A série Grok 4.20 Beta da xAI foi oficialmente lançada na plataforma APIYI — trazendo 4 novos modelos de uma só vez, cobrindo desde respostas rápidas até pesquisas profundas com múltiplos agentes. Com preços de $2 por milhão de tokens de entrada e $6 por milhão de tokens de saída, esta é uma das opções com melhor custo-benefício entre os principais modelos de ponta atuais.
Estes 4 modelos não são apenas incrementos de versão, mas sim diferenças estruturais: alguns focam em resposta ultrarrápida, outros em raciocínio profundo, e há um que permite que 4 agentes de IA colaborem simultaneamente — reduzindo a taxa de alucinação em 65%.
Valor central: Ao ler este artigo, você entenderá o posicionamento e os melhores cenários de uso de cada um dos 4 modelos Grok 4.20 Beta, aprenderá como realizar a invocação do modelo e tomará a melhor decisão de escolha.
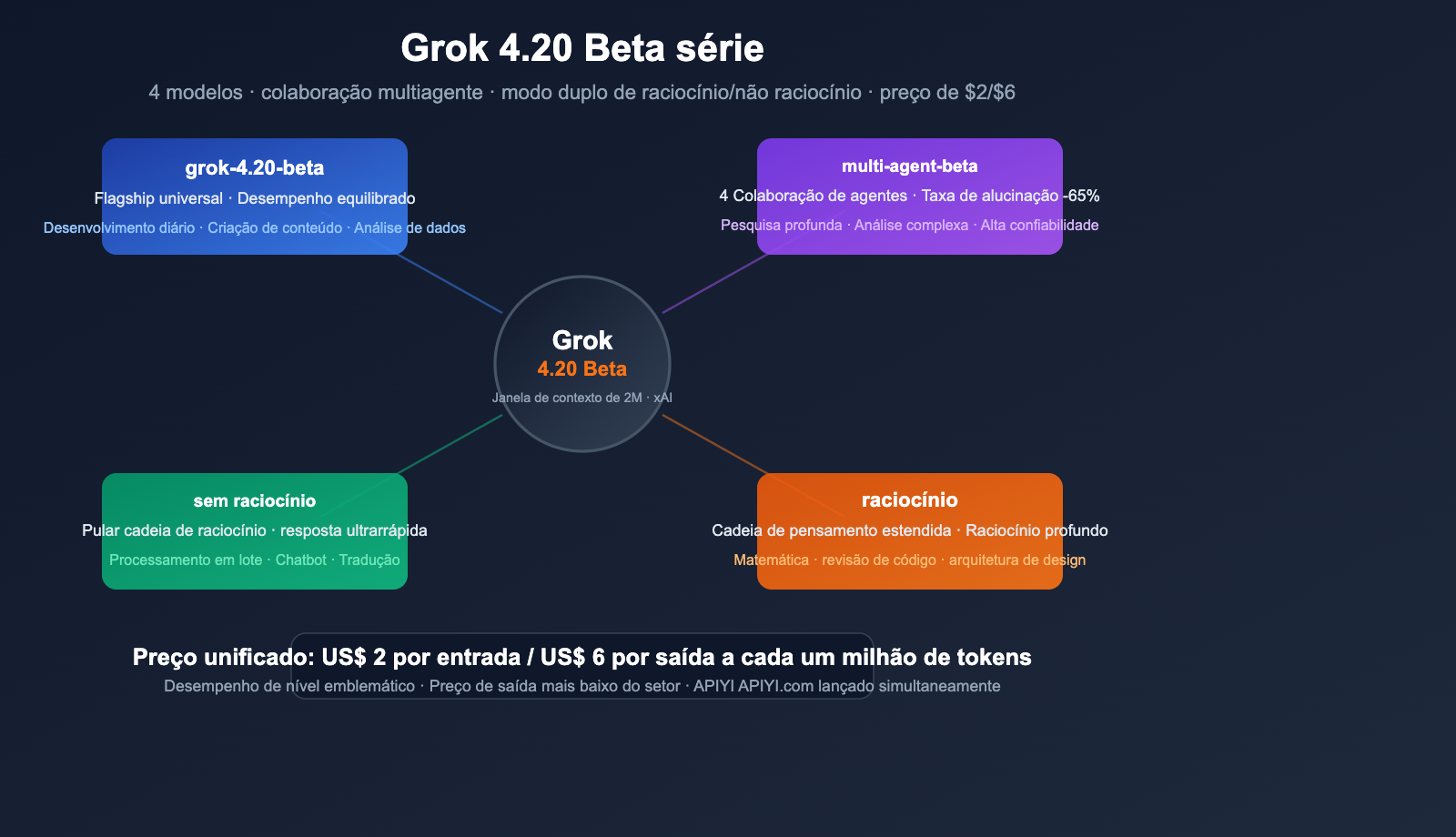
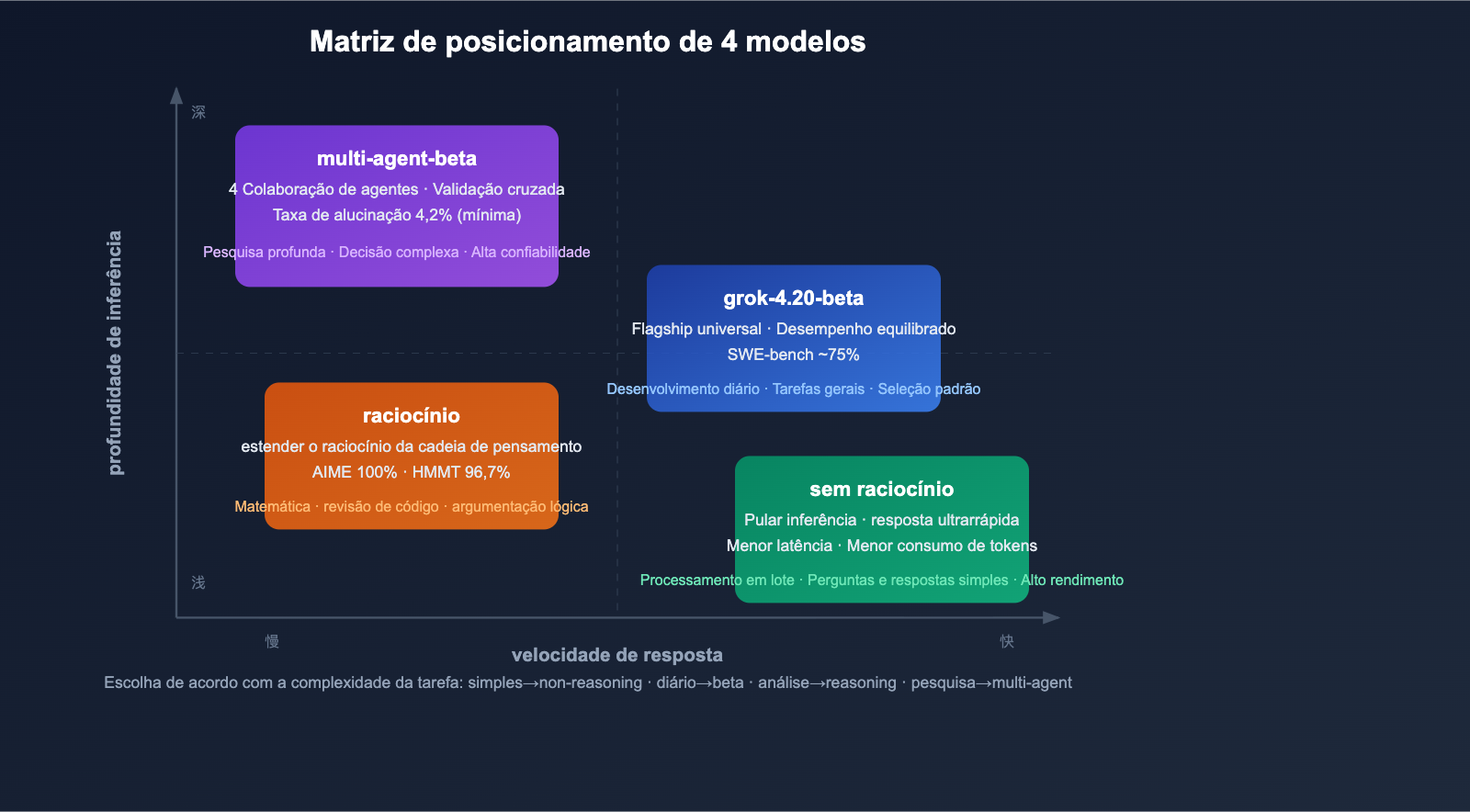
Visão geral dos 4 modelos: consulta rápida de diferenças principais
Matriz de modelos
| ID do Modelo | Posicionamento | Característica Principal | Melhor Cenário |
|---|---|---|---|
grok-4.20-beta |
Flagship Geral | Equilíbrio entre desempenho e velocidade | Desenvolvimento diário, tarefas gerais |
grok-4.20-multi-agent-beta-0309 |
Colaboração Multi-Agente | 4 Agentes trabalhando em paralelo | Pesquisa profunda, análise complexa |
grok-4.20-beta-0309-non-reasoning |
Resposta Rápida | Pula a cadeia de raciocínio, baixa latência | Processamento em lote, perguntas simples |
grok-4.20-beta-0309-reasoning |
Raciocínio Profundo | Cadeia de pensamento estendida | Matemática, análise de código, lógica |
Preços unificados
| Item de cobrança | Preço |
|---|---|
| Token de entrada | $2.00 / milhão de tokens |
