No dia 6 de maio de 2026, a xAI enviou um comunicado oficial a todos os usuários da API com o título "Grok 4.3 release and xAI API model retirement". A mensagem trouxe duas informações cruciais para os desenvolvedores: o Grok 4.3 já está totalmente disponível na API e, simultaneamente, oito modelos legados — incluindo grok-4-fast, grok-4-0709, grok-3, grok-code-fast-1 e grok-imagine-image-pro — serão descontinuados em 15 de maio de 2026, às 12:00 PT. Por trás deste e-mail, há não apenas uma grande atualização de versão, mas também uma contagem regressiva de apenas 9 dias para a migração.
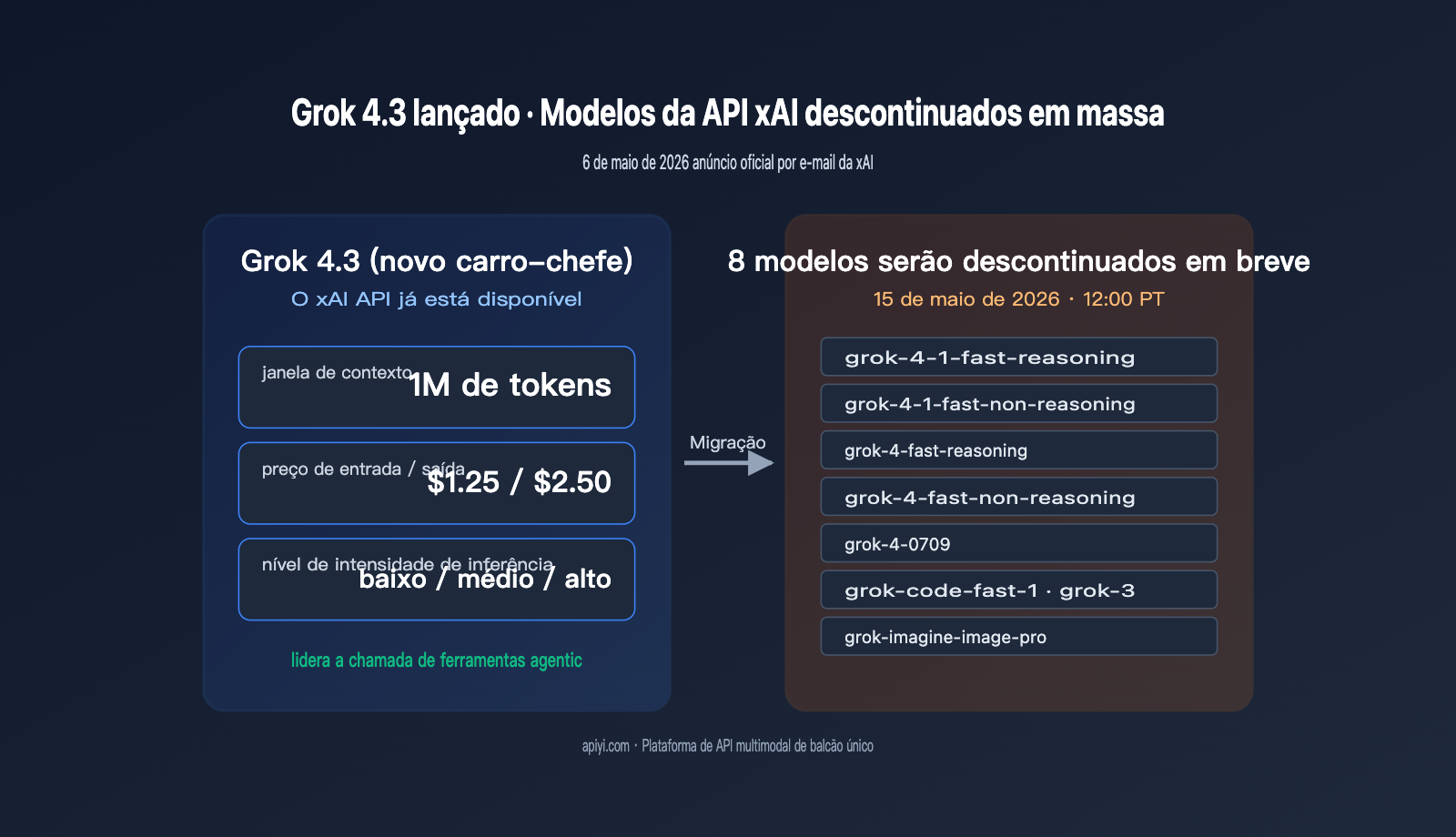
O que mais chama a atenção no lançamento do Grok 4.3 não é apenas a mudança de nome, mas a combinação de uma janela de contexto de 1M de tokens, preços de entrada/saída de US$ 1,25/US$ 2,50 e três níveis ajustáveis de intensidade de raciocínio. Essa faixa de preço coloca o Grok 4.3 diretamente na concorrência com modelos de raciocínio mainstream como o Gemini 3.1 Pro e o GPT-5.4, mantendo a vantagem característica da xAI de alta velocidade de processamento de tokens. Recomendamos que as equipes que dependem da família Grok realizem testes de integração o quanto antes através da plataforma APIYI (apiyi.com); a interface compatível com OpenAI permite reduzir ao mínimo os custos de migração ao alternar entre modelos.
