Nano Banana Pro API を使用して画像を生成する際、同期呼び出しと非同期呼び出しにはどのような違いがあるのでしょうか?現在、APIYI と Gemini 公式はどちらも同期呼び出しモードのみをサポートしていますが、APIYI は OSS URL による画像出力を提供することで、ユーザーエクスペリエンスを大幅に向上させています。本記事では、同期呼び出しと非同期呼び出しの核心的な違いと、APIYI プラットフォームにおける画像出力形式の最適化案について体系的に解説します。
核心となる価値: この記事を読み終える頃には、API 設計における同期呼び出しと非同期呼び出しの本質的な違い、base64 エンコーディングと比較した APIYI プラットフォームの OSS URL 出力の利点、そしてビジネスシーンに合わせた最適な画像取得方法の選び方を理解できるでしょう。

Nano Banana Pro API 呼び出しモードの核心的な比較
| 特性 | 同期呼び出し (Synchronous) | 非同期呼び出し (Asynchronous) | APIYI の現在の対応状況 |
|---|---|---|---|
| 接続モード | HTTP 接続を維持し、完了を待機 | 即座にタスク ID を返し、接続を終了 | ✅ 同期呼び出し |
| 待機方法 | ブロッキング待機 (30〜170秒) | ノンブロッキング、ポーリングまたは Webhook | ✅ 同期 (ブロッキング待機) |
| タイムアウトのリスク | 高い (300〜600秒のタイムアウト設定が必要) | 低い (タスク送信時のみ短いタイムアウトが必要) | ⚠️ 適切なタイムアウト設定が必要 |
| 実装の複雑さ | 低い (1回のリクエストで完結) | 中程度 (ポーリングまたは Webhook の監視が必要) | ✅ シンプルで使いやすい |
| 適用シーン | リアルタイム生成、即時表示 | バッチ処理、バックグラウンドタスク | ✅ リアルタイム生成 |
| コストの最適化 | 標準価格 | Google Batch API で 50% 節約可能 | – |
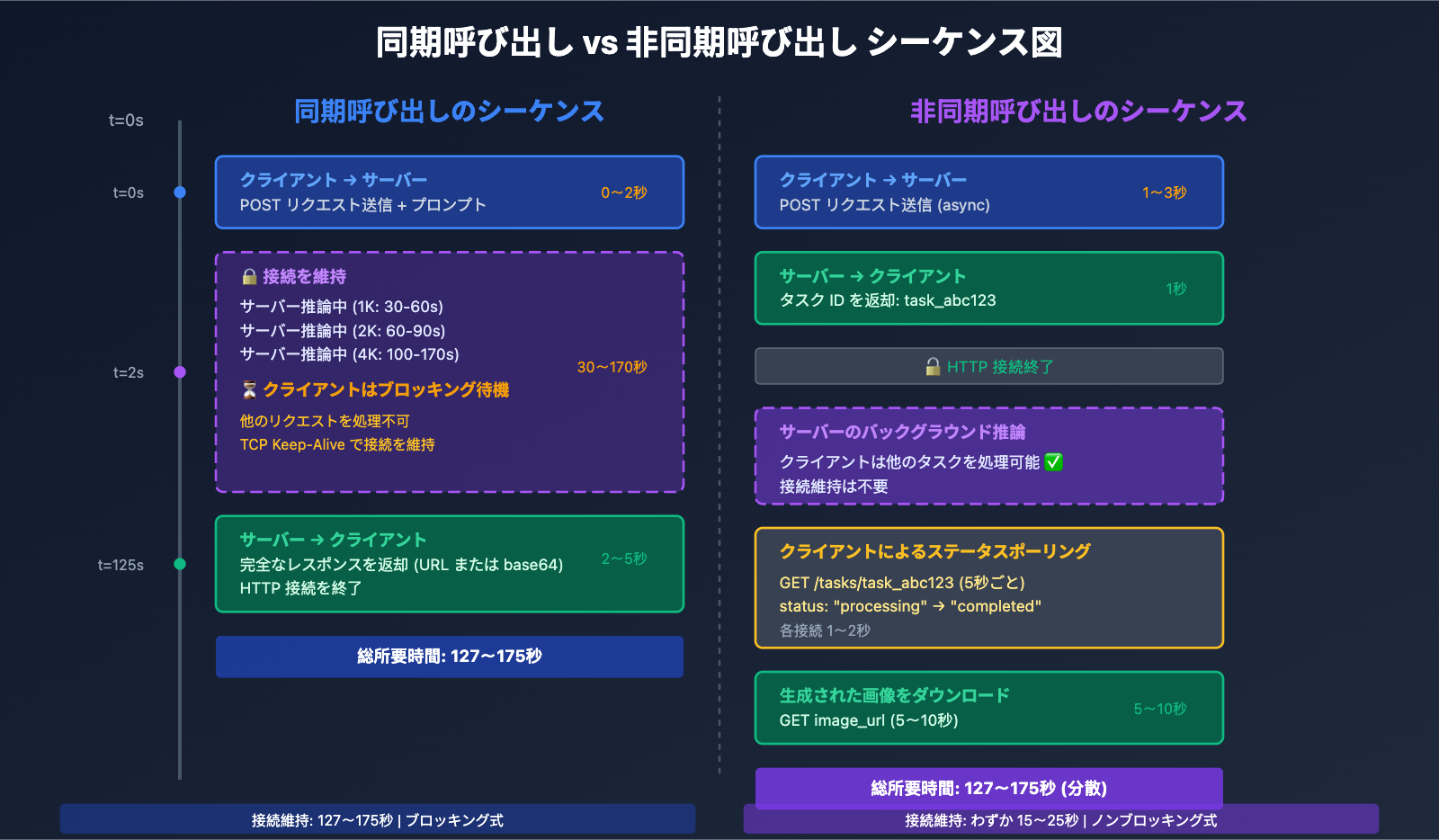
同期呼び出しの工作原理
同期呼び出し (Synchronous Call) は、リクエスト-待機-レスポンスパターンを採用しています。
- クライアントがリクエストを開始: サーバーに画像生成リクエストを送信します。
- HTTP 接続を維持: クライアントは TCP 接続を開いたままにし、サーバーの推論完了を待ちます。
- ブロッキング待機: 30〜170秒の推論時間中、クライアントは他の操作を処理できません。
- 完全なレスポンスを受信: サーバーが生成された画像データ(base64 または URL)を返します。
- 接続を終了: 完了後に HTTP 接続を閉じます。
主な特徴: 同期呼び出しはブロッキング式 (Blocking) であり、クライアントはサーバーのレスポンスを待ってからでないと後続の処理を実行できません。推論が完了する前に接続が切断されるのを防ぐため、十分な長さのタイムアウト時間を設定する必要があります(1K/2K は 300秒、4K は 600秒を推奨)。
非同期呼び出しの工作原理
非同期呼び出し (Asynchronous Call) は、リクエスト-受付-通知パターンを採用しています。
- クライアントがタスクを送信: サーバーに画像生成リクエストを送信します。
- 即座にタスク ID を返却: サーバーはリクエストを受け付け、タスク ID(例:
task_abc123)を返して、すぐに接続を閉じます。 - バックグラウンド推論: サーバーはバックグラウンドで画像生成を行い、その間クライアントは他の操作を行うことができます。
- 結果の取得: クライアントは以下のいずれかの方法で結果を取得します。
- ポーリング (Polling):
/tasks/task_abc123/statusに対して定期的にリクエストを送り、タスクの状態を確認します。 - Webhook コールバック: タスク完了後、サーバーがクライアント提供のコールバック URL を能動的に呼び出します。
- ポーリング (Polling):
