Autorennotiz: Beantwortung der am häufigsten gestellten Frage von Entwicklern: Können große Sprachmodelle PDFs direkt verarbeiten? Die Antwort ist: Die meisten unterstützen es nicht. Dieser Artikel erläutert drei praktische Lösungen: Textextraktion, Bildverständnis und Client-seitige Verarbeitung.
"Kann ich PDF-Dateien direkt an die API eines großen Sprachmodells senden?" – das ist eine der am häufigsten gestellten Fragen in unseren Support-Chats. Viele Entwickler sind es gewohnt, in der Webversion von ChatGPT oder Claude PDFs einfach per Drag & Drop einzufügen und direkt darüber zu chatten, und nehmen daher an, dass die API genauso funktioniert.
Die Realität sieht jedoch anders aus: Die überwiegende Mehrheit der APIs für große Sprachmodelle unterstützt keine direkte Eingabe von PDF-Dateien. Selbst führende Anbieter wie OpenAI und Anthropic erwarten bei ihren API-Schnittstellen im Kern Text- und Bildformate – PDF gehört nicht zum Standard-Support. Noch wichtiger: Auch Drittanbieter-API-Proxy-Dienste wie APIYI unterstützen keinen direkten PDF-Upload, da das zugrundeliegende Protokoll dies nicht vorsieht.
Aber keine Sorge, es gibt drei bewährte Lösungen für die PDF-Verarbeitung. Dieser Artikel erklärt Ihnen die Hintergründe und hilft Ihnen, die für Sie passende Methode auszuwählen.
Kernaussage: Nach dem Lesen dieses Artikels verstehen Sie, warum APIs für große Sprachmodelle PDFs nicht direkt unterstützen, und wie Sie mit drei Vorverarbeitungsansätzen PDF-Eingaben effizient umsetzen können.

Kernpunkte zur PDF-Eingabe bei APIs für große Sprachmodelle
| Kernpunkt | Erläuterung | Auswirkung |
|---|---|---|
| API akzeptiert PDF nicht direkt | Standardeingabe für APIs von GPT, DeepSeek, Llama, Qwen und anderen gängigen Modellen ist Text und Bilder | Vorverarbeitungsschritt erforderlich |
| Webversion ≠ API | Das PDF-Upload in ChatGPT, Claude usw. ist eine Frontend-Vorverarbeitung vor dem API-Aufruf | Web-Erfahrung nicht mit API-Fähigkeiten gleichsetzen |
| Drittplattformen unterstützen es ebenfalls nicht | Plattformen wie APIYI leiten das originale API-Protokoll durch, wenn die zugrundeliegende API PDF nicht unterstützt, tut es die Plattform auch nicht | Keine zusätzliche PDF-Verarbeitung durch Proxy-Dienste erwarten |
| 3 bewährte Vorverarbeitungsansätze | Textextraktion, Bildverständnis und Client-seitige Verarbeitung haben jeweils ihre Anwendungsfälle | Den richtigen Ansatz zu wählen ist praktikabler als eine "PDF-fähige API" zu suchen |
Warum APIs für große Sprachmodelle keine PDF-Eingabe unterstützen
Viele Entwickler fragen sich: Warum kann die Webversion PDFs hochladen, die API aber nicht? Der Grund ist einfach – die Funktion "PDF hochladen" in der Webversion wird nicht vom Modell selbst verarbeitet, sondern von Frontend/Backend, die im Hintergrund Vorverarbeitung durchführen:
- Textextraktion: Das Frontend extrahiert den Text aus dem PDF, wandelt ihn in reinen Text um und sendet ihn dann an das Modell.
- Seitenrendering: Jede PDF-Seite wird als Bild gerendert, das Modell versteht es über seine Vision-Fähigkeiten.
- RAG-Retrieval: Der PDF-Inhalt wird vektorisiert gespeichert, bei der Konversation werden nur relevante Teile an das Modell gesendet.
Diese Vorverarbeitungsschritte sind in Webprodukten gekapselt und für den Nutzer unsichtbar. Wenn Sie jedoch direkt die API aufrufen, müssen Sie diese Vorverarbeitung selbst durchführen.
