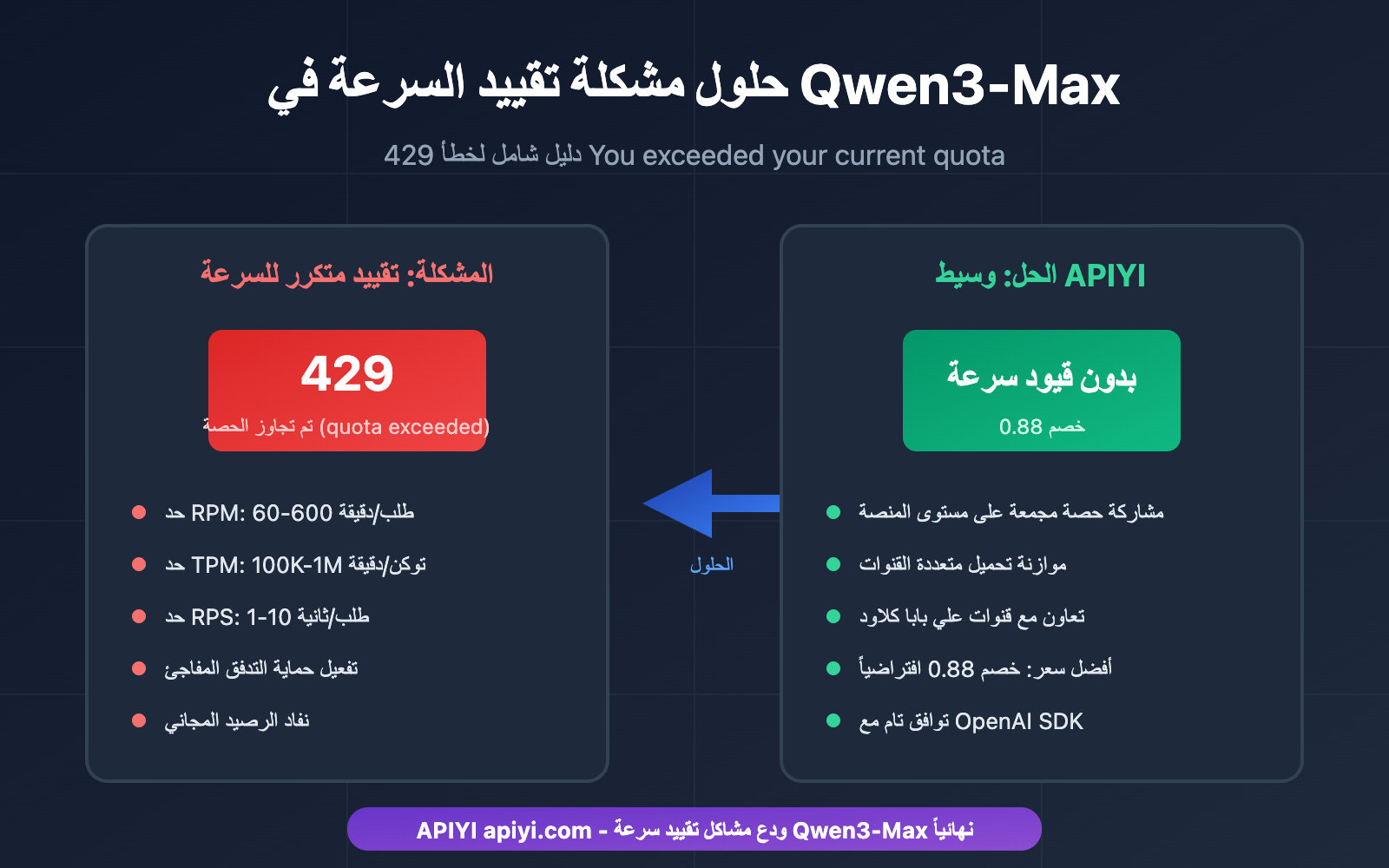
يُعد مواجهة خطأ 429 You exceeded your current quota بشكل متكرر عند تطوير تطبيقات الذكاء الاصطناعي باستخدام Qwen3-Max نقطة ألم كبيرة للعديد من المطورين. سيتناول هذا المقال تحليلاً عميقاً لآليات تقييد السرعة (Rate Limit) في Qwen3-Max من "علي بابا كلاود"، وسيوفر 5 حلول عملية لمساعدتك على توديع مشاكل نقص الحصة نهائياً.
