Nota do autor: Detalhamento da arquitetura Thinker-Talker MoE, janela de contexto de 256K, capacidades de codificação de áudio e vídeo e a habilidade emergente de Audio-Visual Vibe Coding do modelo multimodal nativo Qwen3.5-Omni da Alibaba.
A equipe do Qwen da Alibaba lançou oficialmente o Qwen3.5-Omni em 30 de março de 2026, um modelo multimodal nativo que processa texto, imagem, áudio e vídeo em um único pipeline de computação. Como parte da ofensiva de lançamentos intensivos da Alibaba entre março e abril, o Qwen3.5-Omni atingiu o estado da arte (SOTA) em 215 benchmarks, marcando um avanço significativo para as empresas chinesas de IA no campo dos modelos de linguagem grandes multimodais.
Valor central: Entenda em 3 minutos o design da arquitetura Thinker-Talker do Qwen3.5-Omni, a estratégia de seleção das três variantes do modelo e a habilidade emergente de Audio-Visual Vibe Coding.
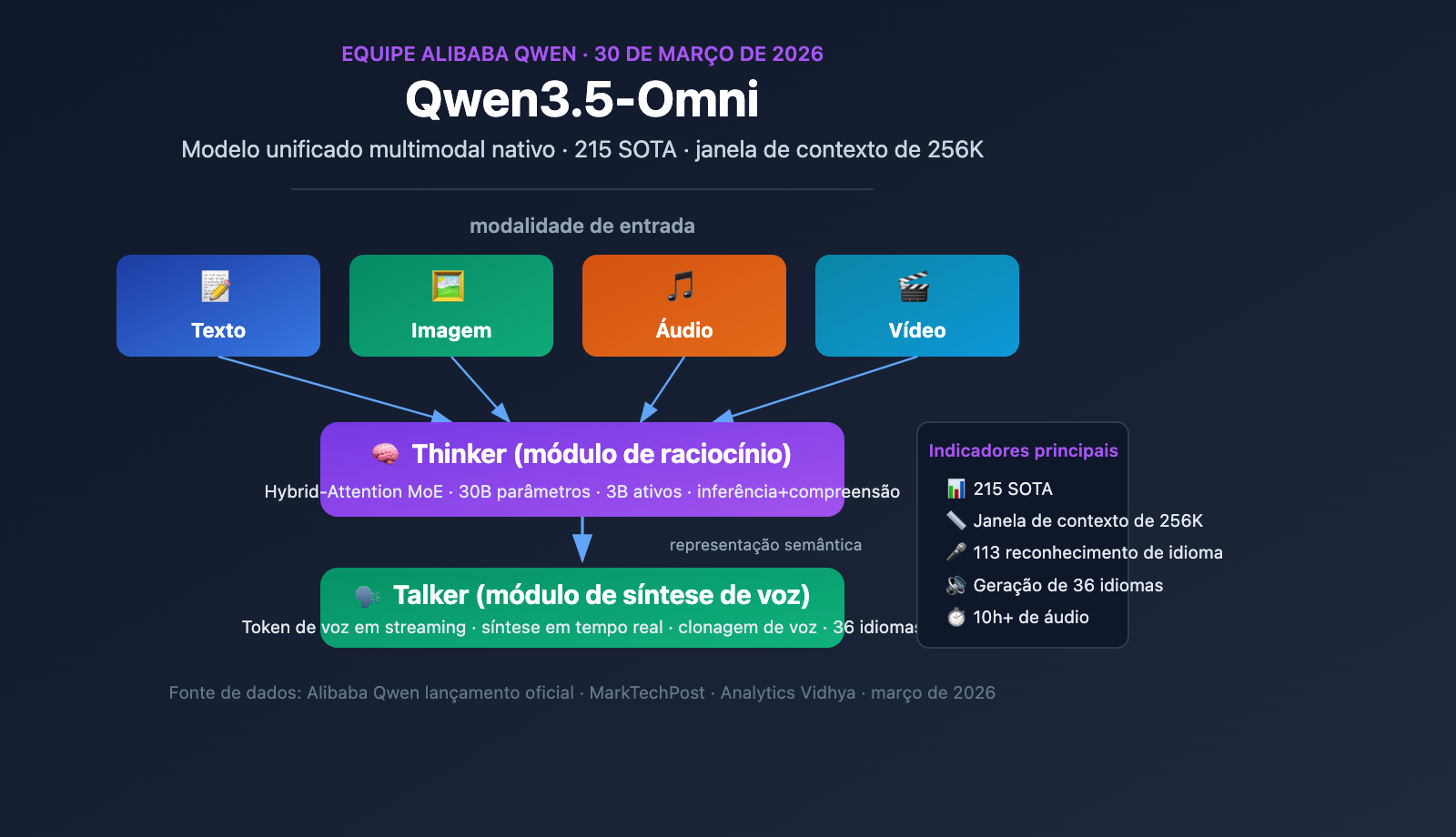
Informações principais do modelo multimodal Qwen3.5-Omni
Visão geral dos parâmetros do Qwen3.5-Omni
| Parâmetro | Detalhes |
|---|---|
| Data de lançamento | 30 de março de 2026 |
| Desenvolvedor | Equipe Qwen (Alibaba) |
| Arquitetura | Thinker-Talker + Hybrid-Attention MoE |
| Variantes do modelo | Plus (30B-A3B MoE), Flash (MoE leve), Light (modelo denso/pesos abertos) |
| Janela de contexto | 256K tokens |
