O ecossistema de Modelos de Linguagem Grande open-source atingiu um marco importante em 2026 com o lançamento oficial do Kimi K2.6, o modelo carro-chefe da Moonshot AI. Com uma pontuação de 58,6 no benchmark SWE-Bench Pro, superando o GPT-5.4 (57,7) e o Claude Opus 4.6 (53,4), ele se tornou o modelo invocável mais eficiente para a resolução de Issues reais do GitHub.
Este artigo explora o fluxo de integração da API Kimi K2.6, detalhando sua arquitetura MoE de 1T, a janela de contexto de 256K, as capacidades de Function Call e o preenchimento de prefixo, além de oferecer exemplos de código completos para você integrar a API em menos de 5 minutos. Comparado ao faturamento oficial, o APIYI (apiyi.com), através do canal oficial da Huawei Cloud, oferece taxas de $0,60 para entrada / $2,40 para saída por 1 milhão de tokens — aproximadamente 60% do custo oficial.
Valor central: Ao ler este artigo, você dominará o método de invocação da API Kimi K2.6, a orquestração de ferramentas (Function Call), técnicas de otimização de cache de prefixo e saberá quando o K2.6 é a escolha com melhor custo-benefício.

Pontos-chave da API Kimi K2.6
O Kimi K2.6 é a nova geração de Modelo de Linguagem Grande open-source lançado pela Moonshot AI em abril de 2026. Ele mantém a arquitetura MoE da série Kimi K2, apresentando melhorias significativas em codificação, contexto longo e invocação de ferramentas. A tabela abaixo resume as especificações principais:
| Item | Especificação Detalhada | Valor Prático |
|---|---|---|
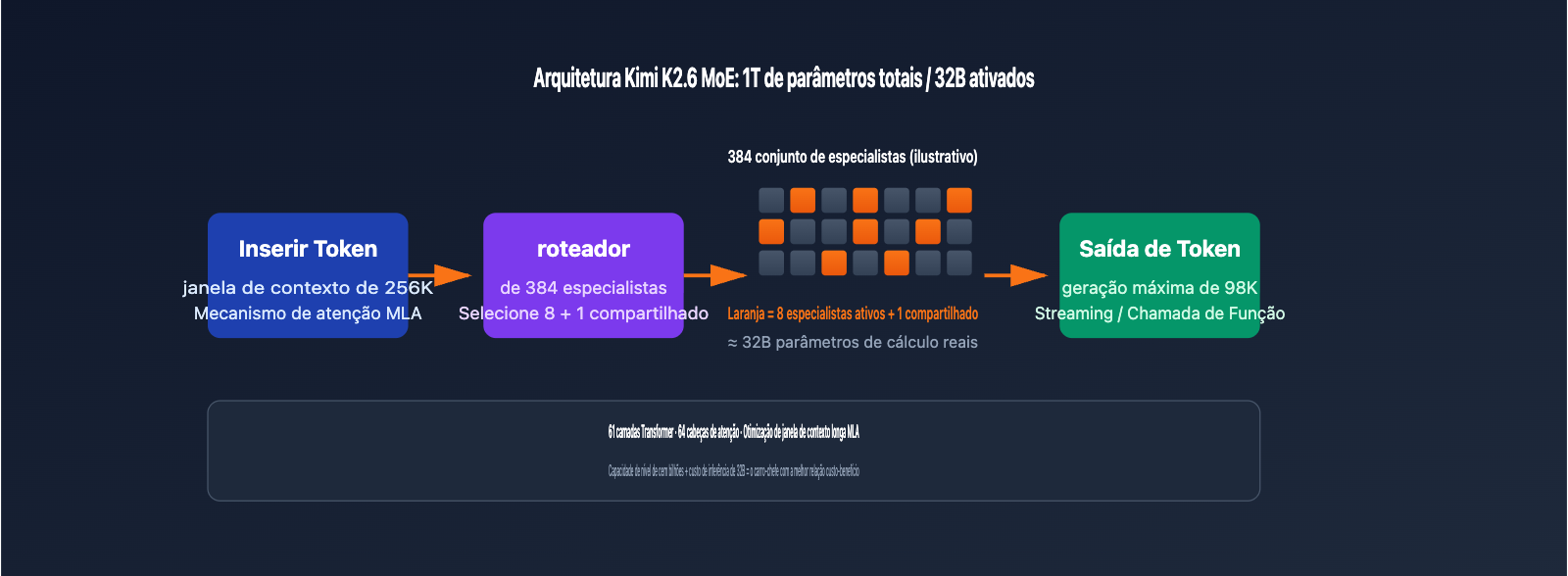
| Arquitetura MoE | 1T parâmetros totais / 32B ativos / 384 especialistas (8 seleções + 1 compartilhado) | Capacidade de centenas de bilhões, custo de inferência equivalente a um modelo de 32B |
| Janela de Contexto | 256K tokens (exatos 262.144) | Processamento de repositórios de código extensos ou documentos jurídicos em uma única vez |
| Geração Máxima | Até 98.304 tokens por saída | Atende cenários de refatoração de código longo e geração de documentos |
| Capacidade Multimodal | Codificador visual MoonViT de 400M integrado | Suporte nativo para entrada de imagens e vídeos |
| Orquestração de Agentes | Agent Swarm suporta 300 subagentes / 4.000 passos de coordenação | Capacidade para processos complexos de P&D de várias etapas |
| Licença Open-source | Licença MIT Modificada | Amigável para uso comercial, sem restrições significativas |
Detalhes das capacidades da API Kimi K2.6
Comparado à geração anterior K2.5, o K2.6 apresenta avanços saltatórios em três dimensões: primeiro, o SWE-Bench Pro superou 58,6 pontos, vencendo o GPT-5.4 e o Claude Opus 4.6 em tarefas de resolução de Issues em repositórios open-source reais; segundo, o número de subagentes Agent Swarm aumentou de 100 para 300, e os passos de coordenação subiram de 1.500 para 4.000; terceiro, a janela de 256K está aberta para toda a série, reduzindo significativamente os custos de memória de vídeo e latência para inferências de contexto longo através do Multi-head Latent Attention (MLA).
