作者注:從編碼、推理、多模態、知識工作、定價 5 大維度對比 Gemini 3.1 Pro 和 Claude Sonnet 4.6,幫你選出最適合的高性價比前沿模型
2026 年 2 月的 AI 模型格局出現了一個有意思的局面:真正的競爭不再是「誰是最強」,而是 「誰是性價比之王」。Google 的 Gemini 3.1 Pro(2 月 19 日發佈)和 Anthropic 的 Claude Sonnet 4.6(2 月 17 日發佈),幾乎同期上線,定價接近,都宣稱接近旗艦級性能——開發者的選擇從未如此糾結。
核心價值: 看完本文,你將清楚兩個模型在編碼、推理、多模態、知識工作上的真實差距,以及在你的具體場景下該選哪一個。

Gemini 3.1 Pro 與 Claude Sonnet 4.6 基礎參數對比
兩個模型的定位非常相似——都是「接近旗艦性能、遠低於旗艦價格」的實力派,但技術路線截然不同。
| 參數維度 | Gemini 3.1 Pro | Claude Sonnet 4.6 | 對比說明 |
|---|---|---|---|
| 發佈日期 | 2026.02.19 | 2026.02.17 | 相隔僅 2 天 |
| 上下文窗口 | 100 萬(標準) | 20 萬標準 / 100 萬 Beta | Gemini 原生百萬上下文 |
| 最大輸出 | 64K tokens | 64K tokens | 完全一致 |
| 輸入價格 | $2/百萬 Token | $3/百萬 Token | ✅ Gemini 便宜 33% |
| 輸出價格 | $12/百萬 Token | $15/百萬 Token | ✅ Gemini 便宜 20% |
| 長上下文輸入價 | $4(>200K) | $3(不變) | ⚠️ 長上下文 Sonnet 更便宜 |
| 長上下文輸出價 | $18(>200K) | $15(不變) | ⚠️ 長上下文 Sonnet 更便宜 |
| 輸入模態 | 文本、圖片、音頻、視頻、PDF | 文本、圖片、PDF | ✅ Gemini 多模態更全 |
| 推理模式 | 三級思考(Low/Med/High) | 自適應思考(動態調節) | 設計理念不同 |
| Prompt 緩存 | 支持 | 緩存讀取僅 $0.30/百萬(省 90%) | ✅ Sonnet 緩存更省 |
🎯 定價關鍵細節: 在 200K 以內的常規場景下,Gemini 3.1 Pro 更便宜($2/$12 vs $3/$15)。但一旦上下文超過 200K,Gemini 漲價到 $4/$18,反而比 Sonnet 4.6 的 $3/$15 更貴。你的平均上下文長度直接決定誰更划算。
Gemini 3.1 Pro 與 Sonnet 4.6 Benchmark 全面對比
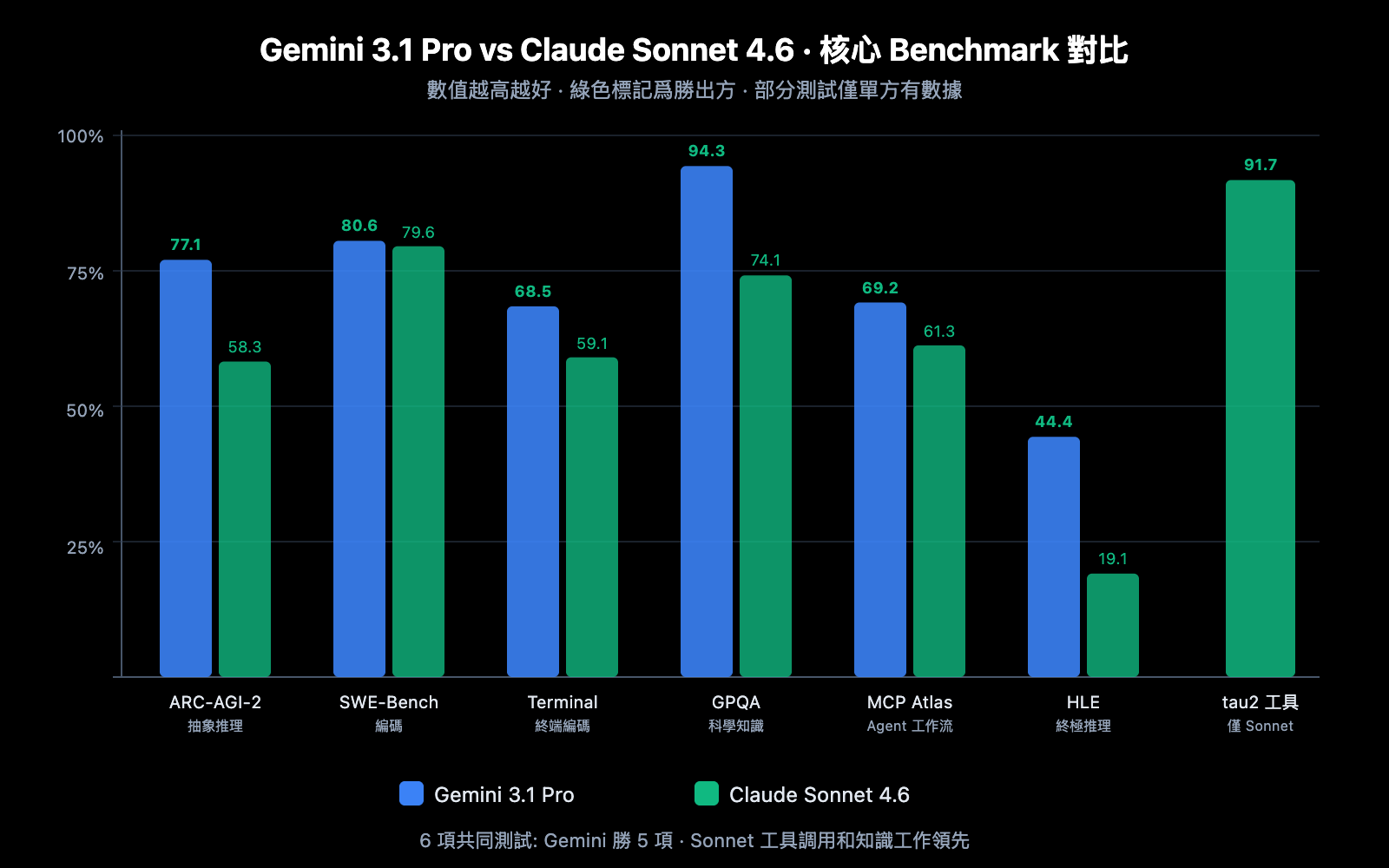
編碼能力對比
| 編碼測試 | Gemini 3.1 Pro | Claude Sonnet 4.6 | 勝出方 |
|---|---|---|---|
