作者注:逐字段解读 Nano Banana Pro API 返回的 IMAGE_SAFETY 报错信息,分析双层安全过滤机制、Token 计费逻辑和 8 种提高生成成功率的实战方法
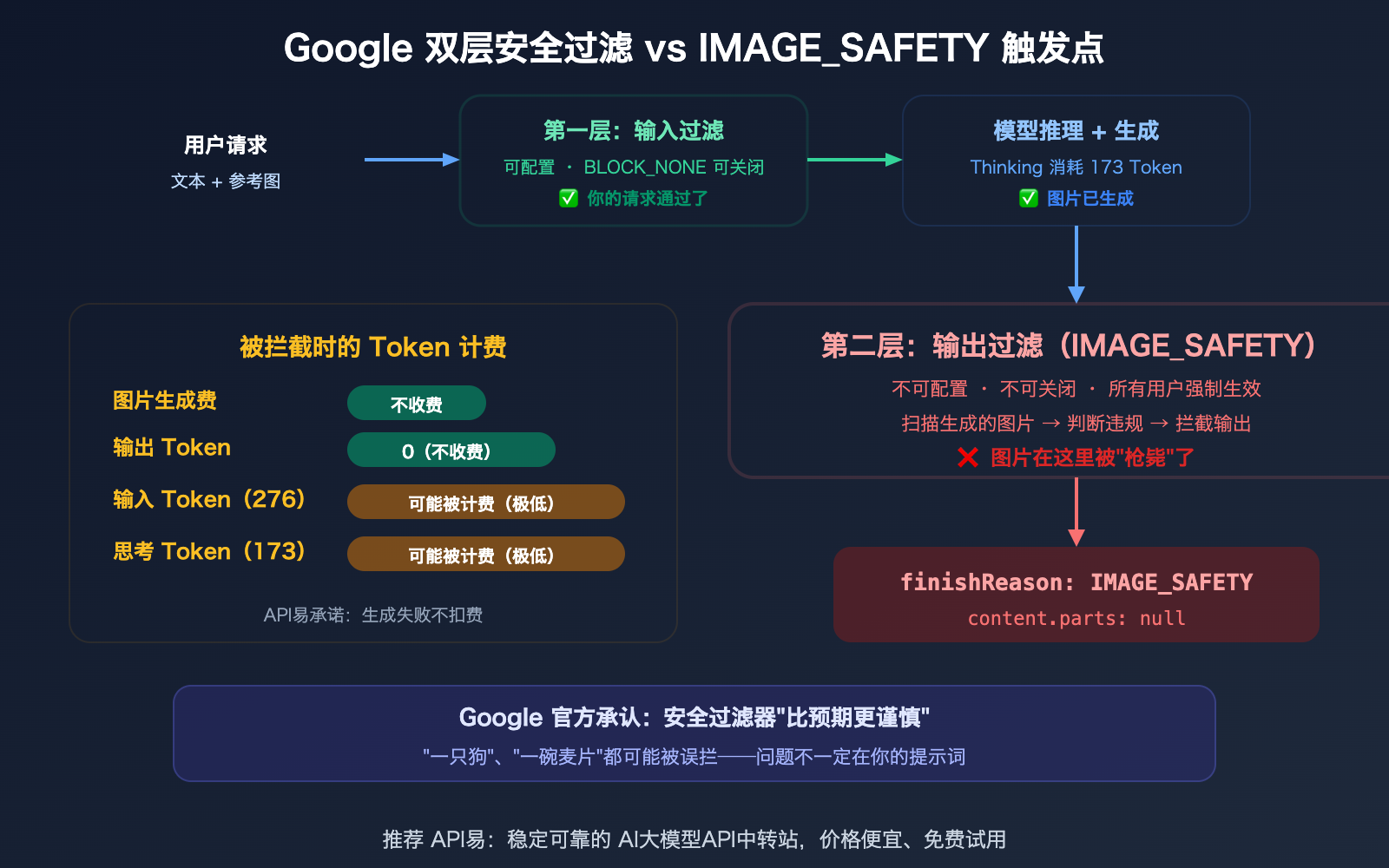
用 Nano Banana Pro API 生成图片时,你可能遇到过这个令人困惑的响应——明明提示词没有任何敏感内容,却返回 finishReason: IMAGE_SAFETY,图片被安全过滤器拦截了。更让人不解的是,响应中 thoughtsTokenCount: 173 说明模型已经完成了思考,但最终图片还是被"枪毙"了。本文将逐字段解析这个报错,讲清楚 Google 的双层安全过滤机制、被拦截时的 Token 计费逻辑,以及如何提高生成成功率。
核心价值: 读完本文,你将理解 IMAGE_SAFETY 报错的每个字段含义,知道被拦截时有没有被扣费,以及如何通过提示词优化将成功率提升到 70-80%。

IMAGE_SAFETY 报错逐字段解析
先把这个响应中每个字段的含义讲清楚。
| 字段 | 值 | 含义 |
|---|---|---|
content.parts |
null |
没有返回任何内容(图片被拦截) |
finishReason |
IMAGE_SAFETY |
触发了第二层输出安全过滤器 |
finishMessage |
"Unable to show…" | Google 官方提示:违反了生成式 AI 使用政策 |
promptTokenCount |
276 | 输入消耗了 276 个 Token |
candidatesTokenCount |
0 | 输出 Token 为 0(图片被拦截,没有生成输出) |
totalTokenCount |
449 | 总计 449 Token(输入 276 + 思考 173) |
thoughtsTokenCount |
173 | 模型的思考过程消耗了 173 个 Token |
promptTokensDetails |
TEXT:18, IMAGE:258 | 输入中 18 个文本 Token + 258 个图片 Token(参考图) |
modelVersion |
gemini-3-pro-image-preview | Nano Banana Pro 模型 |
IMAGE_SAFETY 报错中最关键的 3 个信号
信号一:thoughtsTokenCount: 173 — 模型确实思考了
这说明你的提示词通过了第一层安全检查(输入端),模型开始了推理过程(Thinking),甚至已经生成了图片——但在最终输出时被第二层安全过滤器拦截了。问题不在你的提示词,而在模型"想画出来"的内容。
信号二:candidatesTokenCount: 0 — 输出为零
图片被拦截后,输出 Token 计为 0。Google 官方说法是"You will not be charged for blocked images"(被拦截的图片不收费)。但注意:输入 Token(276)和思考 Token(173)是否被计费取决于具体情况和计费逻辑。
信号三:IMAGE: 258 — 你输入了参考图