🎯 Dica técnica: Para o desenvolvimento real, recomendamos chamar o Kimi K2.6 diretamente através da plataforma APIYI (apiyi.com). Esta plataforma integra o modelo oficial através do canal da Huawei Cloud, é totalmente compatível com o SDK da OpenAI e permite alternar modelos sem a necessidade de modificar o código existente.
Explicação Detalhada da Arquitetura Técnica da API Kimi K2.6
Compreender a arquitetura de base do Kimi K2.6 ajuda a tomar decisões de escolha adequadas em diferentes cenários de negócios. Seu design de arquitetura equilibra a "capacidade de parâmetros em escala de trilhões" com um "custo de inferência em escala de bilhões".
Mecanismo de Ativação Escassa MoE
O Kimi K2.6 adota uma arquitetura de Mistura de Especialistas (MoE) com 1 trilhão de parâmetros, contendo 384 redes especialistas. Durante a inferência de cada token, apenas 8 especialistas são ativados (mais 1 especialista compartilhado), o que significa que 32B de parâmetros participam do cálculo. Esse design permite que o modelo possua a amplitude de conhecimento de um modelo de escala de trilhões, mantendo a velocidade de inferência de um nível de 32B, sendo um dos modelos carro-chefe com melhor relação custo-benefício em termos de invocação do modelo atualmente.
Otimização de Longo Contexto
| Componente Técnico | Função | Configuração K2.6 |
|---|---|---|
| Multi-head Latent Attention (MLA) | Reduz o volume do KV cache na inferência de longo contexto | 64 cabeças de atenção |
| Camadas de rede | Determina a profundidade da inferência do modelo | 61 camadas Transformer |
| Janela de contexto | Número máximo de tokens por entrada única | 262.144 tokens (256K) |
| Codificação posicional | Tecnologia chave para suporte a sequências ultra longas | Treinado especificamente para longo contexto |
| Cache de prefixo | Aproveita o cache em comandos repetidos, reduzindo custos | O custo de entrada cai cerca de 75% após o acerto |
💡 Insight de Arquitetura: Em cenários de diálogo multirrodada ou com comando de sistema fixo, o cache de prefixo pode reduzir significativamente os custos de entrada. Recomendamos manter o comando de sistema estável no ambiente de produção para maximizar a taxa de acerto do cache.
Comparativo de Benchmark de Desempenho da API Kimi K2.6
Para determinar se um modelo vale a pena ser integrado, os testes de benchmark são a base mais intuitiva. Abaixo comparamos o desempenho do Kimi K2.6, GPT-5.4 e Claude Opus 4.6 em cinco benchmarks de autoridade.
Capacidade de Codificação e Engenharia de Software
| Benchmark | Kimi K2.6 | GPT-5.4 | Claude Opus 4.6 | Modelo Superior |
|---|---|---|---|---|
| SWE-Bench Pro | 58.6 | 57.7 | 53.4 | Kimi K2.6 |
| SWE-Bench Verified | 80.2 | – | 80.8 | Claude Opus 4.6 |
| Terminal-Bench 2.0 | 66.7 | 65.4 | – | Kimi K2.6 |
| HLE (com ferramentas) | 54.0 | – | 53.0 | Kimi K2.6 |
| AIME 2026 | 96.4 | 99.2 | – | GPT-5.4 |
| GPQA-Diamond | 90.5 | – | – | – |
Interpretação Chave:
- SWE-Bench Pro mede a capacidade de resolução de ponta a ponta de Issues reais do GitHub. O K2.6 obteve 58,6 pontos, fazendo com que um modelo aberto supere, pela primeira vez, os modelos fechados carro-chefe neste benchmark, o que significa que o K2.6 deve ser priorizado para manutenção de código e tarefas de correção de bugs.
