في عام 2026، حصد مشروع مفتوح المصدر أنجزه مطور نمساوي مستقل خلال عطلة نهاية الأسبوع، 247 ألف نجمة على GitHub في غضون شهرين، ليصبح منصة وكيل ذكاء اصطناعي تتسابق شركات وادي السيليكون والصين على نشرها.
يُعرف هذا المشروع باسم OpenClaw.
في الوقت نفسه، برز سؤال مهم: في سيناريوهات الوكيل الحقيقية مثل OpenClaw، أي نموذج ذكاء اصطناعي يقدم أفضل أداء؟
هذا بالضبط ما يسعى PinchBench لحله. إنه معيار التقييم الرسمي لـ OpenClaw، وقد طوره فريق kilo.ai باستخدام لغة Rust، ويستخدم مهامًا حقيقية بدلاً من الاختبارات الاصطناعية، ليوفر للمطورين أساسًا موثوقًا لاختيار النماذج.
تنطلق هذه المقالة من قصة صعود OpenClaw، وتقدم تحليلًا معمقًا لنظام تقييم PinchBench، لمساعدتك على فهم المعنى الحقيقي لمعايير الذكاء الاصطناعي، وكيفية اختيار النموذج الأنسب لسير عمل الوكيل الخاص بك بناءً على بيانات التقييم.
أولاً: ما هو OpenClaw: ظاهرة مفتوحة المصدر غيرت اسمها 3 مرات في شهر واحد
ولادة OpenClaw وجدل التسمية
تبدأ قصة OpenClaw في نوفمبر 2025.
قام المطور النمساوي Peter Steinberger، مستغلاً وقت فراغه، ببناء منصة وكيل ذكاء اصطناعي، أطلق عليها في البداية اسم Clawdbot. كانت الفكرة الأساسية للمشروع بسيطة: جعل الذكاء الاصطناعي ليس مجرد أداة دردشة، بل قادرًا على تولي مهام سير العمل الرقمية الخاصة بك حقًا – قراءة رسائل البريد الإلكتروني، كتابة الأكواد، إدارة التقويم، والبحث عن المعلومات.
لكن مفهوم وكيل الذكاء الاصطناعي (AI Agent) ليس جديدًا، فلماذا انفجر OpenClaw بين عشية وضحاها؟
يكمن المفتاح في التوقيت والدعم المزدوج للمصدر المفتوح. في أواخر يناير 2026، ومع الانتشار الفيروسي لمشروع Moltbook، وصل الشغف في الأوساط التقنية "بجعل الذكاء الاصطناعي يقوم بالمهام فعليًا" إلى ذروته، وصعد Clawdbot ليصبح محط الأنظار.
لكنه سرعان ما تلقى إشعارًا باعتراض على العلامة التجارية من Anthropic – حيث اعتبر أن "Clawd" في Clawdbot قد يسبب التباسًا مع اسم منتج داخلي لـ Anthropic. اضطر المشروع في 27 يناير 2026 إلى تغيير اسمه على وجه السرعة إلى Moltbot، تكريمًا لمشروع Moltbook الذي اشتهر في نفس الفترة.
ومع ذلك، بعد ثلاثة أيام، اعترف Steinberger على GitHub بأن الاسم الجديد "لم يكن سلسًا عند النطق" ("never quite rolled off the tongue")، وتم تغيير اسم المشروع مرة أخرى إلى OpenClaw، واستمر بهذا الاسم حتى الآن.
هذا الجدل حول التسمية، تحول بدوره إلى أفضل "تسويق مجاني" للمشروع، مما جعل OpenClaw معروفًا على نطاق واسع في مجتمع المطورين.
حتى 2 مارس 2026، جمع OpenClaw على GitHub ما يلي:
- ⭐ 247 ألف نجمة (ما يعادل ما يقرب من نصف عدد نجوم إطار عمل React في نفس الفترة)
- 🍴 47.7 ألف تفرع (Forks)
- 🌍 تم نشره على نطاق واسع في شركات وادي السيليكون وأوروبا والصين.
البنية التقنية الأساسية لـ OpenClaw
فلسفة تصميم OpenClaw هي: التشغيل المحلي، استقلالية النموذج، التكامل مع تطبيقات المراسلة.
هذه السمات الثلاث تحدد اختلافه الجوهري عن أطر عمل وكلاء الذكاء الاصطناعي الأخرى.
التشغيل المحلي يعني أن بياناتك لا تمر عبر أي خادم تابع لجهة خارجية. على عكس معظم مساعدي الذكاء الاصطناعي الذين يعملون كخدمة (SaaS)، يتم نشر OpenClaw على جهاز المستخدم الخاص، ويمكن أن تشير استدعاءات API للنموذج إلى نقاط نهاية خاصة.
استقلالية النموذج تعني أن OpenClaw نفسه لا يرتبط بأي نموذج لغة كبير (LLM). إنه "غلاف دماغي" يدعم التكامل مع أي نموذج سائد مثل Claude وGPT وDeepSeek، ويمكن للمطورين التبديل بحرية بين النماذج بناءً على نوع المهمة وميزانية التكلفة.
التكامل مع تطبيقات المراسلة هو التصميم الأكثر تميزًا في OpenClaw – لا يحتاج المستخدمون العاديون إلى فتح أي تطبيق مخصص، بل يمكنهم استدعاء قدرات وكيل الذكاء الاصطناعي مباشرة عن طريق إرسال الرسائل في Signal أو Telegram أو Discord أو WhatsApp. هذا يقلل بشكل كبير من عتبة الاستخدام، مما يتيح للمستخدمين غير التقنيين الاستفادة منه.
| بُعد التصميم | اختيار OpenClaw | البدائل السائدة | شرح الاختلاف |
|---|---|---|---|
| موقع النشر | تشغيل محلي | خدمة سحابية (SaaS) | خصوصية بيانات أقوى، لكن يتطلب صيانة ذاتية |
| ربط النموذج | مستقل تمامًا | مرتبط بنموذج معين | مرونة في التبديل، لكن يتطلب تكوينًا ذاتيًا |
| واجهة المستخدم | تطبيقات المراسلة | واجهة ويب/تطبيق مخصص | سهولة البدء، لكن الوظائف محدودة بتطبيق المراسلة |
| نطاق الأذونات | وصول واسع | قيود بيئة معزولة (Sandbox) | وظائف قوية، لكن مخاطر أمنية أعلى |
| ترخيص المصدر المفتوح | مفتوح المصدر بالكامل | مغلق المصدر/مفتوح جزئيًا | مدفوع بالمجتمع، لكن دعم محدود |
🎯 نصيحة للاستخدام: يتطلب نشر OpenClaw تكوين واجهة خلفية لنموذج لغة كبير عالية الجودة.
نوصي بالاتصال بـ Claude Sonnet 4.6 أو GPT-5.4 عبر APIYI (apiyi.com)،
حيث أظهر كلا النموذجين أداءً ممتازًا في PinchBench، وتدعم APIYI التبديل الموحد للواجهة،
مما يسهل عليك مقارنة تأثيرات النماذج المختلفة بسرعة دون تعديل التكوين الأساسي لـ OpenClaw.
