调用 Gemini 3.0 Pro Preview 或 gemini-3-flash-preview 模型时遇到 thinking_budget and thinking_level are not supported together 错误?这是 Google Gemini API 在不同模型版本间参数升级导致的兼容性问题。本文将从 API 设计演进角度,系统解析这个错误的根本原因和正确的配置方法。
核心价值: 读完本文,你将掌握 Gemini 2.5 和 3.0 模型思考模式参数的正确配置方法,避免常见的 API 调用错误,优化模型推理性能和成本控制。

Gemini API 思考模式参数演进核心要点
| 模型版本 | 推荐参数 | 参数类型 | 配置示例 | 适用场景 |
|---|---|---|---|---|
| Gemini 2.5 Flash/Flash-Lite | thinking_budget |
整数或 -1 | thinking_budget: 0 (禁用)thinking_budget: -1 (动态) |
精确控制思考 token 预算 |
| Gemini 3.0 Pro/Flash | thinking_level |
枚举值 | thinking_level: "minimal"/"low"/"medium"/"high" |
简化配置,按场景分级 |
| 兼容性说明 | ⚠️ 不可同时使用 | – | 同时传递两个参数会触发 400 错误 | 根据模型版本选择其一 |
Gemini 思考模式参数核心差异
Google 在 Gemini 3.0 引入 thinking_level 参数的核心原因是简化开发者配置体验。Gemini 2.5 的 thinking_budget 要求开发者精确估算思考 token 数量,而 Gemini 3.0 的 thinking_level 将复杂度抽象为 4 个语义化等级,降低了配置门槛。
这种设计变化反映了 Google 在 API 演进中的取舍:牺牲部分精细控制能力,换取更好的易用性和跨模型一致性。对于大多数应用场景,thinking_level 的抽象已经足够,只有在需要极致成本优化或特定 token 预算控制时,才需要使用 thinking_budget。
💡 技术建议: 在实际开发中,我们建议通过 API易 apiyi.com 平台进行接口调用测试。该平台提供统一的 API 接口,支持 Gemini 2.5 Flash、Gemini 3.0 Pro、Gemini 3.0 Flash 等模型,有助于快速验证不同思考模式配置的实际效果和成本差异。
错误根本原因:参数设计的向前兼容策略
API 错误信息解析
{
"status_code": 400,
"error": {
"message": "Unable to submit request because thinking_budget and thinking_level are not supported together.",
"type": "upstream_error",
"code": 400
}
}
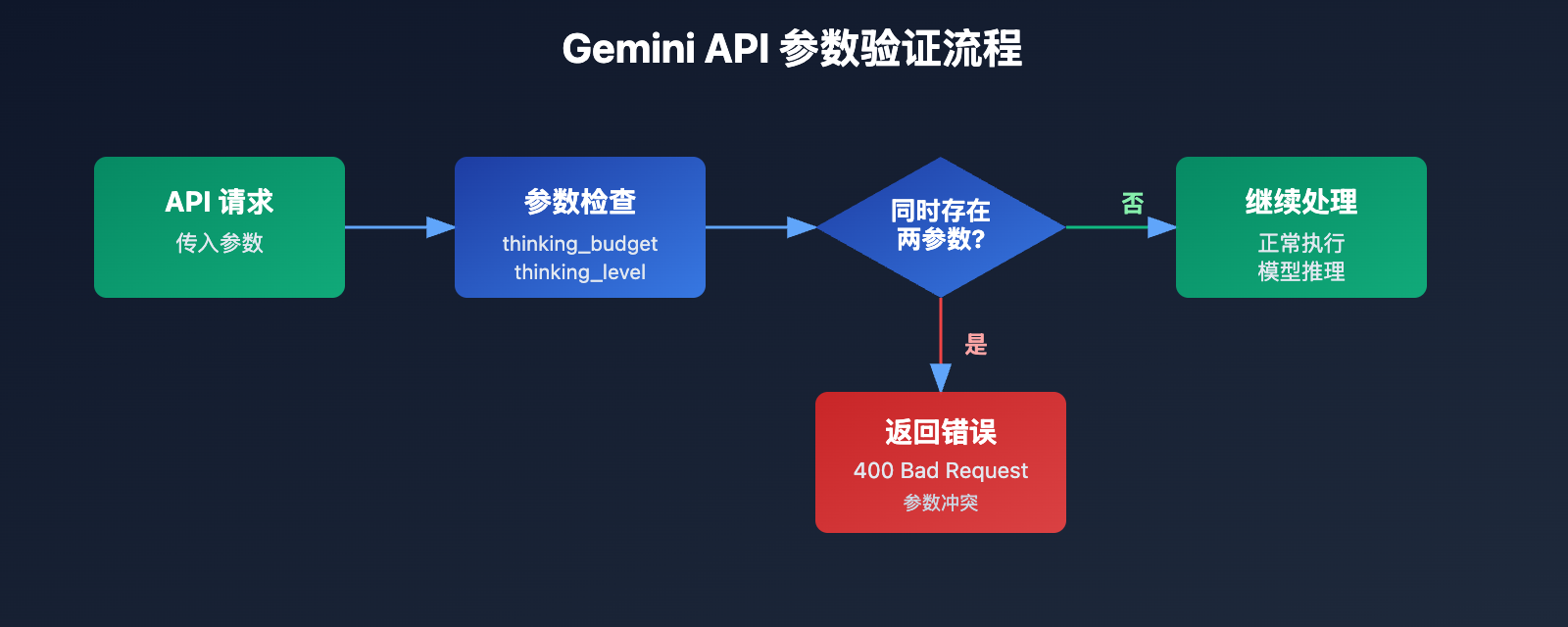
这个错误的核心信息是 thinking_budget 和 thinking_level 不能同时存在。Google 在 Gemini 3.0 引入新参数时,并未完全废弃旧参数,而是采用了互斥策略:
- Gemini 2.5 模型: 只接受
thinking_budget,忽略thinking_level - Gemini 3.0 模型: 优先使用
thinking_level,同时接受thinking_budget以保持向后兼容,但不允许两者同时传递 - 错误触发条件: API 请求中同时包含
thinking_budget和thinking_level参数
为什么会出现这个错误?
开发者遇到这个错误,通常是以下 3 种场景:
| 场景 | 原因 | 典型代码特征 |
|---|---|---|
| 场景 1: SDK 自动填充 | 某些 AI 框架(如 LiteLLM、AG2)会根据模型名自动填充参数,导致同时传递两个参数 | 使用封装好的 SDK,未检查实际请求体 |
| 场景 2: 硬编码配置 | 代码中硬编码了 thinking_budget,后续切换到 Gemini 3.0 模型时未更新参数名 |
配置文件或代码中同时存在两个参数的赋值 |
| 场景 3: 模型别名误判 | 使用 gemini-flash-preview 等别名,实际指向 Gemini 3.0,但按 2.5 参数配置 |