- SWE-Bench Verified é uma versão relativamente simplificada, onde o Claude Opus 4.6 superou ligeiramente (80,8 vs 80,2). A diferença é pequena, mas indica que o Claude ainda possui vantagem em tarefas de codificação padronizadas.
- Terminal-Bench 2.0 testa a capacidade de orquestração de comandos de terminal. A pontuação de 66,7 do K2.6 lidera, tornando-o adequado para cenários de DevOps e operações automatizadas.
- AIME / HMMT e outros raciocínios matemáticos puros ainda são o ponto forte do GPT-5.4; sugerimos manter a opção do GPT-5.4 para cenários puramente matemáticos.
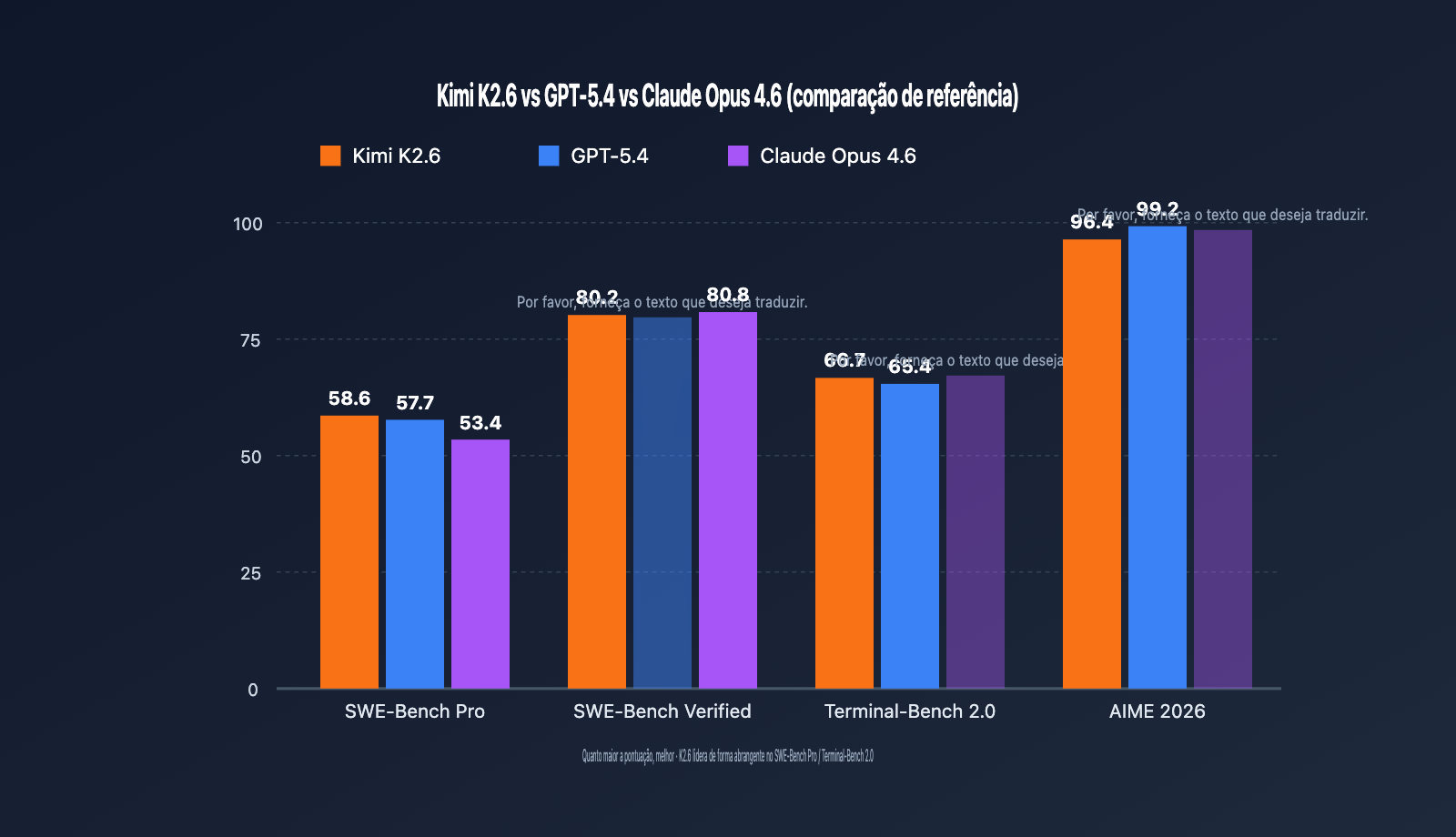
🎯 Sugestão de Cenário: Recomendamos testes A/B entre modelos para diferentes tarefas — K2.6 para manutenção de código, GPT-5.4 para raciocínio matemático, e pode-se manter a opção do Claude para escrita criativa longa.
