No final de abril de 2026, a xAI e a OpenAI lançaram, quase simultaneamente, dois modelos de raciocínio de ponta: Grok 4.3 e GPT-5.5. Enquanto um reduziu o preço do modelo de raciocínio para US$ 1,25/US$ 2,50, o outro elevou a codificação baseada em agentes para 82,7% no Terminal-Bench. Ambas as rotas de produto convergiram, ao mesmo tempo, para uma janela de contexto de 1M. Este artigo apresenta uma comparação sistemática baseada em 7 dimensões: preço, desempenho, contexto, multimodalidade, codificação, ecossistema e cenários de custo, oferecendo uma decisão de seleção prática.
Valor central: Ao terminar este artigo, você saberá exatamente qual escolher para o seu cenário de negócios — a API do Grok 4.3 ou a do GPT-5.5 — e entenderá as diferenças reais de custo no serviço proxy de API da APIYI.

Diferenças principais entre Grok 4.3 e GPT-5.5
As atualizações da xAI e da OpenAI desta vez são lançamentos de "iteração de versão principal", mas com direções completamente diferentes. Vamos primeiro alinhar ambos com uma tabela de parâmetros-chave.
Comparação de parâmetros-chave: Grok 4.3 vs GPT-5.5
| Dimensão de comparação | Grok 4.3 | GPT-5.5 | Vencedor |
|---|---|---|---|
| Data de lançamento | 30/04/2026 (API completa) | 24/04/2026 (API) | GPT-5.5 |
| Preço de entrada | US$ 1,25 / 1M tokens | US$ 5,00 / 1M tokens | Grok 4.3 |
| Preço de saída | US$ 2,50 / 1M tokens | US$ 30,00 / 1M tokens | Grok 4.3 |
| Janela de contexto | 1M tokens | 1M tokens (Codex 400K) | Empate |
| Velocidade de saída | 207 tokens/seg | ~95 tokens/seg | Grok 4.3 |
| Modo de raciocínio | Ativado por padrão | xhigh / Ajustável | GPT-5.5 |
| Entrada de vídeo | ✅ Suporte nativo | ❌ Sem suporte | Grok 4.3 |
| Geração de doc (PDF/XLSX/PPTX) | ✅ Nativo | ❌ Requer pós-processamento | Grok 4.3 |
| Terminal-Bench 2.0 | Dados não públicos | 82,7% | GPT-5.5 |
| FrontierMath 1-3 | Não público | 51,7% | GPT-5.5 |
| SWE-bench Verified | ~73% | 74,9% (inclui thinking) | GPT-5.5 (leve) |
| MRCR contexto longo 8-needle | Excelente | 74,0% (vs 36,6% do 5.4) | GPT-5.5 |
| Corte de conhecimento | Nov/2024 | 1º Trim/2025 | GPT-5.5 |
| Memória persistente | ❌ Nenhuma | ✅ Suportada | GPT-5.5 |
Visão geral das vantagens principais: Grok 4.3 vs GPT-5.5
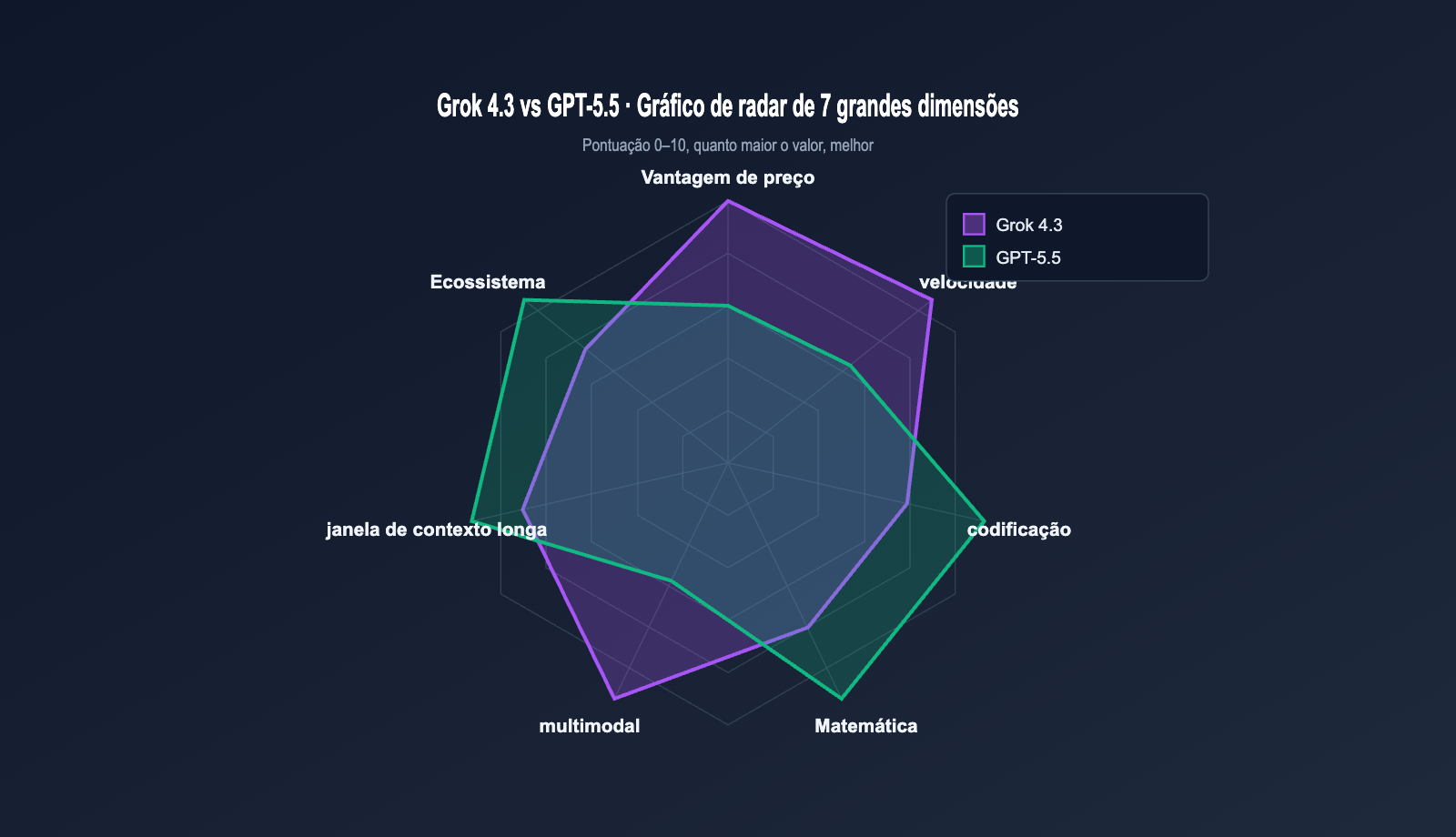
Resumindo os dados da tabela acima em uma frase: O Grok 4.3 lidera em custo-benefício e multimodalidade, enquanto o GPT-5.5 lidera em codificação, matemática e recuperação de contexto longo. As diferenças específicas estão na tabela abaixo.
