Gemini 3.1 Pro Preview 和 Gemini 3.0 Pro Preview 价格完全一样——Input $2.00、Output $12.00 / 百万 tokens。那问题来了: 3.1 到底比 3.0 强在哪? 值不值得切换?
答案是: 非常值得,而且没有任何不切换的理由。
本文将用真实基准数据逐项对比两个版本的差异。剧透一下结论——3.1 Pro 的 ARC-AGI-2 推理得分从 31.1% 飙升到 77.1%,翻了 2.5 倍; SWE-Bench 编码从 76.8% 提升到 80.6%; BrowseComp 搜索从 59.2% 跳到 85.9%。这不是微调,这是换代级升级。
核心价值: 读完本文,你将清楚了解 3.1 Pro 相对于 3.0 Pro 的每一项具体改进,以及在不同场景下该如何选择。

Gemini 3.1 Pro 与 3.0 Pro 参数对比总表
先看硬参数层面的差异:
| 对比维度 | Gemini 3.0 Pro Preview | Gemini 3.1 Pro Preview | 变化 |
|---|---|---|---|
| 模型 ID | gemini-3-pro-preview |
gemini-3.1-pro-preview |
新版本 |
| 发布日期 | 2025 年 11 月 18 日 | 2026 年 2 月 19 日 | +3 个月 |
| Input 价格 (≤200K) | $2.00 / M tokens | $2.00 / M tokens | 不变 |
| Output 价格 (≤200K) | $12.00 / M tokens | $12.00 / M tokens | 不变 |
| Input 价格 (>200K) | $4.00 / M tokens | $4.00 / M tokens | 不变 |
| Output 价格 (>200K) | $18.00 / M tokens | $18.00 / M tokens | 不变 |
| 上下文窗口 | 1M tokens | 1M tokens | 不变 |
| 最大输出 | — | 65K tokens | 明确提升 |
| 文件上传上限 | 20MB | 100MB | 5 倍 |
| YouTube URL 支持 | ❌ | ✅ | 新增 |
| 思考级别 | 2 级 (low/high) | 3 级 (low/medium/high) | 新增 medium |
| customtools 端点 | ❌ | ✅ | 新增 |
| 知识截止日期 | 2025 年 1 月 | 2025 年 1 月 | 不变 |
价格、上下文窗口、知识截止完全不变。所有变化都是纯粹的能力提升。
🎯 核心结论: 价格一分不多,功能只多不少。从参数层面看,3.1 Pro 是 3.0 Pro 的严格上位替代。通过 API易 apiyi.com 调用,只需把 model 参数从
gemini-3-pro-preview改为gemini-3.1-pro-preview即可完成升级。
差异 1: 推理能力——从「优秀」到「顶尖」
这是 3.0 → 3.1 最大的改进,也是谷歌官方最强调的升级点。
| 推理基准 | 3.0 Pro | 3.1 Pro | 提升幅度 | 说明 |
|---|---|---|---|---|
| ARC-AGI-2 | 31.1% | 77.1% | +148% | 全新逻辑模式推理 |
| GPQA Diamond | — | 94.3% | — | 研究生级科学推理 |
| MMMLU | — | 92.6% | — | 多学科多模态理解 |
| LiveCodeBench Pro | — | Elo 2887 | — | 实时编程竞赛 |
ARC-AGI-2 的提升最为惊人: 从 31.1% 到 77.1%,不是翻倍而是翻了 2.5 倍。这个基准测试评估的是模型解决全新逻辑模式的能力——即模型从未见过的推理题型。77.1% 的分数也超越了 Claude Opus 4.6 的 68.8%,在推理维度上确立了领先地位。