Guia de Início Rápido da API Kimi K2.6
A seguir, apresentamos um código completo para demonstrar como invocar o Kimi K2.6. A série de APIs Kimi é totalmente compatível com o protocolo SDK da OpenAI; se você já possui um código de invocação da OpenAI, basta substituir a base_url e o model.
Exemplo Minimalista (Python)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "Você é um engenheiro Python sênior."},
{"role": "user", "content": "Implemente um pool de solicitações concorrentes usando asyncio, limitando a concorrência máxima a 10."}
],
temperature=0.3,
max_tokens=2048
)
print(response.choices[0].message.content)
Ver exemplo completo de invocação assíncrona por streaming (com tratamento de erros)
import asyncio
from openai import AsyncOpenAI
from openai import APIError, RateLimitError
client = AsyncOpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
max_retries=3,
timeout=120.0
)
async def call_kimi_k26_stream(prompt: str, system: str = "") -> str:
"""Invoca o Kimi K2.6 via streaming e exibe os tokens em tempo real"""
messages = []
if system:
messages.append({"role": "system", "content": system})
messages.append({"role": "user", "content": prompt})
full_response = ""
try:
stream = await client.chat.completions.create(
model="kimi-k2.6",
messages=messages,
stream=True,
temperature=0.3,
max_tokens=8192
)
async for chunk in stream:
if chunk.choices[0].delta.content:
token = chunk.choices[0].delta.content
print(token, end="", flush=True)
full_response += token
except RateLimitError:
print("\n[Limite de taxa atingido, recomenda-se configurar novas tentativas ou fazer upgrade do plano]")
raise
except APIError as e:
print(f"\n[Erro de API: {e}]")
raise
return full_response
async def main():
result = await call_kimi_k26_stream(
prompt="Explique como a arquitetura MoE reduz o custo de inferência",
system="Você é um especialista em arquitetura de IA, responda de forma concisa e profissional"
)
print(f"\n\n[Contagem total de tokens: {len(result)}]")
if __name__ == "__main__":
asyncio.run(main())
🚀 Início Rápido: Após obter sua chave API pela plataforma APIYI (apiyi.com), basta definir a
base_urlcomohttps://api.apiyi.com/v1. Todos os SDKs do ecossistema OpenAI (Python/Node.js/Go) podem ser usados diretamente, permitindo a integração em apenas 5 minutos.
Invocação em Node.js / TypeScript
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.APIYI_KEY,
baseURL: "https://api.apiyi.com/v1",
});
const completion = await client.chat.completions.create({
model: "kimi-k2.6",
messages: [
{ role: "user", content: "Escreva uma função debounce em TypeScript com suporte a genéricos" }
],
temperature: 0.2,
});
console.log(completion.choices[0].message.content);
Invocação Direta via cURL
curl https://api.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_APIYI_KEY" \
-d '{
"model": "kimi-k2.6",
"messages": [
{"role": "user", "content": "Olá, Kimi K2.6"}
],
"max_tokens": 1024
}'
Prática de Invocação de Ferramentas (Function Call)
A capacidade de Function Call do K2.6 é um avanço significativo em relação à série K2, apresentando excelente desempenho no Berkeley Function-Calling Leaderboard. Abaixo, demonstramos o fluxo de orquestração de ferramentas com um exemplo de "consulta meteorológica".
Definição e Invocação de Ferramenta
from openai import OpenAI
import json
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Consulta o clima em tempo real para uma cidade específica",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "Nome da cidade"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["city"]
}
}
}
]
def get_weather(city: str, unit: str = "celsius") -> dict:
"""Interface simulada de consulta meteorológica"""
return {"city": city, "temperature": 22, "unit": unit, "condition": "ensolarado"}
messages = [{"role": "user", "content": "Ajude-me a verificar o clima em Pequim e Xangai"}]
response = client.chat.completions.create(
model="kimi-k2.6",
messages=messages,
tools=tools,
tool_choice="auto"
)
assistant_msg = response.choices[0].message
messages.append(assistant_msg)
if assistant_msg.tool_calls:
for tool_call in assistant_msg.tool_calls:
args = json.loads(tool_call.function.arguments)
result = get_weather(**args)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": json.dumps(result, ensure_ascii=False)
})
final_response = client.chat.completions.create(
model="kimi-k2.6",
messages=messages
)
print(final_response.choices[0].message.content)
Continuação de Prefixo (Partial Mode)
O K2.6 suporta a "continuação de prefixo" ao estilo OpenAI, ou seja, você preenche previamente o início na mensagem do assistente, e o modelo continua a geração a partir dessa posição. Comum para forçar saída JSON ou restrições de formato específico:
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "user", "content": "Retorne os dados do PIB de Pequim em formato JSON (2023)"},
{"role": "assistant", "content": '{"city": "Pequim", "year": 2023, "gdp":'}
],
max_tokens=200
)
print(response.choices[0].message.content)
💰 Otimização de Custos: Para cenários com system prompt longo (como RAG e agentes), após o hit do cache de prefixo, o preço de entrada cai cerca de 25%, sendo ideal para diálogos de várias rodadas e modelos fixos de alta frequência. Recomendamos ativar o monitoramento de cache em nível de conta na plataforma apiyi.com para observar a taxa de sucesso em tempo real.