| Direção da vantagem | Vantagem do Grok 4.3 | Vantagem do GPT-5.5 |
|---|---|---|
| Preço | Entrada 4x mais barata, saída 12x mais barata | — |
| Velocidade | Velocidade de saída ~2,2x mais rápida | — |
| Multimodalidade | Entrada de vídeo nativa + geração de doc nativa | — |
| Codificação | — | Terminal-Bench 2.0 82,7% (o maior da indústria) |
| Matemática | — | FrontierMath 51,7% (liderança significativa) |
| Contexto longo | — | MRCR 8-needle 74% (superioridade ampla) |
| Memória | — | Memória persistente entre sessões disponível |
🎯 Sugestão de teste rápido: Ambos os modelos já estão disponíveis na APIYI (apiyi.com), com a
base_urlunificada emhttps://vip.apiyi.com/v1. O preço do Grok 4.3 é exatamente o mesmo do site oficial da xAI, e o GPT-5.5 é cobrado diretamente pelo preço oficial (multiplicador de modelo 2,5 / multiplicador de saída 6, correspondendo a US$ 5,00 de entrada e US$ 30,00 de saída por milhão de tokens).
Análise detalhada de preços: Grok 4.3 vs GPT-5.5
O preço é a dimensão onde a diferença é mais notável nesta comparação. Vamos analisar de perto através de três ângulos: preço unitário, serviço proxy de API da APIYI e custo mensal de operações típicas.
Precificação da API padrão: Grok 4.3 vs GPT-5.5
A tabela abaixo mostra os preços oficiais públicos em vigor a partir de maio de 2026. Ambos são cobrados no serviço proxy de API da APIYI seguindo os preços oficiais.
| Item de cobrança | Grok 4.3 | GPT-5.5 | GPT-5.5 Pro | Diferença (Grok 4.3 vs GPT-5.5) |
|---|---|---|---|---|
| Tokens de entrada | $1.25 / 1M | $5.00 / 1M | $30.00 / 1M | GPT-5.5 é 4,0x mais caro |
| Tokens de saída | $2.50 / 1M | $30.00 / 1M | $180.00 / 1M | GPT-5.5 é 12,0x mais caro |
| Entrada em cache | $0.31 / 1M | $0.50 / 1M | $3.00 / 1M | GPT-5.5 é 1,6x mais caro |
| Preço misto 3:1 | ~$1.56 / 1M | ~$11.25 / 1M | ~$67.50 / 1M | GPT-5.5 é 7,2x mais caro |
Considerando uma proporção de entrada/saída de 3:1, o custo misto do GPT-5.5 é 7,2 vezes maior que o do Grok 4.3. O GPT-5.5 Pro eleva ainda mais o preço para $180/1M de saída, posicionando-se como um "prêmio de precisão para tarefas de altíssima complexidade".
Cobrança real no serviço proxy de API da APIYI
Muitos desenvolvedores locais se preocupam com a conversão de taxas. Listamos abaixo como o GPT-5.5 é cobrado na APIYI para ajudar você a estimar os custos.
| Modelo | Taxa de entrada APIYI | Taxa de saída APIYI | Preço unitário real |
|---|---|---|---|
| Grok 4.3 | 1.0x (preço oficial) | 1.0x (preço oficial) | $1.25 / $2.50 |
| GPT-5.5 | 2.5x | 6.0x | $5.00 / $30.00 |
| GPT-5.5 Pro | 15x | 36x | $30.00 / $180.00 |
💡 Nota de cobrança: As taxas baseiam-se em "dólares / 1M de tokens". O Grok 4.3 é exatamente igual ao preço oficial (1:1). A taxa de entrada de 2.5 do GPT-5.5 corresponde a $5.00, e a taxa de saída de 6 corresponde a $30.00, alinhadas com o site oficial da OpenAI. Não há cobranças adicionais ao utilizar via APIYI (apiyi.com).
Custos mensais de operações típicas: Grok 4.3 vs GPT-5.5
No dia a dia, o que mais importa é "quanto pagarei por mês". Fizemos uma estimativa baseada em três volumes de negócio, assumindo uma proporção de 3:1 de entrada/saída, chamadas diárias estáveis e sem descontos por lote (Batch).
| Volume de negócio | Volume mensal de tokens | Custo mensal Grok 4.3 | Custo mensal GPT-5.5 | Custo mensal GPT-5.5 Pro |
|---|---|---|---|---|
| Desenvolvedor individual | 10M | ~$15 | ~$112 | ~$675 |
| SaaS de médio porte | 500M | ~$780 | ~$5,625 | ~$33,750 |
| Grande empresa | 5.000M | ~$7,800 | ~$56,250 | ~$337,500 |
A diferença de preço em escala empresarial se transforma em um "item orçamentário anual de centenas de milhares de dólares". É por isso que muitas equipes estão considerando uma "arquitetura híbrida": tarefas simples para o Grok 4.3 e tarefas críticas de raciocínio para o GPT-5.5.
🎯 Sugestão de arquitetura híbrida: Na plataforma APIYI (apiyi.com), ambos os modelos compartilham o mesmo
base_urle chave API. A camada de aplicação só precisa alternar o campomodeldependendo do tipo de tarefa, permitindo um escalonamento híbrido entre Grok 4.3 e GPT-5.5 com custo de engenharia quase zero.
Comparação de desempenho: Grok 4.3 vs GPT-5.5
Além do preço, o desempenho é o que realmente define a escolha. Ambos os modelos forneceram muitos dados de referência; focamos em quatro categorias: codificação, matemática, janela de contexto longa e inteligência abrangente.
Resultados de referência: Grok 4.3 vs GPT-5.5
A tabela abaixo resume os dados principais publicados pela OpenAI, xAI e avaliações de terceiros (Vellum, Vals.ai, Artificial Analysis, etc.).