Análise completa das especificações e preços do Grok 4.3
O Grok 4.3 é o modelo emblemático de última geração que a xAI descreveu no e-mail como "o modelo mais rápido e inteligente que já construímos". Ele ocupa as primeiras posições nos rankings de agentic tool calling e instruction following, sendo posicionado como um carro-chefe versátil para código, agentes e raciocínio complexo. Em termos de especificações, o Grok 4.3 expandiu a janela de contexto de 256K, da era do Grok 4, para 1M de tokens, equiparando-se ao Gemini 3 Pro e ao Claude 4.7, o que significa que é possível inserir bases de código completas ou longos documentos técnicos de uma só vez.
A tabela abaixo resume os parâmetros principais do Grok 4.3 na API da xAI, com dados provenientes do e-mail oficial da xAI e da página de testes de terceiros da Artificial Analysis.
| Parâmetro | Valor no Grok 4.3 | Observações |
|---|---|---|
| Janela de contexto | 1.000.000 de tokens | Entrada + Saída compartilhadas |
| Preço de entrada | US$ 1,25 / 1M tokens | 50% mais barato que o GPT-5.4, igual ao Gemini 3.1 Pro |
| Preço de saída | US$ 2,50 / 1M tokens | Redução de cerca de 83% em relação aos US$ 15 da era Grok 4 |
| Intensidade de raciocínio | 3 níveis: low / medium / high | Controla o orçamento de raciocínio profundo via parâmetro |
| Modalidade de entrada | Texto + Imagem | Suporta compreensão visual |
| Modalidade de saída | Texto | Não gera imagens diretamente |
| Chamada de ferramentas | Function calling nativo | Suporta saída estruturada e chamadas paralelas |
| Velocidade de saída | Aprox. 207 tokens/s | Testado pela Artificial Analysis |
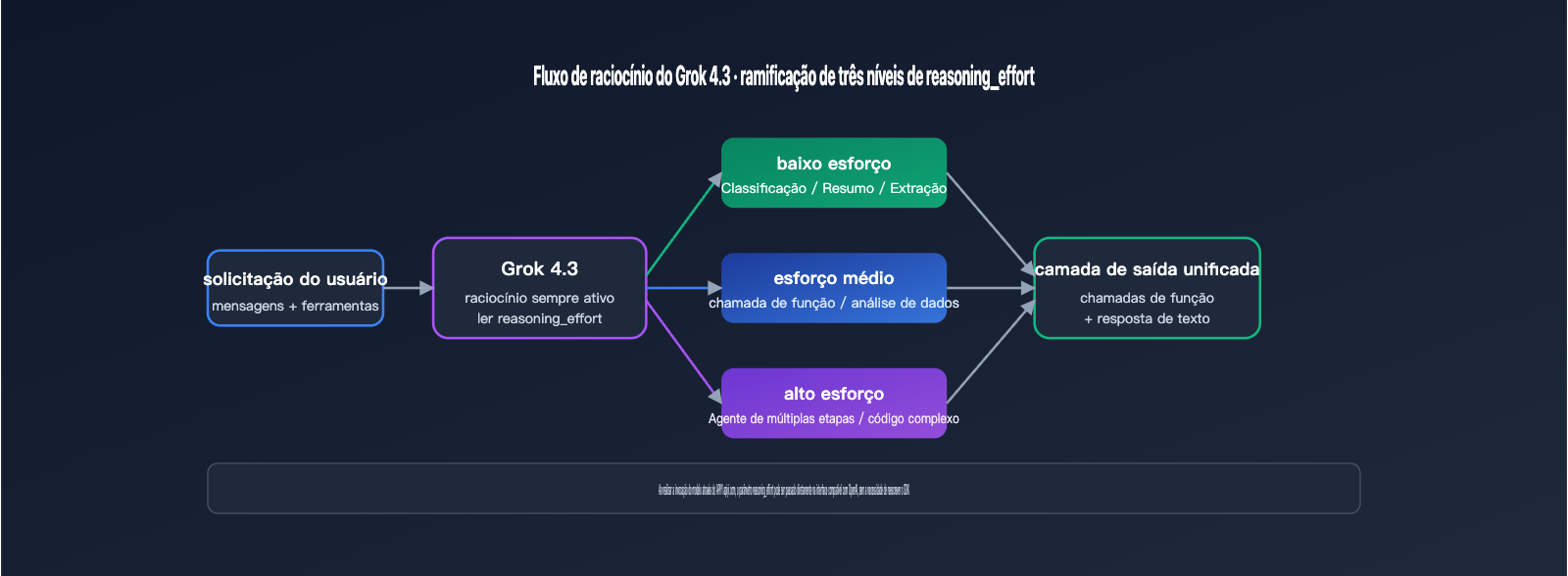
Os 3 níveis de intensidade de raciocínio (reasoning effort) são a principal novidade que diferencia o Grok 4.3 da geração anterior. Eles permitem que os desenvolvedores ajustem a profundidade de "pensamento" do modelo de acordo com a complexidade da tarefa, impactando diretamente a latência e o custo. Esse mecanismo é inspirado no design de reasoning_effort da OpenAI, mas a xAI manteve o raciocínio como um estado "sempre ativo", permitindo apenas o ajuste da profundidade. A tabela abaixo organiza os cenários de uso típicos e os impactos de cada nível.
