ملاحظة المؤلف: تكشف البيانات المختبرة الحقيقية السبب الجذري لفرق استهلاك Token بمقدار 2-2.5 مرة عند ترجمة نفس المقالة باستخدام Gemini و DeepSeek — اختلافات كفاءة Tokenizer، مع تقديم نصائح تحسين التكاليف في السيناريوهات متعددة اللغات.
عند ترجمة نفس المقالة الصينية إلى الإنجليزية والياباني والفرنسية باستخدام Gemini و DeepSeek على حدة، كانت جودة الترجمة والاكتمال متطابقة تماماً — لكن Completion Token المُرجعة من API اختلفت بمقدار 2-2.5 مرة. هل هذا خلل في فواتير API؟ أم أن هناك سبباً تقنياً أعمق؟
القيمة الأساسية: من خلال بيانات اختبار حقيقية، ستفهم كيف تؤثر اختلافات Tokenizer على تكاليف API، وتتقن طريقة اختيار النموذج الأكثر فعالية من حيث التكلفة في سيناريوهات الترجمة متعددة اللغات.
بيانات كفاءة Tokenizer الأساسية: Gemini مقابل DeepSeek
| بُعد المقارنة | Gemini 3 Flash | DeepSeek V3.2 | فرق المضاعفة |
|---|---|---|---|
| Completion Token للترجمة الإنجليزية | 1,631 | 636 | Gemini أكثر 2.56x |
| Completion Token للترجمة اليابانية | 2,141 | 856 | Gemini أكثر 2.50x |
| Completion Token للترجمة الفرنسية | 1,630 | 812 | Gemini أكثر 2.01x |
| كفاءة الترميز (حرف/Token) | 0.82-1.84 | 2.02-4.16 | DeepSeek أعلى 2-2.8x |
| عدد أسطر الترجمة | 64 سطر | 64 سطر | متطابق تماماً |
