Nota do autor: Análise profunda das capacidades principais, benchmarks de desempenho e métodos de integração via API dos modelos MiniMax-M2.7 e M2.7-highspeed, ajudando desenvolvedores a obter capacidades de IA de nível premium com custo extremamente baixo.
A MiniMax lançou em 18 de março de 2026 o Modelo de Linguagem Grande premium MiniMax-M2.7, o primeiro modelo de IA que participa profundamente do seu próprio processo de evolução. Com apenas 10B de parâmetros ativos, ele alcançou um desempenho de Tier-1 equivalente ao Claude Opus 4.6 e ao GPT-5, mantendo um preço 50 vezes menor que os modelos premium convencionais. A versão MiniMax-M2.7-highspeed, lançada simultaneamente, aumenta a velocidade de saída em 66%, atingindo 100 tps.
Valor central: Através de dados de benchmark reais e tutoriais de integração, ajudamos você a decidir se o MiniMax-M2.7 é a escolha de modelo premium com o melhor custo-benefício atualmente.

Pontos principais do MiniMax-M2.7
| Ponto | Descrição | Valor |
|---|---|---|
| 230B total / 10B ativos | Arquitetura de especialistas mistos esparsos (MoE), ativa apenas 10B de parâmetros por inferência | Desempenho premium + custo de inferência baixíssimo |
| Treinamento de autoevolução recursiva | O modelo executa autonomamente 100+ rodadas de iteração para otimizar seu próprio fluxo de treinamento | Aumento de 30% no desempenho sem intervenção humana |
| SWE-bench 78% | Benchmark de engenharia de software significativamente à frente dos 55% do Opus 4.6 | Primeira escolha para tarefas de programação e engenharia |
| Preço 1/50 do Opus | $0,30/M de entrada, $1,20/M de tokens de saída | Queda drástica nos custos de implantação em escala empresarial |
