2026 год стал поворотным моментом для китайских открытых больших языковых моделей: флагманская модель от Moonshot AI — Kimi K2.6 — официально вышла в open source. На бенчмарке SWE-Bench Pro модель набрала 58.6 балла, обойдя GPT-5.4 (57.7) и Claude Opus 4.6 (53.4), и стала самой эффективной моделью для решения реальных задач в GitHub Issue.
В этой статье мы разберем процесс подключения к API Kimi K2.6, подробно рассмотрим её архитектуру 1T MoE, контекстное окно 256K, возможности вызова функций (Function Call) и префиксного кэширования. С помощью готовых примеров кода вы сможете интегрировать API всего за 5 минут. Кроме того, мы сравним стоимость: через сервис-прокси API APIYI (apiyi.com) и официальный канал Huawei Cloud цены составляют $0.60 за ввод и $2.40 за вывод на 1 млн токенов, что примерно на 40% выгоднее официальных цен в ¥6.5 / ¥27.
Основная ценность: прочитав статью, вы узнаете, как вызывать API Kimi K2.6, настраивать инструменты Function Call, оптимизировать кэширование и понимать, когда K2.6 является наиболее экономически оправданным выбором.

Основные сведения об API Kimi K2.6
Kimi K2.6 — это флагманская открытая модель нового поколения, выпущенная Moonshot AI в апреле 2026 года. Она продолжает использовать архитектуру MoE серии Kimi K2 и предлагает значительные улучшения в области кодинга, обработки длинного контекста и вызова инструментов. В таблице ниже собраны ключевые характеристики, важные для разработчиков:
| Характеристика | Спецификация | Практическая ценность |
|---|---|---|
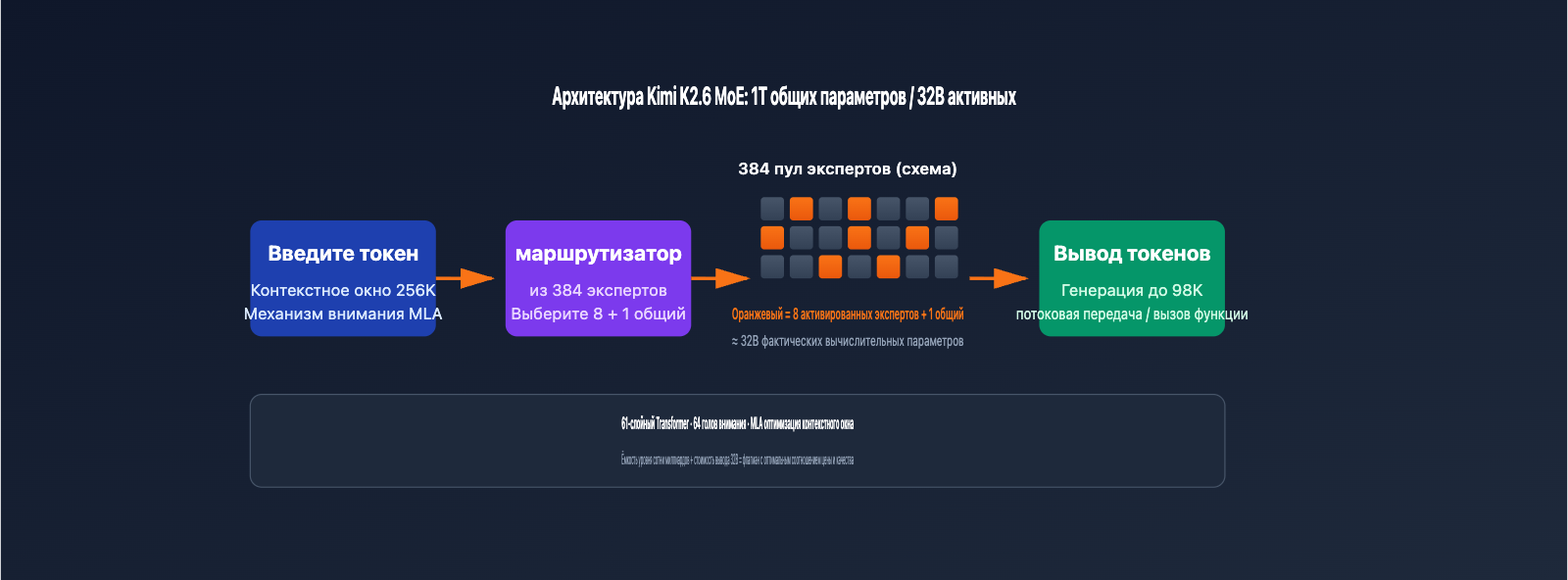
| Архитектура MoE | 1T параметров / 32B активных / 384 эксперта (8 выбора + 1 общий) | Мощность уровня 100B+ при стоимости инференса на уровне модели 32B |
| Контекстное окно | 256K токенов (точно 262,144) | Обработка целых репозиториев кода или огромных юридических документов за раз |
| Максимальный вывод | До 98,304 токенов за один ответ | Идеально для рефакторинга больших блоков кода и генерации документации |
| Мультимодальность | Встроенный визуальный энкодер MoonViT 400M | Нативная поддержка ввода изображений и видео |
| Агентская оркестрация | Agent Swarm: до 300 под-агентов / 4,000 шагов координации | Решение сложных многоэтапных задач разработки |
| Лицензия | Modified MIT License | Удобна для коммерческого использования, без серьезных ограничений |
Подробный обзор возможностей API Kimi K2.6
По сравнению с предыдущим поколением K2.5, модель K2.6 совершила качественный скачок в трех аспектах: во-первых, результат 58.6 балла на SWE-Bench Pro, что впервые позволило превзойти GPT-5.4 и Claude Opus 4.6 в задачах исправления реальных Issue в открытых репозиториях; во-вторых, количество под-агентов в Agent Swarm выросло со 100 до 300, а число шагов координации — с 1500 до 4000, что позволяет брать на себя более длительные цепочки задач; в-третьих, контекст 256K стал доступен всей серии моделей, а технология Multi-head Latent Attention (MLA) заметно снизила потребление видеопамяти и задержки при работе с длинными текстами.
🎯 Технический совет: для реальных задач разработки мы рекомендуем использовать API Kimi K2.6 через платформу APIYI (apiyi.com). Платформа предоставляет доступ к официальной модели через канал Huawei Cloud, полностью совместима с OpenAI SDK, что позволяет переключиться на неё без изменения вашего текущего кода.
Детальный разбор технической архитектуры API Kimi K2.6
Понимание фундаментальной архитектуры Kimi K2.6 поможет вам сделать правильный выбор для различных бизнес-задач. Дизайн этой модели — это баланс между «объемом параметров в сотни миллиардов» и «стоимостью вывода на уровне десятков миллиардов».
Механизм разреженной активации MoE
В Kimi K2.6 используется архитектура смеси экспертов (MoE) с 1 триллионом параметров, состоящая из 384 экспертных сетей. При выводе каждого токена активируются только 8 из них (плюс 1 общий эксперт), что означает, что в вычислениях участвует 32B параметров. Такой подход позволяет модели обладать глубиной знаний, характерной для моделей с сотнями миллиардов параметров, сохраняя при этом скорость вывода уровня 32B. Это делает её одной из самых эффективных флагманских моделей по стоимости вызова API.
Оптимизация длинного контекста
| Технический компонент | Роль | Конфигурация K2.6 |
|---|---|---|
| Multi-head Latent Attention (MLA) | Снижение объема KV-кэша при работе с длинным контекстом | 64 голов внимания |
| Количество слоев | Определяет глубину вывода модели | 61 слой Transformer |
| Контекстное окно | Максимальное количество токенов на один ввод | 262 144 токенов (256K) |
| Позиционное кодирование | Ключевая технология для поддержки сверхдлинных последовательностей | Специально обучена для длинного контекста |
| Префиксный кэш | Кэширование повторных промптов для снижения затрат | Экономия на вводе до 75% при попадании в кэш |
💡 Архитектурный инсайт: В сценариях многоходового диалога или с фиксированным системным промптом использование префиксного кэша позволяет значительно снизить затраты на ввод. Рекомендуем сохранять системный промпт неизменным в продакшене, чтобы максимизировать эффективность кэширования.
Сравнительный анализ производительности API Kimi K2.6
Бенчмарки — это самый наглядный способ понять, стоит ли подключать ту или иную модель к вашему проекту. Ниже представлено сравнение Kimi K2.6, GPT-5.4 и Claude Opus 4.6 по пяти ключевым критериям.
Возможности кодинга и разработки ПО
| Бенчмарк | Kimi K2.6 | GPT-5.4 | Claude Opus 4.6 | Лидер |
|---|---|---|---|---|
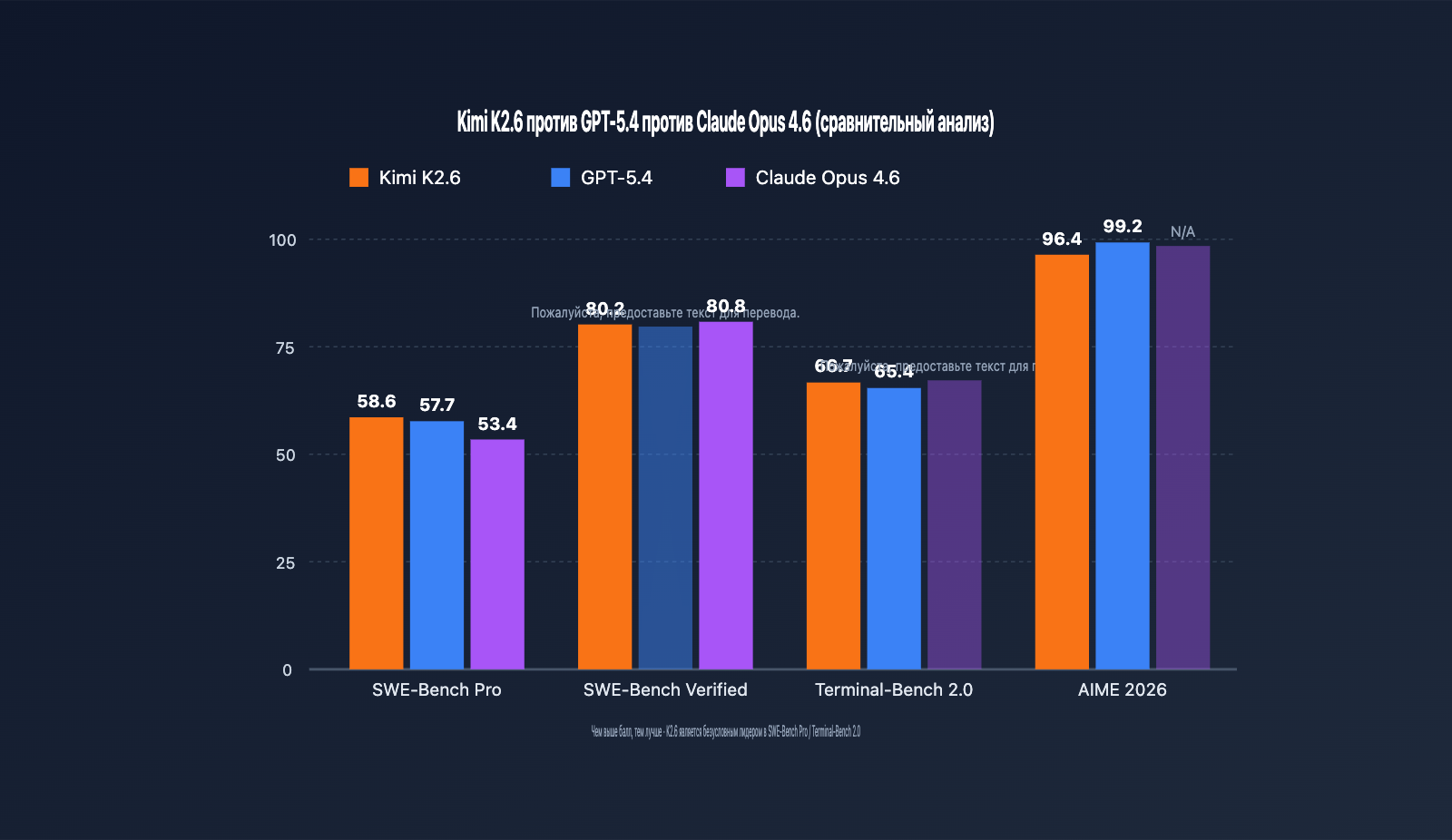
| SWE-Bench Pro | 58.6 | 57.7 | 53.4 | Kimi K2.6 |
| SWE-Bench Verified | 80.2 | — | 80.8 | Claude Opus 4.6 |
| Terminal-Bench 2.0 | 66.7 | 65.4 | — | Kimi K2.6 |
| HLE (with tools) | 54.0 | — | 53.0 | Kimi K2.6 |
| AIME 2026 | 96.4 | 99.2 | — | GPT-5.4 |
| GPQA-Diamond | 90.5 | — | — | — |
Краткие выводы:
- SWE-Bench Pro оценивает способность модели решать реальные GitHub Issue «от и до». K2.6 набрала 58.6 баллов, впервые позволив открытой модели обойти флагманы с закрытым кодом. Это значит, что для задач по поддержке кода и исправлению багов K2.6 сейчас — приоритетный выбор.
- SWE-Bench Verified — это более упрощенная версия, где Claude Opus 4.6 показала результат чуть лучше (80.8 против 80.2). Отрыв невелик, но это показывает, что у Claude сохраняются преимущества в стандартизированных задачах по программированию.
- Terminal-Bench 2.0 тестирует навыки работы с командами в терминале. K2.6 лидирует с 66.7 баллами, что делает её отличным выбором для DevOps и автоматизации эксплуатации.
- AIME / HMMT и другие тесты на математическую логику остаются сильной стороной GPT-5.4. Для сугубо математических сценариев по-прежнему рекомендую оставлять GPT-5.4.
🎯 Рекомендации по применению: Для разных задач стоит проводить A/B-тестирование между моделями. Для сопровождения кода — K2.6, для математических рассуждений — GPT-5.4, а для длинных творческих текстов можно оставить Claude.
Быстрый старт с API Kimi K2.6
Ниже приведено полное руководство по вызову Kimi K2.6. API семейства Kimi полностью совместим с протоколом OpenAI SDK. Если у вас уже есть код для работы с OpenAI, вам достаточно просто заменить base_url и model.
Минимальный пример (Python)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "Вы опытный Python-разработчик."},
{"role": "user", "content": "Реализуй пул конкурентных запросов с использованием asyncio, ограничив максимальную конкурентность до 10."}
],
temperature=0.3,
max_tokens=2048
)
print(response.choices[0].message.content)
Смотреть полный пример асинхронного потокового вызова (с обработкой ошибок)
import asyncio
from openai import AsyncOpenAI
from openai import APIError, RateLimitError
client = AsyncOpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
max_retries=3,
timeout=120.0
)
async def call_kimi_k26_stream(prompt: str, system: str = "") -> str:
"""Потоковый вызов Kimi K2.6 с выводом токенов в реальном времени"""
messages = []
if system:
messages.append({"role": "system", "content": system})
messages.append({"role": "user", "content": prompt})
full_response = ""
try:
stream = await client.chat.completions.create(
model="kimi-k2.6",
messages=messages,
stream=True,
temperature=0.3,
max_tokens=8192
)
async for chunk in stream:
if chunk.choices[0].delta.content:
token = chunk.choices[0].delta.content
print(token, end="", flush=True)
full_response += token
except RateLimitError:
print("\n[Лимит запросов превышен, рекомендуется настроить повторные попытки или обновить тариф]")
raise
except APIError as e:
print(f"\n[Ошибка API: {e}]")
raise
return full_response
async def main():
result = await call_kimi_k26_stream(
prompt="Объясни, как архитектура MoE снижает затраты на вывод",
system="Ты эксперт по AI-архитектуре, отвечай кратко и профессионально"
)
print(f"\n\n[Всего токенов: {len(result)}]")
if __name__ == "__main__":
asyncio.run(main())
🚀 Быстрый старт: Получив API-ключ на платформе APIYI apiyi.com, просто установите
base_urlнаhttps://api.apiyi.com/v1. Все SDK экосистемы OpenAI (Python/Node.js/Go) будут работать «из коробки», интеграция займет не более 5 минут.
Вызов через Node.js / TypeScript
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.APIYI_KEY,
baseURL: "https://api.apiyi.com/v1",
});
const completion = await client.chat.completions.create({
model: "kimi-k2.6",
messages: [
{ role: "user", content: "Напиши на TypeScript функцию debounce с поддержкой дженериков" }
],
temperature: 0.2,
});
console.log(completion.choices[0].message.content);
Прямой вызов через cURL
curl https://api.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_APIYI_KEY" \
-d '{
"model": "kimi-k2.6",
"messages": [
{"role": "user", "content": "Привет, Kimi K2.6"}
],
"max_tokens": 1024
}'
Практическое использование Function Call
Возможность Function Call (вызов инструментов) в K2.6 — это существенное обновление по сравнению с серией K2, демонстрирующее отличные результаты в рейтинге Berkeley Function-Calling Leaderboard. Ниже представлен пример реализации процесса «запроса погоды».
Определение и вызов инструментов
from openai import OpenAI
import json
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Получить текущую погоду в указанном городе",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "Название города"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["city"]
}
}
}
]
def get_weather(city: str, unit: str = "celsius") -> dict:
"""Имитация интерфейса получения погоды"""
return {"city": city, "temperature": 22, "unit": unit, "condition": "солнечно"}
messages = [{"role": "user", "content": "Помоги узнать погоду в Пекине и Шанхае"}]
response = client.chat.completions.create(
model="kimi-k2.6",
messages=messages,
tools=tools,
tool_choice="auto"
)
assistant_msg = response.choices[0].message
messages.append(assistant_msg)
if assistant_msg.tool_calls:
for tool_call in assistant_msg.tool_calls:
args = json.loads(tool_call.function.arguments)
result = get_weather(**args)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": json.dumps(result, ensure_ascii=False)
})
final_response = client.chat.completions.create(
model="kimi-k2.6",
messages=messages
)
print(final_response.choices[0].message.content)
Предварительное заполнение (Partial Mode)
K2.6 поддерживает «предварительное заполнение» в стиле OpenAI, то есть вы можете заранее вставить начало ответа в сообщение assistant, а модель продолжит генерацию с этой позиции. Это полезно для принудительного вывода в формате JSON или соблюдения определенных ограничений:
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "user", "content": "Верни данные ВВП Пекина (2023) в формате JSON"},
{"role": "assistant", "content": '{"city": "Пекин", "year": 2023, "gdp":'}
],
max_tokens=200
)
print(response.choices[0].message.content)
💰 Оптимизация затрат: Для сценариев с длинным системным промптом (например, RAG, Agent) после попадания в кеш префикса стоимость входных токенов снижается примерно на 25%. Это удобно для многоходовых диалогов и задач с часто используемыми шаблонами. Рекомендуем отслеживать показатели попаданий в кеш через панель управления apiyi.com.
Продвинутые возможности API Kimi K2.6
Помимо Function Call, K2.6 предлагает три продвинутых навыка: оркестрация мульти-агентов Agent Swarm, контекстное окно 256K и нативная мультимодальность. Вместе они составляют ядро преимуществ модели в программировании, автоматизации разработки и анализе документов.
Оркестрация мульти-агентов Agent Swarm
Одной из самых ярких особенностей K2.6 является Agent Swarm — возможность планирования до 300 параллельных дочерних агентов для выполнения до 4 000 скоординированных действий. Это делает K2.6 эффективным инструментом для рефакторинга крупных кодовых баз, междокументарного анализа и сложных пайплайнов разработки.
Режимы планирования дочерних агентов
Agent Swarm в K2.6 поддерживает три режима оркестрации:
| Режим оркестрации | Сценарии применения | Кол-во агентов | Шаги координации |
|---|---|---|---|
| Параллельный одноуровневый | Пакетное резюме, Code Review | 10-50 | < 200 |
| Иерархическое планирование | Рефакторинг модулей | 50-150 | 500-1500 |
| Глубокое взаимодействие | Кросс-репозиторные пайплайны | 150-300 | 1500-4000 |
Пример простого планирования агентов
Ниже показано, как K2.6 координирует 5 параллельных агентов для выполнения задачи Code Review:
from openai import OpenAI
import asyncio
import json
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
async def review_module(module_name: str, code: str) -> dict:
"""Дочерний агент для ревью отдельного модуля"""
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "Ты эксперт по Code Review, сфокусированный на безопасности и производительности."},
{"role": "user", "content": f"Проверь модуль {module_name}:\n{code}"}
],
temperature=0.2
)
return {
"module": module_name,
"review": response.choices[0].message.content
}
async def parallel_review(modules: dict) -> list:
"""Параллельное планирование дочерних агентов"""
tasks = [review_module(name, code) for name, code in modules.items()]
return await asyncio.gather(*tasks)
# Основной процесс: координация 5 агентов для ревью 5 модулей
modules = {
"auth.py": "...",
"database.py": "...",
"api_routes.py": "...",
"cache.py": "...",
"logger.py": "..."
}
results = asyncio.run(parallel_review(modules))
for r in results:
print(f"[{r['module']}] {r['review'][:100]}...")
Рекомендации по Agent Swarm
- Контроль гранулярности: Один дочерний агент обрабатывает 5K-20K токенов; слишком большие объемы повышают накладные расходы.
- Изоляция ошибок: Используйте try/except для каждого агента, чтобы избежать каскадных сбоев.
- Агрегация результатов: Назначьте «главного агента» для сбора и перекрестной проверки выводов всех подопечных.
- Тайм-ауты: Таймаут агента — 60-120 с, общий тайм-аут основного процесса — 10-30 мин.
- Rate Limiting: Используйте семафоры для ограничения конкурентности, чтобы не превысить лимиты API.
Контекстное окно 256K
Поддержка 256K (262 144 токенов) — ключевое преимущество K2.6. Это соответствует примерно 400-500 тыс. иероглифов, что позволяет загрузить в модель целую техническую книгу или кодовую базу среднего размера.
Использование длинного контекста
import os
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def load_repo_files(repo_path: str, extensions=(".py", ".ts", ".md")) -> str:
"""Загрузка всех файлов из репозитория с указанными расширениями"""
contents = []
for root, _, files in os.walk(repo_path):
for f in files:
if f.endswith(extensions):
full_path = os.path.join(root, f)
with open(full_path, "r", encoding="utf-8") as fp:
contents.append(f"## {full_path}\n```\n{fp.read()}\n```")
return "\n\n".join(contents)
repo_text = load_repo_files("./my_project")
print(f"Оценка токенов в репозитории: {len(repo_text) // 2}")
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "Ты опытный архитектор, специализирующийся на анализе кода."},
{"role": "user", "content": f"Проанализируй архитектуру проекта и предложи рефакторинг:\n{repo_text}"}
],
temperature=0.3,
max_tokens=8192
)
print(response.choices[0].message.content)
Баланс между стоимостью и производительностью длинного контекста
| Масштаб входных данных | Оценка стоимости | Задержка (первый токен) | Сценарий |
|---|---|---|---|
| 8K | $0.005 | 1-2 сек | Анализ одного файла |
| 32K | $0.019 | 3-5 сек | Модульный ревью |
| 100K | $0.06 | 8-15 сек | Анализ среднего репозитория |
| 200K | $0.12 | 18-30 сек | Крупный репозиторий / Книга |
| 256K (полная загрузка) | $0.154 | 25-40 сек | Экстремально длинные документы |
🎯 Совет: В сценариях RAG разбивайте системный промпт на «фиксированные инструкции» и «динамический контент». После кеширования фиксированной части последующие вызовы будут дешевле. Это может снизить общую стоимость на 40-60%.
Мультимодальный визуальный вызов
K2.6 оснащена визуальным энкодером MoonViT (400 млн параметров), обеспечивающим нативную поддержку изображений и видео. Мультимодальный интерфейс также полностью совместим с протоколом OpenAI:
from openai import OpenAI
import base64
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def encode_image(image_path: str) -> str:
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
image_b64 = encode_image("./architecture_diagram.png")
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Проанализируй схему архитектуры и найди потенциальные точки отказа"},
{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{image_b64}"}
}
]
}
],
max_tokens=2048
)
print(response.choices[0].message.content)
Сценарии использования мультимодальности:
- Анализ схем и диаграмм, рекомендации по улучшению
- Обзор UI-дизайнов и генерация кода
- Понимание скриншотов технической документации
- Извлечение данных из графиков и таблиц
- Визуальный контроль качества в производстве
Миграция на API Kimi K2.6 и оптимизация производительности
Если ваш проект сейчас использует OpenAI, K2.5 или модели других производителей, переход на K2.6 обычно требует всего 3-5 строк кода. При этом грамотная настройка параллелизма и кэширования поможет вам извлечь максимум выгоды из ценовых преимуществ K2.6.
Миграция с серии OpenAI GPT
# Исходный код (OpenAI)
client = OpenAI(api_key="OPENAI_KEY")
response = client.chat.completions.create(
model="gpt-5.4",
messages=[...]
)
# Переход на K2.6 (нужно изменить только base_url и model)
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[...]
)
Миграция с Kimi K2 / K2.5
У моделей серии K2 разные идентификаторы, но протокол API полностью идентичен:
| Идентификатор старой модели | Новый идентификатор | Статус поддержки |
|---|---|---|
kimi-k2 |
kimi-k2.6 |
Отключение: 25.05.2026 |
kimi-k2.5 |
kimi-k2.6 |
Поддерживается, рекомендуется обновление |
moonshot-v1-128k |
kimi-k2.6 |
Отключение: в течение 2026 года |
Проверка совместимости перед миграцией
Перед переходом рекомендуем проверить следующие параметры:
- Лимит max_tokens: K2.6 выдает до 98K токенов за раз. Если в коде жестко прописано ограничение в 8K, его можно увеличить.
- Диапазон temperature: Для K2.6 оптимальным считается значение 0.1–0.7; слишком высокие значения могут негативно сказаться на качестве кода.
- Последовательности остановки (stop sequences): K2.6 поддерживает кастомные стоп-символы, аналогично OpenAI.
- Поведение tool_choice: В режиме
autoK2.6 охотнее вызывает инструменты. Если нужно ограничить это поведение, установитеnoneили укажите конкретный инструмент. - Потоковый протокол: Формат SSE полностью идентичен, изменения во фронтенде не требуются.
Лучшие практики по оптимизации
Оптимизация скорости вызовов
| Что оптимизируем | Как реализовать | Ожидаемый эффект |
|---|---|---|
| Параллельные запросы | Использовать AsyncOpenAI + asyncio.gather | Пропускная способность +300-1000% |
| Потоковый вывод | Включить stream=True | Снижение задержки первого байта на 70% |
| Кэширование префикса | Зафиксировать системный промпт | Экономия на входе до 75% |
| Оптимальный max_tokens | Устанавливать лимит под задачу | Снижение задержки на 30% |
| Управление температурой | Для задач с кодом temp=0.2 | Повышение стабильности ответов |
Обработка ошибок
from openai import OpenAI, APIError, RateLimitError, APITimeoutError
import time
def call_with_retry(prompt: str, max_retries: int = 3):
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
timeout=120.0
)
for attempt in range(max_retries):
try:
return client.chat.completions.create(
model="kimi-k2.6",
messages=[{"role": "user", "content": prompt}]
)
except RateLimitError:
wait = 2 ** attempt
print(f"Лимит запросов, повтор через {wait}с")
time.sleep(wait)
except APITimeoutError:
print(f"Тайм-аут, попытка {attempt+1}")
except APIError as e:
print(f"Ошибка API: {e}")
if attempt == max_retries - 1:
raise
raise Exception("Достигнуто максимальное количество попыток")
Преимущества цены и выбор сценариев для API Kimi K2.6
Цена — фактор, который нельзя игнорировать. В таблице ниже приведено сравнение цен (за 1 млн токенов):
| Канал вызова | Цена на входе | Цена на выходе | Примечание |
|---|---|---|---|
| Офиц. площадка Kimi | ¥6.5 (~$0.95) | ¥27 (~$4.00) | Официальные цены |
| APIYI (через Huawei Cloud) | $0.60 | $2.40 | ~60% от цены на сайте |
| OpenRouter (Parasail) | $0.60 | $2.40+ | Сторонний канал |
| GPT-5.4 (справ.) | $2.50 | $15.00 | В 4-6 раз дороже K2.6 |
| Claude Opus 4.6 (справ.) | $15.00 | $75.00 | В 25+ раз дороже K2.6 |
Оценка реальных затрат
Для примера: повседневный помощник программиста (в сессии: 5K входных / 2K выходных токенов), 100 тыс. вызовов в месяц:
| Модель | Вход (месяц) | Выход (месяц) | Итого в месяц |
|---|---|---|---|
| Kimi K2.6 (APIYI) | $300 | $480 | $780 |
| GPT-5.4 | $1,250 | $3,000 | $4,250 |
| Claude Opus 4.6 | $7,500 | $15,000 | $22,500 |
Итог: В задачах программирования, работы агентов и анализа больших данных K2.6 сопоставим с GPT-5.4/Claude Opus 4.6, но обходится в 5-30 раз дешевле. Это идеальный вариант для команд с ограниченным бюджетом.
🎯 Рекомендация по выбору: Выбор модели зависит от ваших задач и требований к качеству. Мы советуем провести тестирование через платформу APIYI (apiyi.com). Платформа предоставляет единый интерфейс для Kimi K2.6, GPT-5.4, Claude Opus 4.6 и других моделей, что упрощает сравнение.
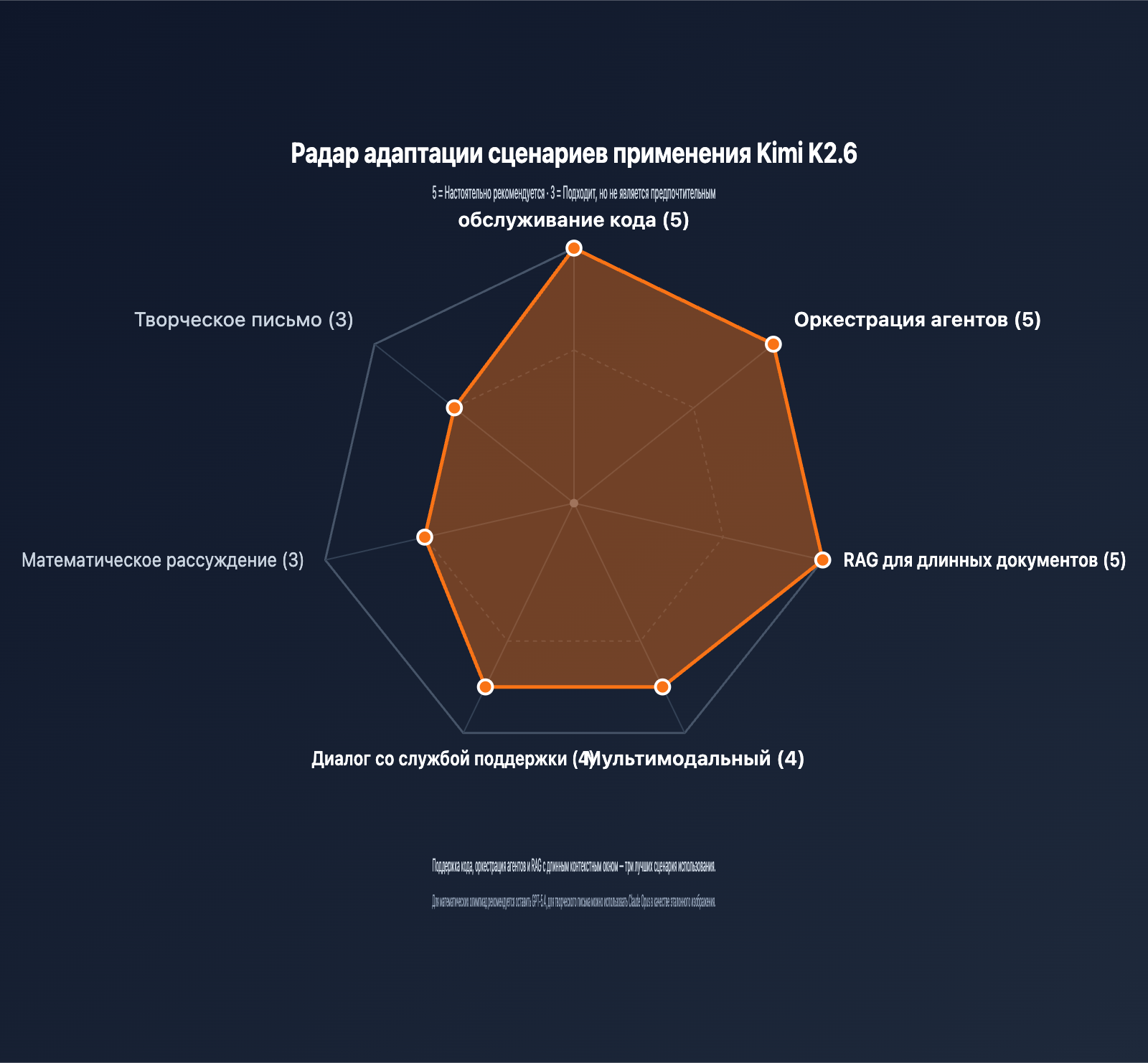
Рекомендуемые сценарии применения
| Сценарий применения | Рейтинг | Почему это выгодно |
|---|---|---|
| Поддержка и рефакторинг кода | ⭐⭐⭐⭐⭐ | 1-е место в SWE-Bench Pro, 256K хватает на крупные репозитории |
| Оркестрация агентов | ⭐⭐⭐⭐⭐ | Поддержка 300 под-агентов, отлично для сложных рабочих процессов |
| Анализ длинных документов | ⭐⭐⭐⭐⭐ | Контекст 256K + оптимизация MLA, высокая экономичность |
| Мультимодальность | ⭐⭐⭐⭐ | Родной MoonViT, распознавание изображений из коробки |
| Поддержка и чат-боты | ⭐⭐⭐⭐ | Отличный Function Call, кэширование снижает расходы |
| Математические вычисления | ⭐⭐⭐ | AIME 96.4 балла — достойно, но GPT-5.4 чуть сильнее |
| Креативный текст | ⭐⭐⭐ | Естественный китайский, но стилистически уступает Claude |
Частые вопросы
Q1: В чем основные отличия Kimi K2.6 API от K2.5 / K2?
Модель K2.6 получила серьезные улучшения по трем направлениям: 1) В бенчмарке SWE-Bench Pro показатель вырос с 53 баллов (у K2.5) до 58.6, впервые обойдя GPT-5.4 и Claude Opus 4.6; 2) Количество субагентов Agent Swarm увеличено со 100 до 300, а шаги координации — с 1500 до 4000; 3) Для всей серии открыто контекстное окно 256K (ранее некоторые варианты K2 поддерживали только 128K). Согласно официальному анонсу Kimi, ранняя версия K2 будет отключена 25 мая 2026 года, поэтому новые проекты следует сразу подключать к K2.6 (идентификатор модели kimi-k2.6), которая полностью совместима с SDK OpenAI.
