智谱AI在 2026 年 2 月 11 日正式发布了 GLM-5,这是目前参数规模最大的开源大语言模型之一。GLM-5 采用 744B MoE 混合专家架构,每次推理激活 40B 参数,在推理、编码和 Agent 任务上达到了开源模型的最佳水平。
核心价值: 读完本文,你将掌握 GLM-5 的技术架构原理、API 调用方法、Thinking 推理模式配置,以及如何在实际项目中发挥这个 744B 开源旗舰模型的最大价值。

GLM-5 Kernparameter im Überblick
Bevor wir in die technischen Details eintauchen, werfen wir einen Blick auf die wichtigsten Parameter von GLM-5:
| Parameter | Wert | Beschreibung |
|---|---|---|
| Gesamtparameteranzahl | 744B (744 Milliarden) | Eines der derzeit größten Open-Source-Modelle |
| Aktive Parameter | 40B (40 Milliarden) | Tatsächlich genutzt pro Inferenz-Schritt |
| Architekturtyp | MoE (Mixture of Experts) | 256 Experten, 8 pro Token aktiviert |
| Kontextfenster | 200.000 Tokens | Unterstützt die Verarbeitung extrem langer Dokumente |
| Maximaler Output | 128.000 Tokens | Erfüllt Anforderungen für lange Textgenerierung |
| Pre-Training-Daten | 28,5T Tokens | 24 % Steigerung gegenüber der Vorgeneration |
| Lizenz | Apache-2.0 | Vollständig Open Source, unterstützt kommerzielle Nutzung |
| Trainings-Hardware | Huawei Ascend-Chips | Vollständig inländische Rechenleistung, unabhängig von Übersee-Hardware |
Ein herausragendes Merkmal von GLM-5 ist, dass es vollständig auf Huawei Ascend-Chips und dem MindSpore-Framework trainiert wurde, was eine lückenlose Validierung des chinesischen Rechen-Stacks darstellt. Für Entwickler bedeutet dies eine weitere leistungsstarke, technologisch souveräne Option.
Versionsentwicklung der GLM-Serie
GLM-5 ist die fünfte Generation der GLM-Serie von Zhipu AI. Jede Generation brachte signifikante Fähigkeitssprünge mit sich:
| Version | Veröffentlichungsdatum | Parameterskala | Kern-Durchbruch |
|---|---|---|---|
| GLM-4 | 01.2024 | Nicht veröffentlicht | Multimodale Basisfähigkeiten |
| GLM-4.5 | 03.2025 | 355B (32B aktiv) | Einführung der MoE-Architektur |
| GLM-4.5-X | 06.2025 | Wie oben | Verstärktes Reasoning, Flaggschiff-Positionierung |
| GLM-4.7 | 10.2025 | Nicht veröffentlicht | Thinking-Inferenzmodus |
| GLM-4.7-FlashX | 12.2025 | Nicht veröffentlicht | Schnelle Inferenz zu extrem niedrigen Kosten |
| GLM-5 | 02.2026 | 744B (40B aktiv) | Durchbruch bei Agent-Fähigkeiten, Halluzinationsrate um 56 % gesenkt |
Von den 355B Parametern bei GLM-4.5 auf 744B bei GLM-5 hat sich die Gesamtparameteranzahl mehr als verdoppelt. Die aktiven Parameter stiegen von 32B auf 40B (ein Plus von 25 %), und die Pre-Training-Daten wuchsen von 23T auf 28,5T Tokens. Hinter diesen Zahlen stehen massive Investitionen von Zhipu AI in Rechenleistung, Daten und Algorithmen.
🚀 Schnell ausprobieren: GLM-5 ist bereits auf APIYI (apiyi.com) verfügbar. Die Preise entsprechen der offiziellen Website, und durch Auflade-Boni lassen sich effektiv etwa 20 % Rabatt erzielen – ideal für Entwickler, die dieses 744B-Flaggschiff-Modell schnell testen möchten.
Technische Analyse der GLM-5 MoE-Architektur
Warum GLM-5 die MoE-Architektur nutzt
MoE (Mixture of Experts) ist der aktuelle Mainstream-Pfad zur Skalierung großer Modelle. Im Gegensatz zur Dense-Architektur (bei der alle Parameter an jeder Inferenz beteiligt sind) aktiviert die MoE-Architektur pro Token nur einen kleinen Teil des Experten-Netzwerks. So bleibt die enorme Wissenskapazität des Modells erhalten, während die Inferenzkosten drastisch sinken.
Das MoE-Design von GLM-5 weist folgende Schlüsselmerkmale auf:
| Architekturmerkmal | GLM-5 Implementierung | Technischer Mehrwert |
|---|---|---|
| Gesamtanzahl Experten | 256 | Enorme Wissenskapazität |
| Aktivierung pro Token | 8 Experten | Hohe Inferenz-Effizienz |
| Sparsity-Rate | 5,9 % | Nutzt nur einen kleinen Teil der Parameter |
| Attention-Mechanismus | DSA + MLA | Senkt Deployment-Kosten |
| Speicheroptimierung | MLA reduziert Bedarf um 33 % | Geringerer VRAM-Verbrauch |
Vereinfacht gesagt: Obwohl GLM-5 über 744B Parameter verfügt, werden pro Inferenz nur 40B (ca. 5,9 %) aktiviert. Das bedeutet, dass die Inferenzkosten weit unter denen eines gleich großen Dense-Modells liegen, während es gleichzeitig auf das reiche Wissen der 744B Parameter zugreifen kann.
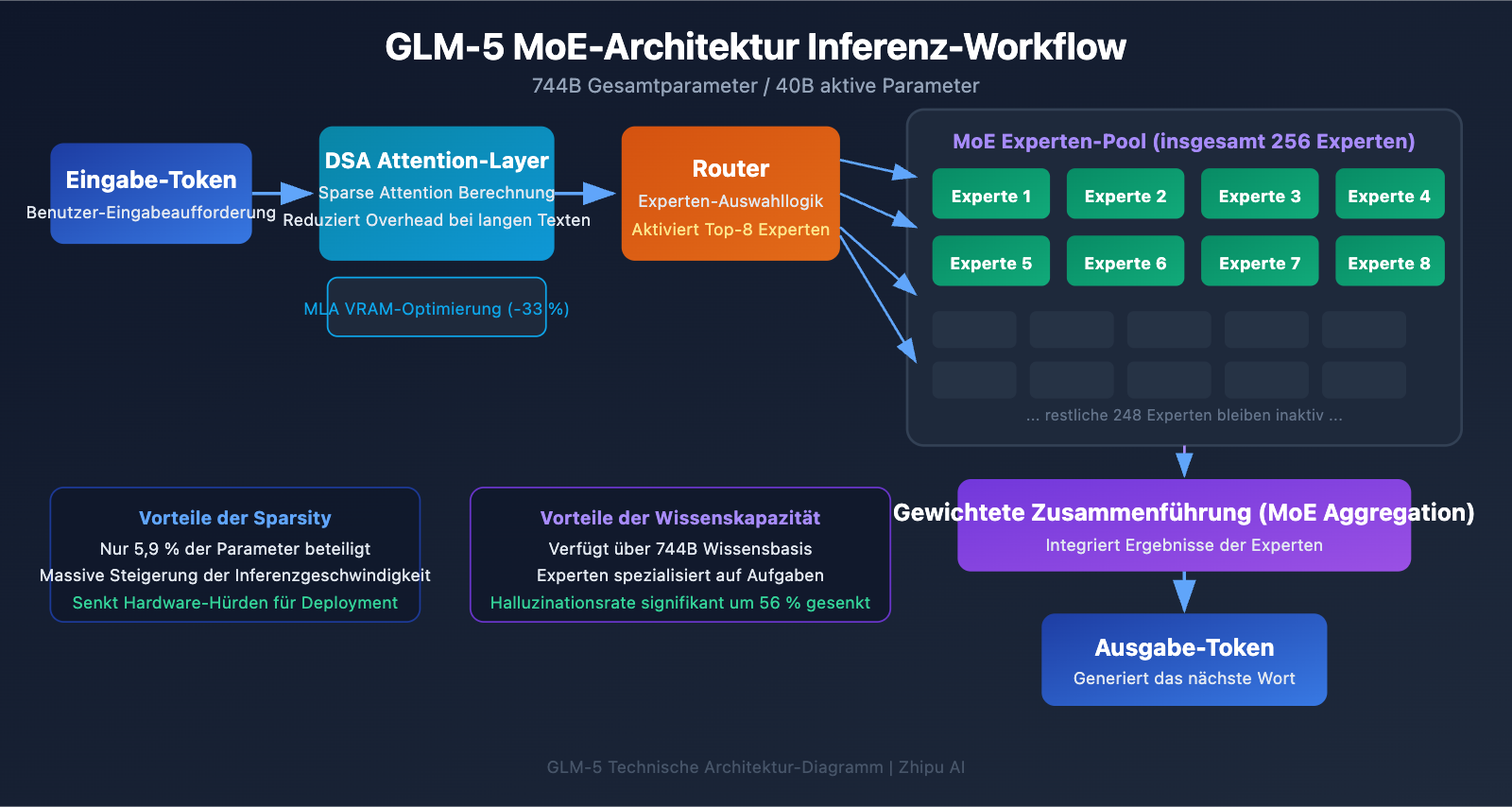
DeepSeek Sparse Attention (DSA) in GLM-5
GLM-5 integriert den DeepSeek Sparse Attention-Mechanismus. Diese Technologie reduziert die Deployment-Kosten erheblich, während die Long-Context-Fähigkeiten erhalten bleiben. In Kombination mit Multi-head Latent Attention (MLA) läuft GLM-5 selbst bei einem Kontextfenster von 200K Tokens hocheffizient.
Im Detail bedeutet das:
- DSA (DeepSeek Sparse Attention): Reduziert die Komplexität der Attention-Berechnung durch spärliche Aufmerksamkeitsmuster. Herkömmliche Full-Attention-Mechanismen erfordern bei 200K Tokens eine enorme Rechenleistung. DSA konzentriert sich selektiv auf kritische Token-Positionen, um den Overhead zu senken, ohne die Informationsintegrität zu gefährden.
- MLA (Multi-head Latent Attention): Komprimiert den KV-Cache der Attention-Heads in einen latenten Raum, was den Speicherverbrauch um etwa 33 % reduziert. In Szenarien mit langem Kontext ist der KV-Cache oft der Hauptverbraucher von Grafikspeicher (VRAM); MLA entschärft diesen Engpass effektiv.
Die Kombination dieser beiden Technologien bedeutet: Selbst ein Modell der 744B-Klasse kann nach einer FP8-Quantisierung auf 8 GPUs betrieben werden, was die Hürden für den Einsatz massiv senkt.
GLM-5 Post-Training: Das asynchrone RL-System "Slime"
Für das Post-Training nutzt GLM-5 eine neue asynchrone Reinforcement Learning (RL) Infrastruktur namens "Slime". Traditionelles RL-Training leidet oft unter Effizienz-Engpässen – es entstehen lange Wartezeiten zwischen den Schritten Generierung, Evaluierung und Aktualisierung. Slime asynchronisiert diese Schritte und ermöglicht so feingranularere Iterationen und einen deutlich höheren Trainingsdurchsatz.
In einem herkömmlichen RL-Prozess muss das Modell erst einen Batch an Inferenzen abschließen, auf die Evaluierungsergebnisse warten und dann die Parameter aktualisieren – diese drei Schritte laufen seriell ab. Slime entkoppelt diese Schritte in unabhängige asynchrone Pipelines, sodass Inferenz, Evaluierung und Aktualisierung parallel stattfinden können.
Diese technische Verbesserung spiegelt sich direkt in der Halluzinationsrate von GLM-5 wider, die im Vergleich zur Vorgängergeneration um 56 % gesenkt wurde. Die intensiveren Post-Training-Iterationen führen zu einer spürbar besseren faktischen Genauigkeit des Modells.
GLM-5 im Vergleich zur Dense-Architektur
Um die Vorteile der MoE-Architektur besser zu verstehen, können wir GLM-5 mit einem hypothetischen Dense-Modell gleicher Größe vergleichen:
| Vergleichsdimension | GLM-5 (744B MoE) | Hypothetisches 744B Dense | Tatsächlicher Unterschied |
|---|---|---|---|
| Parameter pro Inferenz | 40B (5,9 %) | 744B (100 %) | MoE reduziert um 94 % |
| VRAM-Bedarf für Inferenz | 8x GPU (FP8) | ca. 96x GPU | MoE signifikant niedriger |
| Inferenzgeschwindigkeit | Eher schnell | Extrem langsam | MoE besser für Praxiseinsatz |
| Wissenskapazität | Volles 744B Wissen | Volles 744B Wissen | Gleichwertig |
| Spezialisierungsfähigkeit | Experten für versch. Aufgaben | Einheitliche Verarbeitung | MoE ist präziser |
| Trainingskosten | Hoch, aber kontrollierbar | Extrem hoch | MoE bietet besseres Preis-Leistungs-Verhältnis |
Der Kernvorteil der MoE-Architektur liegt darin, dass sie die Wissenskapazität von 744B Parametern bietet, aber nur die Inferenzkosten von 40B Parametern verursacht. Dies ist der Grund, warum GLM-5 Spitzenleistung erbringen kann und gleichzeitig Preise bietet, die weit unter denen vergleichbarer Closed-Source-Modelle liegen.
GLM-5 API-Aufruf: Schnelleinstieg
GLM-5 API-Parameter im Detail
Bevor Sie mit dem Programmieren beginnen, werfen wir einen Blick auf die API-Parameterkonfiguration von GLM-5:
| Parameter | Typ | Erforderlich | Standardwert | Beschreibung |
|---|---|---|---|---|
model |
string | ✅ | – | Festgelegt auf "glm-5" |
messages |
array | ✅ | – | Nachrichten im Standard-Chat-Format |
max_tokens |
int | ❌ | 4096 | Maximale Anzahl an Ausgabe-Token (Limit 128K) |
temperature |
float | ❌ | 1.0 | Sampling-Temperatur, niedriger ist deterministischer |
top_p |
float | ❌ | 1.0 | Nucleus-Sampling-Parameter |
stream |
bool | ❌ | false | Ob die Ausgabe gestreamt werden soll |
thinking |
object | ❌ | disabled | {"type": "enabled"} aktiviert Reasoning |
tools |
array | ❌ | – | Definitionen für Function Calling Tools |
tool_choice |
string | ❌ | auto | Strategie für die Tool-Auswahl |
Minimales GLM-5 Aufrufbeispiel
GLM-5 ist kompatibel mit dem OpenAI SDK-Schnittstellenformat. Sie müssen lediglich die Parameter base_url und model anpassen, um es schnell zu integrieren:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Einheitliche APIYI-Schnittstelle
)
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "Du bist ein erfahrener KI-Experte"},
{"role": "user", "content": "Erkläre die Funktionsweise und Vorteile der MoE (Mixture of Experts) Architektur"}
],
temperature=0.7,
max_tokens=4096
)
print(response.choices[0].message.content)
Dieser Codeabschnitt zeigt die grundlegendste Art, GLM-5 aufzurufen. Die Modell-ID lautet glm-5, und die Schnittstelle ist vollständig kompatibel mit dem chat.completions-Format von OpenAI. Die Migration bestehender Projekte erfordert lediglich die Änderung von zwei Parametern.
GLM-5 Thinking Reasoning-Modus
GLM-5 unterstützt den Thinking Reasoning-Modus, ähnlich den erweiterten Denkfähigkeiten von DeepSeek R1 und Claude. Nach der Aktivierung führt das Modell vor der Antwort eine interne Kettenschluss-Argumentation (Chain-of-Thought) durch, was die Leistung bei komplexen mathematischen, logischen und programmiertechnischen Problemen erheblich steigert:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Einheitliche APIYI-Schnittstelle
)
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "user", "content": "Beweise: Für alle positiven Ganzzahlen n ist n^3 - n durch 6 teilbar"}
],
extra_body={
"thinking": {"type": "enabled"}
},
temperature=1.0 # Für den Thinking-Modus wird 1.0 empfohlen
)
print(response.choices[0].message.content)
Empfehlungen für den GLM-5 Thinking-Modus:
| Szenario | Thinking aktivieren? | Empfohlene Temperatur | Beschreibung |
|---|---|---|---|
| Mathematische Beweise/Wettbewerbe | ✅ Ja | 1.0 | Erfordert tiefes Reasoning |
| Code-Debugging/Architekturdesign | ✅ Ja | 1.0 | Erfordert Systemanalyse |
| Logisches Schlussfolgern/Analyse | ✅ Ja | 1.0 | Erfordert Chain-of-Thought |
| Alltägliche Konversation/Schreiben | ❌ Nein | 0.5-0.7 | Kein komplexes Reasoning nötig |
| Informationsextraktion/Zusammenfassung | ❌ Nein | 0.3-0.5 | Fokus auf stabile Ausgabe |
| Kreative Inhaltserstellung | ❌ Nein | 0.8-1.0 | Erfordert Vielfalt |
GLM-5 Streaming-Ausgabe
Für Szenarien, die eine Echtzeit-Interaktion erfordern, unterstützt GLM-5 die Streaming-Ausgabe. Benutzer können die Ergebnisse schrittweise sehen, während das Modell sie generiert:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
stream = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "user", "content": "Implementiere einen HTTP-Client mit Cache in Python"}
],
stream=True,
temperature=0.6
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
GLM-5 Function Calling und Agent-Erstellung
GLM-5 unterstützt nativ Function Calling, eine Kernkompetenz für den Aufbau von Agent-Systemen. GLM-5 erreichte im Benchmark "HLE w/ Tools" einen Wert von 50,4 % und übertraf damit Claude Opus (43,4 %), was seine hervorragende Leistung bei Tool-Aufrufen und Aufgaben-Orchestrierung unterstreicht:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "search_documents",
"description": "Suche nach relevanten Dokumenten in der Wissensdatenbank",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "Suchbegriff"},
"top_k": {"type": "integer", "description": "Anzahl der Rückgabeergebnisse", "default": 5}
},
"required": ["query"]
}
}
},
{
"type": "function",
"function": {
"name": "execute_code",
"description": "Führe Python-Code in einer Sandbox-Umgebung aus",
"parameters": {
"type": "object",
"properties": {
"code": {"type": "string", "description": "Auszuführender Python-Code"},
"timeout": {"type": "integer", "description": "Timeout (Sekunden)", "default": 30}
},
"required": ["code"]
}
}
}
]
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "Du bist ein KI-Assistent, der Dokumente durchsuchen und Code ausführen kann"},
{"role": "user", "content": "Suche die technischen Parameter von GLM-5 heraus und erstelle dann mit Code ein Leistungsvergleichsdiagramm"}
],
tools=tools,
tool_choice="auto"
)
# Tool-Aufruf verarbeiten
message = response.choices[0].message
if message.tool_calls:
for tool_call in message.tool_calls:
print(f"Tool aufgerufen: {tool_call.function.name}")
print(f"Parameter: {tool_call.function.arguments}")
cURL-Beispiel anzeigen
curl https://api.apiyi.com/v1/chat/completions \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "glm-5",
"messages": [
{"role": "system", "content": "Du bist ein erfahrener Software-Ingenieur"},
{"role": "user", "content": "Entwirf die Architektur für ein verteiltes Aufgabenplanungssystem"}
],
"max_tokens": 8192,
"temperature": 0.7,
"stream": true
}'
🎯 Technischer Tipp: GLM-5 ist kompatibel mit dem OpenAI SDK-Format. Bestehende Projekte können durch einfaches Ändern der Parameter
base_urlundmodelmigriert werden. Durch den Aufruf über die Plattform APIYI (apiyi.com) profitieren Sie von einer einheitlichen Schnittstellenverwaltung und Bonusguthaben bei Aufladungen.
GLM-5 Benchmark Leistungstest
GLM-5 Kern-Benchmark-Daten
GLM-5 zeigt in mehreren gängigen Benchmarks das stärkste Niveau unter den Open-Source-Modellen:
| Benchmark | GLM-5 | Claude Opus 4.5 | GPT-5 | Testinhalt |
|---|---|---|---|---|
| MMLU | 85.0% | 88.7% | 90.2% | 57 Fachbereiche |
| MMLU Pro | 70.4% | – | – | Erweiterte Multidisziplinarität |
| GPQA | 68.2% | 71.4% | 73.1% | Wissenschaft auf Graduiertenniveau |
| HumanEval | 90.0% | 93.2% | 92.5% | Python-Programmierung |
| MATH | 88.0% | 90.1% | 91.3% | Mathematisches Schlussfolgern |
| GSM8k | 97.0% | 98.2% | 98.5% | Mathematische Textaufgaben |
| AIME 2026 I | 92.7% | 93.3% | – | Mathematik-Wettbewerb |
| SWE-bench | 77.8% | 80.9% | 80.0% | Reale Softwareentwicklung |
| HLE w/ Tools | 50.4% | 43.4% | – | Reasoning mit Tools |
| IFEval | 88.0% | – | – | Anweisungsbefolgung |
| Terminal-Bench | 56.2% | 57.9% | – | Terminal-Operationen |
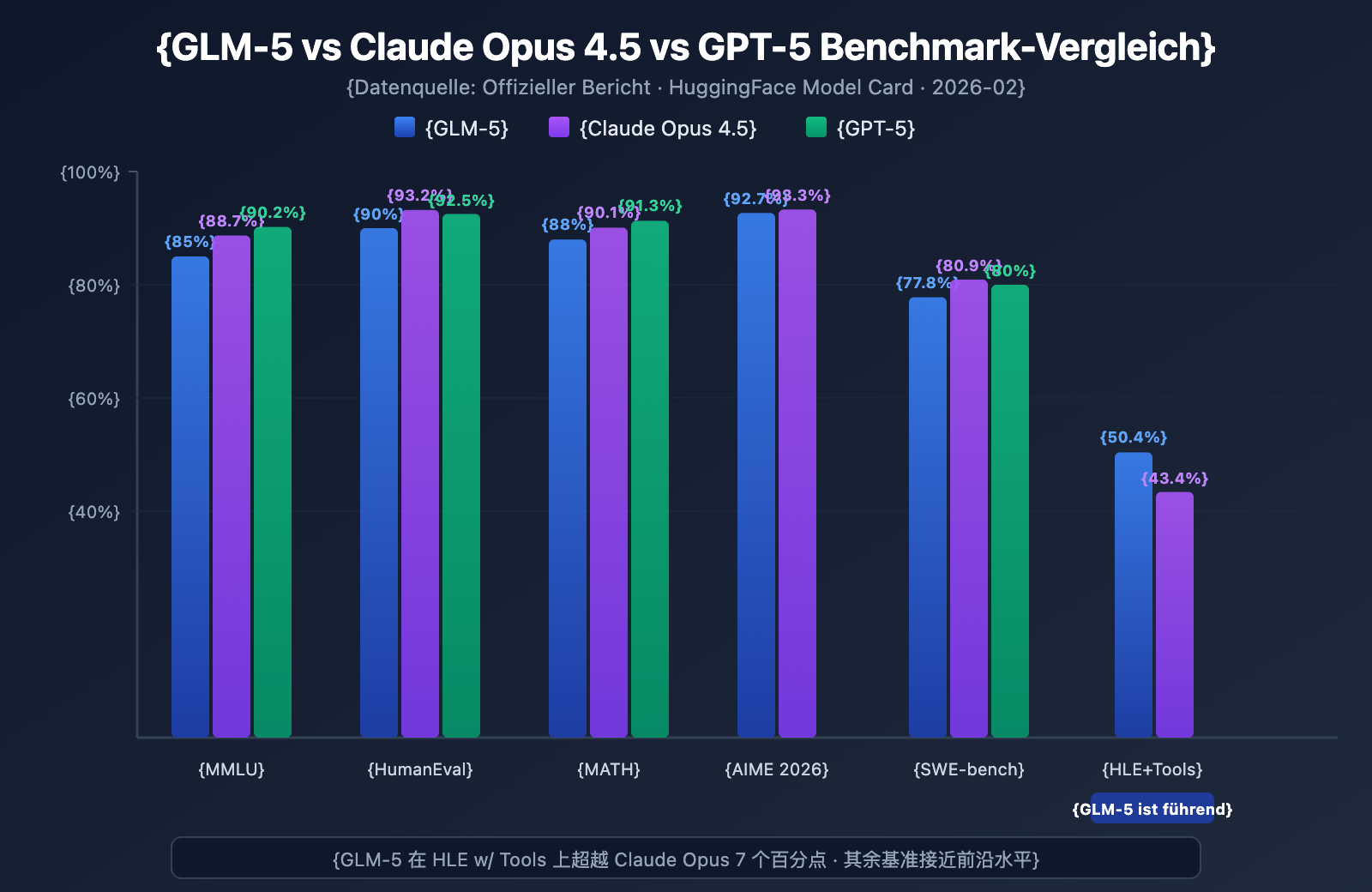
GLM-5 Leistungsanalyse: 4 Kernvorteile
Die Benchmark-Daten zeigen einige bemerkenswerte Punkte:
1. GLM-5 Agent-Fähigkeiten: HLE w/ Tools übertrifft proprietäre Modelle
GLM-5 erreichte im "Humanity's Last Exam" (mit Tool-Nutzung) einen Wert von 50,4 % und übertraf damit Claude Opus (43,4 %), womit es nur knapp hinter Kimi K2.5 (51,8 %) liegt. Dies zeigt, dass GLM-5 in Agent-Szenarien – die Planung, Tool-Aufrufe und iterative Problemlösung für komplexe Aufgaben erfordern – bereits das Niveau modernster Modelle erreicht hat.
Dieses Ergebnis deckt sich mit der Designphilosophie von GLM-5: Es wurde von der Architektur bis zum Post-Training speziell für Agent-Workflows optimiert. Für Entwickler, die KI-Agent-Systeme aufbauen möchten, bietet GLM-5 eine leistungsstarke und kosteneffiziente Open-Source-Alternative.
2. GLM-5 Coding-Fähigkeiten: Eintritt in die erste Riege
Mit 90 % bei HumanEval und 77,8 % bei SWE-bench Verified zeigt GLM-5, dass es bei der Codegenerierung und realen Softwareentwicklungsaufgaben sehr nah an das Niveau von Claude Opus (80,9 %) und GPT-5 (80,0 %) herankommt. Für ein Open-Source-Modell ist ein SWE-bench-Wert von 77,8 % ein bedeutender Durchbruch – es bedeutet, dass GLM-5 in der Lage ist, echte GitHub-Issues zu verstehen, Codeprobleme zu lokalisieren und effektive Fixes einzureichen.
3. GLM-5 Mathematisches Reasoning: Nahe an der Obergrenze
Bei AIME 2026 I erreichte GLM-5 92,7 % und liegt damit nur 0,6 Prozentpunkte hinter Claude Opus. GSM8k mit 97 % zeigt zudem, dass GLM-5 bei mathematischen Problemen mittlerer Schwierigkeit äußerst zuverlässig ist. Auch der MATH-Wert von 88 % platziert das Modell in der Spitzengruppe.
4. GLM-5 Halluzinationskontrolle: Drastisch reduziert
Laut offiziellen Daten wurde die Halluzinationsrate von GLM-5 im Vergleich zur Vorgängergeneration um 56 % gesenkt. Dies ist dem asynchronen RL-System "Slime" zu verdanken, das umfassendere Post-Training-Iterationen ermöglicht. In Szenarien, die eine hohe Genauigkeit erfordern – wie Informationsextraktion, Dokumentenzusammenfassung und Wissensdatenbank-Abfragen –, führt eine geringere Halluzinationsrate direkt zu einer zuverlässigeren Ausgabequalität.
Positionierung von GLM-5 im Vergleich zu Open-Source-Modellen
In der aktuellen Wettbewerbslandschaft der Open-Source-Großsprachmodelle ist die Positionierung von GLM-5 klar definiert:
| Modell | Parameter-Skalierung | Architektur | Kernvorteile | Lizenz |
|---|---|---|---|---|
| GLM-5 | 744B (40B aktiv) | MoE | Agent + geringe Halluzinationen | Apache-2.0 |
| DeepSeek V3 | 671B (37B aktiv) | MoE | Preis-Leistung + Reasoning | MIT |
| Llama 4 Maverick | 400B (17B aktiv) | MoE | Multimodal + Ökosystem | Llama License |
| Qwen 3 | 235B | Dense | Multilingual + Tools | Apache-2.0 |
Die Differenzierungsvorteile von GLM-5 liegen vor allem in drei Bereichen: der speziellen Optimierung für Agent-Workflows (führend bei HLE w/ Tools), der extrem niedrigen Halluzinationsrate (Reduktion um 56 %) sowie der Versorgungssicherheit durch das Training auf rein inländischen Rechenkapazitäten. Für Unternehmen, die modernste Open-Source-Modelle lokal einsetzen müssen, ist GLM-5 eine Option, die man im Auge behalten sollte.
GLM-5 Preisgestaltung und Kostenanalyse
Offizielle GLM-5 Preise
| Abrechnungstyp | Offizieller Z.ai Preis | OpenRouter Preis | Beschreibung |
|---|---|---|---|
| Input-Token | $1.00/M | $0.80/M | Pro Million Input-Token |
| Output-Token | $3.20/M | $2.56/M | Pro Million Output-Token |
| Cache-Input | $0.20/M | $0.16/M | Input-Preis bei Cache-Treffern |
| Cache-Speicherung | Vorübergehend kostenlos | – | Gebühren für die Speicherung von Cache-Daten |
Preisvergleich: GLM-5 vs. Wettbewerber
Die Preisstrategie von GLM-5 ist äußerst wettbewerbsfähig, insbesondere im Vergleich zu proprietären Closed-Source-Frontier-Modellen:
| Modell | Input ($/M) | Output ($/M) | Relative Kosten zu GLM-5 | Modell-Positionierung |
|---|---|---|---|---|
| GLM-5 | $1.00 | $3.20 | Basis | Open-Source-Flaggschiff |
| Claude Opus 4.6 | $5.00 | $25.00 | ca. 5-8x | Closed-Source-Flaggschiff |
| GPT-5 | $1.25 | $10.00 | ca. 1.3-3x | Closed-Source-Flaggschiff |
| DeepSeek V3 | $0.27 | $1.10 | ca. 0.3x | Open-Source Preis-Leistung |
| GLM-4.7 | $0.60 | $2.20 | ca. 0.6-0.7x | Flaggschiff der letzten Generation |
| GLM-4.7-FlashX | $0.07 | $0.40 | ca. 0.07-0.13x | Extrem kostengünstig |
Preislich positioniert sich GLM-5 zwischen GPT-5 und DeepSeek V3 – deutlich günstiger als die meisten Closed-Source-Frontier-Modelle, aber etwas teurer als leichtgewichtige Open-Source-Modelle. In Anbetracht der Parametergröße von 744B und der stärksten Performance im Open-Source-Bereich ist diese Preisgestaltung absolut angemessen.
Die gesamte GLM-Produktlinie und Preise
Falls GLM-5 nicht exakt zu Ihrem Szenario passt, bietet Zhipu eine vollständige Produktpalette zur Auswahl:
| Modell | Input ($/M) | Output ($/M) | Anwendungsbereiche |
|---|---|---|---|
| GLM-5 | $1.00 | $3.20 | Komplexe Logik, Agenten, lange Dokumente |
| GLM-5-Code | $1.20 | $5.00 | Spezialisiert auf Code-Entwicklung |
| GLM-4.7 | $0.60 | $2.20 | Allgemeine Aufgaben mittlerer Komplexität |
| GLM-4.7-FlashX | $0.07 | $0.40 | Hochfrequente, kostengünstige Aufrufe |
| GLM-4.5-Air | $0.20 | $1.10 | Leichtgewichtige Balance |
| GLM-4.7/4.5-Flash | Kostenlos | Kostenlos | Einstiegserfahrung und einfache Aufgaben |
💰 Kostenoptimierung: GLM-5 ist bereits auf APIYI (apiyi.com) verfügbar, wobei die Preise dem offiziellen Z.ai-Niveau entsprechen. Durch Auflade-Boni auf der Plattform können die tatsächlichen Nutzungskosten auf etwa 80 % des offiziellen Preises gesenkt werden – ideal für Teams und Entwickler mit kontinuierlichem Bedarf.
GLM-5 Anwendungsbereiche und Auswahlempfehlungen
Für welche Szenarien eignet sich GLM-5?
Basierend auf den technischen Merkmalen und Benchmark-Ergebnissen von GLM-5 folgen hier spezifische Empfehlungen:
Dringend empfohlene Szenarien:
- Agent-Workflows: GLM-5 wurde speziell für langzyklische Agent-Aufgaben entwickelt. Mit 50,4 % im HLE w/ Tools übertrifft es Claude Opus und eignet sich hervorragend für den Aufbau autonomer Agent-Systeme mit Planung und Tool-Nutzung.
- Software-Engineering: Mit 90 % in HumanEval und 77,8 % in SWE-bench ist es bestens geeignet für Code-Generierung, Bug-Fixing, Code-Reviews und Architekturdesign.
- Mathematik und wissenschaftliche Logik: 92,7 % in AIME und 88 % in MATH machen es ideal für mathematische Beweise, Formelherleitungen und wissenschaftliche Berechnungen.
- Analyse extrem langer Dokumente: Das 200K Kontextfenster ermöglicht die Verarbeitung kompletter Code-Repositories, technischer Dokumentationen, juristischer Verträge und anderer langer Texte.
- Frage-Antwort-Systeme mit geringer Halluzination: Die Halluzinationsrate wurde um 56 % reduziert, was es ideal für Wissensdatenbanken (RAG) und Zusammenfassungen macht, bei denen hohe Genauigkeit gefragt ist.
Szenarien, in denen andere Lösungen in Betracht kommen:
- Multimodale Aufgaben: GLM-5 unterstützt nativ nur Text. Für Bildverständnis sollten Sie visuelle Modelle wie GLM-4.6V wählen.
- Extreme Niedriglatenz: Die Inferenzgeschwindigkeit eines 744B MoE-Modells reicht nicht an die von kleineren Modellen heran. Für hochfrequente Szenarien mit geringer Latenz empfiehlt sich GLM-4.7-FlashX.
- Batch-Verarbeitung bei extrem niedrigen Kosten: Wenn bei der Verarbeitung riesiger Textmengen die Qualität nicht an oberster Stelle steht, bieten DeepSeek V3 oder GLM-4.7-FlashX geringere Kosten.
Auswahlvergleich: GLM-5 vs. GLM-4.7
| Vergleichsdimension | GLM-5 | GLM-4.7 | Auswahlempfehlung |
|---|---|---|---|
| Parametergröße | 744B (40B aktiv) | Nicht veröffentlicht | GLM-5 ist größer |
| Logikfähigkeiten | AIME 92,7% | ~85% | Für komplexe Logik GLM-5 wählen |
| Agent-Fähigkeiten | HLE w/ Tools 50,4% | ~38% | Für Agent-Aufgaben GLM-5 wählen |
| Coding-Fähigkeiten | HumanEval 90% | ~85% | Für Code-Entwicklung GLM-5 wählen |
| Halluzinationskontrolle | 56% Reduktion | Basis | Für hohe Genauigkeit GLM-5 wählen |
| Input-Preis | $1.00/M | $0.60/M | Bei Kostensensibilität GLM-4.7 |
| Output-Preis | $3.20/M | $2.20/M | Bei Kostensensibilität GLM-4.7 |
| Kontextlänge | 200K | 128K+ | Für lange Dokumente GLM-5 wählen |
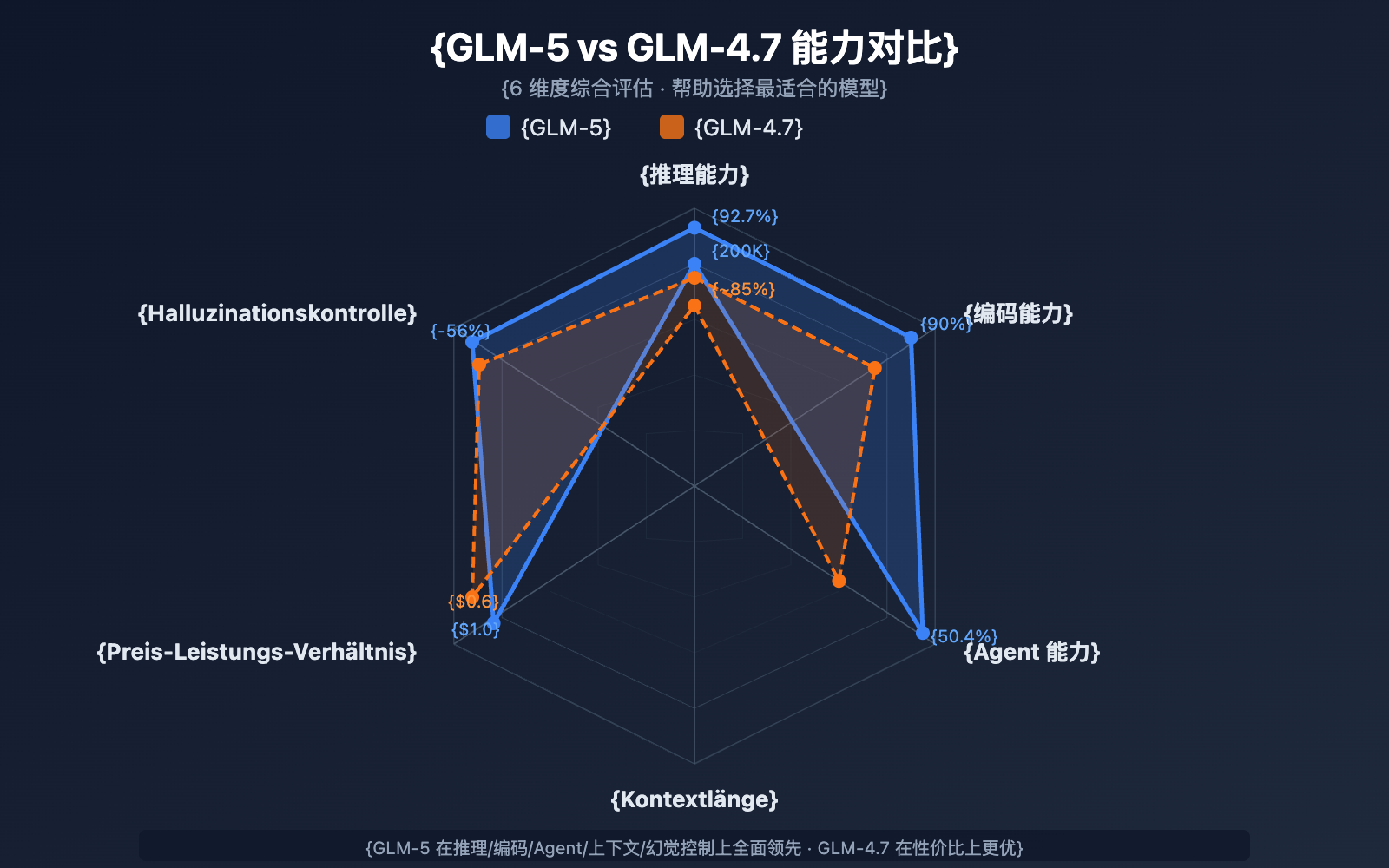
💡 Auswahlempfehlung: Wenn Ihr Projekt erstklassige Logikfähigkeiten, Agent-Workflows oder die Verarbeitung extrem langer Kontexte erfordert, ist GLM-5 die bessere Wahl. Wenn das Budget begrenzt ist und die Aufgabenkomplexität moderat bleibt, bietet GLM-4.7 ein hervorragendes Preis-Leistungs-Verhältnis. Beide Modelle können über die APIYI-Plattform (apiyi.com) aufgerufen werden, was einen einfachen Wechsel für Tests ermöglicht.
GLM-5 API-Aufruf: Häufig gestellte Fragen (FAQ)
Q1: Was ist der Unterschied zwischen GLM-5 und GLM-5-Code?
GLM-5 ist das allgemeine Flaggschiff-Modell (Eingabe $1.00/M, Ausgabe $3.20/M) und eignet sich für alle Arten von Textaufgaben. GLM-5-Code ist eine speziell für Code optimierte Version (Eingabe $1.20/M, Ausgabe $5.00/M), die zusätzlich für die Codegenerierung, das Debugging und Engineering-Aufgaben verbessert wurde. Wenn Ihr Hauptanwendungsfall die Softwareentwicklung ist, ist GLM-5-Code einen Versuch wert. Beide Modelle unterstützen den Aufruf über eine einheitliche, OpenAI-kompatible Schnittstelle.
Q2: Beeinflusst der Thinking-Modus von GLM-5 die Ausgabegeschwindigkeit?
Ja. Im Thinking-Modus generiert GLM-5 zunächst eine interne Argumentationskette (Reasoning Chain), bevor die endgültige Antwort ausgegeben wird. Daher erhöht sich die Latenz bis zum ersten Token (TTFT). Für einfache Fragen wird empfohlen, den Thinking-Modus zu deaktivieren, um eine schnellere Antwort zu erhalten. Bei komplexen mathematischen, programmiertechnischen und logischen Problemen sollte er jedoch aktiviert werden; die Antwort dauert zwar etwas länger, aber die Genauigkeit steigt deutlich.
Q3: Welche Code-Änderungen sind für den Umstieg von GPT-4 oder Claude auf GLM-5 erforderlich?
Die Migration ist sehr einfach, Sie müssen lediglich zwei Parameter anpassen:
- Ändern Sie die
base_urlauf die Schnittstellenadresse von APIYI:https://api.apiyi.com/v1 - Ändern Sie den Parameter
modelauf"glm-5"
GLM-5 ist vollständig kompatibel mit dem Format der chat.completions-Schnittstelle des OpenAI SDKs, einschließlich der Rollen system/user/assistant, Streaming-Ausgabe, Function Calling und weiterer Funktionen. Über eine einheitliche API-Plattform können Sie zudem unter demselben API-Key zwischen Modellen verschiedener Anbieter wechseln, was A/B-Tests sehr komfortabel macht.
Q4: Unterstützt GLM-5 die Eingabe von Bildern?
Nein. GLM-5 ist ein reines Textmodell und unterstützt keine Eingabe von Bildern, Audio oder Video. Wenn Sie Bildverarbeitungsfunktionen benötigen, können Sie die visuellen Varianten von Zhipu verwenden, wie z. B. GLM-4.6V oder GLM-4.5V.
Q5: Wie verwende ich die Context-Caching-Funktion von GLM-5?
GLM-5 unterstützt Context Caching (Kontext-Zwischenspeicherung). Der Preis für zwischengespeicherte Eingaben beträgt nur $0.20/M, was einem Fünftel der normalen Eingabe entspricht. In langen Dialogen oder Szenarien, in denen derselbe Präfix wiederholt verarbeitet werden muss, kann die Caching-Funktion die Kosten erheblich senken. Die Speicherung des Caches ist derzeit vorübergehend kostenlos. In Multi-Turn-Dialogen erkennt das System automatisch wiederholte Kontext-Präfixe und speichert diese zwischen.
Q6: Was ist die maximale Ausgabelänge von GLM-5?
GLM-5 unterstützt eine maximale Ausgabelänge von 128.000 Tokens. Für die meisten Szenarien sind die standardmäßigen 4096 Tokens völlig ausreichend. Wenn Sie lange Texte generieren müssen (z. B. vollständige technische Dokumentationen oder umfangreiche Codeblöcke), können Sie dies über den Parameter max_tokens anpassen. Beachten Sie jedoch, dass mit zunehmender Ausgabelänge auch der Token-Verbrauch und die Wartezeit steigen.
Best Practices für GLM-5 API-Aufrufe
Bei der praktischen Nutzung von GLM-5 können Ihnen die folgenden Erfahrungswerte helfen, bessere Ergebnisse zu erzielen:
Optimierung des GLM-5 System-Prompts
GLM-5 reagiert sehr präzise auf System-Prompts (System-Eingabeaufforderungen). Ein gut durchdachter System-Prompt kann die Ausgabequalität erheblich steigern:
# Empfohlen: Klare Rollendefinition + Anforderungen an das Ausgabeformat
messages = [
{
"role": "system",
"content": """Du bist ein erfahrener Architekt für verteilte Systeme.
Bitte befolge diese Regeln:
1. Die Antwort muss strukturiert sein und das Markdown-Format verwenden.
2. Liefere konkrete technische Lösungen statt allgemeiner Aussagen.
3. Wenn Code involviert ist, stelle ausführbare Beispiele bereit.
4. Markiere an geeigneten Stellen potenzielle Risiken und Vorsichtshinweise."""
},
{
"role": "user",
"content": "Entwirf ein Message-Queue-System, das Millionen von gleichzeitigen Verbindungen unterstützt."
}
]
Leitfaden zur GLM-5 Temperature-Optimierung
Verschiedene Aufgaben reagieren unterschiedlich auf den temperature-Parameter. Hier sind praxisnahe Empfehlungen:
- temperature 0.1-0.3: Für Aufgaben, die präzise Ausgaben erfordern, wie Codegenerierung, Datenextraktion oder Formatkonvertierung.
- temperature 0.5-0.7: Für technische Dokumentationen, Q&A oder Zusammenfassungen, die stabil, aber dennoch sprachlich flexibel sein sollen.
- temperature 0.8-1.0: Für kreatives Schreiben, Brainstorming und Aufgaben, die Vielfalt erfordern.
- temperature 1.0 (Thinking-Modus): Für mathematische Beweise, komplexe Programmierung und Aufgaben mit tiefgehender Logik.
Tipps zum Umgang mit langem Kontext in GLM-5
GLM-5 unterstützt ein Kontextfenster von 200K Tokens. In der Praxis sollten Sie jedoch Folgendes beachten:
- Wichtige Informationen an den Anfang: Platzieren Sie den entscheidenden Kontext an den Anfang des Prompts, nicht ans Ende.
- Segmentierung: Bei Dokumenten mit mehr als 100K Tokens empfiehlt es sich, diese segmentiert zu verarbeiten und die Ergebnisse später zusammenzuführen, um eine stabilere Ausgabe zu erhalten.
- Caching nutzen: In Multi-Turn-Dialogen werden identische Präfixe automatisch zwischengespeichert. Der Preis für diesen Cache-Input liegt bei nur $0.20/M.
- Ausgabelänge kontrollieren: Setzen Sie bei langen Kontext-Eingaben den Parameter
max_tokensangemessen, um unnötig lange Ausgaben und damit verbundene Kosten zu vermeiden.
Referenz für die lokale Bereitstellung von GLM-5
Wenn Sie GLM-5 auf Ihrer eigenen Infrastruktur bereitstellen möchten, sind dies die wichtigsten Methoden:
| Bereitstellungsmethode | Empfohlene Hardware | Präzision | Merkmale |
|---|---|---|---|
| vLLM | 8x A100/H100 | FP8 | Gängiges Inference-Framework, unterstützt spekulative Dekodierung |
| SGLang | 8x H100/B200 | FP8 | Hochleistungs-Inferenz, optimiert für Blackwell-GPUs |
| xLLM | Huawei Ascend NPU | BF16/FP8 | Anpassung an lokale (chinesische) Rechenleistung |
| KTransformers | Consumer-GPUs | Quantisierung | GPU-beschleunigte Inferenz |
| Ollama | Consumer-Hardware | Quantisierung | Einfachste lokale Erfahrung |
GLM-5 bietet zwei Gewichtungsformate: BF16 (volle Präzision) und FP8 (quantisiert). Diese können von HuggingFace (huggingface.co/zai-org/GLM-5) oder ModelScope heruntergeladen werden. Die FP8-quantisierte Version reduziert den Bedarf an Grafikspeicher (VRAM) erheblich, während der Großteil der Leistung erhalten bleibt.
Wichtige Konfigurationen für die Bereitstellung von GLM-5:
- Tensor-Parallelität: 8-fach (tensor-parallel-size 8)
- VRAM-Auslastung: Empfohlen auf 0,85 eingestellt
- Tool-Call-Parser: glm47
- Inference-Parser: glm45
- Spekulative Dekodierung: Unterstützt sowohl MTP- als auch EAGLE-Methoden
Für die meisten Entwickler ist der Aufruf über eine API der effizienteste Weg. Dies spart Kosten für Bereitstellung und Wartung, sodass Sie sich voll auf die Anwendungsentwicklung konzentrieren können. Szenarien, die eine private Bereitstellung erfordern, finden Informationen in der offiziellen Dokumentation:
github.com/zai-org/GLM-5
Zusammenfassung der GLM-5 API-Nutzung
GLM-5 Kernkompetenzen im Überblick
| Fähigkeitsdimension | GLM-5 Performance | Anwendungsbereiche |
|---|---|---|
| Reasoning | AIME 92,7 %, MATH 88 % | Mathematische Beweise, wissenschaftliches Denken, Logikanalyse |
| Coding | HumanEval 90 %, SWE-bench 77,8 % | Codegenerierung, Bugfixing, Architekturdesign |
| Agent | HLE w/ Tools 50,4 % | Tool-Aufrufe, Aufgabenplanung, autonome Ausführung |
| Wissen | MMLU 85 %, GPQA 68,2 % | Fachspezifische Fragen & Antworten, technische Beratung, Wissensextraktion |
| Anweisungen | IFEval 88 % | Formatierte Ausgabe, strukturierte Generierung, Regeleinhaltung |
| Genauigkeit | Halluzinationsrate um 56 % reduziert | Dokumentenzusammenfassung, Faktencheck, Informationsextraktion |
Wert des GLM-5 Open-Source-Ökosystems
GLM-5 ist unter der Apache-2.0-Lizenz quelloffen, was bedeutet:
- Kommerzielle Freiheit: Unternehmen können das Modell kostenlos nutzen, modifizieren und verbreiten, ohne Lizenzgebühren zu zahlen.
- Feintuning & Anpassung: GLM-5 kann auf spezifische Domänen feingetunt werden, um branchenspezifische Modelle zu erstellen.
- Private Bereitstellung: Sensible Daten verlassen nicht das interne Netzwerk, was Compliance-Anforderungen in Bereichen wie Finanzen, Medizin und Behörden erfüllt.
- Community-Ökosystem: Auf HuggingFace gibt es bereits über 11 quantisierte Varianten und mehr als 7 feingetunte Versionen; das Ökosystem wächst stetig.
Als neuestes Flaggschiff-Modell von Zhipu AI setzt GLM-5 neue Maßstäbe im Bereich der Open-Source-Großsprachmodelle:
- 744B MoE-Architektur: Ein System mit 256 Experten, bei dem pro Inferenz 40B Parameter aktiviert werden. Dies schafft eine hervorragende Balance zwischen Modellkapazität und Inferenz-Effizienz.
- Stärkster Open-Source-Agent: Mit 50,4 % im HLE w/ Tools übertrifft es Claude Opus und ist speziell für komplexe Agent-Workflows konzipiert.
- Training auf lokaler Rechenleistung: Trainiert auf 100.000 Huawei Ascend-Chips, was die Leistungsfähigkeit lokaler Rechen-Stacks für modernstes Modelltraining beweist.
- Hohe Kosteneffizienz: Mit Preisen von $1/M (Input) und $3.2/M (Output) liegt es weit unter vergleichbaren Closed-Source-Modellen; die Open-Source-Community kann es frei bereitstellen und anpassen.
- 200K extrem langer Kontext: Unterstützt die Verarbeitung kompletter Code-Repositories und großer technischer Dokumente in einem Durchgang, mit einer maximalen Ausgabe von 128K Token.
- 56 % weniger Halluzinationen: Das Slime asynchrone RL-Post-Training hat die faktische Genauigkeit massiv verbessert.
Wir empfehlen, die verschiedenen Funktionen von GLM-5 schnell über APIYI (apiyi.com) auszuprobieren. Die Plattformpreise entsprechen den offiziellen Tarifen, und durch Auflade-Boni können Sie effektiv von etwa 20 % Rabatt profitieren.
Dieser Artikel wurde vom APIYI Team verfasst. Weitere Tutorials zur Nutzung von KI-Modellen finden Sie im Hilfe-Center von APIYI auf apiyi.com.