Nota do autor: Respondendo à pergunta mais frequente dos desenvolvedores: As APIs de Modelos de Linguagem Grande aceitam PDFs diretamente? A resposta é que a grande maioria não aceita. Este artigo detalha três soluções práticas: extração de texto, compreensão de imagens e processamento no lado do cliente.
"Será que a API do Modelo de Linguagem Grande aceita um arquivo PDF diretamente?" — Essa é uma das perguntas mais comuns no nosso grupo de suporte. Muitos desenvolvedores, acostumados com a funcionalidade de "arrastar e soltar PDF para conversar" nas versões web do ChatGPT ou Claude, assumem que a API funciona da mesma forma.
A realidade é: A grande maioria das APIs de Modelos de Linguagem Grande não suporta entrada direta de arquivos PDF. Mesmo grandes fornecedores como OpenAI e Anthropic têm como formato de entrada principal da sua API texto e imagens — PDF não está na lista de formatos suportados. Mais importante ainda, plataformas de proxy de API de terceiros, como a APIYI, também não suportam upload direto de PDF, porque o protocolo subjacente não o permite.
Mas não se preocupe, existem três soluções maduras para processar PDFs. Este artigo vai te ajudar a entender o porquê e como escolher a melhor abordagem para o seu caso.
Valor principal: Após ler este artigo, você entenderá por que as APIs de Modelos de Linguagem Grande não suportam PDFs e como usar três métodos de pré-processamento para atender eficientemente à necessidade de entrada de PDF.

Pontos Principais para Entrada de PDF em APIs de Modelos de Linguagem Grande
| Ponto | Explicação | Impacto |
|---|---|---|
| API não aceita PDF diretamente | A entrada padrão das APIs de modelos principais como GPT, DeepSeek, Llama, Qwen é texto e imagem | É necessário um fluxo de pré-processamento anterior |
| Versão web ≠ API | O upload de PDF na versão web do ChatGPT, Claude é um pré-processamento frontend antes de chamar a API | Não iguale a experiência web com a capacidade da API |
| Plataformas de terceiros também não suportam | Plataformas proxy como APIYI transmitem o protocolo API original, se a base não suporta, a plataforma também não | Não espere que plataformas proxy processem PDF adicionalmente |
| 3 soluções de pré-processamento maduras e confiáveis | Extração de texto, compreensão de imagem, processamento no cliente têm cenários de aplicação diferentes | Escolher a solução certa é mais prático do que procurar uma "API que suporta PDF" |
Por que as APIs de Modelos de Linguagem Grande não suportam entrada de PDF?
Muitos desenvolvedores ficam confusos: a versão web claramente permite fazer upload de PDF, por que a API não? A razão é simples – a função de "upload de PDF" na versão web não é o próprio modelo processando o PDF, mas o frontend/backend fazendo pré-processamento nos bastidores:
- Extração de texto: O frontend extrai o texto do PDF, converte para texto puro e então envia para o modelo
- Renderização de página: Renderiza cada página do PDF como uma imagem, permitindo que o modelo entenda através da capacidade de visão
- Recuperação RAG: Armazena o conteúdo do PDF de forma vetorizada, durante a conversação apenas recupera trechos relevantes para enviar ao modelo
Essas etapas de pré-processamento são encapsuladas nos produtos da versão web, o usuário não percebe. Mas quando você chama a API diretamente, esse pré-processamento precisa ser feito por você.