Q2: Полностью ли совместим Kimi K2.6 API с OpenAI SDK?
Да. При вызове через такие сервисы, как APIYI, протокол API полностью соответствует интерфейсу chat completions от OpenAI, включая поддержку потоковой передачи (streaming), инструментов (Function Call), tool_choice, temperature, top_p, max_tokens и других параметров. Для перехода в популярных SDK (Python, Node.js, Go) достаточно изменить только base_url и model. Обратите внимание, что максимальный объем вывода K2.6 составляет 98 304 токена, что значительно больше, чем 16K у GPT-5.
Q3: Как обстоят дела с задержкой и стоимостью при работе с контекстом 256K в K2.6?
Благодаря технологии Multi-head Latent Attention (MLA) в K2.6 удалось существенно оптимизировать объем KV-кэша для длинного контекста. Практические тесты показывают, что при вводе 100K токенов задержка до первого токена составляет около 8–15 секунд (в зависимости от нагрузки на сервер), после чего токены начинают поступать в потоковом режиме. Что касается стоимости, то при цене $0.60 за 1 млн токенов ввод 256K обойдется примерно в $0.15 за один запрос. При многоходовых диалогах с тем же системным промптом, после попадания в кэш префикса, затраты на ввод снижаются примерно на 25%. Перед запуском в продакшн мы рекомендуем провести сквозное тестирование на ваших типичных промптах и отслеживать логи потребления токенов для оптимизации расходов.
Q4: Чем отличается Function Call в K2.6 от инструментов в GPT-5 / Claude?
Интерфейсно все идентично (протокол tools в стиле OpenAI), но внутренние возможности различаются: 1) K2.6 поддерживает 300 параллельных субагентов, что дает преимущество при сложной оркестрации инструментов; 2) K2.6 находится в топе Berkeley Function-Calling Leaderboard, приближаясь к уровню GPT-5; 3) K2.6 поддерживает дописывание префикса (Partial Mode), что позволяет принудительно задавать формат вывода JSON и снижать частоту ошибок при вызове инструментов. Для сложных агентских цепочек K2.6 — выбор с лучшим соотношением цены и качества.
Q5: Является ли вызов K2.6 через APIYI официальным? Безопасны ли данные?
APIYI подключается к официальным моделям Kimi через авторизованные шлюзы Huawei Cloud. Это полностью легальный канал: веса модели и результаты вывода идентичны официальным. Передача данных защищена шифрованием HTTPS, платформа не сохраняет содержимое запросов. Для корпоративных клиентов предусмотрены функции безопасности: отдельные субаккаунты, разграничение прав API-ключей, лимиты потребления и т.д. Подробные правила можно найти на странице комплаенса apiyi.com.
Q6: Для каких проектов подходит K2.6? Когда стоит выбрать GPT-5.4 или Claude?
Сценарии для K2.6: ассистенты для программирования, задачи SWE, RAG с длинным контекстом, агентская оркестрация, чувствительные к бюджету проекты. Сценарии для GPT-5.4: сложные математические олимпиады (AIME/HMMT), исследовательские задачи, требующие глубоких рассуждений. Сценарии для Claude Opus 4.6: длинные творческие тексты, генерация контрактов и юридических документов с жесткими требованиями к формату. Рекомендуем проектировать архитектуру с возможностью переключения между моделями, чтобы проводить сравнительное тестирование под конкретные задачи.
Резюме
Kimi K2.6 — важная веха в мире больших языковых моделей 2026 года. Она доказывает, что архитектура MoE (смесь экспертов) с сотнями миллиардов параметров может на равных конкурировать с закрытыми флагманами в написании кода, агентных задачах и работе с длинным контекстом. Результат 58.6 в SWE-Bench Pro, а также инженерные возможности (256K контекста и 300 субагентов) делают эту модель отличным выбором для кодинг-ассистентов и проектов по автоматизации разработки.
Ключевые моменты:
- Архитектурное преимущество: 1T MoE / 32B активных параметров — мощность уровня 100B моделей при стоимости вывода 32B.
- Лидерство в бенчмарках: первые места в SWE-Bench Pro, Terminal-Bench 2.0 и HLE.
- Выгодная цена: через APIYI стоимость составляет $0.60 / $2.40, что примерно на 40% дешевле официального сайта.
- Экосистема: полная совместимость с OpenAI SDK, миграция занимает 5 минут.
- Инженерная мощь: 256K контекста + 300 субагентов + кэширование префиксов.
Для команд, создающих AI-продукты в 2026 году, Kimi K2.6 API — это крайне конкурентоспособное решение по производительности, стоимости и экосистеме. Рекомендуем протестировать модель на платформе APIYI (apiyi.com), сравнить ее поведение с другими моделями в ваших бизнес-сценариях и принять взвешенное решение.
Автор: Техническая команда APIYI | Мы следим за миром больших языковых моделей и приглашаем вас к техническому обсуждению и консультациям на сайте APIYI apiyi.com.