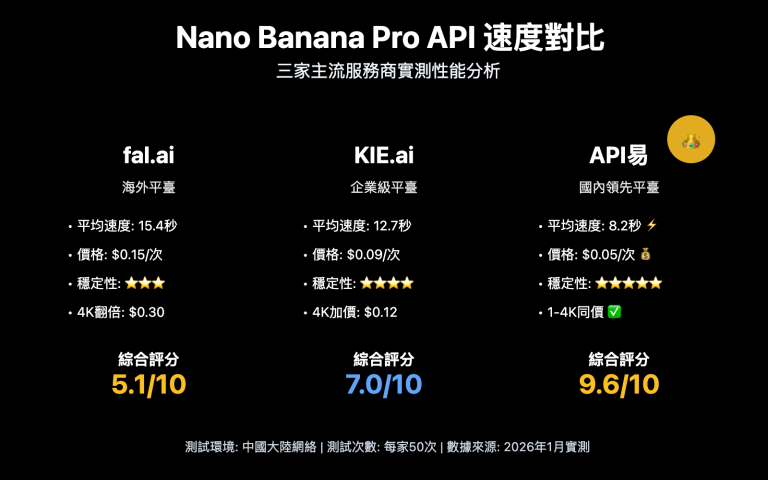
作者注:逐字段解讀 Nano Banana Pro API 返回的 IMAGE_SAFETY 報錯信息,分析雙層安全過濾機制、Token 計費邏輯和 8 種提高生成成功率的實戰方法
用 Nano Banana Pro API 生成圖片時,你可能遇到過這個令人困惑的響應——明明提示詞沒有任何敏感內容,卻返回 finishReason: IMAGE_SAFETY,圖片被安全過濾器攔截了。更讓人不解的是,響應中 thoughtsTokenCount: 173 說明模型已經完成了思考,但最終圖片還是被"槍斃"了。本文將逐字段解析這個報錯,講清楚 Google 的雙層安全過濾機制、被攔截時的 Token 計費邏輯,以及如何提高生成成功率。
核心價值: 讀完本文,你將理解 IMAGE_SAFETY 報錯的每個字段含義,知道被攔截時有沒有被扣費,以及如何通過提示詞優化將成功率提升到 70-80%。

IMAGE_SAFETY 報錯逐字段解析
先把這個響應中每個字段的含義講清楚。
| 字段 | 值 | 含義 |
|---|---|---|
content.parts |
null |
沒有返回任何內容(圖片被攔截) |
finishReason |
IMAGE_SAFETY |
觸發了第二層輸出安全過濾器 |
finishMessage |
"Unable to show…" | Google 官方提示:違反了生成式 AI 使用政策 |
promptTokenCount |
276 | 輸入消耗了 276 個 Token |
candidatesTokenCount |
0 | 輸出 Token 爲 0(圖片被攔截,沒有生成輸出) |
totalTokenCount |
449 | 總計 449 Token(輸入 276 + 思考 173) |
thoughtsTokenCount |
173 | 模型的思考過程消耗了 173 個 Token |
promptTokensDetails |
TEXT:18, IMAGE:258 | 輸入中 18 個文本 Token + 258 個圖片 Token(參考圖) |
modelVersion |
gemini-3-pro-image-preview | Nano Banana Pro 模型 |
IMAGE_SAFETY 報錯中最關鍵的 3 個信號