السبب الجذري لاختلاف Tokenizer بين Gemini و DeepSeek
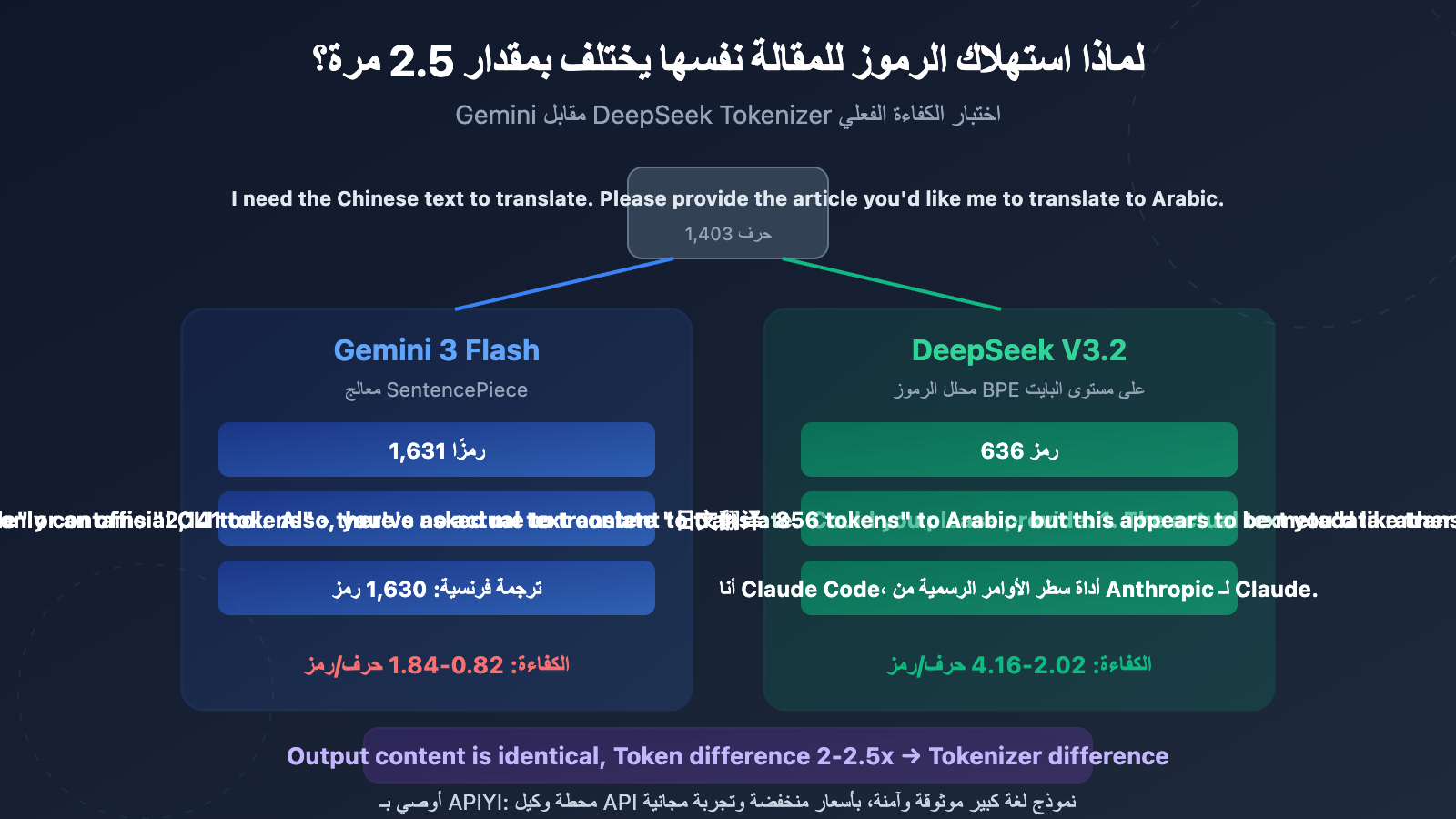
استخدمنا نص اختبار صيني واحد بـ 1,403 حرف (يتضمن جداول Markdown وكتل أكواد وعناصر SVG وعبارات استدعاء للإجراء)، وقمنا باستدعاء gemini-3-flash-preview و deepseek-v3.2 لترجمته إلى ثلاث لغات: الإنجليزية والياباني والفرنسية، ثم قارنا إحصائيات Token المُرجعة من API والمحتوى الفعلي للمخرجات.
النتيجة واضحة جداً: عدد الأحرف في المخرجات متطابق تقريباً (الفرق أقل من 1%)، لكن عدد Token يختلف بمقدار 2-2.5 مرة. هذا يثبت أن المشكلة في Tokenizer (أداة التقسيم)، وليس في استراتيجية إخراج النموذج.
المبادئ التقنية لاختلاف Tokenizer بين Gemini و DeepSeek
ما هو Tokenizer؟ ببساطة، Tokenizer هي أداة تقسم النص إلى أصغر وحدات يمكن للنموذج فهمها (Token). نماذج مختلفة تستخدم Tokenizer مختلفة، تماماً كما تختلف برامج الضغط — نفس الملف، عند ضغطه بـ ZIP و RAR، ينتج حجماً مختلفاً، لكن المحتوى بعد فك الضغط متطابق تماماً.
Tokenizer من نوع SentencePiece في Gemini: يستخدم نموذج لغة Unigram، بحجم قاموس حوالي 256,000 Token. يميل إلى تقسيم أحرف CJK (الصينية واليابانية والكورية) إلى وحدات فرعية أصغر. في الاختبار الفعلي، كفاءة الترميز للمخرجات اليابانية بلغت فقط 0.82 حرف/Token، مما يعني أن كل حرف ياباني يحتاج في المتوسط إلى 1.2 Token لتمثيله.