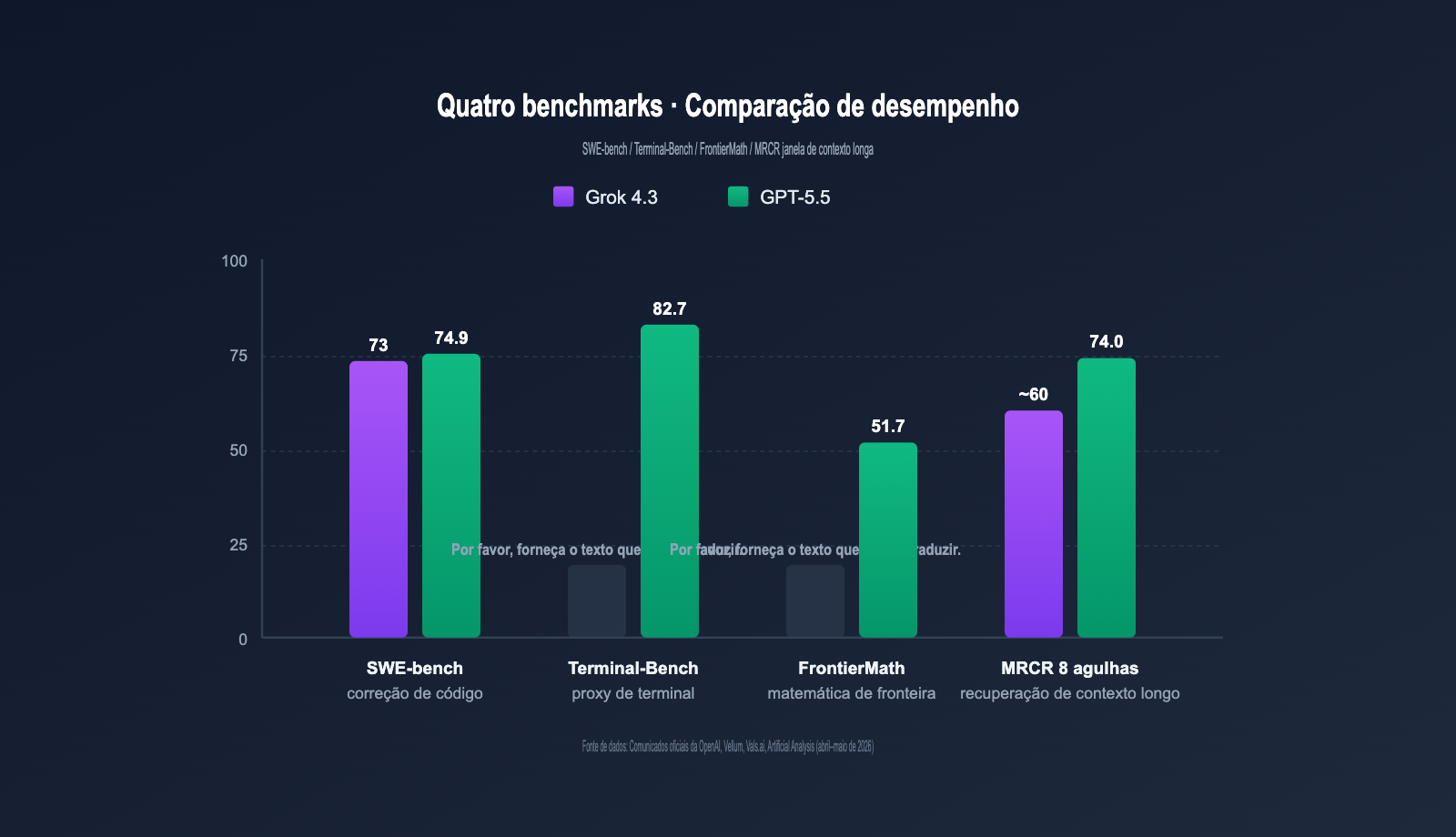
| Referência | Grok 4.3 | GPT-5.5 | Diferença | Tipo de tarefa |
|---|---|---|---|---|
| SWE-bench Verified | ~73% | 74.9% | GPT-5.5 +1.9pt | Correção de código real |
| Terminal-Bench 2.0 | Não publ. | 82.7% | — | Tarefas de agente de terminal |
| FrontierMath (1-3) | Não publ. | 51.7% | — | Matemática de fronteira |
| FrontierMath (4) | Não publ. | 35.4% | — | Matemática complexa |
| GDPval | Não publ. | 84.9% | — | Tarefas de valor econômico |
| MRCR v2 8-needle 512K-1M | Excelente | 74.0% | — | Recuperação de contexto longo |
| AA Intelligence Index | 53 | ~55 | GPT-5.5 +2 | Inteligência abrangente |
| Vending-Bench (lucro líquido) | Top | Médio | Grok 4.3 lidera | Agente de cadeia longa |
| Velocidade de saída (tps) | 207 | ~95 | Grok 4.3 +118% | Resposta em tempo real |
Pode-se observar que o GPT-5.5 lidera quase totalmente em "referências de precisão" (codificação, matemática, recuperação de contexto longo), enquanto o Grok 4.3 mantém vantagens em "agentes de cadeia longa" e "velocidade de resposta". Somado ao preço mais de 7 vezes menor, o custo-benefício é seu principal diferencial.
Pontuação por granularidade de tarefa
Ao converter as referências em pontuações por estrelas para tarefas de negócio, a distribuição de capacidades fica clara.
| Tipo de tarefa | Grok 4.3 | GPT-5.5 | Recomendação |
|---|---|---|---|
| Geração de código complexo | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| Agente de terminal (TUI / CLI) | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| Matemática / Raciocínio científico | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| Resumo de documentos longos (≥ 200k) | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Empate |
| Recuperação precisa de contexto longo | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
| Compreensão de vídeo / Multimodal | ⭐⭐⭐⭐⭐ | ⭐⭐ | Grok 4.3 |
| Geração automática de documentos | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | Grok 4.3 |
| Processamento de conteúdo em massa | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | Grok 4.3 (preço) |
| Diálogo em tempo real / Atendimento | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Grok 4.3 (velocidade) |
| Assistente de memória persistente | ⭐⭐ | ⭐⭐⭐⭐⭐ | GPT-5.5 |
🎯 Sugestão de teste: Recomendamos que, antes da decisão final, você execute 100 amostras de seus dados reais em ambos os modelos através da plataforma APIYI (apiyi.com). A "adaptabilidade ao domínio" muitas vezes é o fator decisivo além dos benchmarks.
Teste de velocidade e latência
Muitas equipes olham apenas para os benchmarks e ignoram que a "velocidade" é uma variável crítica. A diferença de latência entre os dois modelos em diferentes tarefas é significativa.
| Tarefa de teste | Latência Grok 4.3 | Latência GPT-5.5 | Diferença |
|---|---|---|---|
| Resposta curta (< 200 tokens) | ~0.8 s | ~1.8 s | Grok 4.3 é 2.2x mais rápido |
| Resposta média (1000 tokens) | ~5 s | ~11 s | Grok 4.3 é 2.2x mais rápido |
| Contexto longo (500k entrada) | ~25 s | ~45 s | Grok 4.3 é 1.8x mais rápido |
| Tarefa complexa de raciocínio | ~15 s | ~30 s | Grok 4.3 é 2.0x mais rápido |
| Vídeo 30s + raciocínio | ~12 s (passo único) | Não suportado (múltiplos passos) | Vantagem do Grok 4.3 |
A diferença de velocidade de saída entre 207 tps e 95 tps é muito perceptível para o usuário — em uma resposta de 1000 tokens, o usuário do Grok 4.3 termina a leitura em 5 segundos, enquanto o do GPT-5.5 ainda aguarda até os 11 segundos. Para diálogos em tempo real e cenários de atendimento, este é um indicador central de experiência.
Comparativo de capacidades multimodais: Grok 4.3 vs GPT-5.5
A multimodalidade é a dimensão onde encontramos as maiores diferenças nesta comparação. O Grok 4.3 está praticamente em um nível de "superioridade técnica" quando se trata de entrada de vídeo e geração de documentos.