信號一:thoughtsTokenCount: 173 — 模型確實思考了
這說明你的提示詞通過了第一層安全檢查(輸入端),模型開始了推理過程(Thinking),甚至已經生成了圖片——但在最終輸出時被第二層安全過濾器攔截了。問題不在你的提示詞,而在模型"想畫出來"的內容。
信號二:candidatesTokenCount: 0 — 輸出爲零
圖片被攔截後,輸出 Token 計爲 0。Google 官方說法是"You will not be charged for blocked images"(被攔截的圖片不收費)。但注意:輸入 Token(276)和思考 Token(173)是否被計費取決於具體情況和計費邏輯。
信號三:IMAGE: 258 — 你輸入了參考圖
你的請求中包含了一張參考圖片(消耗 258 個圖片 Token)。這意味着你可能在做圖片編輯(image-to-image),而不是純文本生圖。圖片編輯場景的安全過濾通常比純文本更嚴格——因爲參考圖本身也會被安全檢查。
Google 的雙層安全過濾機制
理解 IMAGE_SAFETY 報錯的關鍵是理解 Google 的安全過濾不是一層,而是兩層——而且第二層你無法關閉。
第一層:可配置的輸入安全設置
| 維度 | 說明 | 是否可配置 |
|---|---|---|
| 過濾位置 | 輸入端(提示詞) | 可配置 |
| 過濾對象 | 用戶提交的文本和圖片 | 可配置 |
| 可設置爲 | BLOCK_NONE(不攔截) | 可以 |
| 觸發後表現 | 請求直接被拒絕,不消耗 Token | — |
你可以通過 API 參數設置 safety_settings 爲 BLOCK_NONE,降低第一層的過濾敏感度。
第二層:不可配置的輸出安全過濾
| 維度 | 說明 | 是否可配置 |
|---|---|---|
| 過濾位置 | 輸出端(生成的圖片) | 不可配置 |
| 過濾對象 | 模型生成的圖片內容 | 不可配置 |
| 能否關閉 | 不能,所有用戶、所有層級強制生效 | 不能 |
| 觸發後表現 | finishReason: IMAGE_SAFETY,parts: null |
— |
IMAGE_SAFETY 報錯就是第二層觸發了。你的提示詞通過了第一層,模型完成了思考(173 Token),生成了圖片——但圖片在最終輸出前被第二層攔截了。
Google 官方承認這個過濾器"變得比我們預期的更謹慎",導致了大量誤攔截——連"一隻狗"、"一碗麥片"這樣的提示詞都可能被攔。
