От автора: Сравниваем Gemini 3.1 Pro и Claude Sonnet 4.6 по 5 ключевым параметрам: кодинг, рассуждения, мультимодальность, работа с данными и цена. Поможем выбрать лучшую по соотношению цены и качества передовую модель.
В феврале 2026 года на рынке ИИ-моделей сложилась интересная ситуация: настоящая борьба идет не за звание «самого мощного», а за титул «короля соотношения цены и качества». Gemini 3.1 Pro от Google (вышла 19 февраля) и Claude Sonnet 4.6 от Anthropic (вышла 17 февраля) появились почти одновременно. У них схожие цены и обе заявляют о производительности флагманского уровня — выбор для разработчиков еще никогда не был таким сложным.
Главная ценность: прочитав эту статью, вы поймете реальную разницу между двумя моделями в кодинге, рассуждениях, мультимодальности и интеллектуальных задачах, а также узнаете, какую из них выбрать под ваши конкретные сценарии.

Сравнение базовых характеристик Gemini 3.1 Pro и Claude Sonnet 4.6
Позиционирование этих моделей очень похоже — обе предлагают «производительность флагманского уровня по цене значительно ниже флагманской». Однако их технологические подходы кардинально различаются.
| Параметр | Gemini 3.1 Pro | Claude Sonnet 4.6 | Комментарий |
|---|---|---|---|
| Дата релиза | 19.02.2026 | 17.02.2026 | Разница всего в 2 дня |
| Контекстное окно | 1 млн (стандарт) | 200 тыс. стандарт / 1 млн Beta | У Gemini нативный миллионный контекст |
| Макс. объем вывода | 64K токенов | 64K токенов | Полностью идентичны |
| Цена за вход (input) | $2 / млн токенов | $3 / млн токенов | ✅ Gemini дешевле на 33% |
| Цена за выход (output) | $12 / млн токенов | $15 / млн токенов | ✅ Gemini дешевле на 20% |
| Цена за вход (длинный контекст) | $4 (>200K) | $3 (без изменений) | ⚠️ Sonnet выгоднее на длинном контексте |
| Цена за выход (длинный контекст) | $18 (>200K) | $15 (без изменений) | ⚠️ Sonnet выгоднее на длинном контексте |
| Входные модальности | Текст, фото, аудио, видео, PDF | Текст, фото, PDF | ✅ Gemini более мультимодальный |
| Режим рассуждения | Трехуровневый (Low/Med/High) | Адаптивный (динамическая регулировка) | Разные концепции дизайна |
| Кэширование промптов | Поддерживается | Чтение из кэша всего $0.30/млн (экономия 90%) | ✅ Кэш у Sonnet выгоднее |
🎯 Ключевой нюанс ценообразования: В обычных сценариях до 200 тыс. токенов Gemini 3.1 Pro обходится дешевле ($2/$12 против $3/$15). Но как только контекст превышает 200 тыс., Gemini поднимает цену до $4/$18, становясь дороже, чем Sonnet 4.6 с его фиксированными $3/$15. Ваша средняя длина контекста напрямую определяет, какая модель будет выгоднее.
