最近一位开发者朋友在群里问:"gpt-image-2 能根据 CSV、Excel 文件生图吗?抖音上看到有人用 image 模型生成 PPT,想试试能不能读取文件信息。"答案是直接的:不能。OpenAI 在 2026 年 4 月发布的 gpt-image-2 只接受文本提示词和图片两种输入,既不读 CSV/Excel,也不输出 PPTX/PDF 文件。
但这并不意味着这条路走不通。把文件内容提取成文字、把文件页面截图成图片、再交给 gpt-image-2 生图,正是当前主流的工作流做法。本文把 gpt-image-2 文件上传相关的能力边界和 5 个绕过方案讲清楚,帮你把客户原本以为做不到的需求落地。

gpt-image-2 文件上传支持现状:输入只接受文本与图片
先把官方边界讲清,后面所有方案都是建立在这条边界之上的。根据 OpenAI 开发者文档,gpt-image-2(快照 gpt-image-2-2026-04-21)是一个原生多模态图像生成模型,模态支持表明确列出了输入输出范围。
| 模态类型 | 是否支持输入 | 是否支持输出 | 说明 |
|---|---|---|---|
| 文本 (text) | ✅ 支持 | ❌ 不支持 | 用作提示词,可包含中文、日文等多语言 |
| 图片 (image) | ✅ 支持 | ✅ 支持 | 输入用于编辑/参考,输出 PNG/JPEG/WebP |
| 音频 (audio) | ❌ 不支持 | ❌ 不支持 | 与图像生成不相关 |
| 视频 (video) | ❌ 不支持 | ❌ 不支持 | 与图像生成不相关 |
| 文档 (CSV/Excel/PDF/Word/PPT) | ❌ 不支持 | ❌ 不支持 | 不能直接上传,也不能输出为文件 |
简单说,gpt-image-2 不是 GPT-4 那种"通用大脑",它专精于图像生成与编辑,所以 OpenAI 没有给它做 CSV/Excel/PDF 的解析通道。你把 Excel 二进制塞过去,API 直接返回 400 错误。如果你的项目需要稳定且高 RPM 的 gpt-image-2 调用通道,我们建议通过 API易 apiyi.com 这类聚合中转平台进行接入,该平台已经把模型的输入校验和参数限制做了文档化,新手不容易踩坑。
🎯 核心认知: gpt-image-2 的能力边界是「文本 + 图片 → 图片」,不要把它当成全能 Agent。文件相关的需求要在外层用别的工具补齐,中转层(如 API易 apiyi.com)负责保证调用稳定,业务层负责数据预处理。
为什么客户问的"PPT 生成"和"文件生图"是两回事
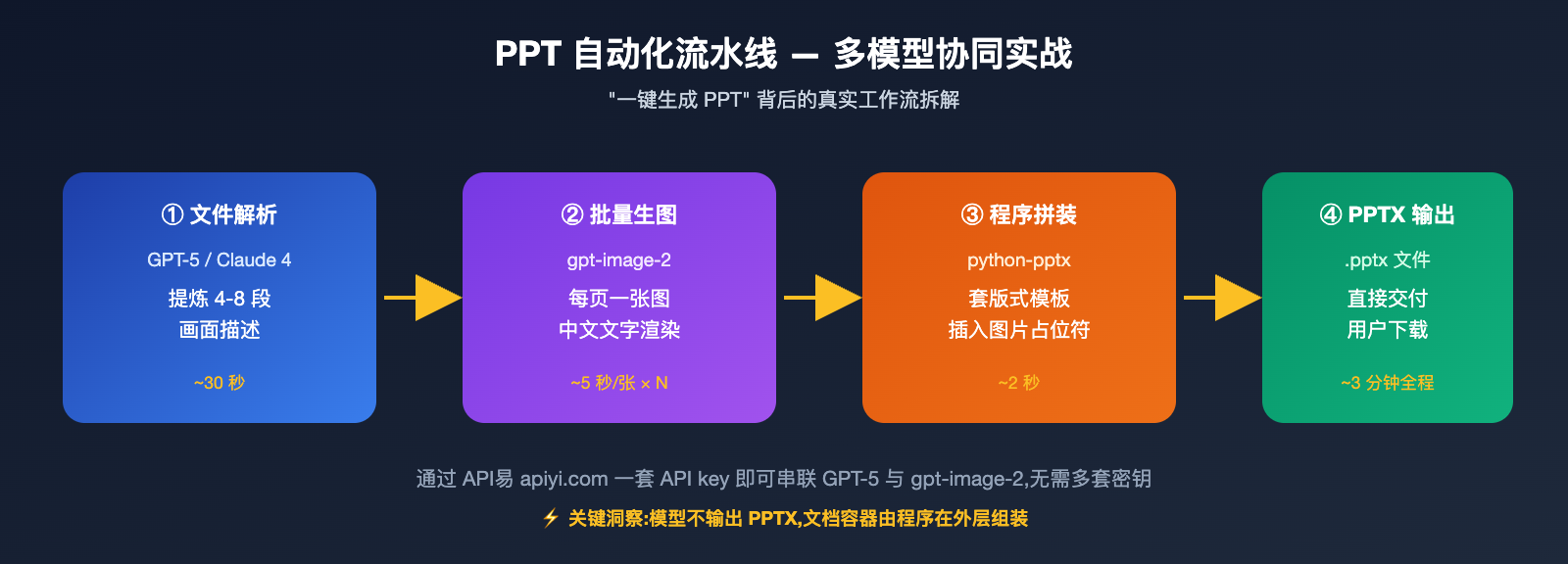
很多客户把"AI 一键生成 PPT"和"模型读文件生图"混在一起,其实是两个完全不同的工作流。从抖音、小红书上看到的 PPT 自动化案例,几乎都是多步流水线:先用大语言模型把数据提炼成文案,再用图像模型生成每一页插图,最后用程序拼装成 PPTX。
中间负责生图的那一环,通常就是 gpt-image-2 这种模型。它只看自己接到的那条文字 prompt 和参考图,根本不知道源头是 Excel 还是 Notion。这一点理解清楚之后,后面 5 个方案就顺理成章。
与上一代 gpt-image-1 相比有哪些升级
很多老用户会问:既然都不能传文件,gpt-image-2 比 gpt-image-1 强在哪。差别其实非常关键,直接决定了"截图作图输入"这条路能不能跑通。新版本在文字渲染、参考图数量、推理能力上都有量级提升。
| 能力维度 | gpt-image-1 | gpt-image-2 |
|---|---|---|