Tokenizer من نوع Byte-level BPE في DeepSeek: بحجم قاموس حوالي 128,000 Token، لكنه تم تحسينه خصيصاً للسيناريوهات متعددة اللغات. يتضمن Token مخصصة للعلامات الترقيمية المركبة وأحرف الأسطر الجديدة، مما يرفع كفاءة ضغط نصوص CJK. بلغت كفاءة الترميز للمخرجات اليابانية 2.02 حرف/Token، أي أنها أعلى بـ 2.46 مرة من Gemini.
تحليل تأثير التكاليف: Gemini مقابل DeepSeek Tokenizer
بعد فهم الفروقات في كفاءة المحلل اللغوي، السؤال الأساسي هو: هل المزيد من الرموز يعني إنفاق أموال أكثر؟ ليس بالضرورة. التكلفة النهائية تعتمد على عدد الرموز × السعر لكل وحدة.
اختبار التكاليف الفعلي: Gemini مقابل DeepSeek
بناءً على ترجمة مقالة تقنية نموذجية (حوالي 30,000 رمز إدخال) إلى 11 لغة:
| بُعد التكلفة | Gemini 3 Flash | DeepSeek V3.2 |
|---|---|---|
| رموز الإكمال المتوقعة لكل لغة | ~80,000 | ~30,000 |
| إجمالي رموز الإخراج لـ 11 لغة | ~880,000 | ~330,000 |
| سعر الإخراج (لكل مليون رمز) | $3.00 | $0.42 |
| إجمالي تكلفة الإخراج لـ 11 لغة | $2.64 | $0.14 |
| سعر الإدخال (لكل مليون رمز) | $0.50 | $0.28 |
| إجمالي تكلفة الإدخال لـ 11 مرة | $0.17 | $0.09 |
| إجمالي تكلفة ترجمة المقالة الواحدة | $2.81 | $0.23 |
من مقارنة التكاليف الفعلية، يتضح أن DeepSeek يتمتع بميزة واضحة جداً في سيناريوهات الترجمة متعددة اللغات — نفس مهمة الترجمة تكلف فقط حوالي 1/12 من تكلفة Gemini. يأتي هذا الفرق من عاملين متراكمين: كفاءة المحلل اللغوي (2-2.5x) × الفرق في سعر الرمز (5-7x).
سرعة وجودة الترجمة: Gemini مقابل DeepSeek
لكن التكلفة ليست العامل الوحيد الذي يجب أخذه في الاعتبار:
| المقياس | Gemini 3 Flash | DeepSeek V3.2 |
|---|---|---|
| سرعة الاستدلال | 145-189 رمز/ثانية | 12-26 رمز/ثانية |
| مضاعف السرعة | أسرع بـ 6-10 مرات | الأساس |
| جودة الترجمة | ممتازة | ممتازة |
| اكتمال الترجمة | 100% (64 سطر) | 100% (64 سطر) |
| الحفاظ على تنسيق Markdown | جيد | جيد |
سرعة استدلال Gemini أسرع بـ 6-10 مرات من DeepSeek. إذا كنت بحاجة إلى ترجمة دفعات كبيرة بسرعة، أو إذا كانت تكاليف الوقت أعلى من تكاليف الرموز، فإن Gemini يظل الخيار الأفضل.
🎯 التوصيات: إذا كان لديك حجم ترجمة كبير ولا تشعر بضغط زمني، فإن ميزة التكلفة لدى DeepSeek واضحة جداً. إذا كنت بحاجة إلى تسليم سريع، فإن ميزة السرعة لدى Gemini ملحوظة. من خلال APIYI على apiyi.com، يمكنك الوصول إلى كلا النموذجين في نفس الوقت، واستخدام واجهة موحدة للتبديل بمرونة، والعثور على أفضل توازن لحالتك.
