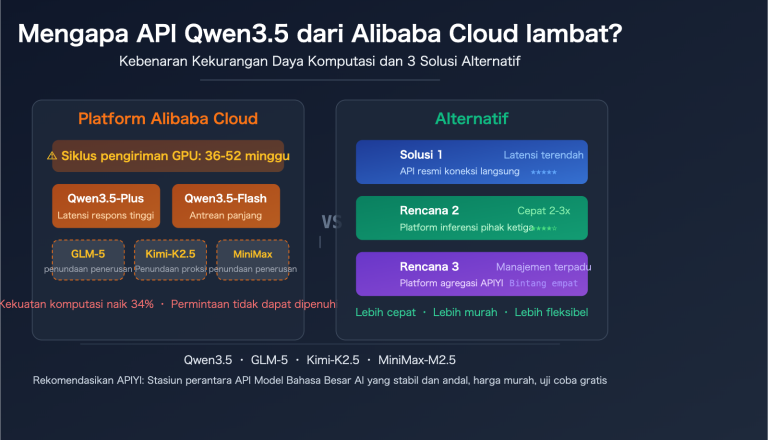
Mengalami kesalahan 429 You exceeded your current quota saat mengembangkan aplikasi AI dengan Qwen3-Max sering kali menjadi masalah bagi banyak pengembang. Artikel ini akan menganalisis mekanisme pembatasan kecepatan Qwen3-Max dari Alibaba Cloud secara mendalam dan memberikan 5 solusi praktis untuk membantu Anda mengatasi masalah kuota yang tidak mencukupi.
Nilai Utama: Setelah membaca artikel ini, Anda akan memahami prinsip pembatasan kecepatan Qwen3-Max, menguasai berbagai solusi, dan memilih cara paling sesuai untuk memanggil Model Bahasa Besar dengan triliunan parameter secara stabil.
Ikhtisar Masalah Pembatasan Kecepatan Qwen3-Max
Informasi Kesalahan Tipikal
Saat aplikasi Anda sering memanggil API Qwen3-Max, Anda mungkin menemui kesalahan berikut:
{
"error": {
"message": "You exceeded your current quota, please check your plan and billing details.",
"type": "insufficient_quota",
"code": "insufficient_quota"
},
"status": 429
}
Kesalahan ini berarti Anda telah memicu batas kuota di Alibaba Cloud Model Studio.
Cakupan Dampak Masalah Pembatasan Kecepatan Qwen3-Max
| Skenario Dampak | Manifestasi Spesifik | Tingkat Keparahan |
|---|---|---|
| Pengembangan Agent | Dialog multi-putaran sering terputus | Tinggi |
| Pemrosesan Batch | Tugas tidak dapat diselesaikan | Tinggi |
| Aplikasi Real-time | Pengalaman pengguna terganggu | Tinggi |