حدود قدرات OpenClaw
يدعم OpenClaw نطاقًا واسعًا من القدرات، ولكن هذا بالضبط ما أثار جدلاً أمنيًا:
مصادر البيانات التي يمكن الوصول إليها:
- حسابات البريد الإلكتروني (قراءة، تصنيف، صياغة الردود)
- أنظمة التقويم (عرض، إنشاء، تعديل المواعيد)
- أنظمة الملفات (تصفح، قراءة، إنشاء، نقل الملفات)
- مستودعات الأكواد (قراءة الأكواد، تشغيل الاختبارات، إرسال التغييرات)
- منصات المراسلة (تجميع الرسائل والاستجابة عبر المنصات)
- معلومات الويب (بحث، تلخيص، استخراج منظم)
سيناريوهات الاستخدام النموذجية:
المستخدم يرسل في Telegram: "ساعدني في تنظيم رسائل البريد الإلكتروني اليوم،
وضع علامة على تلك التي تحتاج إلى رد اليوم، وصِغ مسودات الردود."
تدفق تنفيذ وكيل OpenClaw:
1. استدعاء أداة البريد الإلكتروني، وقراءة رسائل البريد الإلكتروني غير المقروءة اليوم.
2. استخدام نموذج اللغة الكبير (LLM) لتقييم مدى إلحاح كل بريد إلكتروني.
3. تصفية قائمة رسائل البريد الإلكتروني التي تحتاج إلى رد اليوم.
4. إنشاء مسودة رد لكل بريد إلكتروني.
5. إرجاع نتائج التنظيم ومعاينة المسودات في Telegram.
هذه القدرة على "إنجاز المهام حقًا" هي الفرق الجوهري بين OpenClaw وروبوتات الدردشة البسيطة.
انضمام Steinberger إلى OpenAI ومستقبل المشروع
في 14 فبراير 2026، هز خبر المجتمع مفتوح المصدر بأكمله: أعلن Steinberger على GitHub أنه سينضم إلى OpenAI، وسيتم تسليم إدارة المشروع إلى مؤسسة مستقلة مفتوحة المصدر.
كان تأثير ذلك على OpenClaw مزدوجًا: فمن ناحية، حصل المشروع على إدارة أكثر احترافية وحماية قانونية؛ ومن ناحية أخرى، بدأت التكهنات حول الدافع وراء استحواذ OpenAI على هذا المؤسس – هل كان ذلك لاستيعاب التكنولوجيا، أم لمنع منافس محتمل؟
حاليًا، تم إنشاء مؤسسة OpenClaw، ولا يزال المشروع مفتوح المصدر بالكامل، لكن تعديل أولويات خارطة طريق التطوير واضح: أصبحت ميزات الأمان على مستوى المؤسسات ونظام التحكم في الأذونات هي النقاط المحورية للإصدار التالي.
جدل الأمان: المخاطر التي تجلبها القدرات القوية
أثار الطلب الواسع لـ OpenClaw على أذونات النظام اهتمام باحثي الأمن السيبراني منذ البداية.
في مارس 2026، أعلنت السلطات الصينية عن قيود على تشغيل OpenClaw في أجهزة الكمبيوتر المكتبية للشركات الحكومية والمؤسسات الحكومية، وتشمل المخاوف الرئيسية ما يلي:
- احتمال تسرب البيانات إلى مزودي الخدمة الأجانب عبر استدعاءات API لنموذج اللغة الكبير.
- قد تصبح الأذونات الواسعة نقطة دخول للهجمات عند سوء التكوين.
- قد يتم نقل المعلومات الحساسة الداخلية للشركة عبر الأنظمة بواسطة الوكيل.
يذكر هذا الحدث جميع مطوري الشركات بأن: عند إدخال أدوات وكلاء قوية، فإن مبدأ الحد الأدنى من الأذونات وسجلات التدقيق هي أساسيات أمنية لا يمكن تجاوزها.
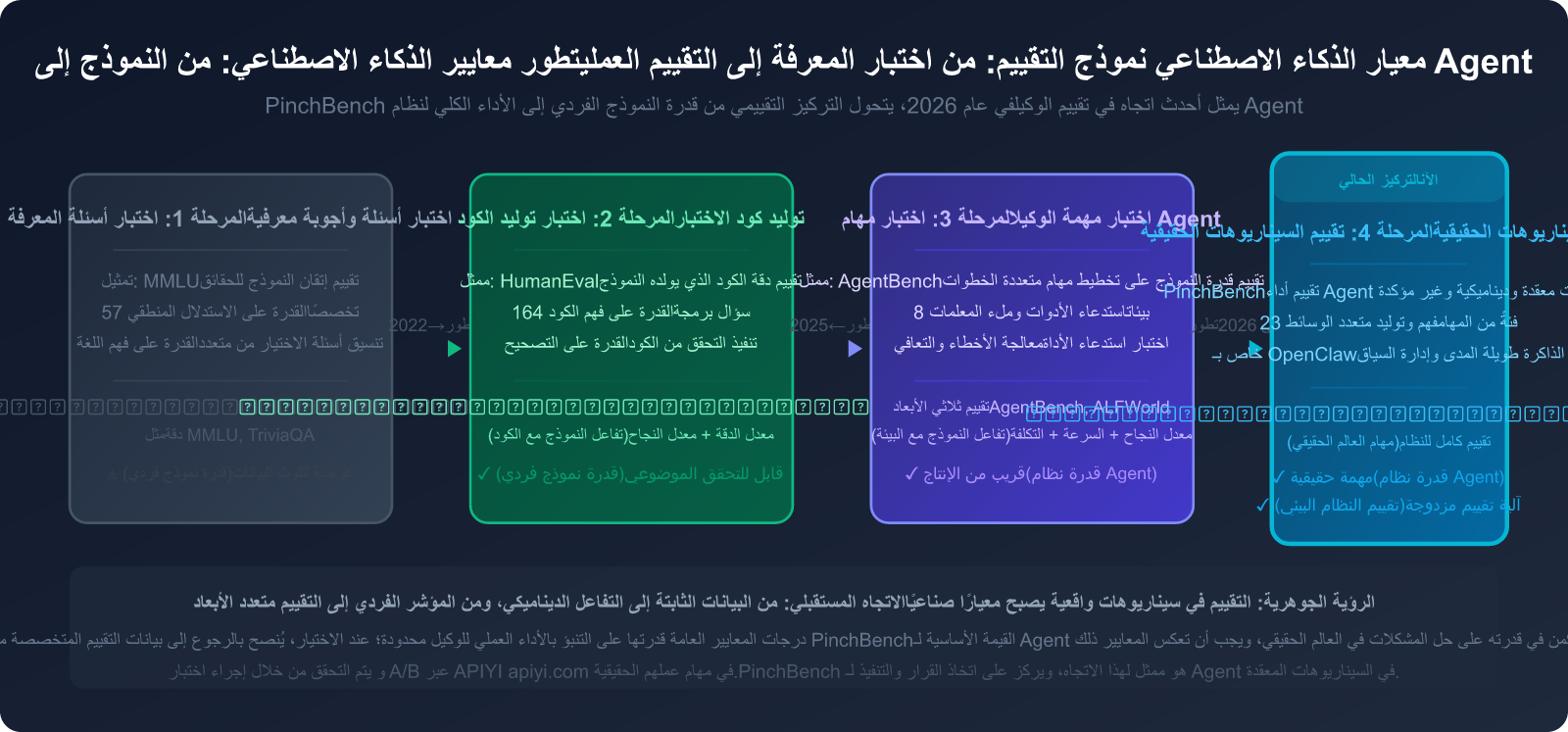
ثانياً: الدور الحقيقي للمقاييس المعيارية (Benchmark) في صناعة الذكاء الاصطناعي: من الاختبار إلى التطبيق العملي
لماذا لا يمكن لصناعة الذكاء الاصطناعي الاستغناء عن المقاييس المعيارية
إذا حاولت يومًا مقارنة قدرات نموذجين للذكاء الاصطناعي، فمن المحتمل أنك واجهت معضلة: جميع الشركات المصنعة تقول إن نموذجها "الأقوى"، لكن ما معنى "قوي"؟ وفي أي مهمة؟ وبالمقارنة مع أي خط أساس؟
المقاييس المعيارية (Benchmark) هي أنظمة اختبار موحدة تم إنشاؤها لحل هذه المشكلة.