| Intensidade de raciocínio | Cenários típicos | Características de latência | Impacto no custo |
|---|---|---|---|
| low | Classificação simples, resumos, extração de regras | Próximo a modelos sem raciocínio | Menor volume de tokens de saída |
| medium | Chamada de função, análise de dados, preenchimento de código | Equilíbrio entre latência e qualidade | Nível recomendado por padrão |
| high | Agentes de múltiplos passos, matemática complexa, código longo | Fase de "pensamento" mais longa | Aumento significativo de tokens de saída |
🎯 Dica de integração: Para equipes que não têm certeza de qual nível escolher, recomendamos realizar um teste com um conjunto de amostras reais de negócio usando o nível medium na plataforma APIYI (apiyi.com) e, em seguida, decidir se vale a pena subir para o nível high com base na precisão e no retorno sobre o custo. A interface unificada permite alternar o parâmetro reasoning_effort entre diferentes modelos com um clique, sem a necessidade de reescrever o SDK.
Desempenho do Grok 4.3 nos rankings de agentic e instruction following
O motivo pelo qual o Grok 4.3 foi destacado pela xAI em e-mails como "líder nos rankings de agentic tool calling e instruction following" baseia-se em dados de benchmarks de terceiros, como Artificial Analysis, τ²-Bench, IFBench e GDPval-AA. O Artificial Analysis Intelligence Index atribuiu uma pontuação global de 53,2, com um custo total de execução de cerca de US$ 395, o que representa uma economia de aproximadamente 20% em relação ao Grok 4.20. No τ²-Bench Telecom (que simula chamadas de ferramentas bidirecionais em atendimento ao cliente), o cenário mais próximo de um agente real, o Grok 4.3 alcançou 98%, uma melhoria de 5 pontos percentuais em relação ao Grok 4.20, empatando com o GLM-5.1.