القيمة الجوهرية: بعد قراءة هذا المقال، ستفهم مبادئ تقييد السرعة في Qwen3-Max، وتتقن حلولاً متعددة، وتختار الطريقة الأنسب لك لضمان استقرار استدعاء نموذج لغة كبير بمليارات البارامترات.
نظرة عامة على مشكلة تقييد السرعة في Qwen3-Max
رسالة الخطأ النموذجية
عندما يقوم تطبيقك باستدعاء API الخاص بـ Qwen3-Max بشكل متكرر، قد تواجه الخطأ التالي:
{
"error": {
"message": "You exceeded your current quota, please check your plan and billing details.",
"type": "insufficient_quota",
"code": "insufficient_quota"
},
"status": 429
}
هذا الخطأ يعني أنك قد فعلت قيود الحصة في Model Studio التابع لـ "علي بابا كلاود".
نطاق تأثير مشكلة تقييد السرعة في Qwen3-Max
| سيناريو التأثير | المظهر المحدد | درجة الخطورة |
|---|---|---|
| تطوير الوكلاء (Agents) | انقطاع متكرر في الحوارات متعددة الجولات | عالية |
| المعالجة الدفعية | عدم القدرة على إكمال المهام | عالية |
| التطبيقات الفورية | تضرر تجربة المستخدم | عالية |
| توليد الأكواد | انقطاع مخرجات الأكواد الطويلة | متوسطة |
| الاختبار وتصحيح الأخطاء | انخفاض كفاءة التطوير | متوسطة |
تفاصيل آلية تحديد السرعة (Rate Limiting) في Qwen3-Max