في صناعة الذكاء الاصطناعي، يجب أن يفي المقياس المعياري الجيد بثلاثة شروط:
- قابلية التكرار: يمكن لأي شخص الحصول على نفس النتائج باستخدام نفس مجموعة الاختبار.
- التمثيلية: يجب أن يعكس محتوى الاختبار متطلبات القدرة في سيناريوهات الاستخدام الحقيقية.
- النزاهة: يجب ألا تكون مجموعة الاختبار ملوثة ببيانات تدريب مطور النموذج.
في عام 2026، كان هناك أكثر من 15 مقياسًا معياريًا رئيسيًا قيد الاستخدام النشط في الصناعة بأكملها، ولكن التقديرات تشير إلى أن حوالي 4 منها فقط يمكنها التنبؤ بالأداء في بيئات الإنتاج الحقيقية.

قيود المقاييس المعيارية التقليدية
لفهم قيمة PinchBench، يجب أولاً فهم سبب عدم كفاية المقاييس المعيارية التقليدية.
MMLU (فهم اللغة متعدد المهام واسع النطاق)
MMLU هو التقييم الأكثر استخدامًا للمعرفة العامة حاليًا، ويغطي 57 تخصصًا، ويحتوي على حوالي 14,000 سؤال اختيار من متعدد. تشمل الأسئلة مجالات مثل الطب، القانون، التاريخ، الرياضيات، والبرمجة.
المشكلة هي: هذه أسئلة اختيار من متعدد، حيث يحتاج النموذج فقط إلى اختيار إجابة واحدة من 4 خيارات. في سيناريوهات وكلاء الذكاء الاصطناعي الفعلية، يحتاج النموذج إلى توليد الإجابات بشكل مستقل، بل وحتى استدعاء الأدوات للحصول على المعلومات – وهذا يختلف تمامًا عن "اختيار إجابة من 4 خيارات".
HumanEval (اختبار توليد الأكواد)
HumanEval هو مقياس معياري رمزي لقياس قدرة توليد الأكواد، ويحتوي على 164 مشكلة برمجة بايثون. لكن أسئلته ثابتة نسبيًا، وقد يكون النموذج قد تعرض لأنواع مماثلة من الأسئلة أثناء التدريب، مما يؤدي إلى "تأثير الغش" – حيث لا تعكس الدرجات العالية القدرة البرمجية الحقيقية.
العيوب الشائعة للاختبارات الاصطناعية:
| نوع المشكلة | المظهر المحدد | التأثير على نتائج التقييم |
|---|---|---|
| تلوث البيانات | مجموعة التدريب تحتوي على أسئلة الاختبار | الدرجات العالية لا تعكس قدرة التعميم الحقيقية |
| تأثير الغش | تحسين النموذج لمقياس معياري معين | ترتيب وهمي مرتفع، والقدرة الفعلية لم تتحسن |
| انفصال السيناريو | أسئلة الاختيار من متعدد تختلف كثيرًا عن الاستخدام الحقيقي | ضعف القدرة التنبؤية للترتيب |
| مجموعات البيانات الثابتة | الأسئلة ثابتة، ولا يمكن تحديثها | لا يمكن تقييم القدرات الجديدة |
| تقييم أحادي البعد | ينظر فقط إلى الدقة | يتجاهل السرعة، التكلفة، الموثوقية |
الأبعاد الخمسة الأساسية لتقييم وكلاء الذكاء الاصطناعي
عندما يتطور نظام الذكاء الاصطناعي من "الإجابة على الأسئلة" إلى "إنجاز المهام"، يجب أن يتطور نظام التقييم بالتوازي.
بالنسبة لمنصات وكلاء الذكاء الاصطناعي مثل OpenClaw، يجب أن يغطي التقييم الأبعاد الخمسة الرئيسية التالية:
البعد 1: معدل إنجاز المهام (Task Completion Rate)
النسبة الإجمالية للنجاح من استلام المهمة إلى إنجازها النهائي. هذا هو المؤشر الأكثر وضوحًا، ولكنه أيضًا الأكثر تعقيدًا – تعريف "الإنجاز" نفسه هو التحدي الأساسي في تصميم التقييم.
طريقة الاختبار: إعطاء الوكيل مهمة مركبة تتكون من 3-5 خطوات، وحساب نسبة النجاح الكامل، والنجاح الجزئي، والفشل.
البعد 2: دقة استدعاء الأدوات (Tool Call Accuracy)
يحتاج الوكيل إلى اختيار الأداة الصحيحة من بين عشرات الأدوات المتاحة، واستدعائها بمعاملات صحيحة. استدعاء الأداة الخاطئ ليس مجرد فشل، بل قد يؤدي أيضًا إلى آثار جانبية (مثل حذف ملفات عن طريق الخطأ، أو إرسال بريد إلكتروني خاطئ).
طريقة الاختبار: تصميم مهام تتطلب تسلسلًا محددًا للأدوات، وحساب معدل الخطأ في اختيار الأداة ومعدل الخطأ في المعاملات.
البعد 3: اتساق الاستدلال متعدد الخطوات (Multi-step Reasoning Coherence)
يتطلب إنجاز مهمة ما غالبًا 5-10 خطوات، ويحتاج الوكيل إلى الحفاظ على وعي واضح بالهدف طوال العملية، ولا يجب أن "ينسى إلى أين يتجه" أثناء التنفيذ.
طريقة الاختبار: تصميم مهام تتطلب أكثر من 10 خطوات طويلة، ومراقبة ما إذا كان هناك انحراف عن الهدف أو انقطاع منطقي في المنتصف.
البعد 4: الاحتفاظ بالسياق عبر الجولات (Cross-turn Context Retention)
في المحادثات متعددة الجولات، يحتاج الوكيل إلى تذكر المعلومات التي تم تبادلها مسبقًا. معلومات مثل "لقد قلت آخر مرة أن الاجتماع سيكون يوم الأربعاء" ضرورية جدًا في سير عمل OpenClaw.
طريقة الاختبار: تصميم سيناريوهات مهام تتطلب الإشارة إلى معلومات من 5 جولات سابقة أو أكثر، وحساب معدل فقدان السياق.