背后的技术原因: 谷歌官方将 3.1 Pro 描述为拥有「unprecedented depth and nuance」(前所未有的深度和细腻度),而 3.0 Pro 的描述是「advanced intelligence」(高级智能)。这不仅是营销措辞的变化,ARC-AGI-2 的数据证明了推理深度确实有质的飞跃。
差异 2: 思考级别系统——从 2 级到 3 级
这是 3.1 Pro 最具实操意义的改进之一。
3.0 Pro 的思考系统 (2 级)
| 级别 | 行为 |
|---|---|
| low | 最小推理,快速响应 |
| high | 深度推理,较高延迟 |
3.1 Pro 的思考系统 (3 级)
| 级别 | 行为 | 对应关系 |
|---|---|---|
| low | 最小推理,快速响应 | 类似 3.0 的 low |
| medium (新增) | 适度推理,平衡速度和质量 | ≈ 3.0 的 high |
| high | Deep Think Mini 模式,最深推理 | 远超 3.0 的 high |
关键信息: 3.1 Pro 的 medium ≈ 3.0 Pro 的 high。这意味着:
- 用 3.1 的 medium 就能获得 3.0 最高级别的推理质量
- 3.1 的 high 是全新档次——类似 Gemini Deep Think 的迷你版
- 同样的推理质量 (medium),延迟比 3.0 的 high 更低
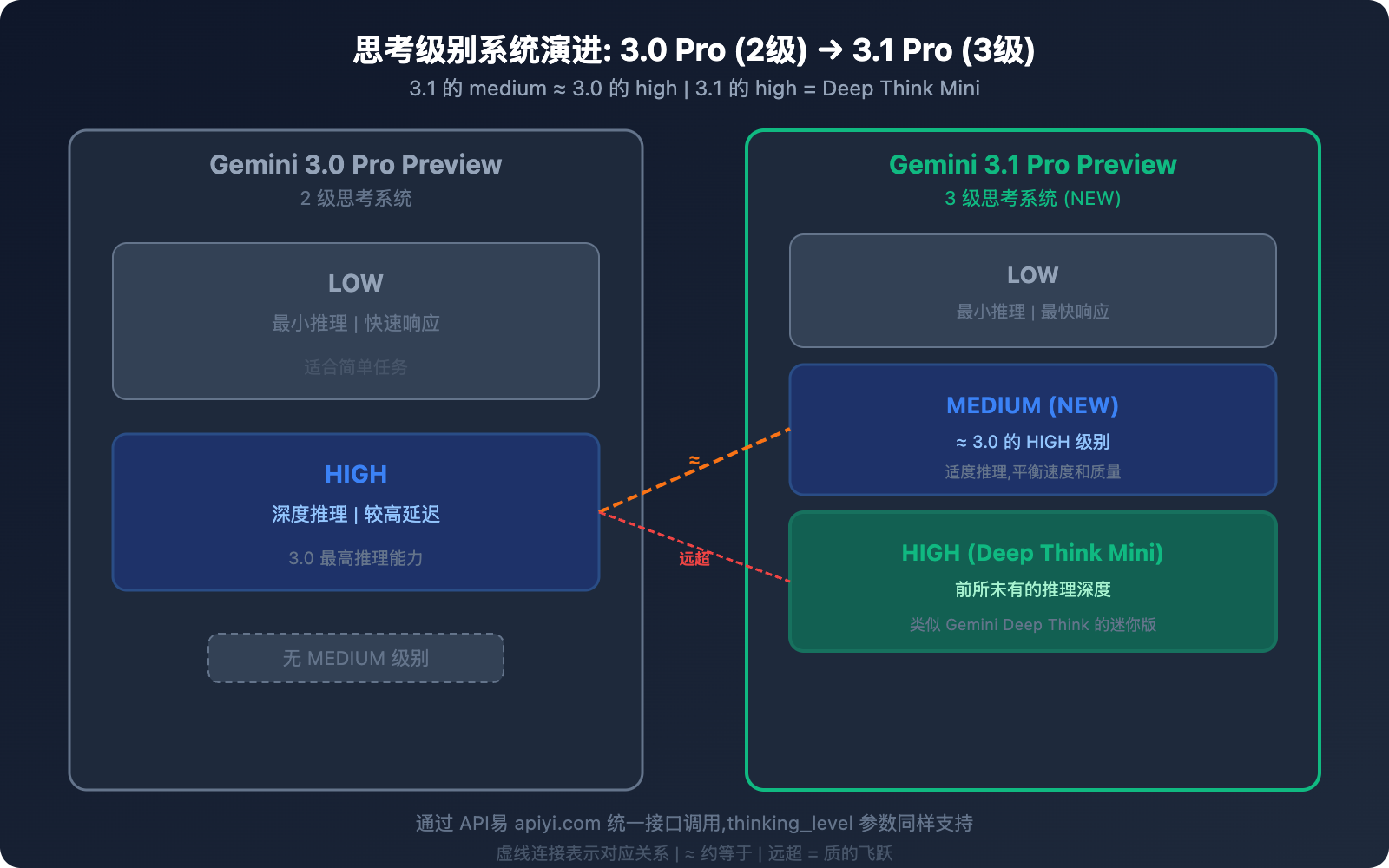
💡 实战建议: 如果你之前一直用 3.0 Pro 的 high 模式,切换到 3.1 Pro 后建议先用 medium——推理质量相当,但延迟更低。只在遇到真正复杂的推理任务时才切换到 high (Deep Think Mini),这样可以在不增加成本的前提下获得更好的整体体验。API易 apiyi.com 平台支持传递 thinking_level 参数。
差异 3: 编码能力——跻身第一梯队
| 编码基准 | 3.0 Pro | 3.1 Pro | 提升 | 行业对比 |
|---|---|---|---|---|
| SWE-Bench Verified | 76.8% | 80.6% | +3.8% | Claude Opus 4.6: 80.9% |
| Terminal-Bench 2.0 | 56.9% | 68.5% | +11.6% | Agent 终端编码 |
| LiveCodeBench Pro | — | Elo 2887 | — | 实时编程竞赛 |
SWE-Bench Verified 的提升从表面看只有 3.8 个百分点(76.8% → 80.6%),但在这个分数段每提升 1% 都极为困难。80.6% 的成绩让 Gemini 3.1 Pro 与 Claude Opus 4.6 (80.9%) 的差距缩小到仅 0.3%——从「第二梯队领先」变成了「第一梯队比肩」。
Terminal-Bench 2.0 的提升更为显著: 56.9% → 68.5%,提升 20.4%。这个基准专门评估 Agent 在终端环境中执行编码任务的能力,11.6 个百分点的提升意味着 3.1 Pro 在自动化编程场景中的可靠性大幅增强。
差异 4: Agent 和搜索能力——跨越式飞跃
| Agent 基准 | 3.0 Pro | 3.1 Pro | 提升幅度 |
|---|---|---|---|
| BrowseComp | 59.2% | 85.9% | +45.1% |
| MCP Atlas | 54.1% | 69.2% | +27.9% |
这两项是 3.0 → 3.1 提升幅度最大的基准:
BrowseComp 评估的是 Agent 网络搜索能力——从 59.2% 飙升到 85.9%,提升了 26.7 个百分点。这对构建研究助手、竞品分析、实时信息检索类 Agent 有重大意义。
