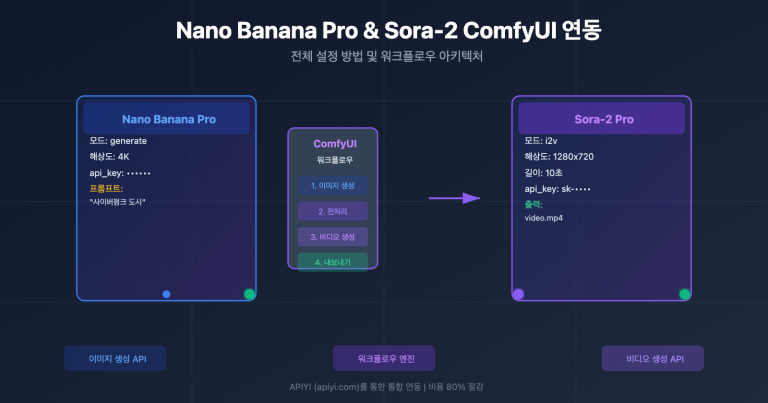
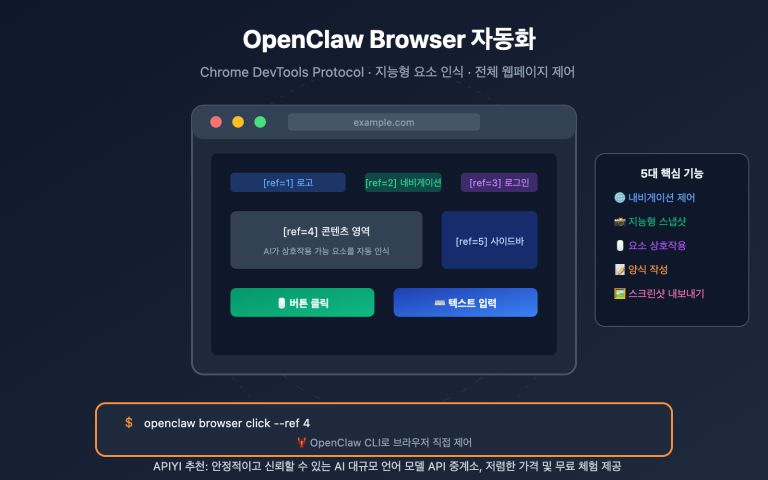
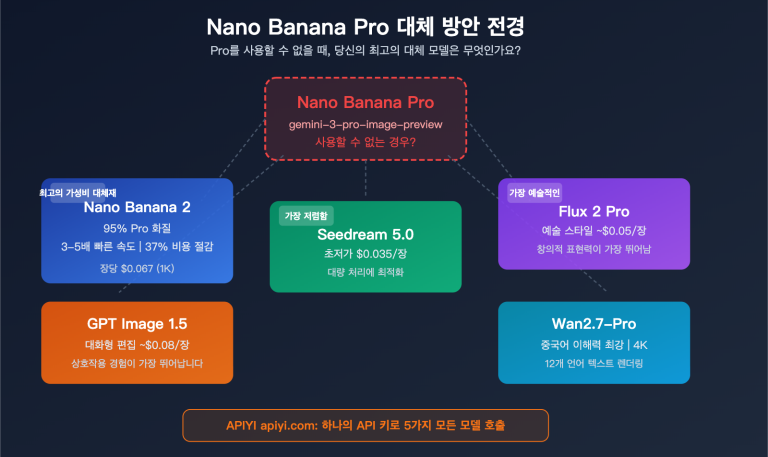
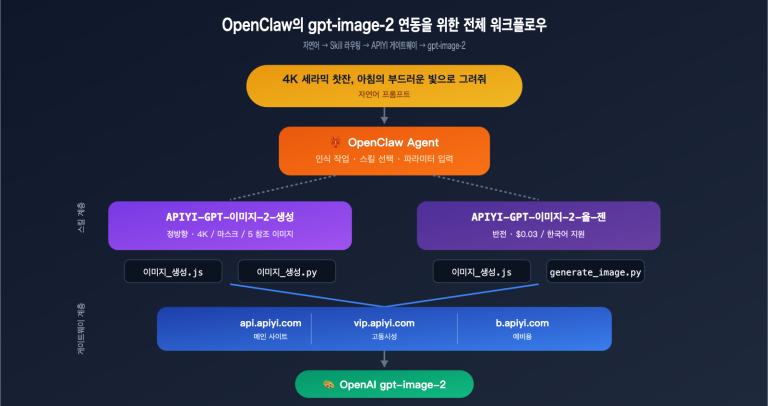
많은 분이 ChatGPT 웹 버전을 처음 사용할 때 이런 착각을 하곤 합니다. PDF 파일이나 문장 하나를 입력하면 모델이 '짠' 하고 스타일이 통일된 이미지 5장을 한 번에 만들어줄 거라 기대하죠. 하지만 막상 API로 넘어와 n 값을 5로 설정해보면, 결과물은 마치 카드 뽑기를 하듯 비슷비슷하면서도 제각각인 변형 이미지들뿐입니다. 같은 모델인데 왜 이렇게 차이가 나는 걸까요?
이 글에서는 표준 정답을 제시하기보다는, 고객 지원 과정에서 반복적으로 마주했던 이 문제를 하나씩 파헤쳐 보려 합니다. **GPT 이미지 생성(GPT Image)**의 두 가지 서로 다른 기술 경로를 명확히 짚어보고, 왜 n 파라미터로는 진정한 의미의 '그룹 생성'이 불가능한지, 그리고 API를 통해 직접 다중 이미지 일관성을 구현하려면 어떤 현실적인 방법이 있는지 알아보겠습니다.
1. GPT 이미지 생성의 두 가지 기술 경로
이 문제를 이해하려면 먼저 간과하기 쉬운 전제를 인정해야 합니다. '한 번에 여러 장의 이미지를 생성하는 것'과 '논리적 관계가 있는 이미지 그룹을 생성하는 것'은 완전히 다른 이야기라는 점입니다. 전자는 단순히 수량적인 대량 생산일 뿐이며, 후자가 바로 우리가 말하는 진정한 '그룹 생성'입니다.
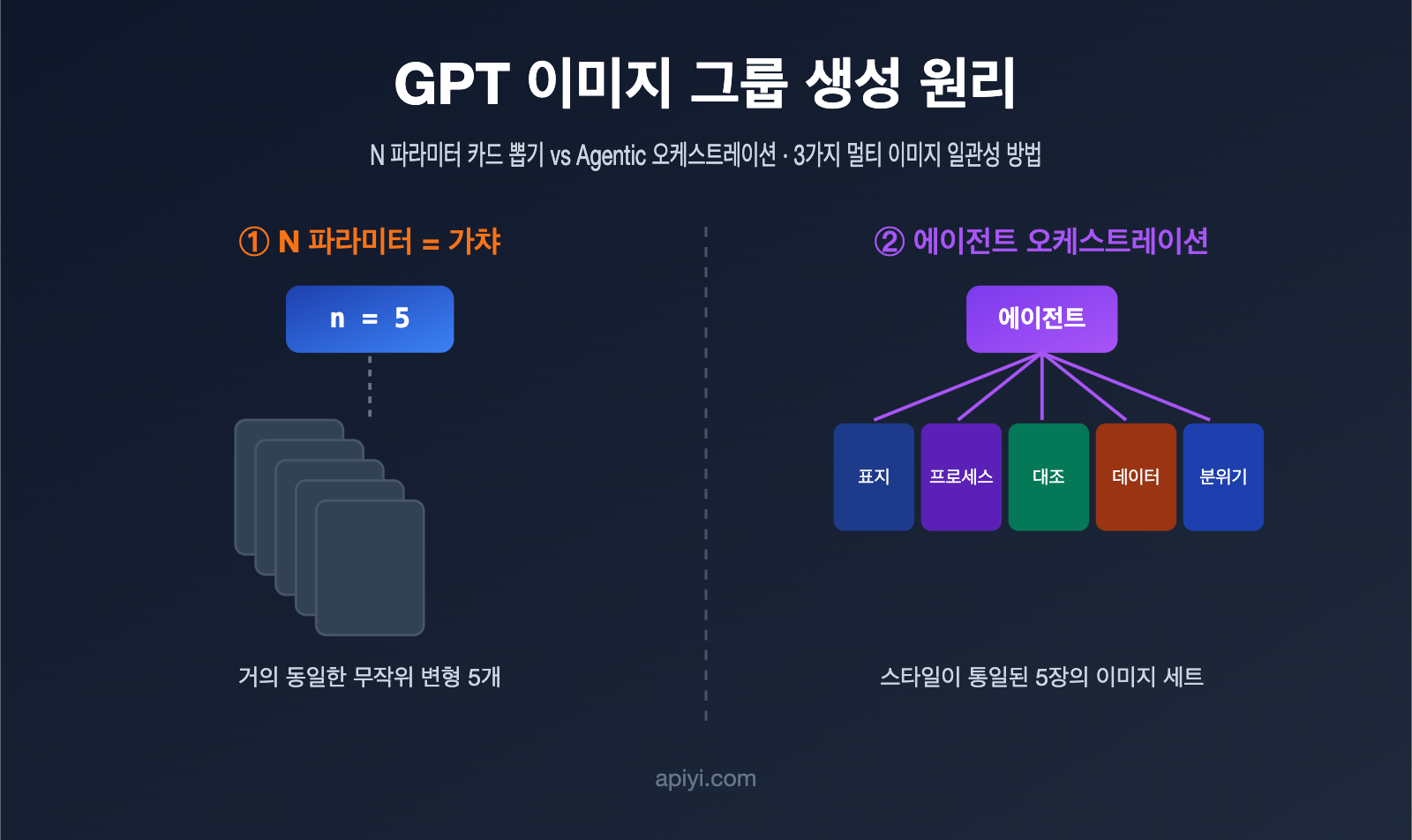
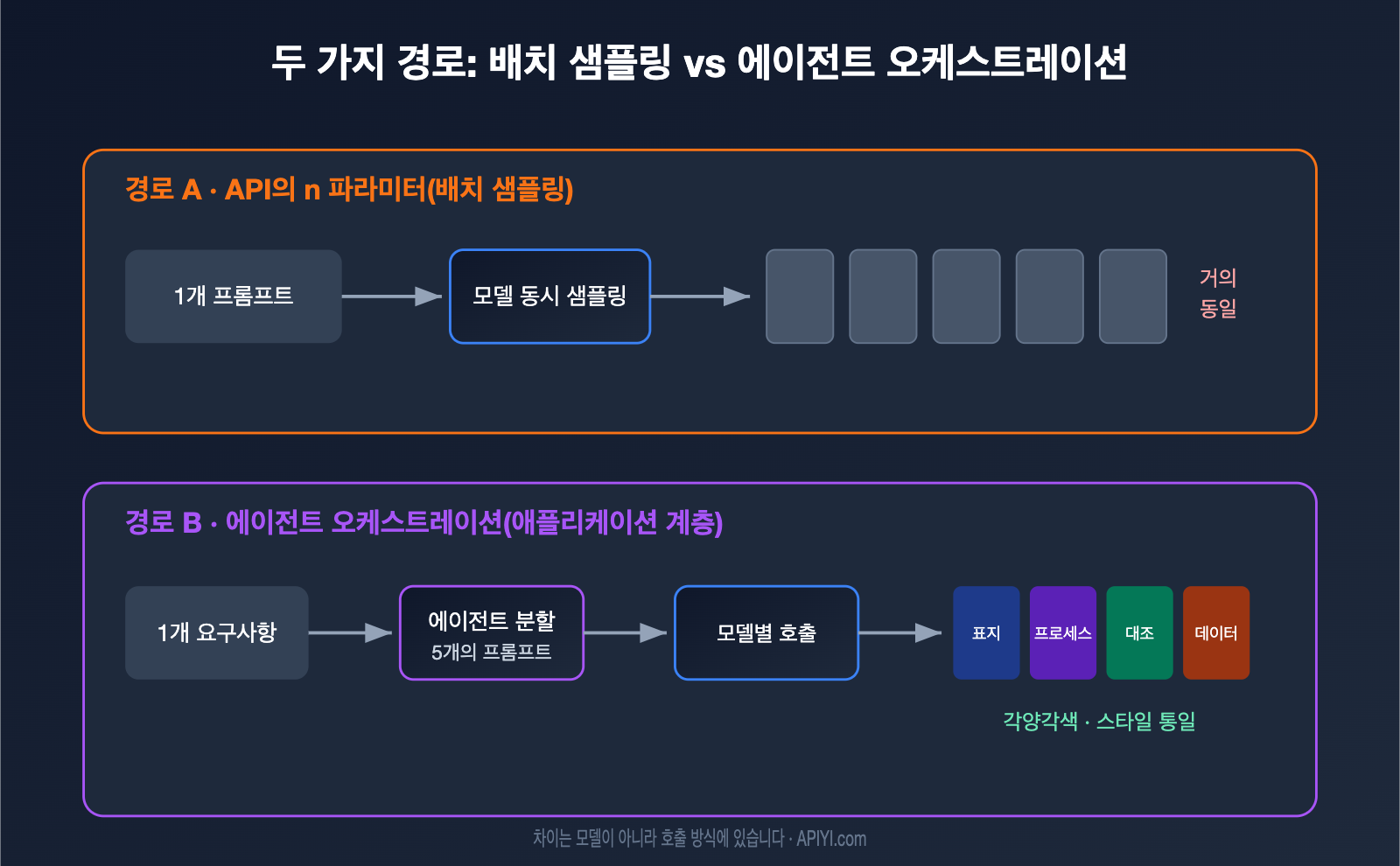
GPT 이미지는 엔지니어링 구현 측면에서 두 가지 경로로 나뉩니다. 첫 번째는 모델 계층의 배치 샘플링으로, API의 n 파라미터가 여기에 해당합니다. 동일한 프롬프트와 입력을 사용하여 모델이 병렬로 여러 결과물을 샘플링하는 방식이죠. 두 번째는 애플리케이션 계층의 에이전트(Agentic) 오케스트레이션입니다. 에이전트가 요구사항을 먼저 이해하고 이를 여러 하위 작업으로 나눈 뒤, 각각 이미지 생성 기능을 호출하고 마지막에 하나로 엮는 방식입니다.
두 경로의 핵심 차이를 아래 표로 정리했습니다.
| 차이점 | API의 n 파라미터 (배치 샘플링) | 에이전트 오케스트레이션 (애플리케이션 계층) |
|---|---|---|
| 본질 | 동일 프롬프트 반복 무작위 샘플링 | 요구사항 분할 후 독립적 생성 |
| 이미지 내용 | 거의 동일, 무작위 차이만 존재 | 각기 다르지만 주제가 연결됨 |
| '그룹' 이해도 | 이해 못 함, 단순 병렬 처리 | 이해함, 계획적 논리 보유 |
| 비용 | 단일 이미지 가격 × N | 다중 호출 비용 합산 |
| 일관성 출처 | 프롬프트와 무작위 시드 | 참조 이미지 + 통합 프롬프트 제약 |
| 주요 활용 | 만족스러운 이미지 하나를 뽑기 | 시리즈 일러스트, PPT 자료, 그림책 |
간단히 말해, n 파라미터는 "후보군을 몇 개 더 줘"라는 요구를 해결하는 것이고, 그룹 생성은 "주제에 맞춰 일련의 콘텐츠를 줘"라는 요구를 해결하는 것입니다. 이것이 바로 API를 직접 호출해 웹 버전의 경험을 재현하려 할 때 무언가 부족하다고 느끼는 이유입니다. 이 두 가지 경로의 실제 성능을 동시에 확인하고 싶다면, APIYI(apiyi.com)에서 동일한 API 키를 사용하여 각각 테스트해보세요. 여러 플랫폼을 오갈 필요 없이 비용을 절감할 수 있습니다.
二、为什么 API 的 n 参数做不出真正的组图
很多开发者的第一反应是:既然要 5 张图,那把 n 设成 5 不就行了?实际跑一遍就会发现,出来的 5 张图往往是「同一个东西的 5 个微小变体」,而不是「一组互相配合的图」。
原因在于 n 参数的工作机制。它并不会改变你的提示词,而是用同一个提示词再跑几遍,靠模型生成过程中的随机采样制造差异。OpenAI 开发者社区里有一句很贴切的描述:这些图来自「同一输入下随机采样产生的变化」(random sampling variations)。换句话说,这就是抽卡——同样的卡池,抽 5 次,卡面相似、稀有度随机。
这带来两个直接后果。其一,你无法在一次调用里表达「第一张画封面、第二张画流程、第三张画对比」这种结构化需求,因为提示词只有一个。其二,费用是线性叠加的:n=5 就是按 5 张图计费,而不是打包优惠。
下表用一个具体场景说明这个差异,假设你想为一篇文章生成 5 张不同用途的配图。
| 需求 | 用 n=5 的结果 | 你真正想要的 |
|---|---|---|
| 封面图 | 5 张都是封面候选 | 1 张封面 |
| 流程图 | 拿不到 | 1 张流程图 |
| 对比图 | 拿不到 | 1 张对比图 |
| 数据图 | 拿不到 | 1 张数据图 |
| 配图 | 拿不到 | 1 张氛围图 |
结论很清楚:n 参数适合「我要一张好图,多给几个候选让我挑」,不适合「我要一套内容不同的组图」。理解了这一点,就不会再纠结于「为什么 API 出不来网页版那种效果」——因为你用错了工具。想低成本验证 n 参数的抽卡特性,APIYI (apiyi.com) 支持按调用量计费,跑几组对比实验花不了多少钱。
三、网页版组图背后的 Agentic 编排原理
那 ChatGPT 网页版凭什么能「一个 PDF 出 5 张图」?答案就是上面提到的第二条路径——Agentic 编排,而这恰好是 2026 年 4 月发布的 GPT Image 2 / ChatGPT Images 2.0 带来的关键升级。
按照 OpenAI 的官方定位,GPT Image 2 是首个把「推理能力」内置进图像模型的版本:它在动笔之前会先研究、规划、推理图像结构(proactively researches, plans, and reasons),这套机制在网页端被称为 Thinking 模式。所以当你丢进去一份 PDF,模型不是简单地「读图」,而是先理解文档讲了什么、需要几张图、每张图分别承担什么角色,再逐张生成。
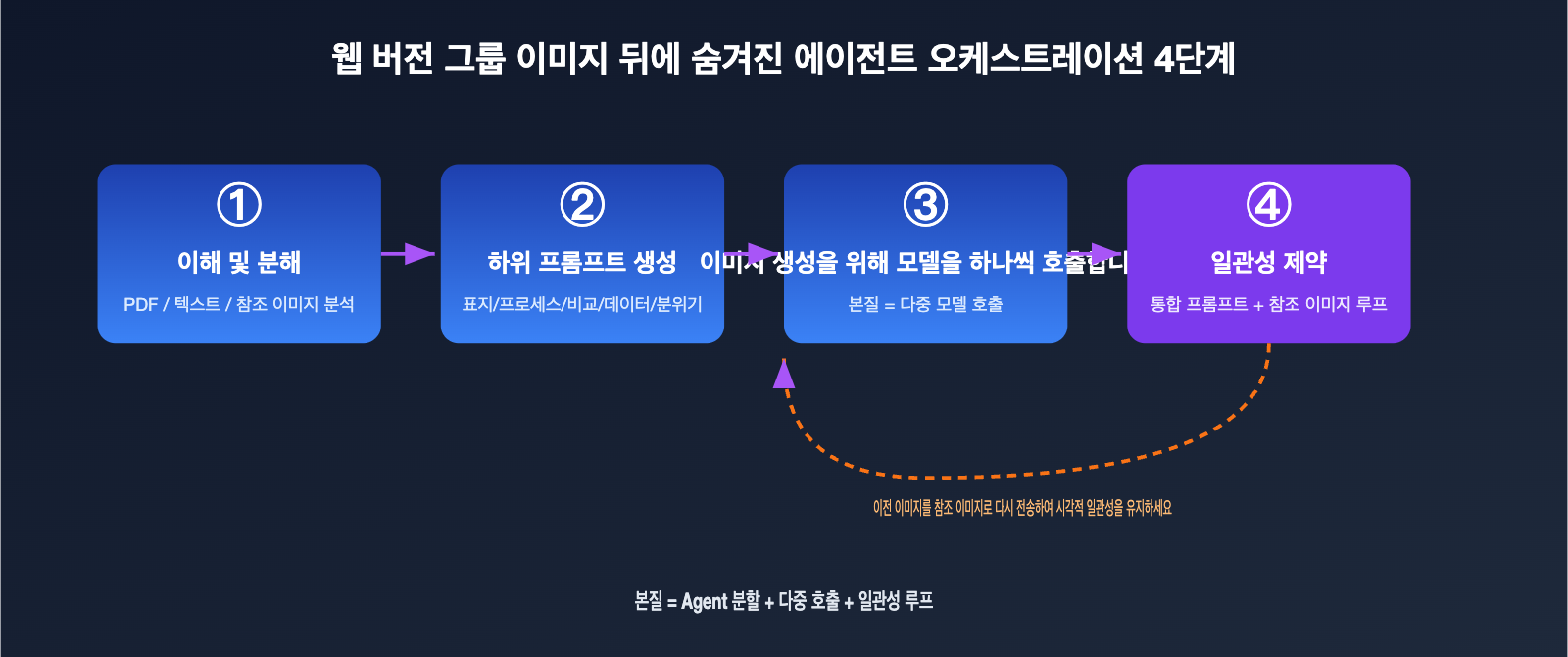
把这个过程翻译成工程语言,大致是四步:
- 理解与拆解: Agent 解析输入(文本、PDF、参考图),判断需要几张图、每张图的主题。
- 生成子提示词:为每张图各写一条独立的提示词,例如「整体架构图」「关键流程图」「数据对比图」。
- 逐张调用生图:对每条子提示词分别调用底层生图能力,本质上是多次 API 调用。
- 一致性约束:在每条提示词里注入统一的风格描述,并把前面生成的图作为参考图传给后面,保证整组视觉统一。
学术界也在用类似思路。多智能体框架(如视频生成里的 ViMax、文生图里的 Maestro)会把一个大需求拆成多个细粒度的视觉子问题,并行生成、择优选取,再把前一帧或前一张图作为后续生成的参考,以此维持角色和场景的连贯。GPT Image 2 的过人之处,是把这套原本要工程师手搭的编排,收进了模型自身的推理回路里。
这里也藏着真正的难点:多次独立调用天然会漂移。每一张图都是一次新的随机采样,角色长相、配色、画风都可能跑偏。这就是我们和客户聊到的那个核心问题——「如何保持视觉一致性」,它比「如何出多张图」难得多。下一节就专门讲怎么对付它。
四、用 API 复刻组图:3 种实现多图一致性的方法
如果你不想依赖网页版,而是要在自己的产品里实现 GPT Image 组图生成,那就得自己搭建那套编排逻辑,核心是用工程手段把「视觉一致性」补回来。结合实践,我们总结出三种由浅入深、可以叠加使用的方法。
方法一:统一提示词约束(角色描述表)。 最低成本的做法,是为整组图写一段固定的「风格 DNA」,每次调用都原样附在提示词里。比如「统一采用扁平插画风格、主色为深蓝与琥珀色、人物为短发女性工程师」。社区里把这种固定描述叫 character bible(角色圣经),描述越具体,跨图一致性越高。
方法二:参考图传递(图像-图像)。 把已经生成满意的第一张图,作为参考图传给后续每一次调用。GPT Image 2 在编辑/参考场景下可接收多张参考图(官方文档标注最多可达 16 张,具体以平台实测为准),这让「以图定调」成为组图一致性的主力手段。它的效果通常比纯文字描述更稳,尤其是角色长相这类细节。
方法三:Agent 编排 + 参考图回环。 把前两种结合进一个循环:先生成第一张作为基准图,后续每张都带着基准图 + 统一提示词去生成,必要时把上一张也一起作为参考。这就是网页版 Thinking 模式在做的事,只是你把它显式地写进了代码。
下面是一段精简的编排示例,演示「先出基准图,再带着参考图生成系列图」的骨架逻辑。
from openai import OpenAI
# base_url 指向 APIYI, 统一管理多模型密钥
client = OpenAI(base_url="https://api.apiyi.com/v1", api_key="YOUR_KEY")
STYLE = "扁平插画风格, 主色深蓝与琥珀, 人物为短发女工程师" # 角色描述表
shots = ["封面: 人物站在数据中心前", "流程: 人物在白板画架构", "总结: 人物竖起大拇指"]
# 1. 先生成基准图, 锁定整组风格
base = client.images.generate(model="gpt-image-2", prompt=f"{shots[0]},{STYLE}")
# 2. 后续每张都带统一风格约束(进阶可叠加 base 作为参考图传入 edits 接口)
for shot in shots[1:]:
img = client.images.generate(model="gpt-image-2", prompt=f"{shot},{STYLE}")
