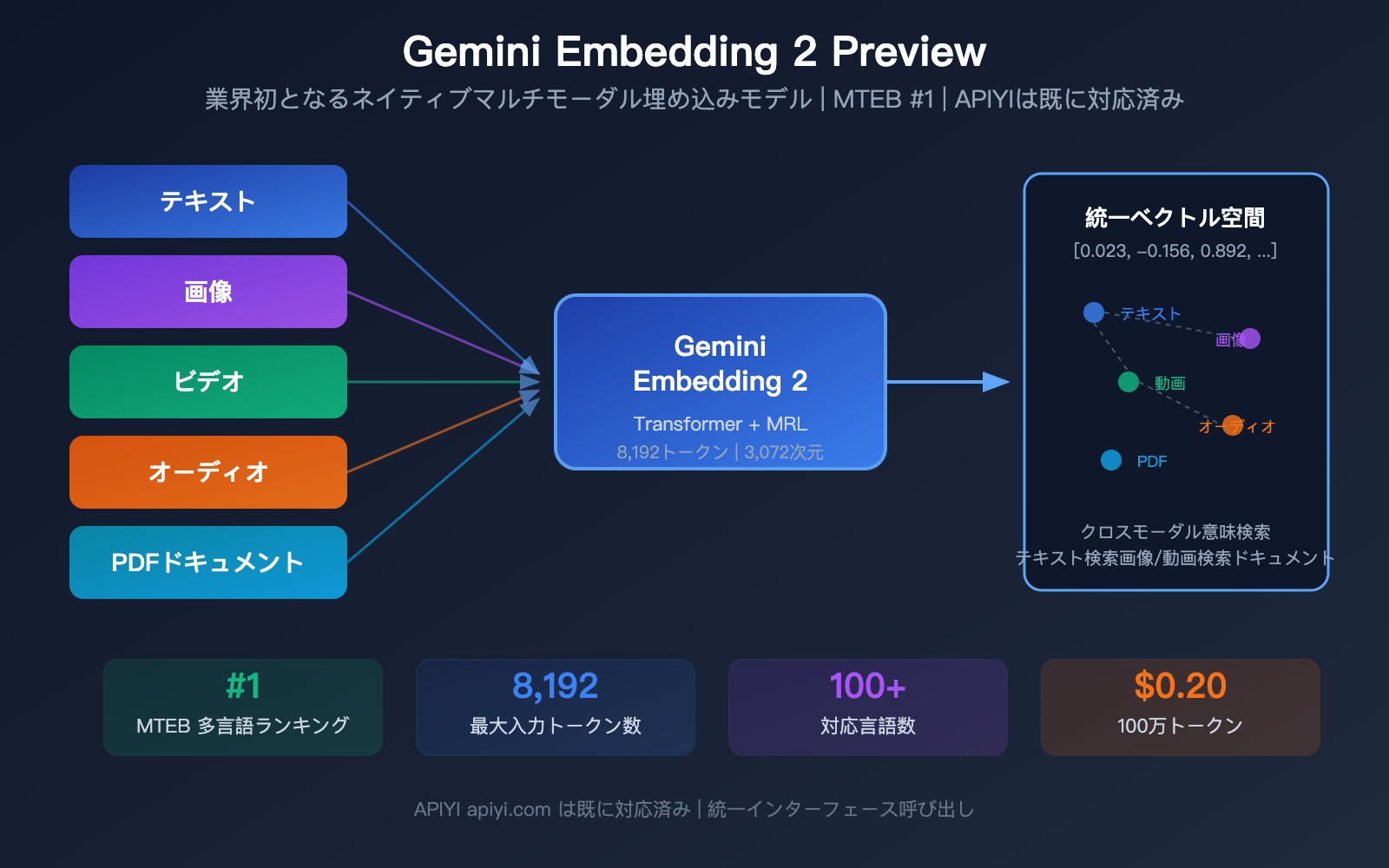
Googleは2026年3月、重要なモデルである「Gemini Embedding 2 Preview:業界初となるネイティブ・マルチモーダル埋め込みモデル」を発表しました。このモデルは、テキスト、画像、動画、音声、PDFドキュメントを同一のベクトル空間に統合してマッピングすることができ、MTEB多言語ベンチマークで1位を獲得し、2位に5ポイント以上の差をつけています。
コアバリュー: 本記事では、Gemini Embedding 2 Previewの5つの技術的ブレイクスルー、競合他社との価格・性能比較、そしてAPIを通じて迅速に導入・利用する方法について解説します。
Gemini Embedding 2 Preview とは
Gemini Embedding 2 Previewは、Googleが2026年3月10日にリリースした最新の埋め込みモデルです。Geminiアーキテクチャをベースに初期化され、双方向アテンションTransformer構造を採用しており、Google初のマルチモーダル入力をネイティブサポートした埋め込みモデルとなります。
| 仕様 | 詳細 |
|---|---|
| モデルID | gemini-embedding-2-preview |
| リリース日 | 2026年3月10日 |
| ステータス | Preview(プレビュー版、正式版は未定) |
| デフォルト出力次元数 | 3,072 |
| 選択可能な次元範囲 | 128 — 3,072 |
| 最大入力トークン数 | 8,192(前世代の4倍) |
| マルチモーダル対応 | テキスト、画像、動画、音声、PDF |
| 言語サポート | 100以上の言語 |
| Matryoshka学習 | 対応(次元を切り詰めても意味品質を保持) |
| 利用可能プラットフォーム | Gemini API、Vertex AI、APIYI apiyi.com |
前世代モデルとの主な違い
| 特性 | text-embedding-004 | gemini-embedding-001 | gemini-embedding-2-preview |
|---|---|---|---|
| 最大入力トークン数 | 2,048 | 2,048 | 8,192 |
| 出力次元数 | 最大768 | 128-3,072 | 128-3,072 |
| マルチモーダル | テキストのみ | テキストのみ | テキスト+画像+動画+音声+PDF |
| タスクタイプ指定 | task_type フィールド |
task_type フィールド |
プロンプト内蔵命令 |
| MRLサポート | 非対応 | 対応 | 対応 |
| 価格/100万トークン | サービス終了 | $0.15 | $0.20 |
🎯 導入のヒント: APIYI apiyi.com は既に gemini-embedding-2-preview のモデル呼び出しに対応しています。OpenAI互換インターフェースを通じて簡単に接続でき、個別のGoogle APIキーを設定する必要はありません。
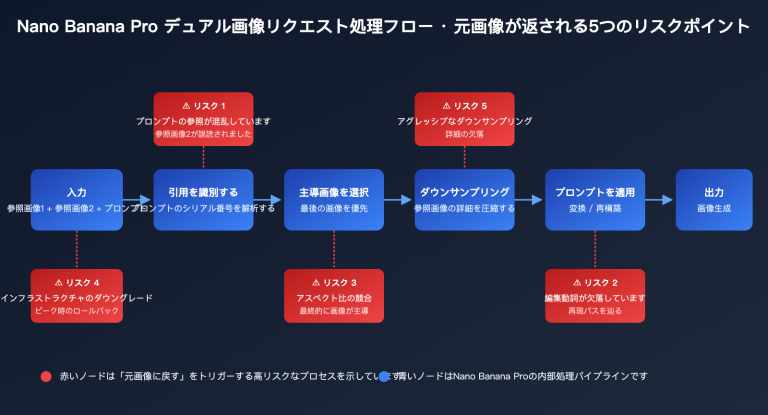
5つの技術的ブレイクスルー詳解
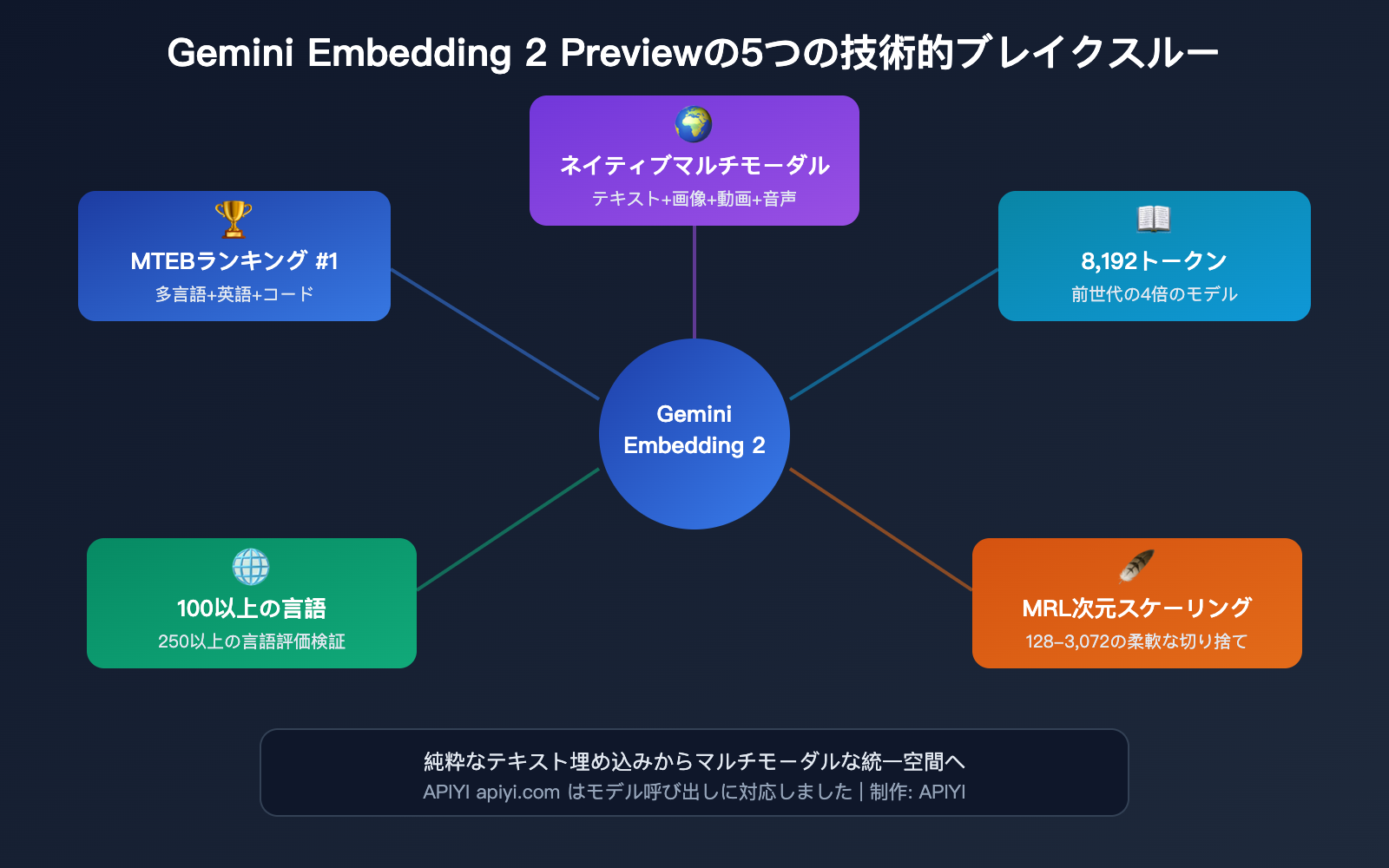
突破一:ネイティブマルチモーダル統合埋め込み空間
これは Gemini Embedding 2 の最大の差別化要因です。5つのモダリティ(形式)の内容が、同一のベクトル空間にマッピングされます。
| モダリティ | フォーマット要件 | 1回あたりの制限 | 説明 |
|---|---|---|---|
| テキスト | プレーンテキスト | 8,192トークン | 100以上の言語に対応 |
| 画像 | PNG, JPEG | 1リクエスト最大6枚 | ピクセルを直接処理 |
| 動画 | MP4, MOV | 最大120秒 | 最大32フレームを自動サンプリング |
| 音声 | MP3, WAV | 最大80秒 | ネイティブ処理(文字起こし不要) |
| PDFドキュメント | 1リクエスト最大6ページ | OCR機能を含む |
実際の活用シーン:
- テキストによる画像検索(「サーキット上の赤いスポーツカー」→一致する画像を返却)
- 画像による類似動画クリップの検索
- 音声による関連ドキュメントの検索
- クロスモーダルな統合ナレッジベースの構築
これは従来の埋め込みモデルでは不可能でした。OpenAI の text-embedding-3 シリーズはテキストのみをサポートしており、画像検索を行うには、まず視覚モデルで説明文を抽出してから埋め込む必要があり、ステップが増える上に情報損失が発生していました。
突破二:8,192トークンのコンテキストウィンドウ
入力ウィンドウが2,048から8,192トークンに拡大されたことで、一度により長いドキュメントセグメントを埋め込むことが可能になりました。
RAG(検索拡張生成)システムにとって、この向上は非常に実用的です:
- 以前はドキュメントを500〜1,000トークンの小さな断片に分割する必要がありました。
- 今では2,000〜4,000トークンの大きなセグメントを使用でき、より多くのコンテキストを保持できます。
- ドキュメントセグメントが大きい=分割数が少ない=検索結果がより包括的になる。
突破三:Matryoshka次元スケーリング