| Capacidade de áudio | 10+ horas de áudio contínuo |
| Capacidade de vídeo | 400+ segundos de vídeo 720p (amostragem de 1 FPS) |
| Reconhecimento de voz | 113 idiomas e dialetos (anteriormente apenas 19) |
| Geração de voz | 36 idiomas (anteriormente apenas 10) |
| Dados de treinamento | Mais de 100 milhões de horas de dados de áudio e vídeo |
| Desempenho em benchmarks | SOTA em 215 benchmarks de compreensão de áudio/vídeo |
Posicionamento do modelo Qwen3.5-Omni
O valor central do Qwen3.5-Omni reside em ser multimodal nativo — não se trata de uma solução montada com um modelo de texto conectado a módulos de áudio e vídeo, mas sim de um modelo unificado pré-treinado do zero em mais de 100 milhões de horas de dados de áudio e vídeo. Todas as modalidades são processadas no mesmo pipeline de computação, o que significa que o modelo pode realmente entender informações semânticas em áudio e vídeo, em vez de simplesmente transcrever áudio e vídeo para texto antes de processá-los.
Ao mesmo tempo, o Qwen3.5-Omni é um dos modelos da série lançados intensivamente pela Alibaba entre março e abril de 2026. Apenas alguns dias depois, em 2 de abril, a Alibaba lançou o modelo Qwen3.6-Plus (suportando 1 milhão de tokens de janela de contexto, focado em programação baseada em agentes), demonstrando o forte investimento da Alibaba no campo dos modelos de linguagem grandes.
