저자 주: 개발자가 가장 자주 묻는 질문에 대한 답변: 대규모 언어 모델 API에 PDF를 직접 전달할 수 있을까요? 대부분은 지원하지 않습니다. 본문에서는 텍스트 추출, 이미지 이해, 클라이언트 처리라는 3가지 실용적인 해결책을 상세히 설명합니다.
"대규모 언어 모델 API에 PDF 파일을 그냥 넣을 수 있나요?" — 이는 저희 고객 지원 그룹에서 가장 많이 받는 질문 중 하나입니다. 많은 개발자들이 웹 버전 ChatGPT나 Claude에서 "PDF를 끌어다 놓고 바로 대화하기" 기능에 익숙해져서, API도 그렇게 작동할 거라 생각하곤 합니다.
실제 상황은 이렇습니다: 대부분의 대규모 언어 모델 API는 PDF 파일 직접 입력을 지원하지 않습니다. OpenAI나 Anthropic 같은 주요 업체조차도, API 인터페이스의 핵심 입력 형식은 여전히 텍스트와 이미지입니다 — PDF는 표준 지원 범위에 포함되지 않습니다. 더 중요한 점은, APIYI 같은 제3자 API 중계 플랫폼도 PDF 직접 전송을 지원하지 않는다는 것입니다. 왜냐하면 기본 프로토콜 자체가 지원하지 않기 때문입니다.
하지만 걱정하지 마세요. PDF 처리를 위한 3가지 검증된 해결책이 있습니다. 이 글을 통해 전후 맥락을 명확히 이해하고, 여러분에게 가장 적합한 방법을 선택할 수 있을 겁니다.
핵심 가치: 이 글을 읽고 나면, 대규모 언어 모델 API가 왜 PDF를 지원하지 않는지, 그리고 PDF 입력 요구사항을 효율적으로 해결하기 위한 3가지 전처리 방법은 무엇인지 이해하게 될 것입니다.

대규모 언어 모델 API PDF 입력 핵심 요점
| 요점 | 설명 | 영향 |
|---|---|---|
| API는 PDF를 직접 받지 않음 | GPT, DeepSeek, Llama, Qwen 등 주요 모델 API의 표준 입력은 텍스트와 이미지입니다 | 사전 전처리 과정이 필요합니다 |
| 웹 버전 ≠ API | ChatGPT, Claude 웹 버전의 PDF 업로드는 프론트엔드에서 전처리한 후 API를 호출하는 것입니다 | 웹 경험을 API 능력과 동일시하지 마세요 |
| 제3자 플랫폼도 마찬가지로 지원 안 함 | APIYI 등 중계 플랫폼은 원본 API 프로토콜을 전달하며, 하위 계층이 지원하지 않으면 플랫폼도 지원하지 않습니다 | 중계 플랫폼이 PDF를 추가로 처리해주길 기대하지 마세요 |
| 3가지 전처리 솔루션이 성숙하고 신뢰할 수 있음 | 텍스트화 추출, 이미지 이해, 클라이언트 처리 각각 적합한 시나리오가 있습니다 | "PDF를 지원하는 API"를 찾는 것보다 올바른 솔루션을 선택하는 것이 더 실용적입니다 |
대규모 언어 모델 API가 PDF 입력을 지원하지 않는 이유
많은 개발자들이 궁금해합니다: 웹 버전에서는 분명히 PDF를 업로드할 수 있는데, 왜 API는 안 될까요? 이유는 간단합니다. 웹 버전의 "PDF 업로드" 기능은 모델 자체가 PDF를 처리하는 것이 아니라, 프론트엔드/백엔드가 여러분이 보지 못하는 곳에서 전처리를 수행하기 때문입니다:
- 텍스트 추출: 프론트엔드가 PDF 안의 텍스트를 추출하여 일반 텍스트로 변환한 후 모델에 전달합니다
- 페이지 렌더링: PDF의 각 페이지를 이미지로 렌더링하여 Vision 기능을 통해 모델이 이해하도록 합니다
- RAG 검색: PDF 내용을 벡터화하여 저장하고, 대화 시 관련된 일부만 검색하여 모델에 보냅니다
이러한 전처리 단계는 웹 버전 제품에 캡슐화되어 있어 사용자는 인지하지 못합니다. 하지만 API를 직접 호출할 때는 이 전처리를 여러분이 직접 수행해야 합니다.