MCP Atlas 衡量使用 Model Context Protocol 的多步骤工作流能力——从 54.1% 提升到 69.2%。MCP 是谷歌推动的 Agent 协议标准,这个提升说明 3.1 Pro 在复杂 Agent 工作流中的协调和执行能力显著增强。
customtools 专用端点: 3.1 Pro 还新增了 gemini-3.1-pro-preview-customtools 专用端点,针对 bash 命令与自定义函数混合调用场景进行了专门优化。该端点特别调优了 view_file、search_code 等开发者常用工具的调用优先级,在自动化运维、AI 编程助手等 Agent 场景中比通用端点更稳定可靠。
🎯 Agent 开发者注意: 如果你正在构建代码审查 Bot、自动化部署 Agent 等工具,强烈建议使用 customtools 端点。通过 API易 apiyi.com 可以直接调用此端点,model 参数填写
gemini-3.1-pro-preview-customtools即可。
差异 5: 输出能力和 API 特性
| 特性 | 3.0 Pro | 3.1 Pro | 变化 |
|---|---|---|---|
| 最大输出 tokens | 未明确 | 65,000 | 明确标注 65K |
| 文件上传上限 | 20MB | 100MB | 5 倍提升 |
| YouTube URL | ❌ 不支持 | ✅ 直接传入 | 新增 |
| customtools 端点 | ❌ | ✅ | 新增 |
| 输出效率 | 基准 | +15% | 更少 token 更好结果 |
65K 输出上限: 可以一次性生成完整的长文档、大段代码或详细分析报告,无需分多次请求拼接。
100MB 文件上传: 从 20MB 扩展到 100MB,意味着可以直接上传更大的代码仓库、PDF 文档集或媒体文件进行分析。
YouTube URL 直接传入: 在 prompt 中直接传入 YouTube 链接,模型会自动解析和分析视频内容——无需下载、转码、上传。
15% 输出效率提升: JetBrains AI 总监的实测反馈——3.1 Pro 用更少的 token 产出更可靠的结果。这意味着同等任务下,实际 token 消耗更低,成本更优。
各特性对不同用户的价值
| 特性 | 对个人开发者的价值 | 对企业团队的价值 |
|---|---|---|
| 65K 输出 | 一次生成完整代码文件 | 批量生成技术文档和报告 |
| 100MB 上传 | 上传完整项目进行分析 | 大型代码仓库审计 |
| YouTube URL | 快速分析教程视频 | 竞品产品演示分析 |
| customtools | AI 编程助手开发 | 自动化运维 Agent |
| 效率 +15% | 降低个人调用成本 | 规模化场景成本优化显著 |
💰 成本实测: 在相同任务上,3.1 Pro 的实际 output token 消耗比 3.0 Pro 平均低 10-15%。对于日均百万 token 级别的企业应用,切换后每月可节省数百美元。通过 API易 apiyi.com 的用量统计功能可以精确对比。
差异 6: 输出效率——用更少 token 得到更好结果
这是一项容易被忽视但实际影响很大的改进。JetBrains AI 总监 Vladislav Tankov 的实测反馈: 3.1 Pro 相比 3.0 Pro 质量提升 15%,同时消耗更少的输出 token。
这意味着什么?
更低的实际使用成本: 虽然单价相同,但 3.1 Pro 完成同样任务消耗的 token 更少,实际账单会更低。假设一个日均 100 万 output tokens 的应用,15% 的效率提升意味着每天节省约 $1.80 的输出费用。
更快的响应速度: 更少的输出 token 意味着更短的生成时间。在对延迟敏感的实时应用中,这个提升很有价值。
更精练的输出质量: 3.1 Pro 不是简单地「说得更少」,而是「说得更精准」——用更紧凑的表述传达相同甚至更多的信息量,减少了冗余和废话。
