ملاحظة المؤلف: مقارنة بين Gemini 3.1 Pro وClaude Sonnet 4.6 من 5 أبعاد رئيسية: البرمجة، الاستدلال، الوسائط المتعددة، العمل المعرفي، والتسعير، لمساعدتك في اختيار النموذج الرائد الأكثر فعالية من حيث التكلفة.
في فبراير 2026، شهد مشهد نماذج الذكاء الاصطناعي وضعاً مثيراً للاهتمام: المنافسة الحقيقية لم تعد حول "من هو الأقوى"، بل حول "من هو ملك القيمة مقابل السعر". أطلقت جوجل نموذج Gemini 3.1 Pro (في 19 فبراير) وأطلقت Anthropic نموذج Claude Sonnet 4.6 (في 17 فبراير)، حيث تم إصدارهما في وقت متقارب جداً وبأسعار متقاربة، وكلاهما يدعي تقديم أداء يقترب من النماذج الرائدة – لم يكن خيار المطورين محيراً بهذا القدر من قبل.
القيمة الجوهرية: بعد قراءة هذا المقال، ستعرف الفجوة الحقيقية بين النموذجين في البرمجة، الاستدلال، الوسائط المتعددة، والعمل المعرفي، وأيهما تختار بناءً على احتياجاتك المحددة.

مقارنة المعلمات الأساسية بين Gemini 3.1 Pro و Claude Sonnet 4.6
يتمتع كلا النموذجين بمكانة متشابهة جدًا – كلاهما "أداء يقترب من الرائد بسعر أقل بكثير من الرائد"، لكن بمسارات تقنية مختلفة تمامًا.
| بُعد المعلمة | Gemini 3.1 Pro | Claude Sonnet 4.6 | توضيح المقارنة |
|---|---|---|---|
| تاريخ الإصدار | 19-02-2026 | 17-02-2026 | الفارق يومان فقط |
| نافذة السياق | مليون (قياسي) | 200 ألف قياسي / مليون تجريبي (Beta) | Gemini يدعم مليون سياق بشكل أصلي |
| الحد الأقصى للمخرجات | 64 ألف توكن | 64 ألف توكن | متطابق تمامًا |
| سعر الإدخال | 2 دولار / مليون توكن | 3 دولار / مليون توكن | ✅ Gemini أرخص بنسبة 33% |
| سعر المخرجات | 12 دولار / مليون توكن | 15 دولار / مليون توكن | ✅ Gemini أرخص بنسبة 20% |
| سعر الإدخال للسياق الطويل | 4 دولار (>200 ألف) | 3 دولار (ثابت) | ⚠️ Sonnet أرخص في السياق الطويل |
| سعر المخرجات للسياق الطويل | 18 دولار (>200 ألف) | 15 دولار (ثابت) | ⚠️ Sonnet أرخص في السياق الطويل |
| وسائط الإدخال | نص، صور، صوت، فيديو، PDF | نص، صور، PDF | ✅ Gemini أكثر شمولاً في تعدد الوسائط |
| وضع الاستدلال | تفكير ثلاثي المستويات (منخفض/متوسط/عالي) | تفكير تكيفي (تعديل ديناميكي) | فلسفة تصميم مختلفة |
| تخزين الموجهات مؤقتًا (Prompt Caching) | مدعوم | القراءة من التخزين المؤقت بـ 0.30 دولار فقط / مليون (توفير 90%) | ✅ تخزين Sonnet المؤقت يوفر أكثر |
🎯 تفاصيل تسعير هامة: في السيناريوهات العادية التي تقل عن 200 ألف توكن، يكون Gemini 3.1 Pro أرخص (2$/12$ مقابل 3$/15$). ولكن بمجرد أن يتجاوز السياق 200 ألف توكن، يرتفع سعر Gemini إلى 4$/18$، ليصبح أغلى من Sonnet 4.6 الذي يحافظ على 3$/15$. متوسط طول السياق لديك هو ما يحدد أيهما أكثر توفيرًا لك.