Полное сравнение бенчмарков Gemini 3.1 Pro и Sonnet 4.6
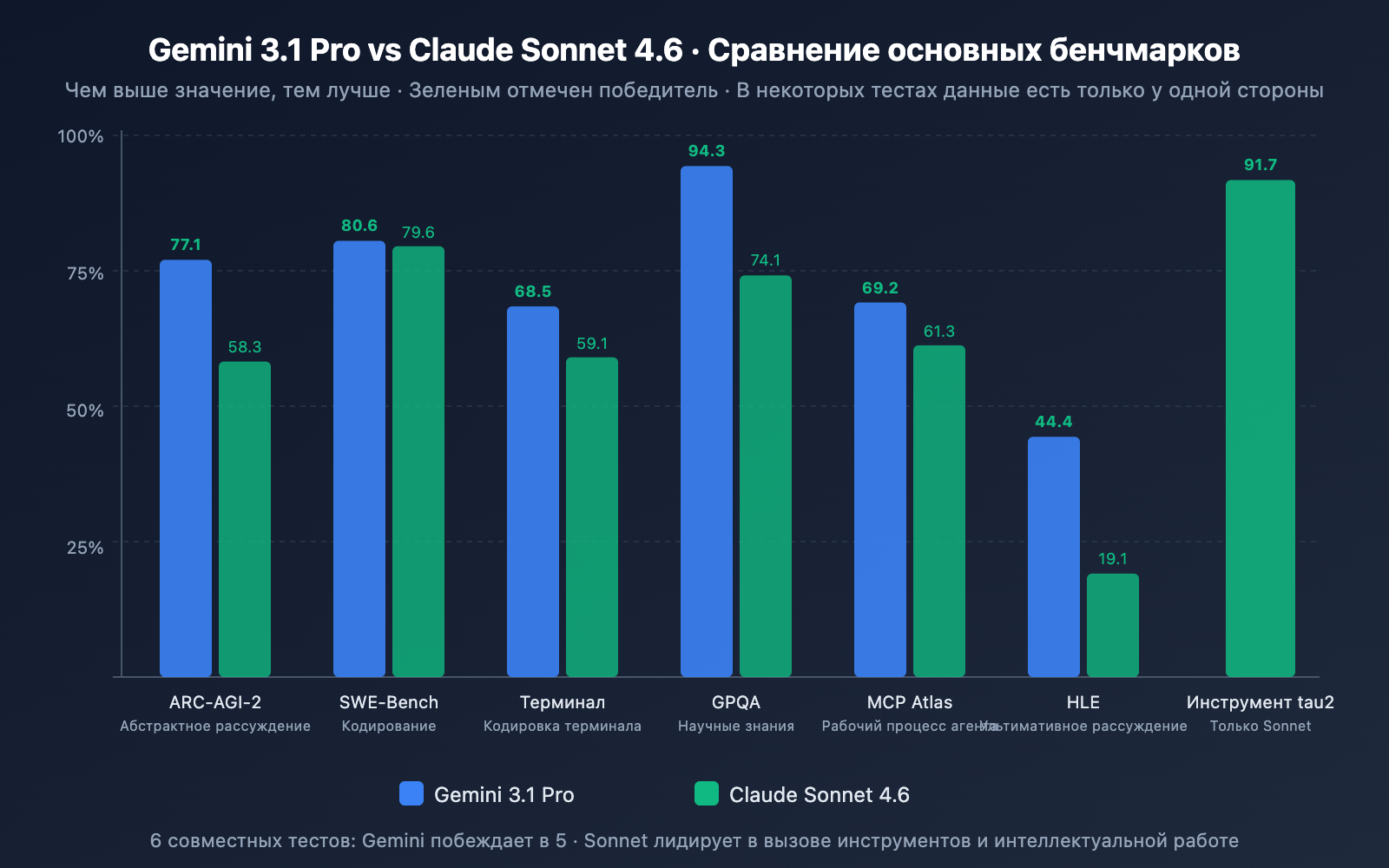
Сравнение навыков программирования
| Тест на кодинг | Gemini 3.1 Pro | Claude Sonnet 4.6 | Победитель |
|---|---|---|---|
| SWE-Bench Verified | 80.6% | 79.6% | ✅ Gemini (+1.0 балл) |
| SWE-Bench Pro | 54.2% | 42.7% | ✅ Gemini (+11.5 баллов) |
| Terminal-Bench 2.0 | 68.5% | 59.1% | ✅ Gemini (+9.4 балла) |
Анализ: Gemini 3.1 Pro лидирует во всех трех тестах на программирование. Особенно заметен разрыв в SWE-Bench Pro (сложные задачи в реальном коде) — 11.5 баллов, и в Terminal-Bench (кодинг в терминальной среде) — 9.4 балла. Однако стоит отметить, что Sonnet 4.6 показал 0% ошибок во внутренних тестах Replit по редактированию продакшн-кода и был выбран в качестве базовой модели для кодинг-агента GitHub Copilot. Реальный опыт программирования в рабочей среде может быть ближе к результатам бенчмарков, чем кажется.
