Nota do autor: Compartilho aqui minha experiência prática com o Claude Opus 4.7 no processamento de arquivos CSV e Excel, explicando por que você não deve simplesmente despejar tabelas grandes na IA, mas sim usá-la para escrever scripts, construir ferramentas e realizar validações.
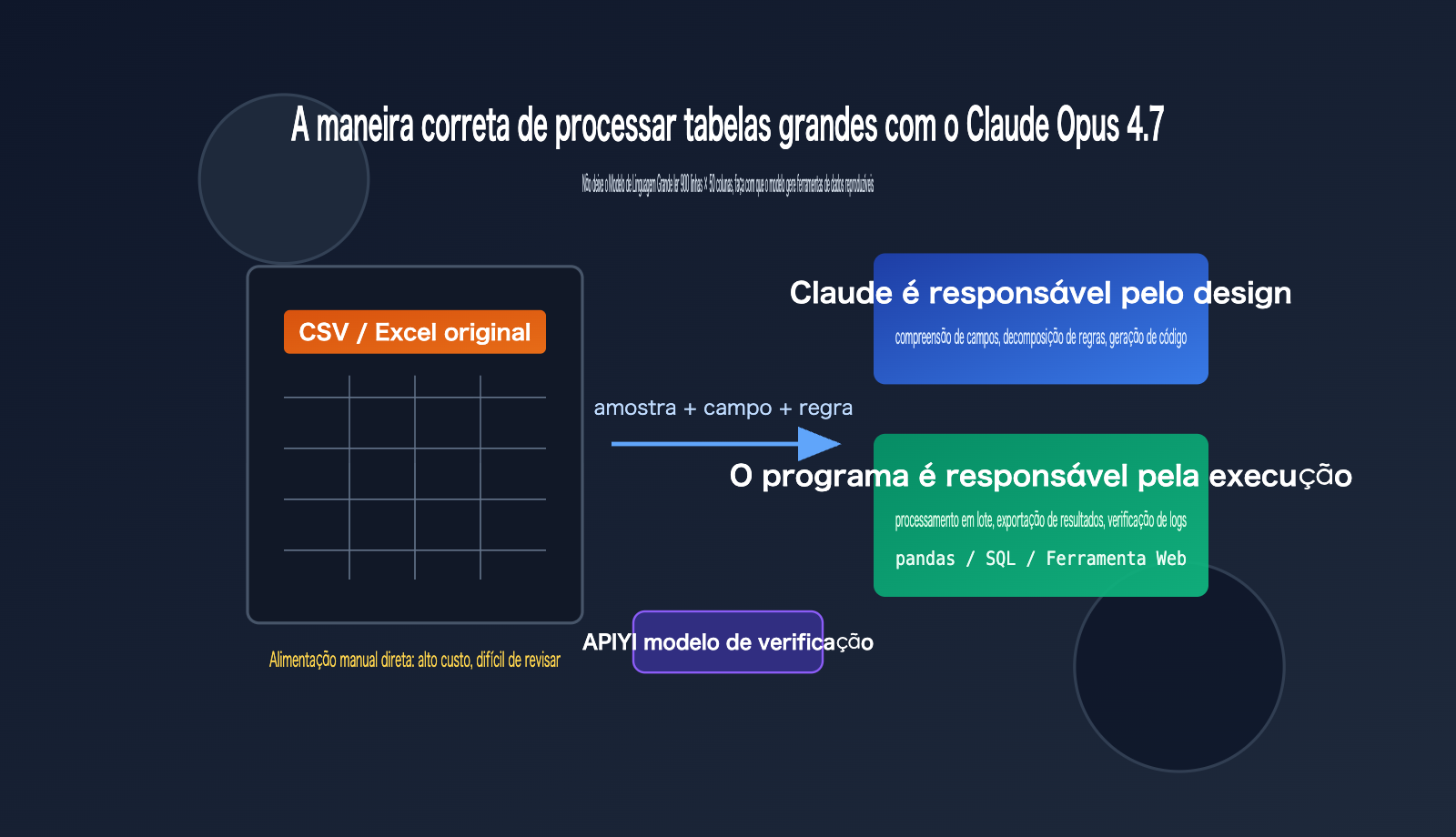
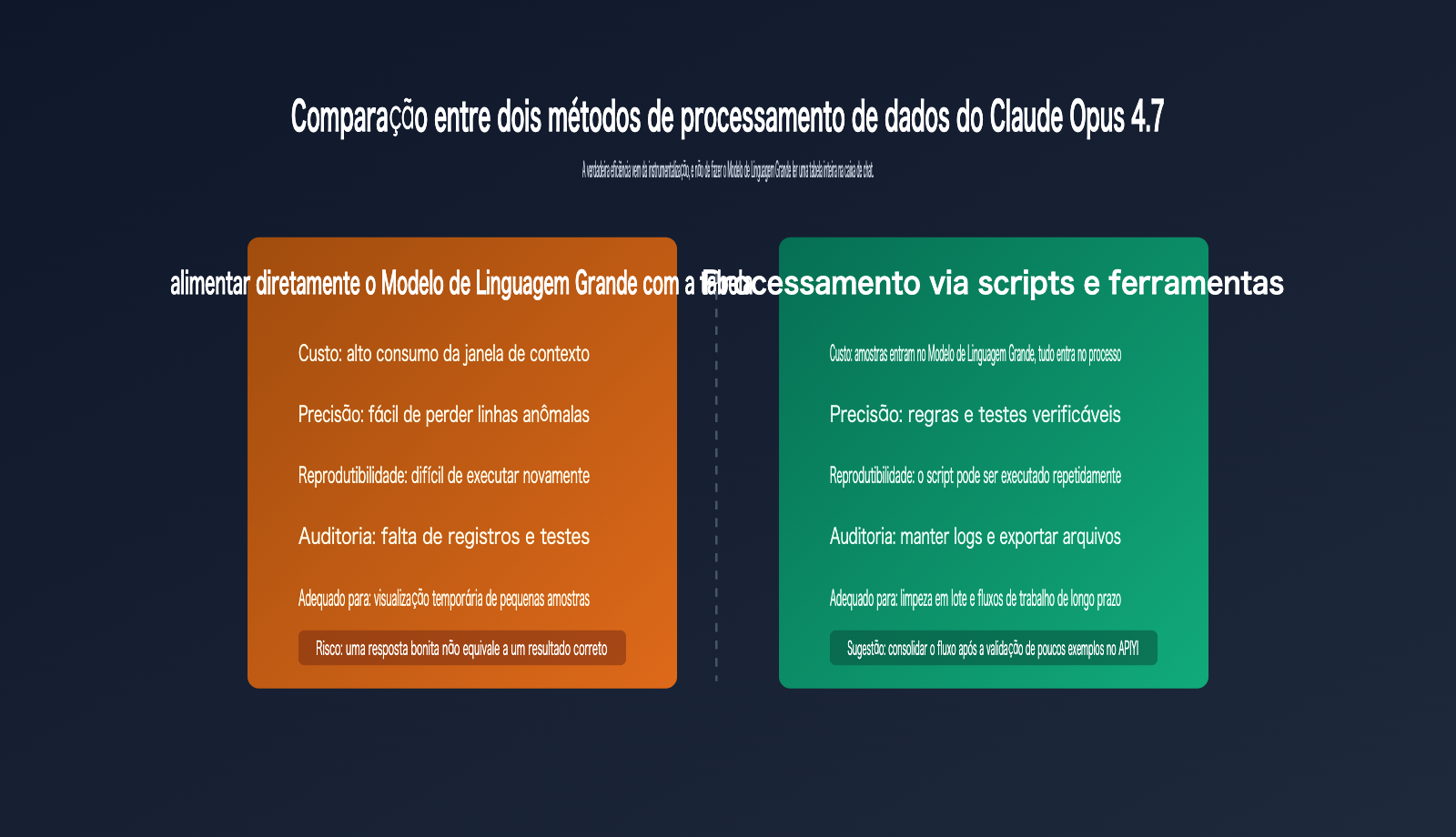
Se você tem um arquivo CSV ou Excel com mais de 900 linhas e 50 colunas e pergunta diretamente ao Claude Opus 4.7 "ajude-me a processar esta tabela", é muito provável que você receba uma resposta que parece inteligente, mas que não é reproduzível. O problema não é que o Claude Opus 4.7 não seja capaz, mas sim que você o está tratando como um leitor de tabelas humano, e não como um designer de fluxos de processamento de dados.
A melhor abordagem é: forneça ao Claude Opus 4.7 uma pequena amostra dos dados, a descrição completa dos campos e o resultado desejado. Peça para ele escrever um script em Python, gerar uma ferramenta web ou projetar um pipeline de dados reproduzível, e então use esse script para processar os dados completos. Isso permite que você aproveite a capacidade de raciocínio e codificação do modelo, enquanto deixa o cálculo, a filtragem, a agregação e a validação para um programa determinístico.