البعد 5: تكرار الهلوسة (Hallucination Rate)
قيام الوكيل باختلاق ملفات غير موجودة، أو جهات اتصال غير موجودة، أو تواريخ خاطئة، هذه الهلوسات قد تكون مشكلة صغيرة في الدردشة، ولكن في سيناريوهات الوكلاء قد تسبب خسائر حقيقية (مثل إرسال بريد إلكتروني بمحتوى خاطئ).
طريقة الاختبار: تصميم مهام تتطلب الإشارة إلى بيانات حقيقية (أسماء الملفات، عناوين البريد الإلكتروني، التواريخ)، وحساب تكرار حدوث الهلوسة.
🎯 نصيحة للمطورين: عند اختيار نموذج وكيل، فإن معدل إنجاز المهام ودقة استدعاء الأدوات هما أهم مؤشرين.
نوصي باستخدام منصة APIYI (apiyi.com) للاتصال السريع بالعديد من النماذج، والتحقق من فعاليتها في مهامك الفعلية باستخدام الأبعاد الخمسة المذكورة أعلاه،
بدلاً من الاعتماد فقط على أرقام لوحات الصدارة. تدعم APIYI الدفع حسب الاستخدام، وهي مناسبة لإجراء اختبارات A/B صغيرة النطاق قبل اتخاذ القرار النهائي.
ثالثًا: تحليل متعمق لـ PinchBench: معيار التقييم الرسمي لـ OpenClaw
خلفية نشأة PinchBench
تم تطوير PinchBench بواسطة فريق kilo.ai باستخدام Rust، وهو معيار تقييم مصمم خصيصًا لسيناريوهات OpenClaw، وقد تم إصداره كمصدر مفتوح على GitHub (مستودع pinchbench/skill).
المشكلة الأساسية التي يحلها: قدرة لوحات صدارة النماذج العامة على التنبؤ بأداء الوكلاء (Agent) الحقيقي ضعيفة جدًا.
أظهرت الأبحاث أن نموذجًا يحتل المرتبة الأولى ضمن أفضل 5% في MMLU، قد يكون أداؤه في مهمة OpenClaw المدمجة لتصنيف البريد الإلكتروني وجدولة الاجتماعات، أسوأ بكثير من نموذج ذي ترتيب متوسط في MMLU ولكنه مُحسّن خصيصًا لاستدعاء الأدوات.
مع ظهور PinchBench، أصبح لدى المطورين لأول مرة معيار تقييم موثوق به ومخصص لسير عمل الوكلاء (Agent).
23 فئة مهمة في PinchBench
يستخدم PinchBench مهامًا حقيقية بدلاً من المسائل الاصطناعية، ويغطي 23 فئة مهمة، كل فئة منها تتوافق مع سيناريو استخدام حقيقي لمستخدمي OpenClaw:
فئات المهام الأساسية (6 فئات رئيسية):
| فئة المهمة الرئيسية | محتوى الاختبار المحدد | الأدوات المعنية | صعوبة التقييم |
|---|---|---|---|
| إدارة الجداول | جدولة الاجتماعات، حل النزاعات، التعامل مع المناطق الزمنية، التذكيرات الدورية | واجهة برمجة تطبيقات التقويم (Calendar API)، أدوات المناطق الزمنية | ★★★☆☆ |
| كتابة الكود | تنفيذ الوظائف، إصلاح الأخطاء (Bug Fixing)، إعادة هيكلة الكود، اختبار الوحدات | تنفيذ الكود، نظام الملفات | ★★★★☆ |
| معالجة البريد الإلكتروني | التصنيف، ترتيب الأولويات، مسودات الرد التلقائي، معالجة المرفقات | واجهة برمجة تطبيقات عميل البريد الإلكتروني (Email Client API) | ★★★☆☆ |
| البحث عن المعلومات | البحث عبر الويب، تجميع المعلومات، توليد الملخصات، التحقق من المصادر | محركات البحث، المتصفحات | ★★★★☆ |
| إدارة الملفات | التنظيم، تحويل التنسيقات، العمليات المجمعة، التحكم في الإصدارات | نظام الملفات، أدوات التحويل | ★★☆☆☆ |
| التعاون متعدد الأدوات | تدفق البيانات عبر الأنظمة الأساسية، تنسيق سلسلة الأدوات، التشغيل الشرطي | مجموعات أدوات متعددة | ★★★★★ |
منهجية تقييم PinchBench
يعتمد PinchBench على آلية تقييم مزدوجة، تجمع بين الموضوعية وتقييم الجودة:
التحقق الآلي (Automated Checks)
يُستخدم للمعايير الموضوعية القابلة للتحقق:
- هل اجتاز الكود جميع حالات الاختبار؟
- هل تم نقل الملفات بشكل صحيح إلى الموقع المحدد؟
- هل تم إنشاء أحداث التقويم في الوقت الصحيح؟
- هل استدعاء API يعيد التنسيق المتوقع؟
حَكَم نموذج اللغة الكبير (LLM Judge)
يُستخدم للتقييم النوعي الذي يتطلب حكمًا ذاتيًا:
- نبرة الرد على البريد الإلكتروني ومستوى الاحترافية
- دقة واكتمال المعلومات في التقرير البحثي
- دقة فهم المهمة (هل فهم حقًا نية المستخدم؟)
- مدى معقولية استراتيجية التعامل مع الحالات الهامشية
توازن هذه الطريقة المدمجة بين الكفاءة (يمكن تشغيل الفحوصات الآلية على نطاق واسع) والجودة (يلتقط حَكَم نموذج اللغة الكبير التفاصيل التي يصعب على البشر قياسها كميًا).
مصفوفة مؤشرات التقييم ثلاثية الأبعاد:
┌─────────────────────────────────────────────────┐
│ نظام تقييم PinchBench ثلاثي الأبعاد │
├─────────────────────────────────────────────────┤
│ معدل النجاح (Success Rate) │
│ → قياس شامل لجودة إنجاز المهمة │
│ → البعد الرئيسي للترتيب │
│ → يجمع بين التحقق الآلي + حَكَم نموذج اللغة الكبير │
├─────────────────────────────────────────────────┤
│ السرعة (Speed) │
│ → متوسط وقت إنجاز المهمة (ثانية/دقيقة) │
│ → بالغ الأهمية لسيناريوهات الاستجابة في الوقت الفعلي │
│ → يتضمن تأخير API ووقت الاستدلال │
├─────────────────────────────────────────────────┤
│ التكلفة (Cost) │
│ → تكلفة التوكن المستهلكة لإنجاز المهمة (دولار أمريكي) │
│ → مؤشر رئيسي لسيناريوهات الاستخدام المتكرر │
│ → يساعد في حساب عائد الاستثمار (ROI) وقرارات الاختيار │
└─────────────────────────────────────────────────┘
حتى تاريخ 13 مارس 2026، بيانات لوحة صدارة PinchBench العامة هي:
- 📊 49 نموذجًا أكملت التقييم، تغطي جميع النماذج التجارية والمفتوحة المصدر الرئيسية
- 🔄 327 سجل تشغيل، يتم تحديثها باستمرار
- 🌐 لوحة الصدارة العامة: pinchbench.com (تحديثات فورية)
- 📁 المستودع مفتوح المصدر: github.com/pinchbench/skill (تعريفات المهام عامة)
🎯 نصيحة لاستخدام PinchBench: عند تصفح لوحة الصدارة، يُنصح بالتبديل بين طرق العرض الثلاثة: معدل النجاح، السرعة، والتكلفة،
لاختيار النموذج الأنسب بناءً على احتياجاتك الفعلية (الاستجابة الفورية مقابل الجودة مقابل التكلفة).