| 最多参考图数量 | 4 张 | 16 张(实测建议 ≤4 张效果最佳) |
| 文字渲染 | 英文较好,中日韩易出错 | 中、日、韩、印地、孟加拉多语言准确度大幅提升 |
| 推理能力 | 无 | 内置 thinking 模式,可处理复杂版面 |
| 知识截止 | 2024 年早期 | 2025 年 12 月 |
| 输出分辨率 | 最大 1024×1024 | 最大 3840×2160(4K) |
也就是说,如果你之前用 gpt-image-1 处理"截图改风格"效果不理想,现在用 gpt-image-2 重新跑一遍是值得的,尤其在中文海报、PPT 内页这类需要精确文字渲染的场景。
5 个工作流方案让 gpt-image-2 文件内容也能生图
下面这 5 个方案对应不同的数据源和落地场景,选择哪一个取决于文件类型、输出形态和自动化深度。我们按从轻量到重型的顺序排列。
方案一:文件转文本提示词,直接喂给 gpt-image-2
适用于 CSV、Excel、JSON、纯文本等结构化数据。流程是先用脚本(pandas、openpyxl)读取文件,把表头、关键行、统计指标拼成一段自然语言描述,再作为 prompt 调用 /v1/images/generations。比如把销售数据表汇总为"2026 年 Q1 三大区域销售额柱状图,华东 1200 万、华北 980 万、华南 760 万,深色商务风格"。
这种方法的好处是简单直接,不需要图片输入。缺点是 prompt 里能塞的信息有限,gpt-image-2 在数字精确还原方面做得好但不完美,需要在提示词中明确写出每一根柱子的数值,否则模型会按视觉合理性重新分配高度。
方案二:文件页面截图,作为参考图输入
适用于 PDF、PPT 既有版面、网页报表等"已经长成图的内容"。把目标页转换成 PNG(可用 macOS 预览、pdftoppm、Puppeteer 等工具),然后通过 /v1/images/edits 端点上传作为 image 参数,搭配 prompt 描述要做的修改,例如"保留布局,把英文标题改成中文,把柱状图改成苹果风格"。
gpt-image-2 在 2026 年的版本里最多接受 16 张参考图,但官方和社区实测都建议主参考图 1 张 + 风格参考图 1–2 张,加多了模型注意力会被稀释。每张图建议控制在 1.5MB 以内,否则 input token 消耗会显著上涨。
方案三:数据先做可视化,再交给 gpt-image-2 美化
适用于追求"既准确又好看"的数据可视化场景。先用 matplotlib、ECharts、Excel 自带图表把数据画出基础版,导出 PNG;然后把这张基础图作为 gpt-image-2 的输入图,prompt 写成"保持数据点位置和数值不变,把图表风格改成深色、霓虹高亮、信息图风格"。
这是目前数据图表 + AI 美化最稳的做法。原始数值由确定性的画图库保证,视觉风格由 gpt-image-2 重塑,两边各做自己擅长的事。如果你要批量跑这个流程,推荐通过 API易 apiyi.com 调用 gpt-image-2,它对 5000 RPM 的高并发场景做了上游账号池调度,适合每天几千上万张图的任务。

方案四:LLM + gpt-image-2 双模型流水线
适用于内容复杂、需要语义理解的文件,比如长报告、合同摘要、产品文案。先用 GPT-4 系列或 Claude 4 把文件读懂、提炼出 4-8 段画面描述,再循环调用 gpt-image-2 生成对应张数的图。
这一步的关键是把"语义理解"和"图像生成"解耦。LLM 负责说"这一页应该画什么",gpt-image-2 负责"按这条 prompt 把图画出来"。整个流水线在 API易 apiyi.com 上可以用同一个 API key 串通,省去了切换 SDK 和密钥管理的麻烦。