| Pembuatan Kode | Output kode panjang terpotong | Sedang |
| Pengujian & Debugging | Efisiensi pengembangan menurun | Sedang |
Penjelasan Detail Mekanisme Pembatasan Kecepatan Qwen3-Max
Batasan Kuota Resmi Alibaba Cloud
Berdasarkan dokumentasi resmi Alibaba Cloud Model Studio, batasan kuota untuk Qwen3-Max adalah sebagai berikut:
| Versi Model | RPM (Permintaan/Menit) | TPM (Token/Menit) | RPS (Permintaan/Detik) |
|---|---|---|---|
| qwen3-max | 600 | 1,000,000 | 10 |
| qwen3-max-2025-09-23 | 60 | 100,000 | 1 |
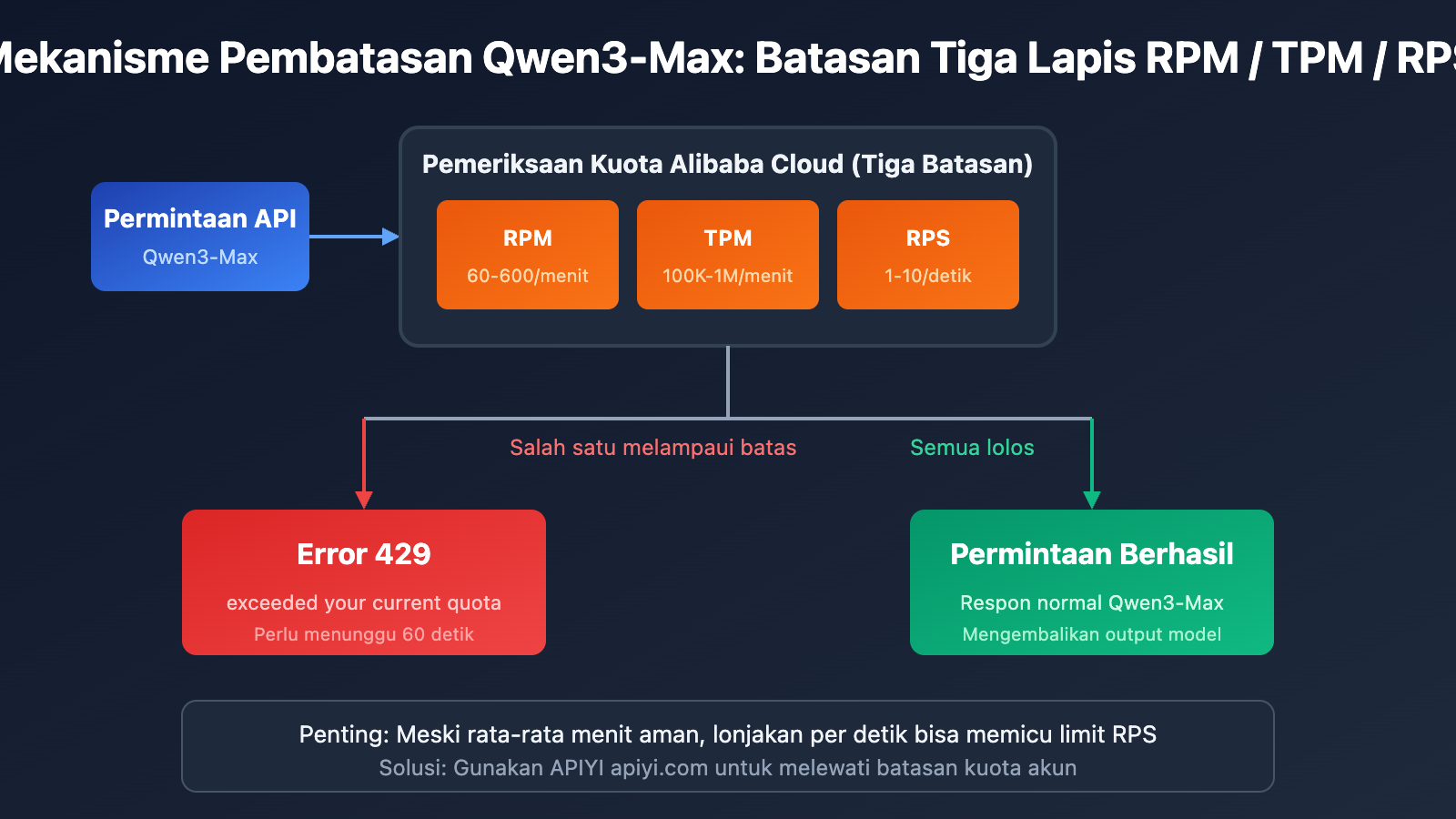
4 Situasi yang Memicu Pembatasan Kecepatan Qwen3-Max
Alibaba Cloud menerapkan mekanisme pembatasan ganda pada Qwen3-Max. Jika salah satu kondisi berikut terpenuhi, sistem akan mengembalikan error 429:
| Tipe Error | Pesan Error | Penyebab |
|---|---|---|
| Frekuensi Permintaan Terlampaui | Requests rate limit exceeded | RPM/RPS melebihi batas |
| Konsumsi Token Terlampaui | You exceeded your current quota | TPM/TPS melebihi batas |
| Perlindungan Lonjakan Trafik | Request rate increased too quickly | Lonjakan permintaan instan |
| Kuota Gratis Habis | Free allocated quota exceeded | Kuota uji coba telah habis |
Rumus Perhitungan Pembatasan Kecepatan
Batas Aktual = min(Batas RPM, RPS × 60)
= min(Batas TPM, TPS × 60)
Catatan Penting: Meskipun penggunaan dalam satu menit belum melampaui batas, permintaan yang melonjak dalam skala detik tetap dapat memicu pembatasan (throttling).
