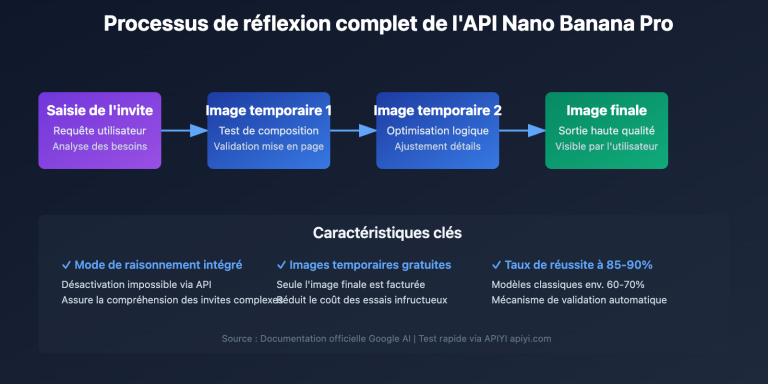
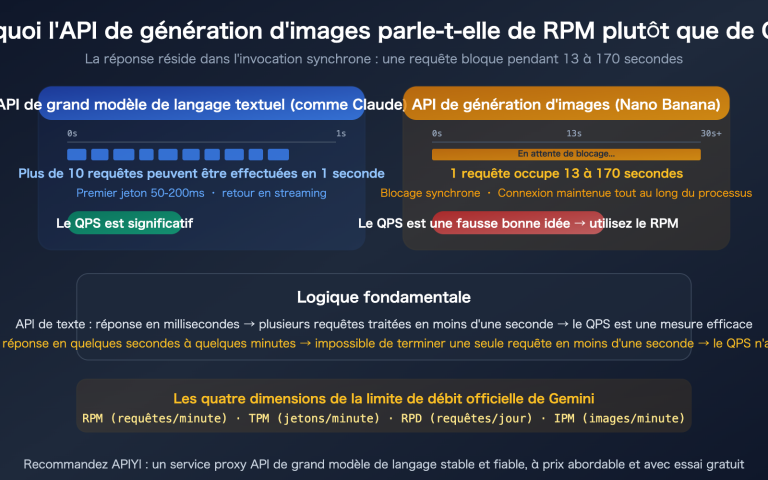
Lors de la génération d'images avec l'API Nano Banana Pro, quelle est la différence entre un appel synchrone et un appel asynchrone ? Actuellement, APIYI et Gemini ne supportent officiellement que le mode d'appel synchrone, mais APIYI améliore considérablement l'expérience utilisateur en proposant une sortie d'image via URL OSS. Cet article analyse de manière systématique les différences fondamentales entre les appels synchrones et asynchrones, ainsi que les solutions d'optimisation de la plateforme APIYI pour les formats de sortie d'image.
Valeur clé : En lisant cet article, vous comprendrez la différence de conception entre les appels synchrones et asynchrones, les avantages des sorties URL OSS d'APIYI par rapport au codage base64, et comment choisir la meilleure méthode de récupération d'image selon vos besoins métier.
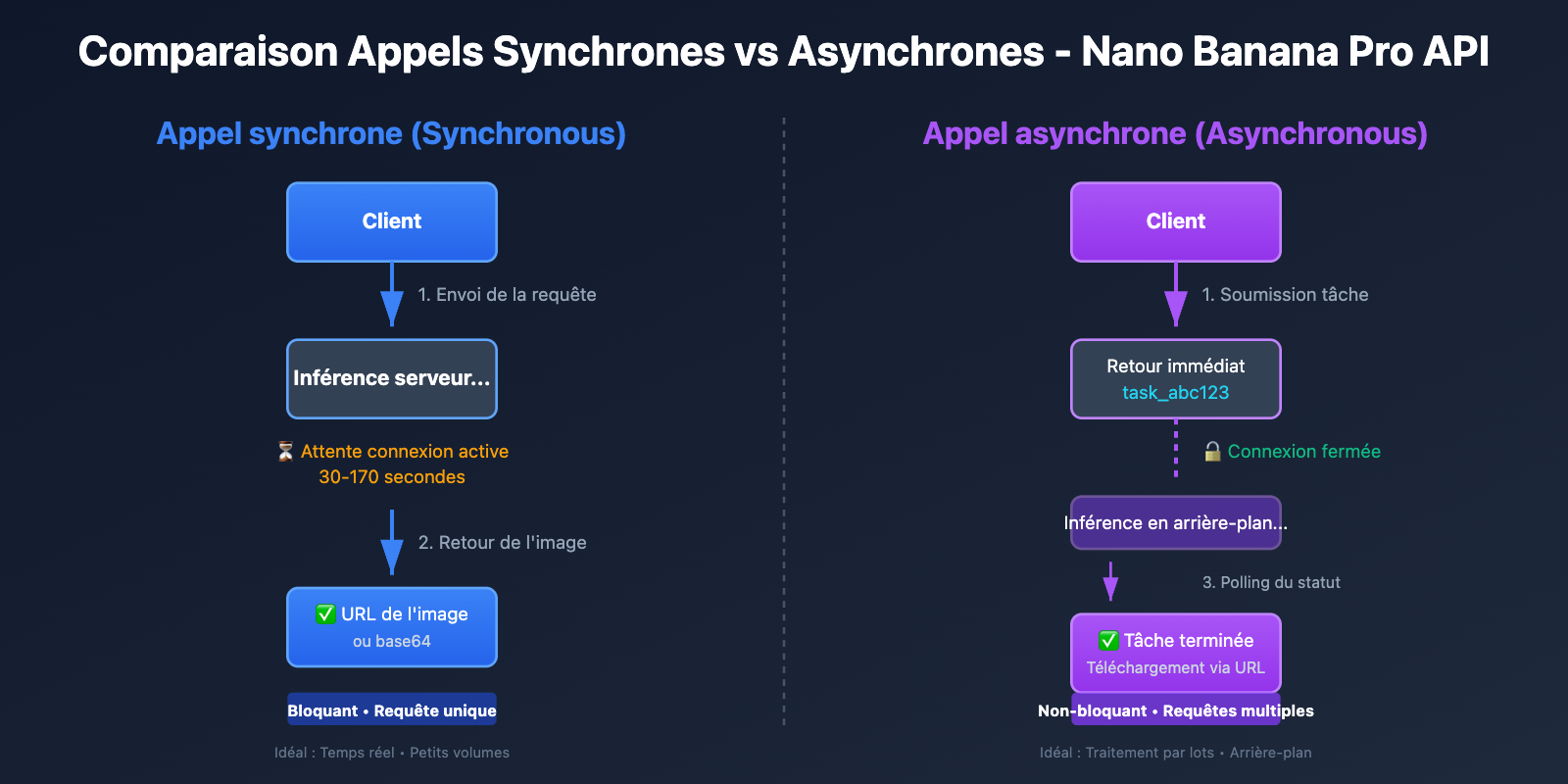
Comparaison des modes d'appel de l'API Nano Banana Pro