Detalhes da arquitetura técnica do MiniMax-M2.7
O MiniMax-M2.7 utiliza uma arquitetura Transformer de especialistas mistos esparsos (Sparse Mixture-of-Experts), com um total de 230B de parâmetros, mas ativando apenas 10B por token. Esse design torna o M2.7 o modelo de menor volume em seu nível de desempenho — alcançando um desempenho de Tier-1 equivalente ao Claude Opus 4.6 e ao GPT-5 com o mínimo de recursos computacionais.
A janela de contexto chega a 205K tokens (aprox. 307 páginas de documentos A4), suportando cenários como análise de documentos longos e compreensão de grandes bases de código. Na avaliação do Artificial Analysis Intelligence Index, o M2.7 ficou em primeiro lugar entre 136 modelos da mesma categoria com uma pontuação máxima de 50.
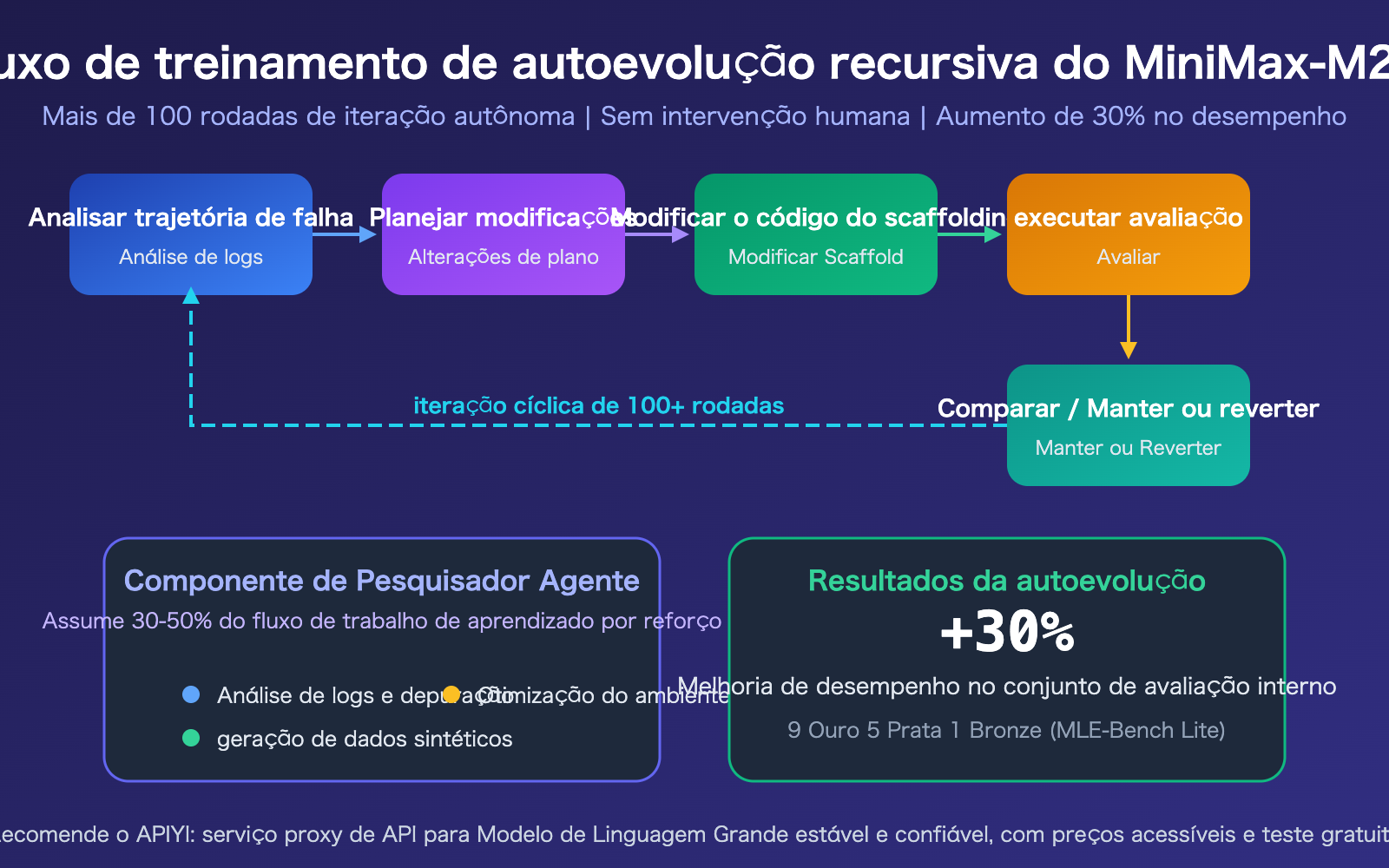
Mecanismo de autoevolução recursiva do MiniMax-M2.7
A "autoevolução recursiva" é o destaque técnico mais inovador do M2.7. Durante o treinamento, o modelo executa autonomamente um ciclo de iteração completo: análise de trajetórias de falha → planejamento de modificações → alteração do código de suporte ao treinamento → execução de avaliação → comparação de resultados → decisão de manter ou reverter. Esse processo foi executado de forma totalmente autônoma por mais de 100 rodadas.
Seu componente central, o "Pesquisador Agêntico" (Agentic Researcher), assumiu 30-50% do fluxo de trabalho de aprendizado por reforço, incluindo análise de logs e depuração, geração de dados sintéticos e otimização do ambiente de treinamento. O resultado final foi um aumento de 30% no desempenho sem qualquer intervenção humana.
