國產開源大模型在 2026 年迎來重要節點 —— 月之暗面 (Moonshot AI) 旗艦模型 Kimi K2.6 正式開源,在 SWE-Bench Pro 基準上以 58.6 分反超 GPT-5.4 (57.7) 與 Claude Opus 4.6 (53.4),成爲目前真實 GitHub Issue 解決率最高的可調用模型。
本文將圍繞 Kimi K2.6 API 的接入流程,深入解析其 1T MoE 架構、256K 上下文、Function Call 與前綴續寫能力,並通過完整代碼示例幫助你在 5 分鐘內完成 API 集成。同時對比官方計費,API易 (apiyi.com) 通過華爲雲官轉通道掛牌 $0.60 輸入 / $2.40 輸出 每 1M tokens,約爲官網 ¥6.5 / ¥27 價格的 6 折。
核心價值: 讀完本文,你將掌握 Kimi K2.6 API 的完整調用方法、Function Call 工具編排、前綴緩存優化技巧,並瞭解何時選用 K2.6 纔是性價比最優解。

Kimi K2.6 API 核心要點
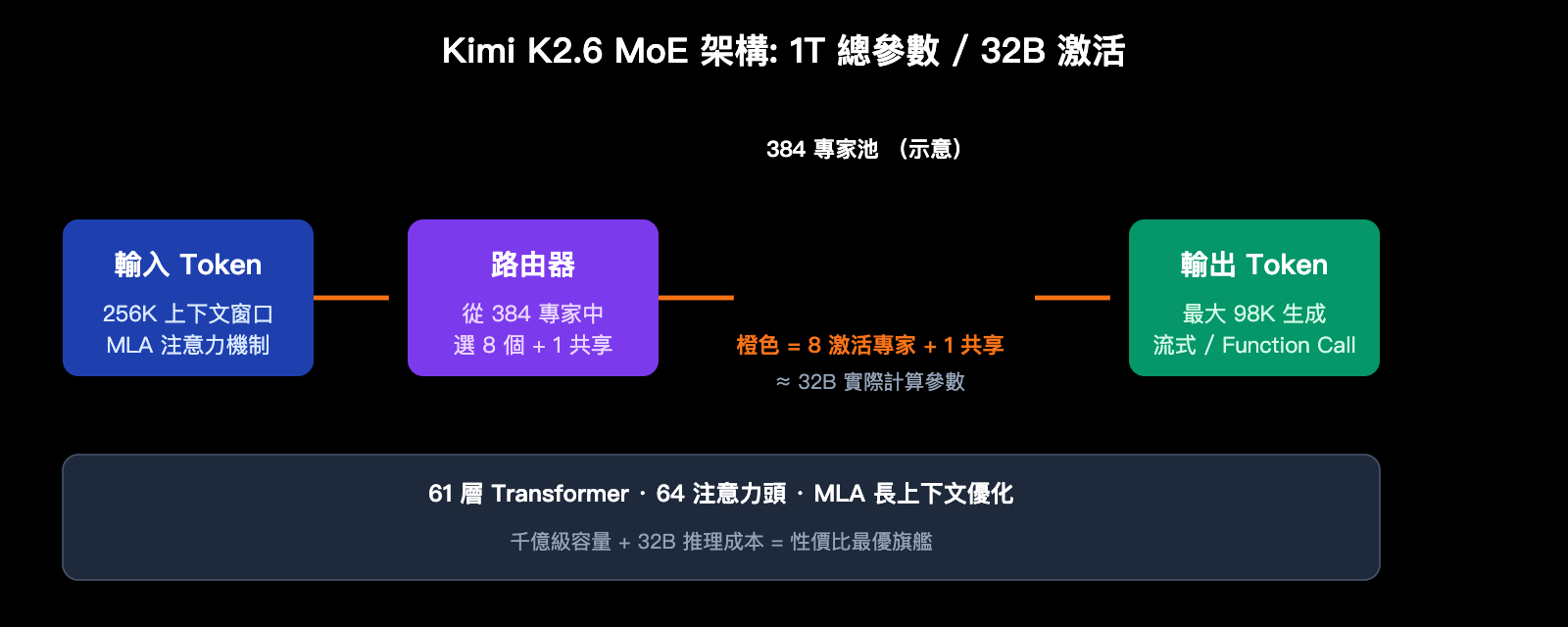
Kimi K2.6 是月之暗面在 2026 年 4 月正式發佈的新一代旗艦開源模型,沿用 Kimi K2 系列 MoE 架構,在編碼、長上下文、工具調用三大方向均有顯著升級。下表彙總了開發者最關心的核心規格:
| 要點 | 詳細規格 | 實際價值 |
|---|---|---|
| MoE 架構 | 1T 總參數 / 32B 激活 / 384 專家 (8選+1共享) | 千億級能力,推理成本僅與 32B 模型相當 |
| 上下文窗口 | 256K tokens (精確 262,144) | 一次性處理超長倉庫代碼或法律文檔 |
| 最大生成 | 單次輸出最高 98,304 tokens | 滿足長篇代碼重構與文檔生成場景 |
| 多模態能力 | 內置 400M MoonViT 視覺編碼器 | 原生支持圖像與視頻輸入 |
| 代理編排 | Agent Swarm 支持 300 子代理 / 4,000 協調步 | 可處理複雜多步驟研發流程 |
| 開源協議 | Modified MIT License | 商業使用友好,無顯著限制 |
Kimi K2.6 API 重點能力詳解
相比上一代 K2.5,K2.6 在三個維度有跨越式提升: 一是 SWE-Bench Pro 突破 58.6 分,首次在真實開源倉庫 Issue 解決任務上壓倒 GPT-5.4 與 Claude Opus 4.6;二是 Agent Swarm 子代理數從 100 提升到 300,協調步驟從 1500 提升到 4000,可承接更長鏈路的研發任務;三是 256K 上下文全系列開放,且通過 Multi-head Latent Attention (MLA) 顯著降低了長上下文推理的顯存與延遲成本。
🎯 技術建議: 在實際開發中,我們建議通過 API易 apiyi.com 平臺直接調用 Kimi K2.6,該平臺通過華爲雲官轉通道接入官方模型,接口完全兼容 OpenAI SDK,無需改動現有代碼即可切換模型。
Kimi K2.6 API 技術架構詳解
理解 Kimi K2.6 的底層架構,有助於在不同業務場景下做出合理選型。其架構設計兼顧了"千億級參數容量"與"百億級推理成本"的平衡。
MoE 稀疏激活機制
Kimi K2.6 採用 1 萬億參數的混合專家 (MoE) 架構,包含 384 個專家網絡。每個 token 推理時僅激活其中 8 個 (加 1 個共享專家),即 32B 參數參與計算。這種設計使模型既具備千億級模型的知識廣度,又保持了 32B 級別的推理速度,是當前 API 調用成本最優的旗艦模型之一。
長上下文優化
| 技術組件 | 作用 | K2.6 配置 |
|---|---|---|
| Multi-head Latent Attention (MLA) | 降低長上下文推理的 KV cache 體積 | 64 個注意力頭 |
| 網絡層數 | 決定模型推理深度 | 61 層 Transformer |
| 上下文窗口 | 單次輸入最大 token 數 | 262,144 tokens (256K) |
| 位置編碼 | 支持超長序列的關鍵技術 | 經過專門長上下文訓練 |
| 前綴緩存 | 重複 prompt 命中緩存,降低成本 | 命中後輸入價降低約 75% |
💡 架構洞察: K2.6 在多輪對話或固定 system prompt 場景下,前綴緩存可顯著降低輸入成本。建議生產環境保持 system prompt 穩定,以最大化緩存命中率。