- 画像をダウンロード: タスク完了後、返された URL を通じて生成された画像をダウンロードします。
主な特徴: 非同期呼び出しはノンブロッキング式 (Non-blocking) であり、クライアントはタスク送信後すぐに他のリクエストを処理でき、接続を長時間維持する必要がありません。バッチ処理、バックグラウンドタスク、およびリアルタイム性がそれほど重視されないシナリオに適しています。
💡 技術的なアドバイス: APIYI プラットフォームは現在、同期呼び出しモードのみをサポートしていますが、タイムアウト設定の最適化と OSS URL 出力の提供により、ユーザーエクスペリエンスを大幅に向上させています。画像を大量に生成する必要がある場合は、APIYI apiyi.com プラットフォーム経由での呼び出しをお勧めします。このプラットフォームは安定した HTTP ポートインターフェースを提供し、適切なタイムアウト時間がデフォルトで設定されており、高コンカレンシーな同期呼び出しをサポートしています。
核心的な違い 1: 接続維持時間とタイムアウト設定
同期呼び出しの接続維持要件
同期呼び出しでは、クライアントが画像生成のプロセス全体を通してHTTP接続を開いたままにする必要があります。これには、以下のような技術的課題が伴います。
| 課題 | 影響 | 解決策 |
|---|---|---|
| 長時間のアイドル接続 | 中間ネットワーク機器(NAT、ファイアウォール)が接続を切断する可能性がある | TCP Keep-Aliveを設定する |
| タイムアウト設定の複雑化 | 解像度に応じてタイムアウト時間を正確に設定する必要がある | 1K/2K: 300秒、4K: 600秒 |
| ネットワークの変動に敏感 | 不安定なネットワーク環境で接続が切れやすい | リトライメカニズムを実装する |
| 同時接続数の制限 | ブラウザのデフォルトは最大6つの同時接続 | サーバーサイドでの呼び出し、または接続プールの拡張 |
Python 同期呼び出しの例:
import requests
import time
def generate_image_sync(prompt: str, size: str = "4096x4096") -> dict:
"""
Nano Banana Pro APIを同期呼び出しして画像を生成する
Args:
prompt: 画像のプロンプト
size: 画像のサイズ
Returns:
APIレスポンス結果
"""
start_time = time.time()
# 同期呼び出し:生成が完了するまで接続を維持する
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations",
json={
"prompt": prompt,
"size": size,
"model": "nano-banana-pro",
"n": 1,
"response_format": "url" # APIYIはURL出力をサポート
},
headers={"Authorization": "Bearer YOUR_API_KEY"},
timeout=(10, 600) # 接続タイムアウト10秒、読み取りタイムアウト600秒
)
elapsed = time.time() - start_time
print(f"⏱️ 同期呼び出しの所要時間: {elapsed:.2f} 秒")
print(f"🔗 接続状態: {elapsed:.2f} 秒間オープンを維持")
return response.json()
# 使用例
result = generate_image_sync(
prompt="A futuristic cityscape at sunset",
size="4096x4096"
)
print(f"✅ 画像 URL: {result['data'][0]['url']}")
重要な観察ポイント:
- クライアントは100〜170秒の推論時間中、完全にブロックされます。
- HTTP接続が開き続け、システムリソースを消費します。
- タイムアウト設定が不適切(例:60秒)な場合、推論が完了する前に接続が切断されます。
非同期呼び出しの短時間接続のメリット
非同期呼び出しでは、タスクの送信時とステータスの照会時のみ短時間の接続を確立するため、接続維持時間を大幅に短縮できます。