方案五:批量生图后程序化合成 PPT/海报
这就是抖音上那些"一键 PPT"案例的真相。模型本身不会输出 PPTX 文件,但可以生成每一页的图,再用 Python 的 python-pptx 或前端的 PptxGenJS 把图片塞到 PPT 模板的对应位置。
简单一句话:PPT 本质是多张图组成的演示文档,gpt-image-2 解决"图"的问题,python-pptx 解决"文档容器"的问题。一个常见的拆解是:封面用 4K 高质量图、内页用 1536×1024 中等质量图、目录页和过渡页用低质量草图,通过 quality 参数差异化控制成本。一份 20 页的 PPT 大约需要 20-30 次模型调用,在 5000 RPM 的中转通道上,几分钟就能跑完。
| 方案 | 适用文件类型 | 工程量 | 输出质量 | 推荐场景 |
|---|---|---|---|---|
| 方案一 文件转文本 | CSV/Excel/JSON | 低 | 中 | 简单图表、风格化插图 |
| 方案二 页面截图作图输入 | PDF/PPT/网页 | 低 | 中高 | 版面改写、风格迁移 |
| 方案三 可视化预渲染 | CSV/Excel | 中 | 高 | 数据图表美化 |
| 方案四 LLM+gpt-image-2 | 长报告/文案 | 中高 | 高 | 内容卡片、教程图 |
| 方案五 批量合成 PPT | 任意 | 高 | 高 | 演示文档自动化 |
API 调用代码示例:文件内容如何变成 gpt-image-2 的输入
把概念落到代码层面看就更直观了。下面是一个最小可运行的 Python 示例,把 Excel 表格转成文本 prompt,然后调用 gpt-image-2 生成对应的可视化图。我们以 API易 apiyi.com 作为统一中转入口,只需要替换 base_url 即可,SDK 的其他写法和官方完全一致。
from openai import OpenAI
import pandas as pd
import base64
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
df = pd.read_excel("sales_q1.xlsx")
summary = df.groupby("region")["sales"].sum().to_dict()
prompt_text = (
f"绘制 2026 年 Q1 区域销售额柱状图,"
f"数据为:{summary}, "
f"深色商务风格,纯白标题,数据标签清晰可见。"
)
resp = client.images.generate(
model="gpt-image-2",
prompt=prompt_text,
size="1536x1024",
quality="high"
)
img_b64 = resp.data[0].b64_json
with open("sales_chart.png", "wb") as f:
f.write(base64.b64decode(img_b64))
代码思路很清楚:业务层把 Excel 解析成文字描述,模型层只接收文字。如果是图生图(方案二),把 client.images.generate 换成 client.images.edit,并通过 image=open("page.png", "rb") 传入图片即可。
| 参数 | 取值范围 | 说明 |
|---|---|---|
model |
gpt-image-2 / gpt-image-2-mini |
mini 版本速度更快、价格更低 |
size |
1024×1024 / 1536×1024 / 1024×1536 / 自定义 | 最长边 ≤ 3840px,边长需被 16 整除 |
quality |
low / medium / high / auto | 高质量耗时更长,token 消耗更高 |
n |
1–4 | 单次生成图数,批量推荐外层循环 |
response_format |
png(默认)/ jpeg / webp | gpt-image-2 不支持 PDF/PPTX 输出 |
🎯 代码层建议: 想要快速跑通这个流程,我们推荐先在 API易 apiyi.com 注册一个账号,把
base_url切到https://api.apiyi.com/v1就能用统一接口同时调 gpt-image-2、GPT-5 和 Claude 4 系列,免去一次次接入不同厂商的烦恼。

客户最常踩的 4 个坑和绕开方法
把 5 个方案理解清楚之后,真正落地时还会遇到一些细节坑。我们整理了客服群里被问到最多的 4 类问题。
坑一:把 base64 编码的 CSV 塞进 prompt
有同学想了个"聪明办法":把 CSV 文件读成 base64 字符串塞进 prompt,以为模型会自己解码。这条路完全不通,gpt-image-2 不会执行代码,也不会把字符串当成数据,它只会把 base64 字符串当成无意义的字符,渲染出一堆乱码。正确做法是在业务层把 CSV 解析为文字描述,见方案一。
坑二:期望 gpt-image-2 把表格"画得和 Excel 一模一样"
模型擅长视觉一致和风格化,但像素级还原是另一回事。如果你要严格的表格,推荐组合策略:用 ECharts/matplotlib 画准确版本(方案三),再让 gpt-image-2 美化外观。指望一句 prompt 让模型把 100 行数据精确画出来,目前还做不到。
坑三:输出文件想要 SVG 或 PDF 矢量格式
gpt-image-2 输出格式只有 PNG、JPEG、WebP 三种位图格式,没有 SVG、PDF、AI 等矢量格式。需要矢量图请用 Stable Diffusion 配合 vectorizer.ai,或直接让 GPT-5 生成 SVG 代码。选模型前先确认输出格式,可以避免事后返工。
坑四:同一参考图反复传,token 消耗暴涨
gpt-image-2 对每张输入图都按高保真度处理,即使你的提示词只是微调,每次请求都会重新计算 input token。建议在客户端做参考图缓存,或者直接使用 previous_response_id 做对话式编辑(Responses API),复用上一次的图像上下文。
另外要注意的一个细节是:即使你输出的目标只是 256×256 的缩略图,只要参考图是 4K 大图,input token 还是按 4K 计费。先在本地把参考图压缩到 1024 长边再上传,可以节省 60% 以上的 input token,这是大批量任务里最容易被忽视的成本控制点。
| 错误现象 | 根因 | 推荐解决方法 |
|---|---|---|
| 400 invalid_request_error | 上传了非图片二进制(CSV/Excel) | 在外层把文件转文本或截图 |
| 字符渲染成乱码 | base64 字符串当 prompt 用 | 改用解析后的自然语言描述 |
| 表格数据不准确 | 用 prompt 画精确表格 | 改用方案三可视化预渲染 |
| 想要 SVG 输出 | 模型不支持矢量格式 | 改用 GPT-5 生成 SVG 代码 |
| token 消耗超预期 | 大尺寸参考图重复传 | 压缩到 1.5MB 以内,启用缓存 |
常见问题 FAQ
Q1: gpt-image-2 真的完全不能上传 PDF 吗?