Kimi K2.6 API 性能基準對比
判斷一個模型是否值得接入,基準測試是最直觀的依據。下面對比 Kimi K2.6、GPT-5.4、Claude Opus 4.6 在五大權威基準上的表現。
編碼與軟件工程能力
| 基準測試 | Kimi K2.6 | GPT-5.4 | Claude Opus 4.6 | 優勢模型 |
|---|---|---|---|---|
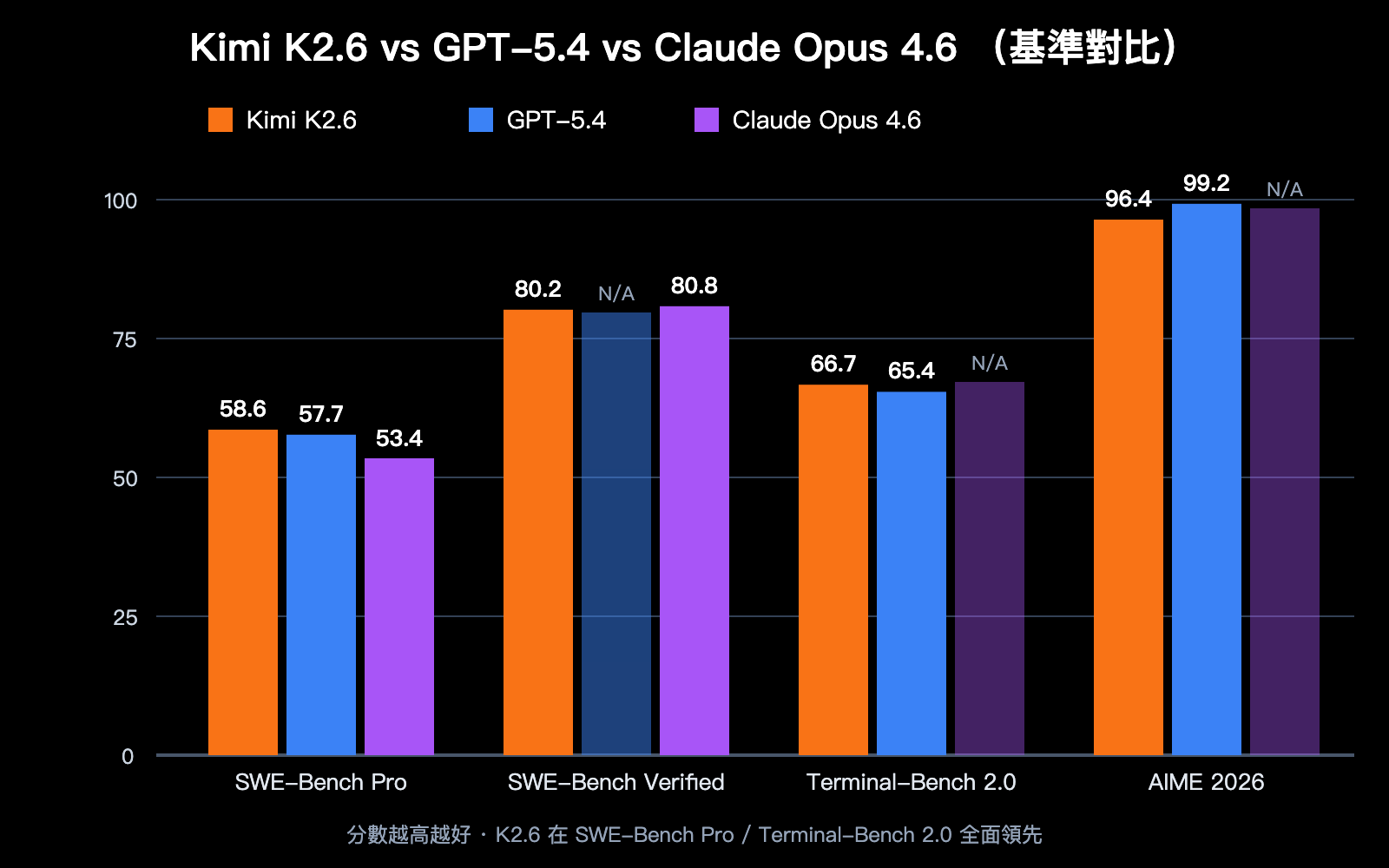
| SWE-Bench Pro | 58.6 | 57.7 | 53.4 | Kimi K2.6 |
| SWE-Bench Verified | 80.2 | – | 80.8 | Claude Opus 4.6 |
| Terminal-Bench 2.0 | 66.7 | 65.4 | – | Kimi K2.6 |
| HLE (with tools) | 54.0 | – | 53.0 | Kimi K2.6 |
| AIME 2026 | 96.4 | 99.2 | – | GPT-5.4 |
| GPQA-Diamond | 90.5 | – | – | – |
關鍵解讀:
- SWE-Bench Pro 測量真實 GitHub Issue 的端到端解決能力。K2.6 拿下 58.6 分,首次讓開源模型在該基準上反超閉源旗艦,意味着代碼維護、bug 修復類任務可優先選 K2.6。
- SWE-Bench Verified 是相對簡化版,Claude Opus 4.6 略勝 (80.8 vs 80.2),差距很小但表明 Claude 在標準化代碼任務上仍有優勢。
- Terminal-Bench 2.0 測試終端命令編排能力,K2.6 的 66.7 分領先,適合 DevOps、自動化運維場景。
- AIME / HMMT 等純數學推理仍是 GPT-5.4 強項,純數學場景仍建議保留 GPT-5.4 選項。
🎯 場景建議: 不同任務建議跨模型 A/B 測試 —— 代碼維護類優先 K2.6,數學推理優先 GPT-5.4,長篇創意寫作可保留 Claude 選項。
Kimi K2.6 API 快速上手
接下來通過完整代碼演示如何調用 Kimi K2.6。Kimi 系列 API 完全兼容 OpenAI SDK 協議,如果你已有 OpenAI 調用代碼,只需替換 base_url 和 model 即可。
極簡示例 (Python)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "你是一位資深 Python 工程師。"},
{"role": "user", "content": "用 asyncio 實現一個併發請求池,限制最大併發 10。"}
],
temperature=0.3,
max_tokens=2048
)
print(response.choices[0].message.content)
查看完整異步流式調用示例 (含錯誤處理)
import asyncio
from openai import AsyncOpenAI
from openai import APIError, RateLimitError
client = AsyncOpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
max_retries=3,
timeout=120.0
)
async def call_kimi_k26_stream(prompt: str, system: str = "") -> str:
"""流式調用 Kimi K2.6 並實時打印 token"""
messages = []
if system:
messages.append({"role": "system", "content": system})
messages.append({"role": "user", "content": prompt})
full_response = ""
try:
stream = await client.chat.completions.create(
model="kimi-k2.6",
messages=messages,
stream=True,
temperature=0.3,
max_tokens=8192
)
async for chunk in stream:
if chunk.choices[0].delta.content:
token = chunk.choices[0].delta.content