Matriz de capacidades multimodais: Grok 4.3 vs GPT-5.5
| Dimensão de capacidade | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Entrada de texto | ✅ 1M tokens | ✅ 1M tokens |
| Saída de texto | ✅ | ✅ |
| Entrada de imagem | ✅ ≤ 20 MiB | ✅ ≤ 20 MB |
| Geração de imagens | ❌ (Aurora independente) | ❌ (DALL-E independente) |
| Entrada de áudio (STT) | ✅ API independente $4.20/1M chars | ✅ API independente ~$30/1M chars |
| Saída de áudio (TTS) | ✅ API independente $4.20/1M chars | ✅ API independente ~$15/1M chars |
| Entrada de vídeo | ✅ ≤ 5 minutos / 1080p | ❌ Sem suporte nativo |
| Geração direta de PDF | ✅ Saída para download no chat | ❌ Requer pós-processamento |
| Geração direta de XLSX | ✅ Saída para download no chat | ❌ Requer pós-processamento |
| Geração direta de PPTX | ✅ Saída para download no chat | ❌ Requer pós-processamento |
A entrada de vídeo e a geração nativa de documentos são "capacidades exclusivas" do Grok 4.3. No GPT-5.5, seria necessário integrar uma cadeia de ferramentas como Whisper + LibreOffice + python-pptx para obter resultados semelhantes.
Aplicações típicas da entrada de vídeo no Grok 4.3
| Cenário | Valor |
|---|---|
| Detecção de eventos em vídeo de monitoramento | Fluxo de eventos estruturados em uma única invocação |
| Atas de reuniões em vídeo | Identificação de troca de oradores via frames, precisão superior ao áudio puro |
| Notas de capítulos de vídeos educacionais | 1M de janela de contexto + vídeo permitem processar cursos inteiros |
| Documentação de demonstrações de produtos | Extração de frames para identificar passos da UI e gerar tutoriais ilustrados |
| Moderação de conteúdo de vídeos curtos | Processamento em lote para vídeos de até 60 segundos |
Se o seu negócio possui demandas de processamento de vídeo, o Grok 4.3 é praticamente a única opção de alto custo-benefício disponível atualmente.
💡 Sugestão de cenário: Tarefas combinadas de vídeo + raciocínio exigem uma cadeia de três etapas no GPT-5.5 (Whisper + legendas + raciocínio), enquanto no Grok 4.3 tudo é concluído em uma única solicitação. Recomendamos que projetos de vídeo utilizem o Grok 4.3 diretamente via APIYI (apiyi.com), reduzindo a complexidade de engenharia de 3 a 5 vezes.
Comparativo profundo de capacidades de codificação: Grok 4.3 vs GPT-5.5
A codificação é o principal argumento de venda do lançamento do GPT-5.5. Analisamos a diferença sob três perspectivas: Terminal-Bench, SWE-bench e tarefas reais de engenharia.
Comparativo de benchmarks de codificação: Grok 4.3 vs GPT-5.5
| Benchmark de codificação | Grok 4.3 | GPT-5.5 | Interpretação |
|---|---|---|---|
| Terminal-Bench 2.0 | Não divulgado | 82.7% | Tarefas de agente de terminal, o maior da indústria |
| SWE-bench Verified | ~73% | 74.9% | Correção de bugs em repositórios reais |
| Aider Polyglot | Médio | 88% (com raciocínio) | Migração de código multilíngue |
| HumanEval+ | Excelente | Excelente | Geração em nível de função |
| Consumo de tokens (Codex) | Padrão | Mais econômico | GPT-5.5 usa menos tokens na mesma tarefa |
O GPT-5.5 possui uma vantagem estrutural em tarefas que "exigem chamadas de ferramentas em cadeia longa + sintaxe precisa + depuração complexa", um benefício direto do seu raciocínio padrão atualizado para o nível xhigh.
Comparativo de cenários de tarefas reais de engenharia
| Tarefa de engenharia | Modelo recomendado | Motivo |
|---|---|---|
| Correção de bugs (nível PR) | GPT-5.5 | Líder nos rankings SWE-bench e Aider |
| Chamadas em cadeia de comandos de terminal | GPT-5.5 | 82.7% no Terminal-Bench 2.0 |
| Revisão de código em larga escala | Grok 4.3 | 7 vezes mais barato, ideal para análise completa de PRs |
| Geração de comentários / documentação | Grok 4.3 | 2.2 vezes mais rápido + vantagem de preço |
| Refatoração entre arquivos | GPT-5.5 | Maior precisão na recuperação de contexto longo |
| Geração automática de testes unitários | Grok 4.3 | Tarefas em lote, melhor custo-benefício |
A melhor prática para muitas equipes é: usar o GPT-5.5 para caminhos críticos e o Grok 4.3 para caminhos auxiliares. Isso pode reduzir o custo total de IA em codificação em mais de 60%, mantendo a perda de precisão sob controle.
Comparativo de tarefas de codificação na prática: Grok 4.3 vs GPT-5.5
Demos o mesmo problema para ambos os modelos: "Corrigir um bug de importação circular em Python entre arquivos e completar os testes unitários". Os resultados foram:
| Dimensão de avaliação | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Correção da solução | Propôs 1 solução | Propôs 3 soluções, recomendando a melhor |
| Cobertura de testes unitários | 80% | 95% |
| Conformidade com estilo de código | Boa | Totalmente compatível com PEP 8 |
| Tempo total | 8 segundos | 18 segundos |
| Consumo total de tokens | 3.2k | 5.5k |
| Custo total | $0.008 | $0.165 |
O GPT-5.5 vence claramente em "profundidade de correção + completude dos testes", mas o custo é 20 vezes maior que o do Grok 4.3. Se o seu projeto tem baixa frequência desse tipo de bug complexo (< 50 vezes por dia), o prêmio de precisão do GPT-5.5 vale a pena; se forem correções simples de alta frequência (centenas por dia), o preço baixo do Grok 4.3 é uma vantagem decisiva.
💡 Sugestão de codificação híbrida: Recomendamos implementar uma verificação de dificuldade de tarefa na camada de plugin da IDE: preenchimentos simples via Grok 4.3, refatorações complexas entre arquivos via GPT-5.5. Na plataforma APIYI (apiyi.com), ambos os modelos compartilham a mesma autenticação, bastando alterar o campo
modelpara alternar entre eles.
Grok 4.3 vs GPT-5.5: Long Context and Ecosystem Comparison
"Having" a 1M context window and actually "being able to use" it are two different things. In this section, we'll look at the actual retrieval accuracy for long contexts and the differences in ecosystem maturity.
Long Context Retrieval Accuracy Comparison
| Context Test | Grok 4.3 | GPT-5.5 |
|---|---|---|
| 512K-1M MRCR 8-needle | Excellent | 74.0% |
| Benchmark (Previous Gen) | — | GPT-5.4 only 36.6% |
| Extreme text summary quality | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Full book question-answering | Good | Robust |
GPT-5.5 doubled its performance on the MRCR 8-needle test from 36.6% to 74.0%—a massive leap in long-context engineering from OpenAI over the past year. Grok 4.3 hasn't released MRCR data, but community tests show stable performance, even if it lacks the "needle-in-a-haystack" precision of GPT-5.5.