Para os desenvolvedores, o que merece mais atenção é o GDPval-AA, um benchmark que mede o valor real do fluxo de trabalho econômico. O Grok 4.3 obteve 1500 ELO no GDPval-AA, um salto de 321 pontos em relação aos 1179 ELO do Grok 4.20 0309 v2, superando modelos como Gemini 3.1 Pro Preview, Muse Spark, GPT-5.4 mini (xhigh) e Kimi K2.5. Em termos de instruction following, o Grok 4.3 manteve 81% no IFBench, empatado com o Grok 4.20 0309 v2.
| Benchmark | Pontuação Grok 4.3 | Referência da Categoria | Capacidade Avaliada |
|---|---|---|---|
| AA Intelligence Index | 53.2 | Superior a 98% dos modelos | Inteligência Geral |
| AA Coding Index | 41.0 | Superior a 89% dos modelos | Codificação e Refatoração |
| τ²-Bench Telecom | 98% | Empatado com GLM-5.1 | Chamada de ferramenta + Colaboração |
| IFBench | 81% | Empatado com Grok 4.20 | Seguimento de instruções complexas |
| GDPval-AA | ELO 1500 | Superou Gemini 3.1 Pro Preview | Valor real de fluxo de trabalho |
Vale notar que o ponto forte do Grok 4.3 são os fluxos de trabalho de agentes e a chamada de ferramentas, não competições puras de algoritmos. Para aplicações como agentes de código, agentes de navegador ou bots de atendimento que exigem saída JSON estável e chamadas de ferramentas em várias etapas, a confiabilidade do Grok 4.3 é significativamente superior à da geração anterior. No entanto, se o cenário principal da sua equipe for a síntese pura de código (estilo SWE-bench), recomendamos testar o Grok 4.3, Claude 4.7 Opus e GPT-5.4 no mesmo conjunto de testes na plataforma APIYI (apiyi.com) e decidir o modelo principal com base na taxa de sucesso.
Lista de descontinuação de modelos da API xAI e sugestões de migração
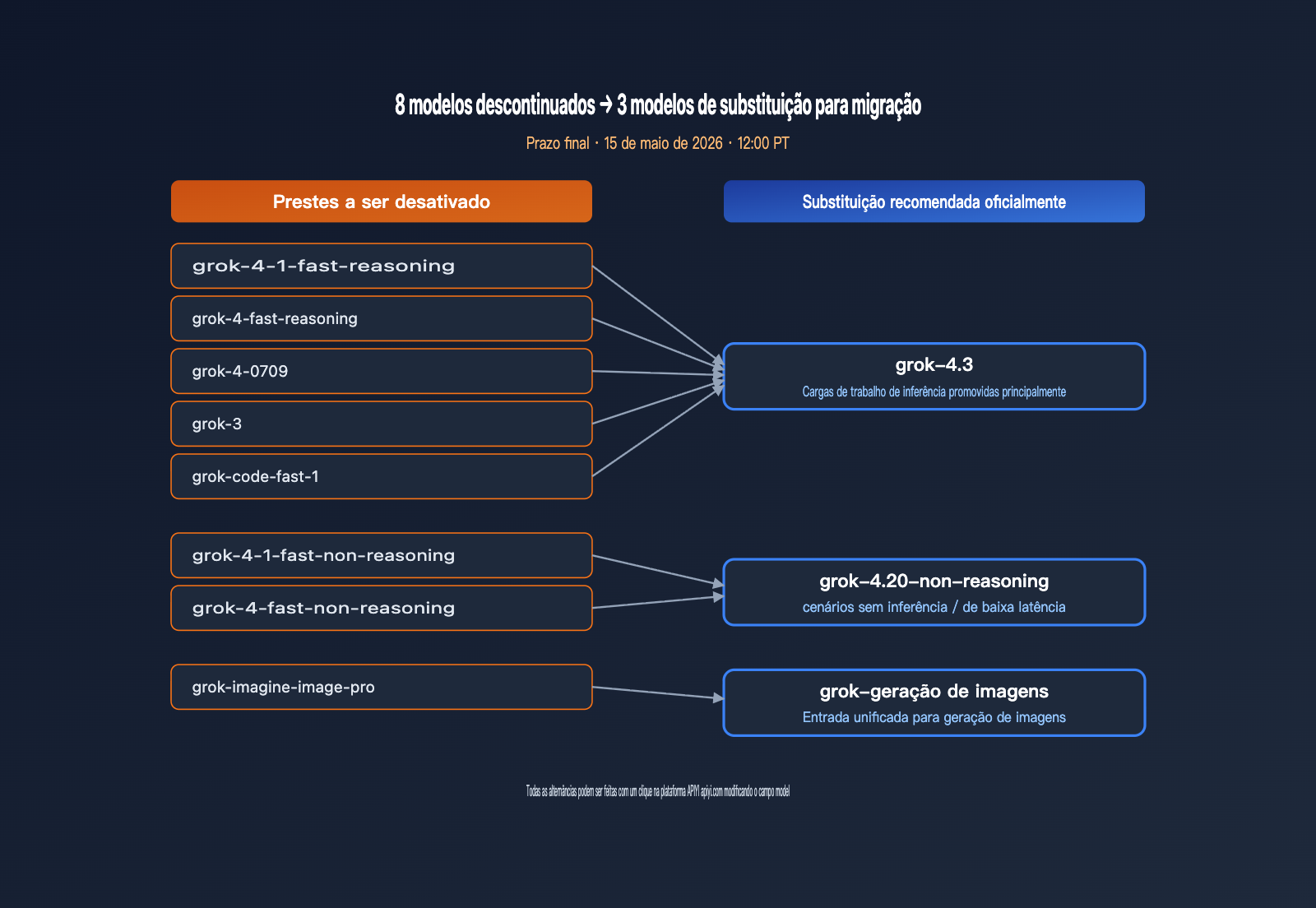
A xAI está descontinuando 8 modelos de uma só vez, abrangendo raciocínio de texto, modelos de código e geração de imagens, essencialmente limpando todo o portfólio da era Grok 4. Para equipes que possuem nomes de modelos "hard-coded" em seus sistemas, este é um prazo rigoroso que exige a atualização do código em até 9 dias. A tabela abaixo resume os modelos afetados e os caminhos de substituição recomendados oficialmente.
