Примечание автора: Отвечаем на самый частый вопрос разработчиков: можно ли напрямую передавать PDF в API больших языковых моделей? Ответ: в подавляющем большинстве случаев — нет. В этой статье подробно разбираем три практических подхода: извлечение текста, анализ изображений и обработка на стороне клиента.
"Можно ли просто загрузить PDF-файл прямо в API большой языковой модели?" — это один из самых частых вопросов в нашей группе поддержки. Многие разработчики, привыкнув к функции "перетащи PDF и сразу общайся" в веб-версиях ChatGPT или Claude, думают, что API работает так же.
Реальность такова: Подавляющее большинство API больших языковых моделей не поддерживает прямой ввод PDF-файлов. Даже у лидеров рынка, таких как OpenAI и Anthropic, основным форматом ввода для API остаётся текст и изображения — PDF не входит в стандартный список поддерживаемых форматов. Что ещё важнее, сторонние платформы-прокси вроде APIYI также не поддерживают прямую загрузку PDF, потому что это не предусмотрено базовыми протоколами.
Но не волнуйтесь, для работы с PDF есть три проверенных решения. В этой статье мы разберёмся, почему так происходит, и выберем подход, который лучше всего подойдёт именно вам.
Основная ценность: Прочитав эту статью, вы поймёте, почему API больших языковых моделей не поддерживает PDF напрямую, и как с помощью трёх методов предварительной обработки эффективно решить задачу ввода PDF.

Ключевые моменты по вводу PDF в API больших языковых моделей
| Ключевой момент | Объяснение | Влияние |
|---|---|---|
| API напрямую не принимает PDF | Стандартный ввод для API основных моделей (GPT, DeepSeek, Llama, Qwen и др.) — это текст и изображения | Требуется предварительная обработка |
| Веб-версия ≠ API | Загрузка PDF в веб-интерфейсах ChatGPT, Claude — это препроцессинг на стороне фронтенда/бэкенда перед вызовом API | Не приравнивайте опыт работы в веб-интерфейсе к возможностям API |
| Сторонние платформы также не поддерживают | Прокси-сервисы, такие как APIYI, передают оригинальный API-протокол; если базовый API не поддерживает, то и платформа не поддерживает | Не ожидайте дополнительной обработки PDF от прокси-платформ |
| 3 проверенные схемы предварительной обработки | Извлечение текста, понимание изображений, обработка на стороне клиента — у каждой свои сценарии применения | Выбор правильной схемы практичнее, чем поиск "API с поддержкой PDF" |
Почему API больших языковых моделей не поддерживает ввод PDF
Многие разработчики задаются вопросом: если в веб-версии можно загрузить PDF, почему API этого не умеет? Причина проста — функция "загрузки PDF" в веб-интерфейсе обрабатывается не самой моделью, а фронтендом/бэкендом, который выполняет предварительную обработку незаметно для вас:
- Извлечение текста: Фронтенд извлекает текст из PDF, преобразует его в обычный текст и только потом передаёт модели.
- Рендеринг страниц: Каждая страница PDF рендерится в изображение, и модель понимает его с помощью Vision-возможностей.
- RAG-поиск: Содержимое PDF векторизуется и сохраняется, а при диалоге в модель отправляются только релевантные фрагменты.
Эти шаги предобработки инкапсулированы в веб-продуктах, и пользователь их не замечает. Но при прямом вызове API эту предобработку вам нужно выполнять самостоятельно.
Быстрая справка по поддержке PDF в API больших языковых моделей
| Модель | Прямая передача PDF через API | Стандартный формат ввода | Рекомендация по обработке PDF |
|---|---|---|---|
| GPT-4o / GPT-4.1 | Не поддерживается | Текст + изображения (Base64) | Сначала извлечь текст или преобразовать в изображения |
| Claude | Частичная поддержка (Beta) | Текст + изображения | Для стабильности всё равно рекомендуется схема предобработки |
| Gemini | Частичная поддержка | Текст + изображения | Для управляемости всё равно рекомендуется схема предобработки |
| DeepSeek | Не поддерживается | Простой текст | Обязательно сначала извлечь текст |
| Llama / Qwen | Не поддерживается | Текст (частично поддерживаются изображения) | Обязательно сначала извлечь текст |
| APIYI и другие сторонние | Не поддерживается | Передача оригинального протокола | Необходима самостоятельная предобработка перед вызовом |
🎯 Важное пояснение: Хотя в официальной документации API Claude и Gemini упоминается возможность ввода PDF, эта функция имеет неопределённости в совместимости и стабильности, и при вызове через сторонние прокси-платформы, такие как APIYI, прямая передача PDF не поддерживается. Мы рекомендуем использовать универсальную схему предобработки — она обеспечивает наилучшую совместимость и стабильность.
Схема обработки PDF для API больших языковых моделей №1: Предварительное извлечение текста
Это самая универсальная, наименее затратная и совместимая со всеми моделями схема. Основная идея: сначала с помощью Python-библиотек преобразовать PDF в Markdown или обычный текст, а затем передать этот текст в промпт API.
Сравнение инструментов для извлечения текста из PDF
| Инструмент | Скорость | Лучший сценарий | Особенности |
|---|---|---|---|
| PyMuPDF4LLM | ~0.14с/документ | Извлечение общего текста + таблиц | Оптимальный баланс скорости и качества, вывод в Markdown |
| pdfplumber | Средняя | Извлечение табличных данных | Высокая точность извлечения таблиц на уровне координат |
| Marker-PDF | ~11с/документ | Конвертация со сложной структурой макета | Лучшее сохранение структуры, медленнее |
| PyPDF2 | Быстрая | Простые PDF с чистым текстом | Лёгкий, подходит для базового извлечения |
Пример кода для извлечения текста из PDF
Ниже приведён наиболее распространённый подход: извлечь текст из PDF и передать его в API большой языковой модели:
import pymupdf4llm
import openai
# Шаг 1: Преобразование PDF в Markdown
md_text = pymupdf4llm.to_markdown("report.pdf")
# Шаг 2: Передача обычного текста в любую большую языковую модель
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": f"Пожалуйста, выделите ключевые моменты этого отчёта:\n\n{md_text}"}]
)
print(response.choices[0].message.content)
Сценарии применения: Контракты, научные статьи, отчёты, техническая документация и другие PDF, где преобладает текст. Пока PDF содержит текстовый слой (не сканы), извлечение работает хорошо.
Рекомендация: Схема извлечения текста совместима со всеми большими языковыми моделями — GPT, Claude, DeepSeek, Llama, Qwen. Получите API-ключ на APIYI apiyi.com, один ключ позволяет вызывать все модели для сравнительного тестирования.
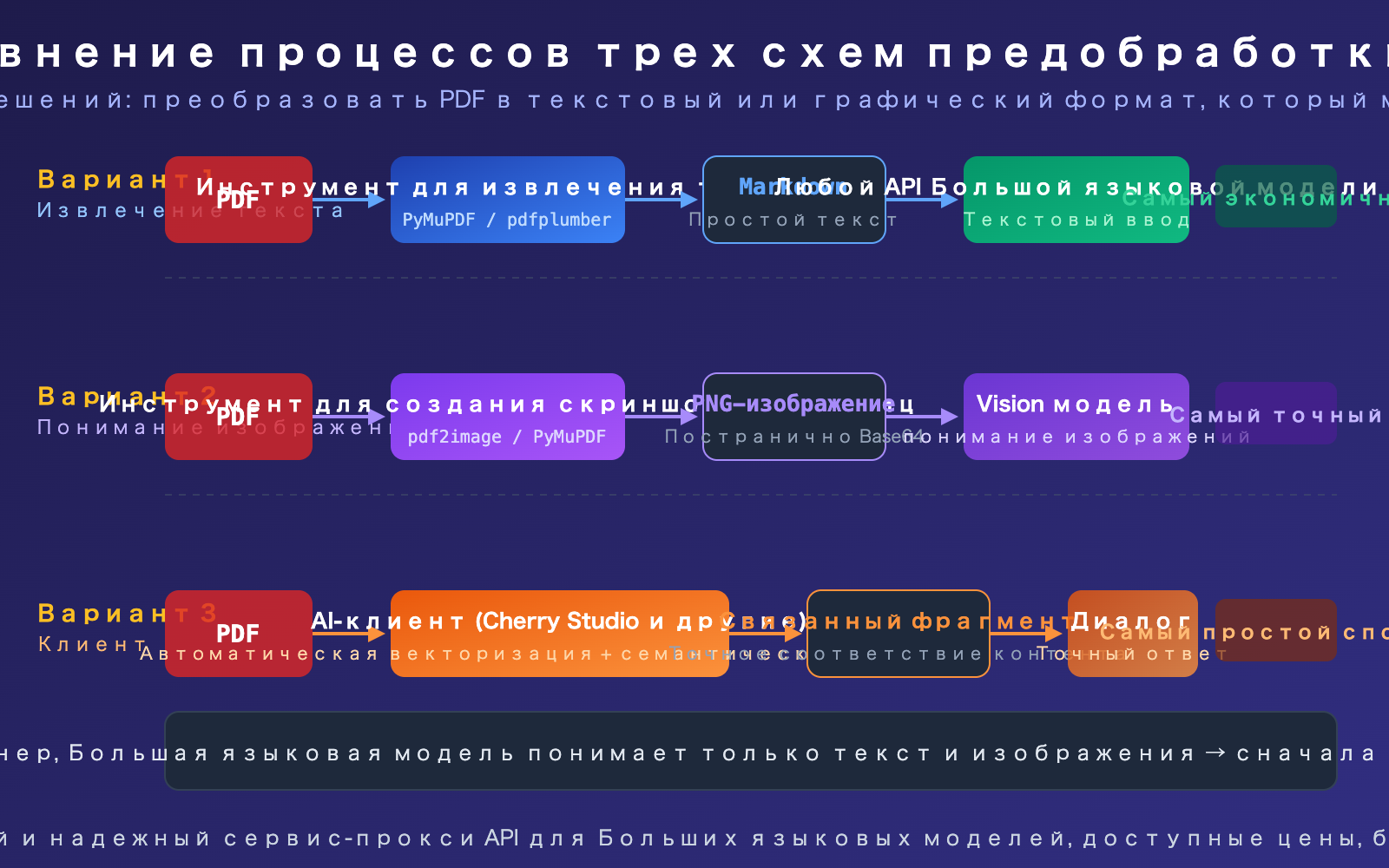
Решение 2 для обработки PDF через API больших языковых моделей: преобразование в изображения + визуальное понимание
Когда PDF содержит визуальную информацию, такую как диаграммы, сканированные документы, сложное форматирование, то извлечение только текста приводит к потере этих данных. В таких случаях необходимо преобразовать каждую страницу PDF в изображение и использовать модель с поддержкой Vision для её анализа.
Пример кода: преобразование PDF в изображения
import fitz # PyMuPDF
import base64
import openai
# Шаг 1: Преобразование PDF в PNG изображения постранично
doc = fitz.open("report.pdf")
images = []
for page in doc:
pix = page.get_pixmap(dpi=200)
b64 = base64.b64encode(pix.tobytes("png")).decode()
images.append(b64)
Посмотреть полный код: передача изображений в Vision API
import fitz
import base64
import openai
def pdf_to_vision(pdf_path, question, max_pages=10):
"""Преобразует PDF в изображения и передаёт их в Vision API"""
doc = fitz.open(pdf_path)
# Формируем сообщение с несколькими изображениями (контролируем количество страниц, чтобы не превысить лимит токенов)
content = [{"type": "text", "text": question}]
for i, page in enumerate(doc):
if i >= max_pages:
break
pix = page.get_pixmap(dpi=150)
b64 = base64.b64encode(pix.tobytes("png")).decode()
content.append({
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{b64}"}
})
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": content}]
)
return response.choices[0].message.content
# Пример использования
result = pdf_to_vision(
"financial_report.pdf",
"Проанализируйте трендовые диаграммы в этом финансовом отчёте и выделите ключевые данные",
max_pages=5 # Контролируем количество страниц, каждая страница расходует примерно 765 токенов
)
print(result)
Когда использовать: PDF с визуально насыщенным контентом: отчёты с диаграммами, сканированные документы, счета-фактуры, архитектурные чертежи.
