一個值得開發者關注的更新~ 字節跳動 Dola 基礎模型家族在 2026 年 4 月 28 日上線了首款全模態(Omnimodal)理解模型 Seed-2.0-lite-260428,統一支持視頻、圖像、音頻與文本四種模態的原生輸入。這是 Dola Seed 家族中第一個能"既看得見又聽得見"的模型,並在 Agent、Coding、GUI 等任務上同步做了增強。本文基於 BytePlus ModelArk 官方規格與 ByteDance Seed 公開基準,結合 API易 apiyi.com 的接入實測,系統講解模型能力、音頻理解細節與典型應用場景。

一、Seed-2.0-lite-260428 是什麼:核心定位與升級要點
Seed-2.0-lite-260428 是 ByteDance Seed 在 2026 年 4 月 28 日發佈的一次重要迭代,基礎模型沿用了 3 月初發布的 Seed-2.0-Lite,但首次把"音頻輸入"作爲原生能力加入,從而把這條產品線推進到真正的"全模態(Omnimodal)"階段。模型名稱中的 260428 即對應 2026 年 4 月 28 日的版本號。
1.1 來自字節 Dola 家族的首個全模態模型
在此前的 Dola Seed 家族裏,文本與多模態能力是分別放在不同分支的。Seed-2.0-lite-260428 把視頻、圖像、音頻與文本統一在同一個模型裏推理,意味着它可以同時"看視頻畫面"和"聽音頻內容",並據此進行聯合判斷與時序檢索。這種統一架構對 Agent 類應用尤爲關鍵,因爲很多真實任務(例如視頻審覈、會議總結、客服質檢)天然需要跨模態推理。
1.2 模型的核心規格速覽
下表整理了 Seed-2.0-lite-260428 當前在 BytePlus ModelArk 上的核心參數,便於讀者快速判斷是否符合自家業務需求。
| 規格項 | 具體參數 |
|---|---|
| API 模型 ID | seed-2-0-lite-260428 |
| 模型家族 | ByteDance Seed / Dola |
| 發佈日期 | 2026-04-28 |
| 上下文窗口 | 262,144 tokens(約 256K) |
| 最大輸出 | 131,072 tokens(約 128K) |
| 輸入模態 | 文本 + 圖像 + 視頻 + 音頻 |
| 輸入價格 | $0.25 / M tokens |
| 輸出價格 | $2.00 / M tokens |
| 接口兼容 | OpenAI Compatible API |
二、Seed-2.0-lite-260428 的全模態理解 4 項關鍵能力
模型的全模態能力不是簡單地把多種輸入"接進來",而是通過統一表徵做聯合推理。官方文檔把它的核心能力概括爲四個方向。
2.1 音視頻聯合推理與時序檢索
模型可以同時分析視頻中的視覺與音頻信息,準確判斷"看到的畫面"與"聽到的聲音"是否一致。例如可以判斷一段視頻裏的人物表情是否與說話情緒相符,或者畫面中的物體動作是否對應了正確的音效。這種音視頻對齊能力,在視頻審覈、深度僞造檢測等場景下非常實用。
2.2 視頻深度分解與長時序跟蹤
針對長視頻,Seed-2.0-lite-260428 支持跨多個時間段抽取關鍵線索,持續追蹤人物與事件進展,並在多幀之間進行多步推理,重建事件關係與行爲上下文。比起逐幀描述的傳統做法,它的"長時序理解"能力更適合監控視頻覆盤、紀錄片剪輯助手等任務。