تأثير الفروقات في كفاءة المحلل اللغوي على اللغات المختلفة
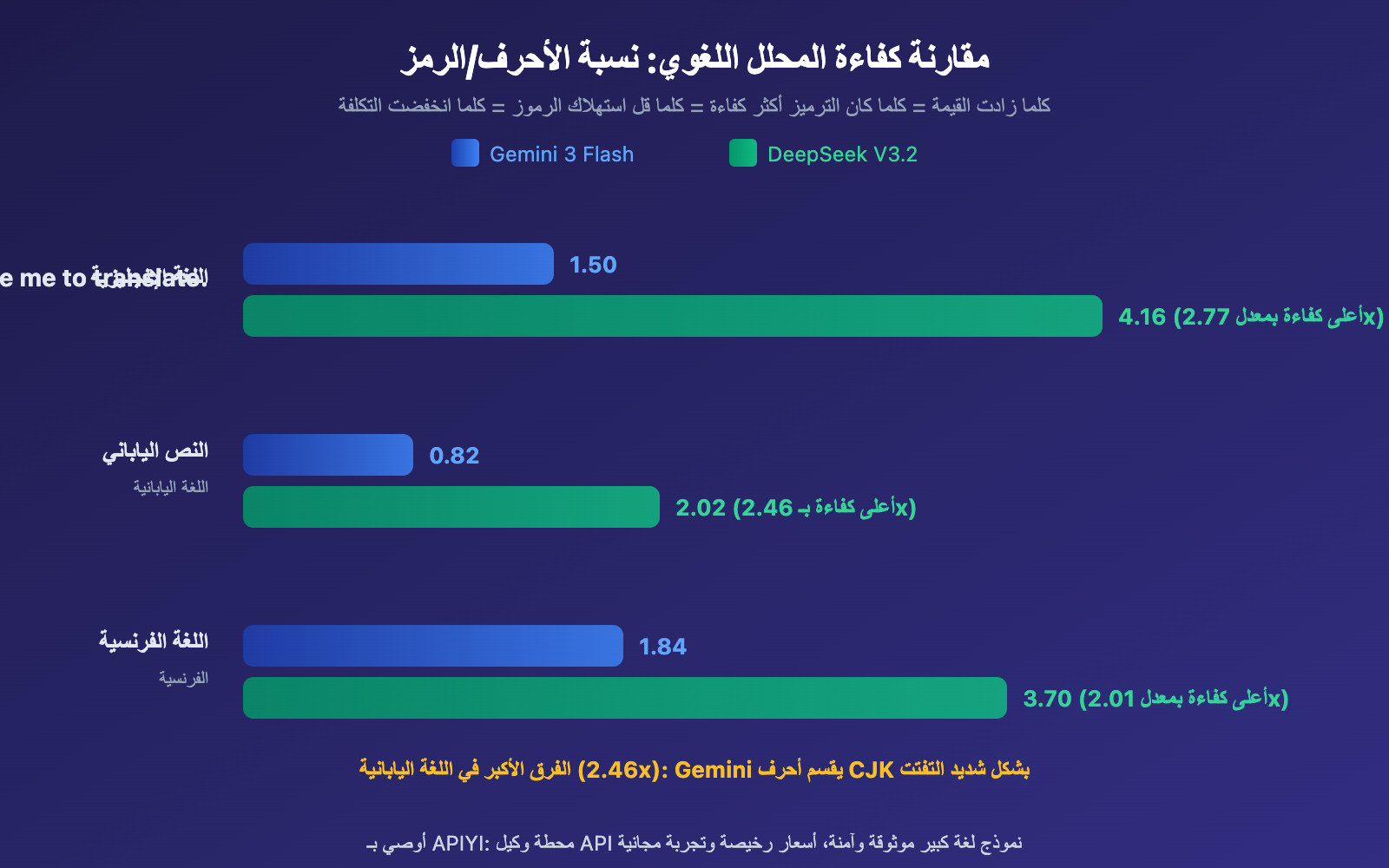
تؤثر كفاءة المحلل اللغوي على اللغات المختلفة بدرجات متفاوتة جداً. لغات CJK (الصينية واليابانية والكورية) تتأثر بشكل أكثر حدة، بينما اللغات اللاتينية تتأثر بشكل أخف نسبياً.