| Modelo a ser descontinuado | Tipo | Substituição Recomendada | Notas de Migração |
|---|---|---|---|
| grok-4-1-fast-reasoning | Raciocínio | grok-4.3 | Melhor qualidade, menor preço |
| grok-4-1-fast-non-reasoning | Não-raciocínio | grok-4.20-non-reasoning | Mantém baixa latência |
| grok-4-fast-reasoning | Raciocínio | grok-4.3 | Ganha 1M de janela de contexto |
| grok-4-fast-non-reasoning | Não-raciocínio | grok-4.20-non-reasoning | Compatível com a API |
| grok-4-0709 | Raciocínio | grok-4.3 | Snapshot inicial do Grok 4 |
| grok-code-fast-1 | Código | grok-4.3 | Cenários de código unificados |
| grok-3 | Geral | grok-4.3 | Fim da era Grok 3 |
| grok-imagine-image-pro | Geração de imagem | grok-imagine-image | Simplificação de SKU |
A data de descontinuação é 15 de maio de 2026, às 12:00 PT (16 de maio, às 03:00 no horário de Pequim). Após esse prazo, todas as solicitações enviadas a esses 8 IDs de modelo retornarão erro. Contando a partir do e-mail enviado em 6 de maio, restam apenas 9 dias, um cronograma apertado para operações de médio e grande porte. Recomendamos dividir a migração em 3 etapas: primeiro, localizar todos os IDs de modelo hard-coded no código; segundo, executar um teste de carga na plataforma APIYI (apiyi.com); terceiro, alternar o campo model via variáveis de ambiente em vez de alterar a lógica de negócio.
Um lembrete especial: o grok-code-fast-1 foi o modelo padrão para muitos projetos de agentes de código no último semestre. Sua descontinuação significa que todas as ferramentas do tipo Cursor, plugins de IDE e agentes de CLI que dependem desse ID precisarão migrar para o grok-4.3. Em cenários de código, a estabilidade de chamada de ferramenta do Grok 4.3 é melhor que a do grok-code-fast-1, mas o custo por token é ligeiramente maior, sendo necessário reavaliar o orçamento de chamadas.