مقارنة شاملة لاختبارات الأداء (Benchmarks) بين Gemini 3.1 Pro و Sonnet 4.6
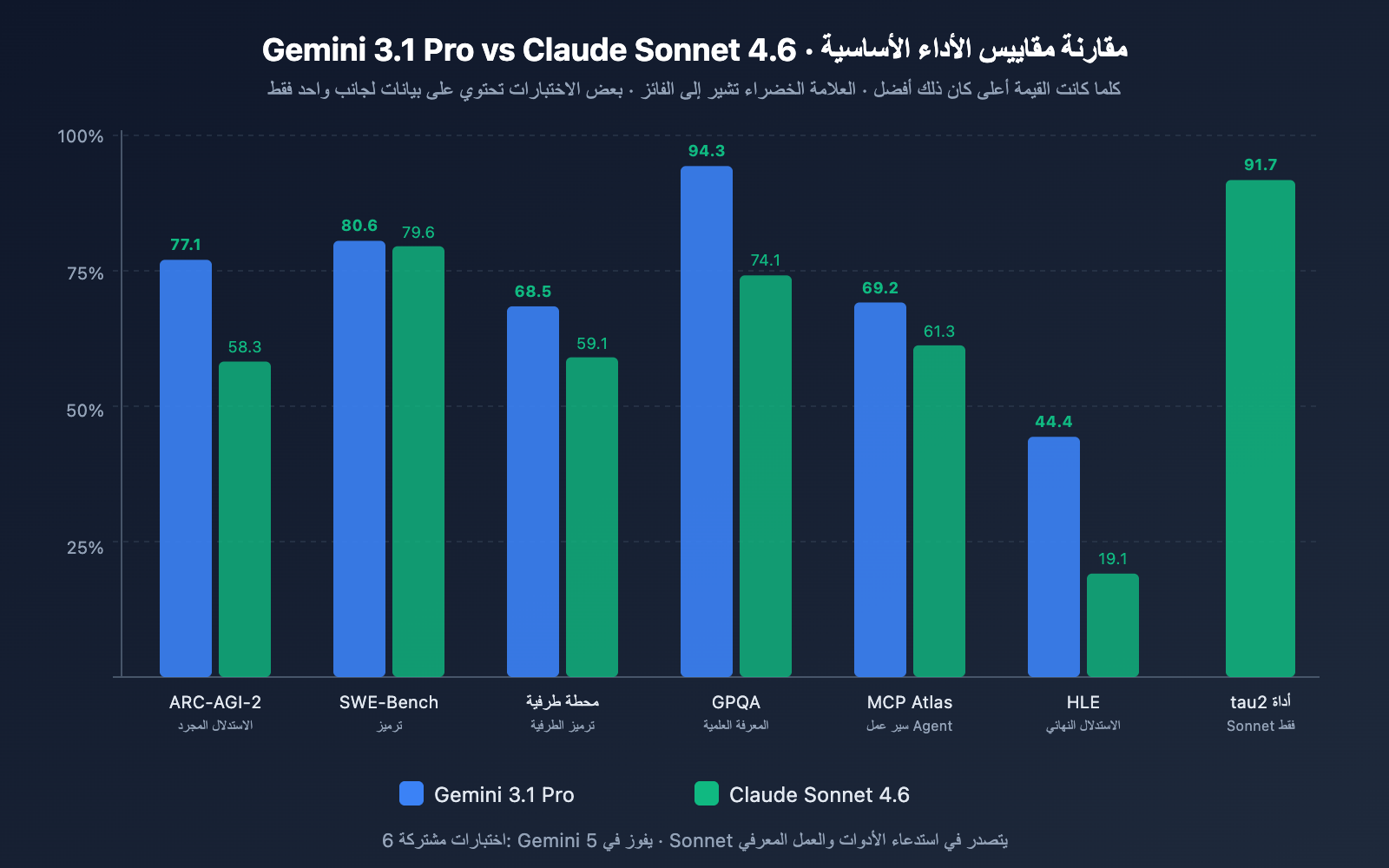
مقارنة القدرات البرمجية
| اختبار البرمجة | Gemini 3.1 Pro | Claude Sonnet 4.6 | الفائز |
|---|---|---|---|
| SWE-Bench Verified | 80.6% | 79.6% | ✅ Gemini متفوق بـ 1.0 نقطة |
| SWE-Bench Pro | 54.2% | 42.7% | ✅ Gemini متفوق بـ 11.5 نقطة |
| Terminal-Bench 2.0 | 68.5% | 59.1% | ✅ Gemini متفوق بـ 9.4 نقطة |
التحليل: يتصدر Gemini 3.1 Pro بشكل كامل في اختبارات البرمجة الثلاثة. خاصة في SWE-Bench Pro (مهام برمجية حقيقية أكثر تعقيدًا) حيث وصل الفارق إلى 11.5 نقطة، وفي Terminal-Bench (البرمجة في بيئة الواجهة النصية) وصل الفارق إلى 9.4 نقطة. ومع ذلك، تجدر الإشارة إلى أن Sonnet 4.6 حقق نسبة خطأ 0% في الاختبارات الداخلية لتحرير الأكواد البرمجية في Replit، وتم اختياره كنموذج أساسي لوكيل البرمجة في GitHub Copilot – مما يعني أن تجربة البرمجة في بيئات الإنتاج الفعلية قد تكون أقرب مما تظهره اختبارات الأداء.