Важно о стоимости: Каждая страница изображения расходует примерно 765 токенов (стандартное разрешение для GPT-4o). Таким образом, 10-страничный PDF обойдётся примерно в 7 650 токенов только за изображения, плюс токены на вопрос и ответ — итого может превысить 10 000 токенов. Обязательно контролируйте количество страниц.
🎯 Совет по контролю затрат: Не отправляйте все страницы PDF разом. Сначала используйте Решение 1 для извлечения текста и предварительного анализа, чтобы определить ключевые страницы. Затем примените Решение 2 для визуального анализа только этих страниц. На панели мониторинга использования APIYI apiyi.com можно отслеживать расход токенов в реальном времени.
Решение 3 для обработки PDF через API больших языковых моделей: использование AI-клиентов
Если вы не хотите писать код и вам просто нужно "задавать вопросы по содержимому PDF" в повседневной работе, то использование AI-клиентов — самый простой способ.
Как работают PDF-обработчики в клиентах, таких как Cherry Studio
По сути, эти клиенты автоматически выполняют работу из Решения 1 и Решения 2:
- Автоматическая векторизация: Извлекают содержимое PDF, разбивают его на фрагменты и сохраняют в локальную векторную базу данных.
- Семантический поиск: Когда вы задаёте вопрос, клиент сначала находит наиболее релевантные фрагменты.
- Точная отправка: Отправляет модели только эти релевантные фрагменты, а не весь документ целиком.
- Экономия токенов: Использование RAG (Retrieval-Augmented Generation) значительно сокращает объём данных, отправляемых модели.
Что важно учитывать при обработке PDF в клиентах
- Настройка API-ключа: Введите ваш API-ключ от APIYI apiyi.com в настройках клиента. Один ключ даёт доступ ко всем моделям.
- Контроль размера файла: Векторизация очень больших PDF (сотни страниц) может занять много времени. Рекомендуется разбивать их на части.
- Внимание к стоимости токенов: Хотя RAG сжимает контент, работа с длинными документами всё равно может привести к значительным расходам.
- Выбор подходящей модели: Для простых вопросов используйте более доступные модели (например, GPT-4o-mini), для сложного анализа — флагманские модели.
Сравнение 3 подходов к обработке PDF с помощью API больших языковых моделей

| Подход | Стоимость в токенах | Поддержка графиков | Сложность разработки | Совместимость с моделями | Лучший сценарий |
|---|---|---|---|---|---|
| Текстовое извлечение | Самая низкая (300-1500/стр.) | Не поддерживается | Средняя | Все модели | PDF с чистым текстом, большие объёмы |
| Конвертация в изображение + анализ | Высокая (~765/стр.) | Полная поддержка | Средняя | Требуются Vision-модели | Графики, сканированные документы |
| Обработка на стороне клиента | Средняя (сжатие RAG) | Зависит от клиента | Без кода | Все модели | Повседневные диалоги, не для разработки |
Пояснение к сравнению: Три подхода не исключают друг друга, в реальных проектах их часто комбинируют. Например, сначала используют первый подход для извлечения текста и предварительного отбора, а затем для ключевых страниц применяют второй подход с анализом изображений. Через APIYI apiyi.com можно единообразно подключиться ко всем моделям.
Часто задаваемые вопросы
В1: Почему веб-версия ChatGPT позволяет загружать PDF, а API — нет?
Функция "Загрузить PDF" в веб-версии — это результат препроцессинга на стороне продукта: фронтенд извлекает текст, рендерит изображения, строит поисковый индекс, а затем уже вызывает базовый API. Сам API по своей сути принимает на вход текст и изображения, а PDF как сложный формат-контейнер для документов не входит в стандартную поддержку. При вызове API вам нужно самостоятельно выполнить эти шаги предварительной обработки.
В2: Могут ли сторонние платформы-прокси, такие как APIYI, обработать PDF за меня?
Нет. Суть сервисов-прокси API, таких как APIYI, заключается в передаче API-запросов без изменений. Если базовый протокол не поддерживает PDF, то и платформа не может его обработать. Вам необходимо самостоятельно выполнить препроцессинг PDF (извлечь текст или конвертировать в изображения) перед вызовом API, а затем отправить обработанный текст или изображения через APIYI на сайте apiyi.com в большую языковую модель.
В3: Как контролировать стоимость в токенах при обработке PDF?
Несколько практических советов:
- Отдавайте приоритет Схеме 1 (текстовое извлечение) — это самый дешёвый вариант.
- Обрабатывайте только нужные страницы, не загружайте весь документ целиком.
- Используйте технологию RAG для разделения на фрагменты и поиска, отправляя модели только релевантные части.
- Для простых вопросов используйте более дешёвые модели (например, GPT-4o-mini), для сложного анализа — флагманские.
- Отслеживайте расход в реальном времени через панель использования на APIYI apiyi.com.
Итог
Ключевые моменты по вводу PDF в API больших языковых моделей:
- Подавляющее большинство API не поддерживает прямой ввод PDF: Основной вход для больших моделей — это текст и изображения, PDF требует предварительной обработки.
- Сторонние платформы также не поддерживают: Сервисы-прокси API, такие как APIYI, передают исходный протокол и не могут дополнительно обрабатывать PDF.
- Выбирайте 1 из 3 схем по необходимости: PDF с чистым текстом — текстовое извлечение (самое экономичное), PDF с изображениями — конвертация в картинки для понимания (самое точное), повседневные диалоги — через клиент (самое простое).
Не стоит зацикливаться на вопросе "какой API поддерживает PDF". Гораздо продуктивнее сосредоточиться на выборе правильной схемы предобработки — это и есть верный подход.
Рекомендуем получить бесплатные лимиты через APIYI на сайте apiyi.com, предобработать PDF и с одним API-ключом протестировать и сравнить вызовы всех основных моделей, таких как GPT, Claude, DeepSeek.
📚 Справочные материалы
-
Документация PyMuPDF4LLM: Инструмент для извлечения текста из PDF
- Ссылка:
pymupdf.readthedocs.io/en/latest/pymupdf4llm - Описание: Самый быстрый инструмент для конвертации PDF в Markdown, рекомендуется как основной выбор
- Ссылка:
-
Документация pdfplumber: Специализированный инструмент для извлечения таблиц
- Ссылка:
github.com/jsvine/pdfplumber - Описание: Инструмент с наивысшей точностью извлечения табличных данных из PDF
- Ссылка:
-
Cherry Studio: Открытый AI-клиент
- Ссылка:
github.com/CherryHQ/cherry-studio - Описание: Бесплатный клиент с поддержкой перетаскивания PDF в диалог, можно настроить APIYI в качестве бэкенда
- Ссылка:
-
Документация платформы APIYI: Единый доступ к API крупных моделей
- Ссылка:
docs.apiyi.com - Описание: Получение API-ключей, список моделей и примеры вызовов
- Ссылка:
Автор: Техническая команда APIYI
Технические обсуждения: Приглашаем к обсуждению в комментариях. Больше материалов доступно в документации APIYI по адресу docs.apiyi.com