سألني مؤخراً أحد الأصدقاء المطورين في المجموعة: "هل يمكن لـ gpt-image-2 توليد صور بناءً على ملفات CSV أو Excel؟ لقد رأيت أشخاصاً على تيك توك يستخدمون نماذج الصور لإنشاء عروض تقديمية (PPT)، وأريد تجربة ما إذا كان بإمكاني قراءة معلومات الملفات بهذه الطريقة". الإجابة المباشرة هي: لا يمكن. فنموذج gpt-image-2 الذي أطلقته OpenAI في أبريل 2026 يقبل فقط الموجهات النصية والصور كمدخلات، ولا يقرأ ملفات CSV/Excel ولا يخرج ملفات PPTX أو PDF.
لكن هذا لا يعني أن الطريق مسدود. إن استخراج محتوى الملفات وتحويله إلى نصوص، أو التقاط صور لصفحات الملفات، ثم تسليمها إلى gpt-image-2 لتوليد الصور، هو بالضبط سير العمل السائد حالياً. في هذا المقال، سنوضح حدود قدرات gpt-image-2 المتعلقة برفع الملفات مع استعراض 5 حلول بديلة، لمساعدتك في تنفيذ متطلبات عملائك التي كانوا يظنون أنها مستحيلة.

gpt-image-2 文件上传支持现状:输入只接受文本与图片
首先明确官方边界,后续所有方案都是建立在这条边界之上的。根据 OpenAI 开发者文档,gpt-image-2(快照 gpt-image-2-2026-04-21)是一个原生多模态图像生成模型,模态支持表明确列出了输入输出范围。
| 模态类型 | 是否支持输入 | 是否支持输出 | 说明 |
|---|---|---|---|
| 文本 (text) | ✅ 支持 | ❌ 不支持 | 用作提示词,可包含中文、日文等多语言 |
| 图片 (image) | ✅ 支持 | ✅ 支持 | 输入用于编辑/参考,输出 PNG/JPEG/WebP |
| 音频 (audio) | ❌ 不支持 | ❌ 不支持 | 与图像生成不相关 |
| 视频 (video) | ❌ 不支持 | ❌ 不支持 | 与图像生成不相关 |
| 文档 (CSV/Excel/PDF/Word/PPT) | ❌ 不支持 | ❌ 不支持 | 不能直接上传,也不能输出为文件 |
简单说,gpt-image-2 不是 GPT-4 那种“通用大脑”,它专精于图像生成与编辑,因此 OpenAI 没有给它做 CSV/Excel/PDF 的解析通道。如果你把 Excel 二进制文件传过去,API 会直接返回 400 错误。如果你的项目需要稳定且高 RPM 的 gpt-image-2 调用通道,我们建议通过 APIYI (apiyi.com) 这类聚合服务平台进行接入,该平台已经把模型的输入校验和参数限制做了文档化,新手不容易踩坑。
🎯 核心认知:gpt-image-2 的能力边界是「文本 + 图片 → 图片」,不要把它当成全能 Agent。文件相关的需求要在外层用别的工具补齐,服务层(如 APIYI apiyi.com)负责保证调用稳定,业务层负责数据预处理。
为什么客户问的“PPT 生成”和“文件生图”是两回事
很多客户把“AI 一键生成 PPT”和“模型读文件生图”混在一起,其实是两个完全不同的工作流。从抖音、小红书上看到的 PPT 自动化案例,几乎都是多步流水线:先用大语言模型把数据提炼成文案,再用图像模型生成每一页插图,最后用程序拼装成 PPTX。
中间负责生图的那一环,通常就是 gpt-image-2 这种模型。它只看自己接到的那条文字 prompt 和参考图,根本不知道源头是 Excel 还是 Notion。这一点理解清楚之后,后面 5 个方案就顺理成章。
与上一代 gpt-image-1 相比有哪些升级
很多老用户会问:既然都不能传文件,gpt-image-2 比 gpt-image-1 强在哪?差别其实非常关键,直接决定了“截图作图输入”这条路能不能跑通。新版本在文字渲染、参考图数量、推理能力上都有量级提升。
| 能力维度 | gpt-image-1 | gpt-image-2 |
|---|---|---|
| 最多参考图数量 | 4 张 | 16 张(实测建议 ≤4 张效果最佳) |
| 文字渲染 | 英文较好,中日韩易出错 | 中、日、韩、印地、孟加拉多语言准确度大幅提升 |
| 推理能力 | 无 | 内置 thinking 模式,可处理复杂版面 |
| 知识截止 | 2024 年早期 | 2025 年 12 月 |
| 输出分辨率 | 最大 1024×1024 | 最大 3840×2160(4K) |
也就是说,如果你之前用 gpt-image-1 处理“截图改风格”效果不理想,现在用 gpt-image-2 重新跑一遍是值得的,尤其在中文海报、PPT 内页这类需要精确文字渲染的场景。
5 个工作流方案让 gpt-image-2 文件内容也能生图
下面这 5 个方案对应不同的数据源和落地场景,选择哪一个取决于文件类型、输出形态和自动化深度。我们按从轻量到重型的顺序排列。
方案一:文件转文本提示词,直接喂给 gpt-image-2
适用于 CSV、Excel、JSON、纯文本等结构化数据。流程是先用脚本(pandas、openpyxl)读取文件,把表头、关键行、统计指标拼成一段自然语言描述,再作为 prompt 调用 /v1/images/generations。比如把销售数据表汇总为“2026 年 Q1 三大区域销售额柱状图,华东 1200 万、华北 980 万、华南 760 万,深色商务风格”。
这种方法的好处是简单直接,不需要图片输入。缺点是 prompt 里能塞的信息有限,gpt-image-2 在数字精确还原方面做得好但不完美,需要在提示词中明确写出每一根柱子的数值,否则模型会按视觉合理性重新分配高度。
方案二:文件页面截图,作为参考图输入
适用于 PDF、PPT 既有版面、网页报表等“已经长成图的内容”。把目标页转换成 PNG(可用 macOS 预览、pdftoppm、Puppeteer 等工具),然后通过 /v1/images/edits 端点上传作为 image 参数,搭配 prompt 描述要做的修改,例如“保留布局,把英文标题改成中文,把柱状图改成苹果风格”。
gpt-image-2 在 2026 年的版本里最多接受 16 张参考图,但官方和社区实测都建议主参考图 1 张 + 风格参考图 1–2 张,加多了模型注意力会被稀释。每张图建议控制在 1.5MB 以内,否则 input token 消耗会显著上涨。
方案三:数据先做可视化,再交给 gpt-image-2 美化
适用于追求“既准确又好看”的数据可视化场景。先用 matplotlib、ECharts、Excel 自带图表把数据画出基础版,导出 PNG;然后把这张基础图作为 gpt-image-2 的输入图,prompt 写成“保持数据点位置和数值不变,把图表风格改成深色、霓虹高亮、信息图风格”。
这是目前数据图表 + AI 美化最稳的做法。原始数值由确定性的画图库保证,视觉风格由 gpt-image-2 重塑,两边各做自己擅长的事。如果你要批量跑这个流程,推荐通过 APIYI (apiyi.com) 调用 gpt-image-2,它对 5000 RPM 的高并发场景做了上游账号池调度,适合每天几千上万张图的任务。
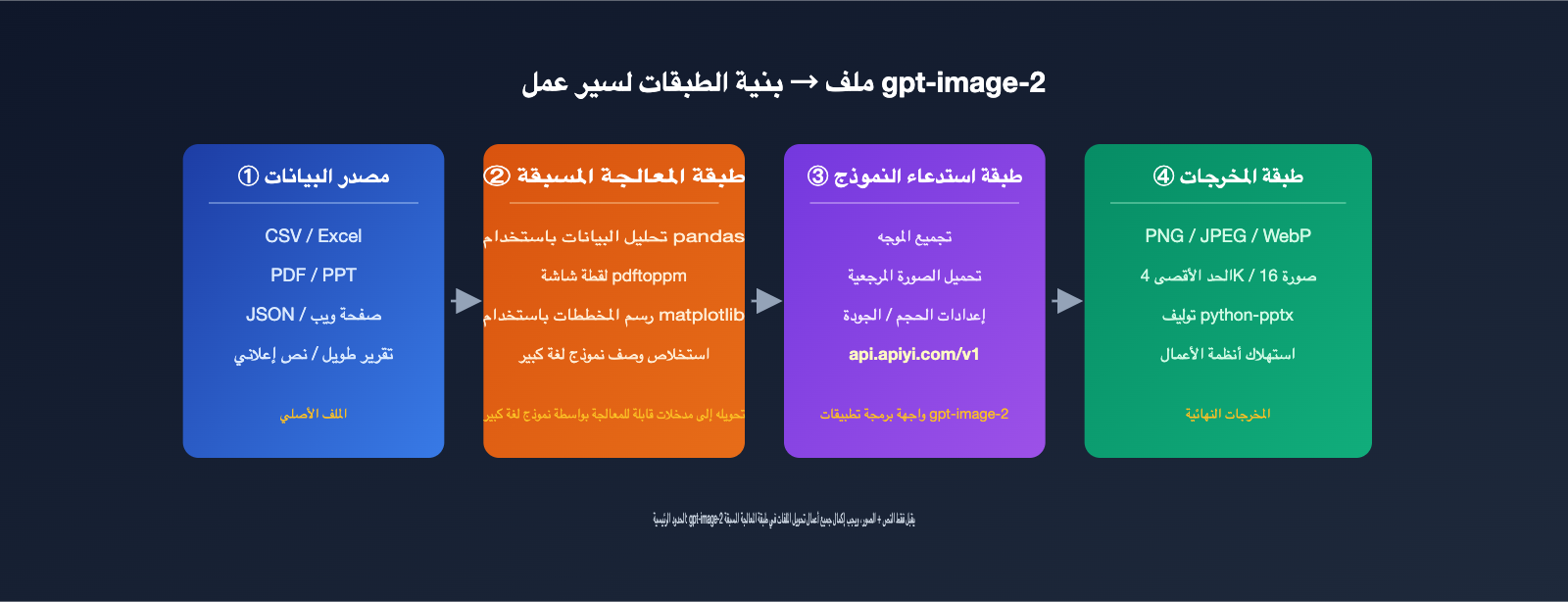
方案四:LLM + gpt-image-2 双模型流水线
适用于内容复杂、需要语义理解的文件,比如长报告、合同摘要、产品文案。先用 GPT-4 系列或 Claude 4 把文件读懂、提炼出 4-8 段画面描述,再循环调用 gpt-image-2 生成对应张数的图。
这一步的关键是把“语义理解”和“图像生成”解耦。LLM 负责说“这一页应该画什么”,gpt-image-2 负责“按这条 prompt 把图画出来”。整个流水线在 APIYI (apiyi.com) 上可以用同一个 API key 串通,省去了切换 SDK 和密钥管理的麻烦。
方案五:批量生图后程序化合成 PPT/海报
这就是抖音上那些“一键 PPT”案例的真相。模型本身不会输出 PPTX 文件,但可以生成每一页的图,再用 Python 的 python-pptx 或前端的 PptxGenJS 把图片塞到 PPT 模板的对应位置。
简单一句话:PPT 本质是多张图组成的演示文档,gpt-image-2 解决“图”的问题,python-pptx 解决“文档容器”的问题。一个常见的拆解是:封面用 4K 高质量图、内页用 1536×1024 中等质量图、目录页和过渡页用低质量草图,通过 quality 参数差异化控制成本。一份 20 页的 PPT 大约需要 20-30 次模型调用,在 5000 RPM 的中转通道上,几分钟就能跑完。
| 方案 | 适用文件类型 | 工程量 | 输出质量 | 推荐场景 |
|---|---|---|---|---|
| 方案一 文件转文本 | CSV/Excel/JSON | 低 | 中 | 简单图表、风格化插图 |
| 方案二 页面截图作图输入 | PDF/PPT/网页 | 低 | 中高 | 版面改写、风格迁移 |
| 方案三 可视化预渲染 | CSV/Excel | 中 | 高 | 数据图表美化 |
| 方案四 LLM+gpt-image-2 | 长报告/文案 | 中高 | 高 | 内容卡片、教程图 |
| 方案五 批量合成 PPT | 任意 | 高 | 高 | 演示文档自动化 |
مثال برمجي لاستدعاء API: كيف تحول محتوى الملف إلى مدخلات لـ gpt-image-2
تصبح المفاهيم أكثر وضوحاً عند تطبيقها برمجياً. إليك مثال بسيط وقابل للتنفيذ بلغة Python، حيث نقوم بتحويل جدول Excel إلى "موجه" (prompt) نصي، ثم نستدعي gpt-image-2 لتوليد الرسم البياني المقابل. نستخدم هنا خدمة APIYI (apiyi.com) كبوابة موحدة لخدمة وكيل API، حيث تحتاج فقط إلى استبدال base_url، بينما تظل بقية صيغ كتابة الـ SDK مطابقة تماماً للنسخة الرسمية.
from openai import OpenAI
import pandas as pd
import base64
# إعداد العميل باستخدام مفتاح APIYI
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
# قراءة ملف Excel وتجهيز البيانات
df = pd.read_excel("sales_q1.xlsx")
summary = df.groupby("region")["sales"].sum().to_dict()
prompt_text = (
f"ارسم مخططاً عمودياً لمبيعات الربع الأول من عام 2026،"
f"البيانات هي: {summary}، "
f"بنمط عمل احترافي داكن، مع عنوان باللون الأبيض الصافي، وتسميات بيانات واضحة."
)
# استدعاء النموذج لتوليد الصورة
resp = client.images.generate(
model="gpt-image-2",
prompt=prompt_text,
size="1536x1024",
quality="high"
)
img_b64 = resp.data[0].b64_json
# حفظ الصورة الناتجة
with open("sales_chart.png", "wb") as f:
f.write(base64.b64decode(img_b64))
فكرة الكود واضحة جداً: طبقة الأعمال تقوم بتحليل ملف Excel إلى وصف نصي، بينما لا تستقبل طبقة النموذج سوى النصوص. إذا كنت تستخدم تقنية "تحويل صورة إلى صورة" (الخيار الثاني)، فما عليك سوى استبدال client.images.generate بـ client.images.edit وتمرير الصورة عبر image=open("page.png", "rb").
| المعامل | نطاق القيم | الشرح |
|---|---|---|
model |
gpt-image-2 / gpt-image-2-mini |
نسخة mini أسرع وأقل تكلفة |
size |
1024×1024 / 1536×1024 / 1024×1536 / مخصص | أطول ضلع ≤ 3840px، يجب أن يقبل الضلع القسمة على 16 |
quality |
low / medium / high / auto | الجودة العالية تستغرق وقتاً أطول وتستهلك tokens أكثر |
n |
1–4 | عدد الصور في الاستدعاء الواحد، للكميات الكبيرة يُنصح باستخدام حلقة تكرار خارجية |
response_format |
png(افتراضي) / jpeg / webp | gpt-image-2 لا يدعم مخرجات PDF/PPTX |
🎯 نصيحة برمجية: لتشغيل هذه العملية بسرعة، نوصي بإنشاء حساب على APIYI (apiyi.com)، وتغيير
base_urlإلىhttps://api.apiyi.com/v1. بهذه الطريقة يمكنك استخدام واجهة موحدة لاستدعاءgpt-image-2وGPT-5وClaude 4في آن واحد، مما يوفر عليك عناء الربط مع كل مزود على حدة.

4 أخطاء شائعة يقع فيها العملاء وطرق تجنبها
بعد فهم الخطط الخمس، قد تواجه بعض التفاصيل الدقيقة عند التنفيذ الفعلي. لقد قمنا بتلخيص أكثر 4 فئات من الأسئلة شيوعاً التي تردنا في مجموعات خدمة العملاء.
الخطأ الأول: إدراج ملف CSV مشفر بـ base64 داخل الموجه (Prompt)
يفكر بعض الزملاء في "حل ذكي": قراءة ملف CSV وتحويله إلى سلسلة نصية بصيغة base64 وإدراجها في الموجه، معتقدين أن النموذج سيقوم بفك تشفيرها بنفسه. هذا المسار غير مجدٍ تماماً؛ فنموذج gpt-image-2 لا ينفذ الأكواد البرمجية، ولن يتعامل مع السلسلة النصية كبيانات، بل سيعتبرها مجرد رموز غير مفهومة، مما يؤدي إلى عرض مجموعة من النصوص المشوهة. الطريقة الصحيحة هي تحليل ملف CSV في طبقة الأعمال (Business Layer) وتحويله إلى وصف نصي، راجع الخطة الأولى.
الخطأ الثاني: توقع أن يقوم gpt-image-2 "برسم جدول مطابق تماماً لبرنامج Excel"
يتميز النموذج بالاتساق البصري والأسلوب الفني، لكن الاستعادة على مستوى البكسل أمر مختلف تماماً. إذا كنت بحاجة إلى جدول دقيق، نوصي باستراتيجية الدمج: استخدم ECharts أو matplotlib لرسم نسخة دقيقة (الخطة الثالثة)، ثم اطلب من gpt-image-2 تحسين المظهر. إن الاعتماد على موجه واحد لجعل النموذج يرسم 100 صف من البيانات بدقة هو أمر غير ممكن حالياً.
الخطأ الثالث: الرغبة في الحصول على مخرجات بصيغة SVG أو PDF المتجهة
مخرجات gpt-image-2 تقتصر فقط على ثلاث صيغ نقطية (Bitmap) وهي: PNG وJPEG وWebP، ولا يدعم صيغاً متجهة مثل SVG أو PDF أو AI. إذا كنت بحاجة إلى رسومات متجهة، يرجى استخدام Stable Diffusion مع أداة vectorizer.ai، أو اطلب مباشرة من GPT-5 توليد كود SVG. تأكد من صيغة المخرجات قبل اختيار النموذج لتجنب إعادة العمل لاحقاً.
الخطأ الرابع: إرسال نفس الصورة المرجعية بشكل متكرر، مما يؤدي إلى استهلاك هائل للـ token
يعالج gpt-image-2 كل صورة مدخلة بدقة عالية، وحتى لو كان الموجه الخاص بك مجرد تعديل بسيط، فإن كل طلب سيؤدي إلى إعادة حساب الـ input token. ننصحك بعمل تخزين مؤقت (Cache) للصور المرجعية في جانب العميل، أو استخدام previous_response_id مباشرة للتحرير الحواري (Responses API) لإعادة استخدام سياق الصورة السابق.
هناك تفصيل آخر يجب الانتباه إليه: حتى لو كان هدفك هو إخراج صورة مصغرة بحجم 256×256، فإذا كانت الصورة المرجعية بدقة 4K، فسيتم احتساب الـ input token بناءً على دقة 4K. قم بضغط الصورة المرجعية محلياً بحيث يكون طول أطول ضلع فيها 1024 بكسل قبل الرفع، فهذا يمكن أن يوفر أكثر من 60% من الـ input token، وهو أكثر نقطة يتم تجاهلها في التحكم بالتكاليف للمهام ذات الحجم الكبير.
| ظاهرة الخطأ | السبب الجذري | الحل الموصى به |
|---|---|---|
| 400 invalid_request_error | رفع ملفات غير صور (مثل CSV/Excel) | تحويل الملف إلى نص أو لقطة شاشة في الطبقة الخارجية |
| عرض النصوص بشكل مشوه | استخدام سلسلة base64 كموجه | استخدام وصف لغوي طبيعي بعد التحليل |
| بيانات الجدول غير دقيقة | استخدام الموجه لرسم جدول دقيق | استخدام العرض المسبق المرئي (الخطة الثالثة) |
| الرغبة في مخرجات SVG | النموذج لا يدعم الصيغ المتجهة | استخدام GPT-5 لتوليد كود SVG |
| استهلاك token غير متوقع | تكرار رفع صور مرجعية كبيرة الحجم | الضغط إلى أقل من 1.5 ميجابايت وتفعيل التخزين المؤقت |
الأسئلة الشائعة (FAQ)
س1: هل gpt-image-2 لا يستطيع حقاً رفع ملفات PDF؟
لا يمكن رفع ملفات PDF مباشرة. ولكن يمكنك استخدام pdftoppm لتحويل كل صفحة إلى PNG، ثم إدخالها كصور. إذا كنت بحاجة إلى "فهم محتوى PDF وتوليد صورة"، نقترح استخدام GPT-5 لقراءة PDF واستخلاص الوصف، ثم تغذية هذا الوصف إلى gpt-image-2. هذا الدمج يمكن تنفيذه عبر مفتاح API واحد على APIYI (apiyi.com).
س2: هل من الآمن إرسال ملفات تحتوي على بيانات حساسة إلى النموذج؟
تتم عملية تحويل الملف إلى نص على خادمك الخاص، ولا يتم إرسال سوى النص النهائي للموجه إلى النموذج، ويمكنك إجراء عملية إخفاء البيانات (Data Masking) أثناء التحويل. إذا كنت تستخدم خدمة وكيل API، فإن واجهات APIYI (apiyi.com) لا تخزن موجهات المستخدم أو المحتوى المرجع، مما يجعل الامتثال أكثر قابلية للتحكم مقارنة بالوكلاء الخارجيين.
س3: هل أدوات "توليد PPT بضغطة زر" المنتشرة على تيك توك تستخدم gpt-image-2؟
بعضها يستخدمه والبعض الآخر لا. المنطق عادة هو: نموذج لغة كبير (LLM) يكتب المحتوى ← نموذج صور (gpt-image-2 / Nano Banana Pro / Flux) يصمم الرسوم التوضيحية ← الخلفية البرمجية تستخدم python-pptx للتجميع. يتفوق gpt-image-2 في عرض النصوص، وخاصة الصينية، مما يجعله مناسباً جداً للرسوم التوضيحية داخل شرائح PPT.
س4: لماذا يقول البعض إنه يمكن رفع ملفات Excel؟
هؤلاء يقومون بأخذ لقطة شاشة لملف Excel ورفعها كصورة، وفي جوهر الأمر يظل الإدخال صورة، وليس أن النموذج قد فهم هيكل ملف Excel. إذا رأيت أن الأرقام في لقطة الشاشة مشوشة، فلن يتمكن النموذج إلا من إعادة رسمها بناءً على هذا التشوش.
س5: أيهما أختار: gpt-image-2 أم gpt-image-2-mini؟
إصدار mini يتميز بالسرعة والتكلفة المنخفضة، وهو مناسب للمسودات والصور المصغرة ذات الحجم الكبير؛ أما للمواد المنشورة رسمياً فيفضل استخدام الإصدار القياسي. قيود الإدخال لكلا الإصدارين متطابقة تماماً (كلاهما لا يدعم ملفات المستندات)، ما عليك سوى تبديل معرف النموذج في معامل model دون الحاجة لتغيير كود SDK.
الخلاصة
لا يدعم نموذج gpt-image-2 رفع ملفات CSV أو Excel أو PPT مباشرة، كما أنه لا يُخرج ملفات PPTX أو PDF؛ هذه حدود تقنية لقدرات النموذج وليست مشكلة في إعدادات المعاملات (Parameters). بمجرد استيعاب هذه الحدود، يمكنك معالجة محتوى الملفات مسبقاً — عبر تحويلها إلى نصوص، أو لقطات شاشة، أو تصور بيانات (Visualization) ثم تجميلها — مما يتيح لك تلبية معظم الاحتياجات التي تبدو ظاهرياً وكأنها تتطلب مدخلات ملفات. إن أدوات "تحويل PPT بضغطة زر" أو "تحويل Excel إلى ملصق" أو "تغيير نمط PDF" التي نراها على منصات مثل TikTok، تعتمد في جوهرها على سلسلة عمليات (Pipeline) متعددة الخطوات؛ فبمجرد توضيح تقسيم العمل بين استنتاج النموذج ومعالجة البيانات، ستصبح متطلباتك قابلة للتنفيذ.
القاعدة الذهبية للتنفيذ هي: اترك للنموذج ما يجيده، وقم بمعالجة البيانات مسبقاً في الطبقة الخارجية. إذا كنت ترغب في تشغيل سلسلة عمليات متكاملة، نوصي باستخدام منصة APIYI (apiyi.com) للوصول إلى كل من GPT-5 (لفهم النصوص) و gpt-image-2 (لتوليد الصور) عبر مفتاح API واحد يغطي سير العمل بالكامل. كما تتيح لك قدرة المعالجة المتزامنة العالية التي تصل إلى 5000 طلب في الدقيقة (RPM) تشغيل المهام الجماعية بسلاسة، دون الحاجة إلى إدارة مفاتيح متعددة أو حزم SDK مختلفة لكل نموذج.

عن المؤلف: يركز فريق APIYI على تجميع نماذج الذكاء الاصطناعي وتوفير بنية تحتية للاستنتاج عالي التزامن، ونتعامل يومياً مع عدد كبير من استفسارات واجهات برمجة تطبيقات توليد الصور. تم إعداد هذا المقال بناءً على وثائق OpenAI الرسمية واستشارات العملاء الحقيقية. إذا كنت بحاجة إلى معرفة المزيد حول حلول دمج
gpt-image-2، تفضل بزيارة APIYI على apiyi.com.