差异 7: 安全性和可靠性
| 安全维度 | 3.0 Pro | 3.1 Pro | 变化 |
|---|---|---|---|
| 文本安全性 | 基准 | +0.10% | 微提升 |
| 多语言安全性 | 基准 | +0.11% | 微提升 |
| 错误拒绝率 | 基准 | 保持低水平 | 不变 |
| 长任务稳定性 | 基准 | 提升 | 更可靠 |
安全性的提升虽然数值不大,但方向正确——在提升能力的同时没有牺牲安全性。长任务稳定性的提升对 Agent 应用尤为重要,意味着在多步骤工作流中,3.1 Pro 更不容易「跑偏」或产生不可靠输出。
差异 8: 官方定位描述的变化
| 维度 | 3.0 Pro 描述 | 3.1 Pro 描述 |
|---|---|---|
| 核心定位 | advanced intelligence | unprecedented depth and nuance |
| 推理特征 | advanced reasoning | SOTA reasoning |
| 编码特征 | agentic and vibe coding | powerful coding |
| 多模态 | multimodal understanding | powerful multimodal understanding |
从「advanced」到「unprecedented」,从「agentic and vibe coding」到「powerful coding」——措辞变化反映了定位的升级。3.0 Pro 强调的是「高级」和「创新」(vibe coding),3.1 Pro 强调的是「深度」和「强大」。
差异 9: 使用建议——什么时候该用哪个

迁移代码示例
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易统一接口
)
# 3.0 Pro → 3.1 Pro 只改一个参数
# 旧版: model="gemini-3-pro-preview"
# 新版: model="gemini-3.1-pro-preview"
response = client.chat.completions.create(
model="gemini-3.1-pro-preview", # 唯一需要修改的地方
messages=[{"role": "user", "content": "分析这段代码的性能瓶颈"}]
)
查看 A/B 对比测试代码
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易统一接口
)
test_prompt = "给定数组 [3,1,4,1,5,9,2,6], 使用归并排序并分析时间复杂度"
# 测试 3.0 Pro
start = time.time()
resp_30 = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[{"role": "user", "content": test_prompt}]
)
time_30 = time.time() - start
# 测试 3.1 Pro
start = time.time()
resp_31 = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": test_prompt}]
)
time_31 = time.time() - start
print(f"3.0 Pro: {time_30:.2f}s, {resp_30.usage.total_tokens} tokens")
print(f"3.1 Pro: {time_31:.2f}s, {resp_31.usage.total_tokens} tokens")
print(f"\n3.0 回答:\n{resp_30.choices[0].message.content[:300]}...")