| Caractéristique | Appel synchrone (Synchronous) | Appel asynchrone (Asynchronous) | Support actuel APIYI |
|---|---|---|---|
| Mode de connexion | Maintien de la connexion HTTP | Retour immédiat de l'ID, fermeture | ✅ Synchrone |
| Méthode d'attente | Attente bloquante (30-170s) | Non-bloquant, Polling ou Webhook | ✅ Synchrone (bloquant) |
| Risque de timeout | Élevé (nécessite 300-600s) | Faible (timeout court pour soumission) | ⚠️ Nécessite bon paramétrage |
| Complexité | Faible (requête unique) | Moyenne (Polling ou Webhook requis) | ✅ Simple d'utilisation |
| Scénarios | Génération en temps réel | Traitement par lots, arrière-plan | ✅ Temps réel |
| Optimisation coût | Prix standard | L'API Google Batch peut économiser 50% | – |
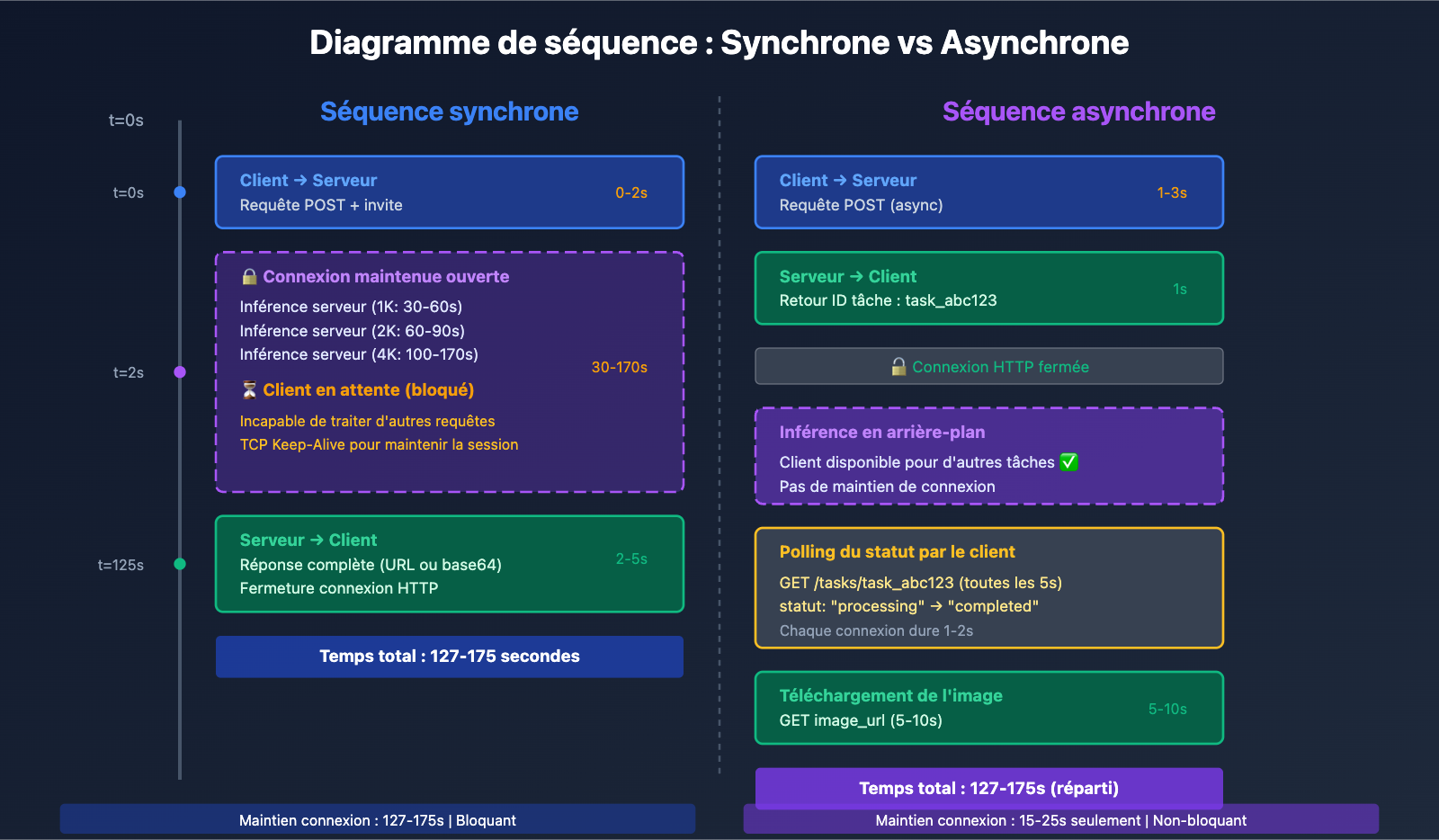
Fonctionnement de l'appel synchrone
L'appel synchrone (Synchronous Call) suit un modèle Requête-Attente-Réponse :
- Le client lance la requête : Envoi de la demande de génération d'image au serveur.
- Maintien de la connexion HTTP : Le client garde la connexion TCP ouverte en attendant que le serveur termine l'inférence.
- Attente bloquante : Pendant les 30 à 170 secondes d'inférence, le client ne peut pas effectuer d'autres opérations.
- Réception de la réponse complète : Le serveur renvoie les données de l'image générée (base64 ou URL).
- Fermeture de la connexion : La connexion HTTP est fermée une fois l'opération terminée.
Caractéristique clé : L'appel synchrone est bloquant (Blocking). Le client doit attendre la réponse du serveur avant de poursuivre. Cela nécessite de configurer des délais d'expiration (timeouts) suffisamment longs (300s recommandées pour le 1K/2K, 600s pour le 4K) pour éviter une coupure avant la fin de l'inférence.
Fonctionnement de l'appel asynchrone
L'appel asynchrone (Asynchronous Call) suit un modèle Requête-Acceptation-Notification :
- Le client soumet la tâche : Envoi de la demande de génération d'image au serveur.
- Retour immédiat de l'ID de tâche : Le serveur accepte la requête, renvoie un ID (ex:
task_abc123) et ferme immédiatement la connexion. - Inférence en arrière-plan : Le serveur génère l'image en tâche de fond, pendant que le client peut traiter d'autres opérations.
- Récupération du résultat : Le client obtient le résultat via l'une des deux méthodes suivantes :
- Polling (Sondage) : Requêtes régulières vers
/tasks/task_abc123/statuspour vérifier l'état. - Rappel Webhook : Une fois terminé, le serveur appelle activement une URL de rappel fournie par le client.
- Polling (Sondage) : Requêtes régulières vers
- Téléchargement de l'image : Une fois la tâche terminée, l'image est téléchargée via l'URL fournie.
Caractéristique clé : L'appel asynchrone est non-bloquant (Non-blocking). Le client peut traiter d'autres demandes immédiatement après la soumission, sans maintenir de connexion longue. C'est idéal pour le traitement par lots et les tâches de fond.
💡 Conseil technique : La plateforme APIYI ne supporte actuellement que le mode synchrone, mais l'optimisation des timeouts et la fourniture d'URL OSS améliorent nettement l'expérience. Pour les besoins de génération massive, nous recommandons de passer par la plateforme APIYI (apiyi.com) qui offre une interface API HTTP stable, des timeouts pré-configurés et supporte une haute concurrence en mode synchrone.
Différence clé 1 : Durée de maintien de la connexion et configuration des délais (timeouts)
Exigences de maintien de la connexion pour les appels synchrones
L'appel synchrone exige que le client maintienne la connexion HTTP ouverte pendant tout le processus de génération d'image, ce qui entraîne les défis techniques suivants :
| Défi | Impact | Solution |
|---|---|---|
| Connexion inactive prolongée | Les équipements réseau intermédiaires (NAT, pare-feu) peuvent couper la connexion | Configurer le TCP Keep-Alive |
| Configuration complexe du timeout | Nécessite de configurer précisément le délai d'expiration selon la résolution | 1K/2K : 300s, 4K : 600s |
| Sensibilité aux fluctuations réseau | Risque de déconnexion fréquent en cas de réseau instable | Implémenter un mécanisme de tentatives (retries) |
| Limitation des connexions simultanées | Les navigateurs limitent par défaut à 6 connexions simultanées | Passer par un appel côté serveur ou augmenter le pool de connexions |
Exemple d'appel synchrone en Python :
import requests
import time
def generate_image_sync(prompt: str, size: str = "4096x4096") -> dict:
"""
Appel synchrone à l'API Nano Banana Pro pour générer une image
Args:
prompt: invite d'image
size: taille de l'image
Returns:
Résultat de la réponse API
"""
start_time = time.time()
# Appel synchrone : maintenir la connexion jusqu'à la fin de la génération
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations",
json={
"prompt": prompt,
"size": size,
"model": "nano-banana-pro",
"n": 1,
"response_format": "url" # APIYI prend en charge la sortie par URL
},
headers={"Authorization": "Bearer YOUR_API_KEY"},
timeout=(10, 600) # Timeout de connexion de 10s, timeout de lecture de 600s
)
elapsed = time.time() - start_time
print(f"⏱️ Temps écoulé (appel synchrone) : {elapsed:.2f} secondes")
print(f"🔗 État de la connexion : maintenue ouverte pendant {elapsed:.2f} secondes")
return response.json()
# Exemple d'utilisation
result = generate_image_sync(
prompt="A futuristic cityscape at sunset",
size="4096x4096"
)
print(f"✅ URL de l'image : {result['data'][0]['url']}")
Observations clés :
- Le client est totalement bloqué pendant les 100 à 170 secondes de l'inférence.
- La connexion HTTP reste ouverte en permanence, consommant des ressources système.
- Si le timeout est mal configuré (ex: 60s), la connexion se coupera avant la fin de l'inférence.
Avantages des connexions courtes pour les appels asynchrones
L'appel asynchrone n'établit des connexions courtes que lors de la soumission de la tâche et de la consultation du statut, réduisant ainsi considérablement le temps de maintien de la connexion :
| Phase | Temps de connexion | Configuration du timeout |
|---|---|---|
| Soumission de la tâche | 1-3 secondes | 30 secondes suffisent |
| Sondage du statut | 1-2 secondes par itération | 10 secondes suffisent |
| Téléchargement de l'image | 5-10 secondes | 60 secondes suffisent |
| Total | 10-20 secondes (dispersées) | Bien inférieur à l'appel synchrone |
Exemple d'appel asynchrone en Python (simulation d'une future version d'APIYI) :
import requests
import time
def generate_image_async(prompt: str, size: str = "4096x4096") -> str:
"""
Appel asynchrone à l'API Nano Banana Pro pour générer une image (fonctionnalité future)
Args:
prompt: invite d'image
size: taille de l'image
Returns:
ID de la tâche
"""
# Étape 1 : Soumission de la tâche (connexion courte)
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations/async", # Interface future
json={
"prompt": prompt,
"size": size,
"model": "nano-banana-pro",
"n": 1,
"response_format": "url"
},
headers={"Authorization": "Bearer YOUR_API_KEY"},
timeout=(10, 30) # Le timeout de soumission n'a besoin que de 30s
)
task_data = response.json()
task_id = task_data["task_id"]
print(f"✅ Tâche soumise : {task_id}")
print(f"🔓 Connexion fermée, vous pouvez traiter d'autres tâches")
return task_id
def poll_task_status(task_id: str, max_wait: int = 300) -> dict:
"""
Sondage (polling) du statut de la tâche jusqu'à complétion
Args:
task_id: ID de la tâche
max_wait: Temps d'attente maximum (secondes)
Returns:
Résultat de génération
"""
start_time = time.time()
poll_interval = 5 # Sondage toutes les 5 secondes
while time.time() - start_time < max_wait:
# Consultation du statut (connexion courte)
response = requests.get(
f"http://api.apiyi.com:16888/v1/tasks/{task_id}", # Interface future
headers={"Authorization": "Bearer YOUR_API_KEY"},
timeout=(10, 10) # Le timeout de consultation n'a besoin que de 10s
)
status_data = response.json()
status = status_data["status"]
if status == "completed":
elapsed = time.time() - start_time
print(f"✅ Tâche terminée ! Temps total : {elapsed:.2f} secondes")
return status_data["result"]
elif status == "failed":
raise Exception(f"Échec de la tâche : {status_data.get('error')}")
else:
print(f"⏳ Statut de la tâche : {status}, attente de {poll_interval}s avant de réessayer...")
time.sleep(poll_interval)
raise TimeoutError(f"Délai de la tâche dépassé : {task_id}")
# Exemple d'utilisation
task_id = generate_image_async(
prompt="A serene mountain landscape",
size="4096x4096"
)
# Pendant le sondage, on peut traiter d'autres tâches
print("🚀 On peut traiter d'autres requêtes en parallèle...")
# Sondage du statut de la tâche
result = poll_task_status(task_id, max_wait=600)
print(f"✅ URL de l'image : {result['data'][0]['url']}")
Voir l’exemple du mode rappel Webhook (fonctionnalité future)
from flask import Flask, request, jsonify
import requests
app = Flask(__name__)
# Dictionnaire global pour stocker les résultats des tâches
task_results = {}
@app.route('/webhook/image_completed', methods=['POST'])
def handle_webhook():
"""Réception du rappel Webhook pour la complétion d'une tâche asynchrone APIYI"""
data = request.json
task_id = data['task_id']
status = data['status']
result = data.get('result')
if status == 'completed':
task_results[task_id] = result
print(f"✅ Tâche {task_id} terminée : {result['data'][0]['url']}")
else:
print(f"❌ Tâche {task_id} échouée : {data.get('error')}")
return jsonify({"received": True}), 200
def generate_image_with_webhook(prompt: str, size: str = "4096x4096") -> str:
"""
Génération d'image asynchrone via le mode Webhook
Args:
prompt: invite d'image
size: taille de l'image
Returns:
ID de la tâche
"""
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations/async",
json={
"prompt": prompt,
"size": size,
"model": "nano-banana-pro",
"n": 1,
"response_format": "url",
"webhook_url": "https://votre-domaine.com/webhook/image_completed" # URL de rappel
},
headers={"Authorization": "Bearer YOUR_API_KEY"},
timeout=(10, 30)
)
task_id = response.json()["task_id"]
print(f"✅ Tâche soumise : {task_id}")
print(f"📞 Le Webhook rappellera sur : https://votre-domaine.com/webhook/image_completed")
return task_id
# Démarrage du serveur Flask pour écouter le Webhook
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
🎯 Limites actuelles : APIYI et les API officielles de Gemini ne supportent actuellement que le mode synchrone ; les fonctionnalités asynchrones sont prévues pour des versions futures. Pour les scénarios nécessitant une haute simultanéité, nous recommandons d'utiliser le multithreading ou le multiprocessing via la plateforme APIYI (apiyi.com) pour appeler les interfaces synchrones, tout en configurant des timeouts appropriés.
Différence clé 2 : Capacité de traitement concurrent et occupation des ressources
Limitations de la simultanéité en appel synchrone
L'appel synchrone pose des problèmes majeurs d'occupation des ressources dans les scénarios à haute fréquentation :
Problème de blocage en mode monothread :
import time
# ❌ ERREUR : Appel séquentiel monothread, Temps total = Temps unitaire × Nombre de tâches
def generate_multiple_images_sequential(prompts: list) -> list:
results = []
start_time = time.time()
for prompt in prompts:
result = generate_image_sync(prompt, size="4096x4096")
results.append(result)
elapsed = time.time() - start_time
print(f"❌ Temps d'appel séquentiel pour {len(prompts)} images : {elapsed:.2f} secondes")
# En supposant 120s par image, 10 images = 1200s (20 minutes !)
return results
Optimisation par concurrence multithread :
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
# ✅ CORRECT : Appel concurrent multithread, exploitant pleinement le temps d'attente I/O
def generate_multiple_images_concurrent(prompts: list, max_workers: int = 5) -> list:
"""
Génération concurrente multithread de plusieurs images
Args:
prompts: Liste d'invites
max_workers: Nombre maximal de threads concurrents
Returns:
Liste des résultats de génération
"""
results = []
start_time = time.time()
with ThreadPoolExecutor(max_workers=max_workers) as executor:
# Soumission de toutes les tâches
future_to_prompt = {
executor.submit(generate_image_sync, prompt, "4096x4096"): prompt
for prompt in prompts
}
# Attente de la complétion de toutes les tâches
for future in as_completed(future_to_prompt):
prompt = future_to_prompt[future]
try:
result = future.result()
results.append(result)
print(f"✅ Terminé : {prompt[:30]}...")
except Exception as e:
print(f"❌ Échec : {prompt[:30]}... - {e}")
elapsed = time.time() - start_time
print(f"✅ Temps d'appel concurrent pour {len(prompts)} images : {elapsed:.2f} secondes")
# En supposant 120s par image, 10 images ≈ 120-150s (2 à 2,5 minutes)
return results
# Exemple d'utilisation
prompts = [
"A cyberpunk city at night",
"A serene forest landscape",
"An abstract geometric pattern",
"A futuristic space station",
"A vintage car in the desert",
# ...plus d'invites
]
results = generate_multiple_images_concurrent(prompts, max_workers=5)
print(f"🎉 {len(results)} images générées")
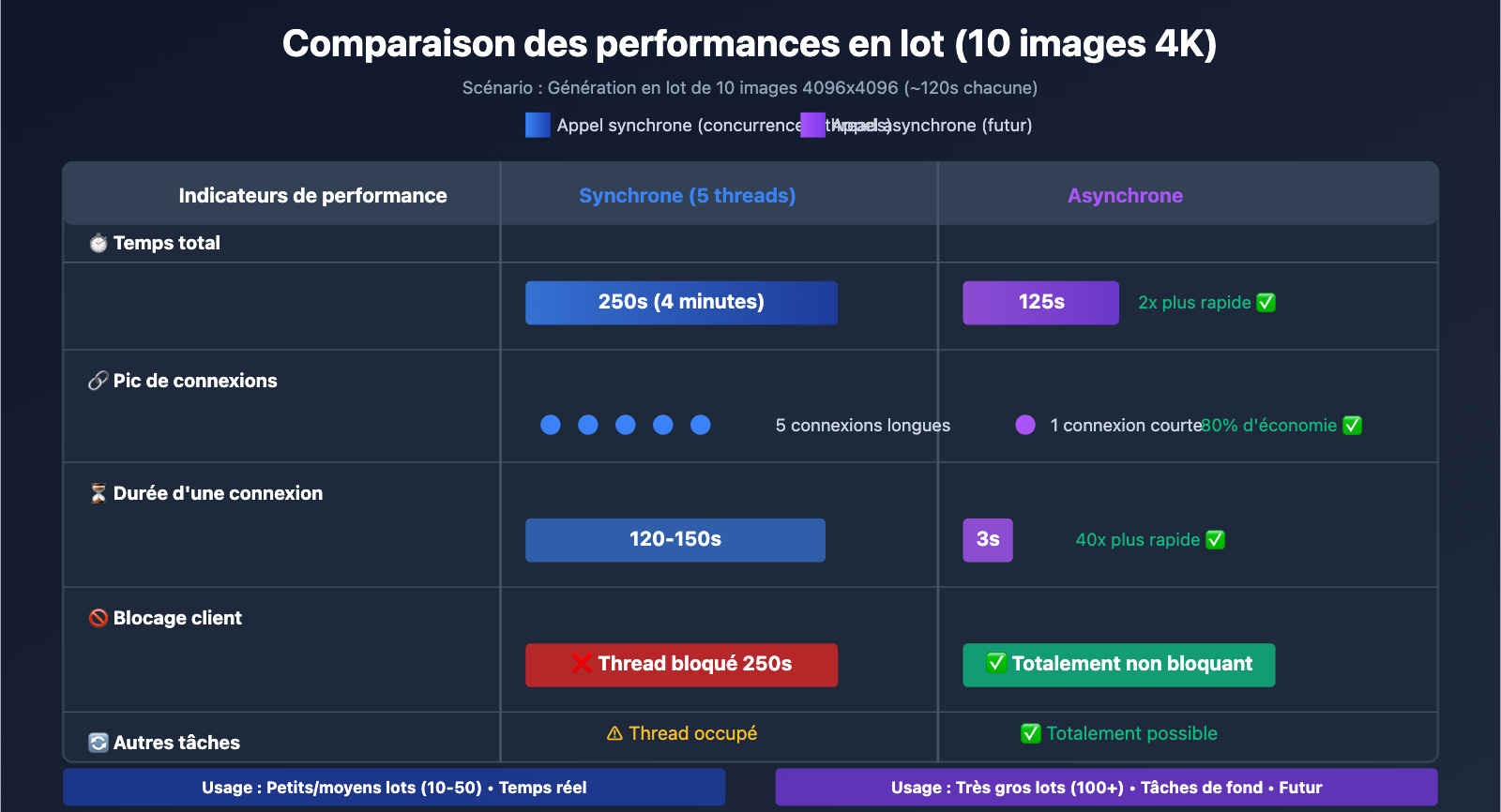
| Méthode de simultanéité | Temps pour 10 images 4K | Occupation des ressources | Scénario d'application |
|---|---|---|---|
| Appel séquentiel | 1200s (20 min) | Faible (connexion unique) | Image unique, génération en temps réel |
| Multithread (5 threads) | 250s (4 min) | Moyenne (5 connexions) | Petits et moyens lots (10-50 images) |
| Multiprocess (10 processus) | 150s (2,5 min) | Élevée (10 connexions) | Gros lots (50+ images) |
| Appel asynchrone (futur) | 120s + surcharge du sondage | Faible (connexions de sondage courtes) | Très gros lots (100+ images) |
Avantage de la simultanéité pour l'asynchrone
L'appel asynchrone présente un avantage significatif pour le traitement par lots :
Soumission en lot + Sondage en lot :
def generate_batch_async(prompts: list) -> list:
"""
Génération asynchrone en lot (fonctionnalité future)
Args:
prompts: Liste d'invites
Returns:
Liste des IDs de tâches
"""
task_ids = []
# Étape 1 : Soumission rapide en lot de toutes les tâches (1-3s chacune)
for prompt in prompts:
task_id = generate_image_async(prompt, size="4096x4096")
task_ids.append(task_id)
print(f"✅ Soumission en lot de {len(task_ids)} tâches, durée environ {len(prompts) * 2} secondes")
# Étape 2 : Sondage en lot du statut des tâches
results = []
for task_id in task_ids:
result = poll_task_status(task_id, max_wait=600)
results.append(result)
return results
| Indicateur | Synchrone (Multithread) | Asynchrone (futur) | Différence |
|---|---|---|---|
| Durée phase soumission | 1200s (attente bloquante) | 20s (soumission rapide) | Asynchrone 60x plus rapide |
| Temps total | 250s (5 threads) | 120s + surcharge de sondage | Asynchrone 2x plus rapide |
| Pic de connexions | 5 connexions longues | 1 connexion courte (soumission) | Économie de 80% des connexions |
| Traitement autres tâches | ❌ Threads bloqués | ✅ Totalement non bloquant | L'asynchrone est plus flexible |
💰 Optimisation des coûts : L'API Google Gemini propose un mode Batch API, permettant un traitement asynchrone avec une réduction de 50 % sur le prix (prix standard 0,133 $ – 0,24 $ / image, Batch API 0,067 $ – 0,12 $ / image), à condition d'accepter un délai de livraison pouvant aller jusqu'à 24 heures. Pour les scénarios ne nécessitant pas de génération en temps réel, le mode Batch API est une excellente option pour réduire les coûts.
Différence majeure 3 : Les avantages de la sortie via URL OSS sur la plateforme APIYI
Comparaison entre l'encodage base64 et la sortie URL
L'API de Nano Banana Pro prend en charge deux formats de sortie pour les images :
| Caractéristique | Encodage base64 | Sortie URL OSS (Exclusivité APIYI) | Recommandation |
|---|---|---|---|
| Taille du corps de la réponse | 6-8 Mo (image 4K) | 200 octets (URL uniquement) | URL ✅ |
| Temps de transfert | 5-10 secondes (plus lent sur réseau faible) | < 1 seconde | URL ✅ |
| Mise en cache navigateur | ❌ Impossible à mettre en cache | ✅ Mise en cache HTTP standard | URL ✅ |
| Accélération CDN | ❌ Inexploitable | ✅ Accélération CDN mondiale | URL ✅ |
| Optimisation d'image | ❌ WebP, etc. non supportés | ✅ Conversion de format supportée | URL ✅ |
| Chargement progressif | ❌ Téléchargement complet obligatoire | ✅ Chargement progressif supporté | URL ✅ |
| Performances mobiles | ❌ Consommation mémoire élevée | ✅ Flux de téléchargement optimisé | URL ✅ |
Les problèmes de performance de l'encodage base64 :
-
Gonflement du corps de la réponse de 33 % : L'encodage base64 augmente le volume de données d'environ 33 %.
- Image 4K originale : environ 6 Mo
- Après encodage base64 : environ 8 Mo
-
Incapacité à utiliser un CDN : La chaîne base64 est intégrée dans la réponse JSON, elle ne peut donc pas être mise en cache par un CDN.
-
Pression sur la mémoire mobile : Le décodage d'une chaîne base64 nécessite des ressources mémoire et CPU supplémentaires.
Avantages de la sortie via URL OSS d'APIYI :
import requests
# ✅ Recommandé : Utiliser la sortie URL OSS d'APIYI
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations",
json={
"prompt": "A beautiful sunset over mountains",
"size": "4096x4096",
"model": "nano-banana-pro",
"n": 1,
"response_format": "url" # Spécifier la sortie URL
},
headers={"Authorization": "Bearer VOTRE_CLE_API"},
timeout=(10, 600)
)
result = response.json()
# Le corps de la réponse ne contient que l'URL, environ 200 octets
print(f"Taille du corps de la réponse : {len(response.content)} octets")
# Sortie : Taille du corps de la réponse : 234 octets
# Exemple d'URL OSS
image_url = result['data'][0]['url']
print(f"URL de l'image : {image_url}")
# Sortie : https://apiyi-oss.oss-cn-beijing.aliyuncs.com/nano-banana/abc123.png
# Téléchargement ultérieur de l'image via HTTP standard, bénéficiant de l'accélération CDN
image_response = requests.get(image_url)
with open("output.png", "wb") as f:
f.write(image_response.content)
Comparaison : Problèmes de performance de la sortie base64 :
# ❌ Non recommandé : Sortie encodée en base64
response = requests.post(
"https://api.example.com/v1/images/generations",
json={
"prompt": "A beautiful sunset over mountains",
"size": "4096x4096",
"model": "nano-banana-pro",
"n": 1,
"response_format": "b64_json" # Encodage base64
},
headers={"Authorization": "Bearer VOTRE_CLE_API"},
timeout=(10, 600)
)
result = response.json()
# Le corps de la réponse contient la chaîne base64 complète, environ 8 Mo
print(f"Taille du corps de la réponse : {len(response.content)} octets")
# Sortie : Taille du corps de la réponse : 8388608 octets (8 Mo !)
# Nécessite de décoder la chaîne base64
import base64
image_b64 = result['data'][0]['b64_json']
image_bytes = base64.b64decode(image_b64)
with open("output.png", "wb") as f:
f.write(image_bytes)
| Indicateur de comparaison | Encodage base64 | URL OSS APIYI | Amélioration des performances |
|---|---|---|---|
| Taille de la réponse API | 8 Mo | 200 octets | Réduction de 99,998 % |
| Temps de réponse API | 125s + 5-10s de transfert | 125s + < 1s | Gain de 5 à 10 secondes |
| Mode de téléchargement | Intégré au JSON | Requête HTTP indépendante | Téléchargement concurrent possible |
| Mise en cache navigateur | Non mis en cache | Cache HTTP standard | Chargement instantané lors des visites répétées |
| Accélération CDN | Non supportée | Nœuds CDN mondiaux | Accès accéléré à l'international |
🚀 Configuration recommandée : Lors de l'appel à l'API Nano Banana Pro sur la plateforme APIYI, utilisez toujours
response_format: "url"pour obtenir une sortie via URL OSS plutôt qu'un encodage base64. Cela réduit non seulement considérablement la taille de la réponse et le temps de transfert, mais permet aussi de profiter pleinement de l'accélération CDN et du cache navigateur pour améliorer l'expérience utilisateur.
Différence majeure 4 : Scénarios d'utilisation et planification future
Meilleurs scénarios pour les appels synchrones
Scénarios recommandés :
- Génération d'images en temps réel : Affichage immédiat de l'image générée après la soumission de l'invite par l'utilisateur.
- Traitement par petits lots : Pour générer 1 à 10 images, des appels concurrents suffisent à répondre aux exigences de performance.
- Intégration simple : Pas besoin d'implémenter de polling (sondage) ou de Webhooks, ce qui réduit la complexité du développement.
- Applications interactives : Outils de dessin IA, éditeurs d'images, etc., nécessitant un retour immédiat.
Modèle de code typique :
from flask import Flask, request, jsonify
import requests
app = Flask(__name__)
@app.route('/generate', methods=['POST'])
def generate_image():
"""Interface de génération d'images en temps réel"""
data = request.json
prompt = data['prompt']
size = data.get('size', '1024x1024')
# Appel synchrone, l'utilisateur attend la fin de la génération
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations",
json={
"prompt": prompt,
"size": size,
"model": "nano-banana-pro",
"n": 1,
"response_format": "url"
},
headers={"Authorization": "Bearer VOTRE_CLE_API"},
# Ajustement du timeout selon la taille
timeout=(10, 300 if size != '4096x4096' else 600)
)
result = response.json()
return jsonify({
"success": True,
"image_url": result['data'][0]['url']
})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8000)
Scénarios d'application futurs pour les appels asynchrones
Scénarios concernés (support futur) :
- Génération d'images en masse : Génération de plus de 100 images, comme des photos de produits pour l'e-commerce ou des bibliothèques de ressources de design.
- Tâches planifiées en arrière-plan : Génération automatique quotidienne de types d'images spécifiques, sans besoin de réponse en temps réel.
- Traitement à bas coût : Utilisation de l'API Google Batch pour obtenir une remise de 50 %, en acceptant un délai de livraison de 24 heures.
- Scénarios à haute concurrence : Des centaines d'utilisateurs soumettant des requêtes simultanément, évitant ainsi l'épuisement du pool de connexions.
Modèle de code typique (Futur) :
from flask import Flask, request, jsonify
from celery import Celery
import requests
app = Flask(__name__)
celery = Celery('tasks', broker='redis://localhost:6379/0')
@celery.task
def generate_image_task(prompt: str, size: str, user_id: str):
"""Tâche asynchrone Celery : générer une image"""
# Soumission de la tâche asynchrone à APIYI
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations/async", # Future interface
json={
"prompt": prompt,
"size": size,
"model": "nano-banana-pro",
"n": 1,
"response_format": "url",
"webhook_url": f"https://votre-domaine.com/webhook/{user_id}"
},
headers={"Authorization": "Bearer VOTRE_CLE_API"},
timeout=(10, 30)
)
task_id = response.json()["task_id"]
return task_id
@app.route('/generate_async', methods=['POST'])
def generate_image_async():
"""Interface de génération d'images asynchrone"""
data = request.json
prompt = data['prompt']
size = data.get('size', '1024x1024')
user_id = data['user_id']
# Soumission de la tâche Celery et retour immédiat
task = generate_image_task.delay(prompt, size, user_id)
return jsonify({
"success": True,
"message": "Tâche soumise, notification via Webhook une fois terminée",
"task_id": task.id
})
@app.route('/webhook/<user_id>', methods=['POST'])
def handle_webhook(user_id: str):
"""Réception du rappel Webhook pour la fin de la tâche asynchrone APIYI"""
data = request.json
task_id = data['task_id']
result = data['result']
# Notification de l'utilisateur (email, push, etc.)
notify_user(user_id, result['data'][0]['url'])
return jsonify({"received": True}), 200
Planification future de la plateforme APIYI
| Fonctionnalité | État actuel | Planification future | Date prévue |
|---|---|---|---|
| Appel synchrone | ✅ Supporté | Optimisation continue des timeouts | – |
| Sortie URL OSS | ✅ Supporté | Ajout de nœuds CDN supplémentaires | T2 2026 |
| Appel asynchrone (Polling) | ❌ Non supporté | Support de la soumission de tâche + requête d'état | T2 2026 |
| Appel asynchrone (Webhook) | ❌ Non supporté | Support des notifications de rappel après fin de tâche | T2 2026 |
| Intégration API Batch | ❌ Non supporté | Intégration de l'API Google Batch | T4 2026 |
💡 Conseil de développement : APIYI prévoit de lancer des fonctionnalités d'appel asynchrone au troisième trimestre 2026, incluant la soumission de tâches, la requête d'état et les rappels Webhook. Pour les développeurs ayant des besoins de traitement par lots dès maintenant, nous recommandons d'utiliser des appels concurrents multi-threadés sur l'interface synchrone, tout en profitant des ports HTTP stables et des configurations de timeout optimisées via la plateforme APIYI (apiyi.com).
Questions Fréquentes
Q1 : Pourquoi APIYI et Gemini ne supportent-ils pas nativement les appels asynchrones ?
Raisons techniques :
-
Limitations de l'infrastructure Google : L'infrastructure sous-jacente de l'API Google Gemini ne supporte actuellement que le mode d'inférence synchrone. Les appels asynchrones nécessiteraient un système de file d'attente de tâches et de gestion d'état supplémentaire.
-
Complexité de développement : Les appels asynchrones nécessitent l'implémentation de :
- Gestion des files d'attente de tâches
- Persistance de l'état des tâches
- Mécanismes de rappel Webhook
- Logique de tentative (retry) et de compensation en cas d'échec
-
Priorité des besoins utilisateurs : La plupart des utilisateurs souhaitent une génération d'image en temps réel. Les appels synchrones répondent déjà à plus de 80 % des cas d'utilisation.
Solutions :
- Actuellement : Utiliser le multithreading ou le multi-processus pour appeler l'interface synchrone de manière concurrente.
- Futur : APIYI prévoit de lancer une fonctionnalité d'appel asynchrone au deuxième trimestre 2026.
Q2 : Les images via URL OSS d’APIYI sont-elles conservées de façon permanente ?
Stratégie de stockage :
| Durée de stockage | Description | Cas d'utilisation |
|---|---|---|
| 7 jours | Conservé par défaut pendant 7 jours, puis supprimé automatiquement | Aperçus temporaires, tests de génération |
| 30 jours | Peut être prolongé à 30 jours pour les utilisateurs payants | Projets à court terme, matériel promotionnel |
| Permanent | L'utilisateur télécharge l'image sur son propre OSS | Utilisation à long terme, projets commerciaux |
Pratique recommandée :
import requests
# 生成图像并获取 URL
result = generate_image_sync(prompt="A beautiful landscape", size="4096x4096")
temp_url = result['data'][0]['url']
print(f"临时 URL: {temp_url}")
# 下载图像到本地或自己的 OSS
image_response = requests.get(temp_url)
with open("permanent_image.png", "wb") as f:
f.write(image_response.content)
# 或上传到自己的 OSS (以阿里云 OSS 为例)
import oss2
auth = oss2.Auth('YOUR_ACCESS_KEY', 'YOUR_SECRET_KEY')
bucket = oss2.Bucket(auth, 'oss-cn-beijing.aliyuncs.com', 'your-bucket')
bucket.put_object('images/permanent_image.png', image_response.content)
Note : L'URL OSS fournie par APIYI est un stockage temporaire, idéal pour un aperçu rapide et des tests. Pour les images nécessitant une conservation à long terme, veuillez les télécharger rapidement en local ou sur votre propre stockage cloud.
Q2 : Comment éviter les timeouts lors d’un appel synchrone ?
3 configurations clés pour éviter les timeouts :
-
Régler correctement les délais d'attente :
# ✅ 正确: 分别设置连接和读取超时 timeout=(10, 600) # (连接超时 10 秒, 读取超时 600 秒) # ❌ 错误: 仅设置单个超时值 timeout=600 # 可能仅作用于连接超时 -
Utiliser l'interface du port HTTP :
# ✅ 推荐: 使用 APIYI HTTP 端口,避免 HTTPS 握手开销 url = "http://api.apiyi.com:16888/v1/images/generations" # ⚠️ 可选: HTTPS 接口,增加 TLS 握手时间 url = "https://api.apiyi.com/v1/images/generations" -
Implémenter un mécanisme de tentative (retry) :
from requests.adapters import HTTPAdapter from requests.packages.urllib3.util.retry import Retry # 配置重试策略 retry_strategy = Retry( total=3, # 最多重试 3 次 status_forcelist=[429, 500, 502, 503, 504], # 仅对这些状态码重试 backoff_factor=2 # 指数退避: 2s, 4s, 8s ) adapter = HTTPAdapter(max_retries=retry_strategy) session = requests.Session() session.mount("http://", adapter) # 使用 session 发起请求 response = session.post( "http://api.apiyi.com:16888/v1/images/generations", json={...}, timeout=(10, 600) )
Q4 : Comment appeler l’API Nano Banana Pro directement depuis le front-end ?
Pourquoi nous ne recommandons pas l'appel direct depuis le front-end :
- Risque de fuite de la clé API : Le code front-end expose votre clé API à tous les utilisateurs.
- Limites de connexions simultanées du navigateur : Les navigateurs limitent par défaut à 6 le nombre de connexions simultanées vers un même domaine.
- Limites de timeout : L'API
fetchdu navigateur a souvent un timeout par défaut assez court, ce qui peut être insuffisant pour terminer la génération.
Architecture recommandée : Mode Proxy Backend :
// 前端代码 (React 示例)
async function generateImage(prompt, size) {
// 调用自己的后端接口
const response = await fetch('https://your-backend.com/api/generate', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': 'Bearer YOUR_USER_TOKEN' // 用户认证 token
},
body: JSON.stringify({ prompt, size })
});
const result = await response.json();
return result.image_url; // 返回 APIYI OSS URL
}
// 使用
const imageUrl = await generateImage("A futuristic city", "4096x4096");
document.getElementById('result-image').src = imageUrl;
# 后端代码 (Flask 示例)
from flask import Flask, request, jsonify
import requests
app = Flask(__name__)
@app.route('/api/generate', methods=['POST'])
def generate():
# 验证用户 token
user_token = request.headers.get('Authorization')
if not verify_user_token(user_token):
return jsonify({"error": "Unauthorized"}), 401
data = request.json
# 后端调用 APIYI API (API Key 不会暴露给前端)
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations",
json={
"prompt": data['prompt'],
"size": data['size'],
"model": "nano-banana-pro",
"n": 1,
"response_format": "url"
},
headers={"Authorization": "Bearer YOUR_APIYI_API_KEY"}, # 安全存储在后端
timeout=(10, 600)
)
result = response.json()
return jsonify({"image_url": result['data'][0]['url']})
Conclusion
Points clés sur les appels synchrones et asynchrones de l'API Nano Banana Pro :
- Caractéristiques de l'appel synchrone : Maintient la connexion HTTP jusqu'à la fin de la génération, nécessite une attente bloquante de 30 à 170 secondes, et impose une configuration de timeout longue (300-600 secondes).
- Avantages de l'appel asynchrone : Retourne immédiatement un ID de tâche, non bloquant, idéal pour le traitement par lots et les tâches de fond, bien qu'il ne soit pas encore supporté par APIYI ou Gemini officiellement.
- Sortie URL OSS d'APIYI : Comparé au codage base64, la taille de la réponse est réduite de 99,998 %, supporte l'accélération CDN et le cache du navigateur, améliorant considérablement les performances.
- Meilleures pratiques actuelles : Utiliser l'appel synchrone + multithreading concurrent + sortie URL OSS, en passant par l'interface du port HTTP d'APIYI pour bénéficier de configurations de timeout optimisées.
- Planification future : APIYI prévoit de lancer des fonctionnalités d'appel asynchrone au T2 2026, incluant la soumission de tâches, la consultation d'état et les rappels Webhook.
Nous vous recommandons d'utiliser APIYI (apiyi.com) pour intégrer rapidement l'API Nano Banana Pro. La plateforme propose une interface optimisée via port HTTP (http://api.apiyi.com:16888/v1), une sortie d'image exclusive via URL OSS, ainsi que des configurations de timeout adaptées aux scénarios de génération en temps réel et de traitement par lots.
Auteur : Équipe technique APIYI | Pour toute question technique, n'hésitez pas à visiter APIYI apiyi.com pour découvrir plus de solutions d'intégration de grands modèles de langage.