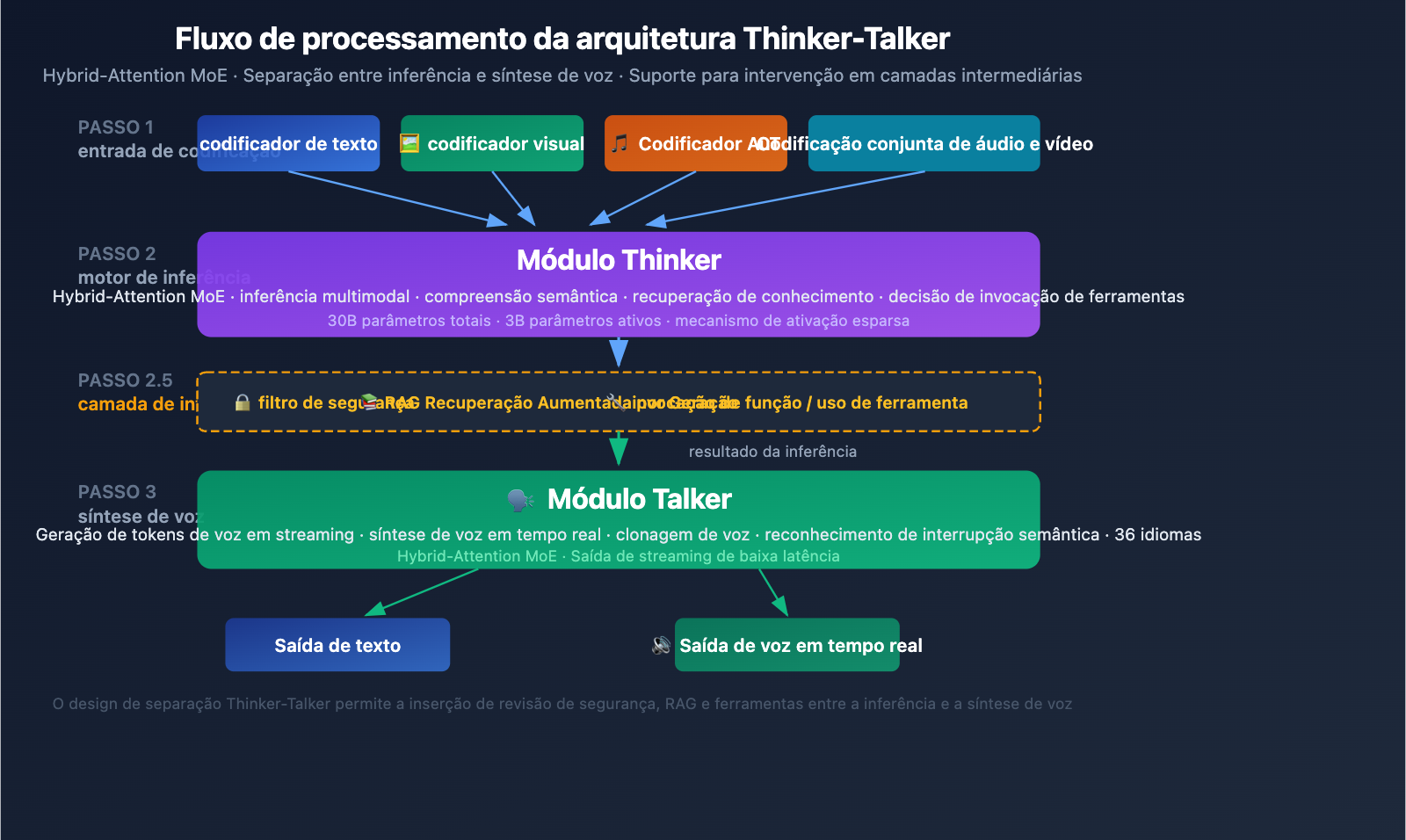
Detalhando a arquitetura do Qwen3.5-Omni Thinker-Talker
Design de módulo duplo Thinker-Talker
O Qwen3.5-Omni adota uma arquitetura exclusiva de módulo duplo Thinker-Talker. Esse design, introduzido pela primeira vez no Qwen2.5-Omni, recebeu uma atualização significativa na versão 3.5: ambos os módulos agora utilizam a arquitetura Hybrid-Attention MoE (Mistura de Especialistas com Atenção Híbrida).
Módulo Thinker (Pensador):
- Processa todas as modalidades de entrada: texto, imagem, áudio e vídeo.
- Executa tarefas de raciocínio e compreensão.
- Gera representações de raciocínio interno.
- Utiliza o codificador nativo Audio Transformer (AuT) para processar áudio.
- Produz representações semânticas estruturadas.
Módulo Talker (Expressador):
- Recebe as representações de raciocínio do Thinker.
- Converte representações semânticas em tokens de voz em streaming.
- Suporta síntese de voz em tempo real.
- Implementa uma expressão vocal natural (incluindo entonação, emoção e pausas).
Valor de engenharia da arquitetura Thinker-Talker
A principal vantagem desse design separado é a intervenção intermediária — sistemas externos (pipelines de recuperação RAG, filtros de segurança, chamadas de função) podem intervir entre a saída do Thinker e a síntese do Talker. Isso significa que:
- As empresas podem adicionar revisões de segurança antes da saída de voz.
- Os desenvolvedores podem acionar chamadas de ferramentas com base nos resultados do raciocínio.
- Sistemas RAG podem complementar os resultados com recuperação de conhecimento antes de responder.
Mecanismo de ativação esparsa MoE
O núcleo do design Hybrid-Attention MoE é a ativação esparsa — o modelo ativa apenas uma parte dos parâmetros ao processar cada token (apenas 3B ativos de um total de 30B). Esse mecanismo permite que o modelo mantenha uma alta capacidade enquanto mantém o custo computacional de inferência única dentro de uma faixa aceitável, o que é crucial para aplicações em tempo real (como diálogos por voz).
🎯 Dica de desenvolvimento: A arquitetura separada Thinker-Talker do Qwen3.5-Omni é ideal para construir fluxos de trabalho de IA de várias etapas. Se você precisa integrar capacidades multimodais em suas aplicações, pode testar rapidamente as diferenças de desempenho entre o Qwen3.5-Omni e outros modelos multimodais líderes através da plataforma APIYI apiyi.com.
Comparação das três variantes do modelo Qwen3.5-Omni
Guia de seleção: Plus / Flash / Light
O Qwen3.5-Omni oferece três variantes de modelo voltadas para diferentes cenários:
| Variante | Tipo de arquitetura | Escala de parâmetros | Método de acesso | Cenários aplicáveis |
|---|---|---|---|---|
| Plus | MoE (30B-A3B) | 30B total / 3B ativo | API (DashScope) | Raciocínio de alta qualidade, tarefas multimodais complexas |
| Flash | MoE leve | Menos parâmetros | API (DashScope) | Cenários de baixa latência, diálogos em tempo real |
| Light | Modelo denso | Escala menor | Pesos abertos (HuggingFace) | Implantação local, dispositivos de borda |
Sugestão de escolha:
- Busca o melhor desempenho → Escolha a variante Plus, que obteve a pontuação mais alta em 215 benchmarks.
- Busca baixa latência → Escolha a variante Flash, ideal para diálogos de voz em tempo real e interações via streaming.
- Necessita de implantação local → Escolha a variante Light, com pesos abertos que podem ser executados em GPUs locais.
Como acessar a API do Qwen3.5-Omni
A API do Qwen3.5-Omni segue o formato padrão /v1/chat/completions, especificando o tipo de saída através do parâmetro modalities:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Acesso unificado via APIYI
)
response = client.chat.completions.create(
model="qwen3.5-omni-plus",
modalities=["text", "audio"],
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Por favor, analise o conteúdo deste vídeo"},
{"type": "video_url", "video_url": {"url": "https://example.com/video.mp4"}}
]
}
]
)
Ver exemplo completo de entrada multimodal
import openai
import base64
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Entrada multimodal: Imagem + Áudio + Texto
response = client.chat.completions.create(
model="qwen3.5-omni-plus",
modalities=["text", "audio"],
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Por favor, gere um relatório de análise com base na imagem e na descrição de áudio"},
{
"type": "image_url",
"image_url": {"url": "data:image/png;base64,..."}
},
{
"type": "input_audio",
"input_audio": {
"data": base64.b64encode(audio_bytes).decode(),
"format": "wav"
}
}
]
}
],
max_tokens=2000
)
# Obter resposta em texto
print(response.choices[0].message.content)
# Se a saída de áudio foi solicitada, obter os dados de voz
if hasattr(response.choices[0].message, 'audio'):
audio_data = response.choices[0].message.audio
print(f"Formato do áudio: {audio_data.format}")
💡 Dica de integração: A API do Qwen3.5-Omni é compatível com o formato do SDK da OpenAI. Se você já possui código baseado no SDK da OpenAI, basta alterar os parâmetros
base_urlemodelpara alternar rapidamente. Através da plataforma APIYI apiyi.com, você pode testar simultaneamente os efeitos multimodais do Qwen3.5-Omni, GPT-4o e outros modelos.
Análise de Desempenho do Benchmark Qwen3.5-Omni
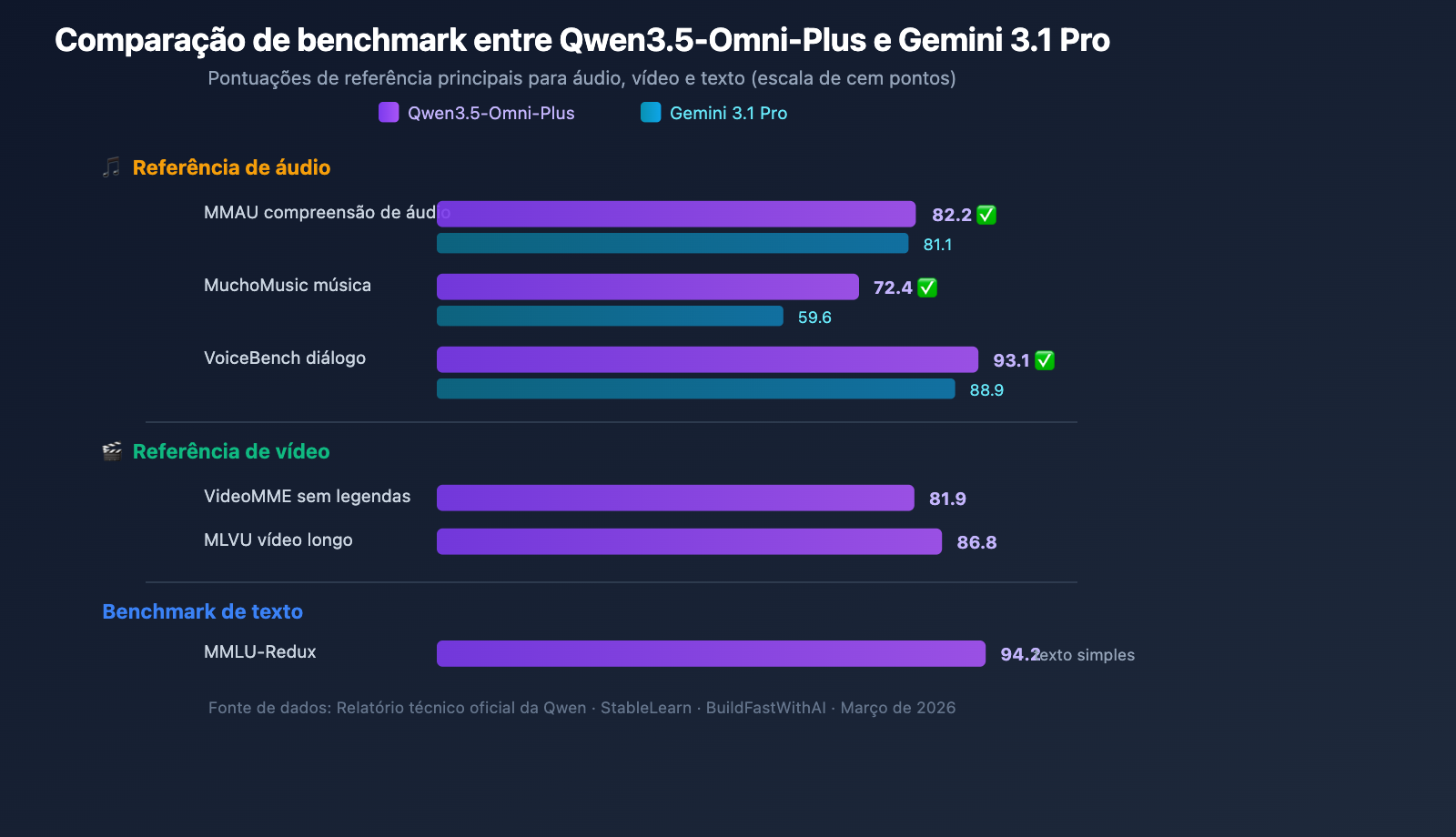
Capacidade de Compreensão de Áudio
O Qwen3.5-Omni-Plus supera o Google Gemini 3.1 Pro em todos os benchmarks relacionados a áudio:
| Benchmark | Qwen3.5-Omni-Plus | Gemini 3.1 Pro | Vencedor |
|---|---|---|---|
| Compreensão de Áudio MMAU | 82.2 | 81.1 | Qwen |
| Compreensão Musical MuchoMusic | 72.4 | 59.6 | Qwen (+21%) |
| Diálogo VoiceBench | 93.1 | 88.9 | Qwen |
A vantagem do Qwen3.5-Omni na compreensão musical (MuchoMusic) é particularmente notável, com uma liderança de 21%.
Capacidades Visuais e de Vídeo
| Benchmark | Qwen3.5-Omni-Plus | Descrição |
|---|---|---|
| MMMU-Pro | 73.9 | Pontuação máxima em compreensão multimodal |
| RealWorldQA | 84.1 | Perguntas e respostas visuais do mundo real |
| VideoMME (sem legendas) | 81.9 | Compreensão multimodal de vídeo |
| MLVU | 86.8 | Compreensão de vídeos longos |
| MVBench | 79.0 | Benchmark de vídeo multidimensional |
| LVBench | 71.2 | Benchmark de vídeo longo |
Manutenção da Capacidade de Raciocínio de Texto
Ao adquirir capacidades multimodais completas, o desempenho de raciocínio de texto do Qwen3.5-Omni praticamente não sofreu redução:
| Benchmark | Qwen3.5-Omni-Plus | Qwen3.5-Plus (apenas texto) | Diferença |
|---|---|---|---|
| MMLU-Redux | 94.2 | 94.3 | -0.1 |
| C-Eval | 92.0 | 92.3 | -0.3 |
| IFEval | 89.7 | 89.7 | 0 |
Isso significa que escolher o Qwen3.5-Omni não sacrifica a qualidade do raciocínio textual — você pode cobrir cenários de texto e multimodais com um único modelo.
🎯 Sugestão de seleção: O Qwen3.5-Omni tem uma vantagem clara na compreensão de áudio e música. Se a sua aplicação envolve interação por voz ou análise de áudio, recomendamos priorizar este modelo. Você pode usar o serviço proxy de API APIYI (apiyi.com) para comparar rapidamente o desempenho do Qwen3.5-Omni e do GPT-4o no seu cenário específico.
As 3 principais capacidades diferenciadas do Qwen3.5-Omni
Capacidade 1: Audio-Visual Vibe Coding
O Qwen3.5-Omni demonstra uma capacidade emergente que a equipe do Qwen chama de "Audio-Visual Vibe Coding" — o modelo pode escrever código funcional ao assistir a vídeos + ouvir comandos de voz, sem a necessidade de treinamento específico para essa habilidade.
Em testes práticos, o modelo consegue:
- Converter esboços feitos à mão (capturados pela câmera) em páginas React funcionais.
- Escrever código de funcionalidade com base em demonstrações em vídeo e descrições verbais.