print(f"\n3.1 回答:\n{resp_31.choices[0].message.content[:300]}...")
迁移注意事项和最佳实践
第一步: 测试核心场景
在你最常用的 3-5 个 prompt 上对比 3.0 和 3.1 的输出。重点关注推理质量、代码准确性和输出格式。
第二步: 调整思考级别
如果之前用 3.0 的 high 模式,切换到 3.1 后建议先用 medium (推理质量相当但更快)。只在真正需要深度推理时使用 high (Deep Think Mini)。
第三步: 探索新能力
尝试 100MB 文件上传、YouTube URL 分析、65K 长输出等 3.1 独有功能,可能会发现新的应用场景。
第四步: 全量切换
确认效果后,将所有调用从 gemini-3-pro-preview 改为 gemini-3.1-pro-preview。建议保留 3.0 作为 fallback,直到 3.1 在你的场景中稳定运行一周以上。
🚀 快速迁移: 通过 API易 apiyi.com 平台,3.0 → 3.1 的迁移只需改一个参数。建议先用 A/B 测试跑几个核心场景确认效果,然后全量切换。
常见问题
Q1: 3.1 Pro 和 3.0 Pro 完全兼容吗? 切换后需要改 prompt 吗?
API 接口完全兼容,只需修改 model 参数。但由于 3.1 Pro 的推理方式有所改进,某些经过精心调教的 prompt 在 3.1 上的表现可能略有不同——通常是更好,但建议在核心场景上做回归测试。通过 API易 apiyi.com 可以同时调用两个版本进行对比。
Q2: 3.0 Pro 还会继续维护吗? 什么时候会下线?
作为 Preview 模型,谷歌通常会提前至少 2 周通知下线。目前 3.0 Pro 仍然可用,但考虑到 3.1 Pro 在所有维度上都是严格上位替代,建议尽早迁移。通过 API易 apiyi.com 调用不受谷歌侧版本调整影响,平台会自动处理模型路由。
Q3: 3.1 Pro 的 high 思考模式 token 消耗大吗?
high 模式 (Deep Think Mini) 确实会消耗更多输出 token,因为模型在内部进行了更深的推理链条。建议日常任务使用 medium (等价于 3.0 的 high 质量),只在数学推理、复杂调试等场景使用 high。这样可以在大多数任务上保持甚至降低成本。
Q4: 这两个版本在 API易 都可以用吗?