مقارنة قدرات الاستدلال
| اختبار الاستدلال | Gemini 3.1 Pro | Claude Sonnet 4.6 | الفائز |
|---|---|---|---|
| ARC-AGI-2 (الاستدلال التجريدي) | 77.1% | 58.3% | ✅ Gemini متفوق بـ 18.8 نقطة |
| GPQA Diamond (العلوم) | 94.3% | 74.1% | ✅ Gemini متفوق بـ 20.2 نقطة |
| HLE (الاستدلال النهائي) | 44.4% | 19.1% | ✅ Gemini متفوق بـ 25.3 نقطة |
| MATH-500 | – | 97.8% | Sonnet متميز في الرياضيات |
التحليل: قدرة الاستدلال هي البعد الذي يظهر فيه أكبر فارق بين الاثنين. يتفوق Gemini 3.1 Pro بفارق كبير في اختبارات ARC-AGI-2 و GPQA Diamond و HLE، حيث تتراوح الفجوة من 18 إلى 25 نقطة. من المهم توضيح أن نتائج استدلال Gemini 3.1 Pro تم تحقيقها في وضع "High" لنظام التفكير ثلاثي المستويات الخاص به، بينما التفكير التكيفي في Sonnet 4.6 ليس بعمق الاستدلال الموجود في Opus 4.6. إذا كان الاستدلال البحت هو مطلبك الأساسي، فإن Gemini 3.1 Pro يتفوق بوضوح.
مقارنة العمل المعرفي وقدرات الوكلاء (Agents)
| الاختبار | Gemini 3.1 Pro | Claude Sonnet 4.6 | الفائز |
|---|---|---|---|
| GDPval-AA Elo (العمل المعرفي) | 1,317 | 1,633 | ✅ Sonnet أعلى بـ 316 نقطة |
| Finance Agent (التحليل المالي) | – | 63.3% | بيانات Sonnet بارزة |
| OSWorld (التحكم في نظام التشغيل) | – | 72.5% | بيانات Sonnet بارزة |
| MCP Atlas (سير عمل متعدد الخطوات) | 69.2% | 61.3% | ✅ Gemini متفوق بـ 7.9 نقطة |
| tau2-bench Retail (استدعاء الأدوات) | – | 91.7% | بيانات Sonnet بارزة |
التحليل: هنا يظهر أكبر تحول مفاجئ. في اختبار GDPval-AA (الذي يحاكي العمل المعرفي الحقيقي على مستوى الخبراء)، لم يتفوق Sonnet 4.6 بـ 1,633 Elo على Gemini 3.1 Pro (1,317) فحسب، بل تجاوز حتى النموذج الرائد الخاص بشركته Opus 4.6 (1,559). هذا يعني أنه في سيناريوهات العمل المعرفي عالي القيمة مثل البحث والتحليل، وكتابة التقارير، واستراتيجيات الأعمال، يعد Sonnet 4.6 الأفضل أداءً بين جميع النماذج حاليًا – بما في ذلك Opus 4.6 الذي يكلف 5 أضعاف سعره.
مقترحات اختيار السيناريو لنموذجي Gemini 3.1 Pro وSonnet 4.6
نقاط القوة والضعف في النموذجين متكاملة للغاية، لذا فإن اختيار السيناريو المناسب أهم من مجرد التساؤل عن "أيهما أفضل".
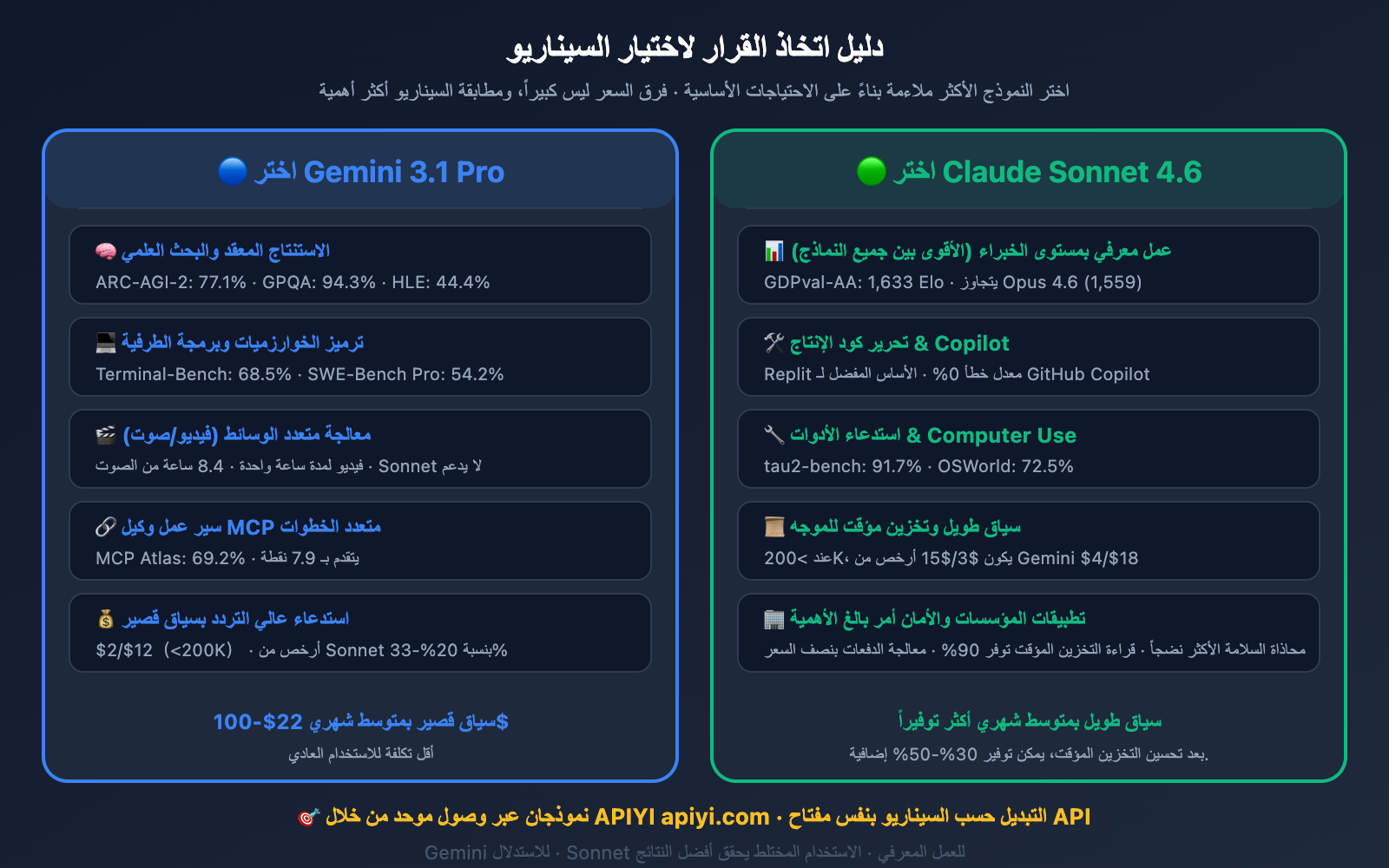
حالات اختيار Gemini 3.1 Pro
- الخوارزميات والبرمجة التنافسية: حقق 2,887 نقطة في LiveCodeBench Elo، مما يمنحه تفوقاً ساحقاً في البرمجة الخوارزمية.