print(token, end="", flush=True)
full_response += token
except RateLimitError:
print("\n[遇到限流, 建議配置重試或升級套餐]")
raise
except APIError as e:
print(f"\n[API 錯誤: {e}]")
raise
return full_response
async def main():
result = await call_kimi_k26_stream(
prompt="解釋 MoE 架構如何降低推理成本",
system="你是 AI 架構專家,回答簡潔專業"
)
print(f"\n\n[完整 token 數: {len(result)}]")
if __name__ == "__main__":
asyncio.run(main())
🚀 快速開始: 通過 API易 apiyi.com 平臺獲取 API Key 後,只需將
base_url設爲https://api.apiyi.com/v1,所有 OpenAI 生態的 SDK (Python/Node.js/Go) 均可直接使用,5 分鐘即可完成集成。
Node.js / TypeScript 調用
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.APIYI_KEY,
baseURL: "https://api.apiyi.com/v1",
});
const completion = await client.chat.completions.create({
model: "kimi-k2.6",
messages: [
{ role: "user", content: "用 TypeScript 寫一個防抖函數,帶泛型支持" }
],
temperature: 0.2,
});
console.log(completion.choices[0].message.content);
cURL 直接調用
curl https://api.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_APIYI_KEY" \
-d '{
"model": "kimi-k2.6",
"messages": [
{"role": "user", "content": "Hello, Kimi K2.6"}
],
"max_tokens": 1024
}'
Function Call 工具調用實戰
K2.6 的 Function Call (工具調用) 能力是其相比 K2 系列的顯著升級,在 Berkeley Function-Calling Leaderboard 上表現優異。下面通過一個"查詢天氣"的完整示例展示工具編排流程。
工具定義與調用
from openai import OpenAI
import json
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "查詢指定城市的實時天氣",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "城市名稱"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["city"]
}
}
}
]
def get_weather(city: str, unit: str = "celsius") -> dict:
"""模擬天氣查詢接口"""
return {"city": city, "temperature": 22, "unit": unit, "condition": "晴"}
messages = [{"role": "user", "content": "幫我查一下北京和上海的天氣"}]
response = client.chat.completions.create(
model="kimi-k2.6",
messages=messages,
tools=tools,
tool_choice="auto"
)
assistant_msg = response.choices[0].message
messages.append(assistant_msg)
if assistant_msg.tool_calls:
for tool_call in assistant_msg.tool_calls:
args = json.loads(tool_call.function.arguments)
result = get_weather(**args)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": json.dumps(result, ensure_ascii=False)
})
final_response = client.chat.completions.create(
model="kimi-k2.6",
messages=messages
)
print(final_response.choices[0].message.content)
前綴續寫 (Partial Mode)
K2.6 支持 OpenAI 風格的"前綴續寫",即在 assistant 消息中預先填入開頭,模型從該位置繼續生成。常用於強制 JSON 輸出或特定格式約束:
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "user", "content": "用 JSON 格式返回北京的GDP數據 (2023)"},
{"role": "assistant", "content": '{"city": "北京", "year": 2023, "gdp":'}
],
max_tokens=200
)
print(response.choices[0].message.content)
💰 成本優化: 對於長 system prompt 場景 (如 RAG、Agent),前綴緩存命中後輸入價格降至約 25%,適合多輪對話和高頻固定模板的業務。建議在 apiyi.com 平臺啓用賬戶級緩存監控,實時觀察命中率。
Kimi K2.6 API 高級能力實戰
K2.6 在 Function Call 之外,還提供了 Agent Swarm 多代理編排、256K 長上下文、原生多模態三大進階能力,共同構成其在編碼、研發自動化、文檔分析場景下的核心競爭力。
Agent Swarm 多代理編排
K2.6 最具差異化的能力之一是 Agent Swarm —— 單次任務可調度多達 300 個並行子代理,執行 4,000 步協調動作。這一特性使 K2.6 在大型代碼庫重構、多文檔跨引用分析、複雜研發流水線等場景中表現突出。
子代理調度模式
K2.6 的 Agent Swarm 支持三種典型編排模式:
| 編排模式 | 適用場景 | 子代理數 | 協調步數 |
|---|---|---|---|
| 單層並行 | 文檔批量摘要、代碼審查 | 10-50 | < 200 |
| 分層調度 | 多模塊代碼重構 | 50-150 | 500-1500 |
| 深度協同 | 跨倉庫 Agent 流水線 | 150-300 | 1500-4000 |
簡易代理調度示例
下面演示如何用 K2.6 協調 5 個並行子代理完成代碼審查任務:
from openai import OpenAI
import asyncio
import json
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
async def review_module(module_name: str, code: str) -> dict:
"""單個模塊審查子代理"""
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "你是一位代碼審查專家,關注安全性和性能。"},
{"role": "user", "content": f"審查模塊 {module_name}:\n{code}"}
],
temperature=0.2
)
return {
"module": module_name,
"review": response.choices[0].message.content
}
async def parallel_review(modules: dict) -> list:
"""並行調度多個子代理"""
tasks = [review_module(name, code) for name, code in modules.items()]
return await asyncio.gather(*tasks)
# 主流程: 協調 5 個子代理審查 5 個模塊
modules = {
"auth.py": "...",
"database.py": "...",
"api_routes.py": "...",
"cache.py": "...",
"logger.py": "..."
