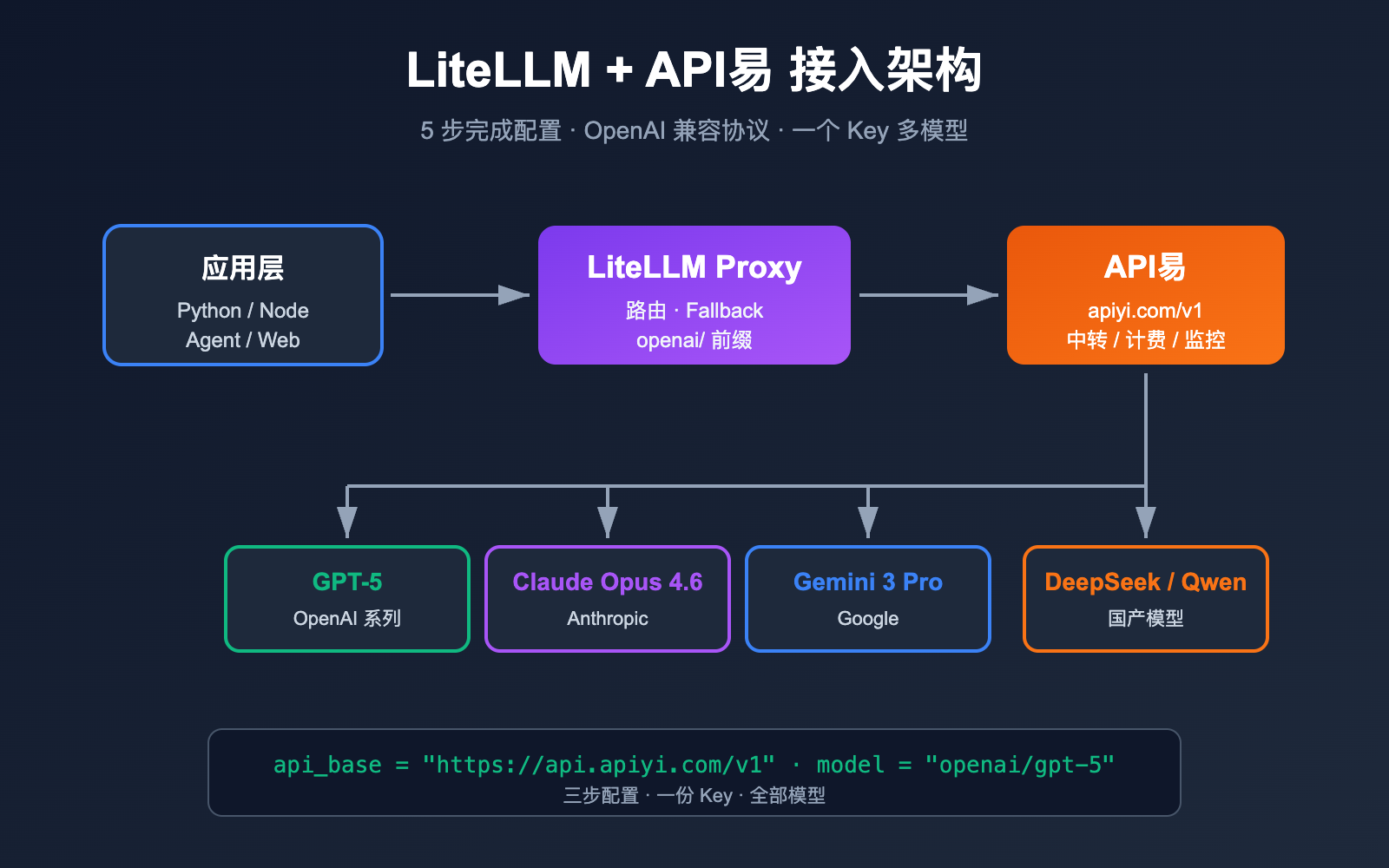
如何让 LiteLLM 同时调度 OpenAI、Claude、Gemini、DeepSeek 等多家大模型,又不被海外账号、网络、支付等问题卡住?答案就是把 LiteLLM 接到一个 OpenAI 兼容的第三方中转站。本文将以 LiteLLM + API易 apiyi.com 为例,手把手教你完成配置。
核心价值: 读完本文,你将掌握 LiteLLM 配置第三方中转站的 3 种主流方式(SDK、Proxy YAML、环境变量),并能够在 5 分钟内完成 API易 接入。
LiteLLM 配置第三方中转站 核心要点
LiteLLM 是一个开源的 LLM 网关 / SDK,目标是用 OpenAI 兼容格式调用 100+ 家大模型。它本身就支持任意"OpenAI 兼容"的端点,只需要把 api_base 指向中转站、api_key 换成中转站颁发的 Key 即可。API易 apiyi.com 正是一个标准的 OpenAI 兼容中转,所以两者天然契合。
| 要点 | 说明 | 价值 |
|---|---|---|
| OpenAI 兼容协议 | LiteLLM 通过 openai/ 前缀路由到 OpenAI 客户端 |
一行配置接入任何中转站 |
| 三种配置方式 | SDK 内联 / Proxy YAML / 环境变量 | 适配脚本、生产、CLI 三种场景 |
| 统一模型命名 | openai/<provider-model> 或自定义 model_name |
上层代码无需感知底层切换 |
| 错误排查关键 | base_url 必须以 /v1 结尾 |
90% 的 404 报错来自这里 |
| Fallback 与负载均衡 | YAML 模式支持多渠道与失败回退 | 生产环境可用性最大化 |
LiteLLM 配置第三方中转站重点详解
LiteLLM 官方文档明确说明:只要在 model 名前加 openai/ 前缀,并指定 api_base,LiteLLM 就会用 openai 客户端去访问你的端点。这意味着无论中转站后面接的是 GPT-5、Claude Opus 4.6、Gemini 3 Pro 还是 DeepSeek,对 LiteLLM 来说都是"一个 OpenAI 端点"。
API易 apiyi.com 的 base_url 为 https://api.apiyi.com/v1,遵循标准的 /v1/chat/completions、/v1/embeddings、/v1/images/generations 规范,因此与 LiteLLM 完美兼容,无需任何 patch。

LiteLLM 配置第三方中转站 快速上手
准备工作
在开始之前,请准备好:
- API易 API Key: 在 apiyi.com 注册后,控制台中创建一个新的 Key(建议起名
litellm-prod) - base_url:
https://api.apiyi.com/v1(注意结尾必须有/v1) - Python 环境: Python 3.9+
- 安装依赖:
pip install litellm
极简示例:SDK 内联配置
最快的接入方式是在代码里直接传入 api_key 和 api_base:
import litellm
response = litellm.completion(
model="openai/gpt-5", # 关键:openai/ 前缀
api_key="YOUR_APIYI_KEY",
api_base="https://api.apiyi.com/v1", # API易 中转站地址
messages=[
{"role": "user", "content": "用一句话介绍 LiteLLM"}
],
)
print(response.choices[0].message.content)
💡 建议: 通过 API易 apiyi.com 控制台获取测试额度后,你可以把
gpt-5换成claude-opus-4-6、gemini-3-pro等模型名,无需修改任何其他代码 —— 这就是 OpenAI 兼容协议的最大价值。
查看完整可运行示例 (含错误处理与流式输出)
import os
import litellm
from litellm import completion
# 推荐通过环境变量管理密钥
os.environ["OPENAI_API_KEY"] = "YOUR_APIYI_KEY"
os.environ["OPENAI_API_BASE"] = "https://api.apiyi.com/v1"
litellm.set_verbose = False # 调试时改为 True
def chat_with_apiyi(model: str, prompt: str, stream: bool = False):
"""通过 LiteLLM + API易 调用任意 OpenAI 兼容模型"""
try:
response = completion(
model=f"openai/{model}",
messages=[{"role": "user", "content": prompt}],
stream=stream,
temperature=0.7,
max_tokens=1024,
)
if stream:
for chunk in response:
delta = chunk.choices[0].delta.content or ""
print(delta, end="", flush=True)
print()
else:
return response.choices[0].message.content
except Exception as e:
print(f"调用失败: {e}")
return None
if __name__ == "__main__":
# 非流式
print(chat_with_apiyi("gpt-5", "解释什么是 LLM 网关"))