| SWE-Bench Verified | 80.6% | 79.6% | ✅ Gemini 高 1.0 分 |
| SWE-Bench Pro | 54.2% | 42.7% | ✅ Gemini 高 11.5 分 |
| Terminal-Bench 2.0 | 68.5% | 59.1% | ✅ Gemini 高 9.4 分 |
分析: Gemini 3.1 Pro 在三項編碼測試中全面領先。特別是 SWE-Bench Pro(更復雜的真實代碼任務)差距達 11.5 分,Terminal-Bench(終端環境編碼)差距達 9.4 分。不過值得注意的是,Sonnet 4.6 在 Replit 的生產代碼編輯內部測試中實現了 0% 錯誤率,並被選爲 GitHub Copilot 的編碼 Agent 基礎模型——實際生產環境中的編碼體驗可能比 Benchmark 更接近。
推理能力對比
| 推理測試 | Gemini 3.1 Pro | Claude Sonnet 4.6 | 勝出方 |
|---|---|---|---|
| ARC-AGI-2(抽象推理) | 77.1% | 58.3% | ✅ Gemini 高 18.8 分 |
| GPQA Diamond(科學) | 94.3% | 74.1% | ✅ Gemini 高 20.2 分 |
| HLE(終極推理) | 44.4% | 19.1% | ✅ Gemini 高 25.3 分 |
| MATH-500 | – | 97.8% | Sonnet 數學能力突出 |
分析: 推理能力是兩者差距最大的維度。Gemini 3.1 Pro 在 ARC-AGI-2、GPQA Diamond、HLE 三項推理測試上大幅領先,差距從 18 到 25 分不等。這裏需要說明的是,Gemini 3.1 Pro 的推理得分是在其三級思考系統的 High 模式下取得的,而 Sonnet 4.6 的自適應思考在推理深度上不如 Opus 4.6。如果純推理是你的核心需求,Gemini 3.1 Pro 優勢明顯。
知識工作與 Agent 能力對比
| 測試 | Gemini 3.1 Pro | Claude Sonnet 4.6 | 勝出方 |
|---|---|---|---|
| GDPval-AA Elo(知識工作) | 1,317 | 1,633 | ✅ Sonnet 高 316 分 |
| Finance Agent(金融分析) | – | 63.3% | Sonnet 數據突出 |
| OSWorld(操作系統控制) | – | 72.5% | Sonnet 數據突出 |
| MCP Atlas(多步驟工作流) | 69.2% | 61.3% | ✅ Gemini 高 7.9 分 |
| tau2-bench Retail(工具調用) | – | 91.7% | Sonnet 數據突出 |