模型名包含 preview 或 latest,参数配置未同步更新 |
🎯 选择建议: 在切换 Gemini 模型版本时,建议先通过 API易 apiyi.com 平台测试参数兼容性。该平台支持快速切换 Gemini 2.5 和 3.0 系列模型,方便对比不同思考模式配置的响应质量和延迟差异,避免在生产环境中遇到参数冲突。
3 种解决方案:根据模型版本选择正确参数
方案 1: Gemini 2.5 模型配置 (使用 thinking_budget)
适用模型: gemini-2.5-flash、gemini-2.5-pro 等
参数说明:
thinking_budget: 0– 完全禁用思考模式,最低延迟和成本thinking_budget: -1– 动态思考模式,模型根据请求复杂度自动调整thinking_budget: <正整数>– 精确指定思考 token 数量上限
极简示例
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-2.5-flash-preview-04-17",
messages=[{"role": "user", "content": "解释量子纠缠的原理"}],
extra_body={
"thinking_budget": -1 # 动态思考模式
}
)
print(response.choices[0].message.content)
查看完整代码 (包含思考内容提取)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-2.5-flash-preview-04-17",
messages=[{"role": "user", "content": "解释量子纠缠的原理"}],
extra_body={
"thinking_budget": -1, # 动态思考模式
"include_thoughts": True # 启用思考摘要返回
}
)
# 提取思考内容 (如果启用)
for part in response.choices[0].message.content:
if hasattr(part, 'thought') and part.thought:
print(f"思考过程: {part.text}")
# 提取最终回答
final_answer = response.choices[0].message.content
print(f"最终回答: {final_answer}")
建议: Gemini 2.5 模型将于 2026 年 3 月 3 日退役,建议尽早迁移到 Gemini 3.0 系列。可通过 API易 apiyi.com 平台快速对比迁移前后的响应质量差异。
方案 2: Gemini 3.0 模型配置 (使用 thinking_level)
适用模型: gemini-3.0-flash-preview、gemini-3.0-pro-preview
参数说明:
thinking_level: "minimal"– 最小思考,接近零预算,需要传递思考签名(Thought Signatures)thinking_level: "low"– 低强度思考,适合简单指令跟随和聊天场景thinking_level: "medium"– 中等强度思考,适合一般推理任务(仅 Gemini 3.0 Flash 支持)thinking_level: "high"– 高强度思考,最大化推理深度,适合复杂问题(默认值)
极简示例
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.0-flash-preview",
messages=[{"role": "user", "content": "分析这段代码的时间复杂度"}],
extra_body={
"thinking_level": "medium" # 中等强度思考
}
)
print(response.choices[0].message.content)
查看完整代码 (包含思考签名传递)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# 第一轮对话
response_1 = client.chat.completions.create(
model="gemini-3.0-flash-preview",
messages=[{"role": "user", "content": "设计一个 LRU 缓存算法"}],
extra_body={
"thinking_level": "high",
"include_thoughts": True
}
)
# 提取思考签名 (Gemini 3.0 自动返回)
thought_signatures = []
for part in response_1.choices[0].message.content:
if hasattr(part, 'thought_signature'):
thought_signatures.append(part.thought_signature)
# 第二轮对话,传递思考签名以保持推理链
response_2 = client.chat.completions.create(
model="gemini-3.0-flash-preview",
messages=[
{"role": "user", "content": "设计一个 LRU 缓存算法"},
{"role": "assistant", "content": response_1.choices[0].message.content, "thought_signatures": thought_signatures},
{"role": "user", "content": "优化这个算法的空间复杂度"}
],
extra_body={
"thinking_level": "high"
}
)
print(response_2.choices[0].message.content)
💰 成本优化: 对于预算敏感的项目,可以考虑通过 API易 apiyi.com 平台调用 Gemini 3.0 Flash API,该平台提供灵活的计费方式和更优惠的价格,适合中小团队和个人开发者。配合
thinking_level: "low"可进一步降低成本。
方案 3: 动态模型切换的参数适配策略
适用场景: 需要在代码中同时支持 Gemini 2.5 和 3.0 模型
智能参数适配函数
def get_thinking_config(model_name: str, complexity: str = "medium") -> dict:
"""
根据模型版本自动选择正确的思考模式参数
Args:
model_name: Gemini 模型名称
complexity: 思考复杂度 ("minimal", "low", "medium", "high", "dynamic")
Returns:
适用于 extra_body 的参数字典
"""
# Gemini 3.0 模型列表
gemini_3_models = [
"gemini-3.0-flash-preview",
"gemini-3.0-pro-preview",
"gemini-3-flash",
"gemini-3-pro"
]
# Gemini 2.5 模型列表
gemini_2_5_models = [
"gemini-2.5-flash-preview-04-17",
"gemini-2.5-flash-lite",
"gemini-2-flash",
"gemini-2-flash-lite"
]
# 判断模型版本
if any(m in model_name for m in gemini_3_models):
# Gemini 3.0 使用 thinking_level
level_map = {
"minimal": "minimal",
"low": "low",
"medium": "medium",
"high": "high",
"dynamic": "high" # 默认高强度
}
return {"thinking_level": level_map.get(complexity, "medium")}
elif any(m in model_name for m in gemini_2_5_models):
# Gemini 2.5 使用 thinking_budget
budget_map = {
"minimal": 0,
"low": 512,
"medium": 2048,
"high": 8192,
"dynamic": -1
}
return {"thinking_budget": budget_map.get(complexity, -1)}
else:
# 未知模型,默认使用 Gemini 3.0 参数
return {"thinking_level": "medium"}
# 使用示例
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
model = "gemini-3.0-flash-preview" # 可动态切换
thinking_config = get_thinking_config(model, complexity="high")
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "你的问题"}],
extra_body=thinking_config
)

| 思考复杂度 | Gemini 2.5 (thinking_budget) | Gemini 3.0 (thinking_level) | 推荐场景 |
|---|---|---|---|
| 最小 | 0 |
"minimal" |
简单指令跟随、高吞吐量应用 |
| 低 | 512 |
"low" |
聊天机器人、轻量级 QA |
| 中 | 2048 |
"medium" |
一般推理任务、代码生成 |
| 高 | 8192 |
"high" |
复杂问题求解、深度分析 |
| 动态 | -1 |
"high" (默认) |
自动适配复杂度 |
🚀 快速开始: 推荐使用 API易 apiyi.com 平台快速搭建原型。该平台提供开箱即用的 Gemini API 接口,无需复杂配置,5 分钟即可完成集成,支持一键切换不同思考模式参数进行效果对比。
Gemini 3.0 思考签名 (Thought Signatures) 机制详解
什么是思考签名?
Gemini 3.0 引入的思考签名 (Thought Signatures) 是模型内部推理过程的加密表示。当你启用 include_thoughts: true 时,模型会在响应中返回思考过程的加密签名,你可以在后续对话中传递这些签名,让模型保持推理链的连贯性。
核心特性:
- 加密表示: 签名内容不可读,仅模型可解析
- 推理链保持: 多轮对话中传递签名,模型可基于之前的思考继续推理
- 强制返回: Gemini 3.0 默认返回思考签名,即使未请求
思考签名的实际应用场景
| 场景 | 是否需要传递签名 | 说明 |
|---|---|---|
| 单轮问答 | ❌ 不需要 | 独立问题,无需保持推理链 |
| 多轮对话 (简单) | ❌ 不需要 | 上下文足够,无复杂推理依赖 |
| 多轮对话 (复杂推理) | ✅ 需要 | 例如:代码重构、数学证明、多步骤分析 |
| 最小思考模式 (minimal) | ✅ 必须 | thinking_level: "minimal" 要求传递签名,否则返回 400 错误 |
思考签名传递示例代码
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# 第一轮:让模型设计算法
response_1 = client.chat.completions.create(
model="gemini-3.0-pro-preview",
messages=[{"role": "user", "content": "设计一个分布式限流算法"}],
extra_body={
"thinking_level": "high",
"include_thoughts": True
}
)
# 提取思考签名
signatures = []
for part in response_1.choices[0].message.content:
if hasattr(part, 'thought_signature'):
signatures.append(part.thought_signature)
# 第二轮:基于之前的推理继续优化
response_2 = client.chat.completions.create(
model="gemini-3.0-pro-preview",
messages=[
{"role": "user", "content": "设计一个分布式限流算法"},
{
"role": "assistant",
"content": response_1.choices[0].message.content,
"thought_signatures": signatures # 传递思考签名
},
{"role": "user", "content": "如何处理分布式时钟不一致问题?"}
],
extra_body={"thinking_level": "high"}
)
💡 最佳实践: 在需要多轮复杂推理的场景(如系统设计、算法优化、代码审查),建议通过 API易 apiyi.com 平台测试思考签名传递的效果差异。该平台支持完整的 Gemini 3.0 思考签名机制,方便验证不同配置下的推理质量。
常见问题
Q1: 为什么 Gemini 2.5 Flash 设置 thinking_budget=0 后仍然返回思考内容?