# 流式
chat_with_apiyi("claude-opus-4-6", "用 100 字介绍 LiteLLM 的优势", stream=True)
Proxy YAML 配置:生产推荐
如果你要把 LiteLLM 跑成一个独立服务(端口 4000,给团队复用),推荐使用 YAML 模式。新建 litellm_config.yaml:
model_list:
- model_name: gpt-5 # 对外暴露的模型名
litellm_params:
model: openai/gpt-5 # openai/ 前缀,路由到 OpenAI 客户端
api_base: https://api.apiyi.com/v1 # API易 中转地址
api_key: os.environ/APIYI_KEY # 引用环境变量
- model_name: claude-opus-4-6
litellm_params:
model: openai/claude-opus-4-6
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
- model_name: gemini-3-pro
litellm_params:
model: openai/gemini-3-pro
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
litellm_settings:
drop_params: true # 自动丢弃模型不支持的参数
num_retries: 2 # 单次调用重试次数
router_settings:
fallbacks:
- gpt-5: ["claude-opus-4-6", "gemini-3-pro"]
启动 Proxy:
export APIYI_KEY=sk-xxxxxxxxxxxxxxxx
litellm --config ./litellm_config.yaml --port 4000
之后任意 OpenAI SDK 都能通过 http://localhost:4000 调用:
from openai import OpenAI
client = OpenAI(
api_key="any-string", # LiteLLM Proxy 不校验内容(除非配 master_key)
base_url="http://localhost:4000",
)
resp = client.chat.completions.create(
model="gpt-5",
messages=[{"role": "user", "content": "Hello via LiteLLM Proxy"}]
)
print(resp.choices[0].message.content)
🎯 生产建议: 我们建议在 LiteLLM Proxy 前面加一层 master_key,并把所有底层模型统一接到 API易 apiyi.com,这样你的应用层只看到