بعد الاتصال الموحد عبر APIYI apiyi.com، يمكنك بسهولة مقارنة التكاليف الفعلية للنماذج المختلفة في نفس السيناريو التجاري.
رابعًا: تحليل متعمق للوحة صدارة PinchBench ودليل اختيار النماذج
ترتيب أفضل 5 نماذج حسب معدل النجاح الحالي (بيانات 13 مارس 2026)

| الترتيب | اسم النموذج | معدل النجاح | نوع النموذج | الميزة الأساسية |
|---|---|---|---|---|
| 🥇 1 | Claude Sonnet 4.6 | 86.9% | تجاري مغلق المصدر | أعلى معدل نجاح، توازن بين السرعة والجودة |
| 🥈 2 | Claude Opus 4.6 | 86.3% | تجاري مغلق المصدر | أقوى قدرة على الاستدلال المعقد |
| 🥉 3 | GPT-5.4 | 86.0% | تجاري مغلق المصدر | استقرار جيد في استدعاء الأدوات |
| 4 | Nvidia Nemotron-3-Super-120B | 85.6% | مفتوح المصدر قابل للنشر | الأداء الأفضل بين النماذج مفتوحة المصدر |
| 5 | Claude Opus 4.5 | 85.4% | تجاري مغلق المصدر | الجيل الرائد السابق، لا يزال يتمتع بقدرة تنافسية |
رؤى بيانات رئيسية: ماذا يعني معدل نجاح 85%؟
تتركز معدلات نجاح النماذج الرائدة في PinchBench في نطاق 85%-87%، بدلاً من الاقتراب من الدرجة الكاملة. يحمل هذا الرقم في حد ذاته ثلاث إشارات مهمة:
الإشارة 1: مهام وكلاء الذكاء الاصطناعي (AI Agent) لا تزال تمثل مشكلة عالية الصعوبة حتى الآن
حتى النموذج الأول Claude Sonnet 4.6 (86.9%)، يفشل في حوالي 13 مهمة من أصل 100. هذا لا يعود إلى نقص في قدرة النموذج، بل إلى التعقيد المتأصل في مهام العالم الحقيقي – فالتعليمات الغامضة، والمعلومات غير الكاملة، والحالات الهامشية في استدعاء الأدوات، كلها يمكن أن تؤدي إلى الفشل.
الإشارة 2: تصميم التسامح مع الأخطاء لا غنى عنه في تطوير الوكلاء (Agent)
عندما يكون معدل الفشل 13% "مستوىً رائدًا"، فإن سير عمل الوكلاء (Agent) الأوتوماتيكي بالكامل بدون نقاط مراجعة بشرية يكون عالي المخاطر في بيئات الإنتاج. أفضل الممارسات هي: الاحتفاظ بخطوات تأكيد يدوية للعمليات عالية المخاطر (مثل إرسال رسائل البريد الإلكتروني، أو إرسال الكود).
الإشارة 3: الفجوة بين النماذج ضئيلة جدًا، وتصميم المهمة أكثر أهمية
الفجوة بين الترتيب الأول والترتيب الخامس تبلغ 1.5 نقطة مئوية فقط (86.9% مقابل 85.4%). هذا يعني أن تأثير اختيار النموذج أقل بكثير من تأثير كيفية تصميم موجه المهمة، وكيفية تعريف واجهات الأدوات، وكيفية التعامل مع حالات الأخطاء.
تحليل شامل للمؤشرات ثلاثية الأبعاد
النظر إلى معدل النجاح وحده لا يكفي. فيما يلي إطار عمل للاعتبارات الشاملة من الأبعاد الثلاثة:
| سيناريو الاستخدام | المؤشر ذو الأولوية | المؤشر الثانوي | اتجاه النموذج الموصى به |
|---|---|---|---|
| مهام خفيفة متكررة (تصنيف البريد، التذكيرات) | السرعة + التكلفة | معدل النجاح | نماذج خفيفة مثل Claude Haiku 4.5 |
| مهام هندسية معقدة (إعادة هيكلة الكود، البحث) | معدل النجاح | السرعة | Claude Sonnet 4.6 / GPT-5.4 |
| سيناريوهات الاستجابة في الوقت الفعلي (مساعد فوري) | السرعة | معدل النجاح | النماذج الرائدة في قائمة السرعة |
| تطبيقات حساسة للتكلفة | التكلفة | معدل النجاح | نماذج مفتوحة المصدر ذاتية النشر / نماذج API منخفضة التكلفة |
| امتثال أمن الشركات | معدل النجاح + قابلية التحكم | التكلفة | نماذج مفتوحة المصدر منشورة بشكل خاص |
🎯 نصيحة شاملة لاختيار النموذج: بناءً على بيانات PinchBench، يُعد Claude Sonnet 4.6 الخيار الشامل الأعلى في معدل النجاح لسيناريوهات OpenClaw الحالية.
بالنسبة للسيناريوهات عالية التكرار والحساسة للتكلفة، يُنصح أولاً باستخدام Claude Sonnet 4.6 لتحديد خط أساس لمعدل نجاح المهمة،
ثم اختبار ما إذا كانت النماذج الأخف وزنًا يمكنها تقليل التكلفة بشكل كبير ضمن نطاق معدل النجاح المسموح به.
يمكن إجراء جميع هذه الاختبارات عبر واجهة API الموحدة لـ APIYI apiyi.com، دون الحاجة إلى تسجيل حسابات متعددة لمقدمي الخدمة.
تحليل القدرة التنافسية للنماذج مفتوحة المصدر
يحتل Nvidia Nemotron-3-Super-120B المرتبة الرابعة بمعدل نجاح 85.6%، وهو أقل بنسبة 1.3 نقطة مئوية فقط من المركز الأول – وهذا إنجاز لافت جدًا بالنسبة لنموذج مفتوح المصدر.
مزايا النماذج مفتوحة المصدر:
- سيادة البيانات: النموذج والبيانات كلاهما في بيئة خاضعة للتحكم الذاتي، مما يلبي متطلبات الامتثال.
- هيكل التكلفة: استثمار لمرة واحدة في وحدات معالجة الرسوميات (GPU)، بدون رسوم استدعاء API لاحقة (في سيناريوهات الحجم الكبير).
- مساحة التخصيص: يمكن ضبطها بدقة (Fine-tuning) لمهام محددة.
قيود النماذج مفتوحة المصدر:
- تكلفة النشر: يتطلب نموذج بـ 120 مليار معلمة من 4 إلى 8 وحدات معالجة رسوميات (GPU) من نوع A100/H100.
- عبء الصيانة: تحديثات النموذج وإدارة الإصدارات تتطلب عمليات تشغيل وصيانة متخصصة.