Pontos principais no processamento de CSV com Claude Opus 4.7
O Claude Opus 4.7 já é um modelo muito forte em codificação e fluxos de trabalho com agentes, e a própria empresa destaca sua adequação para códigos complexos, fluxos de trabalho corporativos e cenários de planilhas. Mas "janela de contexto maior" não significa que você deve colocar a tabela inteira no chat, especialmente quando os dados contêm muitas linhas repetidas, valores discrepantes, colunas ocultas, formatação confusa e regras de negócio.
A maneira realmente eficiente de processar CSV com o Claude Opus 4.7 é colocar o modelo em três posições: entender o objetivo de negócio, gerar o programa de processamento e explicar os resultados da saída. Quanto à leitura linha a linha, conversão de tipos, remoção de duplicatas, agregação, classificação e exportação de arquivos, isso deve ser feito por Python, SQL, ferramentas baseadas em navegador ou pela própria cadeia de ferramentas de análise de dados do Claude.
| Cenário | Problema de deixar a IA ler a tabela diretamente | Abordagem recomendada com Claude Opus 4.7 | Vantagem do resultado |
|---|---|---|---|
| CSV de 900 linhas × 50 colunas | Alto consumo de contexto, risco de perder colunas/linhas | Forneça 20 linhas de amostra e descrição dos campos, peça um script pandas | Reproduzível, execução em lote |
| Excel com várias abas | Fórmulas ocultas, células mescladas e formatação afetam a compreensão | Peça primeiro um script de detecção de estrutura, gere uma visão geral | Entenda a estrutura antes de processar |
| Filtragem por regras de negócio | Linguagem natural é propensa a omitir condições de contorno | Peça ao Claude para converter regras em funções e casos de teste | Regras claras, verificáveis |
| Geração de relatórios | Respostas únicas são difíceis de revisar | Peça ao Claude para gerar script de exportação e resumo de validação | Saída estável, fácil de entregar |
Aqui há um julgamento muito importante: o Claude Opus 4.7 pode "participar da análise de dados", mas não deve ser o "único ambiente de execução para os dados em si". Se você precisar validar repetidamente comandos de processamento de dados ou seleção de modelos via API, recomendamos usar o serviço proxy de API da APIYI (apiyi.com) para testes com pequenas amostras e, em seguida, consolidar os comandos estáveis em scripts, evitando ter que copiar tabelas grandes toda vez.
Princípios de divisão de tarefas para processamento de CSV com Claude Opus 4.7
O Claude Opus 4.7 é mais adequado para julgamentos de alto nível, como inferência de significado de campos, design de estratégias de limpeza, sugestão de casos anômalos, geração de código e explicação de resultados. Ele não é adequado para realizar cálculos determinísticos na caixa de chat, pois o texto da tabela na janela de chat perde parte das informações estruturais e não é conveniente para execuções repetidas ou gerenciamento de versões.
Um princípio mais sólido é "pequenas amostras para o modelo, grandes dados para o programa". Você pode fornecer as primeiras 20 linhas, 20 linhas aleatórias e 20 linhas anômalas, além de um dicionário de campos e a saída desejada. Depois que o Claude Opus 4.7 gerar o script com base nessas informações, você executa o script no arquivo CSV ou Excel completo. Assim, o modelo é responsável pelo design e o programa é responsável pela execução.
Por que você não deve enviar planilhas grandes diretamente para o Claude Opus 4.7
Embora Excel e CSV pareçam ser apenas tabelas, a complexidade entre eles é muito diferente. O CSV é uma estrutura simples de linhas e colunas em texto puro, enquanto o Excel pode conter múltiplas planilhas (Sheets), fórmulas, formatações, filtros, colunas ocultas, células mescladas, séries de datas e formatos numéricos localizados. Ao copiar e colar o conteúdo do Excel como texto para a IA, você geralmente "achata" essas informações cruciais, fazendo com que o modelo não veja a pasta de trabalho original, mas sim um texto plano corrompido.