gpt-5/claude-opus-4-6这种"语义模型名",底层的渠道、计费、限速全部由 API易 + LiteLLM 两层处理,做到上层零感知。
环境变量模式:CLI 与脚本最爽
对一次性脚本和命令行工具,最简单的方式是直接走环境变量。LiteLLM 会自动识别 OPENAI_API_KEY 和 OPENAI_API_BASE:
export OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxx
export OPENAI_API_BASE=https://api.apiyi.com/v1
之后所有 openai/ 前缀的调用都会走 API易:
import litellm
print(litellm.completion(
model="openai/gpt-5",
messages=[{"role": "user", "content": "ping"}]
).choices[0].message.content)
LiteLLM 配置第三方中转站 三种方式对比
不同场景下,三种配置方式的取舍并不一样。下表给出明确的选择建议。
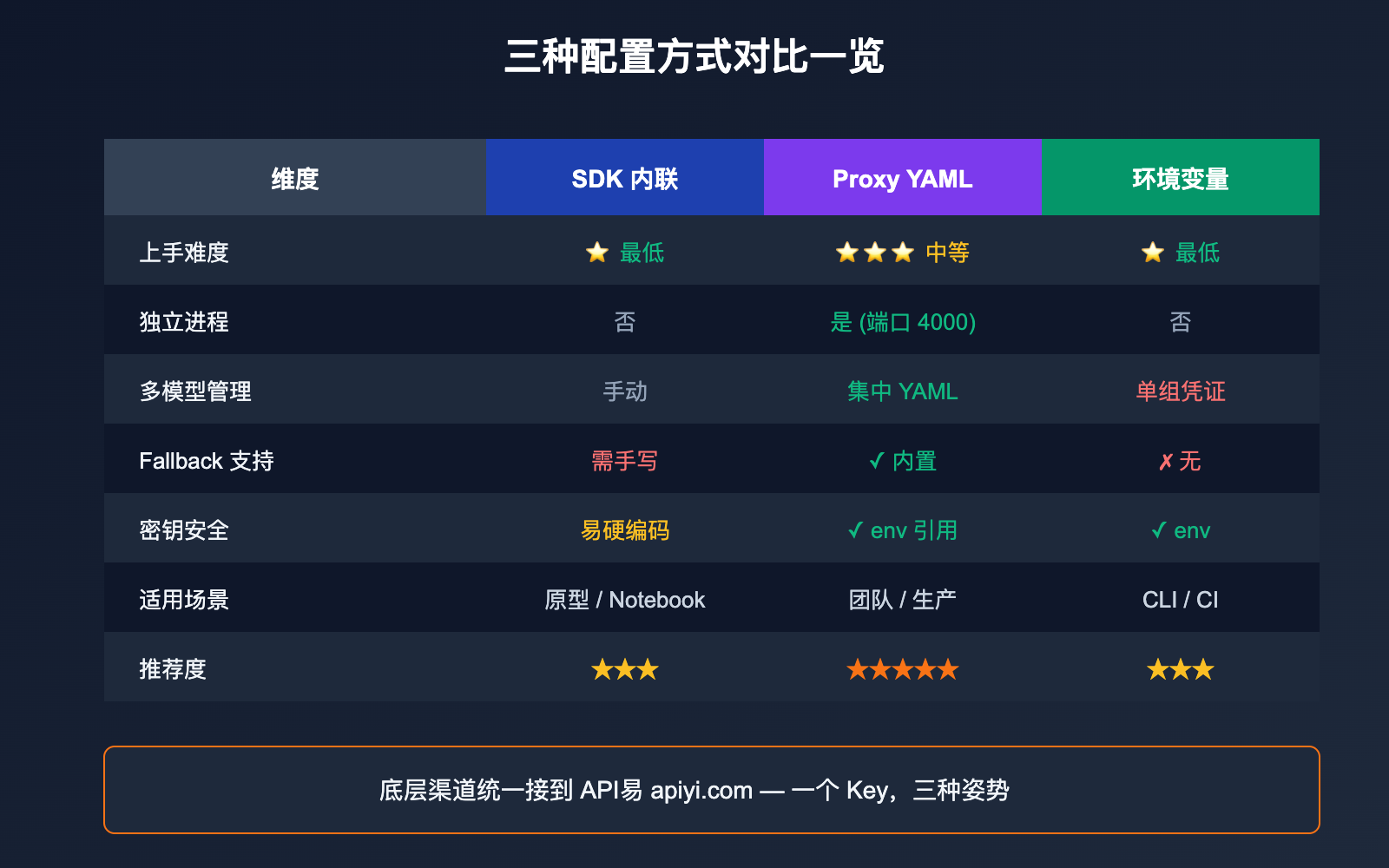
| 维度 | SDK 内联 | Proxy YAML | 环境变量 |
|---|---|---|---|
| 上手难度 | ⭐ 最低 | ⭐⭐⭐ 中等 | ⭐ 最低 |
| 适用场景 | 单脚本、Notebook | 团队共享、生产服务 | CLI 工具、CI |
| 是否独立进程 | 否 | 是(端口 4000) | 否 |
| 多模型管理 | 手动维护变量 | 集中 YAML 管理 | 仅单组凭证 |
| Fallback 支持 | 需要手写 try/except | ✅ 内置 | ❌ 无 |
| 密钥安全性 | 易硬编码(不推荐) | ✅ 引用 env | ✅ 走 env |
| 推荐度 | 原型阶段 | 生产部署 | 个人脚本 |
💡 选择建议: 个人开发可以直接环境变量;团队和生产强烈建议 Proxy YAML 模式,因为它把"模型路由 + Fallback + 限速 + 统计"都在一个文件里管理。无论选哪种,底层渠道接到 API易 apiyi.com 这一层是不变的,你只需要维护一个 API Key。
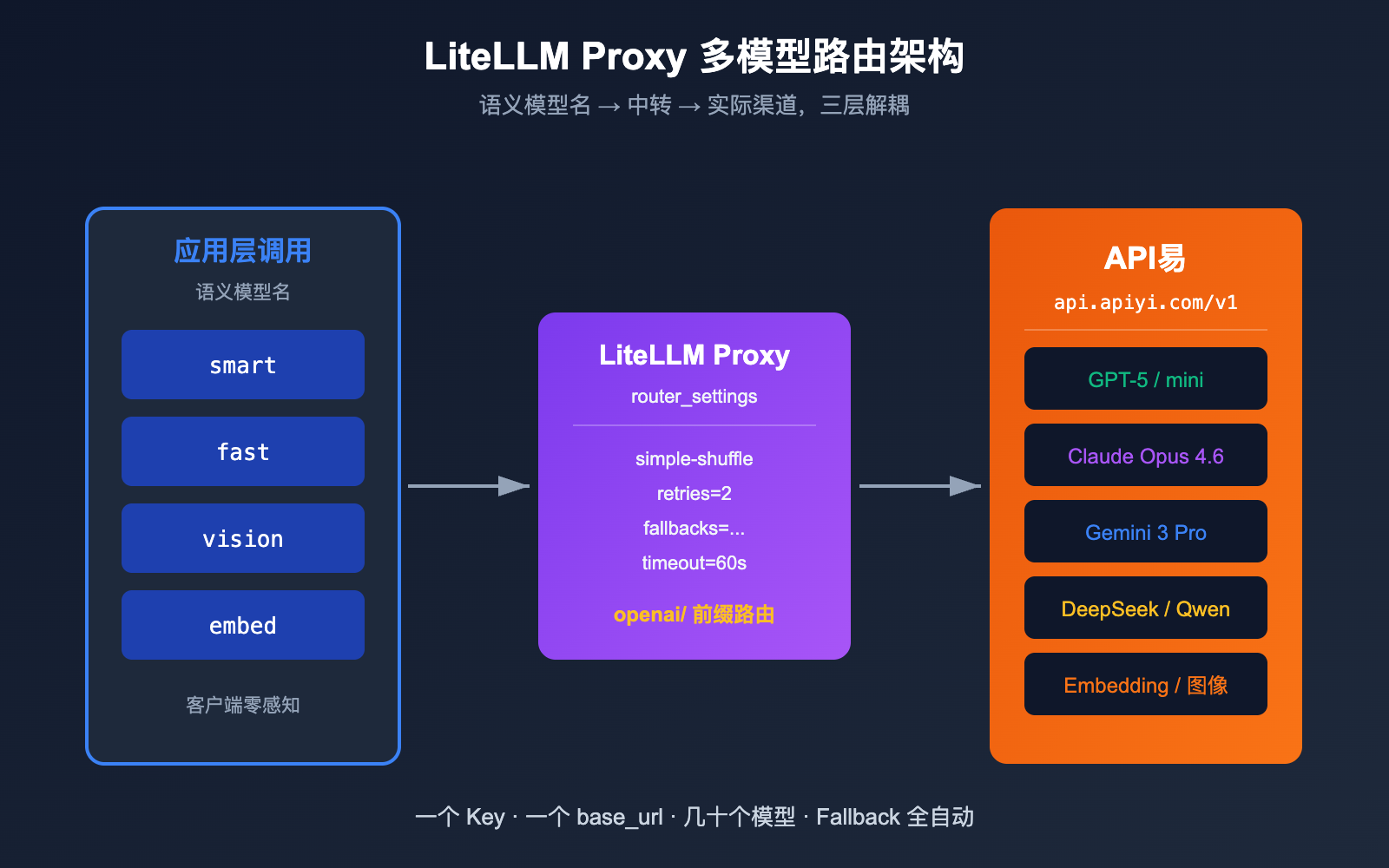
LiteLLM + API易 多模型路由实战
LiteLLM Proxy 模式真正强大的地方,是用同一份 YAML 完成"语义模型名 → 实际渠道"的映射。下面给出一个生产可用的最小路由配置。
# litellm_config.yaml - 生产路由示例
model_list:
# 主力推理模型
- model_name: smart
litellm_params:
model: openai/gpt-5
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
timeout: 60
- model_name: smart
litellm_params:
model: openai/claude-opus-4-6
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
timeout: 60
# 廉价快速模型
- model_name: fast
litellm_params:
model: openai/gpt-5-mini
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
# 视觉/多模态
- model_name: vision
litellm_params:
model: openai/gemini-3-pro
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
# Embedding
- model_name: embed
litellm_params:
model: openai/text-embedding-3-large
api_base: https://api.apiyi.com/v1
api_key: os.environ/APIYI_KEY
litellm_settings:
drop_params: true
num_retries: 2
request_timeout: 60
router_settings:
routing_strategy: simple-shuffle # 同名模型轮询
fallbacks:
- smart: ["fast"] # smart 失败时降级到 fast
general_settings:
master_key: sk-litellm-master-xxxx # 客户端必须携带此 Key
应用层只看到 smart / fast / vision / embed 四个语义化名字。当 GPT-5 限流时,LiteLLM 会自动切换到 Claude Opus 4.6(因为它们都注册为 smart),再失败时降级到 fast。所有底层流量都经过 API易 apiyi.com 统一计费和监控,完美隔离上层与渠道层。
LiteLLM 配置第三方中转站 常见问题
Q1: 为什么我配了 base_url 还是报 404 Not Found?
90% 的情况是 api_base 结尾少了 /v1。LiteLLM 内部用的是 OpenAI 客户端,它会自动拼接 /chat/completions,所以你的 api_base 必须是 https://api.apiyi.com/v1 而不是 https://api.apiyi.com。也不要写成 https://api.apiyi.com/v1/chat/completions,那样会被拼成两次。
Q2: 为什么必须给模型加 openai/ 前缀?
LiteLLM 内部维护了一张 provider 路由表。openai/ 前缀告诉 LiteLLM "请用 OpenAI 客户端去访问这个端点"。如果不加前缀,LiteLLM 可能会尝试匹配它内置的 provider(比如 claude-opus-4-6 会被识别成 Anthropic 原生 API),从而走错协议。接中转站时,永远加 openai/ 前缀。
Q3: 一个 API易 Key 能否同时调用多个模型?
可以。API易 apiyi.com 的单个 Key 默认就支持平台所有可用模型,包括 GPT-5、Claude Opus 4.6、Gemini 3 Pro、DeepSeek、Qwen 等。这正是它和官方 API 的核心区别 —— 你只需要维护一个 Key 和一个 base_url,就能在 LiteLLM YAML 里挂载几十个模型。
Q4: LiteLLM Proxy 启动后,如何确认中转链路是通的?
最快的方式是用 curl 直接打 LiteLLM Proxy:
curl http://localhost:4000/v1/chat/completions \
-H "Authorization: Bearer sk-litellm-master-xxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "smart",
"messages": [{"role": "user", "content": "ping"}]
}'
返回 200 + JSON 即说明 应用 → LiteLLM Proxy → API易 整条链路通畅。如果失败,先看 LiteLLM 控制台日志,再用相同的 base_url + key 直接打 API易,二分定位问题层。
Q5: 流式输出 (stream) 在中转场景下需要额外配置吗?
不需要。API易 apiyi.com 完整支持 SSE 流式响应,LiteLLM 默认透传。你只要在 completion() 调用时加 stream=True,或者在 OpenAI SDK 调用 Proxy 时加 stream=True,就能拿到逐 token 的输出。
Q6: 能否同时把 Embedding 和图片生成也接上?
可以。API易 apiyi.com 同时支持 /v1/embeddings、/v1/images/generations、/v1/audio/transcriptions,全部走同一个 base_url 和 Key。在 LiteLLM YAML 里只需要把对应模型加到 model_list 即可,例如 text-embedding-3-large、gpt-image-1、whisper-1,使用方式与对话模型完全一致,详见上一节的生产路由示例。
总结
LiteLLM 配置第三方中转站,本质上只是三件事:
- 协议对齐: 给 model 加
openai/前缀,告诉 LiteLLM 走 OpenAI 客户端协议 - 入口对齐:
api_base指向中转站根路径 +/v1,例如https://api.apiyi.com/v1 - 凭证对齐: 把中转站颁发的 Key 通过
api_key或环境变量传入
完成这三步,LiteLLM 的所有功能(多模型路由、Fallback、限速、计费、Logging)都可以无缝叠加在一个稳定的中转站之上。
🚀 行动建议: 如果你正在为团队搭建一套统一的 LLM 网关,我们建议采用「应用 → LiteLLM Proxy → API易 apiyi.com」的三层架构。LiteLLM 负责路由与 Fallback,API易 负责底层模型接入、稳定性和按量计费,你只需要管一个 YAML 和一个 Key。在 apiyi.com 注册即可获取测试额度,5 分钟内完成首次调用。
作者: APIYI Team — 专注于为开发者提供主流 AI 大模型的稳定接入,访问 apiyi.com 了解更多。
参考资料
-
LiteLLM 官方文档 – OpenAI 兼容端点
- 链接:
docs.litellm.ai/docs/providers/openai_compatible - 说明: SDK 与 Proxy YAML 的官方示例
- 链接:
-
LiteLLM Proxy 配置总览
- 链接:
docs.litellm.ai/docs/proxy/configs - 说明: model_list、router_settings、fallbacks 完整字段
- 链接:
-
LiteLLM GitHub 仓库
- 链接:
github.com/BerriAI/litellm - 说明: 源码、Issue、最新版本
- 链接:
-
daily_stock_analysis – LLM_CONFIG_GUIDE
- 链接:
github.com/ZhuLinsen/daily_stock_analysis/blob/main/docs/LLM_CONFIG_GUIDE.md - 说明: 三种配置模式与多渠道实战参考
- 链接:
-
API易 官方文档
- 链接:
apiyi.com - 说明: 支持模型清单、base_url 与 Key 管理
- 链接: