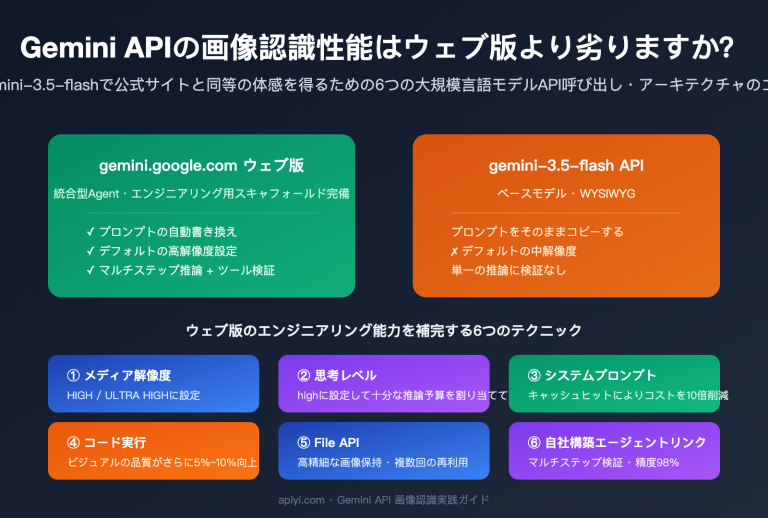
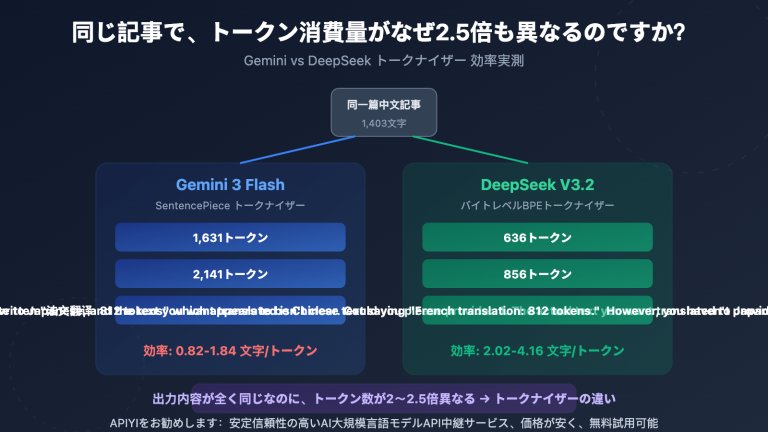
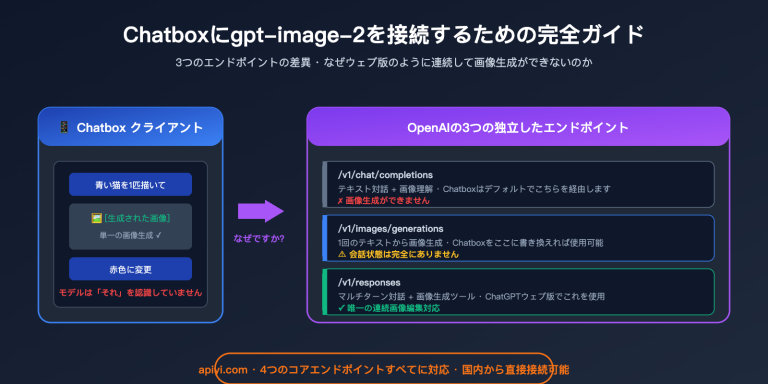
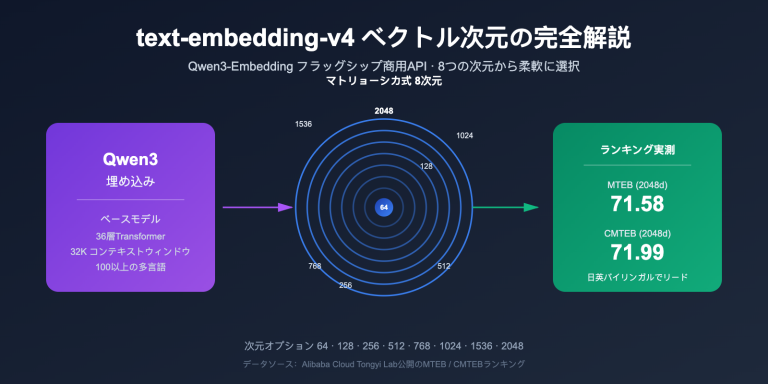
著者注:Gemini Nano Banana Pro API の overloaded および service unavailable エラーについて、発生原因、時間的な傾向、実践的な解決策、そして本番環境におけるベストプラクティスを深く掘り下げて解説します。
2026年1月16日未明 00:18、多くの開発者から Gemini Nano Banana Pro API(モデル名 gemini-3-pro-image-preview)において、「The model is overloaded. Please try again later.」さらには 「The service is currently unavailable.」 というエラーが発生しているとの報告が相次ぎました。これはコードの問題ではなく、Google サーバー側の計算リソースのボトルネックに起因するシステム的な障害です。
この記事の価値: 本文を読み終えることで、これら2種類のエラーの根本原因、発生の法則、技術的なメカニズムを理解し、5つの実践的な解決策を習得できます。また、本番環境レベルの耐障害(フォールトトレラント)戦略の構築方法についても学べます。
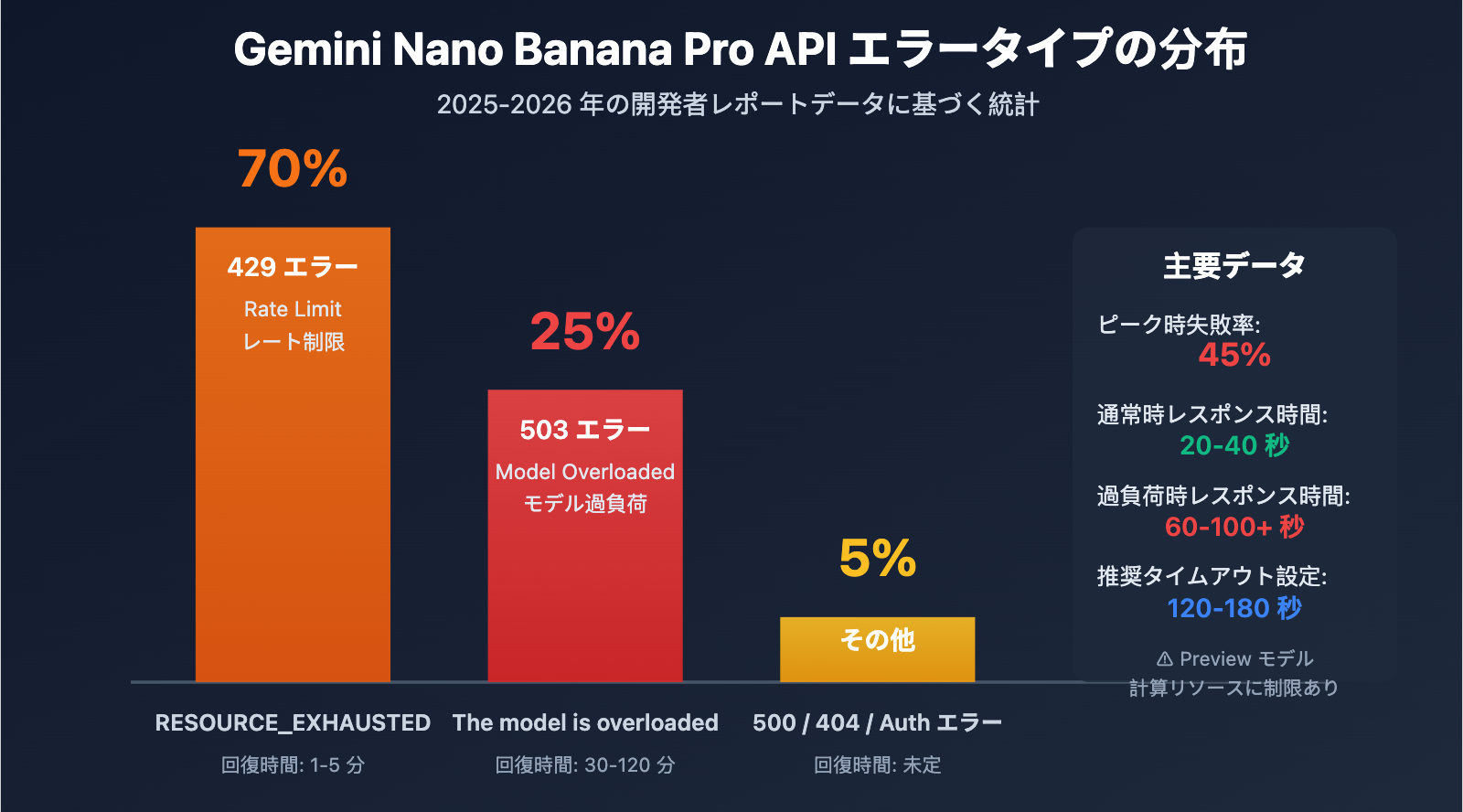
Gemini Nano Banana Pro API エラーの重要ポイント
| 項目 | 説明 | 影響 |
|---|---|---|
| 503 Overloaded エラー | サーバー側の計算リソース不足。コードの問題ではない | ピーク時に API 呼び出しの 45% が失敗する可能性 |
| 503 vs 429 エラー | 503 は容量の問題、429 はレート制限 | 503 の回復には 30〜120 分、429 はわずか 1〜5 分 |
| Preview モデルの制限 | Gemini 3 シリーズはまだプレビュー段階 | 計算リソースが限られ、動的な容量管理が不安定 |
| 時間的な規則性 | 日本時間の深夜から早朝、および夜間のピーク時に失敗率が上昇 | ピーク時間を避けるか、フォールバック戦略の実装が必要 |
| レスポンス時間の急増 | 通常 20〜40 秒のところ、障害時は 60〜100 秒以上に | より長いタイムアウト設定 (120秒以上) が必要 |
Gemini Nano Banana Pro エラーの詳細解説
Nano Banana Pro とは?
Gemini Nano Banana Pro は、Google が提供する最高品質の画像生成モデルであり、対応する API モデル名は gemini-2.0-flash-preview-image-generation または gemini-3-pro-image-preview です。Gemini 3 シリーズのフラッグシップ画像生成モデルとして、画質、ディテールの再現性、文字のレンダリングなどで Gemini 2.5 Flash Image を大きく上回りますが、その分、計算リソースのボトルネックに直面しやすくなっています。
なぜ頻繁にエラーが発生するのか?
Google AI 開発者フォーラムの議論データによると、Nano Banana Pro のエラー問題は 2025 年後半から頻発し始め、2026 年初頭の時点でも完全には解決されていません。主な原因は以下の通りです:
- プレビュー段階のリソース制限: Gemini 3 シリーズモデルはまだ Pre-GA(一般提供開始前)段階にあり、Google が割り当てている計算リソースが限られています。
- 動的な容量管理: ユーザー自身のレート制限(Rate Limit)に達していなくても、システム全体の負荷が高すぎる場合に 503 エラーが返されることがあります。
- グローバルなユーザー競争: 全世界中の開発者が同一の計算リソースプールを共有しているため、ピーク時の需要が供給を大幅に上回ります。
- 計算集約型のモデル: 高品質な画像生成には膨大な GPU 計算が必要であり、1 回のリクエストに 20〜40 秒かかります。これはテキスト生成モデルを遥かに超える負荷です。
503 エラーと 429 エラーの違い
| エラータイプ | HTTP ステータスコード | エラーメッセージ | 根本原因 | 回復時間 | 割合 |
|---|---|---|---|---|---|
| Overloaded | 503 | The model is overloaded |
サーバー側の計算容量不足 | 30-120 分 | 約 25% |
| Rate Limit | 429 | RESOURCE_EXHAUSTED |
ユーザーの割当枠(RPM/TPM/RPD)超過 | 1-5 分 | 約 70% |
| Unavailable | 503 | Service unavailable |
システム的な障害またはメンテナンス | 未定(数時間の場合も) | 約 5% |
Gemini Nano Banana Pro エラー発生時間の法則性分析
ピーク時の故障時間帯
複数の開発者からの報告データに基づくと、Nano Banana Pro API の故障には明確な時間的法則が存在します。
北京時間における高リスク時間帯:
- 00:00 – 02:00: 米国西海岸の始業時間 (08:00-10:00 PST) にあたり、欧米の開発者による利用がピークに達します。
- 09:00 – 11:00: 中国本土の業務開始時間にあたり、アジアの開発者による利用がピークに達します。
- 20:00 – 23:00: 中国本土の夜間のピークタイムと、欧州の午後の時間帯が重なる時間帯です。
比較的安定している時間帯:
- 03:00 – 08:00: 世界的にユーザーが最も少ない時間帯です。
- 14:00 – 17:00: 中国の午後と米国の深夜にあたり、負荷が比較的低くなります。
事例による検証: 2026年1月16日未明 00:18(北京時間)に発生した大規模な故障は、ちょうど米国西海岸の出勤時間(1月15日 08:18 PST)と一致しており、この時間的法則の正確性を裏付けています。

Gemini Nano Banana Pro のエラーを解決する5つの方法
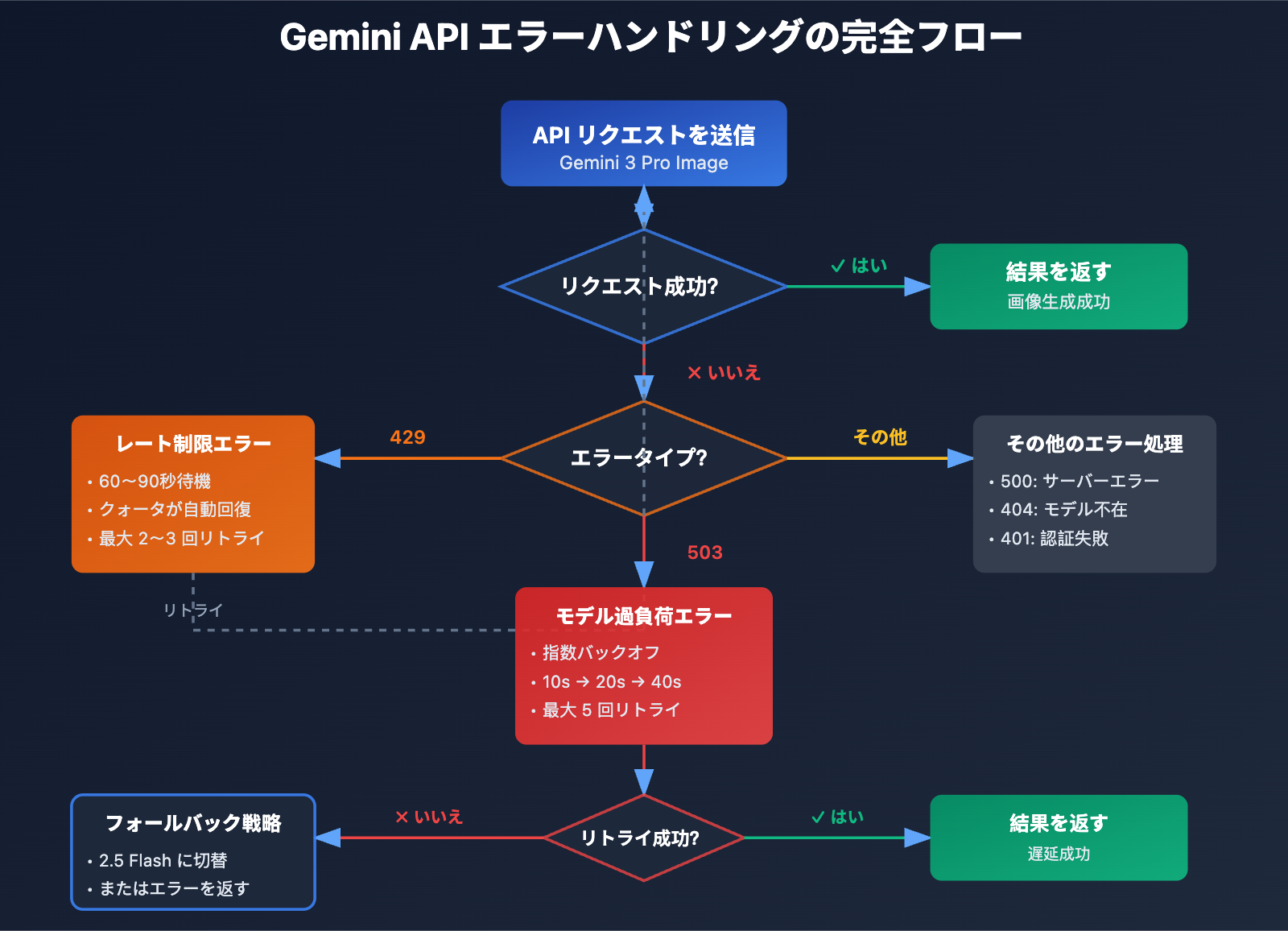
方法 1: 指数バックオフ再試行戦略の実装
これは 503 エラーに対応するための最も基本的なソリューションです。以下に推奨される再試行ロジックを示します。
import time
import random
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def generate_image_with_retry(
prompt: str,
model: str = "gemini-3-pro-image-preview",
max_retries: int = 5,
initial_delay: int = 10
):
"""
带指数退避的图像生成函数
"""
for attempt in range(max_retries):
try:
response = client.images.generate(
model=model,
prompt=prompt,
timeout=120 # 增加超时时间
)
return response
except Exception as e:
error_msg = str(e)
# 503 错误: 指数退避重试
if "overloaded" in error_msg.lower() or "503" in error_msg:
if attempt < max_retries - 1:
delay = initial_delay * (2 ** attempt) + random.uniform(0, 5)
print(f"⚠️ 模型过载,{delay:.1f}秒后重试 (尝试 {attempt + 1}/{max_retries})")
time.sleep(delay)
continue
else:
raise Exception("❌ 达到最大重试次数,模型持续过载")
# 429 错误: 短暂等待重试
elif "429" in error_msg or "RESOURCE_EXHAUSTED" in error_msg:
print("⚠️ 速率限制,60秒后重试")
time.sleep(60)
continue
# 其他错误: 直接抛出
else:
raise e
raise Exception("❌ 所有重试均失败")
# 使用示例
result = generate_image_with_retry(
prompt="A futuristic city at sunset, cyberpunk style",
max_retries=5
)
商用レベルの完全なコードを表示
import time
import random
from typing import Optional, Dict
from openai import OpenAI
from datetime import datetime, timedelta
class GeminiImageClient:
"""
生产级 Gemini 图像生成客户端
支持重试、降级、监控
"""
def __init__(self, api_key: str, base_url: str = "https://vip.apiyi.com/v1"):
self.client = OpenAI(api_key=api_key, base_url=base_url)
self.error_log = []
self.success_count = 0
self.failure_count = 0
def generate_with_fallback(
self,
prompt: str,
primary_model: str = "gemini-3-pro-image-preview",
fallback_model: str = "gemini-2.5-flash-image",
max_retries: int = 3
) -> Dict:
"""
带降级策略的图像生成
"""
# 尝试主模型
try:
result = self._generate_with_retry(prompt, primary_model, max_retries)
self.success_count += 1
return {
"success": True,
"model_used": primary_model,
"data": result
}
except Exception as e:
print(f"⚠️ 主模型 {primary_model} 失败: {str(e)}")
# 自动降级到备用模型
try:
print(f"🔄 降级到备用模型 {fallback_model}")
result = self._generate_with_retry(prompt, fallback_model, max_retries)
self.success_count += 1
return {
"success": True,
"model_used": fallback_model,
"fallback": True,
"data": result
}
except Exception as fallback_error:
self.failure_count += 1
self.error_log.append({
"timestamp": datetime.now(),
"primary_error": str(e),
"fallback_error": str(fallback_error)
})
return {
"success": False,
"error": str(fallback_error)
}
def _generate_with_retry(self, prompt: str, model: str, max_retries: int):
"""内部重试逻辑"""
for attempt in range(max_retries):
try:
response = self.client.images.generate(
model=model,
prompt=prompt,
timeout=120
)
return response
except Exception as e:
if attempt < max_retries - 1:
delay = 10 * (2 ** attempt) + random.uniform(0, 5)
time.sleep(delay)
else:
raise e
def get_stats(self) -> Dict:
"""获取统计数据"""
total = self.success_count + self.failure_count
success_rate = (self.success_count / total * 100) if total > 0 else 0
return {
"total_requests": total,
"success_count": self.success_count,
"failure_count": self.failure_count,
"success_rate": f"{success_rate:.2f}%",
"recent_errors": self.error_log[-5:]
}
# 使用示例
client = GeminiImageClient(api_key="YOUR_API_KEY")
result = client.generate_with_fallback(
prompt="A magical forest with glowing mushrooms",
primary_model="gemini-3-pro-image-preview",
fallback_model="gemini-2.5-flash-image"
)
if result["success"]:
print(f"✅ 生成成功,使用模型: {result['model_used']}")
else:
print(f"❌ 生成失败: {result['error']}")
# 查看统计
print(client.get_stats())
技術アドバイス: 実際の運用環境では、APIYI(apiyi.com)プラットフォーム経由での呼び出しを推奨します。このプラットフォームは統合された API インターフェースを提供しており、Gemini 3 Pro を含む多様な画像生成モデルをサポートしています。Nano Banana Pro が過負荷の際には、Gemini 2.5 Flash や他の代替モデルへ迅速に切り替えることができ、ビジネスの継続性を確保できます。
方法 2: タイムアウト設定とリクエスト構成の最適化
Nano Banana Pro の通常のレスポンス時間は 20〜40 秒ですが、過負荷時には 60〜100 秒、あるいはそれ以上に達することがあります。デフォルトの 30 秒タイムアウト設定では、多くの誤判定を招く可能性があります。
推奨設定:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1",
timeout=120, # 增加全局超时到 120 秒
max_retries=3 # SDK 自动重试 3 次
)
# 或在单次请求中指定
response = client.images.generate(
model="gemini-3-pro-image-preview",
prompt="Your prompt here",
timeout=150 # 单次请求超时 150 秒
)
主要パラメータの説明:
timeout: 単一リクエストの最大待ち時間。120〜180 秒に設定することを推奨します。max_retries: SDK レベルでの自動再試行回数。2〜3 回を推奨します。keep_alive: 長時間のリクエストが切断されないよう、接続をアクティブに保ちます。
方法 3: ピーク時間帯を避ける
業務上、非同期処理が許容される場合は、時間的法則に基づいてタスクをスケジュールすることで、成功率を大幅に向上させることができます。
推奨されるスケジューリング戦略:
- 優先度の高いタスク: 北京時間の 03:00-08:00 または 14:00-17:00 に実行。
- バッチ生成タスク: タスクキューを使用して、オフピーク時に自動実行。
- リアルタイムタスク: 単一のモデルに依存せず、必ずフォールバック戦略を実装。
Python タスクスケジュールの例:
from datetime import datetime
def is_peak_hour() -> bool:
"""判断当前是否为高峰时段 (北京时间)"""
current_hour = datetime.now().hour
# 高峰时段: 0-2, 9-11, 20-23
peak_hours = list(range(0, 3)) + list(range(9, 12)) + list(range(20, 24))
return current_hour in peak_hours
def smart_generate(prompt: str):
"""智能生成: 高峰期自动降级"""
if is_peak_hour():
print("⚠️ 当前为高峰时段,使用备用模型")