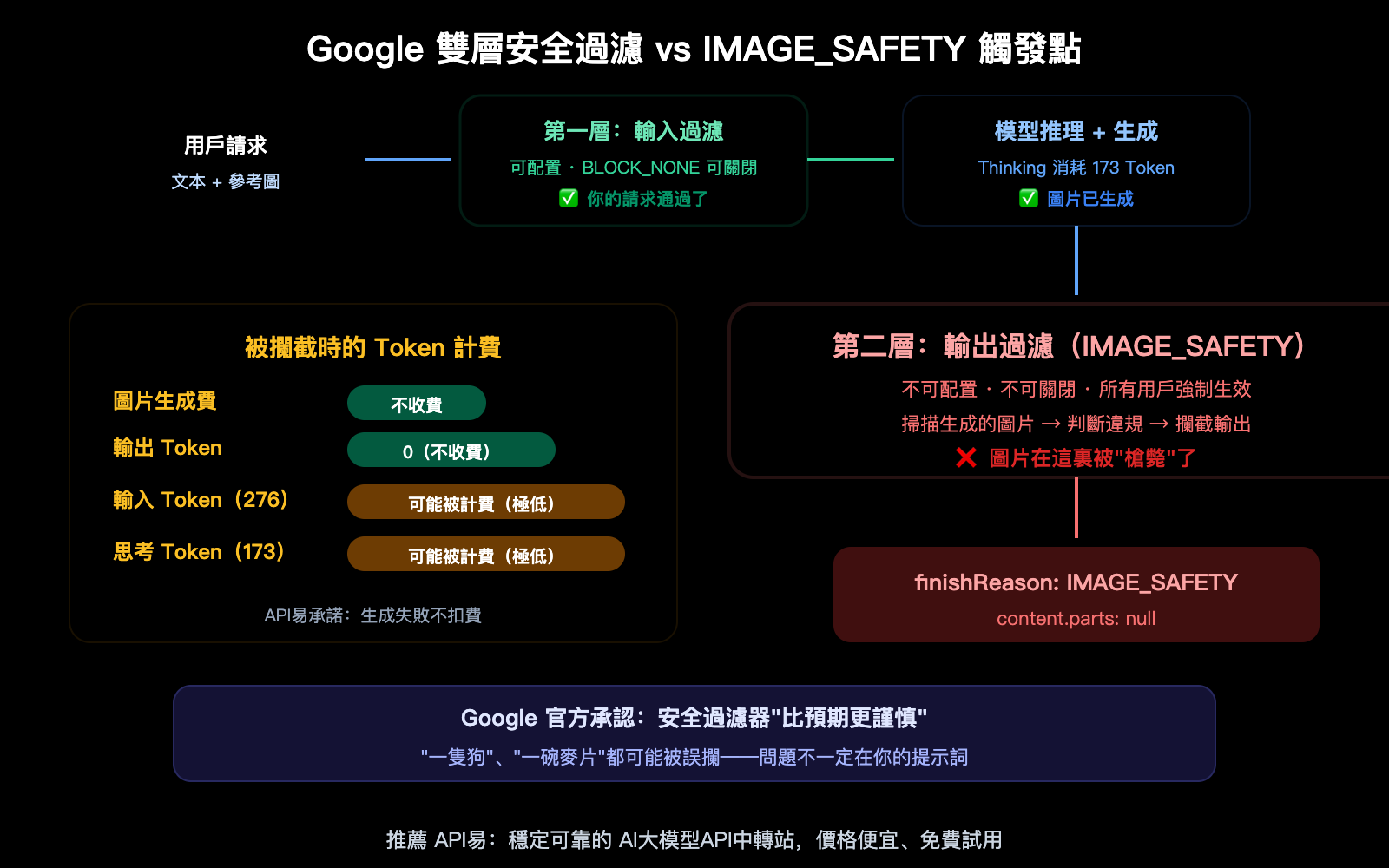
IMAGE_SAFETY 被攔截時到底扣不扣費
這是開發者最關心的實際問題。
Nano Banana Pro IMAGE_SAFETY 計費規則
| 計費項 | 被攔截時是否計費 | 說明 |
|---|---|---|
| 圖片生成費 | 不計費 | Google 明確說"You will not be charged for blocked images" |
| 輸出 Token | 不計費 | candidatesTokenCount: 0,沒有輸出就不計費 |
| 輸入 Token | 可能計費(極低) | 276 Token × $0.25/M ≈ $0.00007(可忽略) |
| 思考 Token | 取決於計費邏輯 | 173 Token,Gemini API 可能包含在 candidates 中 |
結論: 被 IMAGE_SAFETY 攔截時,主要成本(圖片生成費和輸出 Token 費)不會產生。輸入 Token 的費用極低(不到萬分之一美元),基本可以忽略。
API易的額外保障: 通過 API易 apiyi.com 調用時,生成失敗不扣費——包括 IMAGE_SAFETY 攔截的情況。你只爲成功生成的圖片付費。
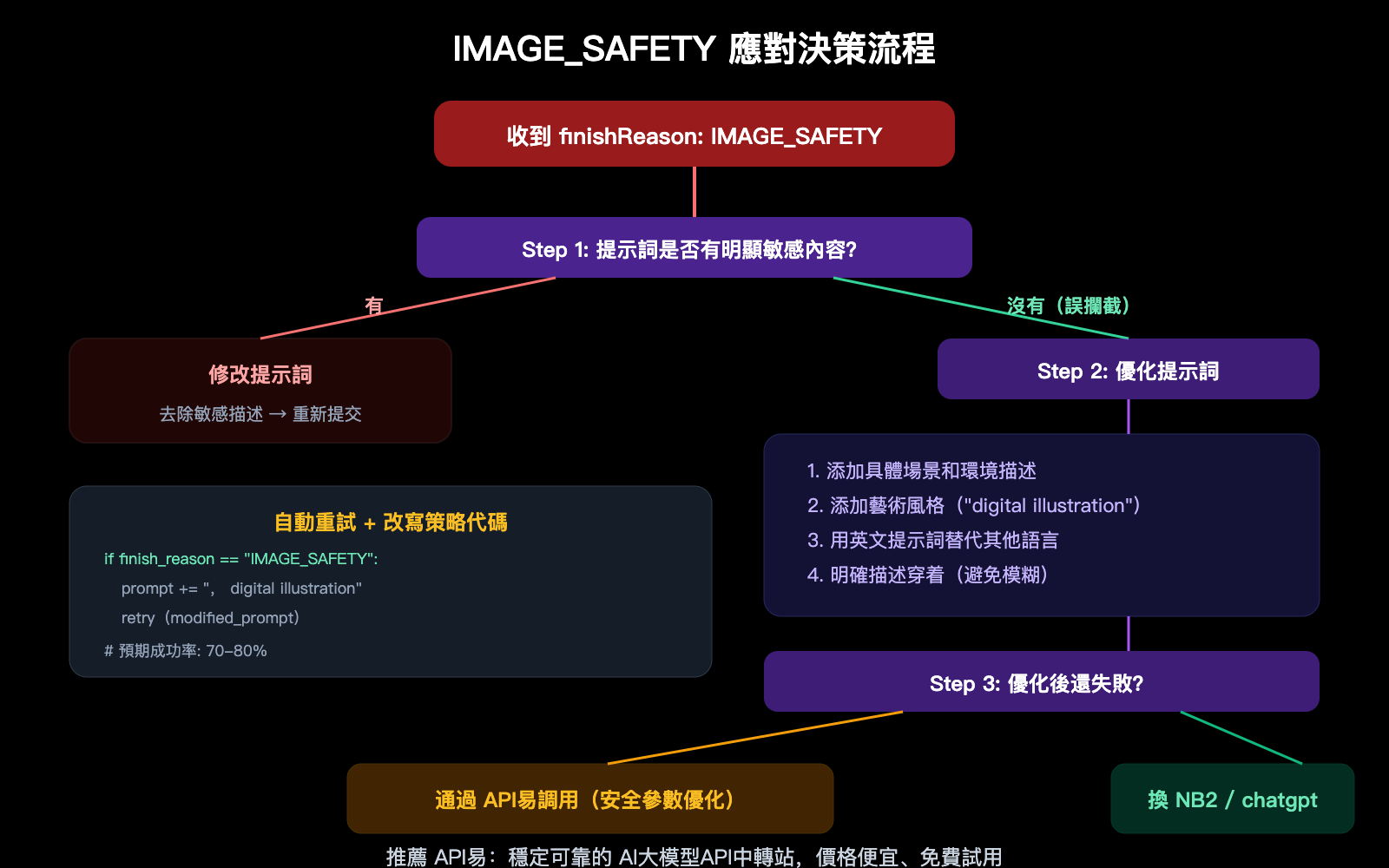
提高 IMAGE_SAFETY 通過率的 8 種方法
既然第二層安全過濾無法關閉,我們只能通過間接方法提高成功率。
方法一:設置 BLOCK_NONE 關閉第一層
先確保第一層不會額外攔截:
from google.genai import types
safety_settings = [
types.SafetySetting(
category="HARM_CATEGORY_HARASSMENT",
threshold="BLOCK_NONE"
),
types.SafetySetting(
category="HARM_CATEGORY_HATE_SPEECH",
threshold="BLOCK_NONE"
),
types.SafetySetting(
category="HARM_CATEGORY_SEXUALLY_EXPLICIT",
threshold="BLOCK_NONE"
),