대규모 언어 모델 API PDF 지원 현황 빠른 확인
| 모델 | API 직접 전송 PDF | 표준 입력 형식 | PDF 처리 권장 사항 |
|---|---|---|---|
| GPT-4o / GPT-4.1 | 지원 안 함 | 텍스트 + 이미지(Base64) | 먼저 텍스트를 추출하거나 이미지로 변환하세요 |
| Claude | 부분 지원(Beta) | 텍스트 + 이미지 | 여전히 전처리 과정을 거치는 것이 더 안정적입니다 |
| Gemini | 부분 지원 | 텍스트 + 이미지 | 여전히 전처리 과정을 거치는 것이 더 제어하기 쉽습니다 |
| DeepSeek | 지원 안 함 | 순수 텍스트 | 반드시 먼저 텍스트를 추출해야 합니다 |
| Llama / Qwen | 지원 안 함 | 텍스트(일부 이미지 지원) | 반드시 먼저 텍스트를 추출해야 합니다 |
| APIYI 등 제3자 | 지원 안 함 | 원본 프로토콜 전달 | 호출 전에 직접 전처리해야 합니다 |
🎯 중요 설명: Claude와 Gemini의 공식 API 문서에서 PDF 입력 기능을 언급하고 있지만, 이 기능은 호환성과 안정성에 불확실성이 있으며, APIYI와 같은 제3자 중계 플랫폼을 통해 호출할 때는 PDF 직접 전송을 지원하지 않습니다. 우리는 호환성이 가장 좋고 가장 안정적인 전처리 솔루션을 통일적으로 사용할 것을 권장합니다.
대규모 언어 모델 API PDF 처리 솔루션 1: 사전 텍스트화 추출
이것은 가장 보편적이고 비용이 가장 저렴하며 모든 모델과 호환되는 솔루션입니다. 핵심 아이디어: 먼저 Python 라이브러리를 사용하여 PDF를 Markdown이나 일반 텍스트로 변환한 후, 텍스트를 프롬프트로 API에 전달합니다.
PDF 텍스트화 추출 도구 비교
| 도구 | 속도 | 최적 시나리오 | 특징 |
|---|---|---|---|
| PyMuPDF4LLM | ~0.14초/문서 | 일반 텍스트 + 표 추출 | 속도와 품질의 최적 균형, Markdown 출력 |
| pdfplumber | 중간 | 표 데이터 추출 | 좌표 수준의 표 추출 정밀도 높음 |
| Marker-PDF | ~11초/문서 | 복잡한 레이아웃 보존 변환 | 구조 보존이 가장 좋음, 속도가 느림 |
| PyPDF2 | 빠름 | 간단한 순수 텍스트 PDF | 경량, 기본 추출에 적합 |
PDF 텍스트화 추출 코드 예시
다음은 가장 일반적으로 사용되는 솔루션으로, PDF 텍스트를 추출한 후 대규모 언어 모델 API에 전달합니다:
import pymupdf4llm
import openai
# 단계1: PDF를 Markdown으로 변환
md_text = pymupdf4llm.to_markdown("report.pdf")
# 단계2: 일반 텍스트를 임의의 대규모 언어 모델에 전달
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": f"이 보고서의 핵심 요점을 요약해 주세요:\n\n{md_text}"}]
)
print(response.choices[0].message.content)
적용 시나리오: 계약서, 논문, 보고서, 기술 문서 등 텍스트가 주를 이루는 PDF. PDF에 텍스트 레이어가 내장되어 있는 한(스캔본이 아닌) 추출 효과가 좋습니다.
권장 사항: 텍스트화 추출 솔루션은 모든 대규모 언어 모델(GPT, Claude, DeepSeek, Llama, Qwen)과 호환됩니다. APIYI apiyi.com에서 API 키를 획득하면 하나의 키로 모든 모델을 호출하여 비교 테스트할 수 있습니다.
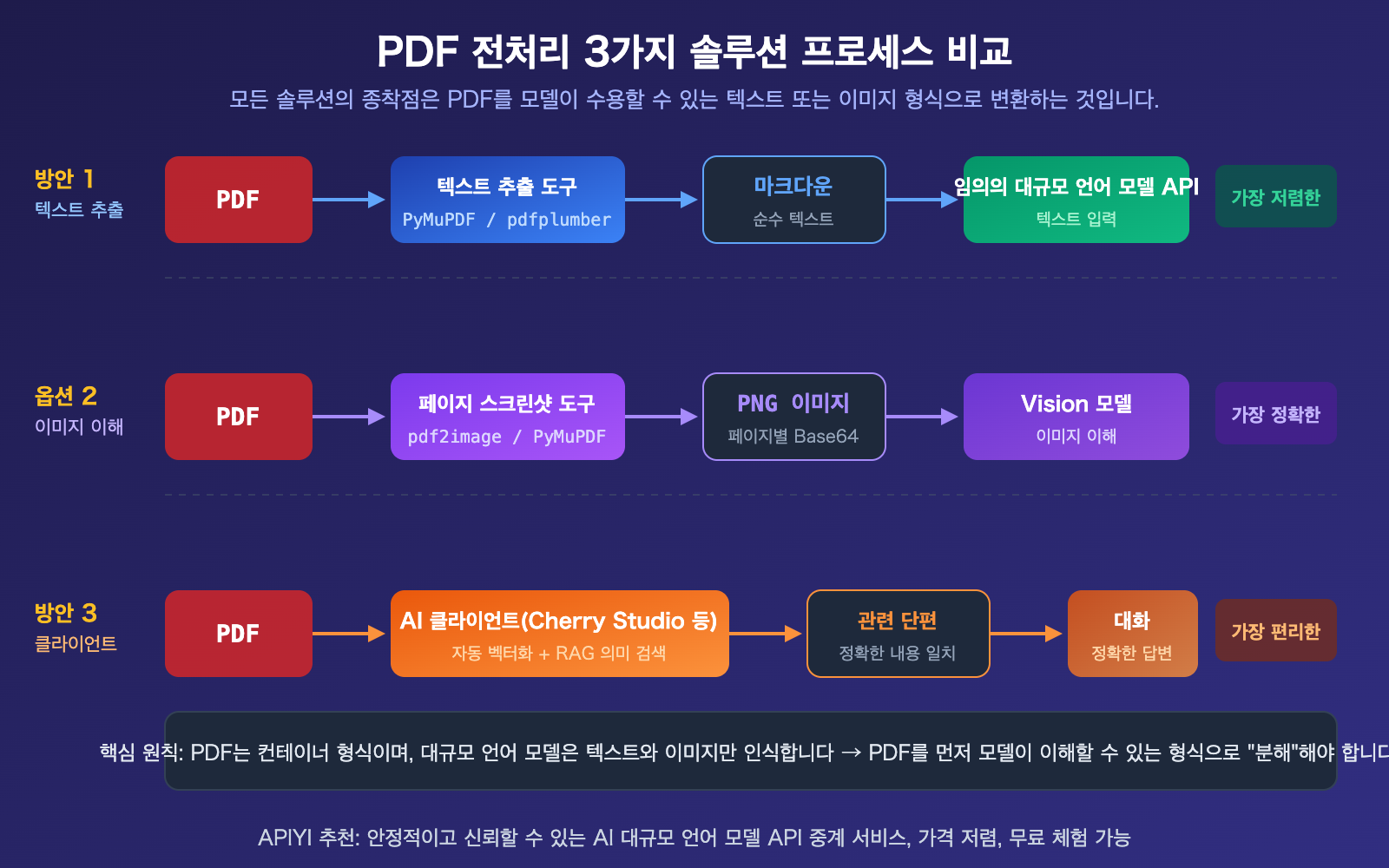
대규모 언어 모델 API PDF 처리 솔루션 2: 이미지 변환 + 시각 이해
PDF에 차트, 스캔본, 복잡한 레이아웃 등 시각 정보가 포함되어 있을 때, 순수 텍스트 추출만으로는 이 내용을 잃어버리게 됩니다. 이럴 때는 PDF의 각 페이지를 이미지로 렌더링한 후, Vision 기능을 지원하는 모델을 통해 이미지를 이해해야 합니다.
PDF를 이미지로 변환하는 코드 예시
import fitz # PyMuPDF
import base64
import openai
# 단계 1: PDF를 페이지별로 PNG 이미지로 변환
doc = fitz.open("report.pdf")
images = []
for page in doc:
pix = page.get_pixmap(dpi=200)
b64 = base64.b64encode(pix.tobytes("png")).decode()
images.append(b64)
전체 코드 보기: Vision API에 이미지 전달
import fitz
import base64
import openai
def pdf_to_vision(pdf_path, question, max_pages=10):
"""PDF를 이미지로 변환 후 Vision API에 전달"""
doc = fitz.open(pdf_path)
# 다중 이미지 메시지 구성 (토큰 초과를 피하기 위해 페이지 수 제어)
content = [{"type": "text", "text": question}]
for i, page in enumerate(doc):
if i >= max_pages:
break
pix = page.get_pixmap(dpi=150)
b64 = base64.b64encode(pix.tobytes("png")).decode()
content.append({
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{b64}"}
})
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": content}]
)
return response.choices[0].message.content
# 사용 예시
result = pdf_to_vision(
"financial_report.pdf",
"이 재무 보고서의 추세 차트를 분석하고 핵심 데이터를 요약해 주세요",
max_pages=5 # 페이지 수 제어, 페이지당 약 765 토큰 소모
)
print(result)
적용 시나리오: 차트가 포함된 연구 보고서, 스캔본, 청구서, 건축 도면 등 시각 정보가 풍부한 PDF.
비용 참고사항: GPT-4o 표준 해상도 기준, 페이지당 이미지는 약 765 토큰을 소모합니다. 10페이지 PDF는 약 7,650 토큰의 이미지 비용이 발생하며, 여기에 텍스트 질문과 답변이 더해져 10,000 토큰을 초과할 수 있습니다. 반드시 페이지 수를 제어하세요.
🎯 비용 관리 팁: 전체 PDF의 모든 페이지를 한 번에 전달하지 마세요. 먼저 솔루션 1로 텍스트를 추출해 대략적으로 살펴보고, 핵심 페이지를 파악한 후 솔루션 2를 사용해 특정 페이지에 대해 이미지 이해를 수행하세요. APIYI apiyi.com의 사용량 패널을 통해 토큰 소모량을 실시간으로 모니터링할 수 있습니다.
대규모 언어 모델 API PDF 처리 솔루션 3: AI 클라이언트 처리
코드를 작성하고 싶지 않고, 일상 대화에서 "PDF 안의 내용을 물어보는" 작업만 필요하다면, AI 클라이언트를 사용하는 것이 가장 간편한 방법입니다.
Cherry Studio 등 클라이언트의 PDF 처리 원리
이러한 클라이언트는 기본적으로 솔루션 1과 2의 작업을 자동으로 대신 수행해 줍니다:
- 자동 벡터화: PDF 내용을 추출한 후 작은 조각으로 나누어 로컬 벡터 데이터베이스에 저장합니다.
- 의미 검색: 사용자가 질문하면, 클라이언트는 가장 관련성 높은 내용 조각을 먼저 검색합니다.
- 정밀 전송: 전체 문서가 아닌, 관련 조각만 대규모 언어 모델 API로 전송합니다.
- 토큰 절약: RAG 검색을 통해 모델에 전송하는 내용량을 크게 줄입니다.
클라이언트로 PDF 처리 시 주의사항
- API 키 설정: 클라이언트에 APIYI apiyi.com의 API 키를 입력하면, 하나의 키로 모든 모델에 접근할 수 있습니다.
- 파일 크기 제어: 매우 큰 PDF(수백 페이지)는 벡터화 시간이 오래 걸리므로, 분할 후 처리하는 것이 좋습니다.
- 토큰 비용 주의: RAG가 내용을 압축하더라도, 긴 문서는 여전히 상당한 비용이 발생할 수 있습니다.
- 적합한 모델 선택: 간단한 질의응답은 저렴한 모델(예: GPT-4o-mini)을, 복잡한 분석은 최상위 모델을 사용하세요.
대규모 언어 모델 API PDF 처리 3가지 방법 비교

| 방법 | 토큰 비용 | 차트 지원 | 개발 난이도 | 모델 호환성 | 최적 시나리오 |
|---|---|---|---|---|---|
| 텍스트 추출 | 최저 (300-1500/페이지) | 미지원 | 중간 | 모든 모델 | 순수 텍스트 PDF, 대량 처리 |
| 이미지 변환 후 이해 | 높음 (~765/페이지) | 완벽 지원 | 중간 | Vision 모델 필요 | 차트, 스캔 문서 |
| 클라이언트 처리 | 중간 (RAG 압축) | 클라이언트에 따라 다름 | 제로 코드 | 모든 모델 | 일상 대화, 비개발자 |
비교 설명: 세 가지 방법은 상호 배타적이지 않으며, 실제 프로젝트에서는 종종 조합해서 사용합니다. 예를 들어 먼저 방법 1로 텍스트를 추출해 대략적인 선별을 하고, 핵심 페이지에 대해 방법 2로 이미지 이해를 적용할 수 있습니다. APIYI apiyi.com을 통해 모든 모델을 통합 접속할 수 있습니다.