Сравнение способностей к рассуждению
| Тест на рассуждение | Gemini 3.1 Pro | Claude Sonnet 4.6 | Победитель |
|---|---|---|---|
| ARC-AGI-2 (абстракция) | 77.1% | 58.3% | ✅ Gemini (+18.8 баллов) |
| GPQA Diamond (наука) | 94.3% | 74.1% | ✅ Gemini (+20.2 балла) |
| HLE (сложное рассуждение) | 44.4% | 19.1% | ✅ Gemini (+25.3 балла) |
| MATH-500 | — | 97.8% | Sonnet силен в математике |
Анализ: Способность к рассуждению — это аспект с самым большим разрывом между моделями. Gemini 3.1 Pro значительно опережает конкурента в тестах ARC-AGI-2, GPQA Diamond и HLE с отрывом от 18 до 25 баллов. Важно уточнить, что эти результаты Gemini были достигнуты в режиме High трехуровневой системы рассуждений, в то время как адаптивное рассуждение Sonnet 4.6 по глубине уступает Opus 4.6. Если ваша основная задача — чистое логическое рассуждение, Gemini 3.1 Pro имеет явное преимущество.
Сравнение в интеллектуальной работе и агентских задачах
| Тест | Gemini 3.1 Pro | Claude Sonnet 4.6 | Победитель |
|---|---|---|---|
| GDPval-AA Elo (знания) | 1,317 | 1,633 | ✅ Sonnet (+316 баллов) |
| Finance Agent (финансы) | — | 63.3% | Выдающиеся данные Sonnet |
| OSWorld (управление ОС) | — | 72.5% | Выдающиеся данные Sonnet |
| MCP Atlas (многошаговость) | 69.2% | 61.3% | ✅ Gemini (+7.9 балла) |
| tau2-bench Retail (инструменты) | — | 91.7% | Выдающиеся данные Sonnet |
Анализ: Здесь мы видим самый неожиданный поворот. В тесте GDPval-AA (симуляция реальной интеллектуальной работы экспертного уровня) Sonnet 4.6 с рейтингом 1,633 Elo не только далеко позади оставил Gemini 3.1 Pro (1,317), но и превзошел собственный флагман Opus 4.6 (1,559). Это означает, что в сценариях высокоуровневой интеллектуальной деятельности, таких как исследовательская аналитика, написание отчетов и разработка бизнес-стратегий, Sonnet 4.6 на данный момент является лучшей моделью на рынке — даже лучше, чем Opus 4.6, который стоит в 5 раз дороже.
Рекомендации по выбору сценариев: Gemini 3.1 Pro vs Sonnet 4.6
Сильные и слабые стороны этих двух моделей отлично дополняют друг друга, поэтому выбор конкретного сценария важнее, чем вопрос «какая из них лучше».

Когда выбирать Gemini 3.1 Pro
- Алгоритмы и спортивное программирование: LiveCodeBench Elo 2,887 — сокрушительное лидерство в написании алгоритмического кода.
- Сложные рассуждения и научные исследования: ARC-AGI-2 77.1%, GPQA Diamond 94.3% — уровень чистой логики здесь на порядок выше, чем у Sonnet 4.6.
- Мультимодальная обработка: Нативная поддержка видео (до 1 часа) и аудио (до 8.4 часов), чего нет в Sonnet 4.6.
- Рабочие процессы MCP-агентов: MCP Atlas 69.2% (отрыв на 7.9 балла) — более надежный выбор для построения многошаговых агентских систем.
- Высокочастотные вызовы с коротким контекстом: При объеме до 200K цена $2/$12 делает эту модель более выгодным вариантом.
Когда выбирать Claude Sonnet 4.6
- Экспертная интеллектуальная работа: GDPval-AA 1,633 Elo — самый высокий балл среди всех текущих моделей. Идеально для аналитических отчетов, финансового анализа и бизнес-стратегий.
- Редактирование продакшн-кода: 0% ошибок в тестах среды Replit; выбрана в качестве базы для кодинг-агента GitHub Copilot.
- Вызов инструментов и Computer Use: tau2-bench 91.7%, OSWorld 72.5% — высочайшая точность в автоматизации действий и вызове функций.
- Сценарии с длинным контекстом: При объеме свыше 200K цена Sonnet 4.6 ($3/$15) становится выгоднее, чем у Gemini ($4/$18).