5 Solusi Masalah Pembatasan Kecepatan Qwen3-Max
Ringkasan Perbandingan Solusi
| Solusi | Kesulitan | Efek | Biaya | Skenario Rekomendasi |
|---|---|---|---|---|
| Layanan Perantara API | Rendah | Sangat Efektif | Lebih Hemat | Semua skenario |
| Strategi Smoothing | Menengah | Meredakan | Gratis | Pembatasan ringan |
| Polling Multi-Akun | Tinggi | Meredakan | Tinggi | Pengguna korporat |
| Fallback ke Model Cadangan | Menengah | Penyelamat | Menengah | Tugas non-inti |
| Pengajuan Penambahan Kuota | Rendah | Terbatas | Gratis | Pengguna jangka panjang |
Solusi 1: Menggunakan Layanan Perantara API (Direkomendasikan)
Ini adalah cara paling langsung dan efektif untuk mengatasi masalah limit Qwen3-Max. Dengan memanggil melalui platform perantara API, Anda bisa melewati batasan kuota di tingkat akun Alibaba Cloud.
Mengapa Perantara API Bisa Mengatasi Limit?
| Item Perbandingan | Langsung ke Alibaba Cloud | Melalui APIYI |
|---|---|---|
| Batasan Kuota | Limit RPM/TPM per akun | Berbagi kuota pool besar platform |
| Frekuensi Limit | Sering memicu 429 | Hampir tidak ada limit |
| Harga | Harga resmi | Diskon hingga 0.88x (lebih murah) |
| Stabilitas | Tergantung kuota akun | Jaminan banyak saluran (multi-channel) |
Contoh Kode Sederhana
from openai import OpenAI
# Gunakan layanan perantara APIYI, lupakan masalah limit
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3-max",
messages=[
{"role": "user", "content": "Jelaskan cara kerja arsitektur MoE"}
]
)
print(response.choices[0].message.content)
🎯 Rekomendasi Utama: Panggil Qwen3-Max melalui APIYI apiyi.com. Selain menuntaskan masalah limit, Anda juga bisa mendapatkan harga diskon yang jauh lebih murah. APIYI bekerja sama dengan Alibaba Cloud untuk menyediakan layanan yang lebih stabil dan ekonomis.
Lihat Kode Lengkap (Termasuk Retry dan Error Handling)
import time
from openai import OpenAI
from openai import APIError, RateLimitError
class Qwen3MaxClient:
"""Client Qwen3-Max via APIYI, bebas hambatan limit"""
def __init__(self, api_key: str):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # Endpoint APIYI
)
self.model = "qwen3-max"
def chat(self, message: str, max_retries: int = 3) -> str:
"""
Mengirim pesan dan mendapatkan balasan.
Menggunakan APIYI hampir tidak akan menemui masalah limit.