- Compreender a intenção do design visual e gerar a implementação de front-end correspondente.
Essa capacidade é valiosa para prototipagem rápida e cenários de baixo código (low-code).
Capacidade 2: Reconhecimento de interrupção semântica
Sistemas tradicionais de interação por voz não conseguem distinguir entre feedbacks reativos do usuário, como "hum" ou "ah", e uma intenção real de interrupção. O Qwen3.5-Omni introduz o Reconhecimento de Intenção de Turn-Taking (tomada de turno) nativo, que pode distinguir entre:
- Backchanneling (Feedback de resposta): Como "hum", "certo", feedbacks sem intenção de interrupção semântica.
- Interrupção Semântica: Situações em que o usuário tem a intenção clara de assumir o controle da conversa.
Isso torna a experiência de diálogo por voz do Qwen3.5-Omni muito mais próxima de uma conversa humana real.
Capacidade 3: Clonagem de voz
Os usuários podem fazer upload de uma gravação de voz, e o Qwen3.5-Omni aprenderá e clonará essas características vocais, utilizando a voz clonada em todas as saídas de voz subsequentes. A voz clonada mantém naturalidade e estabilidade em cenários multilíngues.
O lugar do Qwen3.5-Omni na ofensiva de IA da Alibaba
Ritmo de lançamento de modelos de IA da Alibaba (março-abril de 2026)
| Data de lançamento | Modelo | Posicionamento | Características principais |
|---|---|---|---|
| 30 de março | Qwen3.5-Omni | Modelo multimodal nativo | Processamento unificado de texto/imagem/áudio/vídeo |
| 2 de abril | Qwen3.6-Plus | Modelo de agente corporativo | Janela de contexto de 1 milhão de tokens, programação baseada em agentes |
| Atualização contínua | Qwen3-TTS | Síntese de voz | Série TTS de código aberto, suporte a clonagem de voz |
Esse ritmo intenso de lançamentos mostra que a Alibaba está avançando em todas as frentes na construção de capacidades de Modelos de Linguagem Grande. O Qwen3.5-Omni cobre a percepção e compreensão multimodal, enquanto o Qwen3.6-Plus foca em geração de código corporativo e capacidades de agente, formando uma dupla complementar.
Vale notar que as variantes Plus e Flash do Qwen3.5-Omni foram lançadas via API de código fechado, quebrando a estratégia anterior da Alibaba de priorizar o código aberto. Analistas de mídia como o WinBuzzer acreditam que isso reflete o foco da Alibaba na lucratividade sob pressão comercial — a manchete da Bloomberg foi direta: "Alibaba lança terceiro modelo de IA de código fechado, focando em lucros".
💰 Dica de custo: Se você está pensando em integrar o Qwen3.5-Omni ao seu produto, recomendo fazer um teste de conceito usando o crédito gratuito da plataforma APIYI (apiyi.com) para confirmar o desempenho do modelo antes de investir na implementação em produção. A plataforma suporta toda a linha de modelos, incluindo Qwen, GPT, Claude e Gemini, facilitando a escolha flexível para diferentes cenários.
Perguntas frequentes
Q1: O Qwen3.5-Omni é de código aberto ou fechado?
O Qwen3.5-Omni possui três variantes: Plus e Flash estão disponíveis atualmente apenas via API DashScope da Alibaba Cloud (código fechado), enquanto os pesos da variante Light estão abertos para download no HuggingFace (código aberto). O antecessor Qwen3-Omni era totalmente aberto sob a licença Apache 2.0, mas as variantes Plus/Flash da versão 3.5 mudaram para o modelo exclusivo de API. Se você precisa de implantação local, pode optar pela variante Light.
Q2: Como o Qwen3.5-Omni se compara ao GPT-4o?
Em termos de compreensão de áudio e música, o Qwen3.5-Omni-Plus está visivelmente à frente do GPT-4o. Na compreensão de vídeo, ambos possuem vantagens distintas. No raciocínio textual, o Qwen3.5-Omni está quase empatado com o modelo puramente textual da própria casa, o Qwen3.5-Plus. Sugerimos realizar testes comparativos no seu cenário de aplicação específico através da plataforma APIYI (apiyi.com), pois o desempenho pode variar significativamente dependendo do caso de uso.
Q3: Como começar a usar a API do Qwen3.5-Omni rapidamente?
A API do Qwen3.5-Omni é compatível com o formato padrão do SDK da OpenAI, tornando a integração muito simples. Basta instalar o SDK openai, configurar a chave API e a base_url correspondentes para realizar a invocação do modelo. Através da APIYI (apiyi.com), você pode obter créditos de teste gratuitos e usar os exemplos de código deste artigo para validar rapidamente os resultados da invocação multimodal.
Resumo
Pontos principais do modelo multimodal Qwen3.5-Omni:
- Multimodalidade Nativa: Processa texto, imagem, áudio e vídeo em um único pipeline, sem soluções de "remendo" ou montagem.
- Arquitetura Thinker-Talker: Separa o raciocínio da síntese de voz, permitindo intervenção em camadas intermediárias e invocação de ferramentas.
- 3 Variantes Disponíveis: Plus (mais potente), Flash (baixa latência) e Light (pesos abertos para implantação local).
- 215 resultados SOTA: Liderança significativa sobre o Gemini 3.1 Pro em compreensão de áudio e música.
- Capacidade Emergente: O "Audio-Visual Vibe Coding" permite que o modelo escreva código através de vídeo e voz.
O Qwen3.5-Omni representa um avanço importante na IA multimodal — um único modelo que cobre quatro modalidades (texto, visão, áudio e vídeo) sem comprometer a capacidade de raciocínio textual. Para desenvolvedores que precisam de recursos multimodais, esta é uma opção que vale a pena avaliar seriamente.
Recomendamos testar rapidamente o Qwen3.5-Omni e outros modelos multimodais líderes através da APIYI (apiyi.com). A plataforma oferece créditos gratuitos e uma interface de API unificada, facilitando a comparação e a seleção de modelos.
📚 Referências
-
Relatório MarkTechPost: Detalhes do lançamento do Qwen3.5-Omni
- Link:
marktechpost.com/2026/03/30/alibaba-qwen-team-releases-qwen3-5-omni-a-native-multimodal-model-for-text-audio-video-and-realtime-interaction - Descrição: Análise técnica detalhada e interpretação da arquitetura.
- Link:
-
Repositório GitHub do Qwen3-Omni: Código-fonte e pesos do modelo
- Link:
github.com/QwenLM/Qwen3-Omni - Descrição: Código completo e documentação da geração anterior, Qwen3-Omni.
- Link:
-
Análise Profunda da Analytics Vidhya: Análise do relatório técnico do Qwen3.5-Omni
- Link:
analyticsvidhya.com/blog/2026/03/qwen3-5-omni-ai-model - Descrição: Análise detalhada cobrindo clonagem de voz, Vibe Coding e outras capacidades.
- Link:
-
Relatório eWeek: Qwen3.5-Omni como o modelo multimodal mais avançado do Alibaba
- Link:
eweek.com/news/qwen3-5-omni-alibaba-multimodal-ai-launch - Descrição: Análise sob a perspectiva da indústria e comparação com concorrentes.
- Link:
-
Página do Modelo no HuggingFace: Qwen3-Omni-30B-A3B-Instruct
- Link:
huggingface.co/Qwen/Qwen3-Omni-30B-A3B-Instruct - Descrição: Download dos pesos do modelo e especificações técnicas.
- Link:
Autor: Equipe Técnica APIYI
Troca de experiências: Sinta-se à vontade para discutir práticas de aplicação de IA multimodal na seção de comentários. Para mais materiais de desenvolvimento de IA, visite o centro de documentação da APIYI em docs.apiyi.com.