| Token de saída | $6.00 / milhão de tokens |
| Janela de contexto | 2 milhões de tokens (2M) |
| Desconto em lote | 50% |
Comparação de preços com concorrentes:
| Modelo | Preço de entrada | Preço de saída | Custo-benefício |
|---|---|---|---|
| Grok 4.20 Beta | $2.00 | $6.00 | 🟢 Melhor |
| Gemini 3.1 Pro | $2.00 | $12.00 | Bom |
| GPT-5.4 | $2.50 | $15.00 | Regular |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Regular |
| Claude Opus 4.6 | $15.00 | $75.00 | Alto |
O preço de saída do Grok 4.20 é apenas 40% do Claude Sonnet 4.6 e 8% do Claude Opus 4.6. Para tarefas intensivas de saída (geração de código, textos longos), a vantagem de custo é extremamente significativa.
🎯 Nota sobre preços: A série Grok 4.20 Beta lançada na APIYI (apiyi.com) tem os mesmos preços do site oficial da xAI ($2 entrada / $6 saída), com descontos aplicados através das promoções de recarga da plataforma. Uma única chave API permite invocar mais de 200 modelos, incluindo Grok, Claude e GPT.
Análise profunda de 4 modelos
Modelo 1: grok-4.20-beta (Flagship Geral)
Esta é a porta de entrada padrão da série Grok 4.20, equilibrando desempenho, velocidade e custo.
Principais características:
- Herda todas as capacidades da família Grok 4
- Janela de contexto de 2 milhões de tokens — a maior entre os modelos de ponta ocidentais
- Suporte para entrada de imagens (JPG/PNG)
- Melhorias contínuas semanais baseadas em feedback do mundo real
Desempenho de referência:
- SWE-bench: ~75% (próximo aos 74,9% do GPT-5)
- GPQA (nível de pós-graduação): 88,4%
- Arena Elo: ~1.505-1.535
Cenários de uso: Assistência de programação diária, criação de conteúdo, análise de dados, conversação geral.
import openai