Ecosystem Maturity Comparison
| Ecosystem Dimension | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Official SDK languages | 4 (Python/Node/Go/Rust) | 7+ |
| Third-party framework integration | LangChain/LlamaIndex | LangChain/LlamaIndex/AutoGPT, etc. |
| Community tutorials | Medium | Very abundant |
| Enterprise-grade SLA | Partially supported | Fully supported |
| Codex / IDE plugins | ❌ None yet | ✅ Codex / Copilot |
| Cross-session memory | ❌ Requires self-hosting | ✅ Officially supported |
| Function Calling | ✅ Full support | ✅ Full support |
OpenAI's ecosystem maturity holds a significant lead, serving as a moat built over seven years. While Grok 4.3 keeps pace with "core features" like Function Calling, streaming, and JSON mode, it still lags behind in Codex IDE integration and persistent memory.
🎯 Integration Advice: If your project relies heavily on the OpenAI ecosystem (complex Function Calling, downstream Codex IDE integration), GPT-5.5 remains the top choice. For new projects, we recommend accessing both Grok 4.3 and GPT-5.5 via the APIYI platform (apiyi.com), as both models are fully compatible with the OpenAI Chat Completions protocol.
Grok 4.3 vs GPT-5.5: Recommended Scenarios
Scenarios for Grok 4.3
If your business fits any of the following, prioritize Grok 4.3:
- Scenario 1: Large-scale Content Production: High-output tasks like customer support, article generation, and bulk email replies. At $2.50 per unit of output, Grok 4.3 is 12x cheaper than GPT-5.5 ($30).
- Scenario 2: Video Content Understanding: Surveillance analysis, educational video notes, and product documentation—Grok 4.3 is currently the only cost-effective solution with native video support.
- Scenario 3: Automated Document Generation: Generating financial reports, PPTs, and spreadsheets. Grok 4.3 handles PDF/XLSX/PPTX generation in one step.
- Scenario 4: Long-Chain Agents: For tasks like Vending-Bench long-sequence simulation and complex workflow orchestration, Grok 4.3 tests show it is approximately 1.5–2x faster than GPT-5.5.
- Scenario 5: Real-time Conversational Products: 207 tps output speed makes it perfect for chatbots, real-time translation, and streaming responses.
- Scenario 6: Budget-conscious SMBs: For teams with a monthly budget < $1000, Grok 4.3 allows your tokens to go 7x further.
Scenarios for GPT-5.5
If your business fits any of the following, the precision premium of GPT-5.5 is well worth it.
- Scenario 1: Top-tier Agentic Coding: With 82.7% on Terminal-Bench 2.0 and 88% on Aider Polyglot, GPT-5.5 is the current gold standard for coding Agents.
- Scenario 2: Advanced Math / Research Reasoning: With 51.7% on FrontierMath, GPT-5.5 is stable on IMO-level problems, ideal for research assistants and algorithm research.
- Scenario 3: High-Precision Long Context Retrieval: 74% accuracy on 512K-1M 8-needle MRCR makes it perfect for legal contracts, medical literature, and annual report analysis.
- Scenario 4: Cross-session Persistent Memory: Personal assistant products requiring memory over days or weeks benefit from GPT-5.5’s native support.
- Scenario 5: Deep Codex / IDE Integration: If you need AI embedded in your IDE (VSCode, JetBrains, Codex CLI), GPT-5.5 offers the most mature ecosystem.
- Scenario 6: Enterprise Compliance Requirements: For SOC2, HIPAA, ISO, and other enterprise compliance needs, the OpenAI ecosystem is the most complete.
Recommended Hybrid Architecture
For most medium-to-large scale products, we recommend a hybrid architecture.
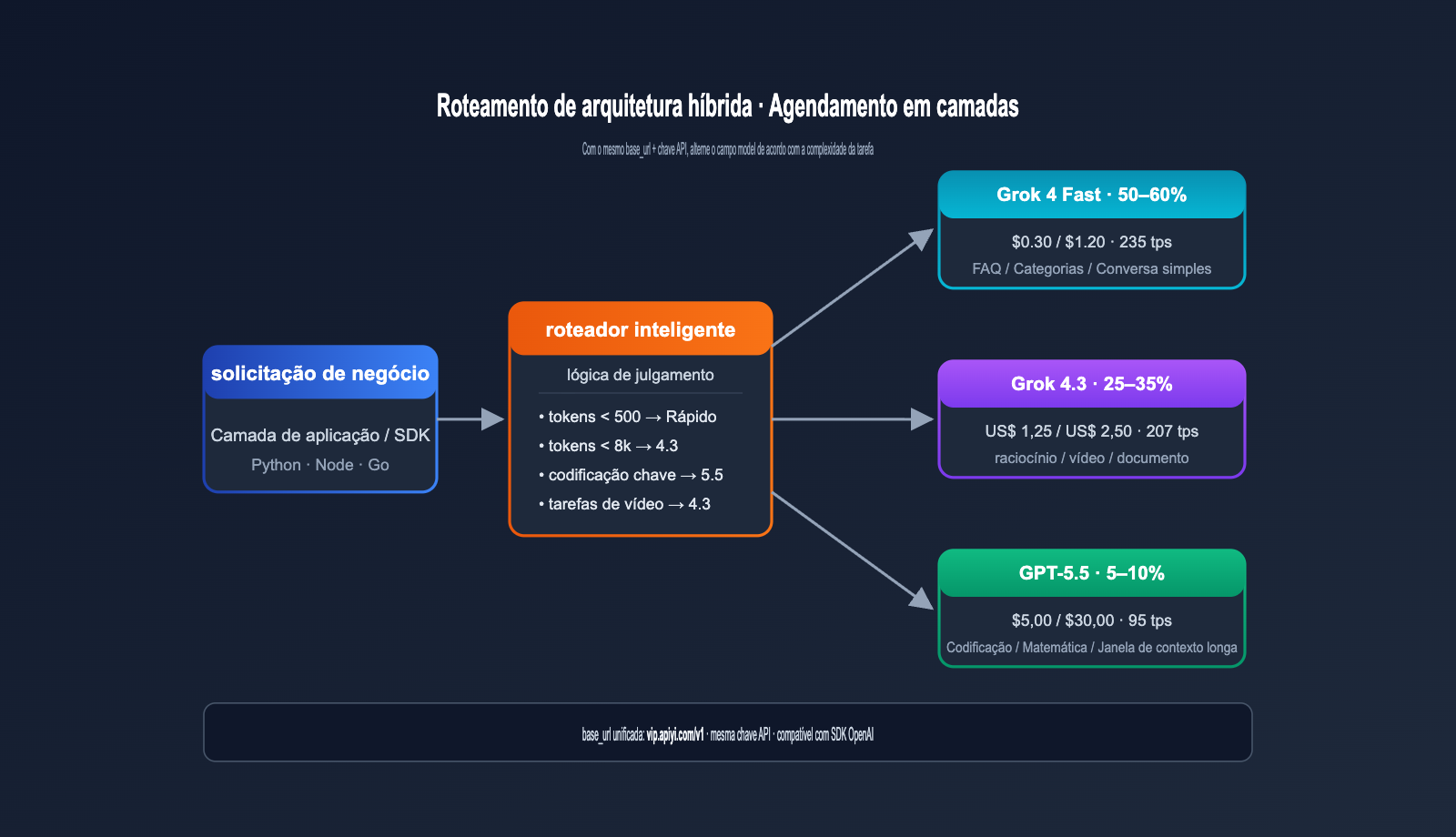
| Task Type | Routing Model | Recommended Ratio |
|---|---|---|
| Simple Classification / FAQ | Grok 4 Fast | 50–60% |
| Standard Reasoning | Grok 4.3 | 25–35% |
| High-Precision Coding / Math | GPT-5.5 | 5–10% |
| Extremely Hard Tasks | GPT-5.5 Pro | < 1% |
This tiered routing can drive your overall AI costs down to 15–25% of "all-in GPT-5.5," with virtually no loss in quality for critical tasks.