2.3 增強的 Agent 與編碼能力
模型在複雜長時序任務上具備穩定可靠的執行能力,並具備深度全棧開發能力。這意味着開發者可以把它接入 Agent 框架,執行包含規劃、調用工具、回看歷史步驟、生成代碼的完整閉環,而不必把任務拆分給多個不同模型。
2.4 GUI 理解與操作執行的統一接口
GUI 能力被整合到同一個接口裏,模型既能理解屏幕截圖(按鈕、表單、菜單),也能輸出操作指令(點擊座標、鍵入文本)。這對自動化測試、桌面 Agent 與 RPA 類應用是直接的能力升級。
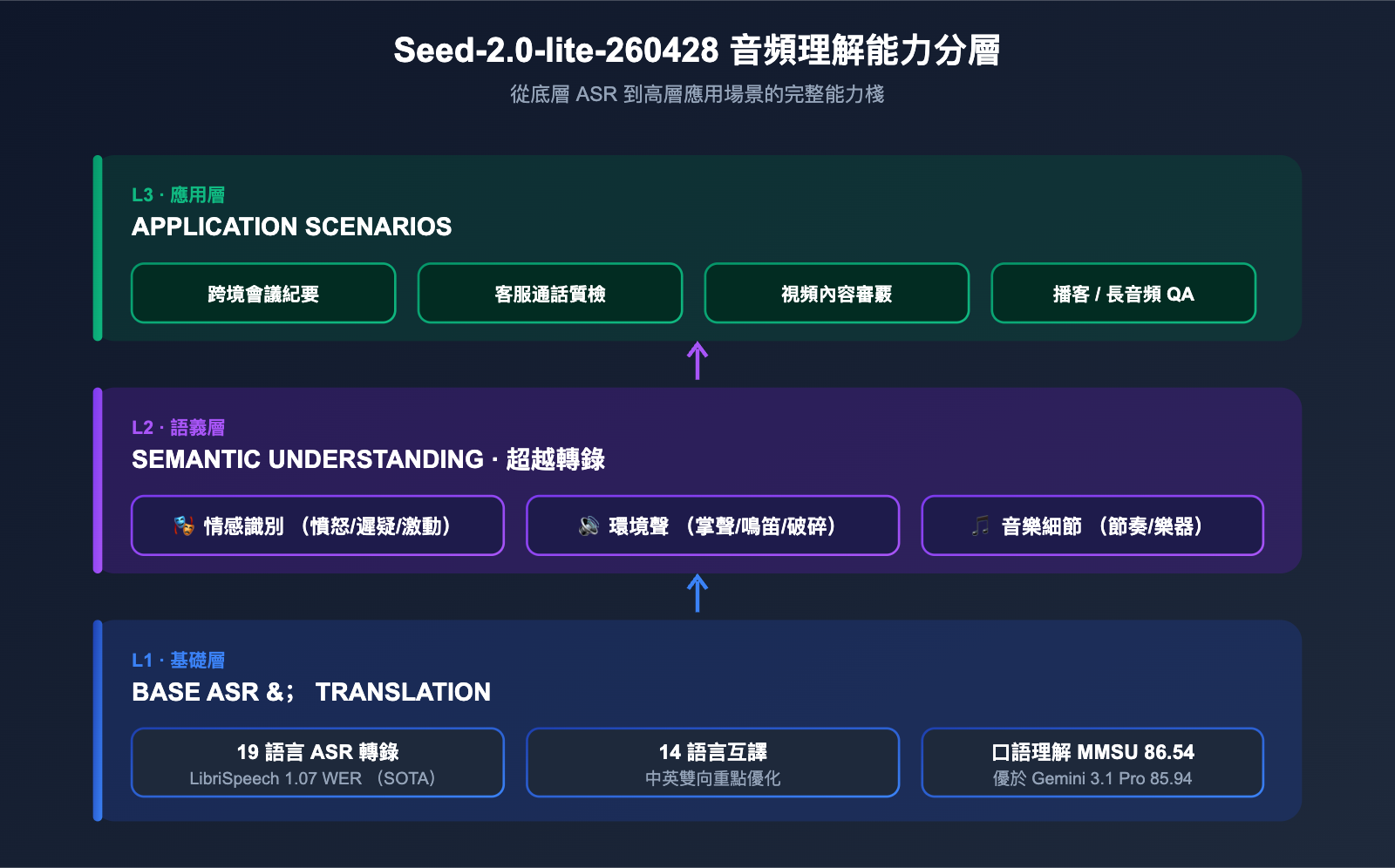
三、Seed-2.0-lite-260428 的音頻理解能力深度解析
音頻是這一次更新最大的差異化能力,所以單獨展開講。模型在多項主流音頻基準上交出了相當亮眼的成績。
3.1 主流音頻基準的實測分數
下表彙總了 ByteDance Seed 官方公開的基準成績,涵蓋語音識別(ASR)、口語理解、野外語音場景三個維度。
| 基準 | 任務類型 | Seed-2.0-lite-260428 |
|---|---|---|
| LibriSpeech test-clean | 英文 ASR(乾淨) | 1.07 WER |
| LibriSpeech test-other | 英文 ASR(噪聲) | 2.17 WER |
| WenetSpeech test-net | 中文 ASR(網絡) | 4.47 WER |
| WenetSpeech test-meeting | 中文會議 ASR | 5.31 WER |
| Fleurs(15 語言) | 多語種 ASR | 74.70 |
| MMSU | 口語理解 | 86.54 |
| WildSpeech | 野外語音 | 75.81 |
LibriSpeech test-clean 上 1.07 的 WER 已經處於業界頂尖水準,優於公開 Whisper large-v3 的同類成績;MMSU 與 WildSpeech 分數也略高於 Gemini 3.1 Pro 的公開數據,說明模型在"理解"層面同樣達到主流旗艦水平,而不僅僅是"聽寫"。
3.2 19 種語言轉錄與 14 種語言互譯
官方文檔說明,模型支持 19 種語言的語音轉錄與 14 種語言之間的互譯,其中中英雙向翻譯被列爲重點優化方向。這意味着同一段多語種會議錄音,模型可以輸出統一語言的字幕與翻譯,適合跨境團隊、跨境電商客服等場景。
3.3 超越"轉錄":情感、環境聲與音樂細節
與傳統 ASR 模型最大的不同,是 Seed-2.0-lite-260428 還能捕捉超出"文字內容"之外的語義層信息:說話人的情緒波動(憤怒、遲疑、激動)、背景環境聲(玻璃破碎、掌聲、汽車鳴笛)、音樂細節(節奏、樂器、風格)。這些維度對於客服質檢、內容審覈、音樂推薦等業務都有直接價值。
🎯 接入建議:在跨境會議紀要、客服質檢、視頻內容審覈等需要"音頻 + 文本"協同的場景裏,我們建議直接通過 API易 apiyi.com 調用 Seed-2.0-lite-260428,一個 base_url 即可同時獲得多模態推理與 256K 長上下文的雙重收益,無需自建語音管線。
四、Seed-2.0-lite-260428 與主流多模態模型的橫向對比