Documentos oficiais em inglês mostram que os produtos relacionados ao Claude já suportam ferramentas de análise, execução de código, plugins de dados e recursos específicos para Excel; tudo isso aponta para um fato: o processamento de tabelas deve depender de um ambiente de ferramentas, e não apenas do "cálculo mental" do modelo de linguagem na janela de chat. Mesmo que o Claude Opus 4.7 suporte uma janela de contexto maior, você deve usar esse espaço para regras de negócio, explicações de campos, exemplos e requisitos de validação, em vez de desperdiçá-lo com as linhas e colunas brutas de uma tabela inteira.
| Característica do Dado | Risco ao colar/enviar diretamente | Entrada recomendada para o Claude Opus 4.7 | Ferramenta de execução recomendada |
|---|---|---|---|
| Muitas colunas | Difícil para o modelo memorizar cada significado | Dicionário de campos, tipos de coluna, descrição de colunas-chave | pandas, SQL |
| Muitas linhas | Custo alto de tokens, resultados não reproduzíveis | Amostras do topo, amostras aleatórias, amostras de exceção | Processamento em blocos com Python |
| Múltiplas Sheets | Relações entre planilhas facilmente perdidas | Resumo da estrutura da pasta de trabalho, uso de cada Sheet | openpyxl, plugin de Excel |
| Dados sujos | Valores atípicos afetam a inferência | Estatísticas de valores ausentes, linhas duplicadas, exemplos de formato | Scripts de qualidade de dados |
| Regras complexas | Explicações em linguagem natural tendem a desviar | Regras claras, contraexemplos, exemplos de saída esperada | Testes unitários, scripts de validação |
Dica técnica: Se você precisa integrar o Claude Opus 4.7 a um sistema de processamento de dados existente, pode realizar uma validação de interface via APIYI (apiyi.com). Recomendo testar o comando, os parâmetros do modelo e o tratamento de erros com uma pequena amostra antes de conectar o fluxo completo de processamento de arquivos.
Equívocos comuns ao processar Excel com o Claude Opus 4.7
O primeiro equívoco é interpretar que "o modelo consegue entender tabelas" como "o modelo deve processar tabelas grandes diretamente". Em arquivos pequenos, análises temporais e perguntas exploratórias, enviar CSV ou Excel é conveniente; mas em tarefas como limpeza em lote, pontuação de listas de clientes, conciliação de pedidos ou classificação financeira, o que você realmente precisa são regras executáveis e reproduzíveis, não respostas únicas em linguagem natural.
O segundo equívoco é fornecer apenas as primeiras 20 linhas como amostra. As primeiras 20 linhas geralmente mostram apenas a estrutura normal e não cobrem situações de exceção. Uma combinação de amostras melhor seria "20 linhas iniciais + 20 linhas aleatórias + 20 linhas de exceção + dicionário de campos + 3 linhas de saída desejada". Assim, o Claude Opus 4.7 conseguirá escrever uma lógica de processamento muito mais próxima da realidade do seu negócio.
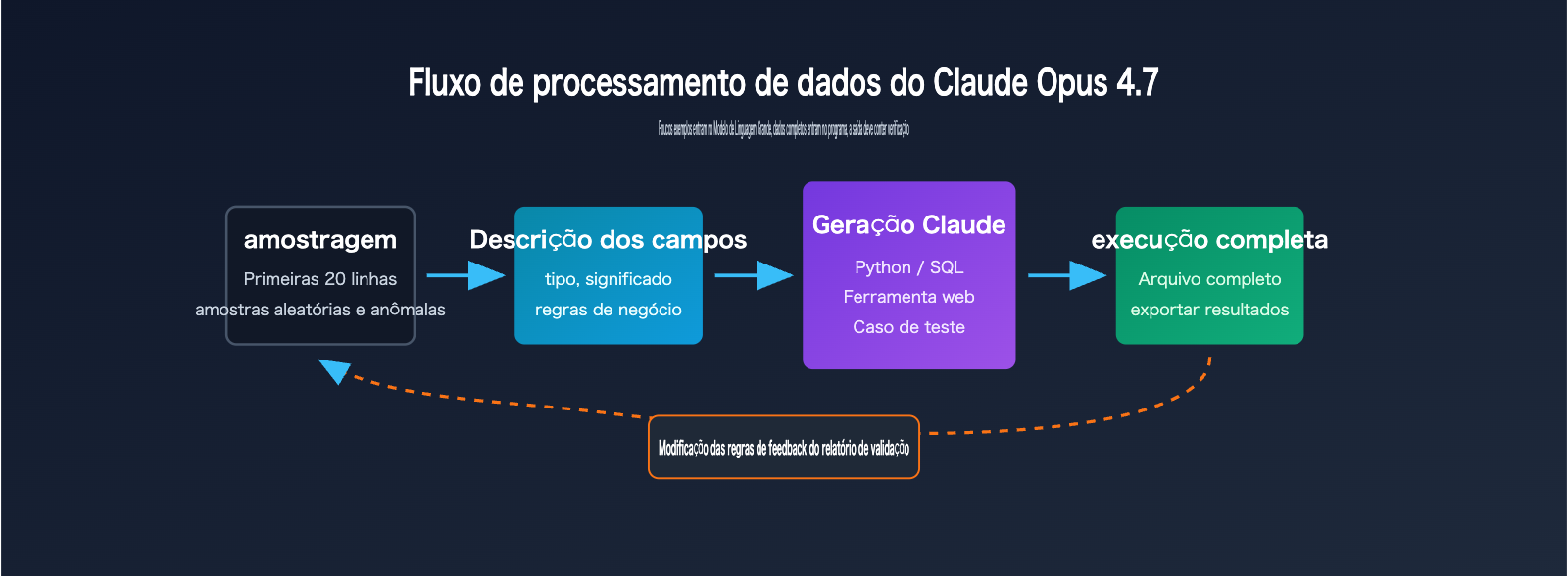
Fluxo de trabalho de 5 etapas para processar CSV com o Claude Opus 4.7