Recursos Avançados da API Kimi K2.6
Além do Function Call, o K2.6 oferece três recursos avançados: orquestração multiagentes (Agent Swarm), janela de contexto de 256K e multimodalidade nativa, que juntos formam sua vantagem competitiva em codificação, automação de P&D e análise de documentos.
Orquestração Multiagentes (Agent Swarm)
Um dos recursos mais distintos do K2.6 é o Agent Swarm — uma única tarefa pode coordenar até 300 subagentes paralelos e executar 4.000 etapas de coordenação. Este recurso destaca o K2.6 em refatoração de bases de código grandes, análise de referência cruzada de múltiplos documentos e pipelines complexos de P&D.
Modos de Agendamento de Subagentes
O Agent Swarm do K2.6 suporta três modos típicos de orquestração:
| Modo de Orquestração | Cenários Aplicáveis | Nº de Subagentes | Etapas de Coordenação |
|---|---|---|---|
| Paralelo simples | Resumos em lote de documentos, revisão de código | 10-50 | < 200 |
| Agendamento hierárquico | Refatoração de código com múltiplos módulos | 50-150 | 500-1500 |
| Colaboração profunda | Pipeline de agentes entre repositórios | 150-300 | 1500-4000 |
Exemplo simples de agendamento de agentes
Abaixo, demonstramos como usar o K2.6 para coordenar 5 subagentes paralelos na conclusão de uma tarefa de revisão de código:
from openai import OpenAI
import asyncio
import json
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
async def review_module(module_name: str, code: str) -> dict:
"""Subagente de revisão de módulo individual"""
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "Você é um especialista em revisão de código, focado em segurança e desempenho."},
{"role": "user", "content": f"Revise o módulo {module_name}:\n{code}"}
],
temperature=0.2
)
return {
"module": module_name,
"review": response.choices[0].message.content
}
async def parallel_review(modules: dict) -> list:
"""Agenda múltiplos subagentes em paralelo"""
tasks = [review_module(name, code) for name, code in modules.items()]
return await asyncio.gather(*tasks)
# Fluxo principal: coordena 5 subagentes para revisar 5 módulos
modules = {
"auth.py": "...",
"database.py": "...",
"api_routes.py": "...",
"cache.py": "...",
"logger.py": "..."
}
results = asyncio.run(parallel_review(modules))
for r in results:
print(f"[{r['module']}] {r['review'][:100]}...")
Melhores práticas para o Agent Swarm
- Controle de granularidade de tarefa: Um único subagente processa 5K-20K tokens; volumes muito altos causam overhead de coordenação.
- Isolamento de erro: Use try/except independente para cada subagente para evitar falhas em cascata.
- Agregação de resultados: Configure um "agente principal" para coletar os resultados e realizar a validação cruzada.
- Gerenciamento de timeout: timeout de 60-120 segundos por subagente e 10-30 minutos para o agente principal.
- Controle de taxa: Use semáforos para limitar a concorrência máxima e evitar gatilhos de limitação da API.
Prática de Contexto Longo de 256K
O contexto de 256K (262.144 tokens) é o principal diferencial do K2.6. Isso equivale a aproximadamente 400.000 a 500.000 caracteres, permitindo acomodar grandes bases de código ou livros técnicos completos de uma só vez.
Uso típico de contexto longo
import os
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def load_repo_files(repo_path: str, extensions=(".py", ".ts", ".md")) -> str:
"""Carrega todos os arquivos com extensões especificadas no repositório"""
contents = []
for root, _, files in os.walk(repo_path):
for f in files:
if f.endswith(extensions):
full_path = os.path.join(root, f)
with open(full_path, "r", encoding="utf-8") as fp:
contents.append(f"## {full_path}\n```\n{fp.read()}\n```")
return "\n\n".join(contents)
repo_text = load_repo_files("./meu_projeto")
print(f"Estimativa total de tokens do repo: {len(repo_text) // 2}") # Chinês 1 token≈2 caracteres
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "Você é um arquiteto sênior especializado em análise de grandes bases de código."},
{"role": "user", "content": f"Analise a arquitetura do seguinte projeto e forneça sugestões de refatoração:\n{repo_text}"}
],
temperature=0.3,
max_tokens=8192
)
print(response.choices[0].message.content)
Trade-offs de custo e desempenho em contexto longo
| Escala de entrada | Custo estimado/execução | Latência do 1º token | Cenários aplicáveis |
|---|---|---|---|
| 8K | $0,005 | 1-2 seg | Análise de arquivo único |
| 32K | $0,019 | 3-5 seg | Revisão de nível de módulo |
| 100K | $0,06 | 8-15 seg | Análise de repositório médio |
| 200K | $0,12 | 18-30 seg | Repositório grande / Livro completo |
| 256K (carga cheia) | $0,154 | 25-40 seg | Documentos longos extremos |
🎯 Dicas para otimização de documentos longos: Em cenários de contexto longo, recomenda-se dividir o system prompt em "instruções fixas + documentos dinâmicos". Uma vez que a parte fixa é atingida pelo cache de prefixo, as invocações subsequentes são cobradas apenas pela parte variável, reduzindo o custo total de 100 chamadas em até 40%-60% em cenários RAG.
