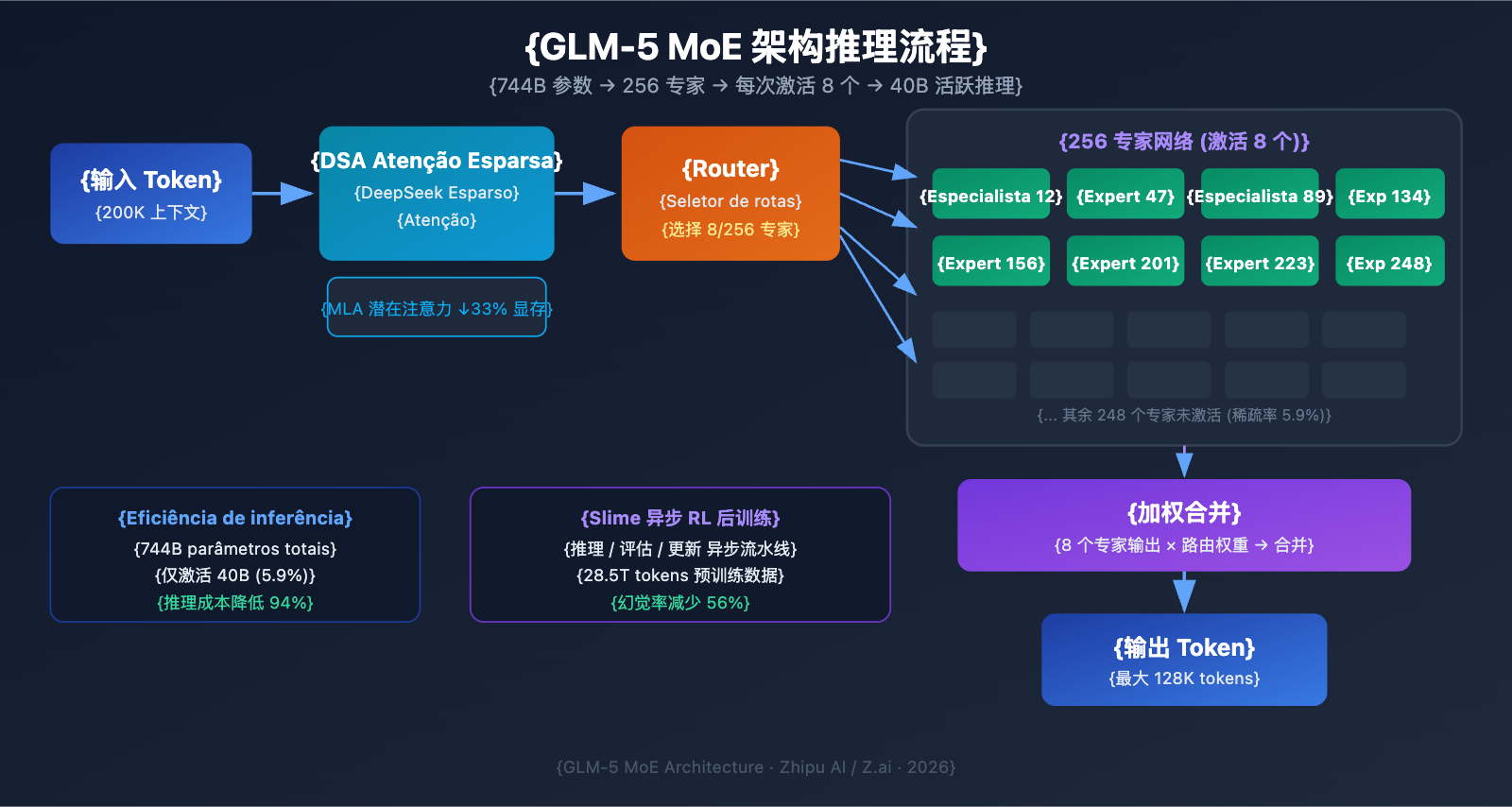
A Zhipu AI lançou oficialmente o GLM-5 em 11 de fevereiro de 2026, sendo este um dos maiores Modelos de Linguagem Grande de código aberto em termos de escala de parâmetros atualmente. O GLM-5 adota uma arquitetura de mistura de especialistas (MoE) de 744B, ativando 40B de parâmetros a cada inferência, alcançando o melhor nível entre os modelos de código aberto em tarefas de raciocínio, codificação e Agentes.
Valor Central: Ao ler este artigo, você dominará os princípios da arquitetura técnica do GLM-5, os métodos de chamada de API, a configuração do modo de raciocínio Thinking e como extrair o máximo valor deste modelo flagship de código aberto de 744B em projetos reais.

Visão Geral dos Parâmetros Principais do GLM-5
Antes de mergulharmos nos detalhes técnicos, vamos dar uma olhada nos parâmetros cruciais do GLM-5:
| Parâmetro | Valor | Descrição |
|---|---|---|
| Total de Parâmetros | 744B (744 bilhões) | Um dos maiores modelos de código aberto atuais |
| Parâmetros Ativos | 40B (40 bilhões) | Utilizados de fato em cada inferência |
| Tipo de Arquitetura | MoE (Mistura de Especialistas) | 256 especialistas, 8 ativados por token |
| Janela de Contexto | 200.000 tokens | Suporta processamento de documentos ultra-longos |
| Saída Máxima | 128.000 tokens | Atende às necessidades de geração de textos longos |
| Dados de Pré-treinamento | 28.5T tokens | Aumento de 24% em relação à geração anterior |
| Licença | Apache-2.0 | Totalmente open source, permite uso comercial |
| Hardware de Treinamento | Chips Huawei Ascend | Poder computacional nacional, independente de hardware estrangeiro |
Uma característica notável do GLM-5 é que ele foi treinado inteiramente com base em chips Huawei Ascend e no framework MindSpore, alcançando uma validação completa da pilha de computação nacional chinesa. Para os desenvolvedores, isso significa que o controle autônomo da pilha tecnológica ganhou uma nova e poderosa opção.
Evolução das Versões da Série GLM
O GLM-5 é o produto de quinta geração da série GLM da Zhipu AI, com cada geração apresentando saltos significativos de capacidade:
| Versão | Data de Lançamento | Escala de Parâmetros | Principais Avanços |
|---|---|---|---|
| GLM-4 | 01/2024 | Não divulgado | Capacidades multimodais básicas |
| GLM-4.5 | 03/2025 | 355B (32B ativos) | Primeira introdução da arquitetura MoE |
| GLM-4.5-X | 06/2025 | Idem | Raciocínio reforçado, posicionamento flagship |
| GLM-4.7 | 10/2025 | Não divulgado | Modo de raciocínio Thinking |
| GLM-4.7-FlashX | 12/2025 | Não divulgado | Raciocínio rápido de ultra baixo custo |
| GLM-5 | 02/2026 | 744B (40B ativos) | Avanço em capacidades de Agente, redução de 56% na taxa de alucinação |
Dos 355B do GLM-4.5 para os 744B do GLM-5, o total de parâmetros mais que dobrou; os parâmetros ativos aumentaram de 32B para 40B, um crescimento de 25%; os dados de pré-treinamento subiram de 23T para 28.5T tokens. Por trás desses números está o investimento total da Zhipu AI em três dimensões: poder computacional, dados e algoritmos.
🚀 Experiência Rápida: O GLM-5 já está disponível no APIYI (apiyi.com). Os preços são idênticos aos do site oficial e, com as campanhas de bônus de recarga, você pode aproveitar cerca de 20% de desconto, ideal para desenvolvedores que desejam testar rapidamente este modelo flagship de 744B.
Análise Técnica da Arquitetura MoE do GLM-5
Por que o GLM-5 escolheu a arquitetura MoE
O MoE (Mixture of Experts) é a principal rota tecnológica para a expansão de Modelos de Linguagem Grande atualmente. Diferente da arquitetura Dense (onde todos os parâmetros participam de cada inferência), a arquitetura MoE ativa apenas uma pequena parte das redes de especialistas para processar cada token, mantendo a imensa capacidade de conhecimento do modelo e, ao mesmo tempo, reduzindo drasticamente os custos de inferência.
O design da arquitetura MoE do GLM-5 traz as seguintes características fundamentais:
| Atributo da Arquitetura | Implementação no GLM-5 | Valor Técnico |
|---|---|---|
| Total de especialistas | 256 | Capacidade de conhecimento imensa |
| Ativados por token | 8 especialistas | Alta eficiência de inferência |
| Taxa de esparsidade | 5,9% | Usa apenas uma pequena fração dos parâmetros |
| Mecanismo de atenção | DSA + MLA | Reduz custos de implantação |
| Otimização de memória | MLA reduz 33% | Menor uso de VRAM |
Resumindo: embora o GLM-5 tenha 744B de parâmetros, cada inferência ativa apenas 40B (cerca de 5,9%). Isso significa que o custo de inferência é muito menor do que o de um modelo Dense do mesmo tamanho, permitindo ainda assim aproveitar o vasto conhecimento contido nos 744B de parâmetros.
DeepSeek Sparse Attention (DSA) no GLM-5
O GLM-5 integra o mecanismo DeepSeek Sparse Attention, uma tecnologia que reduz significativamente os custos de implantação enquanto mantém a capacidade de lidar com contextos longos. Junto com o Multi-head Latent Attention (MLA), o GLM-5 consegue operar de forma eficiente mesmo em janelas de contexto ultra-longas de 200K tokens.
Na prática:
- DSA (DeepSeek Sparse Attention): Reduz a complexidade do cálculo de atenção através de padrões esparsos. Mecanismos tradicionais de atenção total exigem um processamento imenso para 200K tokens; o DSA foca seletivamente em posições de tokens cruciais para diminuir o custo computacional, mantendo a integridade da informação.
- MLA (Multi-head Latent Attention): Comprime o KV Cache dos cabeçotes de atenção em um espaço latente, reduzindo o uso de memória em cerca de 33%. Em cenários de contexto longo, o KV Cache costuma ser o maior consumidor de VRAM, e o MLA alivia esse gargalo de forma eficaz.
A combinação dessas duas tecnologias significa que, mesmo sendo um modelo de 744B, ele pode rodar em 8 GPUs após a quantização FP8, baixando consideravelmente a barreira de entrada para implantação.
Pós-treinamento do GLM-5: Sistema de RL Assíncrono Slime
O GLM-5 utiliza uma nova infraestrutura de aprendizado por reforço (RL) assíncrono chamada "slime" para o seu pós-treinamento. O treinamento de RL tradicional sofre com gargalos de eficiência — há muito tempo de espera entre as etapas de geração, avaliação e atualização. O Slime torna essas etapas assíncronas, permitindo iterações de pós-treinamento mais granulares e aumentando muito o throughput (vazão) do treinamento.
No fluxo tradicional de RL, o modelo precisa terminar um lote de inferência, esperar pelos resultados da avaliação e só então atualizar os parâmetros, executando os três passos em série. O Slime desacopla esses passos em pipelines assíncronos independentes, permitindo que a inferência, a avaliação e a atualização ocorram em paralelo.
Essa melhoria técnica reflete diretamente na taxa de alucinação do GLM-5 — uma redução de 56% em relação à geração anterior. Iterações de pós-treinamento mais frequentes e completas permitiram melhorias nítidas na precisão factual do modelo.
GLM-5 vs. Arquitetura Dense
Para entender melhor as vantagens da arquitetura MoE, podemos comparar o GLM-5 com um modelo Dense hipotético de mesmo tamanho:
| Dimensão de Comparação | GLM-5 (744B MoE) | Dense 744B Hipotético | Diferença Real |
|---|---|---|---|
| Parâmetros por inferência | 40B (5,9%) | 744B (100%) | MoE reduz 94% |
| Requisito de VRAM | 8x GPUs (FP8) | Cerca de 96x GPUs | MoE significativamente menor |
| Velocidade de inferência | Rápida | Extremamente lenta | MoE é mais adequado para uso real |
| Capacidade de conhecimento | Conhecimento total de 744B | Conhecimento total de 744B | Equivalente |
| Especialização | Especialistas para tarefas específicas | Processamento unificado | MoE é mais refinado |
| Custo de treinamento | Alto, mas controlável | Extremamente alto | MoE tem melhor custo-benefício |
A vantagem central da arquitetura MoE é que ela entrega a capacidade de conhecimento de 744B de parâmetros com a eficiência de custo de inferência de apenas 40B. É por isso que o GLM-5 consegue manter um desempenho de ponta e, ao mesmo tempo, oferecer preços muito menores do que modelos proprietários de nível similar.
Guia Rápido de Chamada da API do GLM-5
Detalhamento dos Parâmetros de Requisição da API do GLM-5
Antes de começar a codificar, vamos entender a configuração dos parâmetros da API do GLM-5:
| Parâmetro | Tipo | Obrigatório | Valor Padrão | Descrição |
|---|---|---|---|---|
model |
string | ✅ | – | Fixo como "glm-5" |
messages |
array | ✅ | – | Mensagens no formato chat padrão |
max_tokens |
int | ❌ | 4096 | Número máximo de tokens de saída (limite de 128K) |
temperature |
float | ❌ | 1.0 | Temperatura de amostragem; quanto menor, mais determinístico |
top_p |
float | ❌ | 1.0 | Parâmetro de amostragem de núcleo |
stream |
bool | ❌ | false | Se deve usar saída em fluxo (streaming) |
thinking |
object | ❌ | disabled | {"type": "enabled"} para habilitar o raciocínio |
tools |
array | ❌ | – | Definição de ferramentas de Function Calling |
tool_choice |
string | ❌ | auto | Estratégia de escolha de ferramentas |
Exemplo Minimalista de Chamada do GLM-5
O GLM-5 é compatível com o formato da interface do SDK da OpenAI, bastando alterar os parâmetros base_url e model para uma integração rápida:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI统一接口
)
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "你是一位资深的 AI 技术专家"},
{"role": "user", "content": "解释 MoE 混合专家架构的工作原理和优势"}
],
temperature=0.7,
max_tokens=4096
)
print(response.choices[0].message.content)
Este trecho de código mostra a forma mais básica de chamar o GLM-5. O ID do modelo usado é glm-5, e a interface é totalmente compatível com o formato chat.completions da OpenAI. Para migrar projetos existentes, basta modificar apenas esses dois parâmetros.
Modo de Raciocínio (Thinking) do GLM-5
O GLM-5 suporta o modo de raciocínio Thinking, semelhante à capacidade de pensamento expandido do DeepSeek R1 e do Claude. Quando ativado, o modelo realiza um raciocínio em cadeia interno antes de responder, o que eleva significativamente o desempenho em problemas complexos de matemática, lógica e programação:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI统一接口
)
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "user", "content": "证明: 对于所有正整数 n, n^3 - n 能被 6 整除"}
],
extra_body={
"thinking": {"type": "enabled"}
},
temperature=1.0 # Thinking 模式建议使用 1.0
)
print(response.choices[0].message.content)
Sugestões de uso para o modo Thinking do GLM-5:
| Cenário | Ativar Thinking? | Sugestão de temperature |
Descrição |
|---|---|---|---|
| Provas matemáticas/Questões de competição | ✅ Sim | 1.0 | Requer raciocínio profundo |
| Depuração de código/Design de arquitetura | ✅ Sim | 1.0 | Requer análise sistêmica |
| Raciocínio lógico/Análise | ✅ Sim | 1.0 | Requer pensamento em cadeia |
| Conversas diárias/Escrita | ❌ Não | 0.5-0.7 | Não requer raciocínio complexo |
| Extração de informações/Resumo | ❌ Não | 0.3-0.5 | Busca por saída estável |
| Geração de conteúdo criativo | ❌ Não | 0.8-1.0 | Requer diversidade |
Saída em Fluxo (Streaming) do GLM-5
Para cenários que exigem interação em tempo real, o GLM-5 suporta saída em fluxo, permitindo que o usuário veja o resultado sendo gerado passo a passo:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
stream = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "user", "content": "用 Python 实现一个带缓存的 HTTP 客户端"}
],
stream=True,
temperature=0.6
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
GLM-5 Function Calling e Construção de Agentes
O GLM-5 possui suporte nativo para Function Calling, que é a capacidade central para construir sistemas de Agentes. O GLM-5 obteve uma pontuação de 50,4% no benchmark HLE w/ Tools, superando o Claude Opus (43,4%), o que mostra que ele é excelente na chamada de ferramentas e na orquestração de tarefas:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "search_documents",
"description": "搜索知识库中的相关文档",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "搜索关键词"},
"top_k": {"type": "integer", "description": "返回结果数量", "default": 5}
},
"required": ["query"]
}
}
},
{
"type": "function",
"function": {
"name": "execute_code",
"description": "在沙箱环境中执行 Python 代码",
"parameters": {
"type": "object",
"properties": {
"code": {"type": "string", "description": "要执行的 Python 代码"},
"timeout": {"type": "integer", "description": "超时时间(秒)", "default": 30}
},
"required": ["code"]
}
}
}
]
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "你是一个能够搜索文档和执行代码的AI助手"},
{"role": "user", "content": "帮我查一下 GLM-5 的技术参数,然后用代码画一个性能对比图"}
],
tools=tools,
tool_choice="auto"
)
# 处理工具调用
message = response.choices[0].message
if message.tool_calls:
for tool_call in message.tool_calls:
print(f"调用工具: {tool_call.function.name}")
print(f"参数: {tool_call.function.arguments}")
Ver exemplo de chamada cURL
curl https://api.apiyi.com/v1/chat/completions \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "glm-5",
"messages": [
{"role": "system", "content": "你是一位资深软件工程师"},
{"role": "user", "content": "设计一个分布式任务调度系统的架构"}
],
"max_tokens": 8192,
"temperature": 0.7,
"stream": true
}'
🎯 Dica Técnica: O GLM-5 é compatível com o formato do SDK da OpenAI, então você só precisa alterar o
base_urle omodelpara migrar seus projetos. Ao utilizar a plataforma APIYI (apiyi.com), você conta com uma interface de gerenciamento unificada e bônus em recargas.
Testes de Desempenho (Benchmark) do GLM-5
Dados Principais de Benchmark do GLM-5
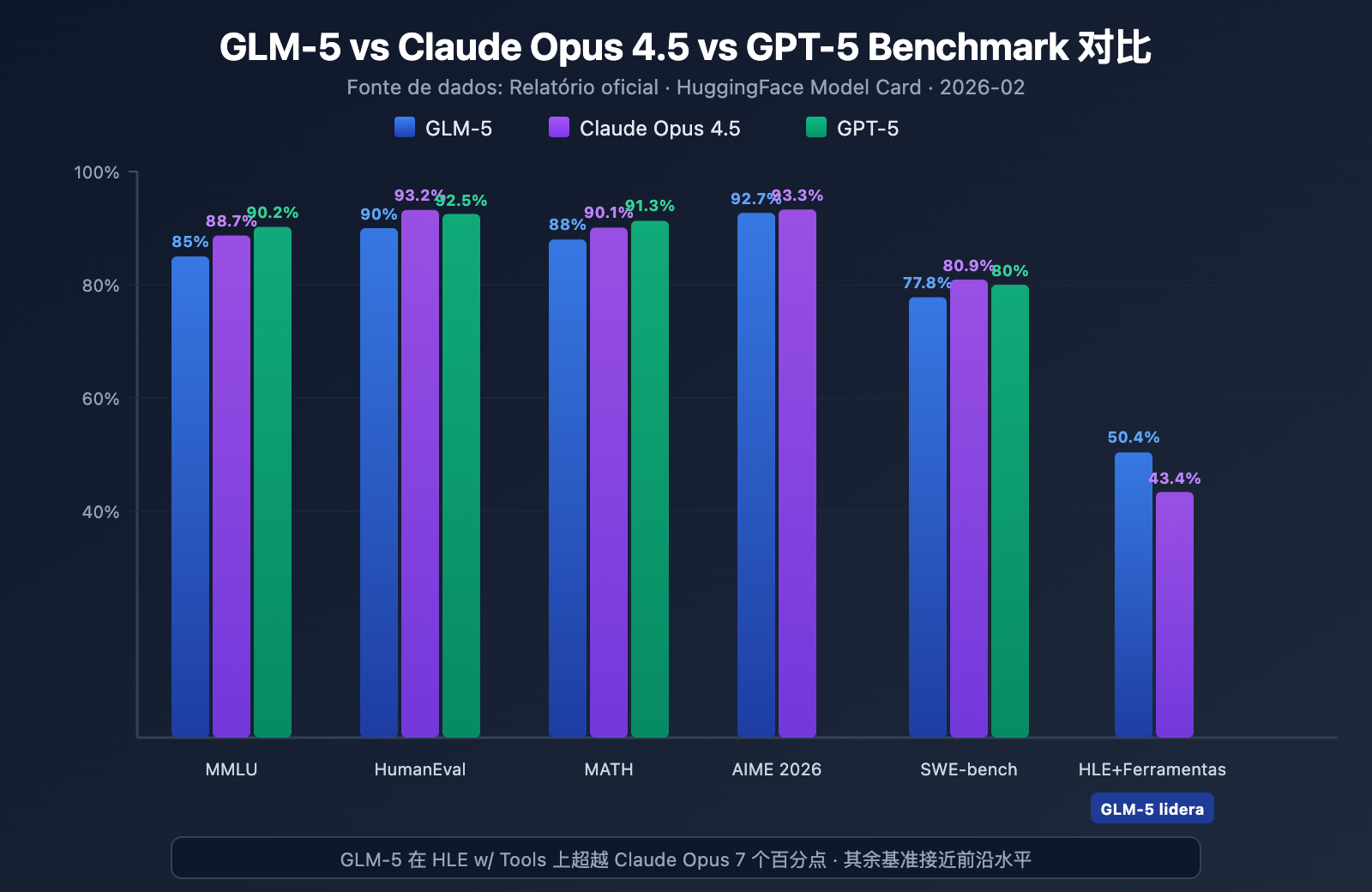
O GLM-5 demonstrou o nível mais alto entre os modelos de código aberto em vários benchmarks populares:
| Benchmark | GLM-5 | Claude Opus 4.5 | GPT-5 | Conteúdo do Teste |
|---|---|---|---|---|
| MMLU | 85,0% | 88,7% | 90,2% | Conhecimento em 57 disciplinas |
| MMLU Pro | 70,4% | – | – | Multidisciplinar aprimorado |
| GPQA | 68,2% | 71,4% | 73,1% | Ciência de nível de pós-graduação |
| HumanEval | 90,0% | 93,2% | 92,5% | Programação em Python |
| MATH | 88,0% | 90,1% | 91,3% | Raciocínio matemático |
| GSM8k | 97,0% | 98,2% | 98,5% | Problemas matemáticos aplicados |
| AIME 2026 I | 92,7% | 93,3% | – | Competição de matemática |
| SWE-bench | 77,8% | 80,9% | 80,0% | Engenharia de software real |
| HLE w/ Tools | 50,4% | 43,4% | – | Raciocínio com ferramentas |
| IFEval | 88,0% | – | – | Seguimento de instruções |
| Terminal-Bench | 56,2% | 57,9% | – | Operações de terminal |
Análise de Desempenho do GLM-5: 4 Principais Vantagens
A partir dos dados de benchmark, podemos observar vários pontos que merecem atenção:
1. Capacidade de Agente do GLM-5: HLE w/ Tools supera modelos fechados
No Humanity's Last Exam (com uso de ferramentas), o GLM-5 obteve uma pontuação de 50,4%, superando os 43,4% do Claude Opus e ficando atrás apenas dos 51,8% do Kimi K2.5. Isso indica que o GLM-5 já atingiu o nível dos modelos de ponta em cenários de Agente — tarefas complexas que exigem planejamento, chamada de ferramentas e resolução iterativa.
Esse resultado está alinhado com a filosofia de design do GLM-5: ele foi otimizado especificamente para fluxos de trabalho de Agentes, desde a arquitetura até o pós-treinamento. Para desenvolvedores que desejam construir sistemas de Agentes de IA, o GLM-5 oferece uma opção de código aberto com excelente custo-benefício.
2. Capacidade de Programação do GLM-5: No primeiro escalão
Com 90% no HumanEval e 77,8% no SWE-bench Verified, o GLM-5 está muito próximo do nível do Claude Opus (80,9%) e do GPT-5 (80,0%) em geração de código e tarefas reais de engenharia de software. Como um modelo de código aberto, atingir 77,8% no SWE-bench é um marco importante — significa que o GLM-5 já é capaz de entender issues reais do GitHub, localizar problemas no código e enviar correções eficazes.
3. Raciocínio Matemático do GLM-5: Próximo ao teto de desempenho
No AIME 2026 I, o GLM-5 alcançou 92,7%, ficando apenas 0,6 ponto percentual atrás do Claude Opus. Os 97% no GSM8k também mostram que o GLM-5 é extremamente confiável em problemas matemáticos de dificuldade média. O resultado de 88% no MATH também o coloca no primeiro escalão.
4. Controle de Alucinações do GLM-5: Redução drástica
De acordo com dados oficiais, a taxa de alucinação do GLM-5 diminuiu 56% em relação à geração anterior. Isso se deve às iterações de pós-treinamento mais robustas proporcionadas pelo sistema de RL assíncrono Slime. Em cenários que exigem alta precisão, como extração de informações, resumos de documentos e perguntas e respostas baseadas em bases de conhecimento, uma menor taxa de alucinação traduz-se diretamente em uma saída mais confiável.
Posicionamento do GLM-5 em relação a outros modelos de código aberto
No atual cenário competitivo de Modelos de Linguagem Grandes de código aberto, o posicionamento do GLM-5 é bem claro:
| Modelo | Escala de Parâmetros | Arquitetura | Principais Vantagens | Licença |
|---|---|---|---|---|
| GLM-5 | 744B (40B ativos) | MoE | Agente + Baixa alucinação | Apache-2.0 |
| DeepSeek V3 | 671B (37B ativos) | MoE | Custo-benefício + Raciocínio | MIT |
| Llama 4 Maverick | 400B (17B ativos) | MoE | Multimodal + Ecossistema | Llama License |
| Qwen 3 | 235B | Dense | Multilíngue + Ferramentas | Apache-2.0 |
As vantagens competitivas do GLM-5 manifestam-se principalmente em três aspectos: otimização específica para fluxos de trabalho de Agentes (liderança no HLE w/ Tools), taxa de alucinação extremamente baixa (redução de 56%) e a segurança da cadeia de suprimentos proporcionada pelo treinamento em hardware totalmente nacional. Para empresas que precisam implantar modelos de código aberto de ponta, o GLM-5 é uma opção que merece atenção especial.
Análise de Preços e Custos do GLM-5
Preços Oficiais do GLM-5
| Tipo de Cobrança | Preço Oficial Z.ai | Preço OpenRouter | Descrição |
|---|---|---|---|
| Token de Entrada | $1.00/M | $0.80/M | Por milhão de tokens de entrada |
| Token de Saída | $3.20/M | $2.56/M | Por milhão de tokens de saída |
| Entrada em Cache | $0.20/M | $0.16/M | Preço de entrada quando há hit no cache |
| Armazenamento de Cache | Temporariamente gratuito | – | Taxa de armazenamento de dados em cache |
Comparação de Preços: GLM-5 vs. Concorrentes
A estratégia de preços do GLM-5 é extremamente competitiva, especialmente quando comparada a modelos de ponta de código fechado:
| Modelo | Entrada ($/M) | Saída ($/M) | Custo relativo ao GLM-5 | Posicionamento do Modelo |
|---|---|---|---|---|
| GLM-5 | $1.00 | $3.20 | Base | Flagship de código aberto |
| Claude Opus 4.6 | $5.00 | $25.00 | Cerca de 5-8x | Flagship de código fechado |
| GPT-5 | $1.25 | $10.00 | Cerca de 1.3-3x | Flagship de código fechado |
| DeepSeek V3 | $0.27 | $1.10 | Cerca de 0.3x | Custo-benefício de código aberto |
| GLM-4.7 | $0.60 | $2.20 | Cerca de 0.6-0.7x | Flagship da geração anterior |
| GLM-4.7-FlashX | $0.07 | $0.40 | Cerca de 0.07-0.13x | Custo ultra baixo |
Olhando para os preços, o GLM-5 se posiciona entre o GPT-5 e o DeepSeek V3 — muito mais barato que a maioria dos modelos de ponta proprietários, mas um pouco mais caro que os modelos de código aberto leves. Considerando a escala de 744B parâmetros e o desempenho como o modelo de código aberto mais forte, esse preço é bastante razoável.
Linha de Produtos e Preços da Família GLM
Se o GLM-5 não se encaixa perfeitamente no seu cenário, a Zhipu oferece uma linha completa de produtos para escolha:
| Modelo | Entrada ($/M) | Saída ($/M) | Cenários de Uso |
|---|---|---|---|
| GLM-5 | $1.00 | $3.20 | Raciocínio complexo, Agents, documentos longos |
| GLM-5-Code | $1.20 | $5.00 | Especializado em desenvolvimento de código |
| GLM-4.7 | $0.60 | $2.20 | Tarefas gerais de complexidade média |
| GLM-4.7-FlashX | $0.07 | $0.40 | Chamadas de alta frequência e baixo custo |
| GLM-4.5-Air | $0.20 | $1.10 | Equilíbrio leve |
| GLM-4.7/4.5-Flash | Gratuito | Gratuito | Experiência inicial e tarefas simples |
💰 Otimização de Custos: O GLM-5 já está disponível no APIYI (apiyi.com), com preços idênticos aos oficiais da Z.ai. Através de campanhas de bônus de recarga na plataforma, o custo real de uso pode cair para cerca de 80% do preço oficial, sendo ideal para equipes e desenvolvedores com demanda contínua de chamadas.
Cenários de Uso e Sugestões de Seleção do GLM-5
Para quais cenários o GLM-5 é indicado?
Com base nas características técnicas e no desempenho em benchmarks, aqui estão as recomendações específicas de cenários:
Cenários Fortemente Recomendados:
- Fluxos de trabalho de Agents: O GLM-5 foi projetado para tarefas de Agents de ciclo longo. Com 50.4% no HLE w/ Tools, ele supera o Claude Opus, sendo ideal para construir sistemas de Agents com planejamento autônomo e chamada de ferramentas.
- Tarefas de engenharia de software: Com 90% no HumanEval e 77.8% no SWE-bench, ele é excelente para geração de código, correção de bugs, revisão de código e design de arquitetura.
- Raciocínio matemático e científico: Com 92.7% no AIME e 88% no MATH, é adequado para provas matemáticas, derivação de fórmulas e cálculos científicos.
- Análise de documentos ultra longos: Janela de contexto de 200K, permitindo processar bases de código completas, documentos técnicos, contratos legais e outros textos extensos.
- Q&A com baixa alucinação: Redução de 56% na taxa de alucinação, ideal para bases de conhecimento (RAG), resumos de documentos e cenários que exigem alta precisão.
Cenários onde outras opções podem ser consideradas:
- Tarefas multimodais: O GLM-5 base suporta apenas texto. Se precisar de compreensão de imagem, escolha modelos de visão como o GLM-4.6V.
- Latência extremamente baixa: A velocidade de inferência de um modelo MoE de 744B não é tão rápida quanto a de modelos menores. Para cenários de alta frequência e baixa latência, recomenda-se o GLM-4.7-FlashX.
- Processamento em lote de custo ultra baixo: Se o processamento de grandes volumes de texto não exigir qualidade máxima, o DeepSeek V3 ou o GLM-4.7-FlashX oferecem custos menores.
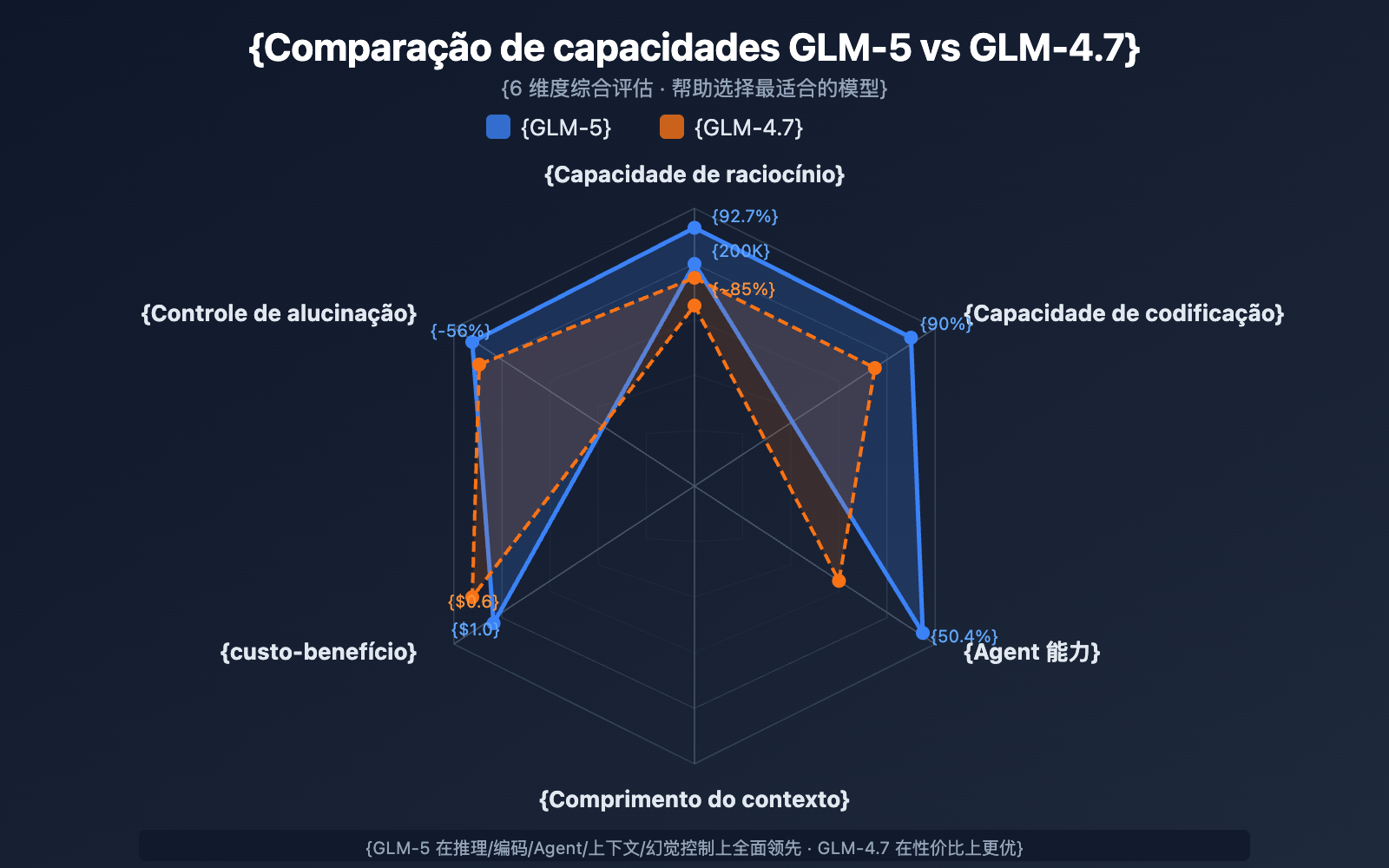
Comparação de Seleção: GLM-5 vs. GLM-4.7
| Dimensão de Comparação | GLM-5 | GLM-4.7 | Sugestão de Seleção |
|---|---|---|---|
| Escala de Parâmetros | 744B (40B ativos) | Não divulgado | GLM-5 é maior |
| Capacidade de Raciocínio | AIME 92.7% | ~85% | Raciocínio complexo: GLM-5 |
| Capacidade de Agent | HLE w/ Tools 50.4% | ~38% | Tarefas de Agent: GLM-5 |
| Capacidade de Codificação | HumanEval 90% | ~85% | Desenvolvimento de código: GLM-5 |
| Controle de Alucinação | Redução de 56% | Base | Alta precisão: GLM-5 |
| Preço de Entrada | $1.00/M | $0.60/M | Sensível ao custo: GLM-4.7 |
| Preço de Saída | $3.20/M | $2.20/M | Sensível ao custo: GLM-4.7 |
| Comprimento do Contexto | 200K | 128K+ | Documentos longos: GLM-5 |
💡 Dica de Seleção: Se o seu projeto exige capacidade de raciocínio de alto nível, fluxos de trabalho de Agents ou processamento de contexto ultra longo, o GLM-5 é a melhor escolha. Se o orçamento for limitado e a complexidade da tarefa for moderada, o GLM-4.7 continua sendo uma excelente opção de custo-benefício. Ambos os modelos podem ser acessados via plataforma APIYI (apiyi.com), facilitando a alternância para testes a qualquer momento.
Perguntas Frequentes sobre a Chamada da API do GLM-5
Q1: Qual a diferença entre o GLM-5 e o GLM-5-Code?
O GLM-5 é o modelo flagship de uso geral (Entrada $1.00/M, Saída $3.20/M), ideal para diversos tipos de tarefas de texto. Já o GLM-5-Code é uma versão turbinada específica para programação (Entrada $1.20/M, Saída $5.00/M), que passou por otimizações extras para geração de código, depuração (debugging) e tarefas de engenharia. Se o seu cenário principal envolve desenvolvimento de software, vale a pena testar o GLM-5-Code. Ambos os modelos podem ser chamados através de uma interface unificada compatível com OpenAI.
Q2: O modo Thinking do GLM-5 afeta a velocidade de resposta?
Sim. No modo Thinking, o GLM-5 gera primeiro uma cadeia de raciocínio interna antes de entregar a resposta final, o que aumenta a latência do primeiro token (TTFT). Para perguntas simples, recomendamos desativar o modo Thinking para obter uma resposta mais rápida. Já para problemas complexos de matemática, programação e lógica, é recomendável ativá-lo; embora seja um pouco mais lento, a precisão aumenta consideravelmente.
Q3: O que preciso mudar no código para migrar do GPT-4 ou Claude para o GLM-5?
A migração é extremamente simples, você só precisa ajustar dois parâmetros:
- Alterar a
base_urlpara o endereço da interface da APIYI:https://api.apiyi.com/v1 - Alterar o parâmetro
modelpara"glm-5"
O GLM-5 é totalmente compatível com o formato da interface chat.completions do SDK da OpenAI, incluindo as funções de roles (system/user/assistant), saída em streaming, Function Calling, entre outras. Através de uma plataforma de API unificada, você também pode alternar entre modelos de diferentes provedores usando a mesma API Key, o que facilita muito a realização de testes A/B.
Q4: O GLM-5 suporta entrada de imagens?
Não. O GLM-5 em si é um modelo puramente de texto e não suporta entrada de imagens, áudio ou vídeo. Se você precisar de capacidades de compreensão visual, pode utilizar as variantes de visão da Zhipu, como o GLM-4.6V ou o GLM-4.5V.
Q5: Como funciona o recurso de cache de contexto do GLM-5?
O GLM-5 suporta o Cache de Contexto (Context Caching). O preço para entrada em cache é de apenas $0.20/M, o que representa 1/5 do valor da entrada normal. Em conversas longas ou cenários que exigem o processamento repetido do mesmo prefixo, o recurso de cache pode reduzir drasticamente os custos. Atualmente, o armazenamento do cache é gratuito por tempo limitado. Em diálogos de múltiplas rodadas, o sistema identifica e armazena automaticamente os prefixos de contexto repetidos.
Q6: Qual é o comprimento máximo de saída do GLM-5?
O GLM-5 suporta um comprimento máximo de saída de até 128.000 tokens. Para a maioria dos casos, o padrão de 4096 tokens é suficiente. Se você precisar gerar textos longos (como documentação técnica completa ou grandes blocos de código), pode ajustar isso através do parâmetro max_tokens. Vale lembrar que, quanto maior a saída, maior será o consumo de tokens e o tempo de espera.
Melhores Práticas para Chamadas da API do GLM-5
Ao utilizar o GLM-5 na prática, as seguintes experiências podem te ajudar a obter resultados melhores:
Otimização do System Prompt (Comando de Sistema) do GLM-5
O GLM-5 responde muito bem aos comandos de sistema. Um design bem estruturado pode elevar significativamente a qualidade da saída:
# Recomendado: Definição clara de papel + requisitos de formato de saída
messages = [
{
"role": "system",
"content": """Você é um arquiteto sênior de sistemas distribuídos.
Por favor, siga estas regras:
1. A resposta deve ser estruturada, usando o formato Markdown.
2. Forneça soluções técnicas específicas em vez de falar de forma genérica.
3. Se envolver código, forneça um exemplo que possa ser executado.
4. Indique riscos potenciais e pontos de atenção nos locais apropriados."""
},
{
"role": "user",
"content": "Projete um sistema de fila de mensagens que suporte milhões de acessos simultâneos."
}
]
Guia de ajuste de temperature no GLM-5
Diferentes tarefas têm sensibilidades distintas à temperature. Aqui estão algumas sugestões baseadas em testes:
- temperature 0.1-0.3: Geração de código, extração de dados, conversão de formatos e outras tarefas que exigem precisão absoluta.
- temperature 0.5-0.7: Documentação técnica, perguntas e respostas (Q&A), resumos e tarefas que precisam de estabilidade com certa flexibilidade de expressão.
- temperature 0.8-1.0: Escrita criativa, brainstorm e tarefas que demandam diversidade.
- temperature 1.0 (Modo Thinking): Raciocínio matemático, programação complexa e outras tarefas de raciocínio profundo.
Dicas para lidar com contextos longos no GLM-5
O GLM-5 suporta uma janela de contexto de 200K tokens, mas na prática é bom ficar atento a:
- Informações importantes no início: Coloque o contexto mais crítico no começo do comando (prompt), e não no final.
- Processamento segmentado: Para documentos que excedam 100K tokens, recomendamos processar por partes e depois consolidar, para obter uma saída mais estável.
- Aproveite o cache: Em conversas de várias rodadas, o conteúdo do prefixo idêntico será armazenado em cache automaticamente, custando apenas $0.20/M.
- Controle o comprimento da saída: Ao enviar contextos longos, configure o
max_tokensadequadamente para evitar saídas excessivamente longas que aumentem custos desnecessários.
Referência para Implantação Local do GLM-5
Se você precisa implantar o GLM-5 em sua própria infraestrutura, aqui estão as principais formas de implantação:
| Método de Implantação | Hardware Recomendado | Precisão | Características |
|---|---|---|---|
| vLLM | 8x A100/H100 | FP8 | Framework de inferência popular, suporta decodificação especulativa |
| SGLang | 8x H100/B200 | FP8 | Inferência de alto desempenho, otimizado para GPUs Blackwell |
| xLLM | Huawei Ascend NPU | BF16/FP8 | Adaptação para poder computacional nacional |
| KTransformers | GPU de nível de consumidor | Quantização | Inferência acelerada por GPU |
| Ollama | Hardware de nível de consumidor | Quantização | A experiência local mais simples |
O GLM-5 oferece dois formatos de pesos: precisão total BF16 e quantização FP8, que podem ser baixados no HuggingFace (huggingface.co/zai-org/GLM-5) ou ModelScope. A versão quantizada em FP8 reduz significativamente a necessidade de memória de vídeo (VRAM), mantendo a maior parte do desempenho.
Configurações cruciais necessárias para implantar o GLM-5:
- Paralelismo de tensores: 8 vias (tensor-parallel-size 8)
- Utilização de VRAM: Recomendado definir como 0.85
- Parser de chamada de ferramenta: glm47
- Parser de inferência: glm45
- Decodificação especulativa: Suporta os métodos MTP e EAGLE
Para a maioria dos desenvolvedores, fazer chamadas via API é a maneira mais eficiente, economizando custos de implantação e manutenção, permitindo focar apenas no desenvolvimento da aplicação. Para cenários que exigem implantação privada, consulte a documentação oficial:
github.com/zai-org/GLM-5
Resumo da Chamada de API do GLM-5
Consulta Rápida das Capacidades Principais do GLM-5
| Dimensão de Capacidade | Desempenho do GLM-5 | Cenários Aplicáveis |
|---|---|---|
| Raciocínio | AIME 92.7%, MATH 88% | Provas matemáticas, raciocínio científico, análise lógica |
| Codificação | HumanEval 90%, SWE-bench 77.8% | Geração de código, correção de bugs, design de arquitetura |
| Agente | HLE w/ Tools 50.4% | Chamada de ferramentas, planejamento de tarefas, execução autônoma |
| Conhecimento | MMLU 85%, GPQA 68.2% | Q&A acadêmico, consultoria técnica, extração de conhecimento |
| Instrução | IFEval 88% | Saída formatada, geração estruturada, seguimento de regras |
| Precisão | Redução de 56% na taxa de alucinação | Resumo de documentos, verificação de fatos, extração de informações |
Valor do Ecossistema de Código Aberto do GLM-5
O GLM-5 é de código aberto sob a licença Apache-2.0, o que significa:
- Liberdade Comercial: As empresas podem usar, modificar e distribuir gratuitamente, sem pagar taxas de licenciamento.
- Personalização via Fine-tuning: É possível realizar o ajuste fino (fine-tuning) baseado no GLM-5 para construir modelos específicos para cada setor.
- Implantação Privada: Dados sensíveis não saem da rede interna, atendendo aos requisitos de conformidade em setores como financeiro, médico e governamental.
- Ecossistema da Comunidade: Já existem mais de 11 variantes quantizadas e mais de 7 versões com ajuste fino no HuggingFace, com o ecossistema em constante expansão.
Como o mais novo modelo topo de linha da Zhipu AI, o GLM-5 estabeleceu um novo padrão no campo dos Modelos de Linguagem Grandes de código aberto:
- Arquitetura MoE de 744B: Sistema de 256 especialistas, ativando 40B de parâmetros em cada inferência, alcançando um excelente equilíbrio entre capacidade do modelo e eficiência de inferência.
- O Agente de Código Aberto mais Forte: Com 50.4% no HLE w/ Tools, supera o Claude Opus, sendo projetado especificamente para fluxos de trabalho de Agentes de ciclo longo.
- Treinado com Poder Computacional Nacional: Treinado com base em 100.000 chips Huawei Ascend, validando a capacidade de treinamento de modelos de ponta com a infraestrutura computacional nacional.
- Alta Relação Custo-Benefício: Entrada a $1/M e saída a $3.2/M, valores muito inferiores aos modelos de código fechado do mesmo nível; a comunidade de código aberto pode implantar e ajustar livremente.
- Contexto Ultra Longo de 200K: Suporta o processamento de bases de código completas e grandes documentos técnicos de uma só vez, com saída máxima de 128K tokens.
- 56% Menos Alucinações: O pós-treinamento com RL assíncrono Slime melhorou significativamente a precisão dos fatos.
Recomendamos experimentar rapidamente as diversas capacidades do GLM-5 através da APIYI (apiyi.com). Os preços da plataforma são idênticos aos oficiais, e as promoções de recarga podem oferecer descontos de cerca de 20%.
Este artigo foi escrito pela equipe técnica da APIYI Team. Para mais tutoriais sobre o uso de modelos de IA, acompanhe a central de ajuda da APIYI em apiyi.com.