Gemini Embedding 2 は Matryoshka Representation Learning (MRL) を用いて学習されており、モデルは最も重要なセマンティック(意味的)情報をベクトルの先頭次元に集中させます。
これにより、用途に応じて柔軟に次元数を選択できます。
| 次元数 | ベクトルサイズ | 適した用途 | 品質低下 |
|---|---|---|---|
| 3,072 (デフォルト) | 12.3 KB | 最高精度の検索 | なし |
| 1,536 | 6.1 KB | 精度とストレージのバランス | 極めて小さい |
| 768 | 3.1 KB | 大規模デプロイの推奨 | 小さい |
| 256 | 1.0 KB | リアルタイム推薦システム | 中程度 |
| 128 | 0.5 KB | 極限の圧縮が必要なシーン | 大きい |
注意: 3,072未満の次元数を使用する場合は、類似度を計算する前に手動でベクトルを正規化する必要があります。
突破四:100以上の言語サポート
MTEB多言語ベンチマークにおいて、Gemini Embedding 2 は250以上の言語で評価されており、そのカバー範囲は競合を大きく上回っています。
主要な言語パフォーマンス指標:
- バイテキストマイニング (Bitext Mining): 79.32点
- クロスリンガル検索 (XOR-Retrieve): Recall@5kt 90.42点
- 多言語理解 (XTREME-UP): MRR@10 64.33点
突破五:MTEBで複数項目1位を獲得
| ベンチマーク | スコア | 順位 | リード幅 |
|---|---|---|---|
| MTEB 多言語 (平均) | 68.32 | 1位 | +5.09 |
| MTEB 多言語 (タイプ別平均) | 59.64 | 1位 | — |
| MTEB 英語 v2 (平均) | 73.30 | 1位 | — |
| MTEB 英語 v2 (タイプ別平均) | 67.67 | 1位 | — |
| MTEB コード (平均) | 74.66 | 1位 | — |
比較として、2位のモデル「gte-Qwen2-7B-instruct」の多言語MTEBスコアは62.51です。Gemini Embedding 2 は約6ポイントの差をつけており、埋め込みモデルの分野では非常に大きな差と言えます。
💡 開発アドバイス: RAGシステムやセマンティック検索アプリケーションを構築中であれば、
Gemini Embedding 2 は多言語およびコード関連のタスクにおいて現在最強の選択肢です。
APIYI (apiyi.com) を通じて、このモデルをワンクリックで統合できます。
OpenAI の埋め込みモデルもサポートしているため、パフォーマンスの比較も簡単に行えます。
競合他社との価格および性能比較

テキスト埋め込み(Embedding)の価格比較
| モデル | 価格/100万トークン | 最大次元数 | 最大入力 | マルチモーダル | 多言語ランキング |
|---|---|---|---|---|---|
| Gemini Embedding 2 | $0.20 | 3,072 | 8,192 | ✅ 5モダリティ | #1 |
| gemini-embedding-001 | $0.15 | 3,072 | 2,048 | ❌ | — |
| OpenAI text-embedding-3-large | $0.13 | 3,072 | 8,191 | ❌ | — |
| OpenAI text-embedding-3-small | $0.02 | 1,536 | 8,191 | ❌ | — |
マルチモーダルコンテンツの価格(Gemini Embedding 2 独自機能):
| 入力タイプ | 通常価格/100万トークン | バッチ価格/100万トークン |
|---|---|---|
| テキスト | $0.20 | $0.10 |
| 画像 | $0.45 (~$0.00012/枚) | $0.225 |
| 音声 | $6.50 (~$0.00016/秒) | $3.25 |
| 動画 | $12.00 (~$0.00079/フレーム) | $6.00 |
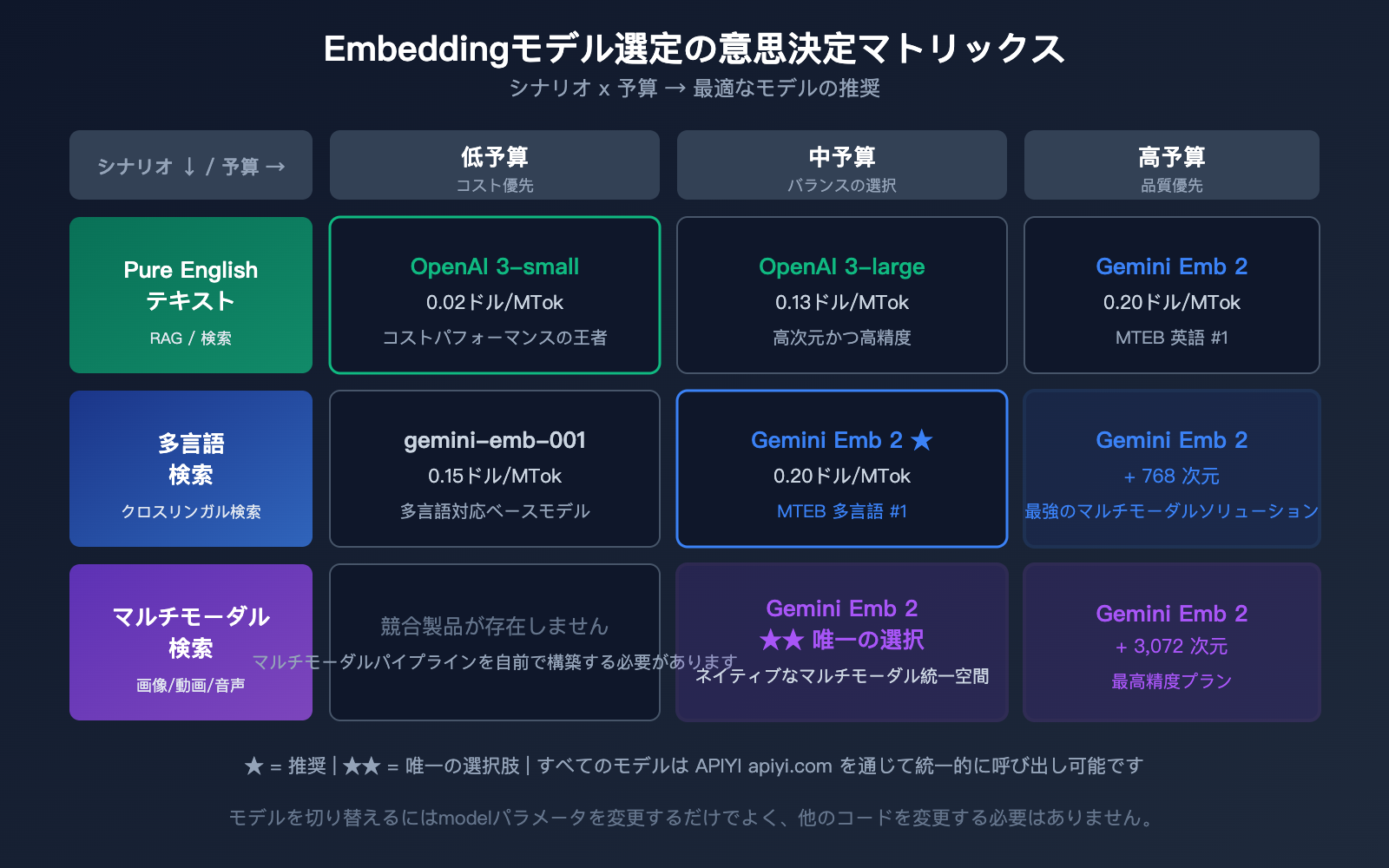
モデル選定のアドバイス
| ニーズ・シナリオ | 推奨モデル | 理由 |
|---|---|---|
| 純粋なテキスト、コスト重視 | OpenAI text-embedding-3-small | 最安 ($0.02) |
| 純粋なテキスト、高精度 | Gemini Embedding 2 または OpenAI 3-large | 精度は同等だが、Gemini は多言語対応が強力 |
| マルチモーダル検索 | Gemini Embedding 2 | 唯一のネイティブマルチモーダルソリューション |
| 多言語検索 | Gemini Embedding 2 | MTEB 多言語部門 #1 |
| コード検索 | Gemini Embedding 2 | MTEB コード部門 #1 |
| 大規模・低コスト | OpenAI 3-small + バッチ API | 10倍の価格優位性 |
🎯 選定のアドバイス: どの埋め込みモデルを選択するかは、具体的な利用シーンに依存します。
APIYI (apiyi.com) プラットフォームを通じて Gemini と OpenAI の埋め込みモデルの両方にアクセスし、実際のデータで検索精度を比較してから決定することをお勧めします。同プラットフォームは統一されたインターフェースをサポートしており、コードを変更せずにモデルを切り替えることが可能です。
API呼び出しの詳細
タスクタイプの指定方法(重要な変更点)
gemini-embedding-001 とは異なり、Gemini Embedding 2 では task_type パラメータは使用しません。代わりに、入力内容にタスク指示を埋め込むことでタスクタイプを指定します。
サポートされている8種類のタスクタイプ:
| タスクタイプ | クエリ側フォーマット | ドキュメント側フォーマット |
|---|---|---|
| 検索/取得 | task: search result | query: {内容} |
title: {タイトル} | text: {内容} |
| 質問応答 | task: question answering | query: {質問} |
title: {タイトル} | text: {内容} |
| ファクトチェック | task: fact checking | query: {声明} |
title: {タイトル} | text: {内容} |
| コード検索 | task: code retrieval | query: {説明} |
title: {タイトル} | text: {コード} |
| 分類 | task: classification | query: {内容} |
同フォーマット |
| クラスタリング | task: clustering | query: {内容} |
同フォーマット |
| 文の類似度 | task: sentence similarity | query: {文} |
同フォーマット |
ドキュメント側にタイトルがない場合は、title: none を使用してください。
Python 呼び出し例
import openai
# APIYI 統一インターフェース経由で呼び出し
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# テキスト埋め込み - 検索シナリオ
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input="task: search result | query: ベクトルデータベースとは",
dimensions=768 # 指定可能な次元数: 128-3072
)
embedding = response.data[0].embedding
print(f"ベクトル次元数: {len(embedding)}")
print(f"最初の5つの値: {embedding[:5]}")
RAG検索フローの完全なコードを表示
import openai
import numpy as np
from typing import List
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def get_embedding(text: str, task: str = "search result", dim: int = 768) -> List[float]:
"""テキスト埋め込みベクトルを取得"""
formatted = f"task: {task} | query: {text}"
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input=formatted,
dimensions=dim
)
vec = response.data[0].embedding
# MRL 次元削減時は手動で正規化が必要
if dim < 3072:
norm = np.linalg.norm(vec)
vec = (np.array(vec) / norm).tolist()
return vec
def get_doc_embedding(title: str, text: str, dim: int = 768) -> List[float]:
"""ドキュメント埋め込みベクトルを取得"""
formatted = f"title: {title} | text: {text}"
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input=formatted,
dimensions=dim
)
vec = response.data[0].embedding
if dim < 3072:
norm = np.linalg.norm(vec)
vec = (np.array(vec) / norm).tolist()
return vec
def cosine_similarity(a: List[float], b: List[float]) -> float:
"""コサイン類似度を計算"""
a, b = np.array(a), np.array(b)
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# 使用例
query_vec = get_embedding("RAG検索の精度を最適化する方法")
doc_vec = get_doc_embedding(
"RAG最適化ガイド",
"この記事では、RAG検索の品質を最適化する5つの方法を紹介します..."
)
similarity = cosine_similarity(query_vec, doc_vec)