- الاستدلال المعقد والبحث العلمي: بنسبة 77.1% في ARC-AGI-2 و94.3% في GPQA Diamond، تعد قدرة الاستدلال المحض لديه في مستوى مختلف تماماً عن Sonnet 4.6.
- معالجة الوسائط المتعددة: يدعم بشكل أصلي الفيديو (حتى ساعة واحدة) والصوت (حتى 8.4 ساعة)، وهو ما لا يدعمه Sonnet 4.6.
- سير عمل وكيل MCP: حقق 69.2% في MCP Atlas (بفارق 7.9 نقطة)، مما يجعله أكثر موثوقية عند بناء أنظمة وكلاء متعددة الخطوات.
- الاستدعاءات عالية التردد بسياق قصير: بتسعير 2$/12$ للنصوص التي تقل عن 200 ألف توكن، يعتبر الخيار الأرخص بين الاثنين.
حالات اختيار Claude Sonnet 4.6
- العمل المعرفي بمستوى الخبراء: سجل 1,633 نقطة Elo في GDPval-AA، وهي أعلى درجة بين جميع النماذج الحالية، مما يجعله الخيار الأمثل لتقارير الأبحاث، التحليل المالي، والاستراتيجيات التجارية.
- تحرير الأكواد البرمجية لمستوى الإنتاج: سجل معدل خطأ 0% في اختبارات بيئة إنتاج Replit، وتم اختياره كأساس لوكيل البرمجة في GitHub Copilot.
- استدعاء الأدوات واستخدام الكمبيوتر (Computer Use): بنسبة 91.7% في tau2-bench و72.5% في OSWorld، يتميز بدقة عالية جداً في العمليات المؤتمتة واستدعاء الدوال.
- سيناريوهات نافذة السياق الطويلة: عندما يتجاوز السياق 200 ألف توكن، يكون تسعير Sonnet 4.6 البالغ 3$/15$ أرخص من تسعير Gemini البالغ 4$/18$.
- تطبيقات المؤسسات: يتميز بمحاذاة أمان أكثر نضجاً، وميزة تخزين الموجهات (Prompt Caching) بتكلفة قراءة تبلغ 0.30$ فقط لكل مليون توكن (توفير 90%)، ومعالجة الدفعات بنصف السعر.
وصول سريع إلى Gemini 3.1 Pro و Claude Sonnet 4.6 عبر API
مثال مبسط
عبر منصة APIYI، يستخدم كلا النموذجين واجهة موحدة:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Gemini 3.1 Pro - أقوى في الاستدلال والوسائط المتعددة
response = client.chat.completions.create(
model="gemini-3.1-pro",
messages=[{"role": "user", "content": "حلل التعقيد الزمني لهذا الكود وقم بتحسينه"}]
)
print(response.choices[0].message.content)
عرض مثال استدعاء Sonnet 4.6 والتبديل التلقائي حسب السيناريو
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Claude Sonnet 4.6 - أقوى في الأعمال المعرفية واستدعاء الأدوات
response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[{"role": "user", "content": "اكتب تقرير تحليل السوق للربع الأول، متضمناً مقارنة مع المنافسين واقتراحات للنمو"}]
)
print(response.choices[0].message.content)
# توجيه تلقائي حسب السيناريو
def route_model(prompt, task_type="general"):
model_map = {
"reasoning": "gemini-3.1-pro",
"multimodal": "gemini-3.1-pro",
"algorithm": "gemini-3.1-pro",
"knowledge": "claude-sonnet-4-6",
"production_code": "claude-sonnet-4-6",
"tool_call": "claude-sonnet-4-6",
"general": "gemini-3.1-pro",
}
return client.chat.completions.create(
model=model_map.get(task_type, "gemini-3.1-pro"),
messages=[{"role": "user", "content": prompt}]
)
نصيحة: يمكنك الوصول إلى كلا النموذجين في وقت واحد عبر منصة APIYI (apiyi.com) والتبديل بينهما باستخدام نفس مفتاح API. توفر المنصة رصيداً مجانياً للاختبار، لذا ننصحك بمقارنة النتائج في سيناريوهاتك الفعلية.
مقارنة عميقة للتكاليف بين Gemini 3.1 Pro و Sonnet 4.6
تقدير التكاليف الشهرية بناءً على ثلاثة سيناريوهات استخدام نموذجية:
| سيناريو الاستخدام | متوسط استهلاك التوكن شهرياً | Gemini 3.1 Pro | Claude Sonnet 4.6 | الطرف الأرخص |
|---|---|---|---|---|
| استخدام خفيف (5 مليون إدخال + 1 مليون إخراج) | 6 مليون | $22 | $30 | Gemini يوفر 27% |
| استخدام متوسط (20 مليون إدخال + 5 مليون إخراج) | 25 مليون | $100 | $135 | Gemini يوفر 26% |
| استخدام مكثف لسياق طويل (50 مليون إدخال >200K + 10 مليون إخراج) | 60 مليون | $380 | $300 | ⚠️ Sonnet يوفر 21% |
🎯 خلاصة التكاليف: في الاستخدام العادي، يعد Gemini 3.1 Pro أرخص بنسبة 26%-27% تقريباً. ولكن إذا كنت تستخدم سياقاً طويلاً يتجاوز 200 ألف توكن بشكل متكرر (مثل تحليل كامل لقاعدة الكود أو معالجة المستندات الطويلة)، فإن Sonnet 4.6 يصبح هو الأرخص — لأن سعر السياق الطويل في Gemini يرتفع إلى 4 دولار/18 دولار، بينما يظل Sonnet ثابتاً عند 3 دولار/15 دولار. بالإضافة إلى ذلك، مع ميزة تخزين الموجهات (Prompt Caching) في Sonnet (تكلفة القراءة 0.30 دولار فقط لكل مليون توكن)، قد تكون التكلفة الفعلية أقل بنسبة 30%-50%.
من خلال الوصول عبر منصة APIYI (apiyi.com)، يمكنك الاستمتاع بأسعار مخفضة إضافية، مما يقلل من تكلفة استخدام كلا النموذجين بشكل أكبر.
الأسئلة الشائعة
س1: هل من الطبيعي أن يكون مؤشر GDPval-AA لنموذج Sonnet 4.6 أعلى من Opus 4.6 الخاص بنفس الشركة؟
بالفعل، هذا صحيح. حقق Sonnet 4.6 في مؤشر GDPval-AA نتيجة 1,633 Elo، متجاوزاً Opus 4.6 الذي حقق 1,559. وقد أكدت شركة Anthropic رسمياً هذه البيانات. السبب المحتمل هو أن Sonnet 4.6 قد خضع لتحسينات مخصصة لسيناريوهات العمل المعرفي في الشركات، بينما يركز Opus 4.6 بشكل أكبر على الاستدلال العام ومعالجة السياقات الطويلة. كما وصلت نسبة تفضيل المطورين لـ Sonnet 4.6 إلى 70% (مقارنة بـ Sonnet 4.5) و59% (مقارنة بـ Opus 4.5).
س2: أي نموذج هو الأنسب لبناء وكيل ذكاء اصطناعي (AI Agent)؟
يعتمد ذلك على نوع الوكيل (Agent). إذا كان وكيلاً لسير عمل متعدد الخطوات يعتمد على MCP، فإن Gemini 3.1 Pro يتصدر بمعدل 69.2% في MCP Atlas بفارق 7.9 نقطة. أما إذا كان الوكيل يعتمد بكثافة على استدعاء الأدوات (مثل OpenClaw)، فإن Sonnet 4.6 أكثر موثوقية بنسبة 91.7% في tau2-bench. وفي حال كان الوكيل من فئة "استخدام الكمبيوتر" (التحكم في المتصفح وسطح المكتب)، فإن Sonnet 4.6 حقق 72.5% في OSWorld، وهي واحدة من أفضل النتائج حالياً. كلا النموذجين متاحان للتجربة مباشرة عبر منصة APIYI apiyi.com.