Comparativo: Grok 4.3 vs. GPT-5.4, Claude 4.7 e Gemini 3.1 Pro
Com o lançamento do Grok 4.3 no segundo trimestre de 2026, o mercado de modelos de ponta vive seu período de competição mais intenso da história. O Claude Opus 4.7 mantém a liderança no SWE-bench Verified com 87,6%, o Gemini 3.1 Pro atingiu 94,3% no GPQA Diamond, e o GPT-5.4 continua sendo a referência básica em estabilidade de raciocínio para textos longos. O posicionamento do Grok 4.3 é claro: "inteligência média + preço baixíssimo + cadeia de ferramentas de agente robusta", focado em cenários de alta frequência sensíveis a custos.
A tabela abaixo compara os dados principais dos quatro modelos emblemáticos em dimensões comuns. Os preços estão em dólares por milhão de tokens.
| Modelo | Preço Entrada | Preço Saída | Janela de Contexto | Cenários de Vantagem |
|---|---|---|---|---|
| Grok 4.3 | $1,25 | $2,50 | 1M | Cadeia de ferramentas de agente, alta frequência, raciocínio médio |
| GPT-5.4 | $2,50 | $15,00 | 400K | Consistência em textos longos, planejamento complexo |
| Claude 4.7 Opus | $15,00 | $75,00 | 1M | Programação de elite, escrita de documentos, análise profunda |
| Gemini 3.1 Pro | $2,00 | $12,00 | 2M | Multimodal, compreensão de vídeo, documentos ultralongos |
A partir desta tabela, um fato fica evidente: o preço do token de saída do Grok 4.3 é 30 vezes mais barato que o do Claude 4.7 Opus e cerca de 4,8 vezes mais barato que o do Gemini 3.1 Pro. Para negócios como agentes de atendimento ao cliente de alta frequência, linters de código ou limpeza de dados em lote, a vantagem de custo unitário do Grok 4.3 é amplificada exponencialmente. No entanto, em cenários que exigem qualidade de codificação extrema ou compreensão multimodal, o Claude 4.7 Opus e o Gemini 3.1 Pro continuam insubstituíveis.
🎯 Sugestão de estratégia multimodelo: Recomendamos usar o Grok 4.3 como camada geral de alta frequência, o Claude 4.7 Opus para camadas de código complexo e saída de documentos, e o Gemini 3.1 Pro para a camada multimodal. Utilize a interface unificada da APIYI (apiyi.com) na camada de roteamento de negócios para distribuir as chamadas. Assim, você aproveita o benefício de baixo custo do Grok 4.3 e, ao mesmo tempo, utiliza modelos mais potentes em pontos críticos.
Guia de migração e exemplo de código para Grok 4.3
A migração para o Grok 4.3 é bastante direta do ponto de vista de engenharia. A xAI fornece uma interface de chat completions compatível com a OpenAI; a maior parte do trabalho de migração consiste em modificar os campos base_url e model. Para projetos que já utilizam o SDK da OpenAI, o exemplo minimalista em Python abaixo é o código de integração completo.
from openai import OpenAI
# Configuração do cliente apontando para o serviço proxy de API da APIYI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="grok-4.3",
messages=[
{"role": "user", "content": "Explique o que é reasoning effort em uma frase."},
],
extra_body={"reasoning_effort": "medium"},
)
print(resp.choices[0].message.content)
Ao apontar a base_url para a plataforma APIYI (apiyi.com), sua aplicação ganha um ponto de entrada unificado para Grok 4.3, Claude 4.7, GPT-5.4 e Gemini 3.1 Pro. Posteriormente, a troca de modelos exige apenas a alteração do parâmetro model, sem a necessidade de reescrever a autenticação ou o código de roteamento. Essa abstração unificada reduz significativamente os riscos de migração antes do prazo final de desativação em 15 de maio.
Para a migração de modelos antigos, preparamos uma tabela de referência com as alterações mínimas necessárias para atualizar os IDs dos modelos, que pode ser aplicada diretamente ao seu código.
| ID do modelo antigo | ID do novo modelo | Precisa alterar outros parâmetros? |
|---|---|---|
| grok-3 | grok-4.3 | Opcional: adicionar reasoning_effort |
| grok-4-0709 | grok-4.3 | Opcional: adicionar reasoning_effort |
| grok-4-fast-reasoning | grok-4.3 | Opcional: adicionar reasoning_effort |
| grok-4-fast-non-reasoning | grok-4.20-non-reasoning | Nenhuma alteração necessária |
| grok-code-fast-1 | grok-4.3 | Recomendado: reasoning_effort=high |
| grok-imagine-image-pro | grok-imagine-image | Endpoint da API de imagem permanece igual |
FAQ: Perguntas Frequentes sobre o Grok 4.3
P1: O Grok 4.3 realmente suporta 1M de janela de contexto? O desempenho cai em textos longos?