Este fluxo é adequado para a maioria das tarefas de automação de CSV e Excel, especialmente para cenários com mais de 500 linhas, mais de 20 colunas e regras que precisam de ajustes frequentes. Você não precisa entregar o arquivo completo ao modelo desde o início; basta deixar claro as amostras, a estrutura e o objetivo, e então solicitar a criação de scripts, testes e explicações de saída.
| Etapa | Material para o Claude Opus 4.7 | Conteúdo para o Claude gerar | Pontos de confirmação humana |
|---|---|---|---|
| 1. Detecção de estrutura | Formato do arquivo, nomes de campos, linhas de amostra | Suposição de tipos de campo e plano de limpeza | O significado dos campos está correto? |
| 2. Definição de regras | Objetivo de negócio, condições de filtro, contraexemplos | Tabela de regras de processamento e condições de contorno | As exceções de negócio foram cobertas? |
| 3. Geração de script | Amostras de dados, formato de saída desejado | Script de processamento em Python ou SQL | É possível executar localmente? |
| 4. Validação de amostra | Amostras de 20 a 60 linhas | Saída esperada e asserções de teste | A saída faz sentido intuitivamente? |
| 5. Execução completa | Caminho do arquivo completo | Arquivo de resultado, logs, relatório de validação | Totais, valores e agrupamentos estão alinhados? |
O valor central deste fluxo é transformar uma "pergunta única" em um "ativo executável". Quando as regras de negócio mudam, você só precisa pedir ao Claude Opus 4.7 para modificar o script e os testes, sem a necessidade de reenviar os dados completos, reexplicar o contexto ou arriscar se o modelo se lembrará de todos os detalhes.
Modelo de comando para processar CSV com o Claude Opus 4.7
Você pode reutilizar a estrutura de comando abaixo. Lembre-se de não apenas colar o conteúdo do CSV, mas também definir claramente o significado dos campos, objetivos de processamento, amostras de exceção e critérios de aceitação. Quanto mais claro o modelo estiver sobre "o que é considerado correto", mais estável será o script gerado.
Tenho uma tarefa de processamento de dados CSV/Excel, por favor, não forneça apenas a conclusão.
Objetivo:
Pontuar a tabela de clientes por setor, cargo e tamanho da empresa, e gerar os principais leads (top leads).
Amostras de dados:
1. Primeiras 20 linhas: ...
2. 20 linhas aleatórias: ...
3. 20 linhas de exceção: ...
Explicação dos campos:
- company_name: nome da empresa
- title: cargo do contato
- employee_count: número de funcionários, pode estar vazio
- industry: setor, pode conter sinônimos
Por favor, complete:
1. Explique primeiro os campos e possíveis problemas de qualidade dos dados
2. Escreva um script Python para ler input.csv
3. Gere cleaned.csv e scored.csv
4. Adicione validações básicas: contagem de linhas, valores vazios, valores duplicados, distribuição de pontuação
5. Não assuma significados de campos desconhecidos; ao encontrar regras incertas, marque como TODO
Se você deseja transformar esse fluxo em um serviço de API, pode usar o modelo de comando, o dicionário de campos e os dados de amostra como entradas fixas, utilizando a APIYI (apiyi.com) para chamar o Claude Opus 4.7 ou outros modelos disponíveis para testes comparativos. Isso permite avaliar rapidamente as diferenças entre os modelos na geração de código, interpretação de regras e tratamento de exceções.