- Корпоративные приложения: Более зрелое выравнивание безопасности, кэширование промптов (чтение всего $0.30 за млн токенов, экономия 90%) и половинная стоимость при пакетной обработке.
Быстрое подключение Gemini 3.1 Pro и Claude Sonnet 4.6 через API
Быстрый старт
Через платформу APIYI оба модели доступны через единый интерфейс:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Gemini 3.1 Pro — сильнее в рассуждениях и мультимодальности
response = client.chat.completions.create(
model="gemini-3.1-pro",
messages=[{"role": "user", "content": "Проанализируй временную сложность этого кода и оптимизируй его"}]
)
print(response.choices[0].message.content)
Посмотреть пример вызова Sonnet 4.6 и автоматического переключения по сценариям
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Claude Sonnet 4.6 — лучше справляется с интеллектуальными задачами и вызовами инструментов
response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[{"role": "user", "content": "Напиши отчет по анализу рынка за первый квартал, включая сравнение с конкурентами и рекомендации по росту"}]
)
print(response.choices[0].message.content)
# Автоматическая маршрутизация по типу задачи
def route_model(prompt, task_type="general"):
model_map = {
"reasoning": "gemini-3.1-pro",
"multimodal": "gemini-3.1-pro",
"algorithm": "gemini-3.1-pro",
"knowledge": "claude-sonnet-4-6",
"production_code": "claude-sonnet-4-6",
"tool_call": "claude-sonnet-4-6",
"general": "gemini-3.1-pro",
}
return client.chat.completions.create(
model=model_map.get(task_type, "gemini-3.1-pro"),
messages=[{"role": "user", "content": prompt}]
)
Совет: Платформа APIYI (apiyi.com) позволяет подключать обе модели одновременно, используя один и тот же API-ключ для переключения. Сервис предоставляет бесплатный тестовый баланс — рекомендуем сравнить результаты на ваших реальных задачах.
Глубокое сравнение стоимости Gemini 3.1 Pro и Sonnet 4.6
Оценка ежемесячных затрат для трех типичных сценариев использования:
| Сценарий использования | Средний расход токенов в месяц | Gemini 3.1 Pro | Claude Sonnet 4.6 | Кто дешевле |
|---|---|---|---|---|
| Легкое использование (5 млн вх. + 1 млн исх.) | 6 млн | $22 | $30 | Gemini выгоднее на 27% |
| Умеренное использование (20 млн вх. + 5 млн исх.) | 25 млн | $100 | $135 | Gemini выгоднее на 26% |
| Интенсивная работа с длинным контекстом (50 млн вх. >200K + 10 млн исх.) | 60 млн | $380 | $300 | ⚠️ Sonnet выгоднее на 21% |
🎯 Вывод по стоимости: При обычном использовании Gemini 3.1 Pro дешевле примерно на 26-27%. Однако, если вы часто работаете с длинным контекстом более 200K токенов (например, анализ всей кодовой базы или длинных документов), Sonnet 4.6 оказывается выгоднее. Это связано с тем, что у Gemini цена за длинный контекст вырастает до $4/$18, в то время как у Sonnet она остается неизменной — $3/$15. С учетом кэширования промптов у Sonnet (чтение всего $0.30 за млн токенов), реальные затраты могут быть ниже еще на 30-50%.
Подключение через платформу APIYI (apiyi.com) позволяет получить дополнительные скидки, что еще больше снижает стоимость использования обеих моделей.
Часто задаваемые вопросы
Q1: Показатель GDPval-AA у Sonnet 4.6 выше, чем у флагманской Opus 4.6. Это нормально?
Да, это действительно так. Sonnet 4.6 набрал 1 633 Elo в тесте GDPval-AA, обойдя Opus 4.6 с его 1 559 баллами. Anthropic официально подтвердили эти данные. Вероятная причина в том, что Sonnet 4.6 прошел специальную оптимизацию для корпоративных задач и работы со знаниями, в то время как Opus 4.6 больше ориентирован на сложные общие рассуждения и обработку сверхдлинного контекста. Индекс предпочтения разработчиков для Sonnet 4.6 также впечатляет: 70% (по сравнению с Sonnet 4.5) и 59% (по сравнению с Opus 4.5).