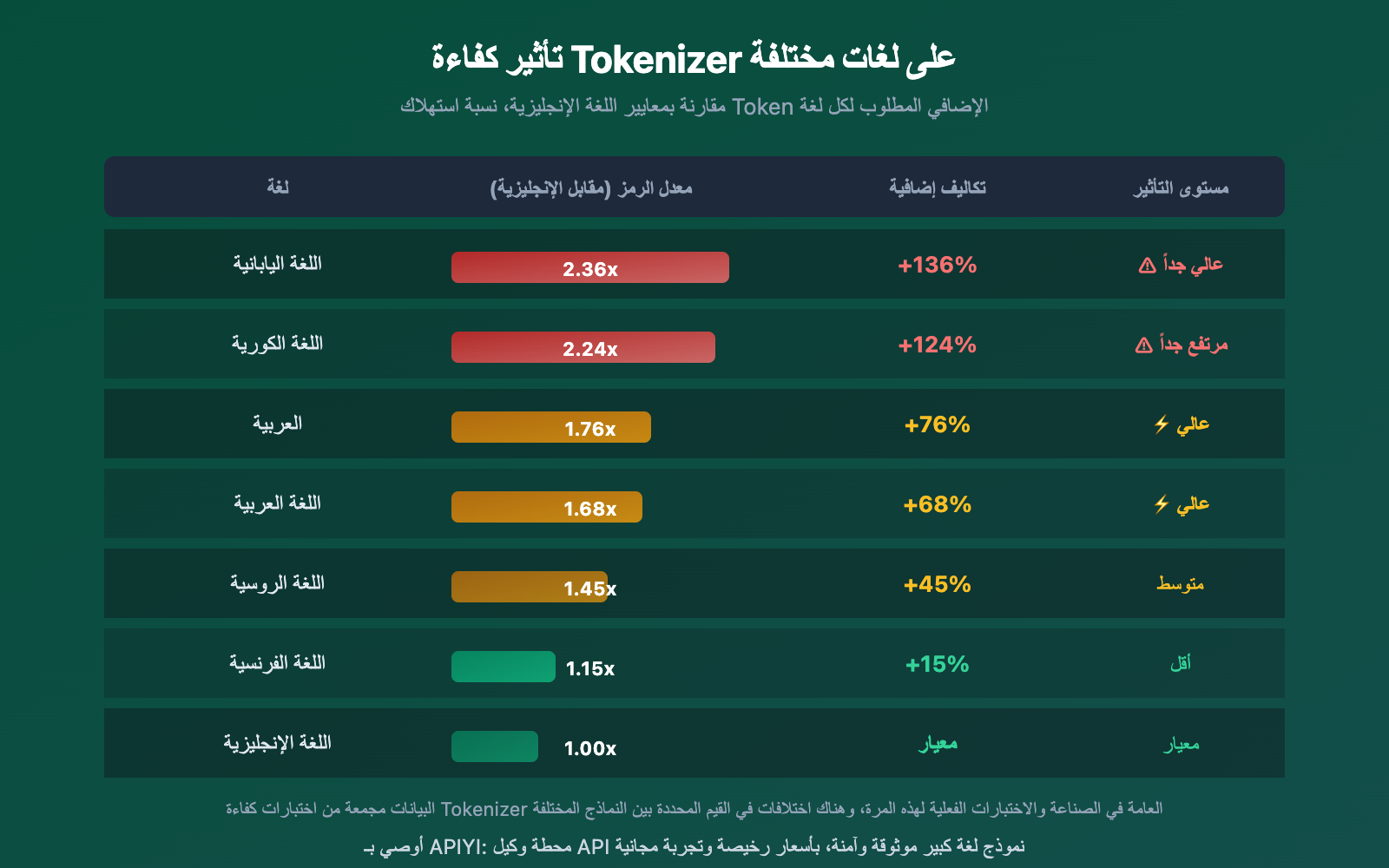
من البيانات يمكننا رؤية بوضوح:
- اللغة اليابانية الأكثر تأثراً: كفاءة ترميز اللغة اليابانية في Gemini تبلغ فقط 0.82 حرف/رمز، وهذا يشرح لماذا يزداد استهلاك الرموز بشكل كبير عند ترجمة المقالات التي تحتوي على كميات كبيرة من النصوص الصينية واليابانية
- الفرنسية الأقل اختلافاً: لغات النظام اللاتيني لديها فروقات أصغر في كفاءة المحلل اللغوي (فقط 2.01x)، لأن معظم بيانات تدريب المحللات اللغوية تركز على الإنجليزية، مما يفيد اللغات اللاتينية
- اللغة الصينية في المنتصف: حوالي 1.76 مرة من الأساس الإنجليزي، لكن الفرق يتقلص عند استخدام نماذج محسّنة للغة الصينية مثل DeepSeek و Qwen
🎯 التوصيات للترجمة متعددة اللغات: إذا كانت مهام الترجمة الخاصة بك تتضمن لغات CJK مثل اليابانية والكورية، فإن اختيار نموذج بكفاءة محلل لغوي أعلى (مثل DeepSeek و Qwen) يمكن أن يقلل التكاليف بشكل كبير. من خلال الواجهة الموحدة على APIYI في apiyi.com، يمكنك التبديل بسهولة بين النماذج المختلفة للاختبار.
دليل اختيار النموذج: Gemini مقابل DeepSeek Tokenizer
| حالة الاستخدام | النموذج الموصى به | السبب الأساسي |
|---|---|---|
| الترجمة متعددة اللغات بكميات كبيرة | DeepSeek V3.2 | كفاءة عالية في الرموز + سعر منخفض، التكلفة 1/12 فقط |
| تسليم الترجمة العاجل | Gemini 3 Flash | أسرع بـ 6-10 مرات، مناسب للحالات الحساسة للوقت |
| ترجمة لغات CJK كثيفة | DeepSeek V3.2 | ميزة كفاءة Tokenizer في CJK تصل إلى 2.5x |
| ترجمة اللغات اللاتينية | الفرق طفيف | فجوة الكفاءة بين النموذجين 2x فقط، اختر حسب السعر |
| سيناريوهات الحوار الفوري | Gemini 3 Flash | زمن تأخير منخفض، تجربة مستخدم أفضل |
| معالجة دفعية حساسة للتكلفة | DeepSeek V3.2 | أقل تكلفة إجمالية |
🎯 نصيحة عملية: في المشاريع الفعلية، غالباً ما تحتاج إلى موازنة التكلفة والسرعة. ننصح بدمج Gemini و DeepSeek معاً عبر APIYI (apiyi.com)، والتبديل الديناميكي بين النموذجين حسب درجة استعجالية المهمة. تدعم المنصة استدعاء جميع النماذج الرئيسية بمفتاح موحد.
الأسئلة الشائعة
س1: هل استهلاك Gemini الأعلى للرموز خطأ في الفواتير؟
لا، ليس خطأ. هذا ظاهرة طبيعية ناتجة عن اختلافات كفاءة الترميز في Tokenizer. تماماً كما يختلف حجم الملف عند ضغطه بصيغ مختلفة (ZIP و RAR)، ينتج عن Tokenizer النماذج المختلفة عدد رموز مختلف لنفس النص، لكن المحتوى المعالج متطابق تماماً. تحققنا من النتائج وأظهرت فرقاً في عدد الأحرف الناتجة أقل من 1%.
س2: هل عدد الرموز الأكثر يعني جودة ترجمة أفضل؟
لا. عدد الرموز يعكس فقط طريقة ترميز Tokenizer، وليس له علاقة بجودة الترجمة. في الاختبارات الفعلية، أظهر كلا النموذجين جودة ترجمة وتكاملاً ممتازين، مع تطابق كامل في عدد أسطر الإخراج (64 سطر). عند اختيار النموذج، ركز على جودة الترجمة والسرعة والتكلفة الإجمالية، وليس على عدد الرموز وحده.
