Примечание автора: основываясь на 6 ключевых бенчмарках, включая SWE-bench Pro, Terminal-Bench 2.0 и LiveCodeBench, мы провели глубокий сравнительный анализ способностей GPT-5.5 и Claude Opus 4.7 в реальных задачах программирования и подготовили для вас конкретные рекомендации по выбору модели.
Спор о том, кто лучше пишет код — GPT-5.5 или Claude Opus 4.7, — стал главной темой в мире AI-разработки в апреле 2026 года. В этой статье мы сравним OpenAI GPT-5.5 (кодовое имя Spud) и Anthropic Claude Opus 4.7. Мы разберем их производительность по таким критериям, как SWE-bench Pro, Terminal-Bench 2.0, качество поиска в длинном контексте, эффективность токенов и стоимость API, чтобы дать вам четкий совет по выбору.
Это не тот случай, когда мы будем писать «у обеих сторон есть свои плюсы» — мы основываемся на официальных данных бенчмарков и прямо рекомендуем подходящую модель для каждой конкретной задачи. Anthropic выпустила Claude Opus 4.7 16 апреля 2026 года, а OpenAI ответила выпуском GPT-5.5 уже 23 апреля. Эти две топовые модели столкнулись с разницей всего в неделю, и битва за первенство в программировании началась.
Что вы получите: после прочтения вы будете точно знать, что выбрать — GPT-5.5 или Claude Opus 4.7 — для четырех типичных сценариев: исправление ошибок в GitHub-ишью, агентное программирование (Agentic coding), рефакторинг с использованием длинного контекста и интерактивное написание кода.

Краткий обзор ключевых различий между GPT-5.5 и Claude Opus 4.7
Разные подходы к позиционированию моделей привели к заметным различиям в их специализации в программировании. В таблице ниже собраны основные параметры для сравнения:
| Параметр | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| Дата выпуска | 23.04.2026 | 16.04.2026 |
| Кодовое имя | Spud | — |
| Контекстное окно | 1 млн токенов | 1 млн токенов |
| Макс. выход | 128 тыс. токенов | 128 тыс. токенов |
| Основные сильные стороны | Агентное программирование, поиск по длинному контексту | Исправление реальных GitHub issue, архитектурное мышление |
| Типичное TTFT | ~3 сек | ~0.5 сек |
| Эффективность токенов | На 72% меньше выходных токенов, чем у Opus | Потребление токенов выше, но точность выше |
| API (ввод) | $5/млн токенов | $5/млн токенов |
| API (вывод) | $30/млн токенов | $25/млн токенов |
| Доплата за длинный промпт | >200K по прежней цене | >200K цена удваивается до $10/$37.50 |
Специализация GPT-5.5 в программировании
GPT-5.5 — это самая мощная на данный момент агентная модель OpenAI для написания кода. Она блестяще справляется с терминальными рабочими процессами, поиском в длинном контексте и координацией работы с внешними инструментами. Она особенно эффективна в автоматизации многошаговых задач. Разработчики OpenAI позиционируют её как лучший выбор для «долгосрочных задач программирования»; согласно внутренним бенчмаркам Expert-SWE, модель способна выполнять задачи, на которые у человека уходит до 20 часов.
Специализация Claude Opus 4.7 в программировании
Claude Opus 4.7 возвращает себе лидерство в реальных инженерных задачах. Модель достигает 87.6% в SWE-bench Verified и 64.3% в SWE-bench Pro, заметно опережая всех конкурентов. По внутренним тестам Anthropic, Opus 4.7 решает в 3 раза больше рабочих задач, чем версия 4.6. Это идеальный инструмент для исправления ошибок в GitHub и рефакторинга огромных кодовых баз, где критически важна архитектурная логика.