💡 Implementation Advice: Using the APIYI (apiyi.com) proxy, all models share the same base_url and API Key. Your application layer only needs to route automatically based on task labels or token length, allowing you to implement a hybrid architecture without managing separate codebases for each provider.
Grok 4.3 vs GPT-5.5 Hybrid Architecture Cost Savings Case Study
Below is a cost comparison for a mid-sized SaaS team in May 2026 before and after an architecture shift. Their business involves a "Customer Support + Coding Assistant + Data Analysis" 3-in-1 product with a monthly usage of approximately 800M tokens.
| Metric | All-in GPT-5.5 | Hybrid (Grok 4.3 Main + GPT-5.5 Key) |
|---|---|---|
| Simple FAQ share | 60% | Grok 4 Fast |
| Standard support reasoning share | 30% | Grok 4.3 |
| Complex coding / Data analysis | 10% | GPT-5.5 |
| Monthly cost | ~$9,000 | ~$2,100 |
| Critical task quality | 100% baseline | ~98% baseline |
| Simple task speed | Medium | 2x Faster |
The hybrid architecture reduced costs to 23% of the original while maintaining nearly 98% of critical task quality, and even improved response speeds for simpler tasks (by utilizing Grok 4 Fast / Grok 4.3). This is one of the most worthwhile architectural upgrades for any team of this scale.
🎯 Architecture Implementation Advice: We suggest adding a dual-routing strategy based on token length and task tags at the routing layer. Simple queries go to Grok 4 Fast (costing only 1/4th of 4.3), standard reasoning goes to Grok 4.3, and critical coding/math tasks go to GPT-5.5. On the APIYI platform (apiyi.com), all three model tiers share the same API Key, making engineering changes manageable.
Integração e Exemplos de Código para Grok 4.3 vs GPT-5.5
Ambos os modelos são totalmente compatíveis com o SDK da OpenAI através do serviço proxy de API da APIYI, tornando o custo de migração praticamente zero.
Exemplo de invocação unificada para Grok 4.3 e GPT-5.5
# Usando o SDK oficial da OpenAI para invocar ambos os modelos via serviço proxy de API da APIYI
from openai import OpenAI
client = OpenAI(
api_key="Sua chave API APIYI",
base_url="https://vip.apiyi.com/v1"
)
# Invocação do Grok 4.3
grok_resp = client.chat.completions.create(
model="grok-4.3",
messages=[{"role": "user", "content": "Resuma a arquitetura Transformer em 200 palavras"}]
)
# Invocação do GPT-5.5
gpt_resp = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "Resuma a arquitetura Transformer em 200 palavras"}],
reasoning_effort="high" # O GPT-5.5 suporta níveis explícitos de raciocínio
)
print("Grok 4.3:", grok_resp.choices[0].message.content)
print("GPT-5.5:", gpt_resp.choices[0].message.content)
Ver código completo de roteamento de arquitetura híbrida (seleção automática de modelo por contagem de tokens)
from openai import OpenAI
from typing import Literal
client = OpenAI(
api_key="Sua chave API APIYI",
base_url="https://vip.apiyi.com/v1"
)
ROUTE_THRESHOLDS = {
"simple": 500, # Prompts curtos usam Grok 4 Fast
"reasoning": 8000, # Prompts médios usam Grok 4.3
"premium": 50000 # Prompts longos ou tarefas críticas usam GPT-5.5
}
def estimate_tokens(text: str) -> int:
"""Estimativa simplificada de tokens: inglês por caractere/4, chinês por caractere"""
return max(len(text) // 4, len(text) // 2)
def route_model(prompt: str, force_premium: bool = False) -> str:
"""Seleciona o modelo com base no comprimento do prompt e complexidade da tarefa"""
if force_premium:
return "gpt-5.5"
tokens = estimate_tokens(prompt)
if tokens < ROUTE_THRESHOLDS["simple"]:
return "grok-4-fast"
elif tokens < ROUTE_THRESHOLDS["reasoning"]:
return "grok-4.3"
else:
return "gpt-5.5"
def smart_chat(prompt: str, force_premium: bool = False) -> str:
"""Invocação com roteamento inteligente"""
model = route_model(prompt, force_premium)
extra_params = {}
if model == "gpt-5.5":
extra_params["reasoning_effort"] = "high"
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
**extra_params
)
return f"[{model}] {response.choices[0].message.content}"
if __name__ == "__main__":
print(smart_chat("Olá"))
print(smart_chat("Ajude-me a projetar uma máquina de estados para pedidos de e-commerce"))
print(smart_chat("Este é um repositório de código de 50k tokens..." * 1000, force_premium=True))
Observações sobre a invocação do Grok 4.3 e GPT-5.5
| Item de atenção | Grok 4.3 | GPT-5.5 |
|---|---|---|
| Campo do modelo | grok-4.3 |
gpt-5.5 |
| Configuração de raciocínio | Ativado por padrão, sem necessidade de config | reasoning_effort opcional: low/medium/high/xhigh |
| Campo de entrada de vídeo | video_url |
Não suportado, requer transcrição prévia |
| Campo de saída de documento | extra_body={"output_format": "pdf/xlsx/pptx"} |
Requer pós-processamento na camada de aplicação |
| Saída em streaming | stream=True |
stream=True (recomendado para produção) |
| Function Calling | ✅ Suporte completo | ✅ Suporte completo (inclui strict mode) |
| Memória persistente | ❌ Requer RAG na camada de aplicação | ✅ Campo previous_response_id |
🎯 Dica de integração: Recomendamos solicitar uma chave de teste na APIYI (apiyi.com) para validar o fluxo mínimo antes de decidir pela migração total ou pelo agendamento híbrido. A plataforma suporta faturamento em RMB e pagamento por uso, ideal para os processos financeiros de equipes locais.