자주 묻는 질문
Q1: ChatGPT 웹 버전은 PDF를 업로드할 수 있는데, 왜 API는 지원하지 않나요?
웹 버전의 'PDF 업로드' 기능은 제품 프론트엔드가 전처리(텍스트 추출, 이미지 렌더링, 검색 인덱스 생성)를 대신 수행한 후, 내부 API를 호출하는 방식입니다. API 자체의 핵심 입력 형식은 텍스트와 이미지이며, 복잡한 문서 컨테이너 형식인 PDF는 표준 지원 범위에 포함되지 않습니다. API를 직접 호출할 때는 이러한 전처리 단계를 직접 수행해야 합니다.
Q2: APIYI 같은 제3자 API 중계 서비스가 PDF 처리를 도와줄 수 있나요?
아니요, 불가능합니다. APIYI 같은 중계 플랫폼의 본질은 API 요청을 그대로 전달(Pass-through)하는 것이며, 하위 프로토콜이 PDF를 지원하지 않으면 플랫폼도 처리할 수 없습니다. API를 호출하기 전에 PDF의 전처리(텍스트 추출 또는 이미지 변환)를 직접 완료한 후, 처리된 텍스트나 이미지를 APIYI apiyi.com을 통해 대규모 언어 모델로 전송해야 합니다.
Q3: PDF를 처리할 때 토큰 비용을 어떻게 통제하나요?
몇 가지 실용적인 팁입니다:
- 비용이 가장 저렴한 방법 1(텍스트 추출)을 우선 사용하세요.
- 필요한 페이지만 처리하고, 문서 전체를 한 번에 전송하지 마세요.
- RAG 기술로 분할 및 검색하여, 관련된 부분만 모델에 전송하세요.
- 간단한 질문답변에는 저렴한 모델(GPT-4o-mini)을, 복잡한 분석에는 플래그십 모델을 사용하세요.
- APIYI apiyi.com의 사용량 패널을 통해 실시간으로 소비량을 모니터링하세요.
요약
대규모 언어 모델 API에 PDF를 입력하는 핵심 포인트입니다:
- 대부분의 API는 PDF 직접 입력을 지원하지 않습니다: 대규모 언어 모델의 핵심 입력은 텍스트와 이미지이며, PDF는 전처리 후에야 사용할 수 있습니다.
- 제3자 플랫폼도 마찬가지로 지원하지 않습니다: APIYI 같은 중계 플랫폼은 원본 프로토콜을 그대로 전달하므로, PDF를 추가로 처리할 수 없습니다.
- 3가지 방법을 필요에 따라 선택하세요: 순수 텍스트 PDF는 텍스트 추출(가장 저렴), 이미지 포함 PDF는 이미지 변환 이해(가장 정확), 일상 대화는 클라이언트 사용(가장 편리)
"어떤 API가 PDF를 지원하나"에 집중하기보다, 올바른 전처리 방법을 선택하는 데 집중하세요. 이것이 올바른 접근 방식입니다.
APIYI apiyi.com을 통해 무료 크레딧을 받아 PDF를 전처리한 후, 하나의 API 키로 GPT, Claude, DeepSeek 등 모든 주요 모델을 호출하여 테스트하고 비교해 보는 것을 추천합니다.
📚 참고 자료
-
PyMuPDF4LLM 문서: PDF 텍스트 추출 도구
- 링크:
pymupdf.readthedocs.io/en/latest/pymupdf4llm - 설명: 가장 빠른 PDF to Markdown 변환 도구, 추천 우선순위
- 링크:
-
pdfplumber 문서: 표 추출 전용 도구
- 링크:
github.com/jsvine/pdfplumber - 설명: PDF 내 표 데이터 추출 정확도가 가장 높은 도구
- 링크:
-
Cherry Studio: 오픈소스 AI 클라이언트
- 링크:
github.com/CherryHQ/cherry-studio - 설명: PDF 드래그 앤 드롭 대화를 지원하는 무료 클라이언트, APIYI를 백엔드로 설정 가능
- 링크:
-
APIYI 플랫폼 문서: 주요 대규모 언어 모델 API 통합 접속
- 링크:
docs.apiyi.com - 설명: API 키 획득, 모델 목록 및 호출 예시
- 링크:
작성자: APIYI 기술 팀
기술 교류: 댓글로 토론을 환영합니다. 더 많은 자료는 APIYI docs.apiyi.com 문서 센터에서 확인하세요