2026년 4월, 중국 본토 개발자 커뮤니티에서 가장 많이 언급된 코딩 모델 두 가지는 단연 GLM-5.1과 Claude Sonnet 4.6이었습니다. 전자는 Z.ai(구 지푸)가 MIT 라이선스로 오픈소스를 공개하자마자 SWE-Bench Pro에서 58.4점을 기록하며 Claude Opus 4.6, GPT-5.4, Gemini 3.1 Pro를 모두 제치고 글로벌 오픈소스 코딩 모델 1위에 등극했습니다. 후자는 Anthropic이 "미들급 모델의 플래그십 수준"이라 자부하는 모델로, SWE-bench Verified에서 Opus 4.6(80.8%)에 육박하는 79.6%의 점수를 기록했습니다. 가격은 Opus의 몇 분의 일 수준이면서, Sonnet 시리즈 최초로 1M 토큰 컨텍스트 윈도우를 지원하는 것이 특징이죠.
그렇다면 질문입니다. "GLM-5.1 vs Claude Sonnet 4.6, 실제 프로그래밍 환경에서는 누가 더 강력할까요?" 이 질문은 단 한 문장으로 답하기 어렵습니다. 두 모델의 강점이 매우 다르기 때문입니다. GLM-5.1은 '산업용 실제 코드 수정' 벤치마크에서 Sonnet 4.6을 앞질렀지만, 제3자 종합 평가에서는 Sonnet이 평균 점수를 다시 끌어올렸습니다. 이 글에서는 **6가지 차원(코드 벤치마크, 지식, 가격, 컨텍스트, 에이전트 장기 작업, 생태계 호환성)**을 중심으로 두 모델의 실질적인 차이를 파헤치고, 비즈니스 시나리오별 명확한 선택 가이드를 제시해 드립니다.

GLM-5.1 vs Claude Sonnet 4.6 핵심 데이터 한눈에 보기
비교를 시작하기 전에, 두 모델의 핵심 정보를 표로 정리했습니다. 모든 데이터는 BenchLM, Z.ai, Anthropic 및 제3자 평가 플랫폼의 공개 정보를 바탕으로 합니다.
| 차원 | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| 제조사 | Z.ai(구 지푸 AI) | Anthropic |
| 출시일 | 2026-04-07(오픈소스) | 2026년 초 |
| 아키텍처 | 754B MoE / 40B 활성 | 미공개(중형 Sonnet급) |
| 오픈소스 라이선스 | ✅ MIT | ❌ 비공개 |
| 컨텍스트 윈도우 | 200K(일부 플랫폼 203K) | 200K → 1M(베타) |
| SWE-bench Verified | 77.8% | 79.6% |
| SWE-Bench Pro | 58.4 ⭐(오픈소스 1위, Opus 4.6 상회) | Opus 4.6 대비 소폭 낮음 |
| BenchLM 종합 코딩 평균 | 58.4 | 66.4 |
| BenchLM 지식 평균 | 52.3 | 73.7 |
| BenchLM 총점 | 79 | 80 |
| 입력 가격 ($/M) | $1.00(Z.ai 직구매) | $3.00 |
| 출력 가격 ($/M) | $3.20(Z.ai 직구매) | $15.00 |
| 에이전트 장기 작업 | 단일 작업 약 8시간 | Claude Code 사용자 선호도 70% |
| APIYI 연동 | ✅ https://api.apiyi.com/v1 지원 |
✅ 지원 |
| 호환 도구 | Claude Code / Cline / Cursor / OpenClaw | 위와 동일 + 네이티브 Anthropic 생태계 |
🎯 빠른 판단 가이드: "두 모델 중 누가 더 강한가"가 아니라 **"어떤 시나리오에서 더 강력한가"**가 핵심입니다. 지금 바로 비교해보고 싶다면, APIYI(apiyi.com)에서 GLM-5.1과 Claude Sonnet 4.6을 모두 지원하므로
model필드만 변경하여 동일한 비즈니스 코드에서 테스트해보세요. 15분이면 어떤 벤치마크보다 정확한 결과를 직접 확인하실 수 있습니다.
title: "GLM-5.1 vs Claude Sonnet 4.6 핵심 차이: 같은 체급이 아닙니다"
GLM-5.1 vs Claude Sonnet 4.6 핵심 차이: 같은 체급이 아닙니다
가장 먼저 확실히 짚고 넘어가야 할 사실은, GLM-5.1과 Claude Sonnet 4.6은 엄밀히 말해 '같은 체급'의 모델이 아니라는 점입니다. 두 모델은 설계 목표부터 시스템적인 차이를 보입니다.
모델 포지셔닝 차이
| 구분 | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| 제조사 포지셔닝 | "최첨단 오픈소스 + 장기 에이전트 코딩" | "중급 플래그십 · 가성비의 제왕" |
| 파라미터 규모 | 대규모 언어 모델(754B MoE) | 중형 모델(파라미터 비공개) |
| 학습 목표 | 코딩 + 에이전트 + 수학적 추론 | 범용 + 코딩 + 지식 + 안전성 |
| 비즈니스 모델 | MIT 오픈소스 + Z.ai 자체 API | 폐쇄형 구독 + API |
| 주요 경쟁 모델 | Claude Opus 4.6 / GPT-5.4 | Claude Opus 4.5 / GPT-5 / Sonnet 4.5 |
이 부분을 주목하세요. Z.ai 내부에서 GLM-5.1은 사실 Sonnet 4.6이 아닌 Claude Opus 4.6을 타깃으로 설계되었습니다. 즉, 단순히 '코딩 능력의 상한선'을 비교한다면 GLM-5.1의 비교 대상은 Sonnet이 아니라 Opus여야 합니다. 하지만 '가격 + 종합 능력 + 실용성'이라는 세 가지 측면에서 Sonnet 4.6은 중급 시장의 매우 강력한 경쟁자이기에, 두 모델을 함께 비교하는 것은 여전히 실무적으로 큰 의미가 있습니다.