Schnellübersicht: PDF-Unterstützung bei APIs für große Sprachmodelle
| Modell | API-Direktübergabe von PDF | Standard-Eingabeformat | Empfehlung zur PDF-Verarbeitung |
|---|---|---|---|
| GPT-4o / GPT-4.1 | Nicht unterstützt | Text + Bilder (Base64) | Zuerst Text extrahieren oder in Bilder umwandeln |
| Claude | Teilweise unterstützt (Beta) | Text + Bilder | Für mehr Stabilität trotzdem Vorverarbeitungsweg empfehlenswert |
| Gemini | Teilweise unterstützt | Text + Bilder | Für mehr Kontrolle trotzdem Vorverarbeitungsweg empfehlenswert |
| DeepSeek | Nicht unterstützt | Reiner Text | Text muss zuerst extrahiert werden |
| Llama / Qwen | Nicht unterstützt | Text (teilweise Bilder unterstützt) | Text muss zuerst extrahiert werden |
| APIYI u.a. Drittanbieter | Nicht unterstützt | Leitet Originalprotokoll durch | Vorverarbeitung muss vor dem Aufruf selbst durchgeführt werden |
🎯 Wichtiger Hinweis: Obwohl die offizielle API-Dokumentation von Claude und Gemini PDF-Eingabefunktionen erwähnt, gibt es hierbei Ungewissheiten bezüglich Kompatibilität und Stabilität. Zudem wird die direkte PDF-Übergabe bei Aufrufen über Drittplattformen wie APIYI nicht unterstützt. Wir empfehlen einheitlich den Vorverarbeitungsansatz – er bietet die beste Kompatibilität und Stabilität.
Ansatz 1 für die PDF-Verarbeitung mit APIs für große Sprachmodelle: Vorverarbeitung durch Textextraktion
Dies ist der universellste, kostengünstigste und mit allen Modellen kompatible Ansatz. Kernidee: Zuerst das PDF mit einer Python-Bibliothek in Markdown oder reinen Text umwandeln, dann den Text als Eingabeaufforderung an die API senden.
Vergleich von Tools zur PDF-Textextraktion
| Tool | Geschwindigkeit | Bestes Anwendungsszenario | Besonderheiten |
|---|---|---|---|
| PyMuPDF4LLM | ~0,14s/Dokument | Allgemeine Textextraktion + Tabellenextraktion | Bestes Gleichgewicht aus Geschwindigkeit und Qualität, gibt Markdown aus |
| pdfplumber | Mittel | Extraktion von Tabellendaten | Hohe Präzision bei koordinatenbasierter Tabellenextraktion |
| Marker-PDF | ~11s/Dokument | Treue Konvertierung komplexer Layouts | Beste Strukturerhaltung, langsamer |
| PyPDF2 | Schnell | Einfache PDFs mit reinem Text | Leichtgewichtig, geeignet für Basisextraktion |
Codebeispiel für PDF-Textextraktion
Hier ist der gängigste Ansatz: PDF-Text extrahieren und an die API für große Sprachmodelle senden:
import pymupdf4llm
import openai
# Schritt 1: PDF in Markdown umwandeln
md_text = pymupdf4llm.to_markdown("report.pdf")
# Schritt 2: Reinen Text an ein beliebiges großes Sprachmodell senden
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": f"Bitte fassen Sie die Kernpunkte dieses Berichts zusammen:\n\n{md_text}"}]
)
print(response.choices[0].message.content)
Anwendungsszenarien: Verträge, wissenschaftliche Arbeiten, Berichte, technische Dokumente usw. – also PDFs, die hauptsächlich aus Text bestehen. Solange das PDF eine Textebene eingebettet hat (kein gescanntes Dokument), ist der Extraktionseffekt gut.
Empfehlung: Der Ansatz der Textextraktion ist mit allen großen Sprachmodellen kompatibel – GPT, Claude, DeepSeek, Llama, Qwen können alle verwendet werden. Holen Sie sich über APIYI apiyi.com einen API-Schlüssel, mit einem Schlüssel können Sie alle Modelle für Vergleichstests aufrufen.
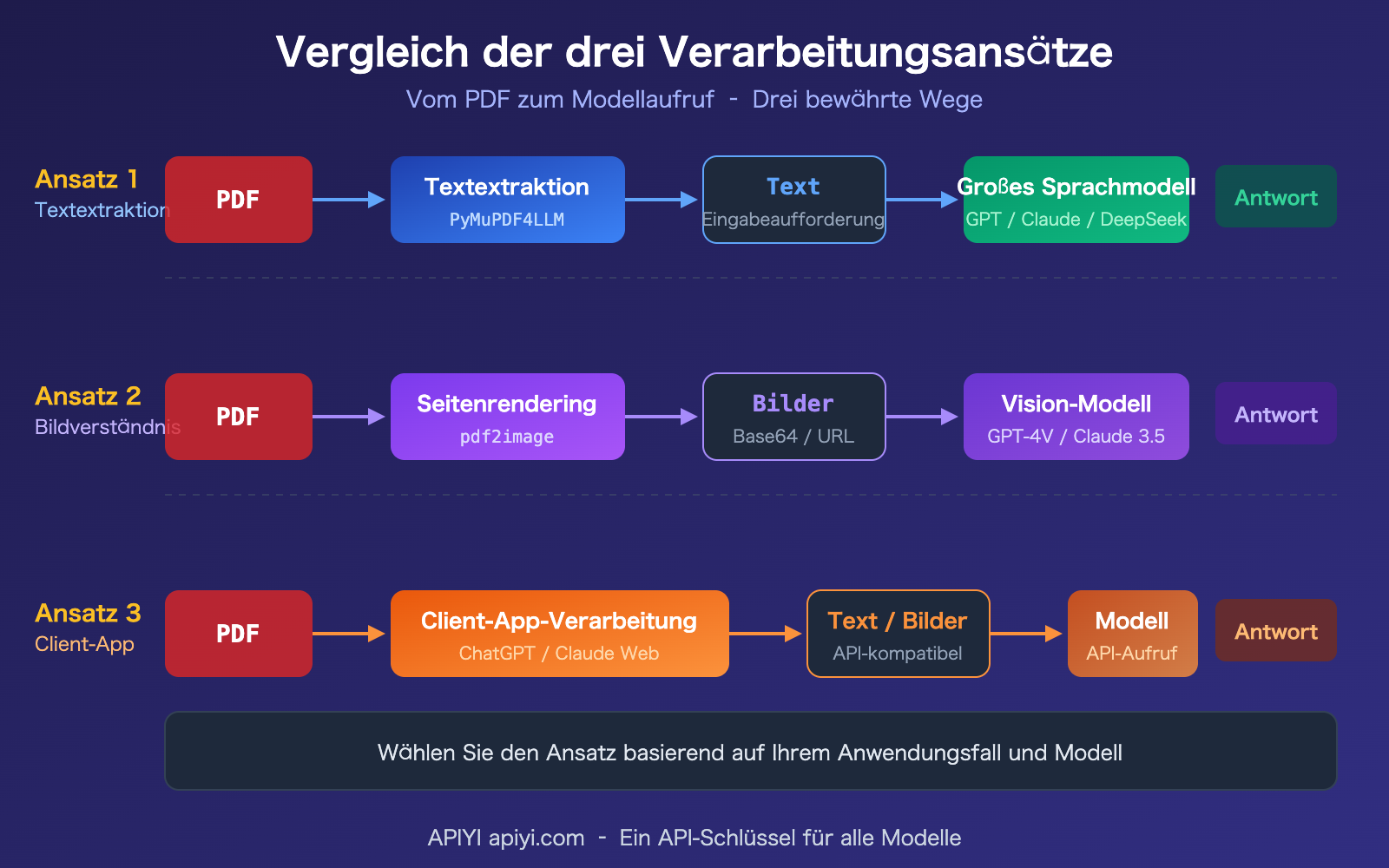
Großes Sprachmodell API PDF-Verarbeitungslösung 2: Konvertierung in Bilder + visuelles Verständnis
Wenn ein PDF Diagramme, gescannte Dokumente, komplexe Layouts oder andere visuelle Informationen enthält, gehen diese bei einer reinen Textextraktion verloren. In diesem Fall muss jede PDF-Seite in ein Bild gerendert und durch ein Modell mit Vision-Fähigkeiten analysiert werden.
Codebeispiel: PDF in Bilder umwandeln
import fitz # PyMuPDF
import base64
import openai
# Schritt 1: PDF seitenweise in PNG-Bilder umwandeln
doc = fitz.open("report.pdf")
images = []
for page in doc:
pix = page.get_pixmap(dpi=200)
b64 = base64.b64encode(pix.tobytes("png")).decode()
images.append(b64)
Vollständigen Code anzeigen: Bilder an Vision API senden
import fitz
import base64
import openai
def pdf_to_vision(pdf_path, question, max_pages=10):
"""PDF in Bilder umwandeln und an Vision API senden"""
doc = fitz.open(pdf_path)
# Multimodale Nachricht mit Bildern erstellen (Seitenzahl kontrollieren, um Token-Limit zu vermeiden)
content = [{"type": "text", "text": question}]
for i, page in enumerate(doc):
if i >= max_pages:
break
pix = page.get_pixmap(dpi=150)
b64 = base64.b64encode(pix.tobytes("png")).decode()
content.append({
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{b64}"}
})
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": content}]
)
return response.choices[0].message.content
# Verwendungsbeispiel
result = pdf_to_vision(
"financial_report.pdf",
"Analysieren Sie die Trenddiagramme in diesem Finanzbericht und fassen Sie die Kernzahlen zusammen",
max_pages=5 # Seitenzahl kontrollieren, jede Seite verbraucht ca. 765 Tokens
)
print(result)
Einsatzszenarien: Berichte mit Diagrammen, gescannte Dokumente, Rechnungen, Architekturzeichnungen und andere PDFs mit vielen visuellen Informationen.
Kostenhinweis: Jede Bildseite verbraucht etwa 765 Tokens (GPT-4o Standardauflösung). Ein 10-seitiges PDF bedeutet also etwa 7.650 Tokens für die Bilder, plus Textfrage und Antwort, was leicht über 10.000 Tokens gehen kann. Kontrollieren Sie unbedingt die Seitenzahl.
🎯 Kostenkontroll-Tipp: Senden Sie nicht alle Seiten eines PDFs auf einmal. Verwenden Sie zuerst Lösung 1 für eine grobe Textextraktion, um die relevanten Seiten zu identifizieren, und dann Lösung 2 für die Bildanalyse dieser spezifischen Seiten. Über das Nutzungs-Dashboard von APIYI apiyi.com können Sie den Token-Verbrauch in Echtzeit überwachen.
Großes Sprachmodell API PDF-Verarbeitungslösung 3: Verarbeitung durch AI-Clients
Wenn Sie keinen Code schreiben möchten und nur im Alltag "Fragen zum Inhalt eines PDFs" stellen wollen, ist die Verwendung eines AI-Clients der einfachste Weg.
Funktionsweise von PDF-Verarbeitung in Clients wie Cherry Studio
Diese Clients erledigen im Wesentlichen automatisch die Arbeit von Lösung 1 und 2 für Sie:
- Automatische Vektorisierung: Der PDF-Inhalt wird extrahiert, in kleine Abschnitte zerlegt und in einer lokalen Vektordatenbank gespeichert.
- Semantische Suche: Bei Ihrer Frage durchsucht der Client zuerst die relevantesten Inhaltsfragmente.
- Präzises Senden: Nur die relevanten Fragmente (nicht das gesamte Dokument) werden an die Großes Sprachmodell API gesendet.
- Token-Einsparung: Durch RAG-basierte Suche wird die an das Modell gesendete Inhaltsmenge erheblich reduziert.
Wichtige Hinweise zur PDF-Verarbeitung in Clients
- API-Schlüssel konfigurieren: Tragen Sie Ihren API-Schlüssel von APIYI apiyi.com in den Client ein, um mit einem einzigen Schlüssel Zugriff auf alle Modelle zu erhalten.
- Dateigröße kontrollieren: Die Vektorisierung sehr großer PDFs (hunderte Seiten) kann lange dauern. Es empfiehlt sich, sie vorab aufzuteilen.
- Token-Kosten beachten: Auch wenn RAG den Inhalt komprimiert, können lange Dokumente immer noch zu höheren Kosten führen.
- Passendes Modell wählen: Für einfache Fragen können günstigere Modelle (wie GPT-4o-mini) verwendet werden, für komplexe Analysen sollten Sie auf Flaggschiff-Modelle zurückgreifen.
Vergleich von 3 Ansätzen zur PDF-Verarbeitung mit Großes Sprachmodell-APIs

| Ansatz | Token-Kosten | Diagramm-Unterstützung | Entwicklungsaufwand | Modellkompatibilität | Bestes Anwendungsszenario |
|---|---|---|---|---|---|
| Textbasierte Extraktion | Niedrigste (300-1500/Seite) | Nicht unterstützt | Mittel | Alle Modelle | Reine Text-PDFs, große Mengen |
| Bildkonvertierung & -analyse | Höher (~765/Seite) | Vollständige Unterstützung | Mittel | Benötigt Vision-Modelle | Diagramme, gescannte Dokumente |
| Client-seitige Verarbeitung | Mittel (RAG-Kompression) | Abhängig vom Client | Kein Code | Alle Modelle | Alltagsdialoge, Nicht-Entwickler |
Vergleichshinweis: Die drei Ansätze schließen sich nicht gegenseitig aus, in realen Projekten werden sie oft kombiniert. Zum Beispiel: Zuerst Ansatz 1 für Text-Extraktion und Grobfilterung, dann für Schlüsselseiten Ansatz 2 zur Bildanalyse. Über APIYI apiyi.com können Sie alle Modelle einheitlich einbinden.
Häufig gestellte Fragen
F1: Warum kann die ChatGPT-Webversion PDFs hochladen, aber die API unterstützt das nicht?