Sim, o Grok 4.3 oferece oficialmente uma janela de contexto de 1M de tokens na API da xAI, equiparando-se ao Claude 4.7 Opus. No entanto, como ocorre com todos os modelos de contexto longo, a compreensão de solicitações pode sofrer uma certa degradação após os 600K tokens. Recomendamos colocar as informações cruciais na primeira metade do documento. Você pode usar a plataforma APIYI (apiyi.com) para realizar um teste de taxa de recuperação de busca com seus documentos reais de negócio antes de decidir adotar o Grok 4.3 como seu principal modelo para textos longos.
P2: Como escolher entre as intensidades de raciocínio low / medium / high?
Use low para tarefas de baixo risco (classificação, resumo, extração de regras), medium para operações de rotina (atendimento ao cliente, invocação de funções, análise de dados) e high para raciocínios complexos (Agentes de múltiplas etapas, código de longa cadeia, matemática complexa). O nível high aumentará significativamente o consumo de tokens de saída e a latência; recomendamos avaliar com base no seu orçamento e no SLA de latência.
P3: Após 15 de maio às 12:00 PT, os modelos antigos ainda poderão ser usados?
Não. O e-mail da xAI afirma claramente: "Após 15 de maio de 2026, as solicitações para esses modelos não funcionarão mais". Solicitações expiradas retornarão um erro diretamente. Todo código com IDs de modelos antigos "hard-coded" deve ser atualizado antes do prazo.
P4: Como reduzir ao mínimo o custo de migração?
A abordagem mais segura é abstrair o campo model em variáveis de ambiente ou itens de configuração no seu negócio, em vez de deixá-lo fixo no código. Com o endpoint compatível com OpenAI da APIYI (apiyi.com), a migração se resume a uma única alteração de configuração e um teste de regressão.
P5: O Grok 4.3 é adequado para um Agente de Programação (Coding Agent)?
Sim. O Grok 4.3 obteve 98% no τ²-Bench Telecom; a estabilidade na invocação de ferramentas e em diálogos de múltiplas rodadas é superior ao grok-code-fast-1. Além disso, o custo unitário é extremamente baixo, tornando-o ideal para plugins de IDE de alta frequência, Agentes CLI e scripts de automação de operações.
Resumo: Pontos principais sobre o lançamento do Grok 4.3 e a migração da API da xAI
O maior destaque do lançamento do Grok 4.3 não é apenas ser "mais forte", mas ser "mais barato e mais forte ao mesmo tempo". O preço de $1,25/$2,50 coloca a xAI no mesmo patamar de custo do Gemini 3.1 Pro, oferecendo 1M de janela de contexto e invocação de ferramentas de alta qualidade, redefinindo o padrão de custo-benefício para a camada de uso geral de alta frequência. Ao mesmo tempo, a descontinuação de 8 modelos antigos em 15 de maio serve como um lembrete para todas as equipes: os IDs de modelos não devem ser "hard-coded" no código de negócio, mas sim abstraídos por trás de uma camada de roteamento configurável.
Recomendamos utilizar o Grok 4.3 como o principal motor para invocações de alta frequência e cadeias de ferramentas de Agentes, realizando a migração através da interface unificada da APIYI (apiyi.com). Isso reduz o custo de troca ao mínimo, mantendo a capacidade de combinar múltiplos modelos, como Claude 4.7 Opus, GPT-5.4 e Gemini 3.1 Pro, permitindo um agendamento dinâmico entre diferentes tarefas para alcançar o equilíbrio ideal entre custo e qualidade.
Equipe técnica da APIYI · Focada em conteúdos práticos sobre APIs de modelos de IA e ferramentas para desenvolvedores. Para mais artigos técnicos, visite apiyi.com