不能直接上传 PDF。但可以用 pdftoppm 把每页转成 PNG,再以图片形式输入。如果需要"理解 PDF 内容再生图",建议先用 GPT-5 读 PDF 提炼描述,再把描述喂给 gpt-image-2。这个组合在 API易 apiyi.com 上一个 API key 就能跑通。
Q2: 文件中含敏感数据,直接送进模型安全吗?
文件转文本环节在你自己的服务器上完成,只有最终的提示词文字会发给模型,你可以在转文本时做脱敏。如果走中转,API易 apiyi.com 的接口明确不存储用户 prompt 和返回内容,合规方面比直接走外网代理更可控。
Q3: 抖音上"一键生成 PPT"工具用的是 gpt-image-2 吗?
部分用,部分不用。逻辑通常是:LLM 写文案 → 图像模型(gpt-image-2 / Nano Banana Pro / Flux)做插图 → 后端用 python-pptx 拼装。gpt-image-2 在文字渲染特别是中文渲染上做得最好,适合做 PPT 内页插图。
Q4: 为什么有人说能上传 Excel?
那是把 Excel 截图当图片传进去了,本质上还是图片输入,不是模型读懂了 Excel 结构。如果你看到截图里数字模糊,模型也只能照着模糊的样子重画。
Q5: gpt-image-2 和 gpt-image-2-mini 选哪个?
mini 版速度快、价格低,适合大批量草稿和缩略图;正式发布物料用标准版。两个版本的输入限制完全一样(都不支持文档文件),只需切换 model 参数中的模型 ID,SDK 写法不用改。
总结
gpt-image-2 不支持 CSV/Excel/PPT 文件直接上传,也不输出 PPTX/PDF 文件,这是模型的能力边界,而不是接入参数没找对。理解这条边界之后,把文件内容做一次预处理——转文本、转截图或先可视化再美化——就能让它服务于绝大多数"看起来需要文件输入"的需求。抖音上看到的一键 PPT、Excel 转海报、PDF 改风格,本质都是这种多步流水线的工程组合,只是把模型推理与数据加工的分工讲清楚,需求就能落地。
落地时的核心心法只有一句:模型层只做模型擅长的事,数据层在外面提前消化好。如果你想跑通完整的流水线,我们推荐在 API易 apiyi.com 上同时接入 GPT-5(负责文本理解)和 gpt-image-2(负责图像生成),一套 API key 走完全流程,5000 RPM 的高并发能力也能让批量任务跑得顺畅,无需为不同模型反复维护多套密钥和 SDK。
关于作者: APIYI 团队专注于多模型聚合接入和高并发推理基础设施,日常处理大量图像生成 API 调用咨询。本文基于 OpenAI 官方文档与真实客户咨询整理,如需了解 gpt-image-2 接入方案,欢迎访问 API易 apiyi.com。