这是一个已知的 Bug,在 Gemini 2.5 Flash Preview 04-17 版本中,thinking_budget=0 未被正确执行。Google 官方论坛已确认此问题。
临时解决方案:
- 使用
thinking_budget=1(极小值) 而非 0 - 升级到 Gemini 3.0 Flash,使用
thinking_level="minimal" - 在后处理中过滤思考内容 (如果 API 返回了 thought 字段)
推荐通过 API易 apiyi.com 快速切换到 Gemini 3.0 Flash 模型,该平台支持最新版本,可避免此类 Bug。
Q2: 如何判断当前使用的是 Gemini 2.5 还是 3.0 模型?
方法 1: 检查模型名称
- Gemini 2.x: 名称包含
2.5-flash、2-flash-lite - Gemini 3.x: 名称包含
3.0-flash、3-pro、gemini-3-flash
方法 2: 发送测试请求
# 仅传递 thinking_level,观察响应
response = client.chat.completions.create(
model="your-model-name",
messages=[{"role": "user", "content": "test"}],
extra_body={"thinking_level": "low"}
)
# 如果返回 400 错误且提示不支持 thinking_level,说明是 Gemini 2.5
方法 3: 查看 API 响应头
部分 API 实现会在响应头中返回 X-Model-Version 字段,可直接识别模型版本。
Q3: Gemini 3.0 的 thinking_level 等级具体消耗多少 token?
Google 官方未公开不同 thinking_level 对应的精确 token 预算,仅给出以下指导:
| thinking_level | 相对成本 | 相对延迟 | 推理深度 |
|---|---|---|---|
| minimal | 最低 | 最低 | 几乎无思考 |
| low | 低 | 低 | 浅层推理 |
| medium | 中等 | 中等 | 中等推理 |
| high | 高 | 高 | 深度推理 |
实测建议:
- 通过 API易 apiyi.com 平台对比不同等级的实际 token 消耗
- 使用相同提示词,分别调用 low/medium/high,观察计费差异
- 根据实际业务场景(响应质量 vs 成本)选择合适等级
Q4: 可以在 Gemini 3.0 中强制使用 thinking_budget 吗?
可以,但不推荐。
Gemini 3.0 为了向后兼容,仍然接受 thinking_budget 参数,但官方文档明确指出:
"While
thinking_budgetis accepted for backwards compatibility, using it with Gemini 3 Pro may result in suboptimal performance."
原因:
- Gemini 3.0 的内部推理机制已针对
thinking_level优化 - 强制使用
thinking_budget可能绕过新版本的推理策略 - 可能导致响应质量下降或延迟增加
正确做法:
- 迁移到
thinking_level参数 - 参考上述"方案 3"的参数适配函数,动态选择正确参数
总结
Gemini API thinking_budget 和 thinking_level 报错的核心要点:
- 参数互斥: Gemini 2.5 使用
thinking_budget,Gemini 3.0 使用thinking_level,不可同时传递 - 模型识别: 通过模型名称判断版本,2.5 系列用
thinking_budget,3.0 系列用thinking_level - 动态适配: 使用参数适配函数,根据模型名自动选择正确参数,避免硬编码
- 思考签名: Gemini 3.0 引入思考签名机制,多轮复杂推理场景需传递签名保持推理链
- 迁移建议: Gemini 2.5 将于 2026 年 3 月 3 日退役,建议尽早迁移到 3.0 系列
推荐通过 API易 apiyi.com 快速验证不同思考模式配置的实际效果。该平台支持 Gemini 全系列模型,提供统一接口和灵活计费方式,适合快速对比测试和生产环境部署。
作者: APIYI 技术团队 | 如有技术问题,欢迎访问 API易 apiyi.com 获取更多 AI 模型接入方案。