Die Funktion "PDF hochladen" in der Webversion ist ein Produkt-Frontend, das für Sie Vorverarbeitung durchführt – Textextraktion, Bildrendering, Erstellung eines Suchindex – und dann die zugrunde liegende API aufruft. Das Kern-Eingabeformat der API selbst ist Text und Bilder. PDF als komplexes Dokumentencontainerformat gehört nicht zum Standard-Support. Wenn Sie die API aufrufen, müssen Sie diese Vorverarbeitungsschritte selbst durchführen.
F2: Können Drittanbieter-API-Proxy-Dienste wie APIYI mir bei der PDF-Verarbeitung helfen?
Nein. API-Proxy-Dienste wie APIYI leiten im Wesentlichen API-Anfragen durch. Wenn das zugrunde liegende Protokoll PDF nicht unterstützt, kann die Plattform es auch nicht verarbeiten. Sie müssen die Vorverarbeitung der PDF (Textextraktion oder Konvertierung in Bilder) vor dem API-Aufruf selbst durchführen und dann den verarbeiteten Text oder die Bilder über APIYI (apiyi.com) an das Große Sprachmodell senden.
F3: Wie kann ich die Token-Kosten bei der PDF-Verarbeitung kontrollieren?
Einige praktische Tipps:
- Priorisieren Sie Methode 1 (Textextraktion), sie ist am kostengünstigsten
- Verarbeiten Sie nur benötigte Seiten, nicht das gesamte Dokument auf einmal
- Verwenden Sie RAG-Technologie zur Segmentierung und Suche, senden Sie nur relevante Abschnitte an das Modell
- Verwenden Sie für einfache Fragen kostengünstige Modelle (z.B. GPT-4o-mini), für komplexe Analysen Flaggschiff-Modelle
- Überwachen Sie den Verbrauch in Echtzeit über das Nutzungs-Dashboard von APIYI (apiyi.com)
Zusammenfassung
Die Kernpunkte für die PDF-Eingabe in Großes-Sprachmodell-APIs:
- Die überwiegende Mehrheit der APIs unterstützt keine direkte PDF-Eingabe: Die Kerneingabe eines Großen Sprachmodells ist Text und Bilder, PDFs müssen vorverarbeitet werden.
- Drittanbieter-Plattformen unterstützen es ebenfalls nicht: API-Proxy-Dienste wie APIYI leiten das ursprüngliche Protokoll durch und können PDFs nicht zusätzlich verarbeiten.
- 3 Methoden je nach Bedarf wählen: Reine Text-PDFs mit Textextraktion (am günstigsten), PDFs mit Bildern in Bilder konvertieren (am originalgetreuesten), Alltagsdialoge mit dem Client (am einfachsten).
Machen Sie sich nicht zu viele Gedanken darüber, "welche API PDF unterstützt", sondern konzentrieren Sie sich darauf, die richtige Vorverarbeitungsmethode zu wählen – das ist der richtige Ansatz.
Empfehlung: Holen Sie sich über APIYI (apiyi.com) kostenloses Guthaben, verarbeiten Sie Ihr PDF vor und testen und vergleichen Sie dann mit einem einzigen API-Schlüssel alle gängigen Modelle wie GPT, Claude, DeepSeek.
📚 Referenzmaterial
-
PyMuPDF4LLM Dokumentation: PDF-Text-Extraktionswerkzeug
- Link:
pymupdf.readthedocs.io/en/latest/pymupdf4llm - Beschreibung: Das schnellste Werkzeug für die PDF-zu-Markdown-Konvertierung, erste Wahl empfohlen
- Link:
-
pdfplumber Dokumentation: Spezialwerkzeug für Tabellenextraktion
- Link:
github.com/jsvine/pdfplumber - Beschreibung: Das Werkzeug mit der höchsten Genauigkeit für die Extraktion von Tabellendaten aus PDFs
- Link:
-
Cherry Studio: Open-Source-AI-Client
- Link:
github.com/CherryHQ/cherry-studio - Beschreibung: Kostenloser Client mit PDF-Drag-and-Drop-Funktionalität für Konversationen, kann mit APIYI als Backend konfiguriert werden
- Link:
-
APIYI Plattformdokumentation: Einheitlicher Zugang zu großen Modell-APIs
- Link:
docs.apiyi.com - Beschreibung: API-Schlüssel-Beschaffung, Modellliste und Aufrufbeispiele
- Link:
Autor: APIYI Technikteam
Technischer Austausch: Diskussionen in den Kommentaren willkommen. Weitere Ressourcen finden Sie im APIYI Dokumentationszentrum unter docs.apiyi.com