# save(img) ...
为了帮你快速选择,下表对比三种方法的特点与适用场景。
| 方法 | 一致性强度 | 实现成本 | 适用场景 |
|---|---|---|---|
| 统一提示词约束 | 중 | 저 | 스타일 통일만 필요할 때, 캐릭터 엄격하지 않음 |
| 参考图传递 | 고 | 중 | 동일 캐릭터/제품 반복 등장 |
| Agent 编排回环 | 최고 | 고 | 그림책, 시리즈 일러스트, 브랜드 홍보물 |
三种方法可以叠加:用提示词定基调,用参考图锁角色,用编排控结构。我们建议先从「统一提示词 + 参考图」起步,跑通后再上完整编排。在 APIYI (apiyi.com),gpt-image-2、gpt-image-1.5 等模型共用同一个 base_url 和密钥,方便你在不改代码的情况下切换模型做一致性对比测试。

五、GPT Image 组图生成的成本与模型选择
组图意味着多次调用,成本会被放大,所以选对模型很关键。目前 GPT Image 系列在生产环境常用的有几档,定位各有侧重。
| 模型 | 定位 | 是否支持推理编排 | 适合的组图场景 |
|---|---|---|---|
| gpt-image-2 | 플래그십, 내장 추론 | 예 (Thinking) | 고품질 시리즈물, 텍스트 포함 포스터 |
| gpt-image-1.5 | 이전 세대 플래그십 | 일부 | 품질과 비용의 균형을 맞춘 대량 생성 |
| gpt-image-1 | 클래식 안정형 | 아니오 | 스타일이 단순한 일반 이미지 |
| gpt-image-1-mini | 경량 저가형 | 아니오 | 대량 생성, 품질 요구사항 낮음 |
비용에 대해서는 명확히 인지해야 합니다. 组图는 '장수별 누적' 방식으로 과금됩니다. 1024×1024 기준으로 품질 등급에 따라 장당 가격이 몇 밀리달러에서 2밀리달러 이상까지 다양합니다(정확한 가격은 공식 및 플랫폼 실시간 견적 기준). 5장으로 구성된 세트라면 5장 분량의 비용이 발생합니다. 수천 장을 대량 생산해야 한다면 비용이 상당할 수 있으므로 미리 계산해 보는 것이 좋습니다.
저희가 드리는 제안은 다음과 같습니다. 초안 단계에서는 mini나 낮은 품질 등급을 사용하여 구도와 일관성을 빠르게 검증하고, 최종 확정 단계에서 gpt-image-2로 고품질 최종 결과물을 생성하세요. 이러한 '저비용 테스트 + 고품질 확정' 조합은 효과를 보장하면서도 비용을 절감할 수 있습니다. APIYI (apiyi.com)는 통합 사용량 대시보드를 제공하여, 그룹 이미지 호출에 얼마가 들었는지, 어떤 모델을 사용했는지 한눈에 파악할 수 있어 비용 관리가 필요한 팀에 적합합니다.
6. 자주 묻는 질문 (FAQ)
Q1: API로 한 번에 서로 다른 이미지 세트를 생성할 수 있나요?
아니요, n 파라미터로는 불가능합니다. n은 동일한 프롬프트에 대한 무작위 샘플링(뽑기)일 뿐이라 내용이 거의 같습니다. 진정한 의미의 이미지 세트를 만들려면 애플리케이션 계층에서 요구 사항을 분할하고, 여러 번 호출한 뒤, 일관성 제약을 적용하는 과정이 필요합니다.
Q2: 웹 버전 ChatGPT가 이미지 세트를 생성하는 비결은 무엇인가요?
특별한 기술이라기보다는 GPT Image 2에 에이전트 추론(Agentic reasoning) 기능이 내장되어 있기 때문입니다. 생성 전 "몇 장의 이미지가 필요한지, 각 이미지에 무엇을 그릴지"를 먼저 계획한 뒤 순차적으로 생성합니다. 본질적으로는 여러 번 호출하는 것이지만, 계획 과정이 사용자에게 투명하게 처리되는 것뿐입니다.
Q3: 다중 이미지 일관성을 유지하는 가장 효과적인 방법은 무엇인가요?
실무에서는 참조 이미지(참조 이미지)를 전달하는 것이 가장 확실합니다. 첫 번째로 만족스러운 이미지를 참조 이미지로 설정하여 후속 호출마다 전달하면, 텍스트 설명만 사용할 때보다 캐릭터와 색감 재현도가 훨씬 높습니다. 여기에 고정된 스타일 설명 문구를 추가하면 효과가 더욱 좋습니다. APIYI(apiyi.com)에서 gpt-image-2의 참조 이미지 인터페이스를 통해 직접 확인해 보세요.
Q4: 이미지 세트 생성 비용이 많이 드나요?
장수, 해상도, 품질 등급에 따라 달라지며, 장당 비용이 누적됩니다. 초안은 가벼운 모델로, 최종본은 플래그십 모델로 생성하고 플랫폼의 사용량 대시보드를 통해 비용을 모니터링하는 것을 추천합니다.
Q5: 이미지 세트 생성에 가장 가성비 좋은 모델은 무엇인가요?
품질과 텍스트 렌더링이 중요하다면 gpt-image-2를, 비용 균형을 맞추려면 gpt-image-1.5를, 대량의 저품질 이미지가 필요하다면 gpt-image-1-mini를 추천합니다. 동일한 인터페이스를 사용하므로 모델 전환 비용은 거의 없습니다.
7. 요약
처음 질문으로 돌아가 보겠습니다. 같은 모델인데 왜 API는 뽑기처럼 작동하고 웹 버전은 이미지 세트를 만들 수 있을까요? 차이는 모델이 아니라 호출 방식에 있습니다. n 파라미터는 모델 계층의 배치 샘플링으로 "후보군을 여러 개 주는" 문제를 해결합니다. 반면, 진정한 GPT Image 이미지 세트 생성은 요구 사항 분할, 다중 호출, 일관성 제약을 활용한 애플리케이션 계층의 에이전트 오케스트레이션입니다.
이 과정에서 다중 이미지 일관성을 유지하는 것이 가장 어렵습니다. 다행히 우리에게는 세 가지 유용한 도구가 있습니다. 기본 톤을 잡는 통일된 캐릭터 설명서, 캐릭터를 고정하는 참조 이미지 전달, 구조를 제어하는 에이전트 오케스트레이션 루프입니다. 이 세 가지를 조합하면 웹 버전의 경험에 근접할 수 있습니다. GPT Image 2의 가치는 바로 이러한 오케스트레이션 능력을 모델의 추론 회로에 통합하여 일반 사용자도 이를 누릴 수 있게 했다는 점입니다.
이 주제에 정답은 없으며, 경험을 공유하는 차원에서 작성했습니다. 이 글의 방법들을 직접 테스트해보고 싶다면, APIYI(apiyi.com)에서 제공하는 gpt-image-2, gpt-image-1.5 등의 통합 인터페이스와 사용량 대시보드를 활용해 보세요. 이미지 세트 실험과 비용 비교를 시작하기에 최적입니다. 더 자세한 연동 방법은 도움말 센터(help.apiyi.com)를 참고하세요.
본 문서는 APIYI 기술팀이 고객 지원 실무를 바탕으로 정리한 기술 탐구 콘텐츠입니다. 모델 사양 및 가격은 공식 및 플랫폼의 실시간 정보를 기준으로 합니다.