Benchmarks de desempenho e comparação do MiniMax-M2.7
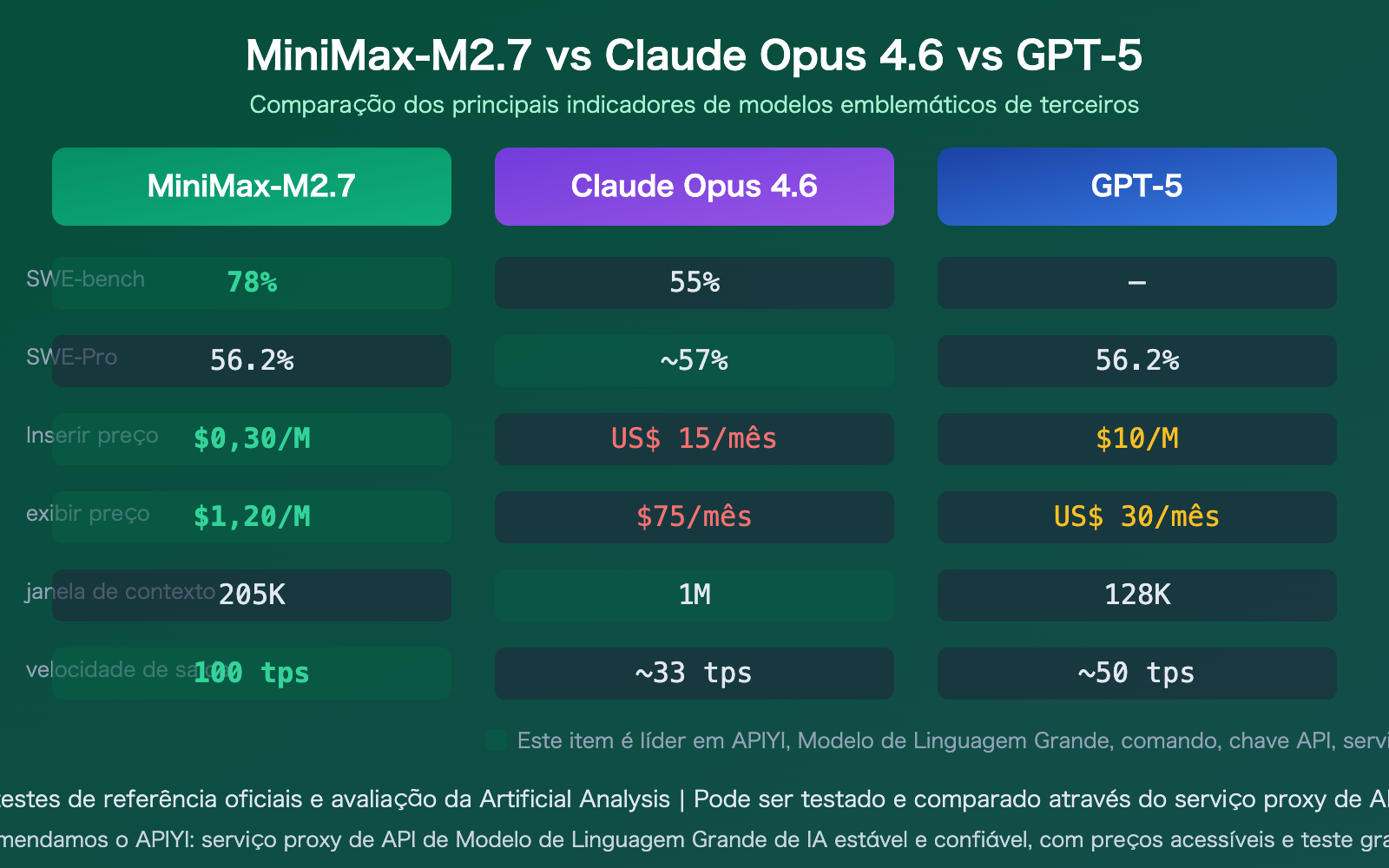
Resultados dos testes de benchmark do MiniMax-M2.7
| Benchmark | Pontuação M2.7 | Claude Opus 4.6 | Série GPT-5 | Observações |
|---|---|---|---|---|
| SWE-bench Verified | 78% | 55% | — | Prática de engenharia de software, liderança significativa |
| SWE-Pro | 56.2% | ~57% | 56.2% (Codex) | Nível próximo aos modelos topo de linha |
| VIBE-Pro | 55.6% | — | — | Entrega de projetos ponta a ponta |
| Terminal Bench 2 | 57.0% | — | — | Sistemas de engenharia complexos |
| MLE-Bench Lite | 66.6% | 75.7% | 71.2% (5.4) | Competições de ML, 9 ouros, 5 pratas, 1 bronze |
| GDPval-AA ELO | 1495 | — | — | Líder em produtividade de escritório |
Comparação de preços do MiniMax-M2.7
A estratégia de preços do M2.7 é extremamente agressiva; com um desempenho praticamente equivalente, o custo é apenas uma fração dos principais modelos do mercado:
| Métrica | MiniMax-M2.7 | Claude Opus 4.6 | GPT-5 | Diferença de custo |
|---|---|---|---|---|
| Preço de entrada | $0.30/M | $15/M | $10/M | 50x / 33x mais barato |
| Preço de saída | $1.20/M | $75/M | $30/M | 62x / 25x mais barato |
| Janela de contexto | 205K | 1M | 128K | Entre os dois |
| Parâmetros ativos | 10B | — | — | O menor modelo Tier-1 |
🎯 Sugestão de escolha: O MiniMax-M2.7 tem um desempenho excelente em tarefas de programação e engenharia, com um custo-benefício altíssimo. Recomendamos testar a integração rapidamente através da plataforma APIYI (apiyi.com), que suporta a invocação do modelo via interface unificada para o MiniMax-M2.7 e M2.7-highspeed, facilitando a comparação prática com outros modelos de ponta.
Detalhes da versão de alta velocidade: MiniMax-M2.7-highspeed
O MiniMax-M2.7-highspeed é uma versão otimizada da série principal M2.7, entregando resultados idênticos aos da versão padrão — ambos possuem o mesmo nível de inteligência, mas a versão highspeed foi projetada especificamente para cenários de aplicação sensíveis à latência.
Principais vantagens do MiniMax-M2.7-highspeed
- Velocidade de saída: Atinge 100 tokens/s, um aumento de 66% em relação à versão padrão
- Latência sub-segundo: Tempo de resposta do primeiro token otimizado, ideal para interações em tempo real
- Arquitetura de inferência aprimorada: O motor de inferência subjacente foi otimizado, não se tratando apenas de uma redução por quantização
- Consistência de resultados: Produz resultados exatamente iguais aos da versão padrão, sem sacrificar a inteligência
Cenários de aplicação para o MiniMax-M2.7-highspeed
| Cenário | Descrição | Por que escolher a versão highspeed? |
|---|---|---|
| Assistente de programação interativo | Autocompletar e refatoração de código em tempo real na IDE | Resposta sub-segundo que melhora a experiência de codificação |
| Loop de agentes em tempo real | Execução de raciocínio em múltiplas etapas no Agent Loop | Reduz o tempo de espera por etapa, acelerando o fluxo geral |
| Pipelines corporativos de alto throughput | Processamento em lote de documentos e extração de dados | 100 tps reduz drasticamente o tempo de conclusão |
| Sistemas de atendimento ao cliente online | Diálogos e resolução de dúvidas em tempo real | Resposta rápida e imperceptível para o usuário |
Sugestão: Se a sua aplicação exige rigorosamente alta velocidade de resposta, o MiniMax-M2.7-highspeed é uma das opções mais rápidas entre os modelos de nível topo de linha atualmente. Você pode invocar este modelo diretamente através da APIYI (apiyi.com).
Guia de Início Rápido da API MiniMax-M2.7
Exemplo Minimalista
Abaixo está o código mais simples para invocar o MiniMax-M2.7 através da plataforma APIYI, funcionando com apenas 10 linhas:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="MiniMax-M2.7",
messages=[{"role": "user", "content": "Analise os gargalos de desempenho deste código e dê sugestões de otimização"}]
)
print(response.choices[0].message.content)
Ver código de implementação completo (incluindo alternância para a versão highspeed)
import openai
from typing import Optional
def call_minimax_m27(
prompt: str,
model: str = "MiniMax-M2.7",
system_prompt: Optional[str] = None,
max_tokens: int = 2000,
use_highspeed: bool = False
) -> str:
"""
Invoca o MiniMax-M2.7 ou M2.7-highspeed
Args:
prompt: Entrada do usuário
model: Nome do modelo
system_prompt: Comando de sistema
max_tokens: Número máximo de tokens de saída
use_highspeed: Se deve usar a versão highspeed
"""
if use_highspeed:
model = "MiniMax-M2.7-highspeed"
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
response = client.chat.completions.create(
model=model,
messages=messages,
max_tokens=max_tokens
)
return response.choices[0].message.content
# Chamada da versão padrão
result = call_minimax_m27(
prompt="Implemente um cache LRU eficiente em Python",
system_prompt="Você é um engenheiro Python sênior"
)
# Chamada da versão highspeed (ideal para cenários em tempo real)
fast_result = call_minimax_m27(
prompt="Explique rapidamente a função deste código",
use_highspeed=True
)
Dica: Obtenha créditos de teste gratuitos através da APIYI (apiyi.com) para verificar rapidamente o desempenho do MiniMax-M2.7 no seu cenário de negócio. A plataforma suporta a alternância entre a versão padrão e a highspeed com um clique.