Invocação Multimodal (Visão)
O K2.6 possui um codificador visual MoonViT integrado com 400M de parâmetros, suportando entrada nativa de imagens e vídeos. A interface multimodal também é compatível com o protocolo OpenAI:
from openai import OpenAI
import base64
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def encode_image(image_path: str) -> str:
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
image_b64 = encode_image("./diagrama_arquitetura.png")
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Analise este diagrama de arquitetura e identifique potenciais pontos únicos de falha"},
{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{image_b64}"}
}
]
}
],
max_tokens=2048
)
print(response.choices[0].message.content)
Cenários aplicáveis para multimodalidade:
- Análise e sugestões de alteração em diagramas de arquitetura/fluxogramas
- Revisão de protótipos de UI e geração de código
- Compreensão de capturas de tela de documentação técnica
- Extração de conteúdo de tabelas e gráficos
- Inspeção visual de qualidade industrial
Migração e Otimização de Performance da API Kimi K2.6
Se o seu projeto utiliza atualmente OpenAI, K2.5 ou modelos de outros fornecedores, a migração para o K2.6 geralmente exige apenas de 3 a 5 linhas de alteração de código. Além disso, estratégias inteligentes de concorrência e cache podem maximizar ainda mais a vantagem de custo do K2.6.
Migração da série OpenAI GPT
# Código original (OpenAI)
client = OpenAI(api_key="OPENAI_KEY")
response = client.chat.completions.create(
model="gpt-5.4",
messages=[...]
)
# Migração para o K2.6 (apenas altere base_url e model)
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[...]
)
Migração do Kimi K2 / K2.5
Os IDs dos modelos da série K2 são diferentes, mas o protocolo da API é exatamente o mesmo:
| ID do modelo antigo | ID do novo modelo | Data de descontinuação |
|---|---|---|
kimi-k2 |
kimi-k2.6 |
25-05-2026 |
kimi-k2.5 |
kimi-k2.6 |
Suporte contínuo, mas atualização recomendada |
moonshot-v1-128k |
kimi-k2.6 |
Durante 2026 |
Verificação de compatibilidade antes da migração
Antes de migrar, recomendamos verificar os seguintes pontos:
- Limite de max_tokens: O K2.6 pode gerar até 98K tokens em uma única saída; se o seu código tiver um limite de 8K, você pode aumentá-lo.
- Intervalo de temperature: O K2.6 recomenda valores entre 0,1 e 0,7; valores muito altos podem comprometer a qualidade do código.
- Sequências de parada (stop sequences): O K2.6 suporta delimitadores de parada personalizados, idêntico ao padrão OpenAI.
- Comportamento de tool_choice: O modo
autodo K2.6 é mais propenso a chamar ferramentas; se precisar de um comportamento conservador, altere paranoneou especifique explicitamente. - Protocolo de streaming: O formato SSE é exatamente o mesmo, não sendo necessária nenhuma alteração no código do front-end.