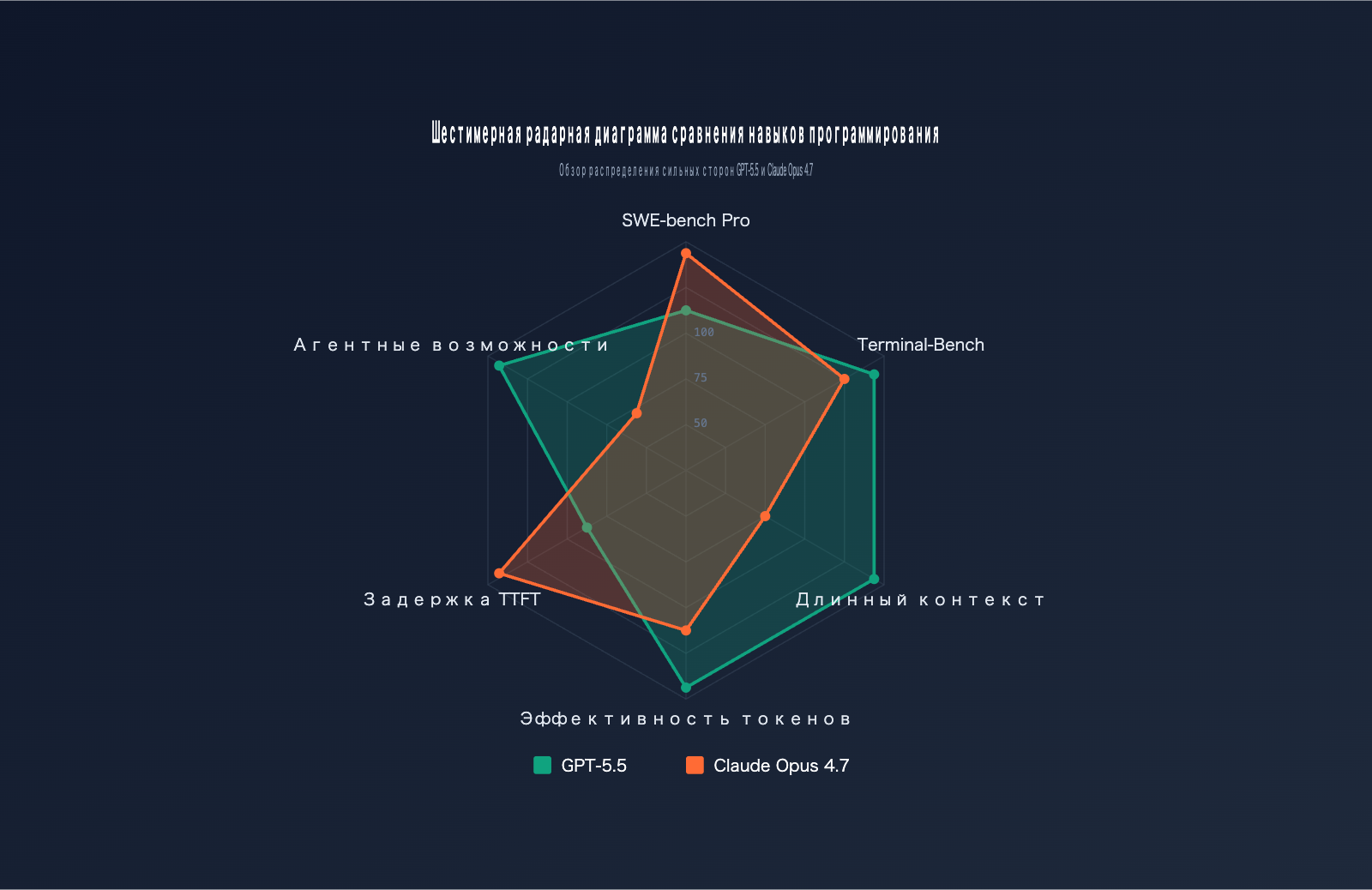
Сравнительное тестирование GPT-5.5 и Claude Opus 4.7
Бенчмарки — самый объективный способ оценки способностей программирования. Мы свели данные по 6 основным тестам:
| Бенчмарк | Предмет тестирования | GPT-5.5 | Claude Opus 4.7 | Победитель |
|---|---|---|---|---|
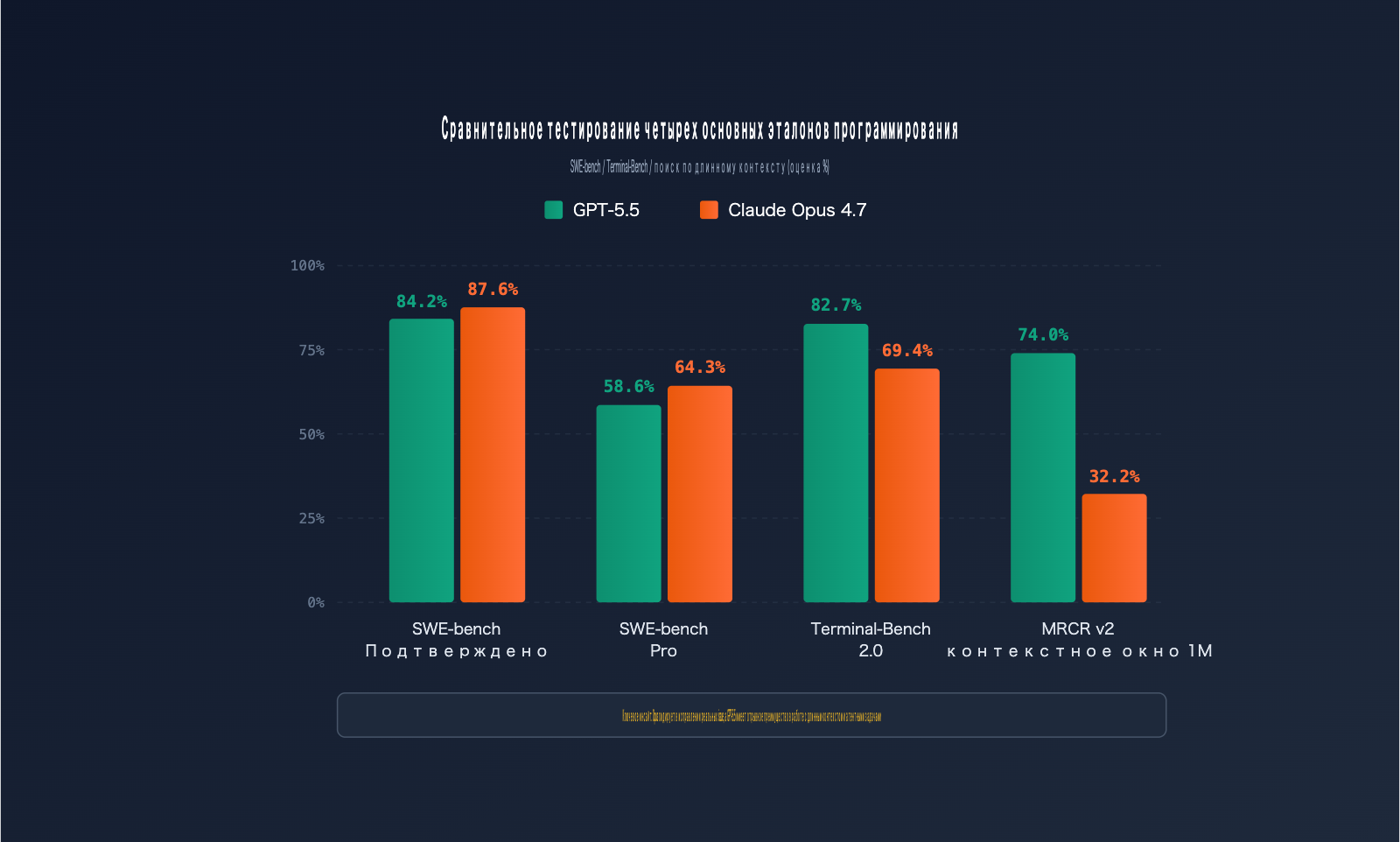
| SWE-bench Verified | Проверенные исправления GitHub issue | 84.2% | 87.6% | Opus 4.7 |
| SWE-bench Pro | Исправление сложных задач в нескольких файлах | 58.6% | 64.3% | Opus 4.7 |
| Terminal-Bench 2.0 | Рабочие процессы в терминале | 82.7% | 69.4% | GPT-5.5 |
| Expert-SWE | Долгосрочное программирование (20 ч. задач) | 73.1% | — | GPT-5.5 |
| OSWorld-Verified | Задачи десктопных агентов | 78.7% | 78.0% | GPT-5.5 (незначительно) |
| MRCR v2 (512K-1M) | Поиск по длинному контексту (8-needle) | 74.0% | 32.2% | GPT-5.5 |
Анализ SWE-bench Pro
SWE-bench Pro — «золотой стандарт» оценки навыков исправления реальных ошибок в коде. Разрыв в 5.7% (64.3% у Opus против 58.6% у GPT-5.5) означает, что на каждые 100 багов Opus 4.7 исправляет на 6 больше. Важно отметить, что прыжок производительности Opus 4.7 по сравнению с версией 4.6 (53.4%) составил почти 11 процентных пунктов — это колоссальный результат для одного обновления.
Совет: Хотите проверить, как модели работают именно с вашим кодом? Попробуйте платформу APIYI (apiyi.com). Она поддерживает единый интерфейс для обоих моделей, что упрощает сравнение.
Анализ Terminal-Bench 2.0
В этом тесте оценивается способность планировать и итерировать задачи в терминале. GPT-5.5 опережает конкурента на 13 процентных пунктов. Это преимущество проистекает из улучшенной работы агентных воркфлоу: GPT-5.5 лучше выбирает инструменты и восстанавливается после ошибок. Если ваша работа связана с shell-командами и CI/CD, GPT-5.5 будет надежнее.
Разрыв в работе с длинным контекстом
В тесте MRCR v2 на поиск 8 элементов в диапазоне до 1 млн токенов GPT-5.5 показывает результат 74.0% против 32.2% у Opus. Для задач вроде «рефакторинг всего монорепозитория» эта разница превращается в принципиальную возможность (или невозможность) решить задачу.
Сравнение GPT-5.5 и Claude Opus 4.7 в задачах программирования
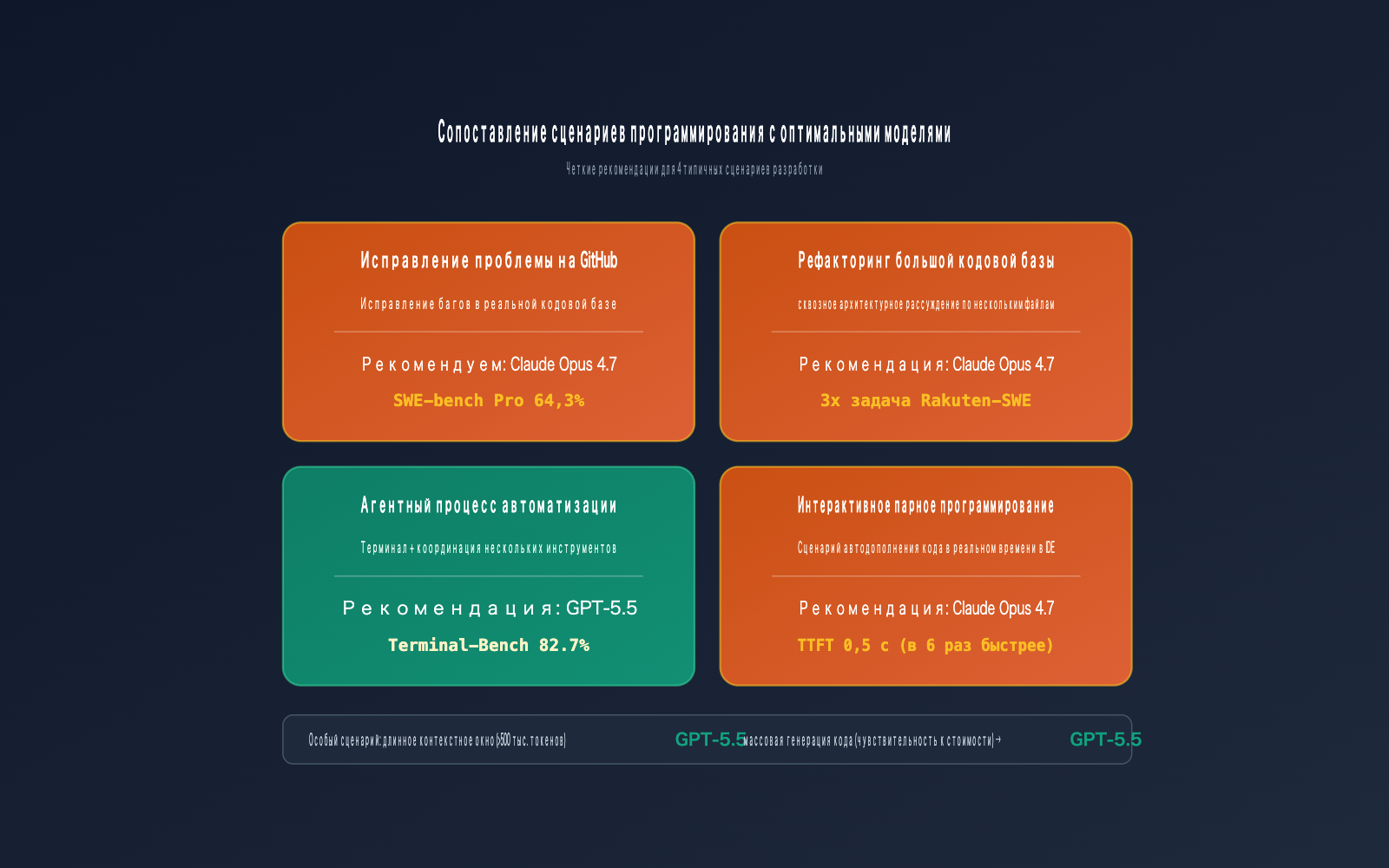
Бенчмарки имеют смысл только тогда, когда их прикладывают к реальным задачам. В таблице ниже приведены четкие рекомендации по выбору модели для 5 типичных сценариев программирования:
| Сценарий программирования | Рекомендуемая модель | Основная причина | Ожидаемая выгода |
|---|---|---|---|
| Исправление GitHub Issue | Claude Opus 4.7 | Лидерство в SWE-bench Pro (+5,7%) | Рост успеха исправлений на 10% |
| Рефакторинг крупного проекта | Claude Opus 4.7 | Лучшее понимание архитектуры | Снижение риска поломки связей |
| Автоматизация через агентов | GPT-5.5 | Лидерство в Terminal-Bench (+13,3%) | Выше стабильность в многошаговых задачах |
| Работа с длинным контекстом (>500K) | GPT-5.5 | Преимущество в MRCR v2 (+41,8%) | Надежный поиск в глубоком контексте |
| Интерактивный парный коддинг | Claude Opus 4.7 | TTFT всего 0,5 сек, быстрый отклик | Более плавный ритм кодинга |
| Массовая генерация кода | GPT-5.5 | Выше эффективность токенов на 72% | Лучшая экономическая эффективность |
Сценарий 1: Исправление реальных GitHub Issue → выбирайте Claude Opus 4.7
Если ваша главная задача — «получить описание issue и сделать PR, готовый к слиянию», Claude Opus 4.7 — вне конкуренции. Его результат 87,6% в тесте SWE-bench Verified означает, что около 9 из 10 хорошо описанных задач по исправлению багов могут быть выполнены успешно.
Важно понимать: 87,6% не означают, что 87,6% всей вашей работы будет автоматизировано — это идеальный показатель для «идеально сформулированных задач». В реальности качество описания issue сильно влияет на результат.
Сценарий 2: Понимание кода с длинным контекстом → выбирайте GPT-5.5
Когда нужно, чтобы модель «прочитала» весь монорепозиторий (обычно 500K–1M токенов) перед принятием решения, GPT-5.5 — единственный надежный выбор. Точность поиска по 8 меткам (needle-in-a-haystack) у Opus 4.7 на объеме 1M токенов составляет всего 32,2%. Это значит, что модель может просто «не увидеть» важные определения в глубине кодовой базы.
Этот разрыв архитектурный: если ваш рабочий процесс зависит от целостного представления проекта (например, глобальное переименование или проверка совместимости API), то с Opus 4.7 процесс может просто не сработать.
Сценарий 3: Агентские рабочие процессы → выбирайте GPT-5.5
Агентское программирование — это рабочий процесс, где ИИ самостоятельно планирует задачи, вызывает инструменты и вносит исправления. Оценка GPT-5.5 в 82,7% в Terminal-Bench 2.0 значительно выше, чем у Opus 4.7. Модель стабильнее в задачах типа:
- Написание и выполнение скриптов автоматического развертывания;
- Отладка нескольких сервисов и анализ логов;
- Выявление проблем в CI/CD пайплайнах;
- Построение и мониторинг потоков обработки данных.
Совет по интеграции: при построении агентских процессов рекомендуем вызывать GPT-5.5 через агрегаторы API, такие как APIYI (apiyi.com). Это упрощает централизованное управление API-ключами, контроль затрат и переключение между моделями при необходимости.
Сценарий 4: Интерактивный парный коддинг → выбирайте Claude Opus 4.7
Ощущения от интерактивного кодинга крайне чувствительны к задержкам. Время до получения первого токена (TTFT) у Opus 4.7 составляет около 0,5 сек, тогда как у GPT-5.5 — около 3 секунд. Эта шестикратная разница очень заметна при частых запросах.
Если вы используете Cursor, Claude Code, Continue и другие IDE-инструменты для частых автодополнений небольших фрагментов кода, низкая задержка Opus 4.7 сделает вашу работу намного комфортнее.
Примеры вызова API для GPT-5.5 и Claude Opus 4.7
Ниже представлены минималистичные примеры вызова обоих моделей для быстрой проверки. Обе модели совместимы с форматом OpenAI SDK, поэтому переход на них потребует минимум усилий.
Минималистичный вызов GPT-5.5
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "Реализуй быструю сортировку на Python"}]
)
print(response.choices[0].message.content)
Минималистичный вызов Claude Opus 4.7
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Реализуй быструю сортировку на Python"}]
)
print(response.choices[0].message.content)
Посмотреть код для параллельного сравнительного тестирования двух моделей
import openai
import time
from typing import Dict
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def benchmark_model(model: str, prompt: str) -> Dict:
"""Тестирование времени отклика и длины вывода модели"""
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=2000
)
elapsed = time.time() - start
return {
"model": model,
"elapsed_seconds": round(elapsed, 2),
"output_tokens": response.usage.completion_tokens,
"content_preview": response.choices[0].message.content[:200]
}
# Тест на навыки программирования
test_prompt = """
Реализуй класс LRU-кэша на Python со следующими требованиями:
1. Поддержка методов get(key) и put(key, value)
2. Автоматическое удаление элемента, который дольше всего не использовался при достижении лимита容量
3. Временная сложность всех операций O(1)
4. Включи полные юнит-тесты
"""
# Параллельное тестирование двух моделей
gpt_result = benchmark_model("gpt-5.5", test_prompt)
claude_result = benchmark_model("claude-opus-4-7", test_prompt)
print(f"GPT-5.5: {gpt_result['elapsed_seconds']}с, {gpt_result['output_tokens']} токенов")
print(f"Claude Opus 4.7: {claude_result['elapsed_seconds']}с, {claude_result['output_tokens']} токенов")
Совет по тестированию: Получите бесплатные тестовые лимиты через APIYI (apiyi.com). Вы сможете тестировать GPT-5.5 и Claude Opus 4.7 параллельно под одной учетной записью, используя единый base_url и API-ключ — нет необходимости отдельно регистрироваться в OpenAI и Anthropic.
Анализ совокупной стоимости GPT-5.5 и Claude Opus 4.7
Ценообразование API — это ключевой фактор при выборе модели. На первый взгляд, стоимость выходных токенов у Opus 4.7 ниже на 17%, но после глубокого анализа ситуация меняется:
| Параметр стоимости | GPT-5.5 | Claude Opus 4.7 | Реальный эффект |
|---|---|---|---|
| Входящие токены | $5/M токенов | $5/M токенов | Наравне |
| Исходящие токены | $30/M токенов | $25/M токенов | Opus дешевле на 17% |
| >200K промпт | Цена та же | Удвоение до $10/$37.50 | GPT лучше для длинного контекста |
| Токенов на задачу | 100% (база) | на 72% больше GPT | GPT выгоднее в целом |
| Задержка TTFT | ~3 сек. | ~0.5 сек. | Opus приятнее в работе |
| Реальная стоимость | 1.0x (база) | 1.4-1.5x (база) | GPT экономит бюджет |
Ключевые выводы по стоимости
Эффективность использования токенов меняет представление о цене. В аналогичных задачах по программированию GPT-5.5 в среднем потребляет на 72% меньше выходных токенов, чем Opus 4.7. Даже если цена за токен у Opus ниже на 17%, с учетом потребления в 1.72 раза больше токенов, реальная стоимость выполнения задачи для GPT-5.5 оказывается ниже.
В сценариях с длинным контекстом разрыв увеличивается. Когда промпт превышает 200 тыс. токенов, стоимость входных и выходных данных Opus 4.7 удваивается до $10 и $37.50, в то время как GPT-5.5 сохраняет прежние цены. Для рабочих процессов, требующих анализа больших объемов данных (например, всего репозитория), преимущество GPT-5.5 по стоимости может достигать 2–3 раз.
Интерпретация сравнения
Особенности затрат Claude Opus 4.7: Цена за токен конкурентоспособна среди передовых моделей. Однако при массовой генерации высокое потребление токенов увеличивает итоговый чек, а в сценариях с большим контекстом механизм удвоения тарифа после 200К токенов создает нагрузку на бюджет.
Особенности затрат GPT-5.5: Цена за токен чуть выше, но отличная эффективность и отсутствие надбавок за длинный контекст делают модель выгоднее для масштабных задач. Очевидно, что OpenAI при формировании ценообразования учитывала структуру затрат для агентских рабочих процессов.
Совет по расчету затрат: Итоговая стоимость проекта зависит от длины промпта, объема ответа и частоты вызовов. Рекомендуем подключаться к обоим моделям через платформу APIYI (apiyi.com), которая предоставляет детальную биллинговую статистику — это поможет принять взвешенное решение на основе реальных данных.
Часто задаваемые вопросы (FAQ)
Q1: Какая модель лучше справляется с программированием: GPT-5.5 или Claude Opus 4.7?
Понятия «лучше» здесь нет — всё зависит от задачи. Claude Opus 4.7 лидирует в тестах SWE-bench Pro (64,3% против 58,6%) и Verified (87,6%), поэтому она лучше подходит для исправления реальных GitHub-ишью и рефакторинга крупных кодовых баз. GPT-5.5 показывает лучшие результаты в Terminal-Bench 2.0 (82,7% против 69,4%) и поиске по длинному контексту (74,0% против 32,2%), что делает её идеальным выбором для агентных процессов программирования и анализа кода в масштабах всего монорепозитория.
Q2: В чем разница в стоимости API для GPT-5.5 и Claude Opus 4.7?
Для обеих моделей стоимость входных токенов составляет $5/M. Что касается выходных токенов, то Opus 4.7 ($25/M) на 17% дешевле, чем GPT-5.5 ($30/M). Однако при использовании промпта объемом более 200 тыс. токенов цена Opus 4.7 удваивается, тогда как GPT-5.5 сохраняет стандартную стоимость. Если учесть, что GPT-5.5 расходует на 72% меньше выходных токенов, то при выполнении массовых задач GPT-5.5 оказывается более выгодным решением.
Q3: Когда были выпущены GPT-5.5 и Claude Opus 4.7?
Claude Opus 4.7 была представлена компанией Anthropic 16 апреля 2026 года и уже доступна в Claude API, Amazon Bedrock, Google Cloud Vertex AI и Microsoft Foundry. GPT-5.5 (внутреннее кодовое имя Spud) вышла 23 апреля 2026 года. Эти топовые модели вышли с разницей всего в 7 дней, задав высокий темп конкуренции.
Q4: В каких задачах программирования стоит выбрать Claude Opus 4.7?
Остановите свой выбор на Opus 4.7 в следующих случаях:
- Исправление GitHub-ишью: преимущество в 5,7 процентных пункта в SWE-bench Pro.
- Рефакторинг крупных кодовых баз: более глубокое понимание архитектурных связей между файлами.
- Интерактивное парное программирование: TTFT (время до первого токена) составляет всего 0,5 секунды, что в 6 раз быстрее отклик.
- Аудит качества кода: более высокие оценки качества кода по результатам Rakuten-SWE-Bench.
Q5: Как быстро получить доступ к GPT-5.5 и Claude Opus 4.7 через API?
Для тестов рекомендуем использовать сервис-прокси API, поддерживающий обе модели:
- Зарегистрируйтесь на платформе APIYI (apiyi.com).
- Получите единый API-ключ и бесплатные тестовые лимиты.
- Используйте пример кода из этой статьи, заменив
base_urlнаhttps://vip.apiyi.com/v1, и укажитеmodelкакgpt-5.5илиclaude-opus-4-7соответственно.
APIYI поддерживает унифицированный интерфейс для подключения к популярным моделям от OpenAI, Anthropic, Google и других. Вам не нужно создавать множество аккаунтов, чтобы оперативно сравнить возможности GPT-5.5 и Claude Opus 4.7 на практике.
Q6: Какие известные ограничения есть у GPT-5.5 и Claude Opus 4.7?
Ограничения GPT-5.5:
- Задержка TTFT около 3 секунд, что менее комфортно для интерактивных сценариев.
- В исправлении реальных ишью в рамках SWE-bench уступает Opus 4.7.
Ограничения Claude Opus 4.7:
- Слабые возможности поиска по длинному контексту (32,2% в диапазоне 1 млн токенов).
- Цена удваивается, если промпт превышает 200 тыс. токенов, что накладно при работе с большими данными.
- Высокий расход выходных токенов делает массовые задачи более затратными.
- Эффективность в агентных задачах, таких как Terminal-Bench, ниже, чем у GPT-5.5.
Q7: Есть ли смысл использовать GPT-5.5 и Claude Opus 4.7 одновременно?
Профессиональным командам разработки мы настоятельно рекомендуем использовать обе модели. Типовая стратегия: Opus 4.7 — для исправления GitHub-ишью, ревью кода и принятия ключевых архитектурных решений; GPT-5.5 — для анализа длинного контекста, агентной автоматизации и генерации кода в больших объемах. Такой гибридный подход позволяет использовать сильные стороны каждой модели, соблюдая баланс между стоимостью и удобством работы.
Основные выводы по GPT-5.5 и Claude Opus 4.7
- Для реальных правок — Opus: Claude Opus 4.7 — лидер в тестах SWE-bench Pro/Verified, лучший выбор для работы с GitHub-ишью.