| フェーズ | 接続時間 | タイムアウト設定 |
|---|---|---|
| タスクの送信 | 1〜3秒 | 30秒で十分 |
| ステータスのポーリング | 各1〜2秒 | 10秒で十分 |
| 画像のダウンロード | 5〜10秒 | 60秒で十分 |
| 合計 | 10〜20秒(分散) | 同期呼び出しより大幅に短い |
Python 非同期呼び出しの例(将来の APIYI サポートを想定):
import requests
import time
def generate_image_async(prompt: str, size: str = "4096x4096") -> str:
"""
Nano Banana Pro APIを非同期呼び出しして画像を生成(将来の機能)
Args:
prompt: 画像のプロンプト
size: 画像のサイズ
Returns:
タスク ID
"""
# ステップ1:タスクの送信(短時間接続)
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations/async", # 将来のインターフェース
json={
"prompt": prompt,
"size": size,
"model": "nano-banana-pro",
"n": 1,
"response_format": "url"
},
headers={"Authorization": "Bearer YOUR_API_KEY"},
timeout=(10, 30) # タスク送信には30秒のタイムアウトで十分
)
task_data = response.json()
task_id = task_data["task_id"]
print(f"✅ タスク送信完了: {task_id}")
print(f"🔓 接続が閉じられました。他のタスクを処理可能です")
return task_id
def poll_task_status(task_id: str, max_wait: int = 300) -> dict:
"""
完了するまでタスクステータスをポーリングする
Args:
task_id: タスク ID
max_wait: 最大待ち時間(秒)
Returns:
生成結果
"""
start_time = time.time()
poll_interval = 5 # 5秒ごとにポーリング
while time.time() - start_time < max_wait:
# タスクステータスの照会(短時間接続)
response = requests.get(
f"http://api.apiyi.com:16888/v1/tasks/{task_id}", # 将来のインターフェース
headers={"Authorization": "Bearer YOUR_API_KEY"},
timeout=(10, 10) # ステータス照会には10秒のタイムアウトで十分
)
status_data = response.json()
status = status_data["status"]
if status == "completed":
elapsed = time.time() - start_time
print(f"✅ タスク完了!総所要時間: {elapsed:.2f} 秒")
return status_data["result"]
elif status == "failed":
raise Exception(f"タスク失敗: {status_data.get('error')}")
else:
print(f"⏳ タスクステータス: {status}、{poll_interval}秒待機してリトライ...")
time.sleep(poll_interval)
raise TimeoutError(f"タスクタイムアウト: {task_id}")
# 使用例
task_id = generate_image_async(
prompt="A serene mountain landscape",
size="4096x4096"
)
# ポーリング中、他のタスクを処理できます
print("🚀 他のリクエストを並行して処理中...")