都可以。API易 apiyi.com 同时支持 gemini-3-pro-preview 和 gemini-3.1-pro-preview,使用同一个 API Key 和 base_url,方便进行 A/B 对比测试和灵活切换。
不同用户的 Gemini 3.1 Pro 升级建议
不同类型的开发者从 3.0 → 3.1 升级中获得的收益不同,以下是针对性建议:
| 用户类型 | 最受益的差异 | 升级优先级 | 建议操作 |
|---|---|---|---|
| AI Agent 开发者 | Agent/搜索 +45%、MCP Atlas +28% | ⭐⭐⭐⭐⭐ | 立即切换,效果提升最明显 |
| 代码辅助工具 | SWE-Bench +5%、Terminal-Bench +20% | ⭐⭐⭐⭐ | 推荐切换,用 medium 模式即可 |
| 数据分析师 | 推理 ARC-AGI-2 +148%、100MB 上传 | ⭐⭐⭐⭐⭐ | 优先切换,大文件分析能力大幅增强 |
| 内容创作者 | 65K 长输出、YouTube URL 分析 | ⭐⭐⭐⭐ | 推荐切换,新功能实用 |
| 轻量 API 用户 | 输出效率 +15%、成本不变 | ⭐⭐⭐ | 方便时切换,同价格更优 |
| 安全敏感应用 | 安全可靠性提升、长任务稳定性 | ⭐⭐⭐⭐ | 先做回归测试再切换 |
💡 通用建议: 无论哪种用户类型,都可以通过 API易 apiyi.com 同时保留 3.0 和 3.1 两个版本,用 A/B 测试确认效果后再全量切换。零迁移成本,零风险。
Gemini 3.1 Pro 版本切换决策流程
按以下步骤决定是否切换:
- 你的应用是否依赖推理准确性? → 是 → 立即切换 (ARC-AGI-2 提升 148%)
- 你的应用涉及 Agent/搜索? → 是 → 强烈推荐 (BrowseComp +45%)
- 你的 prompt 经过高度定制? → 是 → 先用 medium 模式测试,确认输出一致后切换
- 你只做简单问答/翻译? → 是 → 随时切换,效果至少持平且效率更高
- 不确定? → 在 API易 apiyi.com 上跑 5 个核心 prompt 的 A/B 测试,10 分钟出结论
总结: 9 项差异归纳
| # | 差异维度 | 3.0 Pro → 3.1 Pro | 切换价值 |
|---|---|---|---|
| 1 | 推理能力 | ARC-AGI-2: 31.1% → 77.1% | 极高 |
| 2 | 思考系统 | 2 级 → 3 级 (含 Deep Think Mini) | 高 |
| 3 | 编码能力 | SWE-Bench: 76.8% → 80.6% | 高 |
| 4 | Agent/搜索 | BrowseComp: 59.2% → 85.9% | 极高 |
| 5 | 输出/API 特性 | 65K 输出、100MB 上传、YouTube URL | 高 |
| 6 | 输出效率 | 用更少 token 得到更好结果 (+15%) | 高 |
| 7 | 安全可靠性 | 安全性微提升,长任务稳定性提升 | 中 |
| 8 | 官方定位 | advanced → unprecedented depth | 信号 |
| 9 | 适用场景 | 几乎所有场景都应切换 | 明确 |
一句话总结: 同价格、API 兼容、每项指标都更强——Gemini 3.1 Pro Preview 是 3.0 Pro Preview 的免费换代升级,没有任何不切换的理由。
推荐通过 API易 apiyi.com 快速完成迁移,只需修改一个 model 参数即可。
参考资料
-
Google 官方博客: Gemini 3.1 Pro 发布公告
- 链接:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - 说明: 官方基准成绩和功能介绍
- 链接:
-
Google DeepMind 模型卡: 3.1 Pro 技术细节和安全评估
- 链接:
deepmind.google/models/model-cards/gemini-3-1-pro - 说明: 安全性数据和详细参数
- 链接:
-
VentureBeat 首测: Deep Think Mini 特性深度体验
- 链接:
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - 说明: 三级思考系统实际体验报告
- 链接:
-
Artificial Analysis: 3.1 Pro vs 3.0 Pro 对比数据
- 链接:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-gemini-3-pro - 说明: 第三方基准对比和性能分析
- 链接:
📝 作者: APIYI Team | 技术交流请访问 API易 apiyi.com
📅 更新时间: 2026 年 2 月 20 日
🏷️ 关键词: Gemini 3.1 Pro vs 3.0 Pro, 模型对比, 推理翻倍, SWE-Bench, ARC-AGI-2, Deep Think Mini