قيود الحصص الرسمية من Alibaba Cloud
وفقاً للوثائق الرسمية لـ Model Studio من Alibaba Cloud، فإن قيود الحصة لنموذج Qwen3-Max هي كما يلي:
| إصدار النموذج | RPM (طلب/دقيقة) | TPM (توكن/دقيقة) | RPS (طلب/ثانية) |
|---|---|---|---|
| qwen3-max | 600 | 1,000,000 | 10 |
| qwen3-max-2025-09-23 | 60 | 100,000 | 1 |
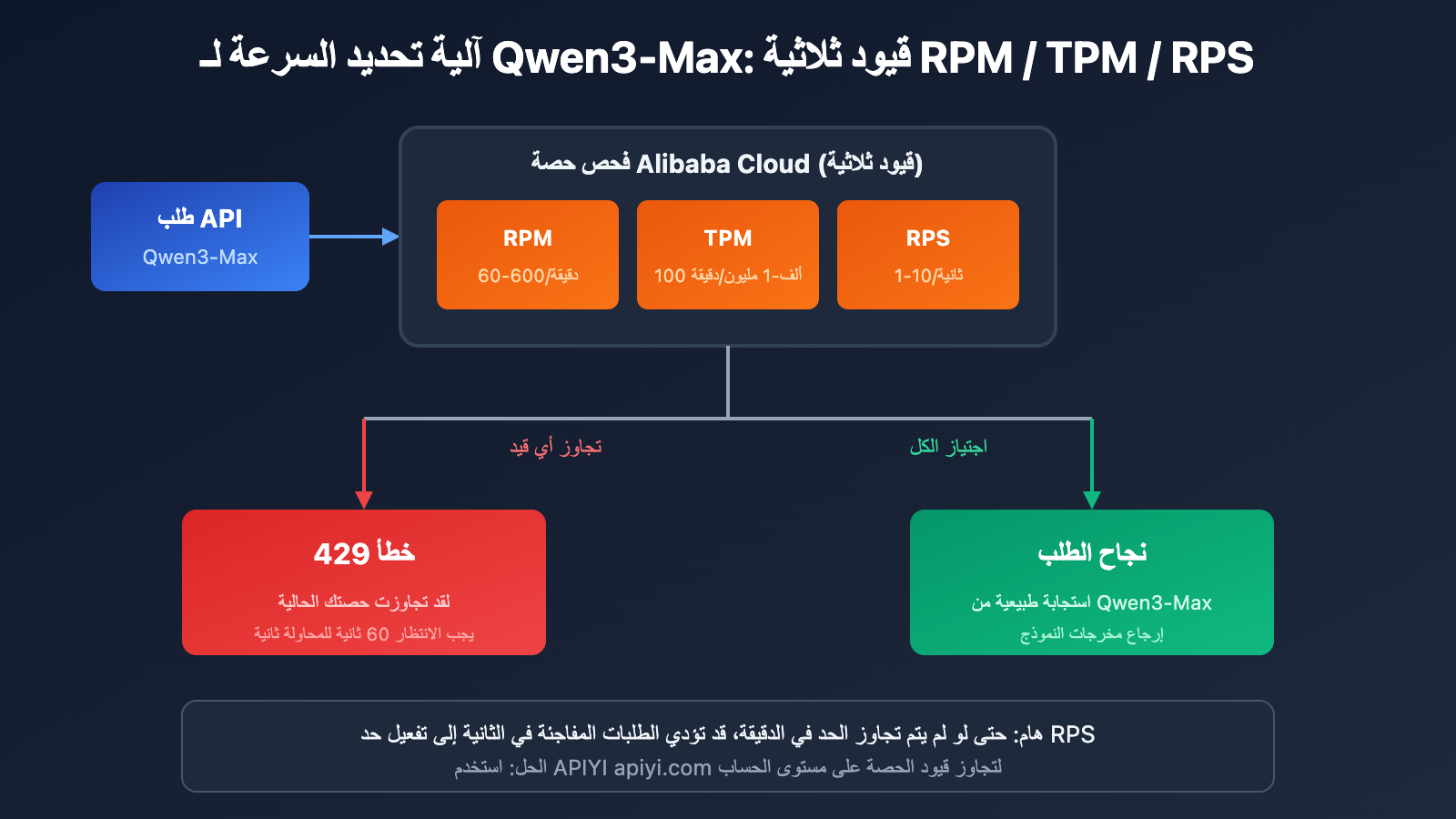
4 حالات تؤدي إلى تفعيل تحديد السرعة في Qwen3-Max
تطبق Alibaba Cloud آلية تقييد مزدوجة على Qwen3-Max، وسيؤدي تفعيل أي شرط منها إلى إرجاع خطأ 429:
| نوع الخطأ | رسالة الخطأ | سبب التفعيل |
|---|---|---|
| تجاوز تردد الطلبات | Requests rate limit exceeded | تجاوز حدود RPM/RPS |
| تجاوز استهلاك التوكن | You exceeded your current quota | تجاوز حدود TPM/TPS |
| حماية من حركة المرور المفاجئة | Request rate increased too quickly | زيادة مفاجئة في الطلبات اللحظية |
| استنفاد الحصة المجانية | Free allocated quota exceeded | نفاد الرصيد التجريبي |
معادلة حساب الحد
الحد الفعلي = min(حد RPM, حد RPS × 60)
= min(حد TPM, حد TPS × 60)
ملاحظة هامة: حتى إذا لم يتم تجاوز الحد على مستوى الدقيقة، فقد تؤدي الطلبات المفاجئة على مستوى الثانية إلى تفعيل تقييد السرعة.
5 حلول لمشكلة تحديد السرعة في Qwen3-Max
نظرة عامة على مقارنة الحلول
| الحل | صعوبة التنفيذ | الفعالية | التكلفة | السيناريو الموصى به |
|---|---|---|---|---|
| خدمة وسيط API | منخفضة | حل جذري | أوفر | جميع السيناريوهات |
| استراتيجية تنعيم الطلبات | متوسطة | تخفيف | مجاني | تحديد سرعة خفيف |
| التدوير بين حسابات متعددة | عالية | تخفيف | عالية | مستخدمو الشركات |
| التبديل لنموذج احتياطي | متوسطة | حل طارئ | متوسطة | المهام غير الأساسية |
| طلب زيادة الحصة | منخفضة | محدودة | مجاني | المستخدمون على المدى الطويل |
الحل الأول: استخدام خدمة وسيط API (موصى به)
هذا هو الحل الأكثر مباشرة وفعالية لحل مشكلة تحديد السرعة في Qwen3-Max. من خلال الاستدعاء عبر منصة وسيطة لـ API، يمكنك تجاوز قيود الحصة المفروضة على مستوى حساب Alibaba Cloud.
لماذا تحل وساطة API مشكلة تحديد السرعة؟
| وجه المقارنة | الاتصال المباشر بـ Alibaba Cloud | عبر وسيط APIYI |
|---|---|---|
| قيود الحصة | قيود RPM/TPM على مستوى الحساب | مشاركة مجمع كبير على مستوى المنصة |
| تكرار تحديد السرعة | تفعيل متكرر لخطأ 429 | لا يوجد تحديد سرعة تقريباً |
| السعر | السعر الرسمي | خصم تلقائي يصل إلى 12% |
| الاستقرار | يتأثر بحصة الحساب | ضمان عبر قنوات متعددة |
مثال بسيط للكود
from openai import OpenAI
# استخدم خدمة وسيط APIYI لتودع مخاوف تحديد السرعة
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3-max",
messages=[
{"role": "user", "content": "يرجى شرح مبدأ عمل بنية MoE"}
]
)
print(response.choices[0].message.content)
🎯 الحل الموصى به: عبر استدعاء Qwen3-Max من خلال APIYI apiyi.com، لا تحل مشكلة تحديد السرعة جذرياً فحسب، بل تستمتع أيضاً بأسعار مخفضة. تتمتع APIYI بشراكات قنوات مع Alibaba Cloud، مما يوفر خدمة أكثر استقراراً وأسعاراً أفضل.
عرض الكود الكامل (بما في ذلك إعادة المحاولة ومعالجة الأخطاء)
import time
from openai import OpenAI
from openai import APIError, RateLimitError
class Qwen3MaxClient:
"""عميل Qwen3-Max، يتم استدعاؤه عبر APIYI، دون قلق من قيود السرعة"""
def __init__(self, api_key: str):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # واجهة وسيط APIYI
)
self.model = "qwen3-max"
def chat(self, message: str, max_retries: int = 3) -> str:
"""
إرسال رسالة والحصول على رد
عبر APIYI، لن تواجه مشكلات تحديد السرعة تقريباً
"""
for attempt in range(max_retries):
try:
response = self.client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": message}],
max_tokens=4096
)
return response.choices[0].message.content
except RateLimitError as e:
# نادراً ما يتم تفعيل هذا الاستثناء عند استخدام APIYI
if attempt < max_retries - 1:
wait_time = 2 ** attempt
print(f"الطلب محدود، إعادة المحاولة بعد {wait_time} ثانية...")
time.sleep(wait_time)
else:
raise e
except APIError as e:
print(f"خطأ في API: {e}")
raise e
return ""
def batch_chat(self, messages: list[str]) -> list[str]:
"""معالجة الرسائل دفعة واحدة دون القلق بشأن تحديد السرعة"""
results = []
for msg in messages:
result = self.chat(msg)
results.append(result)
return results
# مثال على الاستخدام
if __name__ == "__main__":
client = Qwen3MaxClient(api_key="your-apiyi-key")
# استدعاء واحد
response = client.chat("اكتب خوارزمية فرز سريع باستخدام بايثون")
print(response)
# استدعاء جماعي - عبر APIYI لا توجد مشاكل في تحديد السرعة
questions = [
"اشرح ما هي بنية MoE",
"قارن بين Transformer و RNN",
"ما هي آلية الانتباه (Attention Mechanism)"
]
answers = client.batch_chat(questions)
for q, a in zip(questions, answers):
print(f"س: {q}\nج: {a}\n")
الحل الثاني: استراتيجية تنعيم الطلبات
إذا كنت تصر على الاتصال المباشر بـ Alibaba Cloud، يمكنك تخفيف مشكلة تحديد السرعة من خلال تنعيم الطلبات.