分析: 這裏出現了最大的反轉。在 GDPval-AA(模擬真實專家級知識工作)上,Sonnet 4.6 以 1,633 Elo 不僅遠超 Gemini 3.1 Pro 的 1,317,甚至超過了自家旗艦 Opus 4.6 的 1,559。這意味着在研究分析、報告撰寫、商業策略等高價值知識工作場景中,Sonnet 4.6 是目前所有模型中表現最好的——包括比它貴 5 倍的 Opus 4.6。
Gemini 3.1 Pro 與 Sonnet 4.6 的場景選擇建議
兩個模型的優劣勢非常互補,場景選擇比「哪個更好」更重要。
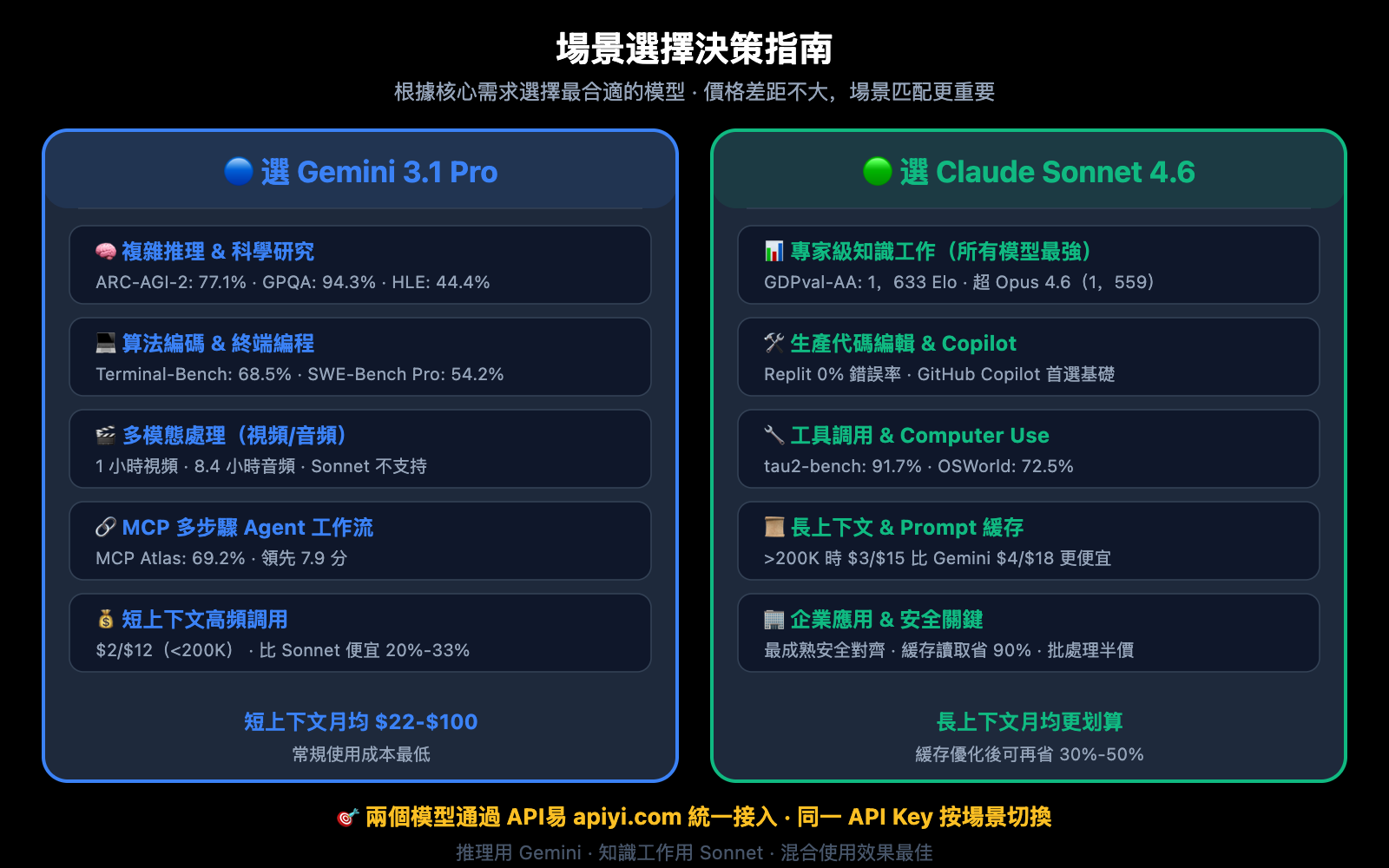
選 Gemini 3.1 Pro 的場景
- 算法和競賽編程: LiveCodeBench Elo 2,887,在算法類編碼上碾壓級領先
- 複雜推理和科學研究: ARC-AGI-2 77.1%、GPQA Diamond 94.3%,純推理能力是 Sonnet 4.6 的另一個層級
- 多模態處理: 原生支持視頻(1 小時)、音頻(8.4 小時),Sonnet 4.6 不支持
- MCP Agent 工作流: MCP Atlas 69.2%(領先 7.9 分),構建多步驟 Agent 系統時更可靠
- 短上下文高頻調用: 200K 以內 $2/$12 的定價是兩者中更便宜的選擇
選 Claude Sonnet 4.6 的場景
- 專家級知識工作: GDPval-AA 1,633 Elo 是當前所有模型最高分,研究報告、金融分析、商業策略等場景無出其右
- 生產代碼編輯: 在 Replit 生產環境測試中 0% 錯誤率,被 GitHub Copilot 選爲編碼 Agent 基礎
- 工具調用和 Computer Use: tau2-bench 91.7%、OSWorld 72.5%,在自動化操作和函數調用上精度極高
- 長上下文場景: 超過 200K 上下文時,Sonnet 4.6 的 $3/$15 比 Gemini 的 $4/$18 更便宜
- 企業級應用: 更成熟的安全對齊、Prompt 緩存(讀取僅 $0.30/百萬 Token,省 90%)、批處理半價
Gemini 3.1 Pro 和 Claude Sonnet 4.6 API 快速接入
極簡示例
通過 API易平臺,兩個模型使用統一接口:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Gemini 3.1 Pro - 推理和多模態更強
response = client.chat.completions.create(
model="gemini-3.1-pro",
messages=[{"role": "user", "content": "分析這段代碼的時間複雜度並優化"}]
)
print(response.choices[0].message.content)
查看 Sonnet 4.6 調用和按場景自動切換示例
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Claude Sonnet 4.6 - 知識工作和工具調用更強
response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[{"role": "user", "content": "撰寫 Q1 市場分析報告,包含競品對比和增長建議"}]
)
print(response.choices[0].message.content)
# 按場景自動路由
def route_model(prompt, task_type="general"):
model_map = {
"reasoning": "gemini-3.1-pro",
"multimodal": "gemini-3.1-pro",
"algorithm": "gemini-3.1-pro",
"knowledge": "claude-sonnet-4-6",
"production_code": "claude-sonnet-4-6",
"tool_call": "claude-sonnet-4-6",
"general": "gemini-3.1-pro",
}
return client.chat.completions.create(
model=model_map.get(task_type, "gemini-3.1-pro"),
messages=[{"role": "user", "content": prompt}]
)
建議: 通過 API易 apiyi.com 平臺可以同時接入兩個模型,使用同一個 API Key 切換。平臺提供免費測試額度,建議在你的實際場景中對比效果。
Gemini 3.1 Pro 與 Sonnet 4.6 成本深度對比
以三種典型使用場景估算月成本:
| 使用場景 | 月均 Token 消耗 | Gemini 3.1 Pro | Claude Sonnet 4.6 | 更便宜方 |
|---|---|---|---|---|
| 輕度使用(500 萬輸入 + 100 萬輸出) | 600 萬 | $22 | $30 | Gemini 省 27% |
| 中度使用(2000 萬輸入 + 500 萬輸出) | 2500 萬 | $100 | $135 | Gemini 省 26% |
| 重度長上下文(5000 萬輸入 >200K + 1000 萬輸出) | 6000 萬 | $380 | $300 | ⚠️ Sonnet 省 21% |
🎯 成本結論: 常規使用下 Gemini 3.1 Pro 便宜約 26%-27%。但如果你頻繁使用超過 200K 的長上下文(如全代碼庫分析、長文檔處理),Sonnet 4.6 反而更便宜——因爲 Gemini 長上下文漲價到 $4/$18,而 Sonnet 保持 $3/$15 不變。再加上 Sonnet 的 Prompt 緩存(讀取僅 $0.30/百萬 Token),實際成本可能還要低 30%-50%。
通過 API易 apiyi.com 平臺接入可享受額外優惠價格,進一步降低兩個模型的使用成本。
常見問題
Q1: Sonnet 4.6 的 GDPval-AA 比自家 Opus 4.6 還高,這正常嗎?