}
results = asyncio.run(parallel_review(modules))
for r in results:
print(f"[{r['module']}] {r['review'][:100]}...")
Agent Swarm 關鍵最佳實踐
- 任務粒度控制: 單個子代理處理 5K-20K tokens,過大會導致協調開銷;
- 錯誤隔離: 每個子代理獨立 try/except,避免單點故障級聯;
- 結果聚合: 設置一個"主代理"統一收集子代理結果並交叉驗證;
- 超時管理: 單子代理超時 60-120 秒,主代理總超時 10-30 分鐘;
- 速率控制: 通過信號量限制最大併發數,避免觸發 API 限流。
256K 長上下文實戰
256K (262,144 tokens) 上下文是 K2.6 的核心賣點。對應中文約 40-50 萬字,可一次性容納大型代碼倉庫或整本技術書籍。
長上下文典型用法
import os
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def load_repo_files(repo_path: str, extensions=(".py", ".ts", ".md")) -> str:
"""加載倉庫內所有指定後綴文件"""
contents = []
for root, _, files in os.walk(repo_path):
for f in files:
if f.endswith(extensions):
full_path = os.path.join(root, f)
with open(full_path, "r", encoding="utf-8") as fp:
contents.append(f"## {full_path}\n```\n{fp.read()}\n```")
return "\n\n".join(contents)
repo_text = load_repo_files("./my_project")
print(f"倉庫總 token 估算: {len(repo_text) // 2}") # 中文 1 token≈2 字符
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "你是資深架構師,擅長大型代碼庫分析。"},
{"role": "user", "content": f"分析以下項目架構,給出重構建議:\n{repo_text}"}
],
temperature=0.3,
max_tokens=8192
)
print(response.choices[0].message.content)
長上下文成本與性能權衡
| 輸入規模 | 估算成本/次 | 首 token 延遲 | 適用場景 |
|---|---|---|---|
| 8K | $0.005 | 1-2 秒 | 單文件分析 |
| 32K | $0.019 | 3-5 秒 | 模塊級審查 |
| 100K | $0.06 | 8-15 秒 | 中型倉庫分析 |
| 200K | $0.12 | 18-30 秒 | 大型倉庫 / 整本書 |
| 256K (滿載) | $0.154 | 25-40 秒 | 極限長文檔場景 |
🎯 長文檔優化技巧: 長上下文場景建議拆分 system prompt 爲"固定指令 + 動態文檔"兩部分,固定部分被前綴緩存命中後,後續調用僅按變化部分計費,實測在 RAG 場景下可將 100 次調用的總成本降低 40%-60%。
多模態視覺調用
K2.6 內置 400M 參數的 MoonViT 視覺編碼器,原生支持圖像與視頻輸入。多模態接口同樣兼容 OpenAI 協議:
from openai import OpenAI
import base64
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def encode_image(image_path: str) -> str:
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
image_b64 = encode_image("./architecture_diagram.png")
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "分析這張架構圖,識別潛在的單點故障"},
{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{image_b64}"}
}
]
}
],
max_tokens=2048
)
print(response.choices[0].message.content)
多模態適用場景:
- 架構圖/流程圖分析與修改建議
- UI 設計稿審查與代碼生成
- 技術文檔截圖理解
- 數據圖表內容提取
- 工業質檢視覺識別
Kimi K2.6 API 遷移與性能優化
如果你的項目當前使用 OpenAI、K2.5、其他廠商模型,遷移到 K2.6 通常只需 3-5 行代碼改動;同時,合理的併發與緩存策略可讓 K2.6 的成本優勢進一步放大。
從 OpenAI GPT 系列遷移
# 原代碼 (OpenAI)
client = OpenAI(api_key="OPENAI_KEY")
response = client.chat.completions.create(
model="gpt-5.4",
messages=[...]