Q2: Какая модель лучше подходит для создания AI-агентов?
Все зависит от типа агента. Если это агент для многошаговых рабочих процессов на базе MCP, то Gemini 3.1 Pro лидирует с результатом 69,2% в MCP Atlas (отрыв в 7,9 балла). Если нужен агент с интенсивным вызовом инструментов (например, OpenClaw), то Sonnet 4.6 надежнее с его 91,7% в tau2-bench. Для агентов категории Computer Use (управление браузером и рабочим столом) Sonnet 4.6 показывает один из лучших результатов на сегодня — 72,5% в OSWorld. Обе модели можно протестировать напрямую через платформу APIYI (apiyi.com).
Q3: Я сейчас использую Sonnet 4.5. Стоит ли переходить на Sonnet 4.6 или лучше выбрать Gemini 3.1 Pro?
Если вас устраивает опыт работы со знаниями и написанием кода в Sonnet 4.5, то переход на Sonnet 4.6 — самый логичный и безопасный шаг. API полностью совместим, цена осталась прежней, а производительность выросла по всем фронтам (SWE-Bench поднялся с 77,2% до 79,6%, а ARC-AGI-2 — с 13,6% до 58,3%, то есть в 4,3 раза). Если же ваши основные задачи связаны с логическими рассуждениями, мультимодальностью или алгоритмическим программированием, у Gemini 3.1 Pro в этих областях есть заметное преимущество. Советуем попробовать обе модели на платформе APIYI (apiyi.com).
Итоги
Основные выводы по сравнению Gemini 3.1 Pro и Claude Sonnet 4.6:
- Для рассуждений и мультимодальных задач выбирайте Gemini 3.1 Pro: преимущество в 18,8 балла в ARC-AGI-2 и 20,2 балла в GPQA Diamond, нативная поддержка видео и аудио, более выгодная цена при коротком контексте.
- Для работы со знаниями и промышленного программирования выбирайте Claude Sonnet 4.6: 1 633 Elo в GDPval-AA — это самый высокий балл среди всех моделей (включая Opus 4.6), 0% ошибок в Replit, лучший выбор для GitHub Copilot.
- В сценариях с длинным контекстом Sonnet выгоднее: при контексте более 200K токенов Sonnet стоит $3/$15 против $4/$18 у Gemini, а использование кэширования промптов позволяет сэкономить еще 30–50% затрат.
Эти две модели — лидеры по соотношению цены и качества среди передовых решений в феврале 2026 года. Лучшая стратегия — использовать их в связке в зависимости от конкретного сценария. Рекомендуем подключаться через APIYI (apiyi.com), чтобы переключаться между моделями по мере необходимости, используя один и тот же API-ключ.
📚 Справочные материалы
-
Анонс Claude Sonnet 4.6: Официальный блог Anthropic
- Ссылка:
anthropic.com/news/claude-sonnet-4-6 - Описание: Полное описание функций Sonnet 4.6, данные бенчмарков и функция адаптивного мышления.
- Ссылка:
-
Официальный блог Gemini 3.1 Pro: Анонс от Google DeepMind
- Ссылка:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - Описание: Трехуровневая система мышления Gemini 3.1 Pro и полные данные о производительности.
- Ссылка:
-
Практическое сравнение от Tom's Guide: Тестирование Gemini 3.1 Pro против Sonnet 4.6 в 7 сложных испытаниях
- Ссылка:
tomsguide.com/ai/i-tested-gemini-3-1-pro-vs-claude-sonnet-4-6-in-7-tough-challenges-and-there-was-one-clear-winner - Описание: Сравнение реальной производительности в практических сценариях.
- Ссылка:
-
Рейтинг Artificial Analysis: Сторонняя независимая платформа для оценки моделей
- Ссылка:
artificialanalysis.ai/leaderboards/models - Описание: Объективные данные для сравнительного анализа производительности, скорости и стоимости.
- Ссылка:
Автор: Техническая команда
Обсуждение: Делитесь своим опытом использования в комментариях. Больше новостей об ИИ-моделях можно найти на сайте APIYI apiyi.com