إعادة المحاولة مع التراجع الأسي (Exponential Backoff)
import time
import random
def call_with_backoff(func, max_retries=5):
"""استراتيجية إعادة المحاولة مع التراجع الأسي"""
for attempt in range(max_retries):
try:
return func()
except Exception as e:
if "429" in str(e) and attempt < max_retries - 1:
# تراجع أسي + تشويش عشوائي (Jitter)
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"تفعيل تحديد السرعة، الانتظار {wait_time:.2f} ثانية قبل إعادة المحاولة...")
time.sleep(wait_time)
else:
raise e
تخزين الطلبات المؤقت (Queue Buffering)
import asyncio
from collections import deque
class RequestQueue:
"""طابور طلبات لتنعيم تردد استدعاء Qwen3-Max"""
def __init__(self, rpm_limit=60):
self.queue = deque()
self.interval = 60 / rpm_limit # الفاصل الزمني بين الطلبات
self.last_request = 0
async def throttled_request(self, request_func):
"""طلب محدد السرعة"""
now = time.time()
wait_time = self.interval - (now - self.last_request)
if wait_time > 0:
await asyncio.sleep(wait_time)
self.last_request = time.time()
return await request_func()
ملاحظة: تنعيم الطلبات يخفف المشكلة فقط ولا يحلها جذرياً. للسيناريوهات ذات الكثافة العالية، نوصي باستخدام خدمة وسيط APIYI.
الحل الثالث: التدوير بين حسابات متعددة
يمكن لمستخدمي الشركات زيادة الحصة الإجمالية من خلال التدوير بين عدة حسابات.

from itertools import cycle
class MultiAccountClient:
"""عميل تدوير الحسابات المتعددة"""
def __init__(self, api_keys: list[str]):
self.clients = cycle([
OpenAI(api_key=key, base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
for key in api_keys
])
def chat(self, message: str) -> str:
client = next(self.clients)
response = client.chat.completions.create(
model="qwen3-max",
messages=[{"role": "user", "content": message}]
)
return response.choices[0].message.content
| عدد الحسابات | RPM المكافئ | TPM المكافئ | تعقيد الإدارة |
|---|---|---|---|
| 1 | 600 | 1,000,000 | منخفض |
| 3 | 1,800 | 3,000,000 | متوسط |
| 5 | 3,000 | 5,000,000 | عالٍ |
| 10 | 6,000 | 10,000,000 | عالٍ جداً |
💡 نصيحة للمقارنة: إدارة حسابات متعددة معقدة ومكلفة، الأفضل استخدام خدمة وسيط APIYI apiyi.com مباشرة، حيث لا تحتاج لإدارة حسابات متعددة وتتمتع بحصة مجمع المنصة الكبيرة.
الحل الرابع: التبديل لنموذج احتياطي (Fallback)
عندما يتم تفعيل تحديد السرعة في Qwen3-Max، يمكن التبديل تلقائياً إلى نموذج احتياطي.
class FallbackClient:
"""عميل Qwen يدعم التبديل للنماذج الاحتياطية"""
MODEL_PRIORITY = [
"qwen3-max", # الخيار الأول
"qwen-plus", # احتياطي 1
"qwen-turbo", # احتياطي 2
]
def __init__(self, api_key: str):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # استخدام APIYI
)
def chat(self, message: str) -> tuple[str, str]:
"""إرجاع (محتوى الرد، النموذج المستخدم فعلياً)"""
for model in self.MODEL_PRIORITY:
try:
response = self.client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": message}]
)
return response.choices[0].message.content, model
except Exception as e:
if "429" in str(e):
print(f"تحديد سرعة في {model}، محاولة التبديل لنموذج أدنى...")
continue
raise e
raise Exception("جميع النماذج غير متاحة")
الحل الخامس: طلب زيادة الحصة
بالنسبة للمستخدمين الذين يحتاجون لخدمة مستقرة لفترة طويلة، يمكن التقدم بطلب لزيادة الحصة من Alibaba Cloud.
خطوات التقديم:
- تسجيل الدخول إلى وحدة تحكم Alibaba Cloud.
- الدخول إلى صفحة إدارة حصص Model Studio.
- تقديم طلب زيادة الحصة.
- انتظار المراجعة (عادة من 1-3 أيام عمل).
متطلبات التقديم:
- توثيق الحساب بالهوية الحقيقية.
- عدم وجود مستحقات مالية متأخرة.
- تقديم شرح لسيناريو الاستخدام.
مقارنة تكاليف مشكلات تحديد السرعة في Qwen3-Max
تحليل مقارنة الأسعار
| مزود الخدمة | سعر الإدخال (0-32K) | سعر الإخراج | حالة تحديد السرعة |
|---|---|---|---|
| اتصال مباشر من Alibaba Cloud | $1.20/مليون | $6.00/مليون | قيود صارمة على RPM/TPM |
| APIYI (خصم 12%) | $1.06/مليون | $5.28/مليون | لا يوجد تحديد للسرعة تقريبًا |
| فارق السعر | توفير 12% | توفير 12% | – |
حساب التكلفة الإجمالية
بافتراض حجم استدعاء شهري يبلغ 10 ملايين رمز (Token) (نصفها إدخال ونصفها إخراج):
| الخطة | التكلفة الشهرية | تأثير تحديد السرعة | التقييم العام |
|---|---|---|---|
| اتصال مباشر من Alibaba Cloud | $36.00 | انقطاعات متكررة، تتطلب إعادة المحاولة | التكلفة الفعلية أعلى |
| وسيط APIYI | $31.68 | مستقر وبدون انقطاعات | الأفضل من حيث القيمة مقابل السعر |
| خطة الحسابات المتعددة | +$36.00 | تكاليف إدارة عالية | غير موصى به |
💰 تحسين التكاليف: تمتلك APIYI apiyi.com شراكة قنوات مع Alibaba Cloud، حيث لا تكتفي بتقديم خصم تلقائي بنسبة 12%، بل توفر أيضًا حلاً جذريًا لمشكلات تحديد السرعة. بالنسبة لسيناريوهات الاستخدام المتوسطة والعالية، تكون التكلفة الإجمالية أقل.
الأسئلة الشائعة
س1: لماذا أواجه تحديدًا للسرعة في Qwen3-Max بمجرد بدء الاستخدام؟
يوفر Alibaba Cloud Model Studio رصيدًا مجانيًا محدودًا للحسابات الجديدة، كما أن حصة (Quota) الإصدار الجديد qwen3-max-2025-09-23 أقل (60 RPM، و100,000 TPM). إذا كنت تستخدم نسخة اللقطة (Snapshot)، فستكون قيود السرعة أكثر صرامة.
يُنصح بالاستدعاء عبر APIYI apiyi.com لتجنب قيود الحصة المفروضة على مستوى الحساب.
س2: كم من الوقت يستغرق استئناف الخدمة بعد تحديد السرعة؟
تعتمد Alibaba Cloud آلية النافذة المنزلقة (Sliding Window) لتحديد السرعة:
- قيود RPM: انتظر حوالي 60 ثانية للاستئناف.
- قيود TPM: انتظر حوالي 60 ثانية للاستئناف.
- الحماية من الاندفاع المفاجئ: قد يتطلب الأمر انتظارًا لفترة أطول.
استخدام منصة APIYI للاستدعاء يجنبك الانتظار المتكرر ويرفع كفاءة التطوير.
س3: كيف يتم ضمان استقرار خدمة وسيط APIYI؟
تتمتع APIYI بعلاقة شراكة قنوات مع Alibaba Cloud، وتعتمد نموذج حصة مجمع كبير على مستوى المنصة:
- توازن الحمل عبر قنوات متعددة.