# タスクステータスのポーリング
result = poll_task_status(task_id, max_wait=600)
print(f"✅ 画像 URL: {result['data'][0]['url']}")
Webhookコールバックパターンの例を表示(将来の機能)
from flask import Flask, request, jsonify
import requests
app = Flask(__name__)
# タスク結果を保存するグローバル辞書
task_results = {}
@app.route('/webhook/image_completed', methods=['POST'])
def handle_webhook():
"""APIYI非同期タスク完了のWebhookコールバックを受信する"""
data = request.json
task_id = data['task_id']
status = data['status']
result = data.get('result')
if status == 'completed':
task_results[task_id] = result
print(f"✅ タスク {task_id} 完了: {result['data'][0]['url']}")
else:
print(f"❌ タスク {task_id} 失敗: {data.get('error')}")
return jsonify({"received": True}), 200
def generate_image_with_webhook(prompt: str, size: str = "4096x4096") -> str:
"""
Webhookパターンを使用して画像を非同期生成する
Args:
prompt: 画像のプロンプト
size: 画像のサイズ
Returns:
タスク ID
"""
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations/async",
json={
"prompt": prompt,
"size": size,
"model": "nano-banana-pro",
"n": 1,
"response_format": "url",
"webhook_url": "https://your-domain.com/webhook/image_completed" # コールバック URL
},
headers={"Authorization": "Bearer YOUR_API_KEY"},
timeout=(10, 30)
)
task_id = response.json()["task_id"]
print(f"✅ タスク送信完了: {task_id}")
print(f"📞 Webhook通知先: https://your-domain.com/webhook/image_completed")
return task_id
# WebhookをリッスンするFlaskサーバーを起動
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
🎯 現在の制限事項: APIYIおよびGemini公式は、現在同期呼び出しモードのみをサポートしており、非同期呼び出し機能は将来のバージョンで提供される予定です。高い同時実行性が求められる画像生成シナリオでは、APIYI(apiyi.com)プラットフォームを通じてマルチスレッドまたはマルチプロセスによる並行呼び出しを行い、適切なタイムアウト時間を設定することを推奨します。
核心的な違い 2: 同時実行処理能力とリソース占有
同期呼び出しの同時実行制限
同期呼び出しは、高い並行性が求められるシナリオにおいて、顕著なリソース占有の問題に直面します。
シングルスレッドのブロッキング問題:
import time
# ❌ 誤り:シングルスレッドの順次呼び出し、総所要時間 = 1回の所要時間 × タスク数
def generate_multiple_images_sequential(prompts: list) -> list:
results = []
start_time = time.time()
for prompt in prompts:
result = generate_image_sync(prompt, size="4096x4096")
results.append(result)
elapsed = time.time() - start_time
print(f"❌ 順次呼び出しによる {len(prompts)} 枚の画像生成所要時間: {elapsed:.2f} 秒")
# 各画像に120秒かかると仮定すると、10枚で1200秒(20分!)
return results
マルチスレッドによる並行処理の最適化:
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
# ✅ 正解:マルチスレッドによる並行呼び出し、I/O待機時間を有効活用
def generate_multiple_images_concurrent(prompts: list, max_workers: int = 5) -> list:
"""
マルチスレッドで複数の画像を並行生成する
Args:
prompts: プロンプトのリスト
max_workers: 最大同時実行スレッド数
Returns:
生成結果のリスト
"""
results = []
start_time = time.time()
with ThreadPoolExecutor(max_workers=max_workers) as executor:
# すべてのタスクを送信
future_to_prompt = {
executor.submit(generate_image_sync, prompt, "4096x4096"): prompt
for prompt in prompts
}
# すべてのタスクの完了を待機
for future in as_completed(future_to_prompt):
prompt = future_to_prompt[future]
try:
result = future.result()
results.append(result)
print(f"✅ 完了: {prompt[:30]}...")