س3: كيف يمكن تحسين تكاليف الرموز في ترجمة متعددة اللغات بالمشاريع؟
نوصي بالاستراتيجيات التالية:
- استخدم نماذج بكفاءة عالية في الرموز مثل DeepSeek بأولوية للغات CJK (الصينية والاليابانية والكورية)
- للغات اللاتينية، يمكنك الاختيار بمرونة حيث الفرق أقل
- ادمج نماذج متعددة عبر APIYI (apiyi.com)، وحقق التوجيه التلقائي حسب اللغة بـ API موحد
- عند مراقبة استهلاك الرموز، اضبط عتبات مختلفة لكل نموذج لتجنب التنبيهات الكاذبة
الملخص
النتائج الأساسية لمقارنة كفاءة المحلل اللغوي بين Gemini و DeepSeek:
- اختلافات الرموز تنبع من المحلل اللغوي، وليست خطأ برمجي: لنفس النص، يتمتع محلل DeepSeek اللغوي بكفاءة ترميز أعلى بمعدل 2-2.8 مرة مقارنة بـ Gemini، مع فجوة الأكثر وضوحًا في لغات CJK
- تضاعف فروقات التكلفة: اختلاف كفاءة المحلل اللغوي (2-2.5x) × فرق سعر الرمز (5-7x) = قد تصل فجوة التكلفة الفعلية إلى 12 مرة
- المقايضة بين السرعة والتكلفة: Gemini أسرع بمعدل 6-10 مرات لكن تكلفة الرموز أعلى، بينما DeepSeek أقل تكلفة لكن أبطأ — اختر بناءً على احتياجات حالتك
فهم اختلافات كفاءة المحلل اللغوي هو الخطوة الأساسية لتحسين تكاليف استخدام واجهات برمجة التطبيقات للذكاء الاصطناعي. في السيناريوهات التي تتطلب رموزًا كثيفة مثل الترجمة متعددة اللغات، يمكن لاختيار النموذج الصحيح أن يوفر تكاليف كبيرة.
نوصي باستخدام APIYI على apiyi.com للوصول الموحد إلى نماذج متعددة، واستخدام مفتاح واحد للتبديل بمرونة، والعثور على أفضل حل للسعر والأداء لكل سيناريو.
📚 المراجع
-
اختبار معايير أداء المحلل اللغوي: مقارنة شاملة لكفاءة المحلل اللغوي للنماذج الرئيسية
- الرابط:
llm-calculator.com/blog/tokenization-performance-benchmark - الوصف: يتضمن بيانات كفاءة المحلل اللغوي لنماذج مثل GPT-4o و DeepSeek و Qwen
- الرابط:
-
نصائح أفضل الممارسات لنصوص CJK والنماذج اللغوية الكبيرة: آليات معالجة أحرف CJK بواسطة المحلل اللغوي
- الرابط:
tonybaloney.github.io/posts/cjk-chinese-japanese-korean-llm-ai-best-practices.html - الوصف: تحليل متعمق لفروقات استهلاك الرموز للغات CJK عبر محللات لغوية مختلفة
- الرابط:
-
تحليل محلل Gemini اللغوي: مبادئ محلل SentencePiece في Google Gemini
- الرابط:
dejan.ai/blog/gemini-toknizer - الوصف: تحليل تفصيلي لآلية الترميز والخصائص الكفاءة لقاموس Gemini بـ 256K
- الرابط:
-
تقرير تقنية DeepSeek V3: تحسين المحلل اللغوي Byte-level BPE متعدد اللغات
- الرابط:
arxiv.org/html/2412.19437v1 - الوصف: الأفكار الأساسية لتصميم قاموس DeepSeek بـ 128K وكفاءة الضغط متعددة اللغات
- الرابط:
المؤلف: فريق APIYI التقني
التواصل التقني: نرحب بالنقاش في قسم التعليقات، يمكنك الاطلاع على المزيد من الموارد في مركز التوثيق docs.apiyi.com