서드파티 종합 평가 현황
2026년 4월 BenchLM에서 발표한 임시 순위에 따르면:
- 총점: Claude Sonnet 4.6 = 80점, GLM-5.1 = 79점 (1점 차이, 거의 대등)
- 코딩 평균: Claude Sonnet 4.6 = 66.4점, GLM-5.1 = 58.4점 (Sonnet 4.6이 8점 앞섬)
- 지식 평균: Claude Sonnet 4.6 = 73.7점, GLM-5.1 = 52.3점 (Sonnet 4.6이 21.4점 앞서며 격차가 가장 큼)
하지만 다른 특정 벤치마크에서는 상황이 완전히 반전됩니다.
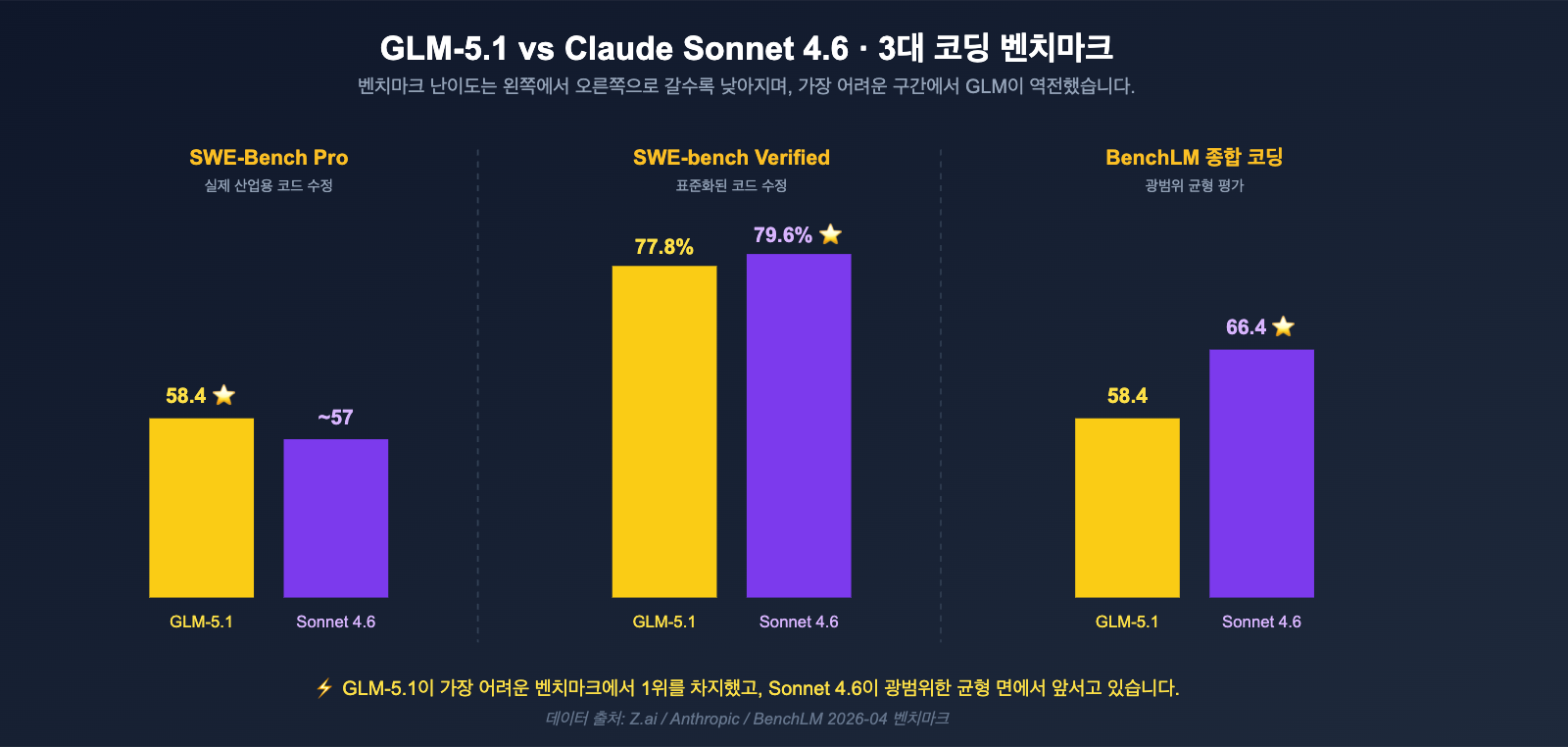
- SWE-Bench Pro(실제 산업용 코드 수정): GLM-5.1 = 58.4점 ⭐, Claude Opus 4.6(57.3점)과 GPT-5.4(57.7점)를 앞질렀으며, Sonnet 4.6 역시 하위권입니다.