"""
for attempt in range(max_retries):
try:
response = self.client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": message}],
max_tokens=4096
)
return response.choices[0].message.content
except RateLimitError as e:
# Dengan APIYI, error ini jarang terjadi
if attempt < max_retries - 1:
wait_time = 2 ** attempt
print(f"Permintaan terbatas, mencoba lagi dalam {wait_time} detik...")
time.sleep(wait_time)
else:
raise e
except APIError as e:
print(f"Error API: {e}")
raise e
return ""
def batch_chat(self, messages: list[str]) -> list[str]:
"""Memproses pesan secara batch tanpa khawatir limit"""
results = []
for msg in messages:
result = self.chat(msg)
results.append(result)
return results
# Contoh Penggunaan
if __name__ == "__main__":
client = Qwen3MaxClient(api_key="your-apiyi-key")
# Pemanggilan tunggal
response = client.chat("Tuliskan algoritma quicksort dalam Python")
print(response)
# Pemanggilan batch - Lancar jaya dengan APIYI
questions = [
"Jelaskan apa itu arsitektur MoE",
"Bandingkan Transformer dan RNN",
"Apa itu mekanisme perhatian (attention mechanism)"
]
answers = client.batch_chat(questions)
for q, a in zip(questions, answers):
print(f"T: {q}\nJ: {a}\n")
Solusi 2: Strategi Smoothing Permintaan
Jika Anda tetap ingin terhubung langsung ke Alibaba Cloud, Anda bisa menggunakan teknik smoothing untuk meredakan masalah limit.
Exponential Backoff Retry
import time
import random
def call_with_backoff(func, max_retries=5):
"""Strategi retry dengan exponential backoff"""
for attempt in range(max_retries):
try:
return func()
except Exception as e:
if "429" in str(e) and attempt < max_retries - 1:
# Backoff eksponensial + jitter acak
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"Limit terpicu, menunggu {wait_time:.2f} detik sebelum mencoba lagi...")
time.sleep(wait_time)
else:
raise e
Buffer Antrean Permintaan (Request Queue)
import asyncio
from collections import deque
class RequestQueue:
"""Antrean permintaan untuk menstabilkan frekuensi pemanggilan Qwen3-Max"""
def __init__(self, rpm_limit=60):
self.queue = deque()
self.interval = 60 / rpm_limit # Interval antar permintaan
self.last_request = 0
async def throttled_request(self, request_func):
"""Permintaan dengan pembatasan kecepatan"""
now = time.time()
wait_time = self.interval - (now - self.last_request)
if wait_time > 0:
await asyncio.sleep(wait_time)
self.last_request = time.time()
return await request_func()
Catatan: Smoothing hanya meredakan, bukan menghilangkan limit sepenuhnya. Untuk skenario konkurensi tinggi, tetap disarankan menggunakan APIYI.
Solusi 3: Polling Multi-Akun
Pengguna korporat dapat meningkatkan total kuota dengan melakukan polling (perputaran) di antara beberapa akun.

from itertools import cycle
class MultiAccountClient:
"""Client dengan mekanisme polling multi-akun"""
def __init__(self, api_keys: list[str]):
self.clients = cycle([
OpenAI(api_key=key, base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
for key in api_keys
])
def chat(self, message: str) -> str:
client = next(self.clients)
response = client.chat.completions.create(
model="qwen3-max",
messages=[{"role": "user", "content": message}]
)
return response.choices[0].message.content
| Jumlah Akun | RPM Setara | TPM Setara | Kompleksitas Manajemen |
|---|---|---|---|
| 1 | 600 | 1,000,000 | Rendah |
| 3 | 1,800 | 3,000,000 | Menengah |
| 5 | 3,000 | 5,000,000 | Tinggi |
| 10 | 6,000 | 10,000,000 | Sangat Tinggi |
💡 Saran Perbandingan: Mengelola banyak akun itu rumit dan mahal. Lebih praktis menggunakan APIYI apiyi.com yang menyediakan kuota besar tanpa perlu repot urus banyak akun.
Solusi 4: Fallback ke Model Cadangan
Ketika Qwen3-Max terkena limit, sistem dapat otomatis dialihkan ke model cadangan.
class FallbackClient:
"""Client Qwen dengan dukungan fallback otomatis"""
MODEL_PRIORITY = [
"qwen3-max", # Pilihan Utama
"qwen-plus", # Cadangan 1
"qwen-turbo", # Cadangan 2
]
def __init__(self, api_key: str):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # Menggunakan APIYI
)
def chat(self, message: str) -> tuple[str, str]:
"""Mengembalikan (isi balasan, model yang akhirnya digunakan)"""
for model in self.MODEL_PRIORITY:
try:
response = self.client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": message}]
)
return response.choices[0].message.content, model
except Exception as e:
if "429" in str(e):
print(f"{model} kena limit, mencoba model cadangan...")
continue
raise e
raise Exception("Semua model tidak tersedia")
Solusi 5: Pengajuan Penambahan Kuota
Bagi pengguna korporat dengan penggunaan yang stabil dalam jangka panjang, Anda bisa mengajukan kenaikan kuota ke Alibaba Cloud.
Langkah Pengajuan:
- Login ke Konsol Alibaba Cloud.
- Masuk ke halaman Manajemen Kuota Model Studio.
- Kirimkan permohonan penambahan kuota.
- Tunggu peninjauan (biasanya 1-3 hari kerja).
Syarat Pengajuan:
- Akun sudah terverifikasi identitasnya (KYC).
- Tidak memiliki catatan tunggakan pembayaran.
- Memberikan penjelasan skenario penggunaan yang jelas.
Perbandingan Biaya Masalah Pembatasan Kecepatan (Rate Limit) Qwen3-Max
Analisis Perbandingan Harga
| Penyedia Layanan | Harga Input (0-32K) | Harga Output | Kondisi Pembatasan Kecepatan |
|---|---|---|---|
| Koneksi Langsung Alibaba Cloud | $1.20/M | $6.00/M | Pembatasan RPM/TPM yang ketat |
| APIYI (Diskon 0,88x) | $1.06/M | $5.28/M | Hampir tanpa pembatasan kecepatan |
| Selisih Harga | Hemat 12% | Hemat 12% | – |
Perhitungan Biaya Menyeluruh
Asumsi volume pemanggilan bulanan 10 juta Token (input dan output masing-masing setengah):
| Solusi | Biaya Bulanan | Dampak Pembatasan Kecepatan | Evaluasi Menyeluruh |
|---|---|---|---|
| Koneksi Langsung Alibaba Cloud | $36.00 | Sering terputus, perlu percobaan ulang | Biaya aktual lebih tinggi |
| Relay APIYI | $31.68 | Stabil tanpa gangguan | Value for money terbaik |
| Solusi Multi-Akun | $36.00+ | Biaya manajemen tinggi | Tidak direkomendasikan |
💰 Optimasi Biaya: APIYI apiyi.com bekerja sama secara channel dengan Alibaba Cloud. Tidak hanya memberikan harga diskon 0,88x secara default, tetapi juga dapat menyelesaikan masalah pembatasan kecepatan secara tuntas. Untuk skenario penggunaan frekuensi menengah hingga tinggi, biaya keseluruhannya jauh lebih rendah.
Pertanyaan Umum (FAQ)
Q1: Mengapa saya langsung terkena pembatasan kecepatan Qwen3-Max saat baru mulai menggunakan?
Alibaba Cloud Model Studio memberikan kuota gratis yang sangat terbatas untuk akun baru, dan kuota untuk versi terbaru qwen3-max-2025-09-23 bahkan lebih rendah (RPM 60, TPM 100.000). Jika Anda menggunakan versi snapshot, pembatasan kecepatannya akan jauh lebih ketat.
Disarankan untuk melakukan pemanggilan melalui APIYI apiyi.com untuk menghindari batasan kuota di tingkat akun.
Q2: Berapa lama waktu pemulihan setelah terkena pembatasan kecepatan?
Pembatasan kecepatan Alibaba Cloud menggunakan mekanisme sliding window:
- Batasan RPM: Tunggu sekitar 60 detik untuk pulih.
- Batasan TPM: Tunggu sekitar 60 detik untuk pulih.