)
# 遷移到 K2.6 (僅改 base_url 和 model)
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[...]
)
從 Kimi K2 / K2.5 遷移
K2 系列模型 ID 不同,但 API 協議完全一致:
| 舊模型 ID | 新模型 ID | 計劃下線時間 |
|---|---|---|
kimi-k2 |
kimi-k2.6 |
2026-05-25 |
kimi-k2.5 |
kimi-k2.6 |
持續支持但建議升級 |
moonshot-v1-128k |
kimi-k2.6 |
2026年內 |
遷移前的兼容性檢查
遷移前建議檢查以下點:
- max_tokens 上限: K2.6 單次輸出可達 98K,如果你的代碼硬編碼了 8K 限制,可放寬
- temperature 範圍: K2.6 推薦 0.1-0.7,過高會影響代碼質量
- stop sequences: K2.6 支持自定義停止符,與 OpenAI 一致
- tool_choice 行爲: K2.6 的
auto模式更傾向於調用工具,如需保守可改爲none或顯式指定 - 流式協議: SSE 格式完全一致,前端代碼無需改動
性能優化最佳實踐
調用速度優化
| 優化項 | 實施方法 | 預期提升 |
|---|---|---|
| 併發請求 | 使用 AsyncOpenAI + asyncio.gather | 吞吐量 3-10x |
| 流式輸出 | 啓用 stream=True | 首屏延遲降低 70% |
| 前綴緩存 | 固定 system prompt | 輸入成本降 75% |
| 合理 max_tokens | 根據任務設定上限 | 單次延遲降 30% |
| 溫度控制 | 代碼任務 temp=0.2 | 輸出更穩定 |
錯誤處理建議
from openai import OpenAI, APIError, RateLimitError, APITimeoutError
import time
def call_with_retry(prompt: str, max_retries: int = 3):
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
timeout=120.0
)
for attempt in range(max_retries):
try:
return client.chat.completions.create(
model="kimi-k2.6",
messages=[{"role": "user", "content": prompt}]
)
except RateLimitError:
wait = 2 ** attempt
print(f"限流,等待 {wait}s 後重試")
time.sleep(wait)
except APITimeoutError:
print(f"超時,第 {attempt+1} 次重試")
except APIError as e:
print(f"API 錯誤: {e}")
if attempt == max_retries - 1:
raise
raise Exception("達到最大重試次數")
Kimi K2.6 API 價格優勢與場景選型
價格是模型選型不可忽視的因素。下表對比 Kimi K2.6 在不同渠道的掛牌價 (單位: 每 1M tokens):
| 調用渠道 | 輸入價格 | 輸出價格 | 備註 |
|---|---|---|---|
| Kimi 官方平臺 | ¥6.5 (~$0.95) | ¥27 (~$4.00) | 國內官方計費 |
| API易 (華爲雲官轉) | $0.60 | $2.40 | 約官網 6 折 |
| OpenRouter (Parasail) | $0.60 | $2.40+ | 非官方通道 |
| GPT-5.4 (參考) | $2.50 | $15.00 | 比 K2.6 貴 4-6 倍 |
| Claude Opus 4.6 (參考) | $15.00 | $75.00 | 比 K2.6 貴 25 倍以上 |
實際成本估算
以日常代碼助手場景爲例 (假設單次會話: 輸入 5K tokens / 輸出 2K tokens),月調用 10 萬次:
| 模型 | 月輸入成本 | 月輸出成本 | 月總成本 |
|---|---|---|---|
| Kimi K2.6 (API易) | $300 | $480 | $780 |
| GPT-5.4 | $1,250 | $3,000 | $4,250 |
| Claude Opus 4.6 | $7,500 | $15,000 | $22,500 |
結論: 在編碼、Agent、長上下文三類高頻場景下,K2.6 性能與 GPT-5.4/Claude Opus 4.6 同檔,但成本僅爲 1/5 至 1/30。對於預算敏感的中小團隊和個人開發者尤其友好。
🎯 選型建議: 選擇哪個模型主要取決於您的具體應用場景和質量要求。我們建議通過 API易 apiyi.com 平臺進行實際測試,以便做出最適合您需求的選擇。該平臺支持 Kimi K2.6、GPT-5.4、Claude Opus 4.6 等多種主流模型的統一接口調用,便於快速對比和切換。
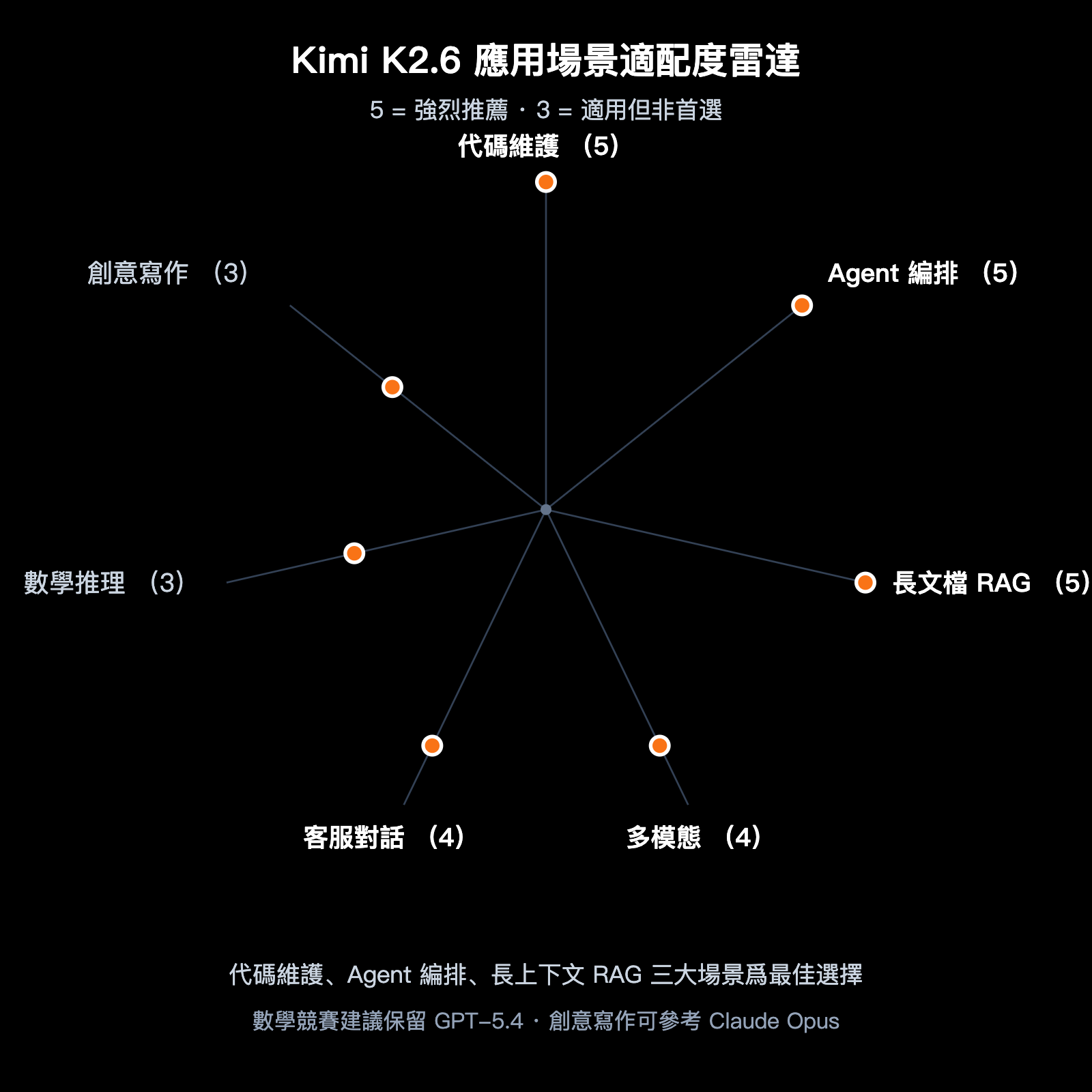
應用場景推薦
不同業務場景下,K2.6 的適配度差異較大。下表給出明確的選型建議:
| 應用場景 | 推薦度 | 理由 |
|---|---|---|
| 代碼維護與重構 | ⭐⭐⭐⭐⭐ | SWE-Bench Pro 第一,256K 可載入大型倉庫 |
| Agent 編排 | ⭐⭐⭐⭐⭐ | 300 子代理 / 4000 步,支持複雜研發流 |
| 長文檔分析 | ⭐⭐⭐⭐⭐ | 256K 上下文 + MLA 優化,長文成本可控 |
| 多模態理解 | ⭐⭐⭐⭐ | 原生 MoonViT,圖像視頻輸入開箱即用 |
| 客服與對話 | ⭐⭐⭐⭐ | Function Call 優秀,前綴緩存降低成本 |
| 純數學推理 | ⭐⭐⭐ | AIME 96.4 分尚可,但 GPT-5.4 更強 |
| 創意寫作 | ⭐⭐⭐ | 中文表達自然,但風格化任務略遜 Claude |
常見問題
Q1: Kimi K2.6 API 與 K2.5 / K2 主要區別是什麼?
