Enfrentar o erro 429 You exceeded your current quota frequentemente ao desenvolver aplicações de IA com o Qwen3-Max é uma dor de cabeça para muitos desenvolvedores. Este artigo analisará profundamente o mecanismo de limitação de velocidade do Qwen3-Max da Alibaba Cloud e oferecerá 5 soluções práticas para ajudar você a se livrar de vez dos problemas de falta de cota.
Valor central: Ao ler este artigo, você entenderá o princípio da limitação do Qwen3-Max, dominará diversas soluções e saberá escolher a forma mais adequada para realizar chamadas estáveis a este Modelo de Linguagem Grande de trilhões de parâmetros.
Visão Geral do Problema de Limite no Qwen3-Max
Mensagem de Erro Típica
Quando sua aplicação faz chamadas frequentes à API do Qwen3-Max, você pode se deparar com o seguinte erro:
{
"error": {
"message": "You exceeded your current quota, please check your plan and billing details.",
"type": "insufficient_quota",
"code": "insufficient_quota"
},
"status": 429
}
Esse erro significa que você atingiu os limites de cota do Model Studio da Alibaba Cloud.
Impacto dos Limites de Velocidade no Qwen3-Max
| Cenário de Impacto | Comportamento Específico | Gravidade |
|---|---|---|
| Desenvolvimento de Agentes | Interrupção frequente de diálogos multi-turno | Alta |
| Processamento em Lote | Tarefas não conseguem ser concluídas | Alta |
| Aplicações em Tempo Real | Experiência do usuário prejudicada | Alta |
| Geração de Código | Saída de código longo truncada | Média |
| Testes e Debugging | Queda na eficiência de desenvolvimento | Média |
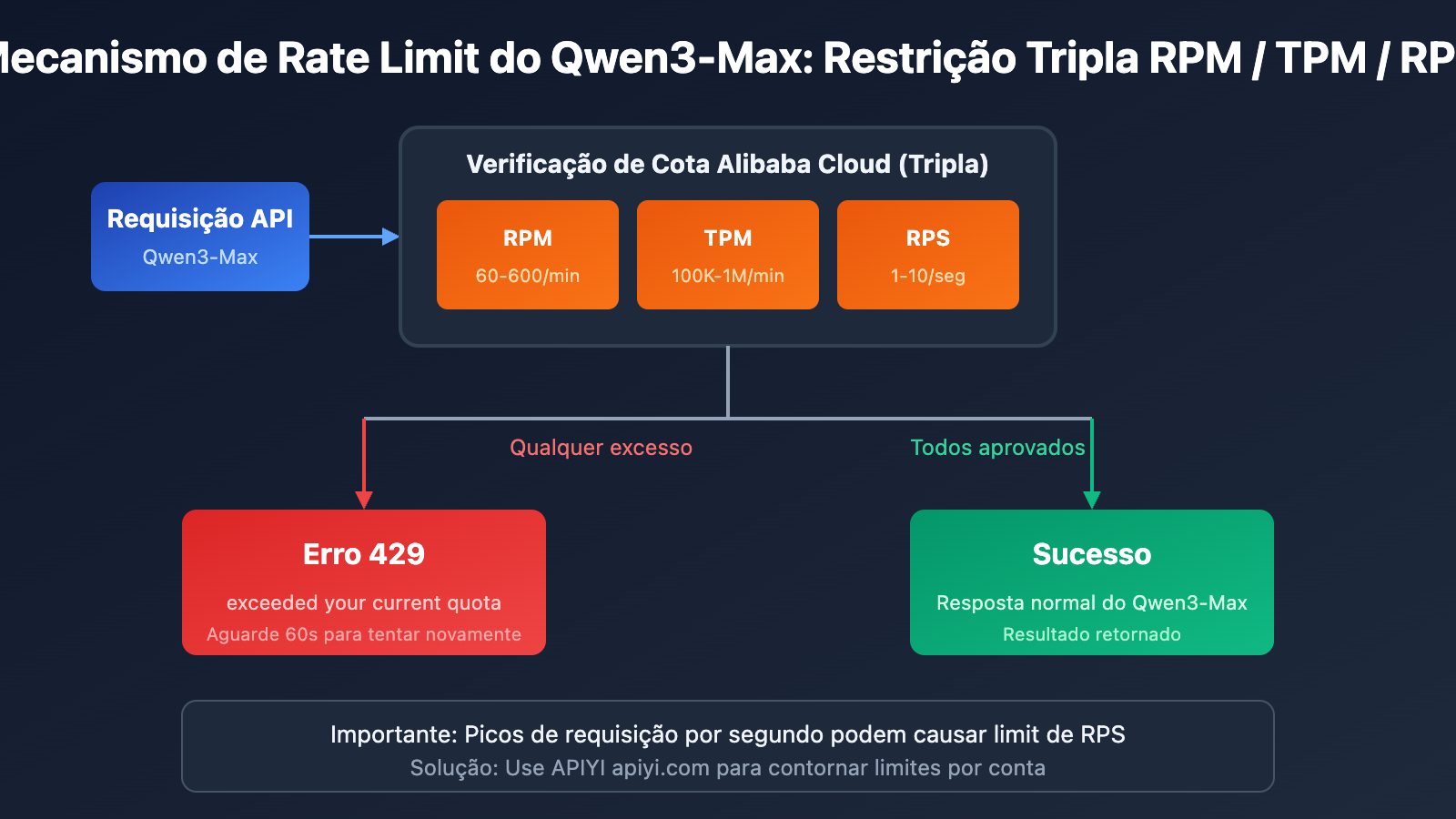
Detalhes do Mecanismo de Limite de Taxa (Rate Limit) do Qwen3-Max
Limites de Cota Oficiais do Alibaba Cloud
De acordo com a documentação oficial do Alibaba Cloud Model Studio, os limites de cota para o Qwen3-Max são os seguintes:
| Versão do Modelo | RPM (Requisições/Min) | TPM (Tokens/Min) | RPS (Requisições/Seg) |
|---|---|---|---|
| qwen3-max | 600 | 1.000.000 | 10 |
| qwen3-max-2025-09-23 | 60 | 100.000 | 1 |
4 Casos que Ativam o Limite de Taxa do Qwen3-Max
O Alibaba Cloud implementa um mecanismo de restrição dupla para o Qwen3-Max. Se qualquer uma dessas condições for atingida, um erro 429 será retornado:
| Tipo de Erro | Mensagem de Erro | Causa |
|---|---|---|
| Excesso de Frequência | Requests rate limit exceeded | RPM/RPS excedeu o limite |
| Excesso de Tokens | You exceeded your current quota | TPM/TPS excedeu o limite |
| Proteção de Tráfego Repentino | Request rate increased too quickly | Aumento súbito de requisições instantâneas |
| Cota Gratuita Esgotada | Free allocated quota exceeded | Limite de teste finalizado |
Fórmula de Cálculo do Limite
Limite Real = min(Limite RPM, RPS × 60)
= min(Limite TPM, TPS × 60)
Dica importante: Mesmo que o limite por minuto não tenha sido atingido, requisições simultâneas em massa no nível de segundos podem disparar o bloqueio.
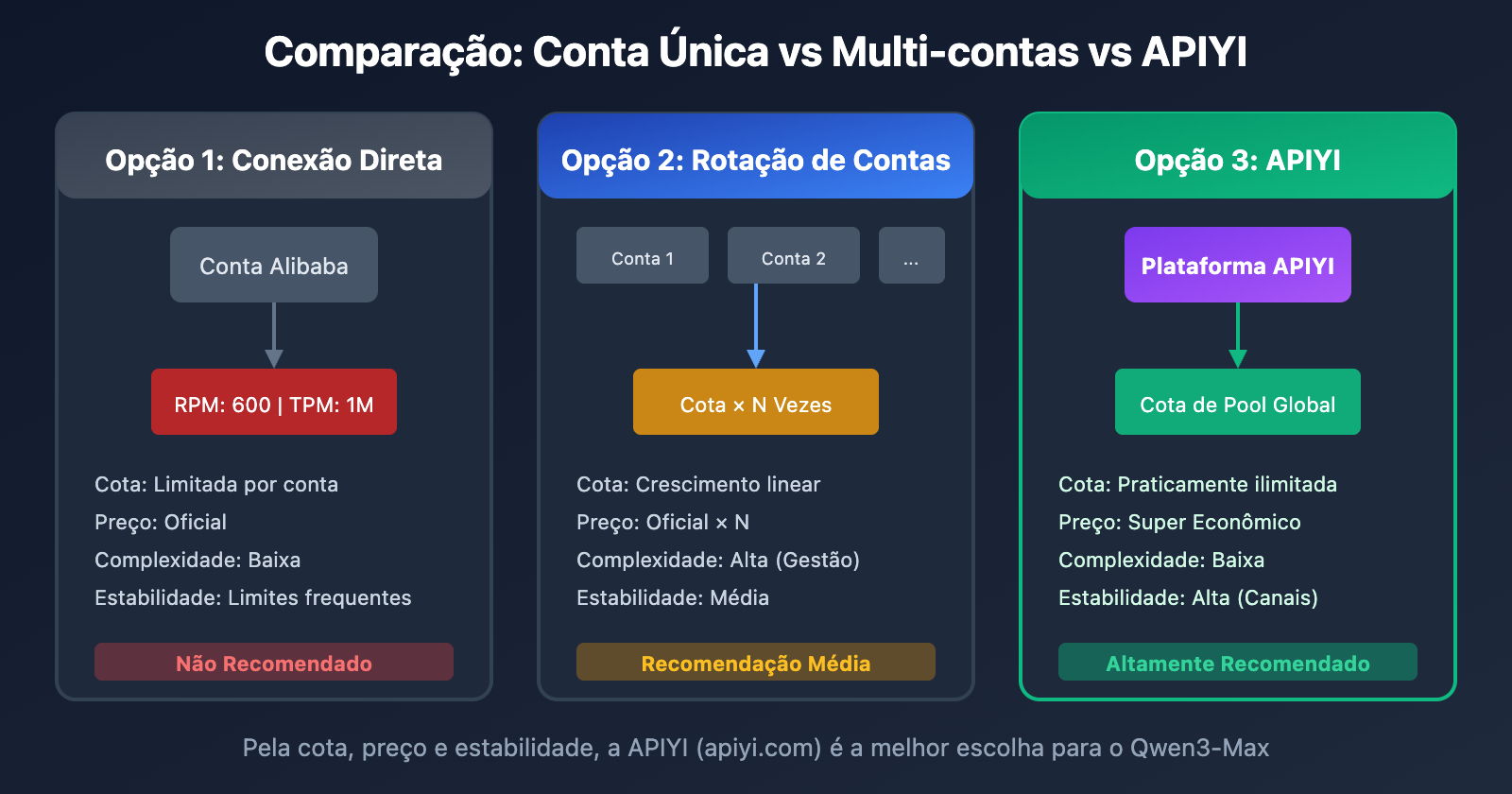
5 Soluções para Problemas de Rate Limit no Qwen3-Max
Visão Geral das Soluções
| Solução | Dificuldade | Efeito | Custo | Cenário Recomendado |
|---|---|---|---|---|
| Serviço de Intermediação APIYI | Baixa | Resolve totalmente | Mais econômico | Todos os cenários |
| Estratégia de Suavização | Média | Alivia | Zero | Limite leve |
| Rotação de Multi-contas | Alta | Alivia | Alto | Usuários corporativos |
| Fallback para Modelo Reserva | Média | Segurança | Médio | Tarefas não críticas |
| Solicitação de Aumento de Cota | Baixa | Limitado | Zero | Usuários de longo prazo |
Solução 1: Usar Serviço de Intermediação (Recomendado)
Esta é a forma mais direta e eficaz de resolver o problema de limite do Qwen3-Max. Ao usar uma plataforma como a APIYI, você contorna as restrições de cota impostas no nível de conta do Alibaba Cloud.
Por que a intermediação resolve o limite?
| Comparação | Direto com Alibaba Cloud | Através da APIYI |
|---|---|---|
| Limite de Cota | Restrição RPM/TPM por conta | Compartilhamento de pool global |
| Frequência de Bloqueio | Erros 429 frequentes | Praticamente sem limites |
| Preço | Preço oficial | Descontos agressivos (aprox. 90% off) |
| Estabilidade | Depende da cota da conta | Garantia de múltiplos canais |
Exemplo de Código Simples
from openai import OpenAI
# Use o serviço APIYI para dar adeus aos limites de taxa
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3-max",
messages=[
{"role": "user", "content": "Explique como funciona a arquitetura MoE"}
]
)
print(response.choices[0].message.content)
🎯 Dica: Ao chamar o Qwen3-Max via APIYI (apiyi.com), você não só resolve o problema de limite, mas também aproveita preços muito mais em conta. A APIYI possui parcerias que garantem um serviço mais estável.
Ver código completo (com tratamento de erros)
import time
from openai import OpenAI
from openai import APIError, RateLimitError
class Qwen3MaxClient:
"""Cliente Qwen3-Max via APIYI, sem dores de cabeça com limites"""
def __init__(self, api_key: str):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # Interface APIYI
)
self.model = "qwen3-max"
def chat(self, message: str, max_retries: int = 3) -> str:
"""
Envia mensagem e obtém resposta.
Via APIYI, dificilmente você encontrará limites de taxa.
"""
for attempt in range(max_retries):
try:
response = self.client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": message}],
max_tokens=4096
)
return response.choices[0].message.content
except RateLimitError as e:
# Com APIYI, isso raramente acontece
if attempt < max_retries - 1:
wait_time = 2 ** attempt
print(f"Requisição limitada, tentando em {wait_time}s...")
time.sleep(wait_time)
else:
raise e
except APIError as e:
print(f"Erro na API: {e}")
raise e
return ""
def batch_chat(self, messages: list[str]) -> list[str]:
"""Processamento em lote sem se preocupar com limites"""
results = []
for msg in messages:
result = self.chat(msg)
results.append(result)
return results
# Exemplo de uso
if __name__ == "__main__":
client = Qwen3MaxClient(api_key="your-apiyi-key")
# Chamada única
response = client.chat("Escreva um algoritmo de QuickSort em Python")
print(response)
# Chamadas em lote - Sem limites via APIYI
questions = [
"O que é arquitetura MoE?",
"Compare Transformer com RNN",
"O que é mecanismo de atenção?"
]
answers = client.batch_chat(questions)
for q, a in zip(questions, answers):
print(f"Q: {q}\nA: {a}\n")
Solução 2: Estratégia de Suavização de Requisições
Se você optar por continuar com a conexão direta, pode usar técnicas de suavização para mitigar os bloqueios.
Retentativa com Backoff Exponencial
import time
import random
def call_with_backoff(func, max_retries=5):
"""Estratégia de retentativa com backoff exponencial"""
for attempt in range(max_retries):
try:
return func()
except Exception as e:
if "429" in str(e) and attempt < max_retries - 1:
# Backoff exponencial + jitter aleatório
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"Limite atingido, aguardando {wait_time:.2f}s...")
time.sleep(wait_time)
else:
raise e
Buffer de Fila de Requisições
import asyncio
from collections import deque
class RequestQueue:
"""Fila de requisições para suavizar a frequência do Qwen3-Max"""
def __init__(self, rpm_limit=60):
self.queue = deque()
self.interval = 60 / rpm_limit # Intervalo entre requisições
self.last_request = 0
async def throttled_request(self, request_func):
"""Requisição com controle de fluxo"""
now = time.time()
wait_time = self.interval - (now - self.last_request)
if wait_time > 0:
await asyncio.sleep(wait_time)
self.last_request = time.time()
return await request_func()
Nota: A suavização apenas alivia o problema, não o resolve completamente. Para alta concorrência, a APIYI ainda é a melhor opção.
Solução 3: Rotação de Multi-contas
Usuários corporativos podem aumentar a cota total alternando entre várias contas.
from itertools import cycle
class MultiAccountClient:
"""Cliente com rotação de múltiplas contas"""
def __init__(self, api_keys: list[str]):
self.clients = cycle([
OpenAI(api_key=key, base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
for key in api_keys
])
def chat(self, message: str) -> str:
client = next(self.clients)
response = client.chat.completions.create(
model="qwen3-max",
messages=[{"role": "user", "content": message}]
)
return response.choices[0].message.content
| Qtd de Contas | RPM Equivalente | TPM Equivalente | Complexidade de Gestão |
|---|---|---|---|
| 1 | 600 | 1.000.000 | Baixa |
| 3 | 1.800 | 3.000.000 | Média |
| 5 | 3.000 | 5.000.000 | Alta |
| 10 | 6.000 | 10.000.000 | Muito Alta |
💡 Conclusão: Gerenciar várias contas é caro e trabalhoso. É muito mais vantajoso usar a APIYI (apiyi.com), onde você tem acesso a um pool gigante de cotas sem precisar de várias chaves.
Solução 4: Fallback (Degradação) de Modelo
Quando o Qwen3-Max atingir o limite, você pode alternar automaticamente para um modelo reserva.
class FallbackClient:
"""Cliente Qwen com suporte a fallback"""
MODEL_PRIORITY = [
"qwen3-max", # Primeira escolha
"qwen-plus", # Reserva 1
"qwen-turbo", # Reserva 2
]
def __init__(self, api_key: str):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # Usando APIYI
)
def chat(self, message: str) -> tuple[str, str]:
"""Retorna (conteúdo, modelo utilizado)"""
for model in self.MODEL_PRIORITY:
try:
response = self.client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": message}]
)
return response.choices[0].message.content, model
except Exception as e:
if "429" in str(e):
print(f"Limite no {model}, tentando fallback...")
continue
raise e
raise Exception("Nenhum modelo disponível no momento")
Solução 5: Solicitar Aumento de Cota Oficial
Para usuários com demanda estável e de longo prazo, é possível pedir um aumento de limite diretamente ao Alibaba Cloud.
Passos para solicitação:
- Faça login no console do Alibaba Cloud.
- Vá para a página de Gestão de Cotas do Model Studio.
- Envie uma solicitação de aumento de cota (Quota Increase).
- Aguarde a revisão (geralmente leva de 1 a 3 dias úteis).
Requisitos comuns:
- Conta com verificação de identidade (KYC).
- Histórico sem faturas pendentes.
- Descrição clara do cenário de uso.
Comparação de Custos e Limites de Taxa do Qwen3-Max
Análise Comparativa de Preços
| Provedor | Preço de Entrada (0-32K) | Preço de Saída | Situação do Limite de Taxa |
|---|---|---|---|
| Alibaba Cloud Direto | $1.20/M | $6.00/M | Limites rigorosos de RPM/TPM |
| APIYI (desconto de 0.88x) | $1.06/M | $5.28/M | Praticamente sem limites |
| Diferença | Economia de 12% | Economia de 12% | – |
Cálculo de Custo Total
Assumindo um volume mensal de 10 milhões de tokens (metade entrada, metade saída):
| Solução | Custo Mensal | Impacto do Limite de Taxa | Avaliação Geral |
|---|---|---|---|
| Alibaba Cloud Direto | $36.00 | Interrupções frequentes, exige reentativas | Custo real mais alto |
| Proxy APIYI | $31.68 | Estável sem interrupções | Melhor custo-benefício |
| Múltiplas Contas | $36.00+ | Alto custo de gerenciamento | Não recomendado |
💰 Otimização de Custos: A APIYI (apiyi.com) possui uma parceria de canal com a Alibaba Cloud. Além de oferecer um preço padrão com desconto de 0.88x, ela resolve completamente o problema dos limites de taxa. Para cenários de uso de média e alta frequência, o custo total acaba sendo menor.
Perguntas Frequentes
Q1: Por que estou enfrentando limites de taxa no Qwen3-Max logo no início do uso?
O Model Studio da Alibaba Cloud oferece uma cota gratuita limitada para contas novas, e a versão qwen3-max-2025-09-23 tem cotas ainda menores (RPM 60, TPM 100.000). Se você estiver usando a versão snapshot, o limite de taxa será ainda mais rigoroso.
Recomendamos fazer as chamadas através da APIYI (apiyi.com) para evitar as restrições de cota por conta.
Q2: Quanto tempo leva para recuperar após atingir o limite de taxa?
O limite de taxa da Alibaba Cloud funciona com um mecanismo de janela deslizante:
- Limite de RPM: aguarde cerca de 60 segundos para recuperar.
- Limite de TPM: aguarde cerca de 60 segundos para recuperar.
- Proteção contra surtos: pode exigir um tempo de espera maior.
Usar a plataforma APIYI evita esperas frequentes e aumenta a produtividade no desenvolvimento.
Q3: Como é garantida a estabilidade do serviço de proxy da APIYI?
A APIYI tem uma parceria de canal com a Alibaba Cloud e utiliza um modelo de cota de "pool" em nível de plataforma:
- Balanceamento de carga em múltiplos canais.
- Failover automático.
- Garantia de disponibilidade de 99,9%.
Comparado às limitações de cota de contas individuais, o serviço em nível de plataforma é muito mais estável e confiável.
Q4: Preciso modificar muito código para usar a APIYI?
Quase nada. A APIYI é totalmente compatível com o formato do SDK da OpenAI. Você só precisa alterar dois pontos:
# Antes (Alibaba Cloud Direto)
client = OpenAI(
api_key="sk-xxx",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# Depois (Proxy APIYI)
client = OpenAI(
api_key="your-apiyi-key", # Substitua pela sua chave da APIYI
base_url="https://api.apiyi.com/v1" # Substitua pelo endereço da APIYI
)
O nome do modelo e o formato dos parâmetros são idênticos, sem necessidade de outras mudanças.
Q5: Além do Qwen3-Max, quais outros modelos a APIYI suporta?
A plataforma APIYI suporta chamadas unificadas para mais de 200 modelos de IA populares, incluindo:
- Série Qwen completa: qwen3-max, qwen-plus, qwen-turbo, qwen-vl, etc.
- Série Claude: claude-3-opus, claude-3-sonnet, claude-3-haiku.
- Série GPT: gpt-4o, gpt-4-turbo, gpt-3.5-turbo.
- Outros: gemini, deepseek, moonshot, etc.
Interface unificada para todos os modelos, uma única API Key para acessar tudo.
Resumo das soluções para problemas de limite de taxa do Qwen3-Max
Árvore de decisão para escolha da solução
Erro 429 no Qwen3-Max
│
├─ Precisa de uma solução definitiva → Use o proxy da APIYI (Recomendado)
│
├─ Limite leve → Suavização de requisições + Exponential Backoff
│
├─ Chamadas empresariais em larga escala → Round-robin de múltiplas contas ou APIYI Enterprise
│
└─ Tarefas não críticas → Downgrade para modelo reserva
Revisão dos pontos principais
| Ponto Principal | Descrição |
|---|---|
| Motivo do limite | Restrições triplas de RPM/TPM/RPS da Alibaba Cloud |
| Melhor solução | Serviço de proxy da APIYI, resolve de vez |
| Vantagem de custo | Preços competitivos, mais barato que a conexão direta |
| Custo de migração | Basta alterar o base_url e a api_key |
Recomendamos usar a APIYI (apiyi.com) para resolver rapidamente os problemas de limite de taxa do Qwen3-Max, garantindo estabilidade e preços promocionais.
Referências
-
Documentação de Rate Limits da Alibaba Cloud: Explicação oficial dos limites
- Link:
alibabacloud.com/help/en/model-studio/rate-limit
- Link:
-
Documentação de Error Codes da Alibaba Cloud: Detalhes dos códigos de erro
- Link:
alibabacloud.com/help/en/model-studio/error-code
- Link:
-
Documentação do modelo Qwen3-Max: Especificações técnicas oficiais
- Link:
alibabacloud.com/help/en/model-studio/what-is-qwen-llm
- Link:
Suporte técnico: Em caso de dúvidas sobre o uso do Qwen3-Max, sinta-se à vontade para obter suporte técnico através da APIYI (apiyi.com).