要判斷這款模型在 2026 年的位置,最好的方式是把它和 GPT-4o、Gemini 3 Pro 等同期旗艦多模態模型放在一起對比。
4.1 主流多模態模型能力對照
| 維度 | Seed-2.0-lite-260428 | GPT-4o | Gemini 3 Pro |
|---|---|---|---|
| 文本輸入 | ✓ | ✓ | ✓ |
| 圖像輸入 | ✓ | ✓ | ✓ |
| 視頻輸入 | ✓ | ✓ | ✓ |
| 音頻輸入 | ✓ | ✓ | ✓ |
| 上下文窗口 | 262K | 128K | 1M |
| 輸入價格 / M | $0.25 | $2.50 | $1.25 |
| 輸出價格 / M | $2.00 | $10.00 | $10.00 |
| 音頻情感識別 | ✓ | ✓ | ✓ |
| 中文音頻優化 | 強(WenetSpeech 優化) | 一般 | 一般 |
可以看出,Seed-2.0-lite-260428 的核心優勢是"價格 + 中文音頻 + 256K 長上下文"的組合,在多語種音視頻處理、長會議覆盤等任務上的性價比尤爲突出。GPT-4o 與 Gemini 3 Pro 仍然在英文綜合能力與生態廣度上具備優勢,適合通用場景。

🎯 選型建議:如果你的業務以中文音視頻處理爲主、對成本敏感,Seed-2.0-lite-260428 是當下性價比極高的選擇;如果是英文爲主或重度多語種創意生成,可以通過 API易 apiyi.com 統一網關同時接入這三家旗艦,按場景做路由。
五、通過 APIYI 調用 Seed-2.0-lite-260428 的快速上手
模型完全兼容 OpenAI 風格接口,遷移成本極低。下面給出一個極簡的調用示例,用於把一段圖像或音頻轉成結構化描述。
5.1 OpenAI 兼容接口的最小示例
from openai import OpenAI
client = OpenAI(
api_key="<APIYI_API_KEY>",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="seed-2-0-lite-260428",
messages=[
{"role": "user", "content": [
{"type": "text", "text": "請描述這段音頻的內容、情緒與背景聲。"},
{"type": "input_audio", "audio": {"data": "<base64-or-url>", "format": "mp3"}}
]}
]
)
print(response.choices[0].message.content)
把 base_url 指向 API易 apiyi.com 的統一接入端點,再切換 model 即可在同一個 SDK 裏調用 Seed-2.0-lite-260428 與其他多模態模型,業務側無需重寫代碼。
5.2 適合 Seed-2.0-lite-260428 的典型應用場景
下表整理了幾類典型場景,以及它們能從這款模型的"音頻 + 視頻 + 文本統一推理"特性中獲得什麼收益。
| 應用場景 | 關鍵能力 | 業務價值 |
|---|---|---|
| 跨境會議紀要 | 19 語言 ASR + 14 語言翻譯 + 256K 上下文 | 多語種會議一鍵轉雙語紀要 |