- Perlindungan lonjakan (burst protection): Mungkin memerlukan waktu tunggu yang lebih lama.
Menggunakan platform APIYI untuk pemanggilan API dapat menghindari waktu tunggu yang sering dan meningkatkan efisiensi pengembangan.
Q3: Bagaimana stabilitas layanan relay APIYI dijamin?
APIYI memiliki hubungan kerja sama channel dengan Alibaba Cloud dan menggunakan model kuota kolam besar tingkat platform:
- Load balancing multi-saluran.
- Pengalihan kegagalan otomatis (automatic failover).
- Jaminan ketersediaan 99,9%.
Dibandingkan dengan batasan kuota akun pribadi, layanan tingkat platform jauh lebih stabil dan andal.
Q4: Apakah saya perlu mengubah banyak kode untuk menggunakan APIYI?
Hampir tidak perlu. APIYI sepenuhnya kompatibel dengan format OpenAI SDK, Anda hanya perlu mengubah dua bagian saja:
# Sebelum diubah (Koneksi langsung Alibaba Cloud)
client = OpenAI(
api_key="sk-xxx",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# Setelah diubah (Relay APIYI)
client = OpenAI(
api_key="your-apiyi-key", # Ganti dengan key dari APIYI
base_url="https://api.apiyi.com/v1" # Ganti dengan alamat APIYI
)
Nama model dan format parameter tetap sama persis, tidak perlu ada perubahan lainnya.
Q5: Selain Qwen3-Max, model apa lagi yang didukung oleh APIYI?
Platform APIYI mendukung pemanggilan terpadu untuk 200+ Model Bahasa Besar populer, termasuk:
- Seluruh seri Qwen: qwen3-max, qwen-plus, qwen-turbo, qwen-vl, dll.
- Seri Claude: claude-3-opus, claude-3-sonnet, claude-3-haiku.
- Seri GPT: gpt-4o, gpt-4-turbo, gpt-3.5-turbo.
- Lainnya: Gemini, DeepSeek, Moonshot, dan lain-lain.
Semua model menggunakan antarmuka yang seragam, satu API Key untuk memanggil semua model.
Ringkasan Solusi Masalah Rate Limit Qwen3-Max
Pohon Keputusan Pemilihan Solusi
遇到 Qwen3-Max 429 错误
│
├─ 需要彻底解决 → 使用 APIYI 中转 (推荐)
│
├─ 轻度限速 → 请求平滑 + 指数退避
│
├─ 企业大规模调用 → 多账号轮询 或 APIYI 企业版
│
└─ 非核心任务 → 备用模型降级
Ringkasan Poin Utama
| Poin | Penjelasan |
|---|---|
| Penyebab Rate Limit | Batasan tiga lapis RPM/TPM/RPS dari Alibaba Cloud |
| Solusi Optimal | Layanan perantara APIYI, solusi tuntas |
| Keunggulan Biaya | Diskon hingga 0.88x, lebih hemat daripada koneksi langsung |
| Biaya Migrasi | Hanya perlu mengubah base_url dan api_key |
Direkomendasikan untuk menggunakan APIYI apiyi.com guna menyelesaikan masalah rate limit Qwen3-Max dengan cepat, serta menikmati layanan stabil dan harga promo.
Referensi
-
Dokumen Rate Limits Alibaba Cloud: Penjelasan pembatasan kecepatan resmi
- Link:
alibabacloud.com/help/en/model-studio/rate-limit
- Link:
-
Dokumen Error Codes Alibaba Cloud: Detail kode error
- Link:
alibabacloud.com/help/en/model-studio/error-code
- Link:
-
Dokumen Model Qwen3-Max: Spesifikasi teknis resmi
- Link:
alibabacloud.com/help/en/model-studio/what-is-qwen-llm
- Link:
Dukungan Teknis: Jika Anda memiliki pertanyaan mengenai penggunaan Qwen3-Max, silakan hubungi dukungan teknis melalui APIYI apiyi.com.