ملاحظة المؤلف: تحليل متعمق للأسباب الخمسة الرئيسية لارتفاع استهلاك الـ Token في OpenClaw (Open WebUI)، بما في ذلك استدعاءات API الخلفية المخفية، وتراكم سجل المحادثات، وغيرها، مع تقديم حلول تكوين قابلة للتطبيق فوراً.
"لقد سألت فقط 'ما هو نموذجك؟'، فلماذا تجاوز عدد الـ Tokens في الموجه (Prompt Token) أكثر من 10,000؟" هذا تساؤل حقيقي يراود الكثير من مستخدمي OpenClaw. في هذا المقال، سنقوم بتحليل الأسباب الجذرية لارتفاع استهلاك الـ Token في OpenClaw من منظور تقني، وسنقدم 5 حلول للتحسين يمكن تطبيقها فوراً.
القيمة الجوهرية: بعد قراءة هذا المقال، ستفهم لماذا يستهلك OpenClaw الـ Tokens بشكل يتجاوز التوقعات، وستتقن طرق التكوين المحددة لخفض تكاليف الـ Token بنسبة 60-80%.
النقاط المحورية لاستهلاك الـ Token في OpenClaw
| النقطة الأساسية | التوضيح | درجة التأثير |
|---|---|---|
| استدعاءات خلفية مخفية | كل رسالة تطلق 4-5 استدعاءات API مستقلة | ⭐⭐⭐⭐⭐ الأعلى |
| تراكم سجل المحادثة | إعادة إرسال سجل المحادثة بالكامل في كل جولة | ⭐⭐⭐⭐ مرتفع |
| عدم فصل نماذج المهام | مهام الخلفية تستخدم النموذج الرئيسي افتراضياً | ⭐⭐⭐⭐ مرتفع |
| حقن موجه النظام | حقن تلقائي لوصف الأدوات وسياق الـ RAG | ⭐⭐⭐ متوسط |
| خطأ تكرار موجه النظام | تراكب موجه النظام عند استدعاء أدوات الـ Agentic | ⭐⭐⭐ متوسط |
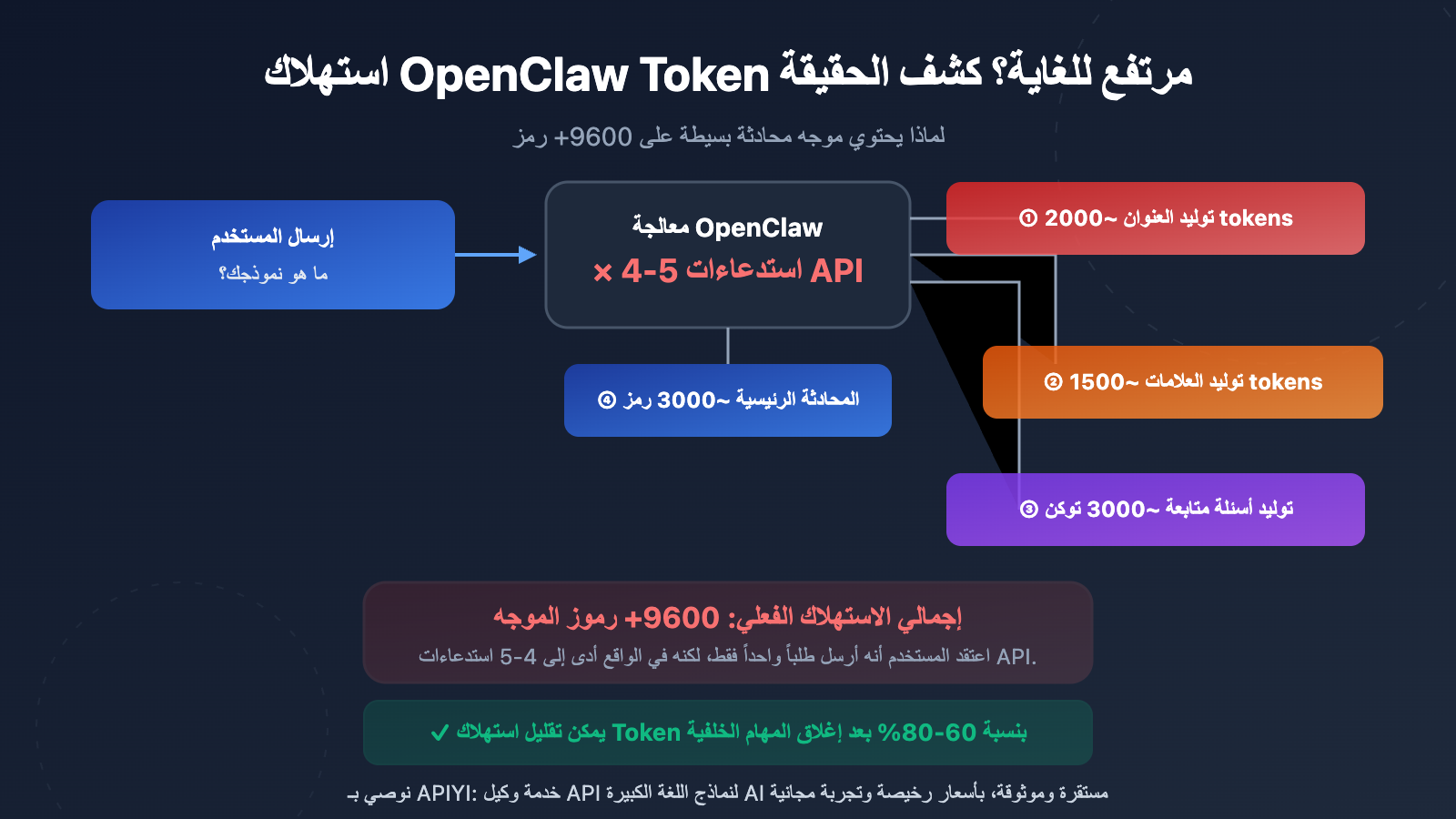
السبب الجذري لارتفاع استهلاك الـ Token في OpenClaw
يُصدم العديد من المستخدمين عند رؤية إحصائيات استخدام الـ API؛ فرغم طرح سؤال بسيط مثل "ما هو نموذجك؟"، قد يصل عدد الـ Tokens في الموجه إلى 9600-10000+. هذه ليست مشكلة في نظام الفوترة لدى مزود الـ API، بل هي ناتجة عن التصميم الهيكلي لـ OpenClaw (Open WebUI).
السبب الرئيسي هو: يقوم OpenClaw تلقائياً بإطلاق عدة استدعاءات API مستقلة في الخلفية في كل مرة يرسل فيها المستخدم رسالة. هذه الاستدعاءات غير مرئية تماماً للمستخدم، ولكن كل واحدة منها تستهلك Tokens حقيقية.
المصادر الخمسة الكبرى لاستهلاك الـ Token في OpenClaw بالتفصيل
المصدر 1: توليد العنوان تلقائياً (Title Generation)
بعد إرسال المستخدم للرسالة الأولى، يقوم OpenClaw تلقائياً باستدعاء الـ API لتوليد عنوان للمحادثة يتكون من 3-5 كلمات. يرسل هذا الاستدعاء محتوى رسالة المستخدم، مما يستهلك حوالي 1500-2000 Token من الموجه.
المصدر 2: توليد الوسوم تلقائياً (Tag Generation)
في الوقت نفسه، يقوم OpenClaw باستدعاء الـ API لتوليد 1-3 وسوم تصنيف للمحادثة. هذا استدعاء API مستقل آخر، يستهلك حوالي 1000-1500 Token من الموجه.
المصدر 3: اقتراح أسئلة متابعة (Follow-up Generation)
يقوم OpenClaw افتراضياً بتوليد 3-5 اقتراحات لأسئلة المتابعة. يستخدم هذا الاستدعاء قالب {{MESSAGES:END:6}} الذي يسحب آخر 6 رسائل من المحادثة كـ سياق، مما يستهلك حوالي 2000-3000 Token من الموجه.
المصدر 4: الإكمال التلقائي (Autocomplete Generation)
في بعض إصدارات OpenClaw، يتم تفعيل ميزة الإكمال التلقائي للمدخلات، والتي تتوقع ما قد يدخله المستخدم في الخطوة التالية.
المصدر 5: طلب المحادثة الرئيسي نفسه
أخيراً يأتي طلب المحادثة الرئيسي الذي يراه المستخدم فعلياً، والذي يتضمن موجه النظام، وسجل المحادثة، ومدخلات المستخدم.
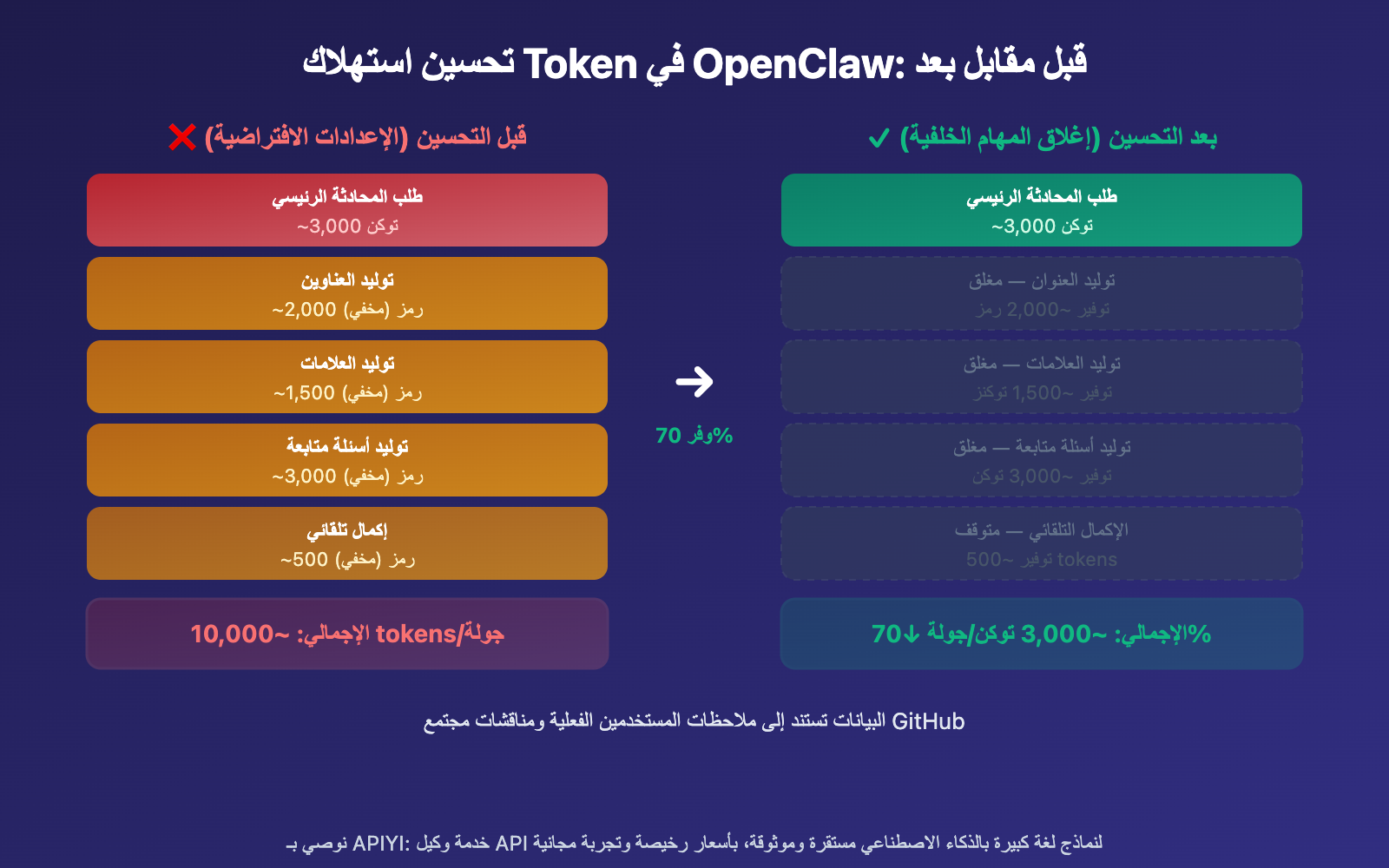
دليل سريع لتحسين استهلاك الـ Token في OpenClaw
الإعداد المبسط: إيقاف المهام الخلفية
فيما يلي أسرع طريقة للتحسين — من خلال إيقاف استدعاءات API الخلفية غير الضرورية عبر متغيرات البيئة:
# أضف متغيرات البيئة التالية في ملف docker-compose.yml
environment:
- ENABLE_TITLE_GENERATION=false
- ENABLE_TAGS_GENERATION=false
- ENABLE_FOLLOW_UP_GENERATION=false
- ENABLE_AUTOCOMPLETE_GENERATION=false
عرض الخطوات الكاملة للتكوين عبر لوحة الإدارة
إذا لم يكن من السهل عليك تعديل متغيرات البيئة، يمكنك أيضًا التكوين عبر لوحة إدارة OpenClaw:
- تسجيل الدخول إلى لوحة إدارة OpenClaw
- انتقل إلى Settings ← Tasks
- قم بإيقاف الخيارات التالية واحدًا تلو الآخر:
- Title Generation ← إيقاف
- Tags Generation ← إيقاف
- Follow-up Generation ← إيقاف
- Autocomplete Generation ← إيقاف
- إذا كنت لا ترغب في إيقافها تمامًا، يمكنك ضبط Task Model على نموذج رخيص (مثل
gpt-4o-mini) - احفظ الإعدادات وقم بتحديث الصفحة
# الخيار الثاني: عدم إيقاف الميزات، ولكن استخدام نموذج رخيص لمعالجة المهام الخلفية
environment:
- TASK_MODEL_EXTERNAL=gpt-4o-mini
بهذه الطريقة، ستستمر المهام الخلفية في العمل بشكل طبيعي (سيتم إنشاء العناوين والوسوم والأسئلة المتابعة تلقائيًا)، ولكن باستخدام نموذج أقل تكلفة بدلاً من نموذج الدردشة الرئيسي الذي اخترته.
🎯 نصيحة للتحسين: يعد إيقاف المهام الخلفية الطريقة الأكثر مباشرة لتقليل استهلاك الـ Token في OpenClaw. إذا كنت تستخدم API عبر APIYI (apiyi.com)، فإن هذه التحسينات يمكن أن تقلل بشكل كبير من تكاليف الاستخدام. توفر APIYI واجهة موحدة لعدة نماذج، مما يسهل عليك تعيين نماذج مهام (Task Model) مختلفة.
تحليل البيانات الفعلية لاستهلاك الـ Token في OpenClaw
فيما يلي بيانات استهلاك الـ Token الحقيقية بناءً على تعليقات المستخدمين، حيث يمكن رؤية مدى جدية المشكلة بوضوح:
| سيناريو الاستخدام | استهلاك الـ Token المتوقع | استهلاك الـ Token الفعلي | المضاعف |
|---|---|---|---|
| سؤال وجواب بسيط "ما هو نموذجك؟" | ~200 | 9,600-10,269 | 50x |
| 5 جولات من الحوار اليومي | ~3,000 | ~45,000 | 15x |
| 30 جولة من حوار البرمجة | ~12,000 | 1,860,000 | 155x |
| حوار بعد رفع المستندات | ~5,000 | 600,000+ | 120x |
البيانات في الجدول أعلاه مستمدة من تعليقات المستخدمين الحقيقية في مجتمع Open WebUI على GitHub. في حالة وصول 30 جولة من حوار البرمجة إلى 155 ضعفًا، يرجع ذلك أساسًا إلى أن قالب توليد الأسئلة المتابعة {{MESSAGES:END:6}} يسحب آخر 6 رسائل، وغالبًا ما تحتوي الرسالة الواحدة في حوارات البرمجة على كمية كبيرة من الأكواد.