- SWE-bench Verified: Claude Sonnet 4.6 = 79.6%, GLM-5.1 = 77.8%, 단 1.8% 포인트 차이
이 수치들을 종합해보면 첫 번째 결론이 나옵니다. GLM-5.1은 "Sonnet 4.6을 완전히 압도하는" 괴물은 아니지만, "난이도가 가장 높은 산업용 코드 수정" 분야에서는 확실히 1위를 차지했습니다. 반면 Sonnet 4.6은 더 넓은 범위의 종합 코딩 평가에서 균형 잡힌 우위를 유지하고 있습니다.
차원 1: 코드 벤치마크 비교 — GLM-5.1과 Sonnet 4.6의 실제 격차
코딩 능력은 이번 비교의 핵심이며, 벤치마크 수치로 가장 오해하기 쉬운 부분이기도 합니다. 관련 벤치마크를 모두 표로 정리하고 엔지니어의 관점에서 해석해 보겠습니다.
코드 관련 벤치마크 전체 비교
| 벤치마크 | GLM-5.1 | Claude Sonnet 4.6 | 우위 | 격차 |
|---|---|---|---|---|
| SWE-Bench Pro | 58.4 | < 57.3 | GLM-5.1 | ~1점 이상 |
| SWE-bench Verified | 77.8% | 79.6% | Sonnet 4.6 | 1.8% |
| BenchLM 코딩 평균 | 58.4 | 66.4 | Sonnet 4.6 | 8점 |
| OSWorld(에이전트 데스크톱) | 미공개 | 72.5% | Sonnet 4.6 | — |
| Claude Code 사용자 선호도 | 미참여 | 70%(Sonnet 4.5 대비), 59%(Opus 4.5 대비) | Sonnet 4.6 | — |
| 8시간 장기 작업 | ✅ 공식 주력 | Claude Code 장기 작업 지원 | 대등 | — |
엔지니어 관점의 해석
이 표를 세 번 정도 꼼꼼히 읽어보면, 비전문가도 이해할 수 있는 몇 가지 결론을 도출할 수 있습니다.
- "실제 저장소의 실제 버그를 수정하는" 업무라면: GLM-5.1이 SWE-Bench Pro에서 1위를 차지했습니다. 이는 일선 엔지니어의 일상과 가장 밀접한 벤치마크로, GLM-5.1이 코딩 에이전트의 핵심 엔진으로 가장 적합함을 의미합니다.
- "표준화된 코드 수정 + 범용 프로그래밍" 업무라면: Sonnet 4.6의 SWE-bench Verified 점수가 약간 더 높고, BenchLM 종합 코딩 평균이 확실히 앞서므로 '범용성' 측면에서 더 안정적입니다.
- Claude Code / Cursor 내 장기 작업 업무라면: Sonnet 4.6의 70% 사용자 선호도는 '실제 개발 흐름'에서 검증되었음을 보여줍니다. GLM-5.1의 8시간 장기 작업 능력은 Z.ai의 주력 셀링 포인트이지만, 직접 사용해보고 확인이 필요합니다.
- "지식 집약적 문제"(문서 검색, 설계 작성, 기술 조사)가 포함된 업무라면: Sonnet 4.6(73.7점) vs GLM-5.1(52.3점)로 격차가 매우 뚜렷합니다.
왜 이런 "벤치마크 간의 충돌"이 발생하는가?
많은 독자분이 질문합니다. "똑같은 코딩 능력인데 왜 어떤 벤치마크는 GLM-5.1이 강하다고 하고, 다른 쪽은 Sonnet 4.6이 강하다고 할까?" 그 답은 벤치마크 설계의 차이에 있습니다.
- SWE-Bench Pro는 "난이도가 매우 높은 실제 산업용 코드 수정"에 치중되어 있습니다. 작업 품질 기준이 높고 데이터셋이 적어 모델의 '장기 추론 + 도구 호출' 능력을 극단적으로 요구하는데, 이것이 바로 GLM-5.1이 주력하는 방향입니다.
- SWE-bench Verified는 "인간이 검증한 표준 코드 수정 작업 세트"로, "일상적인 개발 환경의 평균 수준"에 더 가깝습니다. 모델의 '범용성 + 안정성' 요구치가 더 높으며, 이는 Sonnet 4.6의 강점입니다.
- BenchLM 종합 코딩 평균은 여러 벤치마크를 가중 평균한 것으로, '모든 유형의 작업에 대응 가능한' 중형 플래그십 모델에 더 친화적입니다.
이런 차이를 이해하면 더 이상 단편적인 숫자 하나에 휘둘리지 않게 될 것입니다.
🎯 벤치마크 활용 제안: 하나의 벤치마크만 보고 결론 내리지 마세요. 가장 실무적인 방법은 팀에서 가장 자주 발생하는 5~10개의 실제 코딩 작업을 내부 벤치마크 세트로 구성하는 것입니다. 그런 다음 APIYI(apiyi.com)를 통해 GLM-5.1과 Claude Sonnet 4.6을 각각 호출하여, 여러분의 비즈니스 스타일에 무엇이 더 적합한지 직접 데이터를 통해 검증해 보시기 바랍니다.
차원 2: 지식 및 추론 — Sonnet 4.6의 확실한 우위
코드 영역이 "서로 엎치락뒤치락"하는 수준이라면, 지식 / 추론 / 범용 이해 차원에서는 Sonnet 4.6의 우위가 매우 뚜렷합니다.