model = "gemini-2.5-flash-image"
else:
model = "gemini-3-pro-image-preview"
return generate_image(prompt, model)
方法 4: モデルのフォールバック戦略を実装する
Google 公式は、過負荷に遭遇した際に Gemini 2.5 Flash への切り替えを推奨しています。以下は比較データです。
| 指標 | Gemini 3 Pro (Nano Banana Pro) | Gemini 2.5 Flash Image |
|---|---|---|
| 画像品質 | 最高 (9/10) | 優秀 (7.5/10) |
| 生成速度 | 20-40 秒 | 10-20 秒 |
| 安定性 | ピーク時 45% の失敗率 | ピーク時 <10% の失敗率 |
| 503 復旧時間 | 30-120 分 | 5-15 分 |
| API コスト | 比較的高い | 比較的低い |
ソリューションの提案: 品質を重視するシーン(マーケティングポスター、製品画像など)では Gemini 3 Pro を優先し、失敗した場合には 2.5 Flash へフォールバックします。高並列が求められるシーン(UGC コンテンツ、高速プロトタイプ)では、安定性を高めるために直接 2.5 Flash を使用します。APIYI(apiyi.com)プラットフォームを利用すれば、モデルの比較テストやワンクリックでの切り替えが可能になり、コストと品質の比較データも取得できます。
方法 5: モニタリングおよびアラートシステム
本番環境では、故障をタイムリーに発見し対応するために、完璧なモニタリングを実装する必要があります。
主要なモニタリング指標:
- 成功率: 過去 5 分 / 1 時間 / 24 時間の成功率。
- レスポンス時間: P50 / P95 / P99 のレスポンス時間。
- エラー分布: 503 / 429 / 500 などのエラーの割合。
- フォールバック発動回数: メインモデルの失敗によりフォールバックが発生した回数。
シンプルなモニタリングの実装例:
from collections import deque
from datetime import datetime
class APIMonitor:
"""API 调用监控器"""
def __init__(self, window_size: int = 100):
self.recent_calls = deque(maxlen=window_size)
self.error_counts = {"503": 0, "429": 0, "500": 0, "other": 0}
def log_call(self, success: bool, response_time: float, error_code: str = None):
"""记录 API 调用"""
self.recent_calls.append({
"timestamp": datetime.now(),
"success": success,
"response_time": response_time,
"error_code": error_code
})
if not success and error_code:
if error_code in self.error_counts:
self.error_counts[error_code] += 1
else:
self.error_counts["other"] += 1
def get_success_rate(self) -> float:
"""计算成功率"""
if not self.recent_calls:
return 0.0
success_count = sum(1 for call in self.recent_calls if call["success"])
return success_count / len(self.recent_calls) * 100
def should_alert(self) -> bool:
"""判断是否需要告警"""
success_rate = self.get_success_rate()
# 成功率低于 70% 触发告警
if success_rate < 70:
return True
# 503 错误超过 30% 触发告警
total_errors = sum(self.error_counts.values())
if total_errors > 0 and self.error_counts["503"] / total_errors > 0.3:
return True
return False
# 使用示例
monitor = APIMonitor(window_size=100)
# 每次调用后记录
start_time = time.time()
try:
result = client.images.generate(...)
response_time = time.time() - start_time
monitor.log_call(success=True, response_time=response_time)
except Exception as e:
response_time = time.time() - start_time
error_code = "503" if "overload" in str(e) else "other"
monitor.log_call(success=False, response_time=response_time, error_code=error_code)
# 定期检查告警
if monitor.should_alert():
print(f"🚨 告警: API 成功率降至 {monitor.get_success_rate():.2f}%")
2025年12月のクォータ調整
2025年12月7日、GoogleはGemini APIのクォータ(割当)制限を調整しました。これにより、多くの開発者が予期せぬ429エラーに直面しています。
現在のクォータ基準 (2026年1月):
| クォータ項目 | 無料版 (Free Tier) | 有料版 Tier 1 | 説明 |
|---|---|---|---|
| RPM (1分あたりのリクエスト数) | 5-15 (モデルによる) | 150-300 | Gemini 3 Proは制限がより厳格 |
| TPM (1分あたりのトークン数) | 32,000 | 4,000,000 | テキストモデルに適用 |
| RPD (1日あたりのリクエスト数) | 1,500 | 10,000+ | クォータプールを共有 |
| IPM (1分あたりの画像数) | 5-10 | 50-100 | 画像生成モデル専用 |
重要な注意事項:
- クォータ制限は、個々のAPIキーではなく、Google Cloudプロジェクト単位に基づいています。
- 同一プロジェクト内で複数のAPIキーを作成しても、クォータは増えません。
- いずれかの項目の制限を超えると、429エラーが発生します。
- トークンバケットアルゴリズムを使用して強制実行されるため、バーストトラフィック(突発的な負荷)は制限されます。
コスト最適化: 予算を重視するプロジェクトでは、APIYI(apiyi.com)プラットフォームを介してGemini APIを呼び出すことを検討してください。このプラットフォームは柔軟な従量課金方式を提供しており、Google Cloudのサブスクリプションを購入することなく、中小規模のチームや個人開発者が迅速なテストや小規模なデプロイを行うのに適しています。
よくある質問
Q1: 503 overloaded(オーバーロード)と 429 rate limit(レート制限)エラーをどう見分ければいいですか?
両者の違いは、根本的な原因と復旧時間にあります。
503 Overloaded:
- エラーメッセージ:
The model is overloaded. Please try again later. - HTTP ステータスコード: 503 Service Unavailable
- 根本原因: Google 側のコンピューティングリソース不足であり、ユーザーのクォータとは無関係です。
- 復旧時間: 30~120分 (Gemini 3 Pro)、5~15分 (Gemini 2.5 Flash)。
- 対応策: 指数バックオフによる再試行、予備モデルへの切り替え、ピーク時間帯を避ける。
429 Rate Limit:
- エラーメッセージ:
RESOURCE_EXHAUSTEDまたはRate limit exceeded - HTTP ステータスコード: 429 Too Many Requests
- 根本原因: API呼び出しがクォータ制限 (RPM/TPM/RPD/IPM) を超えています。
- 復旧時間: 1~5分 (クォータプールが自動的に回復)。
- 対応策: リクエスト頻度を下げる、有料版にアップグレードする、クォータの引き上げをリクエストする。
迅速な判断方法: Google AI Studio でクォータの使用状況を確認してください。上限に近い、または達している場合は 429、そうでなければ 503 です。
Q2: なぜ深夜 00:18(北京時間)に大規模な障害が発生するのですか?
2026年1月16日 00:18(北京時間、日本時間では 01:18)の大規模な障害は、米国西海岸時間の1月15日 08:18 PSTに対応しており、ちょうど米国の営業開始時間にあたります。
時間の傾向分析:
- 米国西海岸(シリコンバレー)の開発者が 08:00-10:00 PST に業務を開始(日本時間 01:00-03:00)。
- 欧州の開発者が 14:00-18:00 CET にピークを迎える(日本時間 22:00-02:00)。
- アジア圏の開発者が 09:00-11:00 および 20:00-23:00(日本時間)にピークを迎える。
これら3つの時間帯が重なることで、Nano Banana Pro API の負荷が容量を大幅に超え、大規模な503エラーが発生しやすくなります。
推奨事項: 業務が特定の地域に限定されない場合、バッチ処理などを日本時間の 04:00-09:00(米国の深夜 + 欧州の早朝)にスケジュールすると、グローバルの負荷が最も低いため安定します。
Q3: 本番環境ではどのモデルを選ぶべきですか?
ビジネスニーズに応じて、適切なモデル戦略を選択してください。
戦略1: 品質優先(マーケティング、商品画像など)
- メインモデル: Gemini 3 Pro Image Preview (Nano Banana Pro)
- 予備モデル: Gemini 2.5 Flash Image
- 実装: メインモデルが3回失敗した後、自動的に予備モデルへフォールバック。
- 期待される成功率: 92-95% (フォールバックを含む)。
戦略2: 安定性優先(UGC、高コンカレンシーなど)
- メインモデル: Gemini 2.5 Flash Image
- 予備モデル: その他の画像生成モデル (DALL-E 3, Stable Diffusion XL)
- 実装: 直接 2.5 Flash を使用し、障害発生時にサードパーティ製モデルに切り替え。
- 期待される成功率: 95-98%。
戦略3: コスト優先(テスト、プロトタイプなど)
- 無料版の Gemini 2.5 Flash を使用。
- 時折発生する 429 や 503 エラーを許容する。
- 複雑なフォールバックロジックは実装しない。
推奨プラン: APIYI(apiyi.com)プラットフォームを利用して、さまざまなモデルの効果とコストを迅速にテストしてください。このプラットフォームは複数の画像生成モデルを呼び出せる統合インターフェースを提供しているため、比較や切り替えが容易です。
まとめ
Gemini Nano Banana Pro API エラーに関する重要事項:
- 503 Overloaded はシステム全体の問題: あなたのコードの問題ではなく、Google 側の計算リソース不足が原因です。ピーク時には呼び出しの 45% が失敗する可能性があります。
- 明確な時間的傾向: 北京時間 00:00-02:00、09:00-11:00、20:00-23:00 はリスクの高い時間帯です。これらの時間を避けるか、フォールバック(機能制限)戦略を実装する必要があります。
- 耐障害性の実装が極めて重要: 「指数バックオフによるリトライ」「タイムアウト時間の延長 (120秒以上)」「モデルのダウングレード (2.5 Flash を予備として使用)」という 3 つの保護レイヤーを必ず実装してください。
- 監視とアラート: 本番環境では、成功率、レスポンス時間、エラー分布を必ず監視し、障害を迅速に発見して対応できるようにする必要があります。
- クォータ制限の理解: 429 エラーは個別の API クォータに関連し、503 エラーは Google 全体の負荷に関連します。この 2 つは対応策が異なります。
プレビュー段階のモデルとして、Nano Banana Pro の安定性の問題を短期間で根本的に解決することは困難です。画像生成のニーズを迅速に検証するには、APIYI (apiyi.com) の利用をお勧めします。このプラットフォームは無料枠とマルチモデル統合インターフェースを提供しており、Gemini 3 Pro、Gemini 2.5 Flash、DALL-E 3 などの主要な画像生成モデルをサポートしているため、ビジネスの継続性を確保できます。
📚 参考資料
⚠️ リンク形式の説明: すべての外部リンクは
資料名: domain.com形式を使用しています。コピーには便利ですが、SEO ウェイトの流出を防ぐため、クリックによるジャンプはできません。
-
Nano Banana Errors & Troubleshooting Guide: エラーに関する完全なリファレンスマニュアル
- リンク:
www.aifreeapi.com/en/posts/nano-banana-errors-troubleshooting-guide - 説明: 429、502、403、500 など、すべての Nano Banana Pro エラーコードに対する完全な解決策を網羅しています。
- リンク:
-
Google AI 開発者フォーラム: Gemini 3 Pro overloaded エラーに関する議論
- リンク:
discuss.ai.google.dev/t/gemini-3-pro-nano-banana-tier-1-4k-image-503-unavailable-error-the-model-is-overloaded/110232 - 説明: 503 エラーに関する開発者コミュニティでのリアルタイムな議論と経験の共有。
- リンク:
-
Gemini API Rate Limits 公式ドキュメント: クォータとレート制限の説明
- リンク:
ai.google.dev/gemini-api/docs/rate-limits - 説明: Google 公式の API クォータドキュメントで、RPM/TPM/RPD/IPM に関する詳細な説明が含まれています。
- リンク:
-
Gemini 3 Pro Image Preview Error Codes: エラーコード完全ガイド
- リンク:
www.aifreeapi.com/en/posts/gemini-3-pro-image-preview-error-codes - 説明: 2025-2026 年における Gemini 3 Pro のすべてのエラーコードの調査と解決方法。
- リンク:
著者: 技術チーム
技術交流: コメント欄で Gemini API の使用経験についてぜひ議論しましょう。さらなるトラブルシューティング資料については、APIYI (apiyi.com) 技術コミュニティをご覧ください。