- نقل الفشل التلقائي (Auto-Failover).
- ضمان توفر بنسبة 99.9%.
مقارنة بقيود الحصة في الحسابات الفردية، تعد الخدمات على مستوى المنصة أكثر استقرارًا وموثوقية.
س4: هل يتطلب استخدام APIYI تعديل الكثير من الكود؟
لا يحتاج الأمر إلى ذلك تقريبًا. تتوافق APIYI تمامًا مع تنسيق OpenAI SDK، وتحتاج فقط إلى تعديل جزئيتين:
# قبل التعديل (اتصال مباشر من Alibaba Cloud)
client = OpenAI(
api_key="sk-xxx",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# بعد التعديل (وسيط APIYI)
client = OpenAI(
api_key="your-apiyi-key", # استبدله بمفتاح APIYI الخاص بك
base_url="https://api.apiyi.com/v1" # استبدله بعنوان APIYI
)
اسم النموذج وتنسيق المعلمات متطابقان تمامًا، ولا داعي لأي تعديلات أخرى.
س5: ما هي النماذج الأخرى التي تدعمها APIYI بالإضافة إلى Qwen3-Max؟
تدعم منصة APIYI الاستدعاء الموحد لأكثر من 200 نموذج لغة كبير رائد، بما في ذلك:
- سلسلة Qwen الكاملة: qwen3-max، qwen-plus، qwen-turbo، qwen-vl، وغيرها.
- سلسلة Claude: claude-3-opus، claude-3-sonnet، claude-3-haiku.
- سلسلة GPT: gpt-4o، gpt-4-turbo، gpt-3.5-turbo.
- أخرى: Gemini، DeepSeek، Moonshot، وغيرها.
جميع النماذج بواجهة موحدة، ومفتاح API واحد لاستدعاء كافة النماذج.
ملخص حلول مشكلة تقييد المعدل (Rate Limiting) لنموذج Qwen3-Max
شجرة قرار اختيار الحل
مواجهة خطأ 429 في Qwen3-Max
│
├─ تحتاج إلى حل جذري ← استخدام وسيط APIYI (موصى به)
│
├─ تقييد بسيط ← تسوية الطلبات + تراجع أسي (Exponential Backoff)
│
├─ استدعاءات واسعة النطاق للمؤسسات ← تدوير حسابات متعددة أو نسخة المؤسسات من APIYI
│
└─ مهام غير أساسية ← التبديل لنموذج بديل أقل
مراجعة النقاط الأساسية
| النقطة | التوضيح |
|---|---|
| أسباب تقييد المعدل | قيود Alibaba Cloud الثلاثية: RPM/TPM/RPS |
| الحل الأمثل | خدمة وسيط APIYI، حل نهائي للمشكلة |
| ميزة التكلفة | خصم يصل إلى 0.88، أوفر من الاتصال المباشر |
| تكلفة الانتقال | يتطلب فقط تعديل base_url و api_key |
نوصي باستخدام APIYI عبر apiyi.com لحل مشكلات تقييد Qwen3-Max بسرعة، والتمتع بخدمة مستقرة وأسعار مخفضة.
المراجع
-
وثائق قيود المعدل (Rate Limits) لـ Alibaba Cloud: توضيح رسمي للقيود
- الرابط:
alibabacloud.com/help/en/model-studio/rate-limit
- الرابط:
-
وثائق أكواد الخطأ لـ Alibaba Cloud: شرح مفصل لأكواد الخطأ
- الرابط:
alibabacloud.com/help/en/model-studio/error-code
- الرابط:
-
وثائق نموذج Qwen3-Max: المواصفات التقنية الرسمية
- الرابط:
alibabacloud.com/help/en/model-studio/what-is-qwen-llm
- الرابط:
الدعم الفني: إذا واجهت أي مشاكل في استخدام Qwen3-Max، فنحن نرحب بتواصلك للحصول على الدعم الفني عبر APIYI على apiyi.com.