except Exception as e:
print(f"❌ 失敗: {prompt[:30]}... - {e}")
elapsed = time.time() - start_time
print(f"✅ 並行呼び出しによる {len(prompts)} 枚の画像生成所要時間: {elapsed:.2f} 秒")
# 各画像に120秒かかると仮定すると、10枚で約120〜150秒(2〜2.5分)
return results
# 使用例
prompts = [
"A cyberpunk city at night",
"A serene forest landscape",
"An abstract geometric pattern",
"A futuristic space station",
"A vintage car in the desert",
# ...その他のプロンプト
]
results = generate_multiple_images_concurrent(prompts, max_workers=5)
print(f"🎉 {len(results)} 枚の画像を生成しました")
| 並行処理方式 | 4K画像10枚の所要時間 | リソース占有 | 適用シーン |
|---|---|---|---|
| 順次呼び出し | 1200秒(20分) | 低(単一接続) | 単一の画像、リアルタイム生成 |
| マルチスレッド並行(5スレッド) | 250秒(4分) | 中(5接続) | 中小規模バッチ(10〜50枚) |
| マルチプロセス並行(10プロセス) | 150秒(2.5分) | 高(10接続) | 大規模バッチ(50枚以上) |
| 非同期呼び出し(将来) | 120秒 + ポーリングのオーバーヘッド | 低(ポーリング接続が短時間) | 超大規模バッチ(100枚以上) |
非同期呼び出しの並行処理のメリット
非同期呼び出しは、バッチ処理シナリオにおいて圧倒的な優位性を持ちます。
バッチ送信 + バッチポーリング:
def generate_batch_async(prompts: list) -> list:
"""
バッチ非同期画像生成(将来の機能)
Args:
prompts: プロンプトのリスト
Returns:
タスク ID のリスト
"""
task_ids = []
# ステップ1:すべてのタスクを高速にバッチ送信(各1〜3秒)
for prompt in prompts:
task_id = generate_image_async(prompt, size="4096x4096")
task_ids.append(task_id)
print(f"✅ {len(task_ids)} 個のタスクをバッチ送信しました。所要時間 約 {len(prompts) * 2} 秒")
# ステップ2:タスクステータスのバッチポーリング
results = []
for task_id in task_ids:
result = poll_task_status(task_id, max_wait=600)
results.append(result)
return results
| 指標 | 同期呼び出し(マルチスレッド) | 非同期呼び出し(将来) | 差 |
|---|---|---|---|
| 送信フェーズの所要時間 | 1200秒(ブロッキング待機) | 20秒(高速送信) | 非同期が60倍高速 |
| 総所要時間 | 250秒(5スレッド) | 120秒 + ポーリングのオーバーヘッド | 非同期が2倍高速 |
| 最大接続数 | 5つの長時間接続 | 1つの短時間接続(送信時) | 非同期が接続を80%節約 |
| 他のタスクを処理可能か | ❌ スレッドがブロッキングされる | ✅ 完全な非ブロッキング | 非同期の方が柔軟 |

💰 コストの最適化: Google Gemini API は Batch API モードを提供しており、非同期処理をサポートするとともに50%の価格割引が適用されます(通常価格 1枚 $0.133〜$0.24、Batch API 1枚 $0.067〜$0.12)。ただし、納品までに最大24時間を要することを許容する必要があります。リアルタイム生成が不要なシナリオでは、Batch API を使用してコストを削減することを検討してください。
核心的な違い 3:APIYI プラットフォームの OSS URL 出力のメリット
base64 エンコーディング vs URL 出力の比較
Nano Banana Pro API は、2 つの画像出力フォーマットをサポートしています。
| 特徴 | base64 エンコーディング | OSS URL 出力 (APIYI 独自機能) | 推奨 |
|---|---|---|---|
| レスポンスボディのサイズ | 6-8 MB (4K 画像) | 200 バイト (URL のみ) | URL ✅ |
| 転送時間 | 5-10 秒 (不安定なネットワークではさらに低速) | 1 秒未満 | URL ✅ |
| ブラウザキャッシュ | ❌ キャッシュ不可 | ✅ 標準的な HTTP キャッシュ | URL ✅ |
| CDN 加速 | ❌ 利用不可 | ✅ グローバル CDN 加速 | URL ✅ |
| 画像最適化 | ❌ WebP 変換などは非対応 | ✅ フォーマット変換に対応 | URL ✅ |
| プログレッシブ読み込み | ❌ 完全にダウンロードする必要がある | ✅ プログレッシブ読み込みに対応 | URL ✅ |
| モバイル端末の性能 | ❌ メモリ消費量が高い | ✅ 最適化されたダウンロードストリーム | URL ✅ |
base64 エンコーディングのパフォーマンス問題:
-
レスポンスボディが 33% 肥大化: base64 エンコーディングにより、データ量が約 33% 増加します。
- オリジナルの 4K 画像: 約 6 MB
- base64 エンコーディング後: 約 8 MB
-
CDN を利用できない: base64 文字列は JSON レスポンスに埋め込まれるため、CDN によるキャッシュが不可能です。
-
モバイル端末のメモリ負荷: base64 文字列のデコードには、追加のメモリと CPU リソースが必要になります。
APIYI OSS URL 出力のメリット:
import requests
# ✅ 推荐: 使用 APIYI OSS URL 输出
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations",
json={
"prompt": "A beautiful sunset over mountains",
"size": "4096x4096",
"model": "nano-banana-pro",
"n": 1,
"response_format": "url" # 指定 URL 输出
},
headers={"Authorization": "Bearer YOUR_API_KEY"},
timeout=(10, 600)
)
result = response.json()
# 响应体仅包含 URL,大小约 200 字节
print(f"响应体大小: {len(response.content)} 字节")
# 输出: 响应体大小: 234 字节
# OSS URL 示例
image_url = result['data'][0]['url']
print(f"图像 URL: {image_url}")
# 输出: https://apiyi-oss.oss-cn-beijing.aliyuncs.com/nano-banana/abc123.png
# 后续通过标准 HTTP 下载图像,享受 CDN 加速
image_response = requests.get(image_url)
with open("output.png", "wb") as f:
f.write(image_response.content)
比較:base64 出力のパフォーマンス問題:
# ❌ 不推荐: base64 编码输出
response = requests.post(
"https://api.example.com/v1/images/generations",
json={
"prompt": "A beautiful sunset over mountains",
"size": "4096x4096",
"model": "nano-banana-pro",
"n": 1,
"response_format": "b64_json" # base64 编码
},
headers={"Authorization": "Bearer YOUR_API_KEY"},
timeout=(10, 600)
)
result = response.json()
# 响应体包含完整 base64 字符串,大小约 8 MB
print(f"响应体大小: {len(response.content)} 字节")
