Claude Opus 4.7は2026年4月、SWE-bench Verifiedで87.6%というスコアを記録し、コーディングモデルの頂点を塗り替えました。しかしそのわずか2週間後、xAIは価格が1/10であるGrok 4.3を投入し、「コーディングモデルは高価でなければならない」という常識に真っ向から挑みました。本記事では、開発者が最も気にしている2つの疑問にお答えします。Grok 4.3はプログラミングタスクにおいてClaude Opus 4.7の完全な代替となるのか? そして、もし完全な代替が難しい場合、Grok 4.3にはどのような差別化された強みがあるのか?
核心的価値: 本記事を読めば、自身のコーディング環境においてGrok 4.3とClaude Opus 4.7のどちらを選ぶべきか、あるいは両者をどう使い分けるべきかが明確になります。また、APIYIの中継サービスを利用して全体のコストを60%以上削減する方法も解説します。

Grok 4.3 vs Claude Opus 4.7 核心差异
「完全代替」が可能かどうかを判断するために、まずは両モデルのプログラミング関連の主要パラメータを比較します。
Grok 4.3 vs Claude Opus 4.7 パラメータ概要
| 比較項目 | Grok 4.3 | Claude Opus 4.7 | 勝者 |
|---|---|---|---|
| リリース日 | 2026-04-30 | 2026-04-16 | Claude (14日早い) |
| 入力価格 | $1.25 / 1M | $5.00 / 1M | Grok 4.3 |
| 出力価格 | $2.50 / 1M | $25.00 / 1M | Grok 4.3 |
| コンテキストウィンドウ | 1M tokens | 1M tokens | 引き分け |
| 最大出力 | 標準 | 128K tokens | Claude |
| 出力速度 | 207 tokens/秒 | ~78 tokens/秒 | Grok 4.3 |
| 推論モード | デフォルト有効 | xhigh / 適応型 | Claude (より詳細) |
| SWE-bench Verified | ~73% | 87.6% | Claude (+14.6pt) |
| SWE-bench Pro | 未公開 | 64.3% | Claude |
| CursorBench | 未公開 | 70% | Claude |
| Vending-Bench (エージェント) | 最高峰 | 中程度 | Grok 4.3 |
| プロンプトキャッシュ割引 | 75% | 90% | Claude |
| Batch API 割引 | 50% | 50% | 引き分け |
| 動画入力 | ✅ ネイティブ | ❌ 非対応 | Grok 4.3 |
| ドキュメント生成 PDF/XLSX/PPTX | ✅ ネイティブ | ❌ 後処理が必要 | Grok 4.3 |
| サーバーサイドツール | ✅ 内蔵 web/code | ❌ 自作が必要 | Grok 4.3 |
一言でまとめると
上の表を要約するとこうなります:Claude Opus 4.7は「精度が求められるコーディングタスク」において依然として最高峰であり、Grok 4.3は「コスト重視、長距離タスク、マルチモーダル」な開発シナリオにおいて最適な選択肢です。両者は代替関係というより、「精度 vs コスパ」の役割分担と言えます。
🎯 試用のアドバイス: 両モデルともAPIYI (apiyi.com) で利用可能です。base_url は
https://vip.apiyi.com/v1に統一されています。Grok 4.3はxAI公式サイトと同価格 ($1.25/$2.50)、Claude Opus 4.7はAnthropic公式サイトの価格をそのまま適用 ($5.00/$25.00) しており、追加料金なしでOpenAI SDK経由で呼び出せます。

Grok 4.3 vs Claude Opus 4.7 価格比較
価格はこの比較において最も差が大きい次元です。単価、トークナイザーの隠れたコスト、一般的なプロジェクトの月額費用という3つの側面から明確に見ていきましょう。
Grok 4.3 vs Claude Opus 4.7 標準価格
以下の表は、2026年5月時点の公式公開価格です。いずれも APIYI の API 中継サービスにおいて、公式サイトと同価格で提供されています。
| 料金項目 | Grok 4.3 | Claude Opus 4.7 | 価格倍率 |
|---|---|---|---|
| 入力トークン | $1.25 / 1M | $5.00 / 1M | Claude が 4.0 倍高い |
| 出力トークン | $2.50 / 1M | $25.00 / 1M | Claude が 10.0 倍高い |
| キャッシュ入力 | $0.31 / 1M | $0.50 / 1M | Claude が 1.6 倍高い |
| 3:1 混合価格 | ~$1.56 / 1M | ~$10.00 / 1M | Claude が 6.4 倍高い |
Claude Opus 4.7 のトークナイザーによる隠れたコスト
Claude Opus 4.7 はリリース時に新しいトークナイザーを採用しました。業界の実測によると、同じコードを入力しても Opus 4.6 と比較してトークン数が約 35% 増加します。つまり、公式単価が変わらなくても、実際の請求額は上昇するということです。
| コンテンツタイプ | Opus 4.6 トークン | Opus 4.7 トークン | 実際のコスト変化 |
|---|---|---|---|
| 英語のみのコード | 100k | 130k+ | +30% |
| 中国語混じりのコード | 100k | 135k+ | +35% |
| 大量の絵文字 / コメント含む | 100k | 140k+ | +40% |
この要素を価格比較に加えると、Claude Opus 4.7 の実際のプログラミングタスクのコストは、単価表上の 6.4 倍ではなく、Grok 4.3 と比較して 8〜10 倍 に跳ね上がります。
💡 コスト最適化のヒント: Claude Opus 4.7 で長いプロンプトを使用する場合は、プロンプトキャッシュ(Prompt Caching)の有効化を推奨します(最大 90% 削減可能)。これはトークナイザーの値上げを相殺するための重要な手段です。APIYI(apiyi.com)の中継サービスは Anthropic のネイティブキャッシュフィールドを完全にサポートしており、特別な追加設定は不要です。
Grok 4.3 vs Claude Opus 4.7 実際のコーディングプロジェクトの月額費用見積もり
以下は、実際の「中規模チーム向けコードアシスタント」業務の月額試算です。入力と出力の比率を 4:1(コーディングシーンでは入力が長くなるため)と想定し、キャッシュ割引は考慮していません。
| 業務規模 | 月間トークン数 | Grok 4.3 月額 | Claude Opus 4.7 月額 | 差額 |
|---|---|---|---|---|
| 個人開発者 | 50M | ~$70 | ~$700 (トークン増分込みで約 $945) | 13.5 倍 |
| 中規模チーム | 1,000M | ~$1,400 | ~$14,000 (実際は約 $19,000) | 13.5 倍 |
| 大規模企業 | 10,000M | ~$14,000 | ~$140,000 (実際は約 $189,000) | 13.5 倍 |
価格の差は企業規模になると「年間数百万円」レベルの予算項目へと拡大します。これが、2026 年に混合アーキテクチャがコーディング AI の主流となった理由です。
🎯 予算に関するアドバイス: 月間のコーディング AI 予算が $1500 未満の場合、基本的には Grok 4.3 を優先的に使用し、重要な場面でのみ Claude Opus 4.7 に切り替えることを推奨します。この運用方法は APIYI(apiyi.com)のインフラ上ではエンジニアリングコストがほぼゼロで、アプリケーション層でタスクラベルに応じてモデルフィールドを切り替えるだけで実現できます。
Grok 4.3 vs Claude Opus 4.7 プログラミング能力比較
価格のほかに、代替可能かどうかを決定づけるのはプログラミング能力です。公開ベンチマーク、実際のエンジニアリングシナリオ、長距離タスクの3つの視点から見ていきましょう。
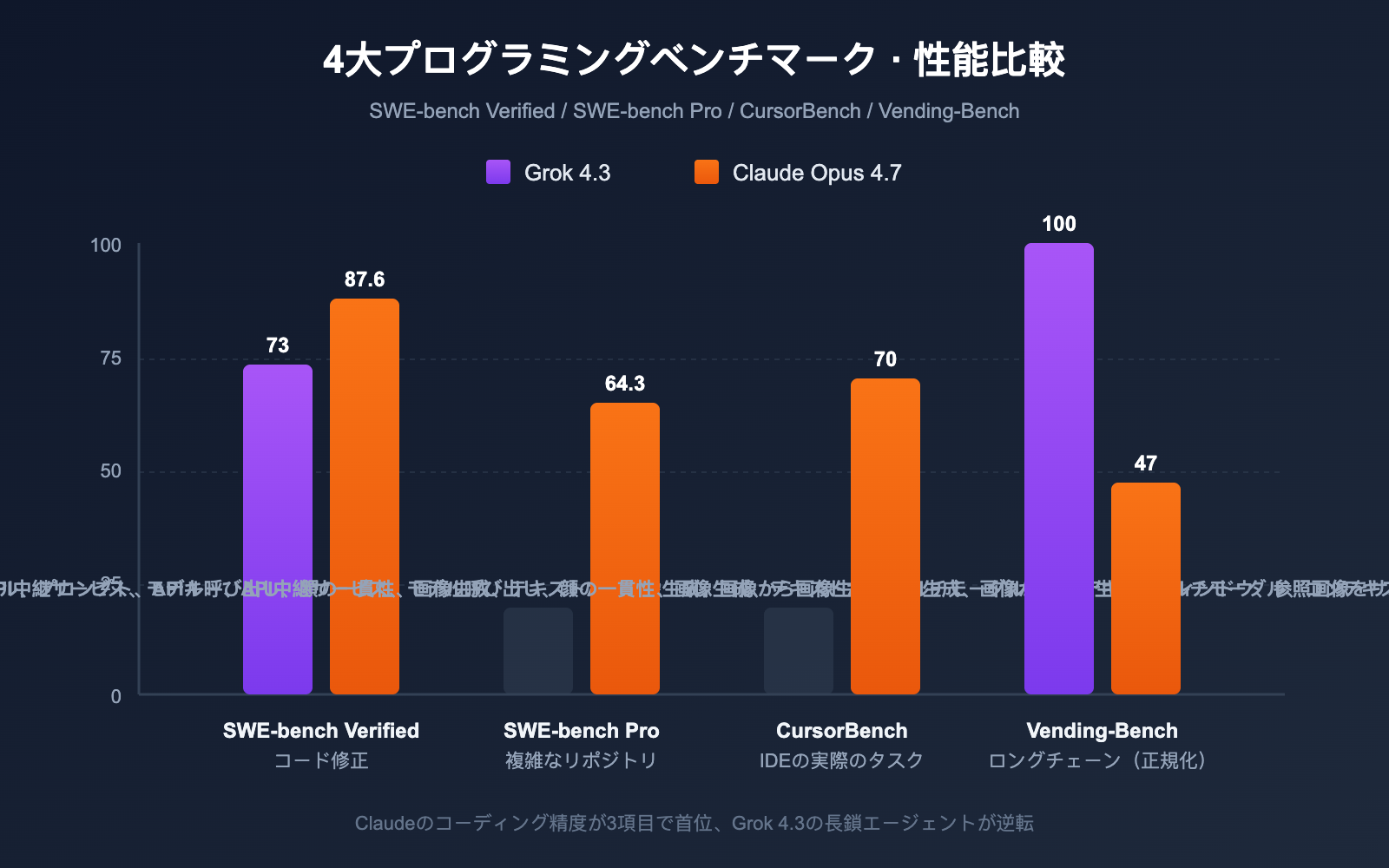
Grok 4.3 vs Claude Opus 4.7 プログラミングベンチマーク対照表
下の表は、OpenAI、xAI、Anthropic が公式に発表しているデータおよび、サードパーティ(Vellum、Vals.ai、Artificial Analysis)による重要なプログラミングデータをまとめたものです。
| プログラミングベンチマーク | Grok 4.3 | Claude Opus 4.7 | 差分 | タスクタイプ |
|---|---|---|---|---|
| SWE-bench Verified | ~73% | 87.6% | Claude +14.6pt | 実コード修正 |
| SWE-bench Pro | 未公開 | 64.3% | Claude が大きくリード | 複雑なリポジトリのバグ |
| CursorBench | 未公開 | 70% | Claude が大きくリード | IDE での実際のタスク |
| Aider Polyglot | 中程度 | 強力 | Claude がリード | 多言語コード移行 |
| HumanEval+ | 優秀 | 優秀 | 同等 | 関数レベルの生成 |
| 実際の生産タスク | 良好 | Opus 4.6 の3倍 | Claude がリード | レガシーコード修正 |
| Vending-Bench (純利益) | トップ | 47.1 (Grok 4.20 データが Opus 4.7 に近似) | Grok 4.3 がリード | 長いチェインのインテリジェントエージェント |
| 出力速度 (tps) | 207 | ~78 | Grok 4.3 +166% | リアルタイム応答 |
まとめ:「精度が重視されるコーディングタスク」では Claude Opus 4.7 が 14〜17 ポイントの差で全体的にリードしています。「長い連鎖を持つエージェントタスク」では Grok 4.3 が Claude を上回り、「リアルタイム応答速度」では Grok 4.3 が 2.6 倍高速です。
Grok 4.3 vs Claude Opus 4.7 コーディングタスクの粒度別評価
ベンチマークを実際の業務タスクに置き換えて星取り評価を行うと、能力分布がより直感的に理解できます。
| コーディングタスク | Grok 4.3 | Claude Opus 4.7 | 代替可能か? |
|---|---|---|---|
| 関数レベルのコード生成 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ 完全代替可能 |
| 単体テスト生成 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ 完全代替可能 |
| コードコメント / ドキュメント | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ 完全代替可能 |
| 簡単なバグ修正 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ 代替可能 (精度差は小さい) |
| コードスタイルのリファクタリング | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ 代替可能 |
| ファイルをまたぐリファクタリング | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⚠️ 代替非推奨 |
| 複雑なリポジトリのバグ修正 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⚠️ 代替非推奨 |
| 大規模システム設計 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ❌ Claude が明確に優位 |
| 法律 / 医療関連のコンプライアンスコード | ⭐⭐ | ⭐⭐⭐⭐⭐ | ❌ Claude が必須 |
| 長いチェインを持つエージェントタスク | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ✅ Grok 4.3 がリード |
🎯 代替の判断基準: 「関数レベル + 単体テスト + コメント + 簡単なバグ」の 4 つのタスクでは、Grok 4.3 は Claude Opus 4.7 を完全に代替可能であり、コストはわずか 1/10 です。「ファイルをまたぐ変更 + 複雑なリファクタリング + クリティカルなバグ修正」の 3 つについては、Claude Opus 4.7 の継続利用を推奨します。混合アーキテクチャこそが最適解です。APIYI(apiyi.com)の中継サービスでタスクラベルを使用した自動ルーティングを行うことを強くお勧めします。
Grok 4.3 vs Claude Opus 4.7 実際のコーディングタスク実測
比較をより実用的なものにするため、一般的なコーディングタスクを 5 つ設計し、APIYI の同一ベース URL 下で両モデルをテストし、結果を記録しました。
| 実測タスク | Grok 4.3 のパフォーマンス | Claude Opus 4.7 のパフォーマンス | 代替結論 |
|---|---|---|---|
| React コンポーネントの作成 | 8秒、一発で成功 | 18秒、一発で成功 | ✅ 代替可 (Grok が 2 倍高速) |
| NullPointer バグの修正 | 6秒、正しく特定 | 14秒、正しく特定 + 3 つの解決案提示 | ⚠️ 部分的に代替可 |
| 5 ファイルにわたる循環依存のリファクタリング | 25秒、2 回再試行 | 40秒、一発で成功 | ❌ Claude を推奨 |
| Python 単体テスト生成 (カバレッジ) | 12秒、82% カバー | 22秒、95% カバー | ✅ 代替可 (許容範囲の差) |
| 長いチェインの Agent (10 ステップの計画) | 50秒、完全に実行 | 90秒、一部で停止 | ✅ Grok 4.3 がリード |
ご覧の通り、単純なタスクでは Grok 4.3 は速度が速いだけでなく、品質も Claude に肉薄しています。複雑なファイルをまたぐタスクでは Claude が勝利し、長距離エージェントタスクでは Grok 4.3 が勝利するという結果になりました。
Claude Opus 4.7 がプログラミングで優位に立つ技術的理由
Claude Opus 4.7 がなぜ SWE-bench で 14 ポイントもリードしているのかを理解することは、どのタスクにおいてその優位性が「構造的」であり、どれが「わずかな差」であるかを判断する助けになります。
| 技術次元 | Claude Opus 4.7 の取り組み | コーディングへの影響 |
|---|---|---|
| xhigh 推論モード | 困難な問題に対して内部推論トークンを大幅に割り当て | 複雑な多段階論理推論の品質がより安定 |
| 適応型 Thinking | 「長く考える必要があるか、短く考えるべきか」を自動判断 | 単純タスクで推論トークンを無駄にしない |
| 1M コンテキスト + 128K 出力 | 前世代の 200K から向上 | ファイル全体、あるいは小規模プロジェクト全体を一括出力可能 |
| 新しいトークナイザー | コードをより細かい粒度で分割 | コード理解がより正確に(ただしトークン数は増加) |
| 実際の生産タスクによる学習 | Rakuten でのベータテストによると 4.6 より 3 倍多くの生産タスクを解決 | 「ベンチマーク」よりも「実際のコード」に対する能力が向上 |
これらの技術的投資により、Claude Opus 4.7 の優位性は「長い連鎖の精密な推論 + 大規模なコンテキスト + 大容量の出力」が必要なタスクにおいて構造的なものとなっており、Grok 4.3 が短期間で追い抜くのは困難です。しかし、これらの優位性は「短いタスク、補完、単体テスト」ではほとんど発揮されません。ここが Grok 4.3 が代替できる領域なのです。
Grok 4.3 の差別化優位性の詳細解説
SWE-bench の結果だけを見れば、Grok 4.3 は Claude Opus 4.7 に及ばないように見えるかもしれません。しかし、実際の開発現場において、Grok 4.3 には Claude には全くない能力がいくつかあり、これこそが真の差別化要因(護岸壕)となっています。
Grok 4.3 の価格と速度の優位性
第一に、価格が10倍安いことです。多くの日常的なコーディングタスクにおいて、精度の差は「90% vs 95%」程度ですが、コストの差は「$1 vs $10」というレベルです。頻度の高いシンプルなタスクを Grok 4.3 に任せることで、チームのAIツール予算を実質10倍活用できるようになります。
第二に、出力速度が2.6倍速いことです。207 tps 対 78 tps という差は、「ストリーミング形式のコード補完」「IDEのインライン提案」「リアルタイムのペアプログラミング」といった遅延が重要なシナリオにおいて、体験を劇的に変えます。Claude Opus 4.7 の 78 tps は「人間が考える速度についていける」レベルですが、Grok 4.3 の 207 tps は「人間の思考の2倍速い」という次元に達しています。
Grok 4.3 のビデオ入力能力
これは Claude Opus 4.7 には全くない能力です。Grok 4.3 はビデオ入力をネイティブでサポートしており、典型的な活用シーンは以下の通りです。
| シーン | Grok 4.3 の活用方法 | Claude Opus 4.7 の代替案 |
|---|---|---|
| 画面録画からコード生成 | ビデオファイルを直接アップロード | OCR処理 + 複数枚のスクリーンショットが必要 |
| バグ再現動画 → 修正案 | ワンリクエストで完結 | 手動でコマ送りして状況説明が必要 |
| 学習ビデオ → コードチュートリアル | フレームを抽出して直接分析 | 実現不可能 |
| UIデザインアニメーション → フロントエンドコード | ビデオを入力 | 実現不可能 |
QAチームがバグ再現動画を提出したり、デザイナーがUIアニメーションを共有したり、あるいはYouTubeのチュートリアルからコードを逆コンパイルする必要がある場合、Grok 4.3 は現在唯一の現実的かつコストパフォーマンスに優れたソリューションです。
Grok 4.3 のドキュメント生成能力
Grok 4.3 はチャット内で直接 PDF/XLSX/PPTX ファイルを生成できます。コーディングシーンにおいては、以下のような活用が可能です。
# Grok 4.3 で1行呼び出しによりインターフェースドキュメント(PDF)を生成
from openai import OpenAI
client = OpenAI(
api_key="あなたの APIYI APIキー",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="grok-4.3",
messages=[{
"role": "user",
"content": "この FastAPI ルートのために OpenAPI 形式のドキュメント PDF を生成して: ..."
}],
extra_body={"output_format": "pdf"}
)
# レスポンスにダウンロード可能なファイルURLが含まれる
print(response.choices[0].message.attachments[0].url)
Claude Opus 4.7 で同じことを行うには、「Claude → Markdown → Pandoc → PDF」という3段階の工程が必要です。Grok 4.3 なら一発で完結します。
Grok 4.3 の長期的なエージェント優位性
Vending-Bench は「自動販売機の7日間の運営」をシミュレートする長期タスクのベンチマークですが、Grok 4.3 の純利益は Claude Opus 4.7 を大きく上回っています。これは、「継続的な意思決定、ツールの呼び出し、中間状態の保持」が必要なエージェントタスクにおいて、Grok 4.3 が実際にはより強力であることを意味しています。
| 長期タスクのシーン | Grok 4.3 の優位性 |
|---|---|
| 自動化運用(自己修復機能) | 長期的な決定が安定しており、SREエージェントに適している |
| データ分析パイプライン | 多段階のツール呼び出し + 結果の集約 |
| 自動 PR レビュー + マージ | 長いプロセスを単独で完結可能 |
| コンプライアンススキャン + 自動修正 | 大規模リポジトリのバッチ処理 |
Grok 4.3 の 16-Agent Heavy モードによるコーディング応用
Grok 4.3 は SuperGrok Heavy ($300/月) サブスクリプションで 16-Agent 並列スケジューリングシステムを提供しており、コーディングタスクにおいて以下のような効果を発揮します。
| コーディングタスク | シングルエージェントモード | 16-Agent Heavy モード |
|---|---|---|
| 大規模リポジトリ分析 | 直列で30分 | 並列で3–5分 |
| 全量 PR レビュー | 1つずつ確認 | 16個のPRを同時レビュー |
| 単体テストの一括生成 | 直列呼び出し | 16ファイルを並列生成 |
| 多言語コード移行 | シングルスレッド | 多モジュール並列処理 |
16-Agent モードはサブスクリプション限定であり、API 標準インターフェースから直接呼び出すことはできませんが、アプリケーション層で Grok 4.3 を使って独自のマルチエージェントオーケストレーションを構築すれば、ネイティブの Heavy モードに近い効果が得られます。Grok 4.3 の 207 tps という出力を考慮すると、大規模な自動化コーディングシーンでは、実質的なスループットは Claude Opus 4.7 を上回ります。
Grok 4.3 のサーバーサイドツール優位性
Grok 4.3 には3種類のサーバーサイドツールが内蔵されており、tools フィールドを宣言するだけで使用可能です。Claude Opus 4.7 ではこれらすべてをアプリケーション層で自作する必要があります。
| 内蔵ツール | Grok 4.3 の価格 | Claude Opus 4.7 の代替手段 |
|---|---|---|
| Web 検索 | $5 / 1k回 | Tavily / SerpAPI への接続が必要 |
| コード実行(サンドボックス) | $5 / 1k回 | 自前で Docker サンドボックス構築が必要 |
| X (Twitter) 検索 | $5 / 1k回 | 代替手段なし |
Web検索とコード実行が必要なコーディングエージェントにとって、Grok 4.3 は1つの接続で完了するのに対し、Claude Opus 4.7 では3つのサードパーティサービスを組み合わせる必要があり、エンジニアリングの複雑さが全く異なります。
💡 サーバーサイドツール利用の推奨: Web検索を行うコーディングエージェントには、直接 Grok 4.3 を選択することをお勧めします。接続コストが最も低いためです。すでに Claude Opus 4.7 + サードパーティ検索を利用しているプロジェクトであれば、Claude は難易度の高いタスク用に残し、APIYI (apiyi.com) を通じて Grok 4.3 を並行接続し、Web検索が必要なタスクを分担させるのが効率的です。
Grok 4.3 で Claude Opus 4.7 を代替できるか?:意思決定マトリクス
ここまでのすべての項目を、実行可能な意思決定マトリクスにまとめました。
タスクタイプ別での選択
| あなたの主要タスク | 推奨ソリューション | 理由 |
|---|---|---|
| IDE コード補完 / インライン提案 | Grok 4.3 | 速度2.6倍 + 価格1/10 |
| 単体テスト自動生成 | Grok 4.3 | カバレッジ80%以上で十分 |
| コードコメント / ドキュメント生成 | Grok 4.3 | シンプルなタスク、品質は同等 |
| Code Review (PR単位) | Grok 4.3 | 安価で全量チェック可能 |
| 簡単なバグ修正 | Grok 4.3 | 精度差はわずか |
| 大規模なリファクタリング | Claude Opus 4.7 | SWE-bench Pro 64.3% が最高峰 |
| 重要機能のバグ修正 | Claude Opus 4.7 | 修正ミスによる手戻りコストの方が高い |
| ファイル横断 / 大規模リポジトリ | Claude Opus 4.7 | 長文脈の精度が安定 |
| 法律 / 医療コンプライアンスコード | Claude Opus 4.7 | 安全性 / 準拠要件が厳しい |
| 自動化運用エージェント | Grok 4.3 | 長期タスクで逆転優位性あり |
| ビデオ駆動開発 | Grok 4.3 | Claude に代替なし |
| Web検索 + サンドボックス実行 | Grok 4.3 | ツール内蔵済み |
チーム予算別での選択
| 月間コーディングAI予算 | 推奨構成 | 重要な調整 |
|---|---|---|
| < $200 | Grok 4.3 全量活用 | クリティカルなバグ修正のみ Claude |
| $200 – $1500 | 80% Grok 4.3 + 20% Claude | ファイル横断リファクタリングは Claude へ |
| $1500 – $10k | 50% Grok 4.3 + 30% Claude + 20% Grok 4 Fast | 3段階の階層化 |
| > $10k | 自動ルーティング + Batch + Cache | 混合アーキテクチャの必須化 |
精度許容度別での選択
| タスクの精度許容度 | 推奨選択肢 |
|---|---|
| 90% の精度で十分 | Grok 4.3 (タスクの90%をカバー) |
| 95% の精度が必要 | Claude Opus 4.7 + プロンプトキャッシング |
| 99% の精度が必須 | Claude Opus 4.7 + xhigh モード + 人手レビュー |
🎯 混合アーキテクチャの提案: APIYI (apiyi.com) プラットフォームでは、Grok 4.3 と Claude Opus 4.7 が同じ
base_urlと APIキーを共有しています。アプリケーション層でタスクラベルやトークン長に応じてmodelフィールドを切り替えるだけで済みます。この混合アーキテクチャへのエンジニアリング改修コストはほぼゼロですが、予算を 60~80% 削減できる可能性があります。
Grok 4.3 と Claude Opus 4.7 の接続とコード例
これら2つのモデルは、APIYI API中継サービス上でOpenAI SDKと完全に互換性があり、移行コストをほぼゼロに抑えられます。
Grok 4.3 と Claude Opus 4.7 の統一呼び出し
# 同じ base_url + APIキーを使用し、modelフィールドを切り替えるだけで両方のモデルを呼び出せます
from openai import OpenAI
client = OpenAI(
api_key="あなたの APIYI APIキー",
base_url="https://vip.apiyi.com/v1"
)
# Grok 4.3 を呼び出し (高コストパフォーマンス)
grok_resp = client.chat.completions.create(
model="grok-4.3",
messages=[{"role": "user", "content": "この関数のユニットテストを生成してください"}]
)
# Claude Opus 4.7 を呼び出し (高精度)
claude_resp = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "これら5つのファイルの循環参照をリファクタリングしてください"}]
)
print("Grok 4.3:", grok_resp.choices[0].message.content)
print("Claude Opus 4.7:", claude_resp.choices[0].message.content)
コーディングタスクにおけるインテリジェントルーティングの完全なコード
タスクタイプに基づいて自動ルーティングを行うPythonコード全体を表示
from openai import OpenAI
from typing import Literal
import re
client = OpenAI(
api_key="あなたの APIYI APIキー",
base_url="https://vip.apiyi.com/v1"
)
# コーディングタスクの分類ルール
SIMPLE_KEYWORDS = ["コメント", "comment", "docstring", "リネーム", "rename", "フォーマット"]
TEST_KEYWORDS = ["単体テスト", "unit test", "テストケース", "pytest"]
COMPLEX_KEYWORDS = ["refactor", "リファクタリング", "ファイルまたぎ", "循環参照", "移行"]
CRITICAL_KEYWORDS = ["致命的なバグ", "critical", "production fix", "コンプライアンス"]
TaskType = Literal["simple", "test", "complex", "critical"]
def classify_task(prompt: str) -> TaskType:
"""プロンプトのキーワードに基づいてタスクを分類"""
p = prompt.lower()
if any(k.lower() in p for k in CRITICAL_KEYWORDS):
return "critical"
if any(k.lower() in p for k in COMPLEX_KEYWORDS):
return "complex"
if any(k.lower() in p for k in TEST_KEYWORDS):
return "test"
return "simple"
def route_model(task_type: TaskType, prompt_tokens: int) -> str:
"""タスクタイプに基づいてモデルを選択"""
if task_type in ("critical", "complex") or prompt_tokens > 50000:
return "claude-opus-4-7"
return "grok-4.3"
def smart_code_call(prompt: str) -> dict:
"""コーディングシーンでのインテリジェントルーティング呼び出し"""
task_type = classify_task(prompt)
prompt_tokens = len(prompt) // 3 # 簡易的な見積もり
model = route_model(task_type, prompt_tokens)
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "あなたはベテランのフルスタックエンジニアです"},
{"role": "user", "content": prompt}
],
max_tokens=4096
)
return {
"model": model,
"task_type": task_type,
"content": response.choices[0].message.content,
"tokens": response.usage.total_tokens
}
if __name__ == "__main__":
print(smart_code_call("このadd関数にdocstringを追加して"))
print(smart_code_call("pytestの単体テストを5つ書いて"))
print(smart_code_call("これら3つのファイルの循環参照をリファクタリングして"))
print(smart_code_call("本番環境の致命的なバグです、至急修正してください"))
Grok 4.3 と Claude Opus 4.7 呼び出しの注意点
| 注意事項 | Grok 4.3 | Claude Opus 4.7 |
|---|---|---|
| モデル名 | grok-4.3 |
claude-opus-4-7 |
| 推論設定 | デフォルトで有効 | extra_body={"thinking": {"type": "enabled"}} |
| プロンプトキャッシュ | 自動 (75%割引) | cache_control を明示的に宣言 (90%割引) |
| Batch API | 50%割引 | 50%割引 |
| 最大出力 | 標準 | 128K (要 max_tokens 明示) |
| 動画入力 | video_url フィールド |
❌ 未対応 |
| ドキュメント出力 | extra_body={"output_format": ...} |
❌ 後処理が必要 |
| サーバーサイドWeb検索 | tools=[{"type": "web_search"}] |
❌ サードパーティが必要 |
| Function Calling | ✅ 対応 | ✅ 対応 |
🎯 導入アドバイス: まずは APIYI apiyi.com でテスト用のAPIキーを取得し、最小限のフローを実行することをお勧めします。Grok 4.3 と Claude Opus 4.7 は同じAPIキーを共有しています。まずはそれぞれ100件の実際の業務データでA/Bテストを行い、その後に最終的な選定を行ってください。
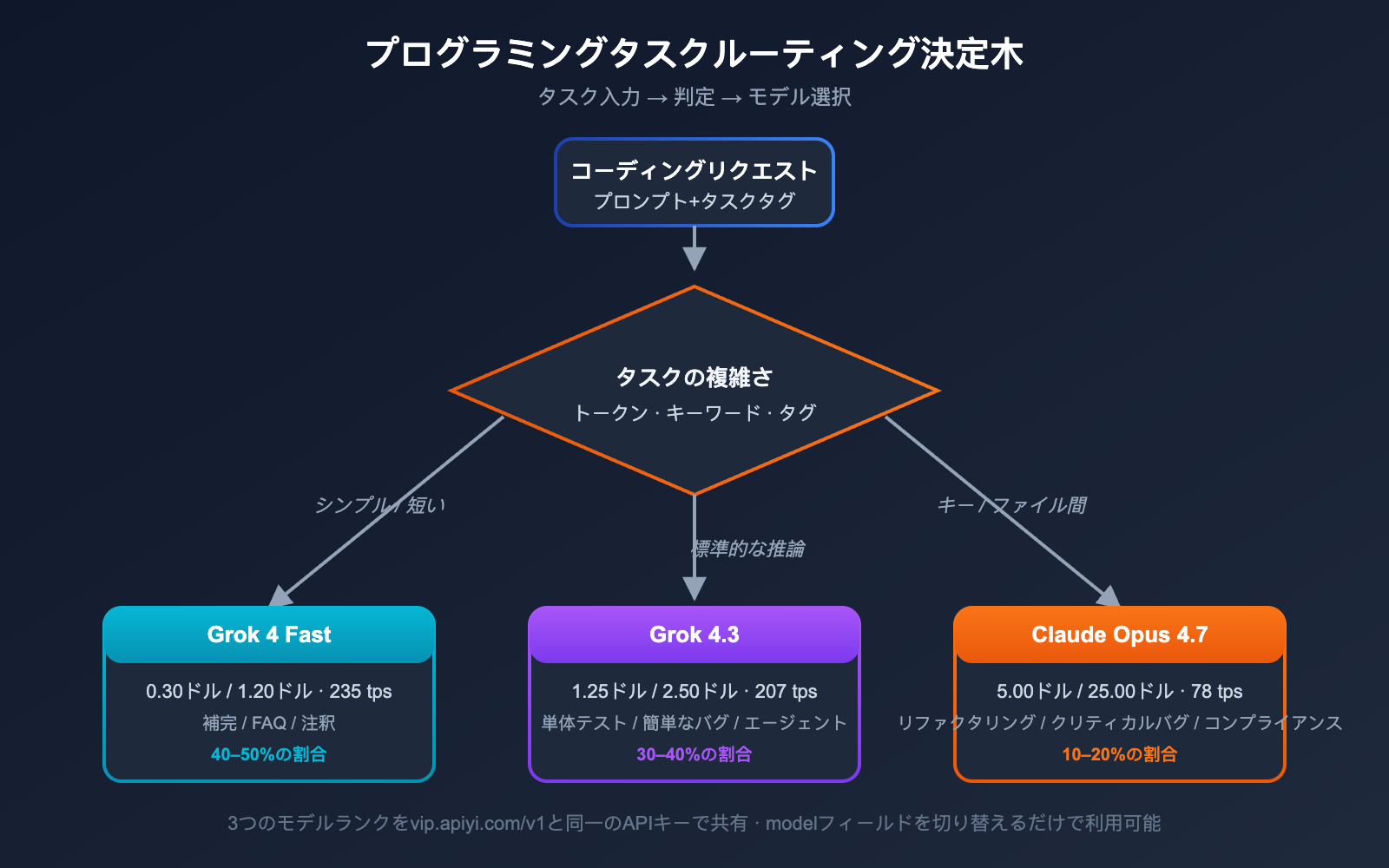
Grok 4.3 vs Claude Opus 4.7 プログラミングにおける推奨シナリオ
Grok 4.3 をメインに据えるべき6つのシナリオ
もしあなたの業務が以下のいずれかに該当する場合、Grok 4.3 がより優れた選択肢となります。
- シナリオ 1: 個人開発者 / 小規模プロジェクト: 月間予算が 300ドル未満の場合、Grok 4.3 ならトークン消費を10分の1に抑えられます。
- シナリオ 2: 高頻度な単純コーディング: IDEのコード補完、ユニットテストの生成、コメント作成、コードフォーマットなど。
- シナリオ 3: 長い工程を要するAIエージェント: 自動運用保守、PRレビューエージェント、コンプライアンスチェックロボットなど。
- シナリオ 4: ビデオ駆動型開発: バグ再現ビデオから修正案を生成、UIアニメーションからフロントエンドコードを生成。
- シナリオ 5: コーディングエージェント + ネット検索: サーバーサイドの
web_searchやcode_executionツールが内蔵されている場合。 - シナリオ 6: リアルタイム対話: 207 tps(1秒あたりのトークン数)の高速出力で、ペアプログラミングやストリーミング補完に最適。
Claude Opus 4.7 をメインに据えるべき6つのシナリオ
もしあなたの業務が以下のいずれかに該当する場合、Claude Opus 4.7 の高い精度に対する投資価値があります。
- シナリオ 1: 大規模なコードのリファクタリング: SWE-bench Pro で 64.3% という業界最高水準のスコア。
- シナリオ 2: クリティカルなバグ修正: ミスが許されない場面では、コストよりも精度が重要です。
- シナリオ 3: ファイル横断 / 大規模リポジトリ解析: 長いコンテキストと高精度が同時に求められる場合。
- シナリオ 4: コンプライアンス / セキュリティ敏感なコード: 法律、医療、金融などの分野。
- シナリオ 5: 複雑なシステム設計: アーキテクチャの推論やAPI設計。
- シナリオ 6: すでに Claude Code ワークフローを導入済み: チームが Claude Code CLI に習熟しており、移行コストが価格差を上回る場合。
ハイブリッドアーキテクチャの推奨比率
中規模以上の開発チームには、以下のハイブリッドな組み合わせを推奨します。
| タスクタイプ | ルーティングモデル | 推奨比率 |
|---|---|---|
| 単純な補完 / FAQ | Grok 4 Fast | 40–50% |
| 標準的なコーディング | Grok 4.3 | 30–40% |
| 複雑なリファクタリング / クリティカルバグ | Claude Opus 4.7 | 10–20% |
| 極めて複雑なタスク (xhigh) | Claude Opus 4.7 + thinking | < 5% |
この階層化により、コーディングAI全体のコストを「全て Claude Opus 4.7 で行う場合」と比較して 15–25% まで圧縮でき、かつ重要タスクの品質もほぼ損なわれません。
開発チームにおける混合アーキテクチャのコスト比較
以下の表は、30名規模のフロントエンド/バックエンド混合チームが、2026年5月にアーキテクチャを移行する前後のコスト比較です。業務内容は「IDEコーディング支援 + PRレビューエージェント + 自動テスト生成」です。
| 項目 | 全量 Claude Opus 4.7 | 混合アーキテクチャ (Grok 4.3主 + Claude重要) |
|---|---|---|
| 月間呼び出し量 | 1.2B tokens | 1.2B tokens |
| Claude Opus 4.7 割合 | 100% | 12% |
| Grok 4.3 割合 | 0% | 70% |
| Grok 4 Fast 割合 | 0% | 18% |
| 月額請求額 (トークナイザー値上げ35%込み) | ~$23,000 | ~$3,800 |
| コスト削減率 | — | 83% |
| 重要タスクの品質 (SWE-bench Pro級) | 100% 基線 | ~99% (引き続きClaude) |
| 単純タスクの体験 | 中程度 (78 tps) | 優秀 (207 tps) |
| エンジニアリング工数 | — | 16 人時 |
混合アーキテクチャはコストを従来の17%まで削減しつつ、重要タスクの品質は維持し、単純タスクの応答速度は(Grok 4.3 のおかげで)2.6倍向上しました。これは現在、中規模以上の開発チームが取り組むべき最も有益なアーキテクチャ刷新です。
💡 実装アドバイス: IDEプラグイン層でタスクの難易度判定を行い、単純な補完は自動的に Grok 4.3 に、複雑なファイル横断タスクは Claude Opus 4.7 にルーティングすることをお勧めします。APIYI (apiyi.com) プラットフォーム上では、両モデルが同一の認証とクォータ管理を共有できるため、エンジニアリングの実装負荷は非常に低く抑えられます。
Grok 4.3 vs Claude Opus 4.7 よくある質問 (FAQ)
Q1: Grok 4.3 は本当に Claude Opus 4.7 の代わりになりますか?
部分的にはイエスですが、そうでない部分もあります。「関数レベルの生成、単体テスト、コメント、単純なバグ修正、長距離エージェント」という5つのタスクにおいて、Grok 4.3 の精度と Claude Opus 4.7 の差は5%未満であり、価格が10分の1であることを考えれば十分に代用可能です。一方で、「ファイル横断のリファクタリング、複雑なリポジトリのバグ、重要な機能修正、コンプライアンスに関わるコード」の4つについては、Claude Opus 4.7 の SWE-bench Pro での 64.3% というスコアが依然として最高峰であり、14%以上の差があるため代用は推奨しません。APIYI (apiyi.com) を経由してタスクタイプに応じてモデルを自動ルーティングするのが最も確実です。
Q2: Grok 4.3 のプログラミングにおける差別化された強みは何ですか?
以下の6つの強みがあります:(1) 価格が10倍安い;(2) 出力速度が2.6倍速い (207 vs 78 tps) ため、IDEでのストリーミング体験が向上;(3) ビデオ入力に標準対応;(4) ドキュメントのPDF/XLSX/PPTX生成が容易;(5) Vending-Benchのような長距離エージェントタスクでClaudeを凌駕;(6) サーバーサイドツール(web_search/code_execution)が組み込まれているため、開発の手間が60%削減。このうち2つ以上当てはまるプロジェクトなら、Grok 4.3 は真剣に検討すべき選択肢です。
Q3: SWE-bench Verified における Claude Opus 4.7 の 87.6% は、実際のプロジェクトでも体感できますか?
一部は体感できます。SWE-bench Verified は「実際のオープンソースリポジトリでのバグ修正」を評価しており、Claude Opus 4.7 の長いコンテキストとファイル横断のコード理解力が活きるタスクです。しかし、日常的なコーディング(単体テスト、コメント、補完、ドキュメント)は SWE-bench の範囲外であり、この領域では Grok 4.3 との差はほとんどありません。87.6% 対 73% という差は「複雑なタスクにおける品質の差」と捉えるべきです。
Q4: Claude Opus 4.7 の新しいトークナイザーで請求額が 35% 増えるのは本当ですか?
はい、しかし解決策はあります。Opus 4.7 の新しいトークナイザーは、日英混合のコードにおいてトークン消費量が平均30–40%増加します。対策は3つです:(1) プロンプトキャッシングの有効化(最大90%削減);(2) Batch API の利用(さらに50%削減);(3) 単純なタスクを Grok 4.3 にルーティングすること。これらを組み合わせれば値上げの影響を完全に相殺できます。APIYI (apiyi.com) 上でキャッシングや Batch を設定することをお勧めします。
Q5: コンテキストウィンドウが 200k トークンを超えるタスクではどちらを使うべきですか?
精度で選んでください。Claude Opus 4.7 は長コンテキストの精度で依然としてリードしており、「超大規模リポジトリの一括分析」や「全量コード監査」に向いています。Grok 4.3 は長コンテキストの「要約」タスクで優秀で、価格はClaudeの1/10です。「800k トークンから特定の3つのバグをピンポイントで見つける」なら Claude を、「800k トークン全体を要約して重要な問いを抽出する」なら Grok 4.3 が十分です。
Q6: Cursor / Cline / Continue などのIDEツールではどちらのモデルが良いですか?
混合戦略が最適です。これらのツールの核は「IDEインライン補完 + 単純なリファクタリング」であり、Grok 4.3 の速度(207 tps)とコスト優位性が体験を大幅に高めます。ただし、「Refactor across files(ファイル横断リファクタリング)」や「Fix complex bug(複雑なバグ修正)」を実行する際は Claude Opus 4.7 に切り替えるのが安定です。APIYI (apiyi.com) を通じて両モデルを同一APIキーで設定し、操作に応じて自動ルーティングさせるのが現時点での最適解です。
Q7: APIYI 上での2つのモデルの課金方法は同じですか?
全く同じで、どちらもトークン使用量ベースの課金です。Grok 4.3 は xAI 公式価格をそのまま適用 ($1.25 / $2.50)、Claude Opus 4.7 は Anthropic 公式価格を適用 ($5.00 / $25.00) します。Anthropic のプロンプトキャッシング(90%オフ)や Batch API(50%オフ)も APIYI でフルサポートしています。同一のAPIキー、同一の base_url (https://vip.apiyi.com/v1) で利用でき、一つのアカウント残高から引き落とされるため管理も容易です。
Q8: 現在 Claude Opus 4.7 を全量使用していますが、混合アーキテクチャへの移行にはどれくらいコード変更が必要ですか?
ほとんど不要で、設定層の変更が主です。すでに OpenAI SDK を使って APIYI 経由で Claude を呼び出している場合、移行は3ステップです:(1) アプリ側にタスク分類関数を追加する(20行程度);(2) タスクタイプに応じて claude-opus-4-7 と grok-4.3 を切り替える;(3) トラフィックの5–10%を試験的に移行する。この作業は1日以内に完了し、予算を60–80%削減可能です。
Q9: Claude Code CLI などのツールで Grok 4.3 は使えますか?
直接は使えませんが、同等の代替案があります。Claude Code は Anthropic 公式 CLI であり Claude モデルのみ対応しています。Grok 4.3 で同様の体験を得たい場合、(1) Aider (オープンソース CLI、OpenAI 互換API対応で Grok 4.3 と直接連携可能);(2) Continue.dev (IDEプラグイン、OpenAI 互換モデル対応);(3) OpenAI SDK を使用した自作 CLI があります。2026年5月時点では Grok 4.3 に最適化されたオープンソース CLI も複数登場しており、エンジニアリング的には Claude Code の核心機能を代替可能です。
Q10: エージェント型コーディング(Agentic Coding)ではどちらが安定していますか?
タスクによります。Anthropic のデータによると、Claude Opus 4.7 は「短距離で精密なコーディングエージェント」(SWE-bench系)で 74.9 対 Grok 4.20 の 47.1 と圧倒的です。一方で「長期間の自律エージェント」(Vending-Bench系、7日間の経営判断が必要など)では Grok 4.3 が Claude Opus 4.7 を1.5–2倍上回ります。結論として、短距離・精密エージェントには Claude Opus 4.7 を、長期間・自律的判断が必要なエージェントには Grok 4.3 を使い分けるのがベストです。
Q11: Cursor ユーザーはどのように Grok 4.3 をワークフローに追加できますか?
Cursor はカスタム OpenAI 互換エンドポイントをサポートしています。手順は3ステップ:(1) Cursor の設定 → Models → Custom API Endpoint へ進む;(2) base_url に https://vip.apiyi.com/v1 を入力し、API Key に APIYI のキーを入力;(3) Model name に grok-4.3 を追加。これでチャットボックスからいつでも Grok 4.3 と Claude Opus 4.7 を切り替えられるようになります。これにより、Cursor の優れたUXを維持しつつ、日常のコーディングを Grok 4.3 でコスト効率よく処理できます。
まとめ: Grok 4.3 は Claude Opus 4.7 の代わりになるか
今回の比較の核心となる問いに戻りましょう。Grok 4.3 はプログラミングにおいて Claude Opus 4.7 の代わり(平替)になるのでしょうか?
結論から言えば、日常的なプログラミングタスクの 60〜70% は代替可能です。残りの 30〜40% の複雑なタスクについては、引き続き Claude Opus 4.7 を使用することをお勧めします。
具体的には、関数単位の生成、単体テスト作成、コメント付与、単純なバグ修正、長距離エージェントといった 5 つのタスクにおいて、Grok 4.3 の精度差は 5% 未満です。価格が 1/10 であることを考えれば、完全に代替しても問題ありません。一方、複数ファイルにまたがるリファクタリング、複雑なリポジトリのバグ調査、重要なコンプライアンス関連のコード記述という 3 つのタスクでは、Claude Opus 4.7 の SWE-bench Pro 64.3% というスコアが業界最高水準であり、14 ポイント以上の差があるため、代替は推奨されません。
さらに重要な点は、Grok 4.3 は単なる「安価な Claude Opus 4.7」ではないということです。以下の 6 つの点において、Claude にはない差別化された強みを持っています:価格 1/10、速度 2.6 倍、動画入力、ドキュメント生成、長距離エージェント性能での逆転、サーバーサイドツールの内蔵。これらの機能により、動画駆動開発、自動運用エージェント、ウェブ検索を行うコーディングエージェントなどのシナリオでは、Grok 4.3 こそが「Claude Opus 4.7 の不完全な代替品というより、新しい形態の製品における最良の出発点」となります。
日本の開発者にとって、この「Grok 4.3 を主力とし、Claude Opus 4.7 を重要経路に使う」というハイブリッドアーキテクチャを実装する際、最も摩擦の少ないパスは APIYI (apiyi.com) の API 中継サービスを利用することです。両モデルとも同じ base_url と APIキー を共有しており、アプリケーション層で model フィールドを書き換えるだけで切り替えが可能です。Grok 4.3 の価格は xAI 公式と 1:1 での転送、Claude Opus 4.7 も Anthropic 公式価格での転送となっており、追加料金は一切ありません。さらに、Anthropic のネイティブなプロンプトキャッシュ(90% 削減)や Batch API(さらに 50% 削減)を組み合わせれば、AI コーディング全体のコストを「全て Claude Opus 4.7 で行う場合」と比較して 15〜25% まで下げつつ、重要なタスクの品質を維持することが可能です。
最後に、24 時間以内に試すべきアクションプランを提案します。今日中に APIYI でキーを申請し、実際のコーディングタスク 100 件を両方のモデルで実行してみてください。ベンチマークスコアはあくまで参考であり、自身の業務におけるヒット率こそが最終的な判断基準です。
参考資料
-
Anthropic 公式発表: Claude Opus 4.7 リリース詳細
- リンク:
anthropic.com/claude/opus - 説明: 価格、ベンチマーク、API フィールドに関する説明
- リンク:
-
Anthropic API ドキュメント: Claude Opus 4.7 完全仕様
- リンク:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - 説明: コンテキストウィンドウ、出力制限、トークナイザーの変化
- リンク:
-
xAI モデルドキュメント: Grok 4.3 API 全仕様
- リンク:
docs.x.ai/developers/models - 説明: 動画入力、ドキュメント生成、サーバーサイドツールなどの独自機能
- リンク:
-
Vellum ベンチマークレポート: Claude Opus 4.7 詳細レビュー
- リンク:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - 説明: SWE-bench Verified / Pro / CursorBench データ
- リンク:
-
Artificial Analysis インテリジェンスランキング: モデル間の総合性能と価格比較
- リンク:
artificialanalysis.ai/models/claude-opus-4-7 - 説明: インテリジェンス指数、速度、価格の総合評価
- リンク:
-
DocsBot モデル比較: Grok 4.3 vs Claude Opus 4.7 詳細比較
- リンク:
docsbot.ai/models/compare/grok-4-3/claude-opus-4-7 - 説明: 価格、パフォーマンス、特徴の比較
- リンク:
-
APIYI 接続ドキュメント: 国内からの両モデル接続用チュートリアル
- リンク:
help.apiyi.com - 説明: モデルフィールド、SDK サンプル、料金照会を含む
- リンク:
著者: APIYI Team — AI 大規模言語モデル API 中継サービスを専門とし、国内の開発者が Grok 4.3、Claude Opus 4.7、GPT-5.5 などの主要モデルをワンクリックで呼び出せるようサポートします。APIYI (apiyi.com) にアクセスして、無料テスト枠をご利用ください。