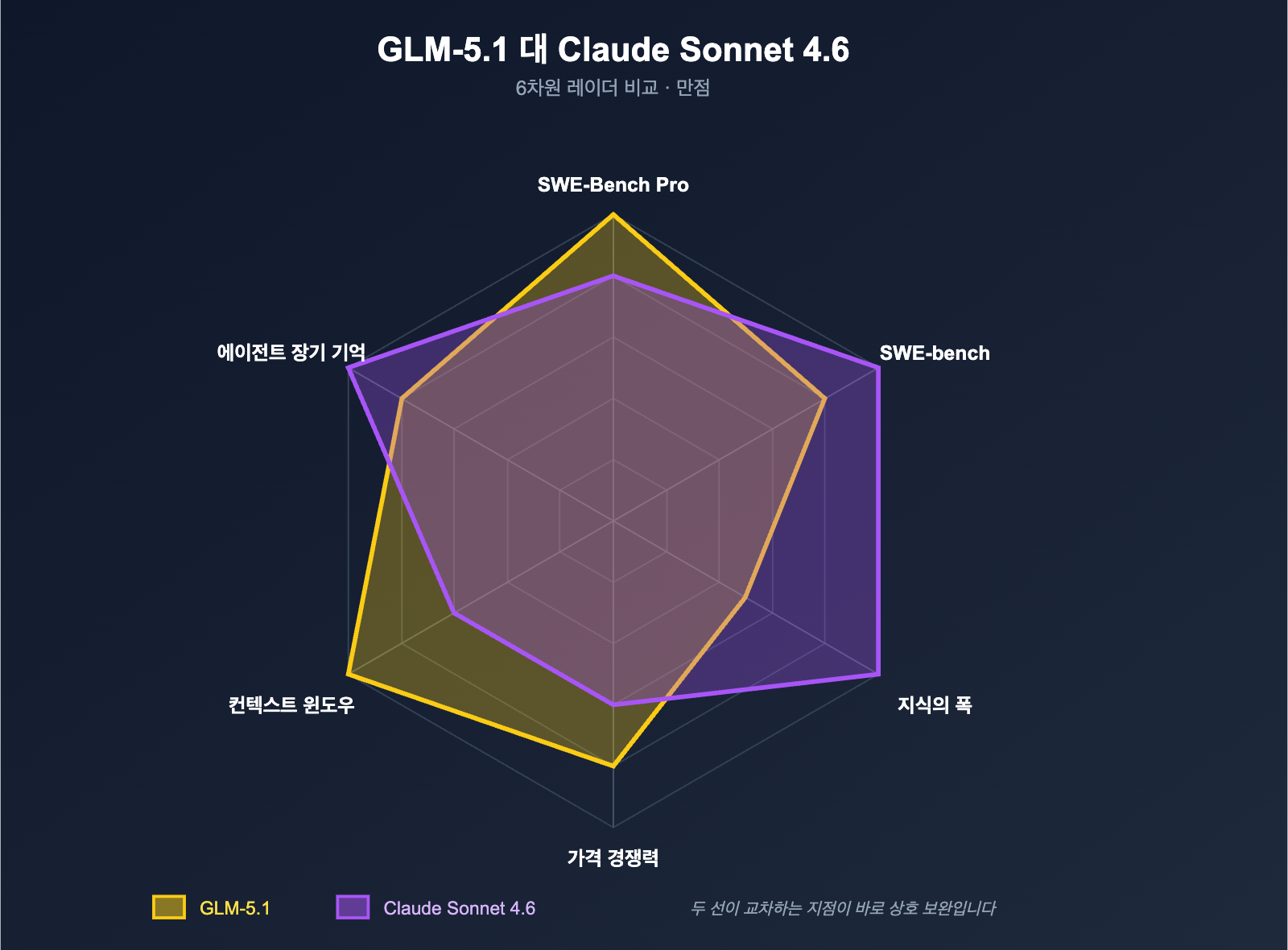
| 차원 | GLM-5.1 | Claude Sonnet 4.6 | 격차 |
|---|---|---|---|
| BenchLM 지식 평균 점수 | 52.3 | 73.7 | 21.4점 |
| 긴 문서 이해 | 강함 | 더 강함(1M 컨텍스트 윈도우 지원) | |
| 자연어 작문 | 중문 우수 | 다국어 균형 잡힘 | |
| 안전 및 규정 준수 추론 | 보통 | 확실히 더 강함(Anthropic 강점) |
즉, 다음과 같은 상황에서는 Sonnet 4.6이 더 안정적인 선택입니다.
- 기술 조사 보고서 / 설계 문서 / 아키텍처 제안서 작성 시
- 다국어 문서 요약 및 규정 준수 분석 시
- "코딩과 비즈니스 이해"가 모두 필요한 복합 작업 시
- 고객 대면 콘텐츠 생성 등 더 강력한 안전 가이드라인이 요구될 때
GLM-5.1이 지식 차원에서 상대적으로 약한 것은 "학습이 부족해서"가 아니라, 학습 데이터와 목표가 코딩 + 수학 + 도구 사용에 더 치중되어 있기 때문이며, "일반 지식" 측면에서는 Sonnet 4.6만큼 균형 잡혀 있지 않습니다.
차원 3: 가격 비교 — GLM-5.1의 필살기
단 하나만 본다면, 가격은 GLM-5.1이 Sonnet 4.6에 맞설 수 있는 가장 강력한 무기입니다.
토큰 단가 직접 비교
| 차원 | GLM-5.1(Z.ai 직구매) | Claude Sonnet 4.6 | GLM-5.1 가성비 우위 |
|---|---|---|---|
| 입력 ($/M) | $1.00 | $3.00 | 3배 저렴 |
| 출력 ($/M) | $3.20 | $15.00 | 약 4.7배 저렴 |
| 종합(2:1 비율) | ~$1.73 | ~$7.00 | 약 4배 저렴 |
몇 가지 참고할 점:
- 서드파티 플랫폼(BenchLM 등)에서 집계하는 GLM-5.1 가격은 리셀링 수수료가 포함되어 다소 높지만($1.40 입력 / $4.40 출력), Z.ai 공식 직구매 가격은 $1.00 / $3.20입니다.
- Sonnet 4.6의 $3 / $15는 Anthropic 공식 가격으로, Opus 4.6보다 이미 5배 저렴하며 미드레인지 시장에서는 "가성비의 제왕"으로 통합니다.
- 그럼에도 불구하고 GLM-5.1은 출력 토큰에서 4~5배의 우위를 점하고 있으며, 이는 "입력보다 출력이 많은" 코드 생성 작업에서 엄청난 의미를 갖습니다.
실제 비용 예시
격차를 더 직관적으로 이해하기 위해, "일일 코딩 에이전트"의 전형적인 작업(입력 5K 토큰, 출력 20K 토큰, 일일 1,000회 호출)을 가정해 보겠습니다.
| 모델 | 일일 입력 비용 | 일일 출력 비용 | 일일 합계 | 월간 합계 |
|---|---|---|---|---|
| GLM-5.1 | $5 | $64 | $69 | ~$2,070 |
| Claude Sonnet 4.6 | $15 | $300 | $315 | ~$9,450 |
격차: Sonnet 4.6의 월 비용은 GLM-5.1의 약 4.5배입니다.
"일일 1,000회 에이전트 호출"을 수행하는 중형 SaaS 기업의 경우, 토큰 비용만으로 월 7,000달러 가까이 차이가 납니다. 이 금액이면 엔지니어 반 명을 더 고용할 수 있는 수준이죠.
🎯 비용 최적화 제안: 이미 Claude Sonnet 4.6을 사용 중인 팀이라면, 먼저 APIYI(apiyi.com)에서 **트래픽의 20%**를 GLM-5.1로 돌려 A/B 테스트를 해보시길 권장합니다. 결과가 만족스럽다면 "비핵심 업무의 코드 생성"은 모두 GLM-5.1로 이전하고, "고객 대면" 등 핵심 호출만 Sonnet 4.6으로 유지하세요. 이렇게 하면 전체적인 품질을 유지하면서도 비용을 대폭 절감할 수 있습니다.
차원 4: 컨텍스트 윈도우 — Sonnet 4.6의 반격
가격 면에서는 GLM-5.1이 완승을 거뒀지만, 컨텍스트 윈도우 항목에서는 Sonnet 4.6이 주도권을 되찾았습니다.
| 차원 | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| 표준 컨텍스트 | 200K(일부 플랫폼 203K) | 200K |
| 베타 컨텍스트 | — | 1M 토큰(beta) |
| 최대 출력 | 128K | 낮음 |
| 컨텍스트 압축 | 아니요 | ✅ 오래된 컨텍스트 자동 압축 |
1M 토큰은 Sonnet 4.6의 상징적인 업그레이드입니다. 이는 RAG 검색 없이도 중형 코드 저장소 전체를 한 번에 프롬프트에 집어넣을 수 있음을 의미합니다. '전체 저장소 리팩토링 / 파일 간 버그 위치 파악 / 전체 코드베이스 이해'와 같은 작업에서 Sonnet 4.6은 2026년 4월 기준 대체 불가능한 모델입니다.
GLM-5.1의 200K도 일상적인 작업의 90%는 충분히 커버하지만, '초장거리 컨텍스트'가 필요한 극한의 상황에서는 확실히 한 발 뒤처지는 모습입니다.
차원 5: Agent 장기 작업 — 두 가지 전략의 대결
다섯 번째 차원은 Agent 장기 작업 능력입니다. 이는 2026년 모든 주요 코딩 모델이 치열하게 경쟁하는 분야죠.
두 모델의 '장기 작업' 접근 방식
- GLM-5.1: Z.ai는 '단일 작업 8시간 연속 수행'을 내세웁니다. 계획 → 실행 → 테스트 → 수정 → 2차 최적화로 이어지는 엔드투엔드 루프를 강조하며, 모델 자체의 추론 깊이와 도구 호출 안정성에 승부를 걸었습니다.
- Claude Sonnet 4.6: Anthropic은 'Claude Code 실전 경험'을 강조합니다. 내부 테스트에서 Sonnet 4.5 사용자의 70%가 Sonnet 4.6을 선호했으며, 공학적으로 설계된 Claude Code 워크플로우 + 1M 컨텍스트 + 컨텍스트 압축을 강점으로 내세웁니다.
정리하자면 다음과 같습니다:
| 접근 방식 | 핵심 강점 | 적합한 시나리오 |
|---|---|---|
| GLM-5.1 | 모델 추론 깊이 + 도구 호출 안정성 | 백그라운드 자동화 Agent / 무인 작업 |
| Sonnet 4.6 | Claude Code 워크플로우 + 1M 컨텍스트 | 개발자 대화형 코딩 / IDE 통합 |
만약 '백그라운드에서 Agent가 스스로 기능을 개발하는' 무인 시나리오를 원하신다면 GLM-5.1의 8시간 장기 작업 능력이 제격입니다. 반면, '엔지니어가 IDE에서 모델과 대화하며 코딩하는' 환경이라면 Sonnet 4.6의 Claude Code 통합 경험이 훨씬 성숙합니다.
차원 6: 생태계 호환성 — Sonnet 4.6의 툴체인 강점
마지막 차원은 생태계입니다. 이 항목에서 Sonnet 4.6은 여전히 확실한 우위를 점하고 있지만, GLM-5.1이 매우 빠르게 추격하고 있습니다.
| 차원 | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Claude Code 호환 | ✅(OpenAI 호환 엔드포인트) | ✅ 네이티브 |
| Cline / Cursor | ✅(OpenAI 호환 엔드포인트) | ✅ 네이티브 |
| OpenClaw | ✅ | ✅ |
| Anthropic 도구 호출 | OpenAI 스타일 | ✅ 네이티브 |
| 서드파티 Agent 프레임워크 | 대부분 OpenAI 호환 지원 | 대부분 Anthropic 네이티브 지원 |
| 배포 유연성 | ✅ MIT 오픈소스 / APIYI / Z.ai 자사 운영 | APIYI / Anthropic 공식 |
주목할 점은 APIYI(apiyi.com)가 OpenAI / Claude 네이티브 / Gemini 네이티브 3가지 형식을 모두 지원한다는 것입니다. 즉, 어떤 스타일의 SDK를 사용하든 동일한 API 키 하나로 GLM-5.1과 Sonnet 4.6을 모두 호출할 수 있습니다. 이는 두 모델을 비교 테스트할 때 매우 유용한 디테일입니다. 테스트 기간 동안 두 개의 인증, 두 개의 모니터링, 두 개의 청구서를 관리할 필요가 없기 때문이죠.
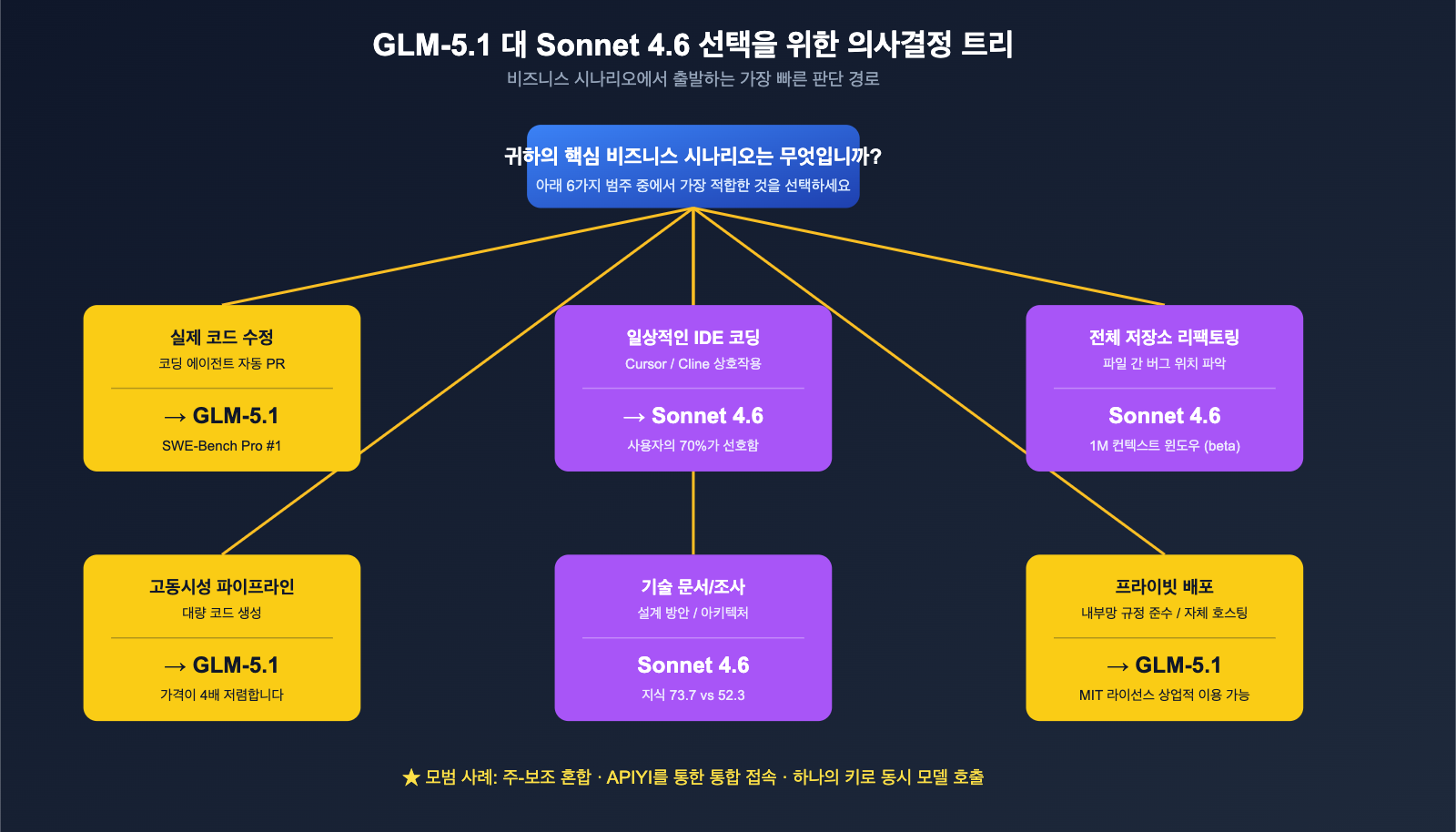
시나리오별 최종 모델 선정 제안
6가지 차원을 종합하여 비즈니스 시나리오별로 구체적인 모델 선정 가이드를 제안해 드립니다.
시나리오 대조표
| 비즈니스 시나리오 | 추천 모델 | 핵심 이유 |
|---|---|---|
| 실제 산업 코드 수정(Agent 자동 PR) | GLM-5.1 | SWE-Bench Pro 세계 1위 + 8시간 장기 컨텍스트 |
| Cursor / Cline 일상 IDE 코딩 | Claude Sonnet 4.6 | Claude Code 사용자 선호도 70%, 워크플로우 성숙 |
| 전체 저장소 리팩토링 / 파일 간 버그 추적 | Claude Sonnet 4.6 | 1M 컨텍스트 윈도우(베타)가 핵심 무기 |
| 표준화된 코드 생성 + 고동시성 호출 | GLM-5.1 | 4배 저렴한 가격, 파이프라인 생산에 적합 |
| 기술 조사 / 설계 문서 / 아키텍처 설계 | Claude Sonnet 4.6 | 지식 점수 73.7 vs 52.3으로 크게 앞섬 |
| 수학적 추론 / 알고리즘 경진대회 스타일 | GLM-5.1 | AIME 2026 95.3 + GPQA-Diamond 86.2 |
| 고객 대면 SaaS 내 코드 생성 모듈 | Sonnet 4.6(주) + GLM-5.1(보조) | Sonnet 주력, GLM 보조로 비용 절감 및 품질 유지 |
| 프라이빗 배포 / 내부망 규정 준수 | GLM-5.1 | MIT 라이선스 + 자체 호스팅 가능 |
| 한국어 코딩 상호작용 | GLM-5.1 | 국산 모델이 한국어 프롬프트에 더 친화적 |
| 일회성 고난도 추론 + 긴 링크 도구 호출 | 무승부, 자체 테스트 필요 | 둘 다 가능, 차이는 5% 이내 |
추천하는 하이브리드 전략
대다수의 중형 팀에게는 "둘 중 하나 선택"보다는 "주력/보조 하이브리드" 전략을 추천합니다.
- 주력 모델: 가장 많은 비즈니스 시나리오에 맞춰 하나를 선택하세요(코드 수정은 GLM-5.1, IDE 통합은 Sonnet 4.6).
- 보조 모델: 다른 모델을 연결하여 핵심 비즈니스의 A/B 테스트 및 그레이드 전환에 활용하세요.
- 통합 액세스 계층: APIYI(apiyi.com)를 통해 동일한 API 키로 두 모델을 호출하세요. 비즈니스 코드에서
model필드만 변경하면 되므로 두 가지 인증 로직을 유지할 필요가 없습니다. - 비용 모니터링: APIYI 콘솔에서 두 모델의 청구서를 분리하여 확인하고, 비즈니스에서 어떤 모델의 "가성비"가 더 높은지 주기적으로 판단하여 트래픽 비율을 동적으로 조정하세요.
🎯 하이브리드 전략 실행 팁: APIYI(apiyi.com)에서는 동일한 API 키로 GLM-5.1과 Claude Sonnet 4.6 사이를 매끄럽게 전환할 수 있으며, 비즈니스 코드 수정은 문자열 하나만 바꾸면 됩니다. "비핵심 코드 생성" 트래픽의 70%는 GLM-5.1로, "고객 대면 + 고난도 추론" 트래픽의 30%는 Sonnet 4.6으로 배분하는 것을 추천합니다. 이렇게 하면 GLM-5.1의 가격 경쟁력을 누리면서도 핵심 시나리오의 안정성을 보장할 수 있습니다.
GLM-5.1 vs Claude Sonnet 4.6 자주 묻는 질문(FAQ)
Q1: GLM-5.1이 정말 코딩 능력에서 Claude Sonnet 4.6을 앞섰나요?
일부 앞섰지만, 여전히 뒤처지는 부분도 있습니다. 실제 산업용 코드 수정 벤치마크인 SWE-Bench Pro에서 GLM-5.1은 58.4점으로 전 세계 1위를 차지하며, Claude Opus 4.6(57.3점)과 GPT-5.4(57.7점)는 물론 Sonnet 4.6까지 넘어섰습니다. 하지만 표준화된 코드 수정 벤치마크인 SWE-bench Verified에서는 Sonnet 4.6이 79.6%로 GLM-5.1(77.8%)보다 약 1.8%p 앞서고, BenchLM 종합 코딩 점수에서도 Sonnet 4.6(66.4점)이 GLM-5.1(58.4점)보다 약 8점 높습니다. 결론은 GLM-5.1이 "최고 난이도"에서는 Sonnet 4.6을 추월했지만, "범용적인 균형감"에서는 여전히 뒤처진다는 것입니다.
Q2: GLM-5.1은 Claude Sonnet 4.6보다 얼마나 저렴한가요?
Z.ai 공식 가격 기준으로 GLM-5.1은 입력 $1.00 / 출력 $3.20인 반면, Claude Sonnet 4.6은 $3.00 / $15.00입니다. 입력은 3배, 출력은 약 4.7배 저렴하죠. "일일 1,000회 코딩 에이전트 호출 + 입력 5K / 출력 20K"의 일반적인 시나리오에서 Sonnet 4.6의 월 이용료는 GLM-5.1의 약 4.5배에 달합니다. 만약 귀하의 비즈니스가 "입력보다 출력량이 훨씬 많은" 구조라면, GLM-5.1의 가성비가 더욱 돋보일 것입니다.