Comparação do MiniMax-M2.7 com Modelos Concorrentes
| Solução | Características Principais | Cenários Aplicáveis | Custo-Benefício |
|---|---|---|---|
| MiniMax-M2.7 | 10B parâmetros ativos, 78% no SWE-bench | Programação, fluxos de trabalho de Agentes, implantação em larga escala | Altíssimo ($0.30/$1.20) |
| M2.7-highspeed | 100 tps, 66% de aumento de velocidade | Interação em tempo real, integração com IDE, Loop de Agentes | Altíssimo + Rápido |
| Claude Opus 4.6 | 1M de janela de contexto, melhor capacidade abrangente | Documentos longos, raciocínio complexo, tarefas versáteis | Médio ($15/$75) |
| GPT-5 | Ecossistema maduro, suporte multimodal | Cenários gerais, aplicações multimodais | Médio ($10/$30) |
Nota de comparação: Os dados acima são provenientes de testes de referência oficiais e avaliações de terceiros da Artificial Analysis, podendo ser verificados na prática através da plataforma APIYI (apiyi.com).
Perguntas Frequentes
Q1: Existe diferença nos resultados entre o MiniMax-M2.7 e o M2.7-highspeed?
As saídas são exatamente as mesmas. A versão highspeed utiliza um motor de inferência otimizado para alcançar uma velocidade de geração de tokens mais rápida (100 tps), mas isso não altera o nível de inteligência ou a qualidade da saída do modelo. Se o seu cenário não for sensível à latência, a versão padrão é suficiente.
Q2: A “autoevolução recursiva” do MiniMax-M2.7 significa que o modelo mudará continuamente?
Não. A autoevolução recursiva é uma técnica utilizada pela MiniMax durante a fase de treinamento — o modelo iterou e otimizou autonomamente o processo de treinamento e os parâmetros. Uma vez publicado, os pesos do modelo são fixos. A API que você invoca fornecerá saídas estáveis e consistentes.
Q3: Como começar a testar o MiniMax-M2.7 rapidamente?
Recomendamos utilizar uma plataforma de agregação de API que suporte múltiplos modelos para realizar os testes:
- Acesse a APIYI em apiyi.com para registrar uma conta
- Obtenha sua chave API e créditos gratuitos
- Utilize os exemplos de código deste artigo para uma verificação rápida
- Basta alternar o parâmetro model para trocar entre a versão padrão e a versão highspeed
Resumo
Pontos principais sobre a invocação do modelo MiniMax-M2.7 via API:
- Custo-benefício extremo: Com 10B de parâmetros ativos, alcança um desempenho de Tier-1 com um custo de apenas 1/50 do Opus, sendo a escolha ideal para implantações em larga escala.
- Capacidade de programação excepcional: Com 78% no SWE-bench Verified, supera significativamente os concorrentes, apresentando um desempenho excelente em tarefas de engenharia de software.
- Versão highspeed: A velocidade de saída de 100 tps é ideal para interações em tempo real e cenários de ciclos de agentes, mantendo o mesmo nível de inteligência da versão padrão.
Para desenvolvedores e usuários corporativos que buscam o melhor custo-benefício, o MiniMax-M2.7 é um dos modelos emblemáticos mais dignos de atenção no mercado atual.
Recomendamos verificar os resultados rapidamente através da APIYI em apiyi.com, que oferece créditos gratuitos e uma interface unificada para múltiplos modelos, permitindo a alternância rápida entre as versões padrão e highspeed do MiniMax-M2.7.
📚 Referências
-
Lançamento oficial do MiniMax M2.7: Detalhes sobre a arquitetura do modelo e tecnologia de autoevolução
- Link:
minimax.io/news/minimax-m27-en - Descrição: Blog técnico oficial, contendo benchmarks e detalhes da arquitetura.
- Link:
-
Página do modelo MiniMax M2.7: Especificações técnicas e documentação da API
- Link:
minimax.io/models/text/m27 - Descrição: Parâmetros do modelo, precificação e métodos de acesso.
- Link:
-
Avaliação da Artificial Analysis: Avaliação de desempenho independente de terceiros
- Link:
artificialanalysis.ai/models/minimax-m2-7 - Descrição: Dados independentes de avaliação de velocidade e índice de inteligência.
- Link:
-
Documentação da plataforma APIYI: Acesso rápido ao MiniMax-M2.7
- Link:
docs.apiyi.com - Descrição: Obtenção de chave API, lista de modelos e exemplos de invocação do modelo.
- Link:
Autor: Equipe técnica da APIYI
Troca de conhecimentos: Sinta-se à vontade para discutir na seção de comentários. Para mais materiais, visite a central de documentação da APIYI em docs.apiyi.com.