| 客服通話質檢 | 情感識別 + 環境聲檢測 + 長音頻分析 | 自動標記憤怒/插話/超時 |
| 視頻內容審覈 | 音視頻聯合推理 + 長時序跟蹤 | 同步識別危險畫面與可疑聲音 |
| 播客 / 長視頻 QA | 256K 長上下文 + 音頻轉錄 | 直接問答多小時音頻內容 |
| 桌面 Agent 自動化 | GUI 理解 + 工具調用 | 完成跨應用複雜工作流 |
六、Seed-2.0-lite-260428 常見問題解答
6.1 API 調用時 model 字段應該怎麼填
直接填 seed-2-0-lite-260428 即可。注意中間是連字符,不是下劃線;後綴 260428 是版本號(2026-04-28),不要省略,否則可能被路由到舊版本。模型列表可以在 API易 apiyi.com 控制檯查詢,確保和最新發布保持一致。
6.2 支持哪些音頻格式與時長
模型遵循 OpenAI 風格的 input_audio 字段約定,常見的 MP3、WAV、M4A、FLAC 格式都支持。具體最大時長與採樣率以官方 ModelArk 文檔爲準,建議單次輸入不超過 30 分鐘以保證推理穩定。超長音頻可以先按段切分再合併結果。
6.3 與無 260428 後綴的 Seed-2.0-Lite 有什麼區別
無後綴版本是 3 月 10 日發佈的初代 Seed-2.0-Lite,只支持文本、圖像、視頻;260428 是 4 月 28 日發佈的全模態升級版,新增音頻輸入與音視頻聯合推理能力。如果業務用到音頻,必須用帶後綴的版本。
6.4 調用是按 token 還是按音頻時長計費
模型按 token 統一計費,音頻會被內部編碼爲 token 後參與計算。當前定價爲 $0.25 / M 輸入、$2.00 / M 輸出。具體一段音頻對應的 token 數可在 API易 apiyi.com 控制檯的"賬單流水"中查看,便於做成本預估與優化。
6.5 是否支持流式輸出與 Function Call
完全支持。Seed-2.0-lite-260428 兼容標準 OpenAI Chat Completions 協議中的 stream=true 與 tools 字段,可以直接接入 LangChain、LangGraph、OpenAI Agents SDK 等主流框架,無需特殊改造。
七、總結:全模態模型讓多模態應用進入"統一推理"時代
Seed-2.0-lite-260428 的價值不僅是"多一種音頻能力",更在於把視頻、圖像、音頻與文本統一在同一個模型內完成推理。這種"統一推理"對那些天然跨模態的業務(會議、客服、內容審覈、視頻分析、Agent 自動化)來說,是一次真正意義上的架構簡化:不再需要 ASR、視覺、文本三套模型拼接,也不再擔心跨模型上下文丟失。
從成本與中文場景的角度看,這款模型在主流旗艦之中具備非常明顯的性價比優勢,$0.25 / M 輸入的價格讓大規模音視頻處理在工程上成爲可能,256K 上下文也足以覆蓋多小時長音頻與長視頻場景。
如需在同一個 base_url 下統一調用 Seed-2.0-lite-260428 與各家旗艦多模態模型,可以訪問 API易 apiyi.com 官方文檔查看完整接入示例與模型列表。
作者:APIYI Team — 持續爲全球 AI 開發者提供穩定、高效的 API 中轉與多模型路由服務,詳情訪問 apiyi.com