Q3: GLM-5.1과 Sonnet 4.6 중 컨텍스트 윈도우가 더 큰 모델은 무엇인가요?
Claude Sonnet 4.6이 더 큽니다. GLM-5.1은 200K(일부 플랫폼은 203K로 표시)를 지원하지만, Sonnet 4.6은 200K에서 최대 **1M 토큰(베타)**까지 지원합니다. 1M 컨텍스트는 Sonnet 4.6이 중형 코드 저장소 전체를 한 번에 읽을 수 있다는 의미이며, 이는 "전체 저장소 리팩토링 / 파일 간 버그 추적" 작업에서 강력한 무기가 됩니다. 초장문 컨텍스트가 필수적인 작업이라면 Sonnet 4.6이 더 안정적인 선택입니다.
Q4: 현재 Cursor / Cline에서 Claude Sonnet 4.6을 사용 중인데, GLM-5.1로 전환할 가치가 있을까요?
당신의 고민이 무엇인지에 따라 다릅니다. "비용 절감"이 최우선이라면 GLM-5.1로 전환하여 비용을 절반 이하로 줄일 가치가 충분합니다. 하지만 "일상적인 코딩 경험의 안정성"이 중요하다면, Sonnet 4.6의 70% 사용자 선호도가 증명하듯 이미 Claude Code 워크플로우에서 검증된 모델이므로 전환에 따른 리스크가 클 수 있습니다. 가장 안전한 방법은 APIYI(apiyi.com)를 통해 트래픽의 20%를 GLM-5.1로 분산하여 A/B 테스트를 일주일간 진행한 뒤 확대 여부를 결정하는 것입니다.
Q5: GLM-5.1과 Sonnet 4.6 모두 APIYI에서 호출할 수 있나요?
네, 두 모델 모두 지원합니다. APIYI(apiyi.com)는 OpenAI / Claude Native / Gemini Native 세 가지 원본 형식을 모두 지원합니다. OpenAI SDK의 base_url을 https://api.apiyi.com/v1로 변경하고, model 값을 glm-5.1과 claude-sonnet-4-6(또는 해당 ID) 사이에서 전환하기만 하면 동일한 코드 내에서 두 모델을 모두 실행할 수 있어 교차 비교 효율이 매우 높습니다.
Q6: 1인 개발자라면 무엇을 선택해야 할까요?
하나만 선택해야 한다면 본인의 워크플로우를 먼저 확인하세요. 코딩 에이전트 / 백엔드 자동화 / 대량 코드 생성 작업이 주력이라면 GLM-5.1을, IDE 내 대화형 프로그래밍 / 전체 저장소 리팩토링 / 고객 대상 콘텐츠 생성이 주력이라면 Sonnet 4.6을 추천합니다. 굳이 하나만 고를 필요가 없다면 두 모델을 모두 연결하고 APIYI로 통합 관리하는 것이 2026년 개발자의 모범 사례입니다. 모델 선택에 따라 비용이 자동으로 최적화되며, 특정 업체에 종속되지 않을 수 있습니다.
요약: GLM-5.1 vs Claude Sonnet 4.6 최종 판단
6가지 측면을 종합해 볼 때, GLM-5.1 vs Claude Sonnet 4.6에 대한 최종 평가는 다음과 같습니다: GLM-5.1은 "최고 난이도 산업용 코드 수정 + 가격 + 국산 오픈소스 + 장기 에이전트" 4가지 측면에서 구조적 강점을 가지며, Claude Sonnet 4.6은 "범용적 균형감 + 지식 깊이 + 1M 컨텍스트 + IDE 워크플로우 성숙도" 4가지 측면에서 우위를 유지합니다. 두 모델은 서로를 대체하는 관계가 아니라, 각기 다른 비즈니스 시나리오를 보완하는 도구입니다.
2026년 중후반 중국 본토 개발팀에게 가장 현명한 전략은 '이것 아니면 저것'이 아닌 **"주력/보조 혼합 + 통합 액세스 레이어"**입니다. 비용 민감도가 높고 장기 자동화가 필요한 작업에는 GLM-5.1을, 사용자 대상의 복잡한 컨텍스트와 기술 문서 작성에는 Sonnet 4.6을 활용하세요. APIYI와 같은 통합 중계 서비스를 통해 두 모델을 하나의 API 키로 관리하고, 실제 비즈니스 비용 데이터를 기반으로 트래픽 비율을 동적으로 조정하면 품질 저하 없이 월간 비용을 획기적으로 절감할 수 있습니다.
🎯 최종 제안: GLM-5.1과 Claude Sonnet 4.6 모두 APIYI(apiyi.com)에서 이용 가능합니다. 지금 바로 apiyi.com에서 API 키를 생성하고, OpenAI SDK의
base_url을https://api.apiyi.com/v1으로 변경해 보세요. 동일한 코드와 프롬프트로 GLM-5.1 작업 5개, Sonnet 4.6 작업 5개를 각각 실행하며 본문의 6가지 결론을 직접 검증해 보시길 권장합니다. 어떤 평가 지표도 직접 해보는 것만큼 정확하지 않습니다. 30분간의 테스트만으로도 2026년 최강의 코딩 모델 두 가지에 대한 확실한 감을 잡으실 수 있을 것입니다.
작성자: APIYI Team | AI 대규모 언어 모델 활용 및 코딩 툴체인 평가에 집중합니다. 더 많은 모델 비교와 실전 호출 가이드는 APIYI(apiyi.com)에서 확인하세요.