你的请求中包含了一张参考图片(消耗 258 个图片 Token)。这意味着你可能在做图片编辑(image-to-image),而不是纯文本生图。图片编辑场景的安全过滤通常比纯文本更严格——因为参考图本身也会被安全检查。
Google 的双层安全过滤机制
理解 IMAGE_SAFETY 报错的关键是理解 Google 的安全过滤不是一层,而是两层——而且第二层你无法关闭。
第一层:可配置的输入安全设置
| 维度 | 说明 | 是否可配置 |
|---|---|---|
| 过滤位置 | 输入端(提示词) | 可配置 |
| 过滤对象 | 用户提交的文本和图片 | 可配置 |
| 可设置为 | BLOCK_NONE(不拦截) | 可以 |
| 触发后表现 | 请求直接被拒绝,不消耗 Token | — |
你可以通过 API 参数设置 safety_settings 为 BLOCK_NONE,降低第一层的过滤敏感度。
第二层:不可配置的输出安全过滤
| 维度 | 说明 | 是否可配置 |
|---|---|---|
| 过滤位置 | 输出端(生成的图片) | 不可配置 |
| 过滤对象 | 模型生成的图片内容 | 不可配置 |
| 能否关闭 | 不能,所有用户、所有层级强制生效 | 不能 |
| 触发后表现 | finishReason: IMAGE_SAFETY,parts: null |
— |
IMAGE_SAFETY 报错就是第二层触发了。你的提示词通过了第一层,模型完成了思考(173 Token),生成了图片——但图片在最终输出前被第二层拦截了。
Google 官方承认这个过滤器"变得比我们预期的更谨慎",导致了大量误拦截——连"一只狗"、"一碗麦片"这样的提示词都可能被拦。
IMAGE_SAFETY 被拦截时到底扣不扣费
这是开发者最关心的实际问题。
Nano Banana Pro IMAGE_SAFETY 计费规则
| 计费项 | 被拦截时是否计费 | 说明 |
|---|---|---|
| 图片生成费 | 不计费 | Google 明确说"You will not be charged for blocked images" |
| 输出 Token | 不计费 | candidatesTokenCount: 0,没有输出就不计费 |
| 输入 Token | 可能计费(极低) | 276 Token × $0.25/M ≈ $0.00007(可忽略) |
| 思考 Token | 取决于计费逻辑 | 173 Token,Gemini API 可能包含在 candidates 中 |
结论: 被 IMAGE_SAFETY 拦截时,主要成本(图片生成费和输出 Token 费)不会产生。输入 Token 的费用极低(不到万分之一美元),基本可以忽略。
API易的额外保障: 通过 API易 apiyi.com 调用时,生成失败不扣费——包括 IMAGE_SAFETY 拦截的情况。你只为成功生成的图片付费。
提高 IMAGE_SAFETY 通过率的 8 种方法
既然第二层安全过滤无法关闭,我们只能通过间接方法提高成功率。
方法一:设置 BLOCK_NONE 关闭第一层
先确保第一层不会额外拦截:
from google.genai import types
safety_settings = [
types.SafetySetting(
category="HARM_CATEGORY_HARASSMENT",
threshold="BLOCK_NONE"
),
types.SafetySetting(
category="HARM_CATEGORY_HATE_SPEECH",
threshold="BLOCK_NONE"
),
types.SafetySetting(
category="HARM_CATEGORY_SEXUALLY_EXPLICIT",
threshold="BLOCK_NONE"
),
types.SafetySetting(
category="HARM_CATEGORY_DANGEROUS_CONTENT",
threshold="BLOCK_NONE"
),
]
方法二:提示词增加具体细节
模糊的提示词更容易触发安全过滤。增加具体细节可以引导模型生成更"安全"的图片:
❌ "一个女人"
→ 模型可能生成被过滤器判定为不当的内容
✅ "一位穿着职业西装的女性,在现代办公室中工作,
自然光线,数字插画风格"
→ 具体场景 + 穿着描述 + 艺术风格 → 成功率大幅提升
方法三至八:进阶优化策略
| 方法 | 操作 | 预期效果 |
|---|---|---|
| 方法三:添加艺术风格 | 末尾加"digital illustration style"或"watercolor style" | 降低写实度 → 减少触发 |
| 方法四:指定环境上下文 | 加明确的场景描述("在公园"、"在办公室") | 限制模型发挥空间 |
| 方法五:避免皮肤暴露描述 | 用"formal attire"、"winter clothing"替代模糊穿着 | 直接避开敏感区域 |
| 方法六:用英文提示词 | 英文提示词的安全过滤校准比其他语言更精准 | 减少误拦截 |
| 方法七:自动重试不同表述 | 失败后自动改写提示词重试 | 提升总体成功率 |
| 方法八:通过 API易调用 | API易对安全参数有优化配置 | 整体成功率更高 |
提示词优化前后对比
| 场景 | 优化前(低通过率) | 优化后(高通过率) |
|---|---|---|
| 人物 | "一个穿泳衣的女孩" | "一位穿着运动装的女性在健身房训练,数字插画风格" |
| 食物 | "牛排" | "一块中等熟度的牛排放在白色瓷盘上,餐厅桌面,专业食物摄影" |
| 动物 | "一只狗" | "一只金毛猎犬在郊区院子里接飞盘,午后阳光,数字插画风格" |
| 电商 | "内衣模特" | "一件白色运动内衣的产品平铺图,纯白背景,无模特,商品摄影" |
🎯 核心原则: 越具体的提示词 = 越少的模型自由发挥空间 = 越少触发安全过滤。加上艺术风格标注(如"digital illustration")可以进一步降低写实度相关的拦截。
通过 API易 apiyi.com 调用的成功率通常高于直连 Google API,因为平台对安全参数做了优化配置。

常见问题
Q1: 同样的提示词为什么有时成功有时被拦截?
因为第二层安全过滤检查的是生成的图片,不是提示词。同样的提示词,模型每次生成的图片略有不同(扩散模型的随机性),某些生成结果可能恰好触发了安全过滤器的阈值。所以重试相同的提示词有时能成功——模型碰巧生成了一张"更安全"的图片。
Q2: thoughtsTokenCount 大于 0 但 candidatesTokenCount 为 0 正常吗?
正常。这恰好说明了拦截发生在第二层(输出端):模型完成了思考(Thinking)并生成了图片,但图片在最终输出前被安全过滤器拦截了。思考 Token 已经消耗(173),但因为图片没有实际输出,输出 Token 计为 0。这是 IMAGE_SAFETY 特有的响应模式——与第一层拦截不同(第一层拦截时 thoughtsTokenCount 也为 0)。
Q3: 电商内衣/泳装类图片频繁被拦怎么办?
这是已知的高频误拦场景。Google 开发者论坛上有大量"non-NSFW ecommerce underwear images with IMAGE_SAFETY error"的报告。建议:1)使用产品平铺图(无模特)替代模特图;2)提示词中明确标注"product flat lay, no model, white background";3)通过 API易 apiyi.com 调用,平台的安全参数配置针对电商场景有优化。
Q4: 被拦截的请求在 API易会被扣费吗?
不会。API易承诺生成失败不扣费,包括 IMAGE_SAFETY 拦截的情况。你只为成功生成的图片付费。这与 Google 官方 API 的计费逻辑一致(blocked images 不收费),但 API易在此基础上进一步保障——即使输入 Token 的微小费用也不会产生。
总结
Nano Banana Pro IMAGE_SAFETY 报错的核心要点:
- 报错本质是第二层输出过滤: 你的提示词通过了第一层,模型完成了思考(173 Token),图片已经生成——但在最终输出时被不可关闭的第二层安全过滤器拦截
- 被拦截基本不扣费:
candidatesTokenCount: 0意味着输出 Token 不计费,Google 明确说"不为被拦截的图片收费",通过 API易调用更有失败不扣费的保障 - 提示词优化可提升到 70-80% 成功率: 核心原则是"越具体越安全"——加具体场景、加艺术风格、加穿着描述、用英文提示词
推荐通过 API易 apiyi.com 调用 Nano Banana Pro——安全参数优化配置、失败不扣费、28% 折扣,降低 IMAGE_SAFETY 误拦截对你业务的影响。
📚 参考资料
-
Gemini API Safety Settings 文档: 官方安全设置参数说明
- 链接:
ai.google.dev/gemini-api/docs/safety-settings - 说明: 包含 BLOCK_NONE 配置和安全类别列表
- 链接:
-
Nano Banana Pro IMAGE_SAFETY 完整修复指南: 8 种提高成功率的方法
- 链接:
help.apiyi.com/en/nano-banana-pro-image-safety-error-fix-guide-en.html - 说明: 包含提示词优化模板和场景化解决方案
- 链接:
-
Google AI 开发者论坛 IMAGE_SAFETY 讨论: 社区报告和官方回应
- 链接:
discuss.ai.google.dev/t/nano-banana-is-unusable-because-of-the-new-safety-filters/132366 - 说明: Google 承认过滤器"过于谨慎"
- 链接:
-
API易文档中心: Nano Banana Pro 失败不扣费保障
- 链接:
docs.apiyi.com - 说明: 包含安全参数优化和电商场景配置指南
- 链接:
作者: APIYI 技术团队
技术交流: 欢迎在评论区讨论,更多资料可访问 API易 docs.apiyi.com 文档中心