# 输出: 响应体大小: 8388608 字节 (8 MB!)
# 需要解码 base64 字符串
import base64
image_b64 = result['data'][0]['b64_json']
image_bytes = base64.b64decode(image_b64)
with open("output.png", "wb") as f:
f.write(image_bytes)
| 比較指標 | base64 エンコーディング | APIYI OSS URL | パフォーマンス向上 |
|---|---|---|---|
| API レスポンスサイズ | 8 MB | 200 バイト | 99.998% 削減 |
| API レスポンス時間 | 125 秒 + 5-10 秒(転送) | 125 秒 + 1 秒未満 | 5~10 秒短縮 |
| 画像ダウンロード方式 | JSON 内に埋め込み | 独立した HTTP リクエスト | 並列ダウンロードが可能 |
| ブラウザキャッシュ | キャッシュ不可 | 標準的な HTTP キャッシュ | 二回目以降のアクセスが瞬時 |
| CDN 加速 | 非対応 | グローバル CDN ノード | 海外からのアクセスも高速化 |
🚀 推奨設定: APIYI プラットフォームで Nano Banana Pro API を呼び出す際は、base64 エンコーディングではなく、常に
response_format: "url"を使用して OSS URL 出力を取得することを推奨します。これにより、API レスポンスサイズと転送時間を劇的に削減できるだけでなく、CDN 加速やブラウザキャッシュを最大限に活用し、ユーザーエクスペリエンスを向上させることができます。
核心的な違い 4:活用シーンと今後のロードマップ
同期呼び出しの最適な活用シーン
推奨されるシーン:
- リアルタイム画像生成: ユーザーがプロンプトを送信した後、即座に生成された画像を表示する場合
- 小規模なバッチ処理: 1~10 枚程度の画像を生成する場合、並列呼び出しで十分に性能要件を満たせます
- シンプルな統合: ポーリングや Webhook を実装する必要がなく、開発の複雑さを抑えられます
- インタラクティブなアプリケーション: AI お絵描きツールや画像エディタなど、即時のフィードバックが必要なシーン
典型的なコードパターン:
from flask import Flask, request, jsonify
import requests
app = Flask(__name__)
@app.route('/generate', methods=['POST'])
def generate_image():
"""实时图像生成接口"""
data = request.json
prompt = data['prompt']
size = data.get('size', '1024x1024')
# 同步调用,用户等待生成完成
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations",
json={
"prompt": prompt,
"size": size,
"model": "nano-banana-pro",
"n": 1,
"response_format": "url"
},
headers={"Authorization": "Bearer YOUR_API_KEY"},
timeout=(10, 300 if size != '4096x4096' else 600)
)
result = response.json()
return jsonify({
"success": True,
"image_url": result['data'][0]['url']
})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8000)
非同期呼び出しの将来的な活用シーン
活用シーン(将来的に対応予定):
- 大規模なバッチ画像生成: EC サイトの商品画像の一括生成や、デザイン素材ライブラリなど、100 枚以上の画像を生成する場合
- バックグラウンドの定期タスク: 特定のタイプの画像を毎日自動生成し、リアルタイムのレスポンスを必要としない場合
- 低コスト処理: Google Batch API を使用して 50% の価格割引を受け、24 時間以内の納品を許容する場合
- 高トラフィックシーン: 数百人のユーザーが同時に生成リクエストを送信し、コネクションプールの枯渇を避ける必要がある場合
典型的なコードパターン(将来イメージ):
from flask import Flask, request, jsonify
from celery import Celery
import requests
app = Flask(__name__)
celery = Celery('tasks', broker='redis://localhost:6379/0')
@celery.task
def generate_image_task(prompt: str, size: str, user_id: str):
"""Celery 异步任务:生成图像"""
# 提交异步任务到 APIYI
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations/async", # 未来接口
json={
"prompt": prompt,
"size": size,
"model": "nano-banana-pro",
"n": 1,
"response_format": "url",
"webhook_url": f"https://your-domain.com/webhook/{user_id}"
},
headers={"Authorization": "Bearer YOUR_API_KEY"},
timeout=(10, 30)
)
task_id = response.json()["task_id"]