- تكلفة الاختبار الأولي: قبل التأكد من أن النموذج مفتوح المصدر مناسب لسيناريو الاستخدام الخاص بك، غالبًا ما يكون التحقق من النموذج الأولي عبر واجهة برمجة تطبيقات تجارية أكثر اقتصادية.
خامساً: دليل عملي: كيفية تهيئة النموذج الأمثل في OpenClaw
ربط Claude Sonnet 4.6 لتشغيل OpenClaw بسرعة
فيما يلي مثال كامل لتهيئة ربط نموذج PinchBench الأول عبر APIYI:
الخطوة 1: الحصول على مفتاح API
قم بزيارة موقع APIYI الرسمي apiyi.com للتسجيل والحصول على مفتاح API من لوحة التحكم. توفر APIYI واجهات متوافقة مع OpenAI، وتدعم أيضاً حزمة تطوير البرمجيات (SDK) الأصلية لـ Anthropic.
الخطوة 2: تهيئة الواجهة الخلفية للنموذج في OpenClaw
# مثال على ملف تهيئة OpenClaw (config.yaml)
model:
provider: anthropic
name: claude-sonnet-4-6
api_key: "${APIYI_API_KEY}"
base_url: "https://api.apiyi.com/v1"
agent:
max_steps: 20 # الحد الأقصى لعدد خطوات التنفيذ
tool_timeout: 30 # مهلة استدعاء الأداة الواحدة (بالثواني)
retry_on_error: true # إعادة المحاولة تلقائياً عند فشل استدعاء الأداة
human_review:
enabled: true
trigger: ["send_email", "commit_code", "delete_file"] # العمليات عالية المخاطر تتطلب موافقة بشرية
الخطوة 3: التحقق من فعالية التهيئة
# استخدام Anthropic SDK لاختبار الاتصال
import anthropic
client = anthropic.Anthropic(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
# إرسال طلب اختبار
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[{
"role": "user",
"content": "الرجاء ذكر 3 أنواع من المهام التي يمكنك تنفيذها في OpenClaw"
}]
)
print(response.content[0].text)
الخطوة 4: تهيئة اختبار A/B لعدة نماذج
# مقارنة نماذج مختلفة على نفس المهمة (يوصى بها قبل النشر الرسمي)
models_to_test = [
"claude-sonnet-4-6", # الأول في تصنيف PinchBench
"gpt-5.4-turbo", # الثالث في تصنيف PinchBench (متوافق مع صيغة OpenAI)
"claude-opus-4-5", # الجيل السابق الرائد، للمقارنة المرجعية للتكلفة
]
# تدعم APIYI استدعاء واجهة برمجة تطبيقات موحدة لجميع النماذج المذكورة أعلاه
# base_url لا يتغير، فقط قم بتعديل معلمة model
for model_name in models_to_test:
result = run_benchmark_task(
model=model_name,
task="schedule_weekly_team_meeting",
base_url="https://api.apiyi.com/v1"
)
print(f"{model_name}: معدل النجاح={result.success_rate}, الوقت المستغرق={result.avg_time}s, التكلفة=${result.cost_per_task}")
🎯 ابدأ بسرعة: قم بزيارة APIYI apiyi.com للتسجيل والحصول على رصيد تجريبي،
يدعم الربط الموحد لواجهة برمجة التطبيقات لنماذج PinchBench الرائدة مثل Claude Sonnet 4.6 و GPT-5.4،
دون الحاجة إلى طلب أذونات وصول منفصلة من مزودي خدمة متعددين، مما يقلل بشكل كبير من العوائق الأولية لاختبار النماذج.
اختبار Agent الخاص بك ذاتياً باستخدام أبعاد PinchBench الخمسة
قبل النشر في بيئة الإنتاج، يوصى بتقييم تهيئة Agent الخاص بك باستخدام قائمة الاختبار الذاتي التالية:
قائمة اختبار Agent الذاتي المستوحاة من PinchBench
□ البعد 1 - معدل إنجاز المهام
أعطِ Agent 10 مهام مركبة تتكون من 3 خطوات أو أكثر
سجل عدد المهام المكتملة كلياً / المكتملة جزئياً / الفاشلة
الهدف: معدل إنجاز كلي ≥ 80%
□ البعد 2 - دقة استدعاء الأداة
راجع سجلات استدعاء الأداة، واحصِ أنواع الأخطاء التالية:
- خطأ في اختيار الأداة (تم اختيار أداة خاطئة)
- خطأ في تنسيق المعلمة (نوع المعلمة أو تنسيقها غير صحيح)
- خطأ في قيمة المعلمة (نوع المعلمة صحيح ولكن القيمة غير منطقية)
الهدف: معدل خطأ الأداة ≤ 5%
□ البعد 3 - اتساق الاستدلال متعدد الخطوات
صمم مهمة تتطلب أكثر من 15 خطوة
راقب ما إذا كان هناك انحراف عن الهدف في المنتصف (نسيان الهدف الأصلي)
الهدف: عدم انحراف عن الهدف في المهام طويلة الأمد
□ البعد 4 - الاحتفاظ بالسياق
قدم معلومات أساسية في الجولة الأولى، واستشهد بها في الجولة الثامنة
تحقق مما إذا كان Agent يمكنه الاستشهاد بها بشكل صحيح
الهدف: دقة الاستشهاد عبر الجولات ≥ 90%
□ البعد 5 - اكتشاف الهلوسة
صمم مهام تتطلب الاستشهاد ببيانات حقيقية (اسم ملف/جهة اتصال/تاريخ)
تحقق مما إذا كان Agent يختلق بيانات غير موجودة
الهدف: معدل حدوث الهلوسة ≤ 2%
سادساً: مستقبل معايير الذكاء الاصطناعي: من التقييم الفردي إلى تقييم النظام البيئي
اتجاهات تطور نظام المعايير الحالي
في عام 2026، يشهد مجال معايير الذكاء الاصطناعي تحولاً عميقاً. يكمن جوهر هذا التحول في توسيع نطاق التقييم من النموذج الفردي ليشمل أنظمة Agent الكاملة.
كانت طريقة التفكير التقليدية في المعايير هي: إعطاء النموذج أسئلة، ومعرفة ما إذا كان يجيب عليها بشكل صحيح. ولكن بعد انتشار منصات Agent مثل OpenClaw، أصبح السؤال المهم حقاً هو: عندما يعمل النموذج كـ "عقل" لنظام، هل يمكنه جعل هذا النظام ينجز العمل؟
إجابة هذا السؤال لا تعتمد فقط على مخزون المعرفة لدى النموذج، بل تعتمد أيضاً على:
- قدرة النموذج على فهم وصف الأدوات
- استراتيجيات اتخاذ القرار للنموذج في ظل المعلومات غير المؤكدة
- قدرة النموذج على تحديد الأخطاء والتعافي منها
- قدرة النموذج على تتبع نية المستخدم على المدى الطويل
تكمن قيمة PinchBench في أنه يقيس هذه الأبعاد ويعرضها علناً.
الاستخدام الصحيح لبيانات معايير الذكاء الاصطناعي
بيانات المعايير قيمة، ولكن من السهل إساءة استخدامها. فيما يلي بعض الأخطاء الشائعة والممارسات الصحيحة:
الخطأ 1: اعتبار النموذج الأعلى تصنيفاً "الأفضل دائماً"
الممارسة الصحيحة: يعتمد التصنيف على مجموعة مهام PinchBench المحددة، وقد يكون لمهامك توزيع أوزان مختلف. اختبر أولاً على مهامك الخاصة، ثم اختر النموذج.
الخطأ 2: التركيز فقط على معدل النجاح، وتجاهل السرعة والتكلفة
الممارسة الصحيحة: المؤشرات ثلاثية الأبعاد لا غنى عنها. في سيناريوهات المعالجة الدفعية، يعني فرق السرعة بنسبة 50% توفيراً في التكلفة بنسبة 50%؛ وفي سيناريوهات الاستجابة في الوقت الفعلي، يعني فرق السرعة بثانيتين تدهوراً كبيراً في تجربة المستخدم.
الخطأ 3: الاعتقاد بأن فرق 1% في معدل النجاح غير مهم
الممارسة الصحيحة: قد يبدو فرق 1% في معدل النجاح ضئيلاً في الاختبارات صغيرة النطاق، ولكنه قد يؤدي إلى مئات الإخفاقات يومياً في سيناريوهات الإنتاج عالية التردد. يجب تقييم التأثير الفعلي بالاقتران مع حجم مهامك.
الخطأ 4: استخدام بيانات المعايير الثابتة للتخطيط طويل الأجل
الممارسة الصحيحة: تتطور نماذج الذكاء الاصطناعي بسرعة فائقة، حيث يصدر المصنعون الرئيسيون تحديثاً مهماً كل ربع سنة في المتوسط في عام 2026. يوصى بدمج تقييم أداء النموذج في المراجعات التقنية المنتظمة، بدلاً من "اختيار نموذج واحد مدى الحياة".
أفضل الممارسات لتقييم Agent على مستوى المؤسسة
بالنسبة للفرق التقنية التي تنشر OpenClaw أو منصات Agent المماثلة في المؤسسات، إليك مجموعة من أفضل الممارسات القابلة للتطبيق للتقييم:
الخطوة الأولى: إنشاء مجموعة مهام أساسية
اختر من 20 إلى 50 مهمة نموذجية من عمليات عملك الفعلية، تغطي العمليات اليومية عالية التردد والسيناريوهات المعقدة العرضية. يجب أن يتم تعريف مجموعة المهام هذه بشكل مشترك من قبل فريق العمل والفريق التقني لتجنب تحيز التقييم الناتج عن المنظور التقني البحت.
الخطوة الثانية: التتبع المستمر للمؤشرات ثلاثية الأبعاد
اقتراح نظام مؤشرات تقييم Agent الداخلي للمؤسسة
المؤشرات الأساسية (إحصائيات أسبوعية):
- معدل إنجاز المهام: الهدف ≥ 85% (بما يتماشى مع مستوى أفضل نماذج PinchBench)
- معدل خطأ استدعاء الأداة: الهدف ≤ 5%
- متوسط الوقت المستغرق للمهمة: يُحدد وفقاً لاتفاقية مستوى الخدمة (SLA) للعمل
المؤشرات المساعدة (إحصائيات شهرية):
- تكلفة الـ Token/المهمة: للتحكم في تكاليف التشغيل
- معدل التدخل البشري: نسبة المهام التي تتطلب تدخلاً بشرياً
- توزيع أنواع الأخطاء: لتحليل اتجاهات التحسين
مؤشرات الإنذار (مراقبة في الوقت الفعلي):
- معدل فشل العمليات عالية المخاطر: إرسال تنبيه فوري عند فشل إرسال بريد إلكتروني/حذف ملف، إلخ.
- حوادث الهلوسة: يجب تسجيل وتحليل حالات اختلاق المعلومات فوراً
الخطوة الثالثة: إعادة تقييم النموذج بانتظام
يوصى بإعادة تقييم النموذج المنشور حالياً، بالإضافة إلى النماذج المرشحة الجديدة، باستخدام مجموعة المهام الداخلية كل ربع سنة. بالاقتران مع أحدث البيانات العامة لـ PinchBench، حدد ما إذا كان هناك حاجة للترقية أو تبديل النموذج.
الخطوة الرابعة: تجميع المعرفة المتخصصة
لا يمكن للمعايير العامة تغطية السيناريوهات الخاصة بكل مؤسسة. مع تراكم الاستخدام، قم تدريجياً بإنشاء مجموعة مهام ومعايير تقييم خاصة بعملك، والتي ستصبح أداة تصفية مهمة لاختيار مزودي الذكاء الاصطناعي.
🎯 نصيحة لاختيار المؤسسات: في المراحل الأولية لإدخال منصة Agent، يوصى بالربط مع عدة نماذج مرشحة عبر APIYI apiyi.com بنظام الدفع حسب الاستخدام،
وإجراء اختبارات فعلية لمدة 3-4 أسابيع باستخدام مجموعة المهام الداخلية الخاصة بك قبل اتخاذ قرار بالانتقال إلى خطة الاشتراك الشهري.
تدعم APIYI واجهة موحدة للنماذج الرائدة مثل Claude و GPT و Gemini،
مما يقلل بشكل كبير من تكاليف إدارة التقييم خلال مرحلة الاختبار دون الحاجة إلى تسجيل حسابات منفصلة لدى مزودي خدمة متعددين.
أسئلة شائعة
س: ما هو الفرق الجوهري بين OpenClaw و AutoGPT و AutoGen؟
يكمن الاختلاف الجوهري في OpenClaw في طريقة الوصول وسهولة الاستخدام: فهو يوفر واجهة الوكيل (Agent) عبر تطبيقات المراسلة (مثل Signal و WhatsApp)، مما يعني أن المستخدمين العاديين لا يحتاجون إلى تثبيت تطبيق مخصص أو فهم التفاصيل التقنية. من منظور البنية التقنية، OpenClaw أقرب إلى "مساعد شخصي بالذكاء الاصطناعي"، بينما الأطر مثل AutoGen أكثر ملاءمة للمطورين لبناء أنظمة وكلاء متعددة معقدة. يركز OpenClaw على "تجربة المستهلك الجاهزة للاستخدام"، بينما يركز AutoGen على "إطار عمل تطوير مرن على مستوى المؤسسات".
🎯 بغض النظر عن إطار عمل الوكيل الذي تختاره، يمكنك الوصول الموحد إلى نماذج الواجهة الخلفية عبر APIYI apiyi.com، لتجنب الحاجة إلى تكوين مفتاح API لكل إطار عمل على حدة.
س: كم مرة يتم تحديث ترتيب معدل النجاح في PinchBench؟
يتم تحديث لوحة صدارة PinchBench في الوقت الفعلي – ففي كل مرة يكمل فيها نموذج جديد التقييم، تنعكس البيانات فورًا على pinchbench.com. ومع استمرار الشركات الكبرى في إصدار إصدارات جديدة، تتغير التصنيفات بشكل متكرر. يُنصح بالتحقق من أحدث البيانات قبل اتخاذ قرار الاختيار النهائي. تستند بيانات هذه المقالة إلى لقطة بتاريخ 13 مارس 2026 (49 نموذجًا، 327 سجل تشغيل).
س: كيف أختار النموذج الأنسب لـ OpenClaw؟
نوصي باتباع طريقة الاختيار المكونة من ثلاث خطوات:
- النظر إلى معدل نجاح PinchBench: قم بتصفية أفضل 5 نماذج من حيث معدل إنجاز المهام.
- النظر إلى بُعدي السرعة والتكلفة: قم بالتصفية بناءً على نوع مهمتك (في الوقت الفعلي مقابل المعالجة الدفعية، عالية التردد مقابل منخفضة التردد).
- اختبار A/B الفعلي: قارن بين 2-3 نماذج مرشحة في مهام عملك الحقيقية.
عبر APIYI apiyi.com، يمكنك التبديل بسرعة بين النماذج المختلفة باستخدام نفس
base_url، واتخاذ القرار النهائي بعد إكمال اختبار A/B.
س: هل يمكن للنماذج مفتوحة المصدر أن تحل محل النماذج التجارية بالكامل لتشغيل OpenClaw؟
بالنظر إلى بيانات PinchBench، يبلغ الفارق بين Nvidia Nemotron-3-Super-120B (85.6%) والنموذج التجاري الرائد (86.9%) حوالي 1.3 نقطة مئوية. بالنسبة لمهام الوكيل العامة، يمكن قبول هذا الفارق. ولكن يجب ملاحظة أن نشر نموذج بـ 120 مليار معلمة يتطلب 4-8 وحدات معالجة رسومية (GPU) عالية الأداء، مما يعني أن تكاليف الاستثمار الأولي في الأجهزة والتشغيل والصيانة ليست منخفضة. يُنصح أولاً بالتحقق من جدوى تصميم الوكيل باستخدام واجهة برمجة تطبيقات (API) تجارية، ثم تقييم ما إذا كان يستحق الانتقال إلى نموذج مفتوح المصدر يتم نشره ذاتيًا.
س: كيف يمكن تجنب المخاطر الأمنية لـ OpenClaw؟
المبدأ الأساسي هو أقل الامتيازات: امنح OpenClaw فقط الحد الأدنى من الامتيازات المطلوبة لإكمال المهام. توصيات محددة:
- صلاحية قراءة البريد الإلكتروني فقط (وليس صلاحيات القراءة والكتابة والحذف الكاملة)
- صلاحية قراءة مستودع الأكواد + صلاحية تقديم طلبات السحب (PR) (وليس الدفع مباشرة إلى الفرع الرئيسي)
- تحديد نظام الملفات بمسار عمل محدد (وليس نظام الملفات بأكمله)
- يجب أن تتضمن العمليات عالية المخاطر (إرسال بريد إلكتروني، حذف ملفات) خطوة تأكيد يدوية
عند النشر في الشركات، يلزم أيضًا تكوين سجلات تدقيق عمليات كاملة لضمان وجود سجل قابل للتتبع لكل عملية يقوم بها الوكيل.
س: ما الفرق بين PinchBench ومعايير تقييم الوكلاء الأخرى؟
الميزة الأبرز لـ PinchBench هي تخصصه في السيناريوهات: فهو مصمم خصيصًا لسيناريوهات استخدام OpenClaw، وليس لتقييم الوكلاء بشكل عام. هذا يعني أن قيمته المرجعية لمستخدمي OpenClaw أعلى، ولكنه غير مناسب للاستخدام المباشر لتقييم اختيار النماذج لأطر عمل الوكلاء الأخرى. تشمل معايير تقييم الوكلاء المعروفة الأخرى AgentBench (الذي يغطي بيئات متعددة) و SWE-Bench (الذي يركز على مهام الأكواد)، ولكل منها تركيزه الخاص.
ملخص: OpenClaw + PinchBench يضعان معيارًا جديدًا لعصر الوكلاء
نما OpenClaw من مشروع عطلة نهاية أسبوع لمطور نمساوي ليصبح أحد أكثر منصات الوكلاء الذكية بالذكاء الاصطناعي شعبية عالميًا في غضون شهرين، وهذا يعكس الشوق الشديد للصناعة بأكملها إلى "الذكاء الاصطناعي الذي ينجز المهام فعليًا".
وقد أدى ظهور PinchBench إلى سد فجوة حاسمة في مجال تقييم الوكلاء: أصبح لدينا أخيرًا مقياس مصمم خصيصًا لقياس قدرات الوكيل.
نظرة سريعة على الاستنتاجات الرئيسية:
- Claude Sonnet 4.6 هو الخيار الأمثل الشامل لسيناريوهات OpenClaw الحالية (معدل نجاح 86.9%، الأول في تصنيف PinchBench).
- تتركز معدلات نجاح النماذج الرائدة بين 85-87%، ولا تزال مهام الوكيل تمثل تحديًا، وتصميم التسامح مع الأخطاء لا غنى عنه.
- السرعة والتكلفة لهما نفس الأهمية، فالنماذج ذات معدل النجاح المرتفع قد لا تكون مناسبة لجميع السيناريوهات، ويتطلب الأمر تقييمًا شاملاً ثلاثي الأبعاد.
- يمثل PinchBench الاتجاه المستقبلي لتقييم الذكاء الاصطناعي: مهام السيناريوهات الحقيقية تحل محل الاختبارات الاصطناعية.
- يبلغ الفارق في اختيار النموذج حوالي 1-2%، وغالبًا ما يكون تأثير تصميم المهام وهندسة الموجهات أكبر.
بالنسبة للمطورين والشركات الراغبين في التعمق في نظام OpenClaw البيئي، الآن هو الوقت المثالي:
المجتمع مفتوح المصدر نشط، وأدوات التقييم متكاملة، وتكاليف الوصول إلى واجهات برمجة تطبيقات (API) النماذج السائدة آخذة في الانخفاض. لست بحاجة إلى انتظار ظهور "الحل الأمثل"، يمكنك البدء الآن في التحقق من جدوى سير عمل الوكيل بمهام صغيرة النطاق.
🎯 تصرف الآن: إذا كنت تبني سير عمل للذكاء الاصطناعي يعتمد على OpenClaw، نوصي بالوصول الموحد عبر APIYI apiyi.com.
تدعم المنصة النماذج السائدة مثل Claude Sonnet 4.6 (الأول في PinchBench) و GPT-5.4 (الثالث)،
بنفس واجهة API، دون الحاجة إلى التسجيل بشكل منفصل لدى عدة مزودين، وتدعم الفوترة حسب الاستخدام، مما يجعلها مناسبة للبدء باختبارات صغيرة النطاق والتوسع تدريجيًا.
قم بزيارة موقع APIYI الرسمي apiyi.com للتسجيل والبدء في التجربة.
تم تجميع بيانات هذه المقالة بناءً على المعلومات المتاحة للجمهور في مارس 2026. للاطلاع على بيانات لوحة صدارة PinchBench في الوقت الفعلي، يرجى زيارة pinchbench.com للاطلاع على أحدث إصدار.
المؤلف: فريق APIYI | لمعرفة المزيد حول الوصول إلى واجهات برمجة تطبيقات نماذج الذكاء الاصطناعي، يرجى زيارة APIYI apiyi.com.