client = openai.OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://api.apiyi.com/v1" # Interface unificada APIYI
)
response = client.chat.completions.create(
model="grok-4.20-beta",
messages=[
{"role": "user", "content": "Implemente um cache LRU em Python"}
]
)
print(response.choices[0].message.content)
Modelo 2: grok-4.20-multi-agent-beta-0309 (Multiagente)
Esta é a variante mais inovadora do Grok 4.20 — 4 agentes de IA colaborando simultaneamente para processar sua solicitação.
Os 4 agentes e suas funções:
| Agente | Papel | Especialidade |
|---|---|---|
| Grok (Líder) | Coordenador | Decomposição de tarefas, gestão de fluxo, agregação de resultados |
| Harper | Pesquisador | Busca de dados em tempo real, verificação de fatos (acesso a dados do X/Twitter) |
| Benjamin | Analista | Raciocínio lógico, cálculos matemáticos, análise de código |
| Lucas | Desafiador | Síntese criativa, posição de oposição embutida — questiona as conclusões dos outros agentes |
Fluxo de trabalho:
Pergunta do usuário
↓
Grok decompõe a tarefa → distribui para os 4 agentes
↓
Harper coleta dados | Benjamin analisa lógica | Lucas desafia e questiona
↓
Debate interno entre agentes + validação cruzada
↓
Grok agrega o consenso → retorna a resposta final
Destaque principal — redução de 65% na taxa de alucinação:
| Métrica | Linha de base (modelo único) | Modo Multiagente | Melhoria |
|---|---|---|---|
| Taxa de alucinação | ~12% | ~4,2% | Redução de 65% |
| Taxa de "dizer que não sabe quando incerto" | — | 78% | A mais alta da indústria |
A "posição de oposição embutida" do Lucas é um design fundamental: o trabalho dele é encontrar falhas nas conclusões dos outros agentes. Essa colaboração adversarial torna o resultado final muito mais confiável.
Cenários de uso: Relatórios de pesquisa profunda, análise de decisões complexas, resultados que exigem alta confiabilidade.
response = client.chat.completions.create(
model="grok-4.20-multi-agent-beta-0309",
messages=[
{"role": "user", "content": "Analise o cenário competitivo e as tendências do mercado de ferramentas de programação com IA em 2026"}
]
)
Modelo 3: grok-4.20-beta-0309-non-reasoning (Não-Raciocínio)
Esta é a variante otimizada para velocidade e throughput. Ele ignora a cadeia de pensamento (Chain-of-Thought) interna e gera a resposta diretamente.
Principais características:
- Baixa latência, alto throughput
- Não gera tokens de raciocínio interno, economizando custos de saída
- Ideal para tarefas simples e diretas
Cenários de uso:
- Chamadas de API de alta frequência (processamento de dados em lote)
- Chatbots / Sistemas de atendimento ao cliente
- Classificação de conteúdo, extração de tags
- Autocompletar código simples
- Tradução, resumos
Não recomendado para: Deduções matemáticas complexas, análise lógica de várias etapas, design de arquitetura que exija pensamento profundo.
response = client.chat.completions.create(
model="grok-4.20-beta-0309-non-reasoning",
messages=[
{"role": "user", "content": "Converta o seguinte JSON para o formato CSV: ..."}
]
)
Modelo 4: grok-4.20-beta-0309-reasoning (Raciocínio)
Esta é a variante de raciocínio profundo, oposta à versão de não-raciocínio. Ela ativa a cadeia de pensamento estendida (Extended Chain-of-Thought), realizando um raciocínio interno aprofundado antes de responder.
Principais características:
- Tokens de raciocínio estendidos para análise profunda de problemas
- Desempenho excelente em tarefas matemáticas e lógicas (AIME 2025: 100%, HMMT25: 96,7%)
- Índice de inteligência da Artificial Analysis: 48
Cenários de uso:
- Provas e deduções matemáticas
- Revisão de código e análise de bugs
- Trade-offs de design de arquitetura
- Argumentação lógica complexa
- Análise de artigos acadêmicos
response = client.chat.completions.create(
model="grok-4.20-beta-0309-reasoning",
messages=[
{"role": "user", "content": "Analise possíveis condições de corrida e riscos de deadlock neste código concorrente"}
]
)
💡 Dica de seleção: Para a maioria das tarefas diárias, o
grok-4.20-betaé suficiente. Use a versão multiagente para resultados de alta confiabilidade, a versão de não-raciocínio para processamento em lote e a versão de raciocínio para análises complexas. Com a APIYI (apiyi.com), você pode acessar todos os 4 modelos com uma única chave e alternar conforme a necessidade.
Árvore de Decisão para Seleção de Modelos
Seleção por Tipo de Tarefa
| Tipo de Tarefa | Modelo Recomendado | Motivo |
|---|---|---|
| Assistência em programação | grok-4.20-beta |
Equilíbrio entre desempenho e custo |
| Processamento de dados em lote | non-reasoning |
Maior velocidade, menor latência |
| Revisão de código/Análise de bugs | reasoning |
Requer raciocínio profundo |
| Escrita de relatórios de pesquisa | multi-agent |
Verificação cruzada por 4 agentes |
| Análise de dados em tempo real | multi-agent |
Harper integrado a dados do X em tempo real |
| Dedução matemática/lógica | reasoning |
100% de pontuação máxima no AIME |
| Chatbot | non-reasoning |
Resposta rápida com baixa latência |
| Tradução/Resumo de conteúdo | non-reasoning |
Tarefas simples sem necessidade de raciocínio |
| Projetos de arquitetura | reasoning ou multi-agent |
Requer análise de trade-offs |
Seleção por Sensibilidade a Custos
Economia máxima → non-reasoning (sem tokens de raciocínio, saída mínima)
↓
Custo-benefício diário → grok-4.20-beta (equilíbrio geral)
↓
Qualidade em primeiro lugar → reasoning (raciocínio profundo, mais tokens de saída)
↓
Máxima confiabilidade → multi-agent (4 agentes, saída mais detalhada)
🚀 Início rápido: Recomendamos começar com o
grok-4.20-beta. Registre-se via APIYI (apiyi.com) para obter sua chave API; o preço é o mesmo do site oficial da xAI ($2 de entrada / $6 de saída), com descontos aplicados em promoções de recarga.
Comparativo: Grok 4.20 vs Modelos Principais
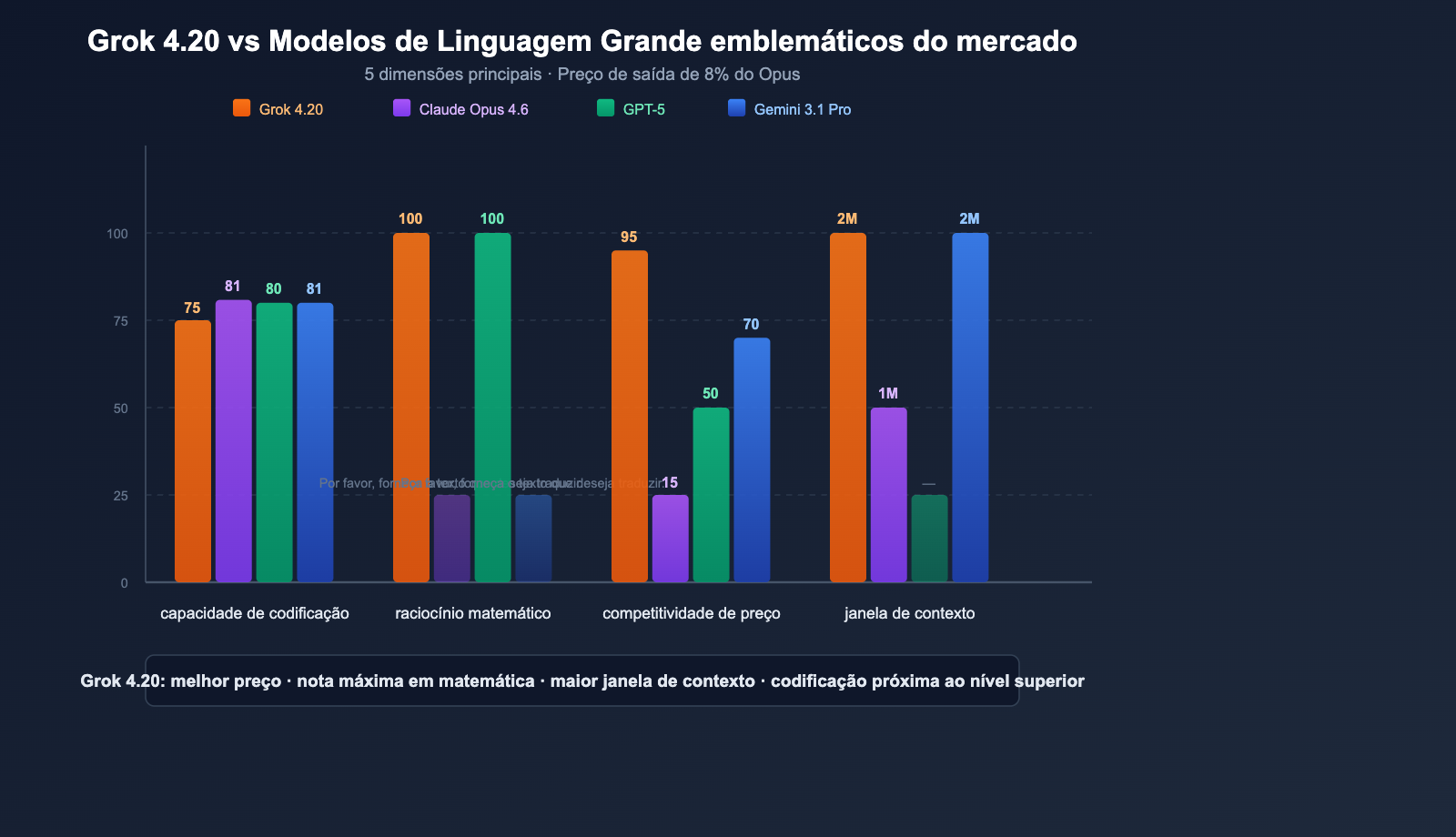
Comparativo Completo
| Dimensão | Grok 4.20 Beta | Claude Opus 4.6 | Série GPT-5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench | ~75% | 81.4% | ~80% | ~80.6% |
| Matemática (AIME) | 100% | — | 100% | — |
| GPQA | 88.4% | — | — | — |
| Contexto | 2 milhões | 1 milhão | Variável | 2 milhões |
| Preço entrada | $2 | $15 | $2.50 | $2 |
| Preço saída | $6 | $75 | $15 | $12 |
| Multi-agente | ✅ 4 Agentes | ❌ | ❌ | ❌ |
| Dados em tempo real | ✅ X/Twitter | ❌ | ✅ Busca | ✅ Busca |
| Controle de alucinação | 4.2% (mínimo) | Baixo | Baixo | Médio |
| Entrada de imagem | ✅ JPG/PNG | ✅ Vários | ✅ Vários | ✅ Vários |
Melhores cenários por modelo
- Grok 4.20: Uso geral com custo-benefício, pesquisa profunda (multi-agente), análise de dados em tempo real.