التأثير التراكمي لجولات الحوار على استهلاك الـ Token في OpenClaw
| جولة الحوار | الاستهلاك بالإعدادات الافتراضية | الاستهلاك بعد التحسين | نسبة التوفير |
|---|---|---|---|
| الجولة 1 | ~10,000 | ~3,000 | 70% |
| الجولة 5 | ~50,000 | ~15,000 | 70% |
| الجولة 10 | ~150,000 | ~45,000 | 70% |
| الجولة 20 | ~500,000 | ~150,000 | 70% |
| الجولة 30 | ~1,200,000 | ~360,000 | 70% |
مع زيادة عدد جولات الحوار، ينمو استهلاك الـ Token بشكل أسي. وذلك لأن كل جولة حوار تعيد إرسال سجل الحوار الكامل. في الإعدادات الافتراضية، لا يتم إرسال هذا السجل مرة واحدة فقط في الحوار الرئيسي، بل يتم إرساله أيضًا في توليد العنوان، وتوليد الوسوم، وتوليد الأسئلة المتابعة.
🎯 نصيحة للتحكم في التكاليف: في سيناريوهات الحوارات الطويلة، يزداد استهلاك الـ Token بشكل مذهل. نوصي بإجراء استدعاءات API عبر APIYI (apiyi.com)، حيث توفر المنصة لوحة إحصائيات مفصلة للاستخدام، مما يسهل عليك مراقبة وتحسين استهلاك الـ Token.
مقارنة حلول تحسين استهلاك التوكن في OpenClaw

| حل التحسين | صعوبة التنفيذ | توفير التوكن | التأثير على الوظائف | درجة التوصية |
|---|---|---|---|---|
| إيقاف توليد الأسئلة المتابعة | بسيط | ~30% | لن تظهر الأسئلة المقترحة | ⭐⭐⭐⭐⭐ |
| إعداد نموذج مهام منخفض التكلفة | بسيط | انخفاض تكلفة المهام بنسبة 90% | الاحتفاظ بكافة الوظائف | ⭐⭐⭐⭐⭐ |
| إيقاف توليد العناوين/الوسوم | بسيط | ~25% | يتطلب تسمية المحادثة يدويًا | ⭐⭐⭐⭐ |
| نقل RAG إلى موجه النظام | متوسط | تفعيل التخزين المؤقت | لا توجد آثار سلبية | ⭐⭐⭐⭐ |
| فلتر طول سياق المحادثة | متوسط | التحكم في تكلفة المحادثات الطويلة | قد يتم فقدان السياق المبكر | ⭐⭐⭐ |
🎯 أفضل الممارسات: إذا كنت لا ترغب في فقدان أي وظيفة، فإن الخيار الثاني (إعداد نموذج مهام منخفض التكلفة) هو الخيار الأمثل؛ حيث تستمر المهام الخلفية في العمل ولكن باستخدام نموذج منخفض التكلفة مثل
gpt-4o-mini. عبر منصة APIYI (apiyi.com)، يمكنك إدارة مفاتيح API لنماذج متعددة بسهولة، حيث يتيح لك مفتاح واحد استدعاء جميع النماذج الرائدة.
الأسئلة الشائعة
س1: لماذا يختلف استهلاك التوكن في OpenClaw بشكل كبير عن ChatGPT الرسمي؟
نسخة ChatGPT الرسمية تعتمد على نظام الاشتراك، ولا يتم المحاسبة فيها بناءً على التوكن، لذا لا تشعر بالاستهلاك. أما OpenClaw فيعمل عبر استدعاء النموذج من خلال API، حيث يتم احتساب تكلفة كل توكن. بالإضافة إلى ذلك، فإن المهام الخلفية في OpenClaw مفعلة افتراضيًا، مما يجعل الاستهلاك الفعلي يتراوح بين 3 إلى 5 أضعاف الطلبات التي يراها المستخدم.
س2: هل سيعود استهلاك التوكن في OpenClaw إلى طبيعته بعد إيقاف المهام الخلفية؟
نعم. عند إيقاف توليد العناوين، والوسوم، والأسئلة المتابعة، والإكمال التلقائي، سيؤدي كل طلب إلى استدعاء واحد فقط للـ API (المحادثة الرئيسية)، مما يقلل استهلاك التوكن بنسبة 60-80%. إذا كنت ترغب في الاحتفاظ بهذه الميزات، يمكنك عبر منصة APIYI (apiyi.com) إعداد نموذج منخفض التكلفة (مثل gpt-4o-mini) لمعالجة هذه المهام الخلفية بشكل خاص.