return task_id
@app.route('/generate_async', methods=['POST'])
def generate_image_async():
"""异步图像生成接口"""
data = request.json
prompt = data['prompt']
size = data.get('size', '1024x1024')
user_id = data['user_id']
# 提交 Celery 任务,立即返回
task = generate_image_task.delay(prompt, size, user_id)
return jsonify({
"success": True,
"message": "任务已提交,完成后将通过 Webhook 通知",
"task_id": task.id
})
@app.route('/webhook/<user_id>', methods=['POST'])
def handle_webhook(user_id: str):
"""接收 APIYI 异步任务完成的 Webhook 回调"""
data = request.json
task_id = data['task_id']
result = data['result']
# 通知用户图像生成完成 (如发送邮件、推送通知等)
notify_user(user_id, result['data'][0]['url'])
return jsonify({"received": True}), 200
APIYI プラットフォームの今後のロードマップ
| 機能 | 現在のステータス | 今後の計画 | 予定時期 |
|---|---|---|---|
| 同期呼び出し | ✅ 対応済み | タイムアウト設定の継続的な最適化 | – |
| OSS URL 出力 | ✅ 対応済み | CDN ノードのさらなる拡充 | 2026 Q2 |
| 非同期呼び出し (ポーリング) | ❌ 未対応 | タスク送信 + ステータス照会のサポート | 2026 Q2 |
| 非同期呼び出し (Webhook) | ❌ 未対応 | タスク完了時のコールバック通知のサポート | 2026 Q2 |
| Batch API 統合 | ❌ 未対応 | Google Batch API との統合 | 2026 Q4 |
💡 開発のアドバイス: APIYI は 2026 年第 2 四半期に、タスク送信、ステータス照会、および Webhook コールバックをサポートする非同期呼び出し機能の提供を開始する予定です。現在、バッチ処理のニーズがある開発者の皆様は、同期インターフェースをマルチスレッドで並列呼び出しし、APIYI(apiyi.com)プラットフォーム経由で安定した HTTP ポートインターフェースと最適化されたタイムアウト設定を利用することをお勧めします。
よくある質問
Q1: なぜ APIYI と Gemini 公式は非同期呼び出しをサポートしていないのですか?
技術的な理由:
-
Google インフラの制限: Google Gemini API の基盤インフラは現在、同期推論モードのみをサポートしています。非同期呼び出しには、追加のタスクキューや状態管理システムが必要となります。
-
開発の複雑さ: 非同期呼び出しを実現するには、以下の実装が必要になります:
- タスクキュー管理
- タスク状態の永続化
- Webhook コールバックメカニズム
- 失敗時のリトライおよび補正ロジック
-
ユーザーニーズの優先順位: 多くのユーザーは画像のリアルタイム生成を求めており、同期呼び出しで 80% 以上のユースケースをカバーできています。
解決策:
- 現在:マルチスレッドやマルチプロセスを使用して、同期インターフェースを並列で呼び出す。
- 将来:APIYI は 2026年 Q2 に非同期呼び出し機能をリリースする予定です。
Q2: APIYI の OSS URL 画像は永久に保存されますか?
ストレージポリシー:
| 保存期間 | 説明 | 利用シーン |
|---|---|---|
| 7 日間 | デフォルトで 7 日間保存され、その後自動的に削除されます | 一時的なプレビュー、生成テスト |
| 30 日間 | 有料ユーザーは 30 日間まで延長可能です | 短期プロジェクト、キャンペーン素材 |
| 永久 | ユーザー自身で自分の OSS にダウンロードします | 長期利用、商用プロジェクト |
推奨される方法:
import requests
# 生成图像并获取 URL
result = generate_image_sync(prompt="A beautiful landscape", size="4096x4096")
temp_url = result['data'][0]['url']
print(f"临时 URL: {temp_url}")
# 下载图像到本地或自己的 OSS
image_response = requests.get(temp_url)
with open("permanent_image.png", "wb") as f:
f.write(image_response.content)
# 或上传到自己的 OSS (以阿里云 OSS 为例)
import oss2
auth = oss2.Auth('YOUR_ACCESS_KEY', 'YOUR_SECRET_KEY')
bucket = oss2.Bucket(auth, 'oss-cn-beijing.aliyuncs.com', 'your-bucket')
bucket.put_object('images/permanent_image.png', image_response.content)
注意: APIYI が提供する OSS URL は一時的なストレージであり、クイックプレビューやテストに適しています。長期的に使用する必要がある画像は、速やかにローカルまたは自身のクラウドストレージにダウンロードしてください。
Q3: 同期呼び出し時にタイムアウトを避けるにはどうすればよいですか?
タイムアウトを避けるための 3 つのキーポイント:
-
タイムアウト時間を正しく設定する:
# ✅ 正解: 接続タイムアウトと読み取りタイムアウトを個別に設定する timeout=(10, 600) # (接続タイムアウト 10 秒, 読み取りタイムアウト 600 秒) # ❌ 間違い: 単一のタイムアウト値のみ設定する timeout=600 # 接続タイムアウトにのみ適用される可能性があります -
HTTP ポートインターフェースを使用する:
# ✅ 推奨: APIYI の HTTP ポートを使用し、HTTPS ハンドシェイクのオーバーヘッドを回避する url = "http://api.apiyi.com:16888/v1/images/generations" # ⚠️ オプション: HTTPS インターフェース、TLS ハンドシェイク時間が増加します url = "https://api.apiyi.com/v1/images/generations" -
リトライメカニズムを実装する:
from requests.adapters import HTTPAdapter from requests.packages.urllib3.util.retry import Retry # 配置重试策略 retry_strategy = Retry( total=3, # 最多重试 3 次 status_forcelist=[429, 500, 502, 503, 504], # 仅对这些状态码重试 backoff_factor=2 # 指数退避: 2s, 4s, 8s ) adapter = HTTPAdapter(max_retries=retry_strategy) session = requests.Session() session.mount("http://", adapter) # 使用 session 发起请求 response = session.post( "http://api.apiyi.com:16888/v1/images/generations", json={...}, timeout=(10, 600) )
Q4: フロントエンドから直接 Nano Banana Pro API を呼び出すにはどうすればよいですか?
フロントエンドからの直接呼び出しを推奨しない理由:
- API Key 漏洩のリスク: フロントエンドのコードは、すべてのユーザーに API Key をさらしてしまいます。
- ブラウザの並列接続制限: ブラウザは同一ドメインに対して、デフォルトで最大 6 つの並列接続に制限されています。
- タイムアウト制限: ブラウザの
fetchAPI はデフォルトのタイムアウトが短く、生成を完了するのに不十分な場合があります。
推奨アーキテクチャ: バックエンドプロキシモード:
// 前端代码 (React 示例)
async function generateImage(prompt, size) {
// 调用自己的后端接口
const response = await fetch('https://your-backend.com/api/generate', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': 'Bearer YOUR_USER_TOKEN' // 用户认证 token
},
body: JSON.stringify({ prompt, size })
});
const result = await response.json();
return result.image_url; // 返回 APIYI OSS URL
}
// 使用
const imageUrl = await generateImage("A futuristic city", "4096x4096");
document.getElementById('result-image').src = imageUrl;
# 后端代码 (Flask 示例)
from flask import Flask, request, jsonify
import requests
app = Flask(__name__)
@app.route('/api/generate', methods=['POST'])
def generate():
# 验证用户 token
user_token = request.headers.get('Authorization')
if not verify_user_token(user_token):
return jsonify({"error": "Unauthorized"}), 401
data = request.json
# 后端调用 APIYI API (API Key 不会暴露给前端)
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations",
json={
"prompt": data['prompt'],
"size": data['size'],
"model": "nano-banana-pro",
"n": 1,
"response_format": "url"
},
headers={"Authorization": "Bearer YOUR_APIYI_API_KEY"}, # 安全存储在后端
timeout=(10, 600)
)
result = response.json()
return jsonify({"image_url": result['data'][0]['url']})
まとめ
Nano Banana Pro API の同期および非同期呼び出しに関する重要ポイント:
- 同期呼び出しの特徴: 生成が完了するまで HTTP 接続を維持します。30〜170 秒ほど待機するため、長いタイムアウト設定(300〜600 秒)が必要です。
- 非同期呼び出しの利点: タスク ID を即座に返し、ブロックされません。一括処理やバックグラウンドタスクに適していますが、現在 APIYI および Gemini 公式ともに未対応です。
- APIYI OSS URL 出力のメリット: Base64 エンコーディングと比較して、レスポンスボディを 99.998% 削減します。CDN 加速やブラウザキャッシュをサポートしており、パフォーマンスが大幅に向上します。
- 現在のベストプラクティス: 同期呼び出し + マルチスレッド並列処理 + OSS URL 出力を組み合わせ、APIYI の HTTP ポートインターフェースを通じて最適化されたタイムアウト設定を利用します。
- 今後のロードマップ: APIYI は 2026年 Q2 に非同期呼び出し機能をリリース予定で、タスクの送信、状態照会、および Webhook コールバックをサポートします。
Nano Banana Pro API の迅速な統合には、APIYI(apiyi.com)の利用をお勧めします。このプラットフォームは、最適化された HTTP ポートインターフェース(http://api.apiyi.com:16888/v1)、独自の OSS URL 画像出力、および適切なタイムアウト設定を提供しており、リアルタイム画像生成や一括処理のシナリオに最適です。
著者: APIYI 技術チーム | 技術的な質問がある場合は、APIYI(apiyi.com)にアクセスして、さらなる大規模言語モデルの導入ソリューションをご確認ください。