Melhores práticas de otimização de performance
Otimização da velocidade de invocação
| Item de otimização | Método de implementação | Melhoria esperada |
|---|---|---|
| Requisições simultâneas | Usar AsyncOpenAI + asyncio.gather | Aumento de 3-10x no throughput |
| Saída em streaming | Habilitar stream=True | Redução de 70% na latência inicial |
| Cache de prefixo | Fixar o system prompt | Redução de 75% nos custos de entrada |
| max_tokens adequado | Definir limites conforme a tarefa | Redução de 30% na latência por requisição |
| Controle de temperatura | Tarefas de código com temp=0.2 | Saídas mais estáveis |
Sugestões para tratamento de erros
from openai import OpenAI, APIError, RateLimitError, APITimeoutError
import time
def call_with_retry(prompt: str, max_retries: int = 3):
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
timeout=120.0
)
for attempt in range(max_retries):
try:
return client.chat.completions.create(
model="kimi-k2.6",
messages=[{"role": "user", "content": prompt}]
)
except RateLimitError:
wait = 2 ** attempt
print(f"Limite excedido, tentando novamente em {wait}s")
time.sleep(wait)
except APITimeoutError:
print(f"Tempo limite excedido, tentativa {attempt+1}")
except APIError as e:
print(f"Erro na API: {e}")
if attempt == max_retries - 1:
raise
raise Exception("Número máximo de tentativas alcançado")
Vantagem de preço e seleção de cenários da API Kimi K2.6
O preço é um fator crucial na escolha de um modelo. A tabela abaixo compara os preços de tabela do Kimi K2.6 em diferentes canais (por 1 milhão de tokens):
| Canal de invocação | Preço de entrada | Preço de saída | Observações |
|---|---|---|---|
| Plataforma Oficial Kimi | ¥6.5 (~$0.95) | ¥27 (~$4.00) | Cobrança oficial doméstica |
| APIYI (Proxy oficial) | $0.60 | $2.40 | Cerca de 60% do preço oficial |
| OpenRouter (Parasail) | $0.60 | $2.40+ | Canal não oficial |
| GPT-5.4 (Referência) | $2.50 | $15.00 | 4-6x mais caro que o K2.6 |
| Claude Opus 4.6 (Referência) | $15.00 | $75.00 | Mais de 25x mais caro que o K2.6 |
Estimativa de custo real
Considerando um cenário diário de assistente de código (sessão única: 5K tokens de entrada / 2K tokens de saída) com 100 mil chamadas mensais:
| Modelo | Custo mensal (entrada) | Custo mensal (saída) | Custo total mensal |
|---|---|---|---|
| Kimi K2.6 (APIYI) | $300 | $480 | $780 |
| GPT-5.4 | $1.250 | $3.000 | $4.250 |
| Claude Opus 4.6 | $7.500 | $15.000 | $22.500 |
Conclusão: Em cenários de alta frequência como codificação, agentes e longas janelas de contexto, o desempenho do K2.6 é comparável ao GPT-5.4/Claude Opus 4.6, mas com um custo entre 1/5 e 1/30 do valor. É particularmente amigável para pequenas e médias equipes e desenvolvedores individuais sensíveis a orçamento.
🎯 Dica de seleção: A escolha do modelo depende das necessidades específicas da sua aplicação e dos requisitos de qualidade. Recomendamos realizar testes práticos através da plataforma APIYI (apiyi.com) para tomar a decisão mais assertiva. A plataforma suporta o Kimi K2.6, GPT-5.4, Claude Opus 4.6 e outros modelos populares via uma interface unificada, facilitando comparações e trocas rápidas.
Recomendações de cenários de aplicação
O K2.6 apresenta diferentes níveis de adequação conforme o cenário. A tabela abaixo apresenta sugestões claras:
| Cenário de aplicação | Recomendação | Motivo |
|---|---|---|
| Manutenção e refatoração de código | ⭐⭐⭐⭐⭐ | Líder no SWE-Bench Pro, 256K permite carregar repositórios grandes |
| Orquestração de Agentes | ⭐⭐⭐⭐⭐ | 300 sub-agentes / 4000 passos, suporta fluxos complexos de P&D |
| Análise de documentos longos | ⭐⭐⭐⭐⭐ | Janela de contexto de 256K + otimização MLA, custo controlado |
| Compreensão multimodal | ⭐⭐⭐⭐ | MoonViT nativo, entrada de imagem e vídeo pronta para uso |
| Atendimento e conversação | ⭐⭐⭐⭐ | Function Call excelente, cache de prefixo reduz custos |
| Raciocínio matemático puro | ⭐⭐⭐ | Pontuação AIME 96.4 é decente, mas GPT-5.4 é superior |
| Escrita criativa | ⭐⭐⭐ | Expressão natural em chinês, mas estilo ligeiramente inferior ao Claude |

Perguntas Frequentes
P1: Quais são as principais diferenças entre a API Kimi K2.6 e as versões K2.5 / K2?
O K2.6 traz melhorias significativas em três pilares: 1) No SWE-Bench Pro, saltou de 53 pontos no K2.5 para 58,6, superando pela primeira vez o GPT-5.4 e o Claude Opus 4.6; 2) O número de subagentes do Agent Swarm aumentou de 100 para 300, e os passos de coordenação subiram de 1500 para 4000; 3) Abertura da janela de contexto de 256K para toda a linha (algumas variantes iniciais do K2 suportavam apenas 128K). De acordo com o anúncio oficial do Kimi, as versões anteriores do K2 serão descontinuadas em 25 de maio de 2026. Novos projetos devem integrar diretamente o K2.6, usando o ID de modelo kimi-k2.6, que é totalmente compatível com o SDK da OpenAI.
P2: A API Kimi K2.6 é totalmente compatível com o SDK da OpenAI?
Sim. Ao utilizar o K2.6 por meio de canais como a APIYI, o protocolo de API é totalmente compatível com a interface de chat completions da OpenAI, incluindo streaming, tools (Function Call), tool_choice, temperature, top_p, max_tokens e outros parâmetros. Em SDKs populares (Python/Node.js/Go), basta alterar os parâmetros base_url e model para alternar. Observe que o limite máximo de tokens de saída do K2.6 é de 98.304, muito superior aos 16K do GPT-5.