K2.6 在三個方向顯著升級: 1) SWE-Bench Pro 從 K2.5 的 53 分躍升至 58.6,首次反超 GPT-5.4 與 Claude Opus 4.6;2) Agent Swarm 子代理從 100 提升到 300,協調步驟從 1500 提升到 4000;3) 256K 上下文全系列開放 (K2 早期版本部分變體僅支持 128K)。Kimi 官方公告顯示,K2 早期版本將於 2026年5月25日下線,新項目應直接接入 K2.6,模型 ID 爲 kimi-k2.6,完全兼容 OpenAI SDK。
Q2: Kimi K2.6 API 與 OpenAI SDK 完全兼容嗎?
是的。K2.6 通過 API易等渠道調用時,API 協議完全兼容 OpenAI 的 chat completions 接口,包括 streaming、tools (Function Call)、tool_choice、temperature、top_p、max_tokens 等參數。Python/Node.js/Go 等主流 SDK 只需修改 base_url 和 model 兩個參數即可切換。注意 K2.6 的最大輸出 token 是 98,304,遠高於 GPT-5 的 16K。
Q3: K2.6 的 256K 上下文實際使用時延遲和成本如何?
K2.6 通過 Multi-head Latent Attention (MLA) 顯著優化了長上下文的 KV cache 體積。實測在 100K 輸入場景下,首 token 延遲約 8-15 秒 (取決於服務器負載),後續 token 流式返回。成本方面,256K 輸入按 $0.60/1M 計算約 $0.15 一次。如果是相同 system prompt 的多輪對話,前綴緩存命中後輸入成本降至約 25%。生產前建議針對你的典型 prompt 做端到端實測,關注 token 消耗日誌以優化成本。
Q4: K2.6 的 Function Call 與 GPT-5 / Claude 的工具調用有何不同?
接口層完全一致 (OpenAI 風格的 tools 協議),但內部能力側重不同: 1) K2.6 支持 300 子代理併發,在多工具並行編排上有原生優勢;2) K2.6 在 Berkeley Function-Calling Leaderboard 上屬於第一梯隊,接近 GPT-5 水平;3) K2.6 支持 前綴續寫 (Partial Mode),可強制 JSON 輸出格式,降低工具調用失敗率。對於複雜 Agent 流水線,K2.6 是性價比最佳選擇。
Q5: 通過 API易調用 K2.6 是官方授權嗎? 數據安全有保障嗎?
API易 通過華爲雲官轉通道接入 Kimi 官方模型,屬於合規授權渠道,模型權重和推理結果與官方一致。數據傳輸使用 HTTPS 加密,平臺不留存請求內容。對於企業級用戶,提供獨立子賬號、API Key 權限分級、消費限額等安全特性。如對數據合規有嚴格要求,可在 apiyi.com 合規說明頁面查閱詳細政策。
Q6: K2.6 適合哪些類型的項目? 何時該選 GPT-5.4 或 Claude?
優先選 K2.6 的場景: 代碼助手、SWE 類任務、長上下文 RAG、Agent 流程編排、對成本敏感的中小項目。優先選 GPT-5.4 的場景: 高難度數學競賽 (AIME/HMMT)、需要頂級推理深度的科研任務。優先選 Claude Opus 4.6 的場景: 長篇創意寫作、嚴格格式合規的合同/法律文檔生成。建議保留多模型可切換的接口設計,針對具體任務做對比測試再確定生產模型。
總結
Kimi K2.6 是 2026 年開源大模型的一個重要里程碑 —— 它證明了千億級 MoE 架構在編碼、Agent、長上下文三大方向上,完全可以與閉源旗艦正面競爭。SWE-Bench Pro 58.6 分的成績,以及 256K 上下文 + 300 子代理的工程能力,使其成爲代碼助手、研發自動化項目的優選模型。
核心要點回顧:
- 架構優勢: 1T MoE / 32B 激活,千億級能力 + 32B 推理成本
- 基準領先: SWE-Bench Pro / Terminal-Bench 2.0 / HLE 三項第一
- 價格優勢: API易渠道 $0.60 / $2.40,約官網 6 折
- 生態友好: OpenAI SDK 完全兼容,5 分鐘完成遷移
- 工程能力: 256K 上下文 + 300 子代理 + 前綴緩存
對於希望在 2026 年構建 AI 產品的團隊,Kimi K2.6 API 是一個性能、成本、生態都極具競爭力的選擇。推薦通過 API易 apiyi.com 平臺快速驗證效果,對比不同模型在你具體業務場景下的真實表現,做出最優選型決策。
作者: APIYI 技術團隊 | 持續關注 AI 大模型動態,歡迎通過 API易 apiyi.com 進行技術交流與方案諮詢。