س3: أستخدم حالياً Sonnet 4.5، هل يجب أن أحدث إلى Sonnet 4.6 أم أنتقل إلى Gemini 3.1 Pro؟
إذا كنت راضياً عن تجربة العمل المعرفي والبرمجة في Sonnet 4.5، فإن الترقية إلى Sonnet 4.6 هي الخيار الأكثر أماناً؛ حيث يتوافق مع نفس الـ API، وبنفس السعر، مع تحسن شامل في الأداء (ارتفع SWE-Bench من 77.2% إلى 79.6%، وARC-AGI-2 من 13.6% إلى 58.3%، أي بزيادة 4.3 مرة). أما إذا كانت احتياجاتك الأساسية تميل نحو الاستدلال، الوسائط المتعددة، أو برمجة الخوارزميات، فإن Gemini 3.1 Pro يتمتع بمزايا ملحوظة في هذه الجوانب. ننصحك بتجربة كلا النموذجين عبر منصة APIYI apiyi.com.
الخلاصة
الاستنتاجات الأساسية للمقارنة بين Gemini 3.1 Pro و Claude Sonnet 4.6:
- للاستدلال والوسائط المتعددة، اختر Gemini 3.1 Pro: يتفوق بفارق 18.8 نقطة في ARC-AGI-2، و20.2 نقطة في GPQA Diamond، مع دعم أصلي للفيديو والصوت، وتكلفة أقل في السياقات القصيرة.
- للعمل المعرفي والبرمجة الإنتاجية، اختر Claude Sonnet 4.6: حقق 1,633 Elo في GDPval-AA وهي أعلى درجة بين جميع النماذج (بما في ذلك Opus 4.6)، مع معدل خطأ 0% في Replit، وهو الخيار المفضل لـ GitHub Copilot.
- في سيناريوهات السياق الطويل، Sonnet أكثر توفيراً: عندما يتجاوز السياق 200 ألف رمز (200K)، تكون تكلفة Sonnet هي 3 دولار/15 دولار مقابل 4 دولار/18 دولار لـ Gemini، ومع خاصية تخزين الموجهات مؤقتاً (Prompt caching) يمكن توفير 30%-50% إضافية.
هذان النموذجان هما الأفضل من حيث القيمة مقابل الأداء بين النماذج الرائدة في فبراير 2026. الاستراتيجية الأمثل هي استخدامهما بشكل مختلط حسب السيناريو. نوصي بالوصول إليهما معاً عبر APIYI apiyi.com، حيث يمكنك التبديل بينهما حسب الحاجة باستخدام نفس مفتاح API.
📚 المراجع
-
إعلان إطلاق Claude Sonnet 4.6: مدونة Anthropic الرسمية
- الرابط:
anthropic.com/news/claude-sonnet-4-6 - الوصف: عرض كامل لميزات Sonnet 4.6، وبيانات الاختبارات المعيارية (Benchmark)، وميزة التفكير التكيفي.
- الرابط:
-
مدونة Gemini 3.1 Pro الرسمية: إعلان إطلاق Google DeepMind
- الرابط:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - الوصف: نظام التفكير ثلاثي المستويات في Gemini 3.1 Pro وبيانات الأداء الكاملة.
- الرابط:
-
مقارنة عملية من Tom's Guide: اختبار Gemini 3.1 Pro مقابل Sonnet 4.6 في 7 تحديات صعبة
- الرابط:
tomsguide.com/ai/i-tested-gemini-3-1-pro-vs-claude-sonnet-4-6-in-7-tough-challenges-and-there-was-one-clear-winner - الوصف: مقارنة الأداء الفعلي في سيناريوهات المهام الحقيقية.
- الرابط:
-
قائمة تصنيف Artificial Analysis: منصة مستقلة لتقييم نماذج الذكاء الاصطناعي
- الرابط:
artificialanalysis.ai/leaderboards/models - الوصف: بيانات مقارنة أفقية موضوعية للأداء والسرعة والسعر.
- الرابط:
الكاتب: الفريق التقني
التواصل التقني: نرحب بمشاركة تجربة استخدامك في قسم التعليقات، لمزيد من المعلومات حول نماذج الذكاء الاصطناعي، يمكنك زيارة APIYI apiyi.com