P3: Qual a latência e o custo real ao usar o contexto de 256K do K2.6?
O K2.6 otimizou significativamente o volume de KV cache para contextos longos através da tecnologia Multi-head Latent Attention (MLA). Em testes reais com entrada de 100K, a latência do primeiro token é de cerca de 8-15 segundos (dependendo da carga do servidor), com os tokens subsequentes retornando via streaming. Quanto ao custo, 256K de entrada calculados a $0,60/1M custam aproximadamente $0,15 por vez. Em conversas de múltiplos turnos com o mesmo system prompt, após o cache de prefixo ser atingido, o custo de entrada cai para cerca de 25%. Antes de colocar em produção, recomendamos testes de ponta a ponta com seu prompt típico, monitorando os logs de consumo de tokens para otimizar os custos.
P4: Como o Function Call do K2.6 difere da chamada de ferramentas do GPT-5 / Claude?
A interface é idêntica (protocolo de tools estilo OpenAI), mas as capacidades internas possuem focos distintos: 1) O K2.6 suporta 300 subagentes simultâneos, possuindo uma vantagem nativa na orquestração de múltiplas ferramentas em paralelo; 2) O K2.6 está no primeiro escalão do Berkeley Function-Calling Leaderboard, aproximando-se do nível do GPT-5; 3) O K2.6 suporta Continuação de Prefixo (Partial Mode), que pode forçar o formato de saída JSON, reduzindo a taxa de falha na chamada de ferramentas. Para fluxos de trabalho complexos de agentes, o K2.6 oferece o melhor custo-benefício.
P5: Chamar o K2.6 pela APIYI é autorizado oficialmente? A segurança dos dados é garantida?
A APIYI integra-se ao modelo oficial do Kimi por meio de canais oficiais de revenda em nuvem, sendo um canal autorizado e em conformidade; os pesos do modelo e os resultados de inferência são idênticos aos oficiais. A transmissão de dados utiliza criptografia HTTPS e a plataforma não armazena o conteúdo das solicitações. Para usuários corporativos, oferecemos recursos de segurança como subcontas independentes, permissões de chave API escalonadas e limites de consumo. Caso haja requisitos rigorosos de conformidade de dados, consulte a política detalhada na página de conformidade do apiyi.com.
P6: Para quais tipos de projetos o K2.6 é indicado? Quando escolher GPT-5.4 ou Claude?
Cenários onde o K2.6 é prioridade: assistentes de código, tarefas tipo SWE, RAG com contexto longo, orquestração de fluxos de Agentes e projetos de pequeno/médio porte sensíveis a custos. Cenários onde o GPT-5.4 é prioridade: competições matemáticas de alta dificuldade (AIME/HMMT) e tarefas científicas que exigem profundidade de raciocínio de nível superior. Cenários onde o Claude Opus 4.6 é prioridade: escrita criativa longa, geração de contratos ou documentos jurídicos com conformidade de formato rigorosa. Recomendamos manter um design de interface que permita a alternância entre modelos para realizar testes comparativos em tarefas específicas antes de definir o modelo de produção.
Resumo
O Kimi K2.6 é um marco importante entre os modelos de linguagem grande de 2026 — provando que uma arquitetura MoE na casa das centenas de bilhões de parâmetros pode competir de igual para igual com os carro-chefes de código fechado em codificação, agentes e contexto longo. Com a pontuação de 58,6 no SWE-Bench Pro e a capacidade de engenharia de 256K de contexto + 300 subagentes, ele se torna o modelo preferencial para assistentes de código e projetos de automação de P&D.
Pontos principais:
- Vantagem de arquitetura: 1T MoE / 32B ativados, capacidade de centenas de bilhões + custo de inferência de 32B.
- Liderança em benchmarks: Primeiro lugar em SWE-Bench Pro, Terminal-Bench 2.0 e HLE.
- Preço: $0,60 / $2,40 via canal APIYI, cerca de 40% mais barato que no site oficial.
- Ecossistema amigável: Totalmente compatível com o SDK da OpenAI, migração em 5 minutos.
- Capacidade de engenharia: 256K de contexto + 300 subagentes + cache de prefixo.
Para equipes que desejam construir produtos de IA em 2026, a API Kimi K2.6 é uma escolha altamente competitiva em desempenho, custo e ecossistema. Recomendamos verificar a eficácia rapidamente através da plataforma APIYI (apiyi.com), comparando o desempenho real de diferentes modelos no seu cenário de negócios para tomar a melhor decisão.
Autor: Equipe Técnica APIYI | Acompanhamos continuamente as tendências de modelos de linguagem grande. Entre em contato pelo apiyi.com para intercâmbio técnico e consultoria de soluções.