س3: كيف يمكنني مراقبة الاستهلاك الفعلي للتوكن في OpenClaw؟
نوصي بالطرق التالية لمراقبة استهلاك التوكن:
- عبر لوحة إحصائيات الاستخدام في APIYI (apiyi.com) لعرض بيانات التوكن التفصيلية لكل استدعاء API.
- مراجعة صفحة الإحصائيات (Usage) في لوحة تحكم OpenClaw.
- مراقبة النسبة بين توكن الموجه (Prompt Token) وتوكن الإكمال (Completion Token)؛ فإذا كان توكن الموجه أكبر بكثير، فهذا يعني أن المهام الخلفية تستهلك الكثير.
ملخص
النقاط الجوهرية لارتفاع استهلاك التوكنات (Tokens) في OpenClaw:
- الاستدعاءات الخلفية المخفية هي السبب الرئيسي: كل رسالة تطلق من 4 إلى 5 استدعاءات API مستقلة، بينما لا يرى المستخدم سوى استدعاء واحد فقط.
- تعيين نموذج مهام رخيص هو الحل الأمثل: استخدام
TASK_MODEL_EXTERNAL=gpt-4o-miniيمكن أن يقلل تكاليف المهام الخلفية بنسبة 90% مع الحفاظ على كامل الوظائف. - انتبه جيدًا للمحادثات الطويلة: يتم إعادة إرسال سجل المحادثة بالكامل في كل استدعاء؛ لذا فإن محادثة مكونة من 30 جولة قد تستهلك أكثر من مليون توكن.
بعد إتقان تقنيات التحسين هذه، يمكنك خفض تكاليف التوكنات في OpenClaw بنسبة تتراوح بين 60-80%، مما يجعل استخدام الـ API أكثر اقتصادية وكفاءة.
نوصي بإدارة استدعاءات الـ API الخاصة بك عبر APIYI (apiyi.com)، حيث توفر المنصة واجهة موحدة وإحصائيات استخدام مفصلة لمساعدتك في التحكم بدقة في استهلاك التوكنات والتكاليف.
📚 المراجع
-
مناقشة استهلاك التوكنات في Open WebUI: نقاشات مجتمع GitHub حول الاستهلاك العالي للتوكنات.
- الرابط:
github.com/open-webui/open-webui/discussions/7281 - الوصف: شارك العديد من المستخدمين بيانات استهلاك التوكنات الفعلية وخبرات التحسين.
- الرابط:
-
وثائق تكوين متغيرات البيئة لـ Open WebUI: المرجع الرسمي لتكوين متغيرات البيئة.
- الرابط:
docs.openwebui.com/reference/env-configuration - الوصف: يحتوي على جميع متغيرات البيئة القابلة للتكوين وقيمها الافتراضية.
- الرابط:
-
مشكلة استهلاك التوكنات في توليد الأسئلة المتابعة (Follow-up): توليد الأسئلة اللاحقة يستهلك السياق كاملاً.
- الرابط:
github.com/open-webui/open-webui/issues/15081 - الوصف: تحليل مفصل لكيفية استهلاك قوالب توليد الأسئلة المتابعة لكميات كبيرة من التوكنات.
- الرابط:
-
خطأ (Bug) تكرار موجه النظام: استدعاء أدوات الـ Agentic يؤدي إلى تراكم موجهات النظام.
- الرابط:
github.com/open-webui/open-webui/issues/19169 - الوصف: مشكلة معروفة يجب الانتباه إليها عند استخدام ميزات استدعاء الأدوات.
- الرابط:
المؤلف: فريق APIYI التقني
التبادل التقني: نرحب بالنقاش في قسم التعليقات، ولمزيد من المعلومات يمكنك زيارة مركز وثائق APIYI عبر docs.apiyi.com.