- Claude Opus 4.6: Engenharia de software (maior pontuação no SWE-bench), saídas longas (128K), segurança corporativa.
- GPT-5: Matemática, automação de desktop, maior ecossistema de usuários.
- Gemini 3.1 Pro: Integração com ecossistema Google, 2 milhões de contexto, custo moderado.
💰 Análise de custo-benefício: O preço de saída do Grok 4.20 ($6/MTok) é apenas 8% do valor do Claude Opus 4.6 ($75/MTok). Para tarefas intensivas em saída (geração de códigos longos, relatórios de pesquisa), usar o Grok 4.20 pode reduzir custos em mais de 90%. Através da APIYI (apiyi.com), você pode acessar toda a linha de modelos Grok, Claude e GPT, alternando conforme a necessidade da tarefa.
Prática de invocação de API
Exemplo de invocação básica
import openai
client = openai.OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://api.apiyi.com/v1" # Interface unificada da APIYI
)
# Tarefa geral → Versão básica
response = client.chat.completions.create(
model="grok-4.20-beta",
messages=[
{"role": "system", "content": "Você é um desenvolvedor Python experiente."},
{"role": "user", "content": "Implemente uma fila de tarefas assíncronas"}
],
max_tokens=4096
)
print(response.choices[0].message.content)
Seleção automática de modelo baseada na tarefa
def choose_grok_model(task_type):
"""Seleciona automaticamente o melhor modelo Grok com base no tipo de tarefa"""
model_map = {
"quick": "grok-4.20-beta-0309-non-reasoning",
"general": "grok-4.20-beta",
"analysis": "grok-4.20-beta-0309-reasoning",
"research": "grok-4.20-multi-agent-beta-0309"
}
return model_map.get(task_type, "grok-4.20-beta")
# Exemplo de uso
model = choose_grok_model("analysis")
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "Analise os gargalos de desempenho deste código..."}]
)
Ver código de teste comparativo entre modelos
import openai
import time
client = openai.OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://api.apiyi.com/v1"
)
models = [
"grok-4.20-beta",
"grok-4.20-beta-0309-non-reasoning",
"grok-4.20-beta-0309-reasoning",
"grok-4.20-multi-agent-beta-0309"
]
prompt = "Implemente o quicksort em Python e analise a complexidade de tempo"
for model in models:
try:
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=2048
)
elapsed = time.time() - start
tokens = response.usage.total_tokens
print(f"{model}")
print(f" Tempo decorrido: {elapsed:.1f}s | Tokens: {tokens}")
print(f" Prévia: {response.choices[0].message.content[:80]}...")
print()
except Exception as e:
print(f"{model} | Erro: {e}")
time.sleep(1)
🎯 Dica prática: Recomendo rodar um benchmark inicial com o
grok-4.20-betae, em seguida, comparar a diferença na qualidade da saída em tarefas complexas com a versãoreasoning. Ao utilizar a APIYI (apiyi.com) para invocar todos os 4 modelos, o preço é o mesmo do site oficial, com descontos aplicados através de promoções de recarga.
Perguntas frequentes
Q1: O preço dos 4 modelos é o mesmo?
Sim, os 4 modelos possuem um preço unificado: $2 para entrada / $6 para saída por milhão de tokens. No entanto, o custo real varia conforme o modelo — os modelos de raciocínio geram mais tokens de raciocínio (contados como saída), e a versão multiagente pode consumir mais tokens devido à colaboração de 4 agentes. A versão sem raciocínio é a mais econômica, pois pula a cadeia de pensamento e gera menos tokens de saída. A invocação via APIYI (apiyi.com) segue o preço oficial da xAI, com descontos via promoções da plataforma.
Q2: Qual a diferença entre a versão multiagente e a versão de raciocínio?
A versão de raciocínio é focada em um único agente realizando um pensamento profundo — ideal para tarefas de análise com respostas claras (matemática, revisão de código). A versão multiagente envolve 4 agentes colaborando em discussão — ideal para questões abertas que exigem análise sob múltiplos ângulos (pesquisa de mercado, análise de decisão). O principal diferencial da versão multiagente é a validação cruzada, que reduz a taxa de alucinação (de 12% para 4,2%).
Q3: O Grok 4.20 pode substituir o Claude na revisão de código?
Em alguns cenários, sim. O Grok 4.20 com raciocínio atinge cerca de 75% no SWE-bench, abaixo dos 81,4% do Claude Opus 4.6, mas custa apenas 8% do valor. Para revisões de código diárias que não sejam críticas para a segurança, o Grok 4.20 com raciocínio é uma escolha de excelente custo-benefício. Para auditorias de segurança e revisões de arquitetura de grande porte, o Claude Opus 4.6 continua sendo mais confiável. Através da APIYI (apiyi.com), você pode acessar ambos os modelos e alternar entre eles conforme a tarefa.
Q4: Para que serve uma janela de contexto de 2 milhões de tokens?
2 milhões de tokens equivalem a aproximadamente um livro técnico de 1500 páginas. Aplicações práticas: (1) Carregar todo o código-fonte de um projeto médio ou grande para análise de uma só vez; (2) Processar documentos extremamente longos (contratos jurídicos, coleções de artigos acadêmicos); (3) Manter memória de conversas muito longas. Esta é, atualmente, uma das maiores janelas de contexto entre os modelos de ponta do ocidente.
Q5: Como invocar esses modelos na plataforma APIYI?
Após registrar-se em apiyi.com e obter sua chave API, basta usar o formato compatível com OpenAI. Defina a base_url como https://api.apiyi.com/v1 e o model como o ID do modelo correspondente (ex: grok-4.20-beta). Veja os exemplos de código acima. O preço dos 4 modelos é igual ao oficial, com descontos via promoções de recarga.
Resumo: Estratégias de uso ideal para os 4 modelos
A série Grok 4.20 Beta oferece uma seleção precisa de modelos para diferentes cenários. A estratégia principal é combinar o modelo com a complexidade da tarefa:
| Complexidade | Modelo Recomendado | Custo |
|---|---|---|
| 🟢 Simples/Alta frequência | non-reasoning |
Mais baixo |
| 🟡 Uso geral diário | grok-4.20-beta |
Moderado |
| 🟠 Análise profunda | reasoning |
Mais alto |
| 🔴 Máxima confiabilidade | multi-agent |
Mais alto |
O preço de $2/$6 torna o Grok 4.20 o modelo carro-chefe com o menor custo de saída do mercado atual. Com uma janela de contexto de 2 milhões de tokens e um sistema multiagente, ele é extremamente competitivo em cenários de pesquisa, análise e alto throughput.
Recomendamos o acesso a toda a série Grok 4.20 Beta através do APIYI (apiyi.com), com preços idênticos aos do site oficial e descontos aplicados em promoções de recarga. Com uma única chave API, você pode invocar mais de 200 modelos, incluindo Grok, Claude, GPT e outros.
Referências
-
Documentação oficial da xAI: Modelos Grok e explicações de preços
- Link:
docs.x.ai/developers/models
- Link:
-
Artificial Analysis: Benchmarks do Grok 4.20 Beta
- Link:
artificialanalysis.ai/models/grok-4-20
- Link:
-
Documentação de Multiagentes da xAI: Detalhes sobre a capacidade Multi-Agent
- Link:
docs.x.ai/developers/model-capabilities/text/multi-agent
- Link:
-
OpenRouter: Página do modelo Grok 4.20 Beta
- Link:
openrouter.ai
- Link:
Autor: Equipe APIYI | Disponibilizamos os modelos de IA mais recentes em primeira mão. Acesse o APIYI (apiyi.com) para experimentar toda a série Grok 4.20 Beta.