- Для агентного программирования — GPT: GPT-5.5 опережает конкурента на 13 процентных пунктов в Terminal-Bench 2.0, обеспечивая стабильную работу многошаговых инструментов.
- Для длинного контекста — GPT: В тесте MRCR v2 GPT-5.5 (74%) значительно превосходит Opus (32,2%) и является единственным надежным выбором для контекста объемом 1 млн токенов.
- Для чувствительных к задержке задач — Opus: TTFT у Opus составляет всего 0,5 сек., что в 6 раз быстрее GPT — идеально для интерактивного кодинга.
- Для экономии бюджета — GPT: GPT-5.5 расходует на 72% меньше выходных токенов, что снижает общую стоимость выполнения задач.
- Быстрое тестирование: С помощью APIYI (apiyi.com) вы можете вызывать обе модели через один аккаунт для удобного сравнения в реальных условиях.
Итоги
Ключевые выводы из сравнения возможностей программирования GPT-5.5 и Claude Opus 4.7:
- Нет универсального чемпиона: у обеих моделей есть четкие сильные стороны, поэтому слепая погоня за «лучшей моделью» — не самый верный подход.
- Выбор модели на основе задач: сначала определите ваш основной сценарий программирования (исправление багов, агентные задачи, работа с длинным контекстом или интерактивная разработка), а уже потом выбирайте основную модель.
- Рекомендуем параллельное использование: профессиональным командам разработки лучше интегрировать обе модели и направлять запросы в зависимости от сценария — это поможет добиться максимальной эффективности.
Если вам нужно выбрать только одну: для повседневного исправления issue в GitHub и ревью кода лучше подойдет Claude Opus 4.7; если ваш приоритет — агентная автоматизация и анализ больших объемов контекста, выбирайте GPT-5.5.
Рекомендуем быстро проверить модели на платформе APIYI apiyi.com. Она предоставляет унифицированный API для GPT-5.5 и Claude Opus 4.7, бесплатные тестовые лимиты и детальную аналитику по расходам — это самый простой способ принять решение на основе данных.
Рекомендуемые материалы
Если вас заинтересовало сравнение GPT-5.5 и Claude Opus 4.7 в программировании, рекомендуем также почитать:
- 📘 Полный обзор Claude Opus 4.7: Инженерная мощь, стоящая за 87.6% в SWE-bench — глубокий разбор того, за счет чего Opus 4.7 достигает таких результатов.
- 📊 Гайд по тестированию GPT-5.5 Spud: 8 приемов для нового короля агентного программирования — осваиваем продвинутые техники работы с GPT-5.5.
- 🚀 Руководство по выбору AI-моделей для программирования 2026: от GPT до Claude — масштабный взгляд на методологию подбора инструментов разработки.
📚 Справочные материалы
-
Официальный анонс GPT-5.5 от OpenAI: Основные бенчмарки и описание возможностей
- Ссылка:
openai.com/index/introducing-gpt-5-5 - Описание: Официальный документ о релизе GPT-5.5, содержащий данные по основным тестам, таким как SWE-bench и Terminal-Bench.
- Ссылка:
-
Официальный анонс Claude Opus 4.7 от Anthropic: Позиционирование модели и показатели производительности
- Ссылка:
anthropic.com/news/claude-opus-4-7 - Описание: Официальный релиз Opus 4.7 с подробными данными по SWE-bench Verified/Pro.
- Ссылка:
-
Публичный рейтинг SWE-Bench Pro: Независимая проверка
- Ссылка:
labs.scale.com/leaderboard/swe_bench_pro_public - Описание: Публичный рейтинг SWE-Bench Pro, поддерживаемый Scale AI, где можно проверить реальные позиции обеих моделей.
- Ссылка:
-
Vellum LLM Leaderboard 2026: Комплексное сравнение моделей ИИ
- Ссылка:
vellum.ai/llm-leaderboard - Описание: Платформа для комплексного сравнения моделей по таким критериям, как программирование, логический вывод, работа с длинным контекстным окном и другие.
- Ссылка:
-
Сравнение моделей на Artificial Analysis: Анализ производительности и стоимости
- Ссылка:
artificialanalysis.ai/models/comparisons/gpt-5-5-vs-claude-opus-4-7-non-reasoning - Описание: Детальное сравнение данных по времени до первого токена (TTFT), пропускной способности и совокупной стоимости использования.
- Ссылка:
Автор: Техническая команда APIYI
Техническое обсуждение: Приглашаем к дискуссии в комментариях, дополнительные материалы доступны в центре документации APIYI docs.apiyi.com