確實如此。Sonnet 4.6 在 GDPval-AA 上拿到了 1,633 Elo,超過了 Opus 4.6 的 1,559。Anthropic 官方確認了這一數據。可能的原因是 Sonnet 4.6 針對企業知識工作場景做了專項優化,而 Opus 4.6 更側重於通用推理和長上下文處理。開發者對 Sonnet 4.6 的偏好率也達到了 70%(對比 Sonnet 4.5)和 59%(對比 Opus 4.5)。
Q2: 哪個模型更適合做 AI Agent?
取決於 Agent 類型。如果是基於 MCP 的多步驟工作流 Agent,Gemini 3.1 Pro 的 MCP Atlas 69.2% 領先 7.9 分。如果是工具調用密集型 Agent(如 OpenClaw),Sonnet 4.6 的 tau2-bench 91.7% 更可靠。如果是 Computer Use 類 Agent(操控瀏覽器和桌面),Sonnet 4.6 的 OSWorld 72.5% 是目前最好的成績之一。兩個模型在 API易 apiyi.com 平臺都可直接接入測試。
Q3: 我現在用的是 Sonnet 4.5,該升級到 Sonnet 4.6 還是換 Gemini 3.1 Pro?
如果你對 Sonnet 4.5 的知識工作和編碼體驗滿意,直接升級 Sonnet 4.6 是最穩妥的選擇——API 兼容、價格不變、性能全面提升(SWE-Bench 從 77.2% 到 79.6%,ARC-AGI-2 從 13.6% 到 58.3%,提升 4.3 倍)。如果你的核心需求偏向推理、多模態或算法編碼,Gemini 3.1 Pro 在這些方向上有顯著優勢。建議通過 API易 apiyi.com 平臺兩個模型都試一試。
總結
Gemini 3.1 Pro 與 Claude Sonnet 4.6 的核心結論:
- 推理和多模態選 Gemini 3.1 Pro: ARC-AGI-2 領先 18.8 分,GPQA Diamond 領先 20.2 分,原生視頻/音頻支持,短上下文下更便宜
- 知識工作和生產編碼選 Claude Sonnet 4.6: GDPval-AA 1,633 Elo 是所有模型最高分(包括 Opus 4.6),Replit 0% 錯誤率,GitHub Copilot 首選
- 長上下文場景 Sonnet 更划算: 超過 200K 上下文時 Sonnet $3/$15 vs Gemini $4/$18,配合 Prompt 緩存可再省 30%-50%
這兩個模型是 2026 年 2 月性價比最高的前沿模型,最佳策略是根據場景混合使用。推薦通過 API易 apiyi.com 同時接入,用同一個 API Key 按需切換。
📚 參考資料
-
Claude Sonnet 4.6 發佈公告: Anthropic 官方博客
- 鏈接:
anthropic.com/news/claude-sonnet-4-6 - 說明: Sonnet 4.6 的完整功能介紹、Benchmark 數據和自適應思考功能
- 鏈接:
-
Gemini 3.1 Pro 官方博客: Google DeepMind 發佈公告
- 鏈接:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - 說明: Gemini 3.1 Pro 的三級思考系統和完整性能數據
- 鏈接:
-
Tom's Guide 實測對比: 7 項挑戰實測 Gemini 3.1 Pro vs Sonnet 4.6
- 鏈接:
tomsguide.com/ai/i-tested-gemini-3-1-pro-vs-claude-sonnet-4-6-in-7-tough-challenges-and-there-was-one-clear-winner - 說明: 真實任務場景下的實際表現對比
- 鏈接:
-
Artificial Analysis 排行榜: 第三方獨立模型評測平臺
- 鏈接:
artificialanalysis.ai/leaderboards/models - 說明: 客觀的性能、速度、價格橫向對比數據
- 鏈接:
作者: 技術團隊
技術交流: 歡迎在評論區分享你的使用體驗,更多 AI 模型資訊可訪問 API易 apiyi.com