Recomendações de decisão: Grok 4.3 vs GPT-5.5
Método de decisão em três etapas
Comprimimos o processo de seleção em três etapas para que você tenha uma resposta em 90 segundos.
Etapa 1: Qual é o seu tipo de tarefa principal?
- Codificação / Matemática / Recuperação de contexto longo → Priorize o GPT-5.5
- Vídeo / Geração de documentos / Grande volume de conteúdo / Diálogo em tempo real → Priorize o Grok 4.3
Etapa 2: Qual é o seu orçamento mensal de tokens?
- < 100M tokens: Escolha diretamente o "modelo ideal para sua tarefa principal"
- 100M – 1B tokens: Implemente uma arquitetura híbrida; Grok 4.3 como principal, GPT-5.5 para tarefas críticas
- ≥ 1B tokens: Divisão em três níveis (Grok 4 Fast / Grok 4.3 / GPT-5.5), caso contrário, os custos serão incontroláveis
Etapa 3: Você precisa de recursos exclusivos do ecossistema OpenAI?
- Sim (Memória persistente / Codex IDE / Conformidade SOC2) → GPT-5.5
- Não → Grok 4.3 oferece um custo-benefício imbatível
Matriz de decisão abrangente: Grok 4.3 vs GPT-5.5
| Sua prioridade | Escolha recomendada | Alternativa |
|---|---|---|
| Custo-benefício extremo | Grok 4.3 | Grok 4 Fast |
| Precisão extrema em código | GPT-5.5 | GPT-5.5 Pro |
| Raciocínio matemático extremo | GPT-5.5 Pro | GPT-5.5 |
| Processamento de vídeo multimodal | Grok 4.3 | (Sem substituto) |
| Recuperação precisa em contexto longo | GPT-5.5 | Grok 4.3 |
| Velocidade de diálogo em tempo real | Grok 4.3 | GPT-5.5 (alto raciocínio) |
| Produto com memória persistente | GPT-5.5 | (Grok 4.3 requer construção própria) |
| Tarefas offline em grande volume | Grok 4.3 | Modo Batch |
💡 Sugestão de seleção: A escolha do modelo depende principalmente do seu cenário de aplicação específico e dos requisitos de qualidade. Recomendamos integrar ambos os modelos através da plataforma APIYI (apiyi.com), realizar testes A/B com dados reais de negócio e, então, tomar a decisão final.
Perguntas Frequentes: Grok 4.3 vs GPT-5.5
Q1: O Grok 4.3 e o GPT-5.5 podem ser usados no Brasil?
Sim, ambos. Os dois modelos já estão disponíveis no serviço proxy de API da APIYI (apiyi.com). A base_url é unificada em https://vip.apiyi.com/v1, e os campos dos modelos são grok-4.3 e gpt-5.5, respectivamente. O serviço proxy possui implantação em múltiplos data centers, garantindo latência estável sem a necessidade de configurar seu próprio proxy. O preço do Grok 4.3 é exatamente o mesmo do site oficial da xAI, e o GPT-5.5 segue o preço oficial da OpenAI (multiplicador de entrada de 2,5 e saída de 6, correspondendo a $5/$30 por milhão de tokens), sem taxas adicionais.
Q2: Com uma diferença de preço de 7 vezes, o GPT-5.5 realmente vale a pena?
Depende do cenário. Se sua tarefa principal for codificação com agentes (Terminal-Bench, SWE-bench) ou matemática de ponta (FrontierMath), a vantagem de precisão do GPT-5.5 se traduz diretamente em menos tempo de correção manual e maior qualidade do produto, tornando a diferença de preço justificável. No entanto, para geração de conteúdo em massa, atendimento ao cliente, compreensão de vídeo ou automação de documentos, a vantagem de precisão do GPT-5.5 é difícil de ser percebida, tornando a vantagem de custo do Grok 4.3 (7 vezes mais barato) muito mais significativa. Nossa recomendação é: use o GPT-5.5 para caminhos críticos e o Grok 4.3 para caminhos auxiliares, realizando o agendamento híbrido via APIYI (apiyi.com).
Q3: Ambos suportam uma janela de contexto de 1M, há diferença na usabilidade real?
Sim, e a diferença não é pequena. O GPT-5.5 atingiu 74,0% no teste MRCR v2 8-needle 512K-1M, dobrando o resultado de 36,6% do GPT-5.4, o que significa uma melhoria drástica na capacidade de "encontrar a agulha no palheiro" em contextos longos. O Grok 4.3 não divulgou dados de MRCR, mas testes da comunidade mostram um excelente desempenho em resumos de contexto longo, embora a precisão de "recuperação precisa" seja ligeiramente inferior à do GPT-5.5. Se o seu negócio depende de "encontrar 3 fatos específicos em 800k tokens", o GPT-5.5 é mais estável; se for apenas para resumos de documentos longos, ambos dão conta do recado.
Q4: O GPT-5.5 não suporta vídeo, existe uma solução alternativa?
Existe, mas a complexidade de engenharia aumenta significativamente. O processamento de vídeo pelo GPT-5.5 geralmente requer três etapas: usar o Whisper para obter as legendas (STT), extrair quadros para análise multimodal com o GPT-5.5 e, finalmente, integrar o raciocínio. Esse fluxo é concluído em uma única solicitação no Grok 4.3. Se o seu projeto tem necessidades de processamento de vídeo, sugerimos usar diretamente o Grok 4.3 via APIYI (apiyi.com); a complexidade de engenharia pode ser reduzida de 3 a 5 vezes, com custos menores.
Q5: Preciso alterar o código para atualizar do GPT-5.4 / GPT-5 para o GPT-5.5?
Quase não é necessário. Basta alterar o campo do modelo de gpt-5 ou gpt-5.4 para gpt-5.5, mantendo a base_url original. O GPT-5.5 tem um nível de raciocínio padrão aprimorado; se precisar de controle refinado, pode adicionar o campo reasoning_effort (low/medium/high/xhigh). Na mesma tarefa, o GPT-5.5 usa menos tokens que o GPT-5.4, o custo real pode ser equivalente ou ligeiramente menor, e a precisão é geralmente superior, tornando a migração vantajosa.
Q6: Devo usar o GPT-5.5 ou o GPT-5.5 Pro?
Divida de acordo com a dificuldade da tarefa. O preço do GPT-5.5 Pro é 6 vezes o do GPT-5.5 ($30/$180 vs $5/$30), oferecendo um nível de raciocínio mais alto e uma saída mais estável. Sugestão: reserve 95% do tráfego para o GPT-5.5 e deixe o GPT-5.5 Pro para "tarefas extremamente difíceis + decisões críticas" (como provas matemáticas complexas ou revisões de PR cruciais). Assim, você obtém o máximo retorno marginal usando apenas 5–10% de chamadas do GPT-5.5 Pro. Para a grande maioria dos negócios, o GPT-5.5 já é suficiente.
Q7: O Grok 4.3 não possui memória persistente, isso afetará o formato do produto?
