (Extended Thinking) immer ausgeschaltet sein?
Nicht unbedingt, aber er sollte nach Bedarf verwendet werden. Empfohlene Strategie:
- Einfache Aufgaben (E-Mail-Klassifizierung, Terminplanung): Reasoning-Modus ausschalten.
- Mittelschwere Aufgaben (Code-Review, Informationszusammenfassung): Standardmäßig aus, bei Problemen einschalten.
- Komplexe Aufgaben (Architekturentscheidungen, mehrstufige Recherche): Einschalten, aber ein vernünftiges
budget_tokens-Limit setzen.
In der Claude-API können Sie den maximalen Token-Verbrauch des Reasoning-Modus über thinking: {"type": "enabled", "budget_tokens": 5000} begrenzen.
Fazit: Die Kernlogik der Kostenersparnis bei OpenClaw
Fassen wir alle Sparmaßnahmen in einer Grafik zusammen:
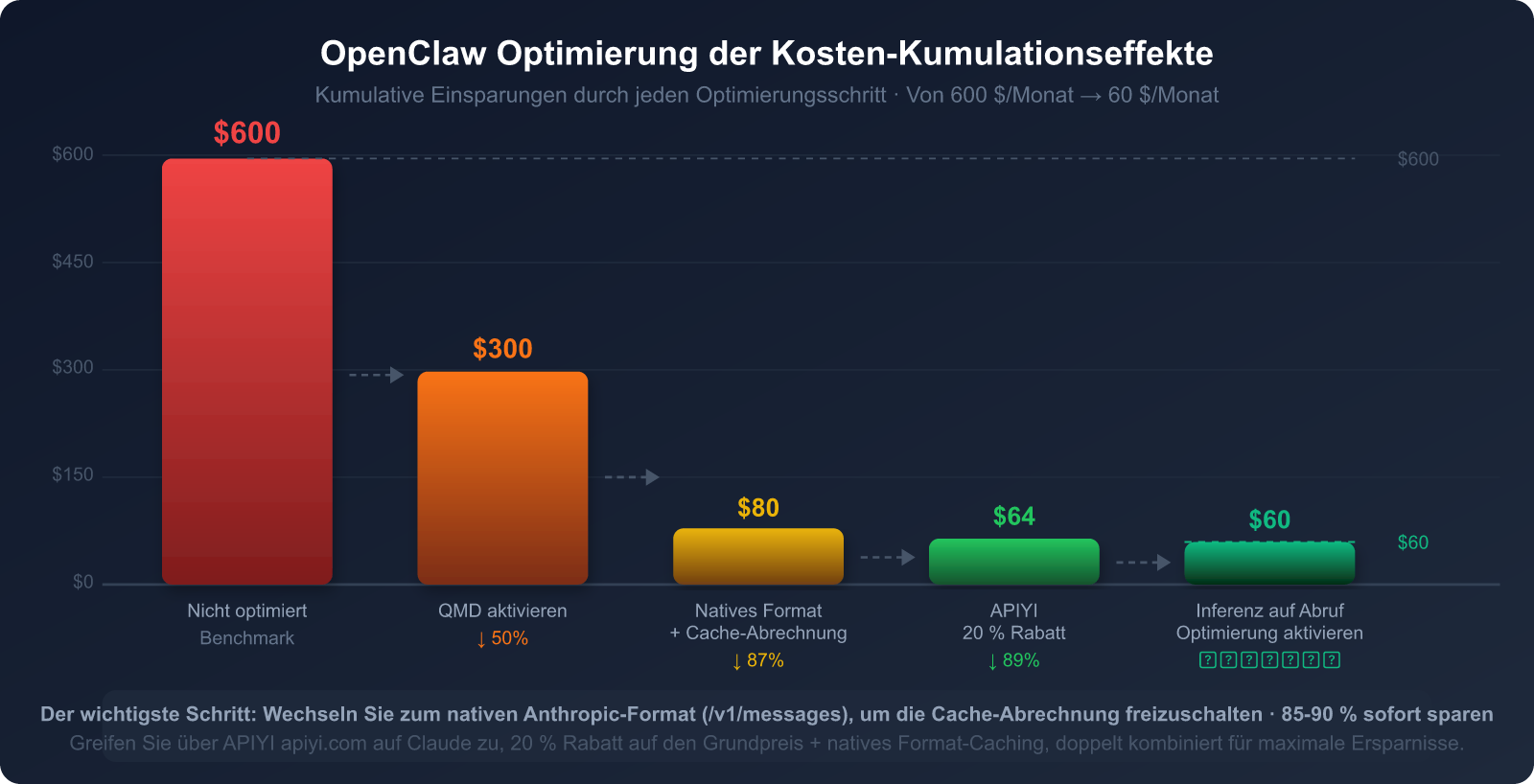
Rückblick auf die Kernpunkte dieses Artikels:
Die drei Hauptursachen für hohen Verbrauch:
- Ständiges erneutes Senden des Chat-Verlaufs (macht 40-50 % des Verbrauchs aus)
- Ständiges erneutes Senden des System-Prompts (macht 25-30 % aus)
- Unkontrollierte Nutzung des Inferenzmodus (macht 20-25 % aus)
Die effektivsten Sparmaßnahmen:
- 🥇 Claude-Caching: Bis zu 90 % Ersparnis (erfordert zwingend das native Anthropic-Format)
- 🥈 Lokale semantische Suche (QMD): Spart 60-97 % der Token im historischen Kontext
- 🥉 Modell-Tiering nach Aufgaben: Haiku für einfache Aufgaben, Sonnet/Opus für komplexe Aufgaben
- API-Kanal APIYI wählen: 20 % Rabatt auf den Basispreis + Unterstützung nativer Formate
Die wichtigste Erkenntnis:
Das OpenAI-kompatible Format (
/v1/chat/completions) kanncache_controlnicht übertragen.
Selbst wenn Sie Claude über einen API-Proxy-Dienst aufrufen, erhalten Sie keinen Caching-Rabatt.
Um Geld zu sparen, müssen Sie das native Anthropic-Format (/v1/messages) verwenden.
🎯 Jetzt handeln: Registrieren Sie sich bei APIYI (apiyi.com) und holen Sie sich einen API-Schlüssel, der das native Anthropic-Format unterstützt.
Ändern Sie diebase_urlzuhttps://api.apiyi.com/v1. Der Wechsel dauert weniger als 3 Minuten,
und Sie werden noch am selben Tag eine deutliche Senkung Ihrer Token-Rechnung feststellen. Mit 20 % Rabatt auf Claude-Modelle und einer einheitlichen Schnittstelle für mehrere Modelle ist dies die beste Wahl für OpenClaw-Nutzer, um Kosten zu senken und die Effizienz zu steigern.
Alle API-Preisdaten in diesem Artikel basieren auf öffentlichen Informationen vom März 2026. Die tatsächlichen Preise entnehmen Sie bitte den offiziellen Ankündigungen der jeweiligen Plattformen.
Autor: APIYI Team | Weitere Tipps zur Nutzung von OpenClaw finden Sie im Hilfe-Center von APIYI (apiyi.com)