Exemplo de Python para processar CSV com o Claude Opus 4.7
Abaixo está uma versão minimalista que reflete a abordagem correta: o Claude Opus 4.7 escreve o script, o script lê o arquivo completo e gera resultados e um resumo de validação. Em projetos reais, você pode adicionar logs, tratamento de exceções, testes unitários e arquivos de configuração.
import pandas as pd
INPUT = "input.csv"
OUTPUT = "scored.csv"
df = pd.read_csv(INPUT)
required = ["company_name", "title", "employee_count", "industry"]
missing = [col for col in required if col not in df.columns]
if missing:
raise ValueError(f"Colunas ausentes: {missing}")
df["employee_count"] = pd.to_numeric(df["employee_count"], errors="coerce").fillna(0)
df["score"] = 0
df.loc[df["title"].str.contains("cto|chief|founder", case=False, na=False), "score"] += 40
df.loc[df["employee_count"].between(50, 500), "score"] += 30
df.loc[df["industry"].str.contains("ai|software|saas", case=False, na=False), "score"] += 30
print({"linhas": len(df), "duplicatas": int(df.duplicated().sum())})
df.sort_values("score", ascending=False).to_csv(OUTPUT, index=False)
Se você ainda precisar que o modelo explique os resultados, pode gerar um summary.json com o script e, em seguida, enviar esse resumo para o Claude Opus 4.7. Para tarefas de automação de várias etapas, recomendo usar a APIYI (apiyi.com) para gerenciar centralizadamente as invocações do modelo, novas tentativas em caso de falha e retenção de logs, tornando o fluxo de processamento de dados mais fácil de manter.
Escolha de ferramentas para processar Excel com Claude Opus 4.7
Tarefas diferentes exigem ferramentas diferentes. Para explorações temporárias, você pode usar a capacidade de análise do Claude ou plugins de dados. Já para fluxos de produção, scripts em Python, pipelines SQL ou ferramentas web são mais adequados. Se houver colegas não técnicos na equipe, você pode pedir ao Claude Opus 4.7 para gerar uma ferramenta web local, criando uma interface visual para upload, seleção de regras e download de resultados.
| Solução de Ferramenta | Tarefas Adequadas | Tarefas Inadequadas | Uso Recomendado |
|---|---|---|---|
| Script Python | Limpeza em lote, pontuação, reconciliação, exportação | Equipes que não entendem nada de linha de comando | Peça ao Claude para escrever o script e o README |
| Ferramenta Web Local | Pessoas não técnicas processando arquivos similares repetidamente | Permissões de backend complexas e colaboração multiusuário | Peça ao Claude para gerar HTML/JS ou um serviço leve |
| Pipeline SQL | Data warehouses, pedidos, análise de logs | Tabelas Excel pequenas e temporárias | Peça ao Claude para escrever consultas e SQL de validação |
| Ferramentas de Dados do Claude | Exploração, gráficos, relatórios temporários | Conformidade rigorosa ou tarefas que exigem automação de longo prazo | Explore primeiro, depois consolide em um script |
| Fluxo de trabalho de API | Comparação de modelos, integração de sistemas automatizados | Tarefas manuais únicas | Depure através de uma interface unificada |
Ideia de ferramenta web para processar Excel com Claude Opus 4.7
Quando o usuário não entende Python, "pedir ao Claude para escrever uma ferramenta web" costuma ser mais prático do que "pedir ao Claude para ler um CSV diretamente". Uma ferramenta web pode oferecer botões de upload, mapeamento de campos, configuração de regras, visualização de resultados e botões de download. O usuário só precisa trocar o arquivo, sem a necessidade de dialogar repetidamente com a IA.
Você pode solicitar ao Claude Opus 4.7 o seguinte: gere uma ferramenta HTML de arquivo único que use Papa Parse para ler CSV, realize o mapeamento de campos e a pontuação no frontend e, por fim, exporte um novo CSV. Para tarefas com volumes de dados pequenos, regras não confidenciais e que rodam apenas no navegador local, essa abordagem é muito econômica. Para tarefas que exigem permissões complexas, auditoria e arquivos grandes, deve-se migrar para um serviço de backend.
Dica de implementação: Se você precisar integrar a ferramenta web com interpretação de modelos, sugestões de mapeamento de campos ou diagnóstico de anomalias, você pode utilizar o serviço proxy de API da APIYI (apiyi.com) para invocar a interface do modelo, deixando o frontend responsável apenas pela interação e o backend pelo registro de logs e solicitações ao modelo.
Lista de verificação para processar CSV com Claude Opus 4.7
O maior medo no processamento de dados não é o erro de código, mas o código que gera um resultado incorreto silenciosamente. Portanto, independentemente de você pedir ao Claude Opus 4.7 para escrever Python, SQL ou uma ferramenta web, exija que ele gere simultaneamente uma lista de verificação. Esta lista não precisa ser complexa, mas deve cobrir contagem de linhas, campos, valores nulos, valores duplicados, indicadores-chave e revisão por amostragem.
| Item de Verificação | Por que é importante | Método de verificação recomendado | Sugestão de tratamento de exceção |
|---|---|---|---|
| Contagem de linhas (entrada/saída) | Evita exclusões acidentais ou duplicação | Compare len(input) e len(output) |
Explicação da diferença na saída |
| Campos obrigatórios | Evita erros de cálculo por mudança de nome | Verifique o conjunto de colunas | Erro imediato se faltar campo |
| Proporção de valores nulos | Evita desvios na pontuação ou classificação | Estatística de nulos por coluna | Aviso se exceder o limite |
| Registros duplicados | Evita cobranças ou contatos repetidos | Deduplicação por chave primária ou composta | Relatório de duplicatas mantidas |
| Soma de valores e quantidades | Evita erros de lógica de agregação | Comparação de totais antes e depois do agrupamento | Interromper se houver inconsistência |
| Revisão por amostragem | Identifica desvios na compreensão das regras | Seleção aleatória de 20 linhas para revisão humana | Feedback para o Claude ajustar a regra |
Na prática, você pode incluir esta tabela diretamente como parte do seu comando, fazendo com que o Claude Opus 4.7 adicione automaticamente as verificações correspondentes ao gerar o script. Ao realizarmos testes de invocação do modelo na APIYI (apiyi.com), também sugerimos definir a saída da validação como um requisito fixo de retorno, o que facilita a comparação da estabilidade entre diferentes modelos, em vez de olhar apenas se uma resposta específica parece boa.
Exemplo de comando "anti-padrão" para processar CSV com Claude Opus 4.7
Não diga apenas "ajude-me a limpar esta tabela". Uma abordagem melhor é: "Por favor, indique quais informações de campo você precisa antes de escrever o script; não forneça a conclusão final diretamente; gere logs a cada passo; marque com TODO as regras que não puder determinar; gere 5 exemplos de testes unitários". Esse tipo de restrição força o modelo a tornar explícitas as inferências implícitas e permite que você descubra mais rapidamente se ele entendeu mal o negócio.
Da mesma forma, não trate as primeiras 20 linhas como a verdade absoluta. As primeiras 20 linhas são úteis para o Claude Opus 4.7 entender a estrutura, mas não são suficientes para cobrir dados sujos. Você deve fornecer amostras de exceção adicionais, como valores nulos, duplicatas, formatos de data confusos, valores negativos, inconsistências na grafia de valores enumerados e misturas de chinês com inglês.
FAQ sobre o processamento de CSV com o Claude Opus 4.7
20 linhas de amostra são suficientes para o Claude Opus 4.7 processar um CSV?
Não são suficientes, mas são um bom ponto de partida. As primeiras 20 linhas servem para mostrar a estrutura dos campos e registros normais, mas não cobrem dados anômalos. Recomendo uma combinação de "20 linhas iniciais + 20 linhas aleatórias + 20 linhas com anomalias". Após fornecer as amostras ao Claude Opus 4.7, peça que ele escreva um script para processar o arquivo completo, em vez de tirar conclusões baseadas apenas na amostra.
Devo fazer o upload do arquivo inteiro ao processar Excel com o Claude Opus 4.7?
Para explorações rápidas, você pode fazer o upload e usar as ferramentas de análise. Para fluxos de trabalho que serão reutilizados a longo prazo, peça ao Claude Opus 4.7 que primeiro crie um script de detecção de estrutura e, depois, gere o script de processamento. Em cenários de automação via API, você pode usar o APIYI (apiyi.com) para testar com uma amostra pequena, garantindo que o Modelo de Linguagem Grande compreenda os campos e regras antes de integrar o fluxo completo.
A janela de contexto de 1M do Claude Opus 4.7 elimina a necessidade de scripts para CSV?
Não. Uma janela de contexto maior permite incluir mais descrições de campos, amostras e contexto de negócio, mas não substitui um programa de cálculo reprodutível. Especialmente ao lidar com valores monetários, rankings, agrupamentos, deduplicação e critérios estatísticos, scripts e validações são a base para resultados confiáveis.
Qual a diferença entre o Claude Opus 4.7 e o BI tradicional no processamento de Excel?
O Claude Opus 4.7 é melhor para transformar requisitos ambíguos em regras, código e explicações, enquanto o BI tradicional é mais adequado para relatórios estáveis, permissões, modelagem de dados e colaboração em equipe. Eles não são excludentes: você pode usar o Claude para gerar scripts de limpeza e lógica de análise e, em seguida, integrar os resultados estáveis em um BI ou data warehouse.
Vale a pena usar o Claude Opus 4.7 para processar CSV se eu não tiver conhecimentos de programação?
Vale, mas sugiro pedir que ele gere ferramentas web locais ou instruções detalhadas, em vez de esperar que ele entregue o resultado final diretamente no chat. Você pode solicitar que ele crie a lógica de processamento com botões, formulários e funções de download, ficando responsável apenas pelo upload do arquivo e pela verificação dos resultados. Quando precisar de interfaces de modelo, use o APIYI (apiyi.com) para testar rapidamente a eficácia da geração de código de diferentes modelos.
O que observar ao processar arquivos Excel sensíveis com o Claude Opus 4.7?
Dados sensíveis devem ser anonimizados ou processados em ambientes controlados. Não envie números de documentos, telefones, contratos de clientes ou detalhes financeiros brutos para ambientes incertos. A abordagem mais segura é fornecer amostras anonimizadas e a estrutura dos campos, pedir que o Claude escreva o script e, então, executar o processamento completo dos dados localmente ou em um ambiente corporativo.
Principais conclusões sobre o processamento de CSV com o Claude Opus 4.7
- A melhor forma de usar o Claude Opus 4.7 para processar CSV não é ler a tabela inteira diretamente, mas gerar scripts executáveis com base em amostras e regras.
- Amostras das primeiras 20 linhas ajudam o modelo a entender a estrutura, mas tarefas reais exigem amostras aleatórias, amostras com anomalias e um dicionário de campos.
- O Excel é mais complexo que o CSV; múltiplas abas, fórmulas, colunas ocultas e formatações podem afetar o resultado, por isso, faça uma detecção de estrutura primeiro.
- Para tarefas em lote, Python, SQL e ferramentas web locais são mais reprodutíveis do que respostas únicas em uma janela de chat.
- Uma lista de verificação deve ser gerada junto com o script de processamento, focando na contagem de linhas, campos, valores nulos, duplicatas e totais críticos.
- Para cenários de automação via API, recomenda-se realizar testes com modelos em pequenas amostras antes de integrar a solução estável ao fluxo de produção.
Sugestões para processar Excel com o Claude Opus 4.7
O Claude Opus 4.7 é excelente para tarefas de dados, mas a abordagem correta não é simplesmente "jogar a planilha no colo da IA", e sim "pedir para a IA projetar ferramentas que processem a planilha". Quando o volume de dados chega a centenas de linhas e dezenas de colunas, ou quando as regras de negócio precisam ser reutilizadas várias vezes, scripts, ferramentas web, pipelines SQL e relatórios de validação são opções muito mais econômicas.
Você pode encarar o Claude Opus 4.7 como um assistente de engenharia de dados: peça para ele analisar pequenas amostras, esclarecer regras, escrever scripts de processamento, gerar testes e explicar os resultados. Dessa forma, você mantém a vantagem do Modelo de Linguagem Grande em entender a semântica do negócio, evitando a ineficiência e a falta de auditabilidade que ocorrem ao fornecer dados brutos diretamente.
Se você está desenvolvendo algo relacionado ao Claude Opus 4.7, CSV, Excel ou automação de dados, recomendo usar o APIYI (apiyi.com) para a invocação do modelo e validação de comando antes de consolidar o fluxo estável em scripts ou ferramentas. Isso torna os custos mais controláveis e os resultados mais fáceis de revisar pela equipe e de manter a longo prazo.
Referências:
- Anthropic Claude Opus 4.7: anthropic.com/claude/opus
- Guia de uso do Claude Opus 4.7: claude.com/resources/tutorials/working-with-claude-opus-4-7
- Ferramenta de execução de código do Claude: platform.claude.com/docs/en/agents-and-tools/tool-use/code-execution-tool
- Plugin de dados do Claude: claude.com/plugins/data