Verificação Rápida do Suporte a PDF em APIs de Modelos de Linguagem Grande
| Modelo | Transmissão direta de PDF via API | Formato de entrada padrão | Recomendação de processamento de PDF |
|---|---|---|---|
| GPT-4o / GPT-4.1 | Não suportado | Texto + imagem (Base64) | Extrair texto primeiro ou converter para imagem |
| Claude | Suporte parcial (Beta) | Texto + imagem | Ainda recomendamos seguir o fluxo de pré-processamento para maior estabilidade |
| Gemini | Suporte parcial | Texto + imagem | Ainda recomendamos seguir o fluxo de pré-processamento para maior controle |
| DeepSeek | Não suportado | Texto puro | Deve extrair texto primeiro |
| Llama / Qwen | Não suportado | Texto (alguns suportam imagem) | Deve extrair texto primeiro |
| APIYI e outros terceiros | Não suportado | Transmite protocolo original | É necessário pré-processamento próprio antes da chamada |
🎯 Observação importante: Embora a documentação oficial da API do Claude e Gemini mencione a funcionalidade de entrada de PDF, essa funcionalidade tem incertezas de compatibilidade e estabilidade, e não suporta transmissão direta de PDF ao chamar através de plataformas proxy de terceiros como APIYI. Recomendamos seguir uniformemente a solução de pré-processamento, que tem a melhor compatibilidade e maior estabilidade.
Solução 1 para Processamento de PDF em APIs de Modelos de Linguagem Grande: Extração de Texto Prévia
Esta é a solução mais universal, de menor custo e compatível com todos os modelos. Ideia central: primeiro usar uma biblioteca Python para converter PDF em Markdown ou texto puro, depois enviar o texto como prompt para a API.
Comparação de Ferramentas de Extração de Texto de PDF
| Ferramenta | Velocidade | Melhor cenário | Características |
|---|---|---|---|
| PyMuPDF4LLM | ~0.14s/documento | Extração de texto geral + tabelas | Melhor equilíbrio entre velocidade e qualidade, saída em Markdown |
| pdfplumber | Média | Extração de dados tabulares | Alta precisão na extração de tabelas por coordenadas |
| Marker-PDF | ~11s/documento | Conversão fiel de layouts complexos | Melhor preservação de estrutura, velocidade mais lenta |
| PyPDF2 | Rápida | PDF simples de texto puro | Leve, adequado para extração básica |
Exemplo de Código para Extração de Texto de PDF
A seguir está a solução mais comumente usada, extraindo o texto do PDF e enviando para a API do Modelo de Linguagem Grande:
import pymupdf4llm
import openai
# Passo 1: Converter PDF para Markdown
md_text = pymupdf4llm.to_markdown("report.pdf")
# Passo 2: Enviar texto puro para qualquer Modelo de Linguagem Grande
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": f"Por favor, resuma os pontos principais deste relatório:\n\n{md_text}"}]
)
print(response.choices[0].message.content)
Cenário de aplicação: PDFs baseados principalmente em texto, como contratos, artigos, relatórios, documentos técnicos. Desde que o PDF tenha uma camada de texto embutida (não seja um documento escaneado), o efeito da extração é muito bom.
Recomendação: A solução de extração de texto é compatível com todos os Modelos de Linguagem Grande – GPT, Claude, DeepSeek, Llama, Qwen, todos podem ser usados. Obtenha a chave API através do APIYI apiyi.com, uma única chave pode chamar todos os modelos para testes comparativos.
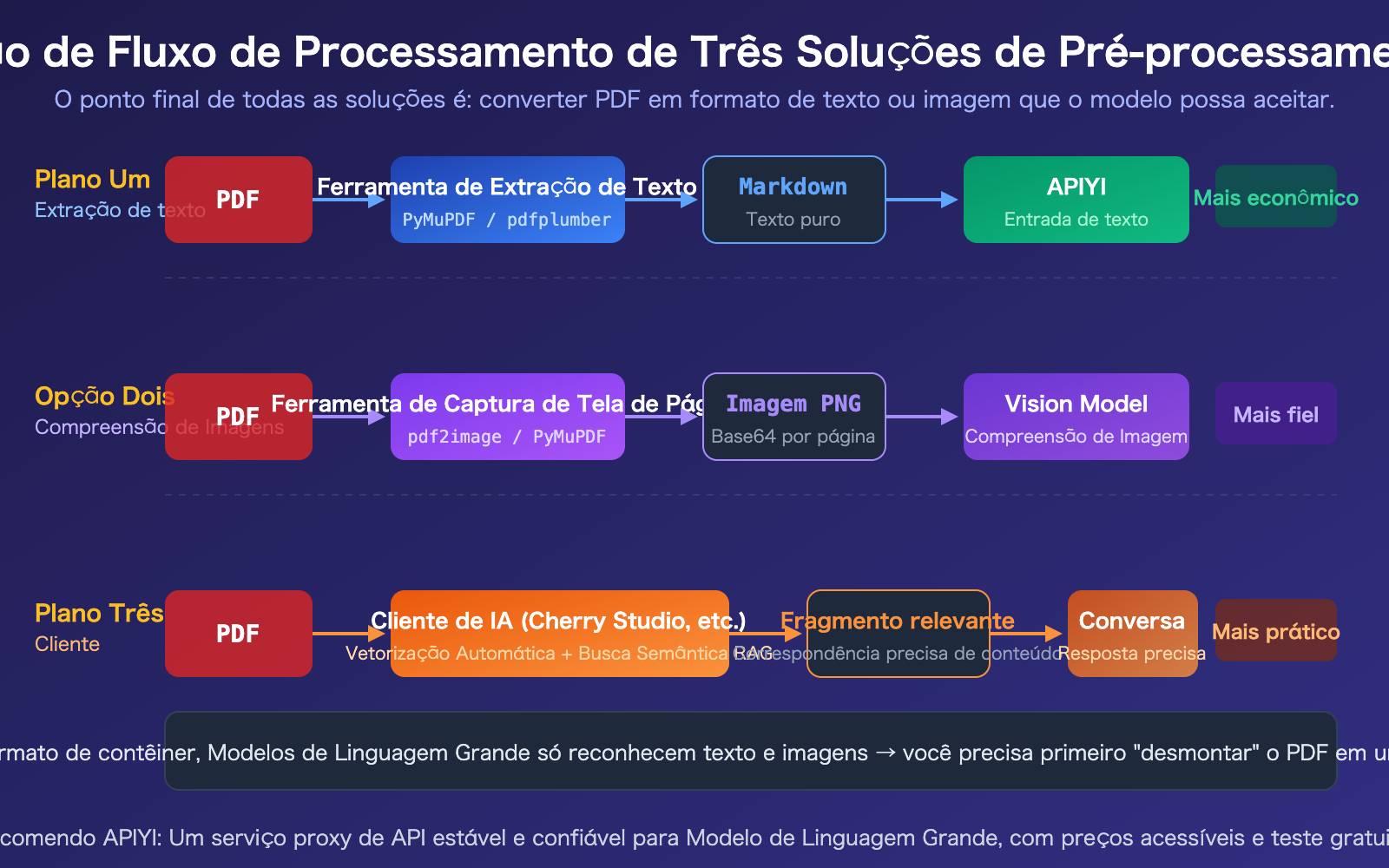
Solução 2 para Processamento de PDF com API de Modelo de Linguagem Grande: Conversão para Imagem + Compreensão Visual
Quando um PDF contém informações visuais como gráficos, documentos digitalizados ou layouts complexos, a extração puramente de texto perde esse conteúdo. Nesses casos, é necessário renderizar cada página do PDF como uma imagem e usar um modelo com suporte a Visão (Vision) para compreendê-la.
Exemplo de Código: PDF para Imagem
import fitz # PyMuPDF
import base64
import openai
# Passo 1: Converter PDF página por página para imagens PNG
doc = fitz.open("report.pdf")
images = []
for page in doc:
pix = page.get_pixmap(dpi=200)
b64 = base64.b64encode(pix.tobytes("png")).decode()
images.append(b64)
Ver código completo: Enviar imagens para a Vision API
import fitz
import base64
import openai
def pdf_to_vision(pdf_path, question, max_pages=10):
"""Converte PDF para imagens e envia para a Vision API"""
doc = fitz.open(pdf_path)
# Construir mensagem com múltiplas imagens (controlar número de páginas para evitar excesso de tokens)
content = [{"type": "text", "text": question}]
for i, page in enumerate(doc):
if i >= max_pages:
break
pix = page.get_pixmap(dpi=150)
b64 = base64.b64encode(pix.tobytes("png")).decode()
content.append({
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{b64}"}
})
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": content}]
)
return response.choices[0].message.content
# Exemplo de uso
result = pdf_to_vision(
"financial_report.pdf",
"Analise os gráficos de tendência neste relatório financeiro e resuma os dados principais",
max_pages=5 # Controlar número de páginas, cada uma consome ~765 tokens
)
print(result)
Cenários de aplicação: Relatórios de pesquisa com gráficos, documentos digitalizados, faturas, plantas de construção e outros PDFs ricos em informações visuais.
Aviso sobre custos: Cada página de imagem consome aproximadamente 765 tokens (resolução padrão GPT-4o). Um PDF de 10 páginas custará cerca de 7.650 tokens só em imagens, somando-se à pergunta e resposta, pode ultrapassar 10.000 tokens. É essencial controlar o número de páginas.
🎯 Sugestão para controle de custos: Não envie todas as páginas de um PDF de uma vez. Primeiro, use a Solução 1 para extrair o texto e fazer uma triagem, identificando as páginas-chave. Depois, use a Solução 2 para fazer a compreensão por imagem apenas dessas páginas específicas. Você pode monitorar o consumo de tokens em tempo real pelo painel de uso da APIYI em apiyi.com.
Solução 3 para Processamento de PDF com API de Modelo de Linguagem Grande: Clientes de IA
Se você não quer escrever código e só precisa "perguntar sobre o conteúdo do PDF" em conversas do dia a dia, usar um cliente de IA é a forma mais prática.
Como clientes como o Cherry Studio processam PDFs
Esses clientes basicamente automatizam o trabalho das Soluções 1 e 2 para você:
- Vetorização automática: Extraem o conteúdo do PDF, dividem em pedaços menores e armazenam em um banco de dados vetorial local.
- Busca semântica: Quando você faz uma pergunta, o cliente primeiro busca os trechos de conteúdo mais relevantes.
- Envio preciso: Apenas os trechos relevantes (e não o documento inteiro) são enviados para a API do modelo de linguagem grande.
- Economia de tokens: A técnica de RAG (Recuperação Aumentada por Geração) reduz drasticamente a quantidade de conteúdo enviada ao modelo.
Considerações ao usar clientes para processar PDFs
- Configurar a chave API: Basta inserir sua chave API da APIYI (apiyi.com) no cliente para acessar todos os modelos disponíveis através dela.
- Controlar o tamanho do arquivo: PDFs muito grandes (centenas de páginas) podem levar muito tempo para serem vetorizados. É recomendável dividi-los antes de processar.
- Atenção aos custos de tokens: Embora o RAG comprima o conteúdo, documentos longos ainda podem gerar custos significativos.
- Escolher o modelo adequado: Para perguntas simples, use modelos mais baratos (como GPT-4o-mini). Para análises complexas, use os modelos mais avançados.
Comparação de 3 Soluções para Processamento de PDF com APIs de Modelos de Linguagem Grande
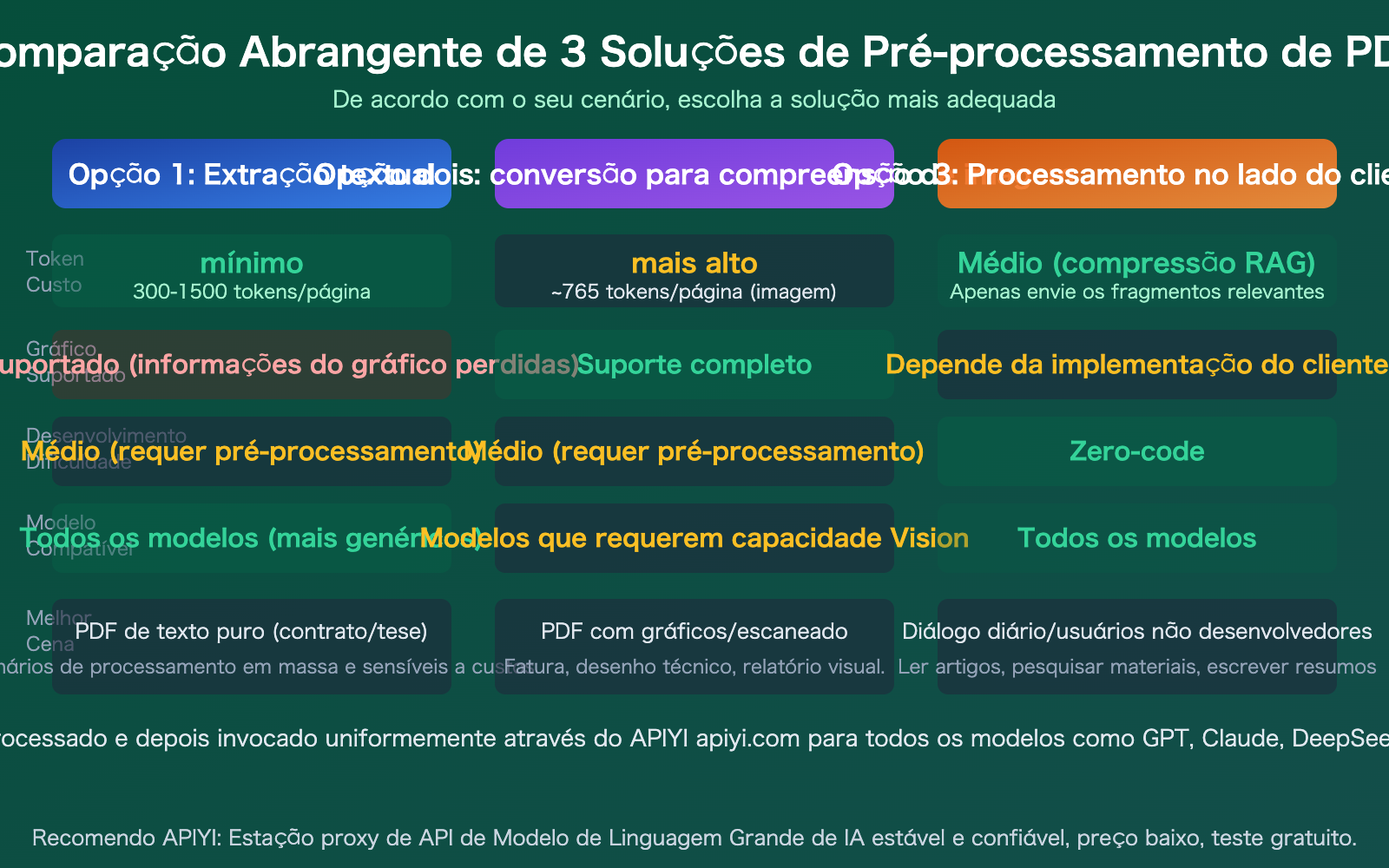
| Solução | Custo de Token | Suporte a Gráficos | Dificuldade de Desenvolvimento | Compatibilidade de Modelo | Melhor Cenário |
|---|---|---|---|---|---|
| Extração por Textualização | Mais baixo (300-1500/página) | Não suporta | Média | Todos os modelos | PDFs de texto puro, grandes volumes |
| Compreensão via Conversão para Imagem | Mais alto (~765/página) | Suporte completo | Média | Requer modelos Vision | Gráficos, documentos escaneados |
| Processamento no Cliente | Médio (compressão RAG) | Depende do cliente | Zero código | Todos os modelos | Conversas diárias, não-desenvolvedores |
Observação da comparação: As três soluções não são mutuamente exclusivas; em projetos reais, geralmente são usadas em combinação. Por exemplo, primeiro use a solução um para extrair texto e fazer uma triagem inicial, depois use a solução dois para compreensão por imagem nas páginas-chave. Através do APIYI apiyi.com, você pode acessar todos os modelos de forma unificada.
Perguntas Frequentes
Q1: Por que o ChatGPT na web permite upload de PDF, mas a API não suporta?
A funcionalidade de "upload de PDF" na versão web é o produto realizando um pré-processamento para você — extraindo texto, renderizando imagens, criando índices de busca — e só então chamando a API subjacente. O formato de entrada principal da API em si é texto e imagem. PDF, sendo um formato de contêiner de documento complexo, não está dentro do suporte padrão. Ao chamar a API, você precisa completar essas etapas de pré-processamento por conta própria.
Q2: Plataformas de proxy como a APIYI podem me ajudar a processar PDFs?
Não. A essência de plataformas de proxy como a APIYI é retransmitir as requisições da API. Se o protocolo subjacente não suporta PDF, a plataforma também não pode processá-lo. Você precisa realizar o pré-processamento do PDF (extrair texto ou converter em imagem) antes de chamar a API e, em seguida, enviar o texto ou imagem processados para o Modelo de Linguagem Grande através da APIYI em apiyi.com.
Q3: Como controlar os custos de Token ao processar PDFs?
Algumas dicas práticas:
- Priorize a Solução 1 (extração de texto), que tem o custo mais baixo
- Processe apenas as páginas necessárias, não envie o documento inteiro de uma vez
- Use técnicas de RAG para dividir e recuperar, enviando apenas os trechos relevantes para o modelo
- Use modelos mais baratos (como GPT-4o-mini) para perguntas simples e modelos premium para análises complexas
- Monitore o consumo em tempo real através do painel de uso da APIYI em apiyi.com
Conclusão
Os pontos principais sobre a entrada de PDFs na API de Modelos de Linguagem Grande são:
- A grande maioria das APIs não suporta entrada direta de PDF: A entrada principal do modelo é texto e imagem. PDFs precisam ser pré-processados antes do uso.
- Plataformas de terceiros também não suportam: Plataformas de proxy como a APIYI retransmitem o protocolo original e não podem processar PDFs adicionalmente.
- Escolha entre as 3 soluções conforme a necessidade: PDFs puramente textuais usam extração de texto (mais econômico), PDFs com imagens convertem para imagem para compreensão (mais fiel), e conversas casuais usam o cliente (mais prático).
Não se preocupe em "qual API suporta PDF", mas sim em focar na escolha da solução de pré-processamento correta — essa é a abordagem certa.
Recomenda-se obter créditos gratuitos através da APIYI em apiyi.com, pré-processar o PDF e usar uma única chave API para testar e comparar a invocação de todos os principais modelos, como GPT, Claude, DeepSeek, entre outros.
📚 Referências
-
Documentação do PyMuPDF4LLM: Ferramenta de extração de texto de PDF
- Link:
pymupdf.readthedocs.io/en/latest/pymupdf4llm - Descrição: A ferramenta mais rápida para converter PDF para Markdown, recomendada como primeira opção
- Link:
-
Documentação do pdfplumber: Ferramenta especializada para extração de tabelas
- Link:
github.com/jsvine/pdfplumber - Descrição: A ferramenta com maior precisão para extrair dados de tabelas em PDFs
- Link:
-
Cherry Studio: Cliente de IA de código aberto
- Link:
github.com/CherryHQ/cherry-studio - Descrição: Cliente gratuito que suporta arrastar e soltar PDFs em conversas, pode ser configurado com o APIYI como backend
- Link:
-
Documentação da plataforma APIYI: Acesso unificado a APIs de grandes modelos
- Link:
docs.apiyi.com - Descrição: Obtenção de chave API, lista de modelos e exemplos de invocação
- Link:
Autor: Equipe técnica da APIYI
Discussões técnicas: Bem-vindo para discutir nos comentários, mais materiais disponíveis no centro de documentação da APIYI docs.apiyi.com