types.SafetySetting(
category="HARM_CATEGORY_DANGEROUS_CONTENT",
threshold="BLOCK_NONE"
),
]
方法二:提示詞增加具體細節
模糊的提示詞更容易觸發安全過濾。增加具體細節可以引導模型生成更"安全"的圖片:
❌ "一個女人"
→ 模型可能生成被過濾器判定爲不當的內容
✅ "一位穿着職業西裝的女性,在現代辦公室中工作,
自然光線,數字插畫風格"
→ 具體場景 + 穿着描述 + 藝術風格 → 成功率大幅提升
方法三至八:進階優化策略
| 方法 | 操作 | 預期效果 |
|---|---|---|
| 方法三:添加藝術風格 | 末尾加"digital illustration style"或"watercolor style" | 降低寫實度 → 減少觸發 |
| 方法四:指定環境上下文 | 加明確的場景描述("在公園"、"在辦公室") | 限制模型發揮空間 |
| 方法五:避免皮膚暴露描述 | 用"formal attire"、"winter clothing"替代模糊穿着 | 直接避開敏感區域 |
| 方法六:用英文提示詞 | 英文提示詞的安全過濾校準比其他語言更精準 | 減少誤攔截 |
| 方法七:自動重試不同表述 | 失敗後自動改寫提示詞重試 | 提升總體成功率 |
| 方法八:通過 API易調用 | API易對安全參數有優化配置 | 整體成功率更高 |
提示詞優化前後對比
| 場景 | 優化前(低通過率) | 優化後(高通過率) |
|---|---|---|
| 人物 | "一個穿泳衣的女孩" | "一位穿着運動裝的女性在健身房訓練,數字插畫風格" |
| 食物 | "牛排" | "一塊中等熟度的牛排放在白色瓷盤上,餐廳桌面,專業食物攝影" |
| 動物 | "一隻狗" | "一隻金毛獵犬在郊區院子裏接飛盤,午後陽光,數字插畫風格" |
| 電商 | "內衣模特" | "一件白色運動內衣的產品平鋪圖,純白背景,無模特,商品攝影" |
🎯 核心原則: 越具體的提示詞 = 越少的模型自由發揮空間 = 越少觸發安全過濾。加上藝術風格標註(如"digital illustration")可以進一步降低寫實度相關的攔截。
通過 API易 apiyi.com 調用的成功率通常高於直連 Google API,因爲平臺對安全參數做了優化配置。
常見問題
Q1: 同樣的提示詞爲什麼有時成功有時被攔截?
因爲第二層安全過濾檢查的是生成的圖片,不是提示詞。同樣的提示詞,模型每次生成的圖片略有不同(擴散模型的隨機性),某些生成結果可能恰好觸發了安全過濾器的閾值。所以重試相同的提示詞有時能成功——模型碰巧生成了一張"更安全"的圖片。
Q2: thoughtsTokenCount 大於 0 但 candidatesTokenCount 爲 0 正常嗎?
正常。這恰好說明了攔截髮生在第二層(輸出端):模型完成了思考(Thinking)並生成了圖片,但圖片在最終輸出前被安全過濾器攔截了。思考 Token 已經消耗(173),但因爲圖片沒有實際輸出,輸出 Token 計爲 0。這是 IMAGE_SAFETY 特有的響應模式——與第一層攔截不同(第一層攔截時 thoughtsTokenCount 也爲 0)。
Q3: 電商內衣/泳裝類圖片頻繁被攔怎麼辦?
這是已知的高頻誤攔場景。Google 開發者論壇上有大量"non-NSFW ecommerce underwear images with IMAGE_SAFETY error"的報告。建議:1)使用產品平鋪圖(無模特)替代模特圖;2)提示詞中明確標註"product flat lay, no model, white background";3)通過 API易 apiyi.com 調用,平臺的安全參數配置針對電商場景有優化。
Q4: 被攔截的請求在 API易會被扣費嗎?
不會。API易承諾生成失敗不扣費,包括 IMAGE_SAFETY 攔截的情況。你只爲成功生成的圖片付費。這與 Google 官方 API 的計費邏輯一致(blocked images 不收費),但 API易在此基礎上進一步保障——即使輸入 Token 的微小費用也不會產生。
總結
Nano Banana Pro IMAGE_SAFETY 報錯的核心要點:
- 報錯本質是第二層輸出過濾: 你的提示詞通過了第一層,模型完成了思考(173 Token),圖片已經生成——但在最終輸出時被不可關閉的第二層安全過濾器攔截
- 被攔截基本不扣費:
candidatesTokenCount: 0意味着輸出 Token 不計費,Google 明確說"不爲被攔截的圖片收費",通過 API易調用更有失敗不扣費的保障 - 提示詞優化可提升到 70-80% 成功率: 核心原則是"越具體越安全"——加具體場景、加藝術風格、加穿着描述、用英文提示詞
推薦通過 API易 apiyi.com 調用 Nano Banana Pro——安全參數優化配置、失敗不扣費、28% 折扣,降低 IMAGE_SAFETY 誤攔截對你業務的影響。
📚 參考資料
-
Gemini API Safety Settings 文檔: 官方安全設置參數說明
- 鏈接:
ai.google.dev/gemini-api/docs/safety-settings - 說明: 包含 BLOCK_NONE 配置和安全類別列表
- 鏈接:
-
Nano Banana Pro IMAGE_SAFETY 完整修復指南: 8 種提高成功率的方法
- 鏈接:
help.apiyi.com/en/nano-banana-pro-image-safety-error-fix-guide-en.html - 說明: 包含提示詞優化模板和場景化解決方案
- 鏈接:
-
Google AI 開發者論壇 IMAGE_SAFETY 討論: 社區報告和官方回應
- 鏈接:
discuss.ai.google.dev/t/nano-banana-is-unusable-because-of-the-new-safety-filters/132366 - 說明: Google 承認過濾器"過於謹慎"
- 鏈接:
-
API易文檔中心: Nano Banana Pro 失敗不扣費保障
- 鏈接:
docs.apiyi.com - 說明: 包含安全參數優化和電商場景配置指南
- 鏈接:
作者: APIYI 技術團隊
技術交流: 歡迎在評論區討論,更多資料可訪問 API易 docs.apiyi.com 文檔中心