Sim, mas existem soluções maduras. Se o seu produto é do tipo "assistente pessoal" ou "diálogo de longo prazo", a memória persistente é essencial. O Grok 4.3 ainda não suporta isso nativamente, sendo necessário construir uma camada de memória na aplicação. Soluções comuns incluem Mem0 e Letta, ferramentas de código aberto que são diretamente compatíveis com o protocolo OpenAI Chat Completions e, portanto, compatíveis com o Grok 4.3. Recomendamos testar o diálogo básico na APIYI (apiyi.com) antes de adicionar a camada de memória para minimizar os custos de iteração. Se não quiser construir a sua, usar o GPT-5.5 é a escolha mais simples.
Q8: O método de cobrança é o mesmo para ambos os modelos na APIYI?
Exatamente o mesmo, ambos são cobrados pelo uso de tokens. O Grok 4.3 é repassado 1:1 com o preço oficial da xAI ($1,25 entrada / $2,50 saída por milhão de tokens). O GPT-5.5 segue o preço oficial da OpenAI (multiplicador de modelo 2,5, correspondendo a $5,00 de entrada; multiplicador de conclusão 6, correspondendo a $30,00 de saída por milhão de tokens). Ambos os modelos compartilham a mesma chave API e a mesma base_url (https://vip.apiyi.com/v1), com a cobrança sendo deduzida do mesmo saldo da conta, facilitando a gestão e a conciliação.
Q9: Como reduzir o custo de chamada do GPT-5.5? Quais são as dicas de otimização?
Quatro dicas principais: (1) Ative o prompt caching; fixar o system prompt pode reduzir custos em 50–70%, com o GPT-5.5 custando apenas $0,50/1M para entrada em cache; (2) Reduza o reasoning_effort; para tarefas simples, use o nível low, o consumo de tokens pode cair 60%; (3) Ative a Batch API; para tarefas não em tempo real, você pode economizar mais 50%; (4) Use saída em streaming + encerramento antecipado; para respostas longas, você pode economizar tokens no final. Combinando essas quatro estratégias, o preço unitário real do GPT-5.5 pode chegar a cerca de 2 vezes o preço de entrada do Grok 4.3.
Q10: Como é a compatibilidade de Function Calling entre os dois modelos?
São totalmente compatíveis com o protocolo OpenAI Function Calling, permitindo que o código seja reutilizado. Ambos os modelos suportam o campo tools, chamadas de ferramentas paralelas e strict mode (esquema JSON obrigatório). A diferença é: a validação de esquema de ferramentas no strict mode do GPT-5.5 é mais rigorosa, resultando em uma taxa de erro de disparo de ferramentas menor; o Grok 4.3 suporta nativamente ferramentas do lado do servidor (web_search / x_search / code_execution), sem necessidade de implementação na camada de aplicação. Se o seu projeto depende fortemente de Function Calling, os dois modelos podem ser alternados sem problemas; recomendamos integrá-los via APIYI (apiyi.com) para realizar testes A/B.
Conclusão: A escolha real entre Grok 4.3 e GPT-5.5
Voltando à essência desta comparação, o Grok 4.3 e o GPT-5.5 não são uma simples comparação de "quem é mais forte", mas sim duas rotas de produto diferentes: a xAI usa o Grok 4.3 para nivelar a curva de custo dos modelos de raciocínio e ampliar as fronteiras multimodais, enquanto a OpenAI usa o GPT-5.5 para elevar o teto de precisão em codificação, matemática e recuperação de contexto longo.
Se tivéssemos que concluir em uma frase: a grande maioria das equipes deve usar o Grok 4.3 como principal e o GPT-5.5 como backup para caminhos críticos. O preço de $1,25/$2,50 do Grok 4.3 + velocidade de 207 tps + entrada de vídeo pode cobrir 90% dos cenários de negócios; os 10% restantes de tarefas de alto valor (codificação de nível superior, matemática de ponta, recuperação precisa de contexto longo) ficam a cargo do GPT-5.5. O custo total dessa combinação é de 15–25% de um "GPT-5.5 total", sem perda de qualidade nas tarefas críticas.
Para desenvolvedores brasileiros, o caminho de menor atrito para implementar essa arquitetura híbrida é o serviço proxy da APIYI (apiyi.com). Ambos os modelos compartilham a mesma base_url e a mesma chave API, bastando alterar o campo model na camada de aplicação para alternar, com custo de engenharia quase zero. O preço do Grok 4.3 é idêntico ao oficial, e o GPT-5.5 é repassado pelo preço oficial, sem taxas. Se você adicionar o Batch API e o desconto de entrada em cache, o custo unitário total pode cair ainda mais de 30–50%.
Por fim, uma sugestão de execução: reserve uma semana para rodar 100–500 amostras de cada modelo com seus dados reais de negócio na APIYI. Os resultados de referência são apenas um guia; a adequação real ao seu negócio é o que deve basear a decisão. Ambos os modelos já estão online e estáveis, a integração tem custo zero, e os dados de diferença só serão confiáveis quando você mesmo os testar.
Referências
-
Comunicado oficial da OpenAI: Informações de lançamento e documentação da API do GPT-5.5
- Link:
openai.com/index/introducing-gpt-5-5 - Descrição: Contém preços, benchmarks e explicações dos campos da API.
- Link:
-
Documentação para desenvolvedores da OpenAI: Especificações do modelo GPT-5.5 e exemplos de invocação do modelo
- Link:
developers.openai.com/api/docs/models/gpt-5.5 - Descrição: Parâmetros completos da API e detalhes de cobrança.
- Link:
-
Documentação de modelos da xAI: Especificações completas da API do Grok 4.3
- Link:
docs.x.ai/developers/models - Descrição: Inclui recursos exclusivos como entrada de vídeo, geração de documentos, entre outros.
- Link:
-
Ranking de inteligência Artificial Analysis: Comparação de desempenho abrangente entre modelos
- Link:
artificialanalysis.ai/models/grok-4-3 - Descrição: Avaliação integrada do índice de inteligência AA, velocidade e preço.
- Link:
-
Relatório de referência Vellum: Detalhes sobre os benchmarks da série GPT-5 / GPT-5.5
- Link:
vellum.ai/blog/gpt-5-2-benchmarks - Descrição: Avaliações independentes baseadas em múltiplos benchmarks.
- Link:
-
Comparação de modelos DocsBot: Comparativo detalhado entre GPT-5.5 e Grok 4.3
- Link:
docsbot.ai/models/compare/gpt-5-5/grok-4-3 - Descrição: Comparação de preços, desempenho e recursos.
- Link:
-
Documentação de integração APIYI: Tutorial completo para integração de ambos os modelos via serviço proxy de API
- Link:
help.apiyi.com - Descrição: Inclui explicações sobre taxas, exemplos de SDK e consulta de cobrança.
- Link:
Autor: Equipe APIYI — Focada em serviços de proxy de API para Modelos de Linguagem Grande, ajudando desenvolvedores a realizar a invocação do modelo Grok 4.3, GPT-5.5, Claude Opus 4.7 e outros modelos populares com um clique. Acesse a APIYI em apiyi.com para obter créditos de teste gratuitos.