print(f"類似度: {similarity:.4f}")
🚀 クイックスタート: APIYI (apiyi.com) プラットフォームを使用して、Gemini Embedding 2 に素早く接続することをお勧めします。
OpenAI 互換の埋め込みインターフェースを提供しており、5分で統合が完了します。また、OpenAI、Gemini、Cohere などの主要な埋め込みモデルの統一呼び出しもサポートしています。
使用上の注意
Preview 状態における制限
| 制限事項 | 説明 | 影響 |
|---|---|---|
| バージョンの変更可能性 | Preview 段階では仕様や価格が調整される可能性があります | 本番環境ではダウングレード策の準備を推奨 |
| ベクトル空間の非互換性 | 旧モデルのベクトルと混在できません | アップグレードには全量再インデックスが必要 |
| 低次元の正規化 | 3,072 次元未満で使用する場合、手動での正規化が必要です | コード内に正規化ステップの追加が必要 |
| 厳格なレート制限 | Preview モデルのクォータは GA モデルより低く設定されています | 大規模利用には制限緩和の申請が必要 |
| 無料枠のデータ利用 | 無料枠のデータは製品改善に使用されます | 機密データには有料枠の利用を推奨 |
旧モデルからの移行に関する注意点
- インデックスの再構築が必須: モデルごとにベクトル空間が異なるため、同一データベース内での混在はできません。
- タスクタイプ形式の変更:
task_typeパラメータから、プロンプト内への埋め込み指示へと変更されました。 - 正規化処理: デフォルト以外の次元数を使用する場合、コード内に正規化ロジックを追加する必要があります。
- 検証後の移行: テスト環境にて新旧モデルの検索精度を比較した上で、移行を決定することを推奨します。
よくある質問
Q1: Gemini Embedding 2 Preview は OpenAI text-embedding-3-large と比べて何が良いのですか?
主な利点は3つあります。ネイティブなマルチモーダル対応(OpenAI はテキストのみ)、MTEB 多言語ランキングで1位(大幅なリード)、そしてコード埋め込みの品質の高さです。ただし、OpenAI text-embedding-3-large は価格がより安価($0.13 vs $0.20)であり、英語テキストの埋め込みのみが必要な場合は、両者の品質は非常に近いです。APIYI (apiyi.com) を通じて両方のモデルを呼び出し、実際のデータで比較することが可能です。
Q2: マルチモーダル埋め込みにはどのような実用的な用途がありますか?
最も直接的な用途はクロスモーダル検索です。ユーザーがテキストを入力し、関連する画像、動画、またはドキュメントを検索結果として返します。例えば、ECサイトで「赤いワンピース」と入力して商品画像を検索したり、企業ナレッジベースでテキスト説明を用いてトレーニング動画の関連シーンを検索したりできます。従来の手法では、まず視覚モデルで説明文を抽出してからテキスト埋め込みを行う必要がありましたが、Gemini Embedding 2 は元の画像や動画を直接処理するため、情報の損失がより少なくなります。
Q3: 次元数はどれくらいが適切ですか?768 と 3072 で大きな違いはありますか?
ほとんどのアプリケーションにおいて、768 次元が最適なバランスです。ストレージコストは 3072 次元の 4 分の 1 ですが、検索品質の低下は最小限(Matryoshka 学習のおかげ)です。データセットが比較的小さく(100 万件未満)、精度が極めて重要な場合は 3072 次元を使用してください。データ量が多い場合やリアルタイム検索が必要な場合は、768 次元や 256 次元も合理的な選択肢です。
Q4: APIYI はどのように Gemini Embedding 2 をサポートしていますか?追加設定は必要ですか?
APIYI (apiyi.com) はすでに gemini-embedding-2-preview モデルをサポートしており、標準的な OpenAI 互換の埋め込みインターフェースを通じて呼び出せます。Google APIキーの追加設定は不要です。model パラメータに gemini-embedding-2-preview を指定するだけで、その他のパラメータ(dimensions など)は OpenAI の埋め込みインターフェースと完全に同じです。
まとめ:マルチモーダル埋め込みの新たな基準
Gemini Embedding 2 Preview は、埋め込みモデルにおける重要なマイルストーンを打ち立てました。それは、純粋なテキストから真のマルチモーダル統合空間への進化です。MTEB(Massive Text Embedding Benchmark)の多言語、英語、コードの3つの領域で同時に1位を獲得したことに加え、8KのコンテキストウィンドウとMRL(Matryoshka Representation Learning)による次元の柔軟な調整機能を備えており、RAGシステム、セマンティック検索、ナレッジベース構築において現在最強の基盤能力を提供します。
重要なポイントの振り返り:
- 業界初のネイティブな5モーダル埋め込みモデル(テキスト+画像+動画+音声+PDF)
- MTEB多言語ベンチマークで1位を獲得、2位以下に5ポイント以上の差をつける圧倒的な性能
- 8,192トークンのコンテキストウィンドウ(前世代の4倍)
- MRL学習により、128〜3,072次元まで柔軟に調整可能
- 価格は100万トークンあたり0.20ドルと、マルチモーダル環境において極めて高いコストパフォーマンスを実現
Gemini Embedding 2 Preview へのアクセスには、APIYI (apiyi.com) を通じた迅速な導入をおすすめします。1つのAPIキーでGeminiやOpenAIなどの主要な埋め込みモデルを同時に利用できるため、比較や切り替えが非常にスムーズです。
📝 執筆者: APIYI 技術チーム | APIYI apiyi.com – 300種類以上のAI大規模言語モデルAPI統合プラットフォーム
参考資料
-
Google 公式ブログ: Gemini Embedding 2 リリース告知
- リンク:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-embedding-2/ - 説明: モデルの設計思想とマルチモーダル機能の紹介
- リンク:
-
Gemini API 埋め込みドキュメント: 公式API利用ガイド
- リンク:
ai.google.dev/gemini-api/docs/embeddings - 説明: APIパラメータと呼び出しの完全なサンプル
- リンク:
-
Gemini Embedding 研究論文: 技術詳細とベンチマーク
- リンク:
arxiv.org/html/2503.07891v1 - 説明: MTEBの詳細なテストデータとモデルアーキテクチャの分析
- リンク:
-
Gemini API 料金体系: 各モーダルの詳細な価格情報
- リンク:
ai.google.dev/gemini-api/docs/pricing - 説明: テキスト、画像、音声、動画ごとの項目別料金情報
- リンク: