구글이 2026년 3월에 발표한 중요한 모델, 바로 Gemini Embedding 2 Preview입니다. 업계 최초의 네이티브 멀티모달 임베딩 모델이죠. 이 모델은 텍스트, 이미지, 비디오, 오디오, PDF 문서를 하나의 벡터 공간에 통합할 수 있으며, MTEB 다국어 벤치마크 테스트에서 2위보다 5% 포인트 이상 앞서며 당당히 1위를 차지했습니다.
핵심 가치: 이 글을 통해 Gemini Embedding 2 Preview의 5가지 기술적 돌파구, 경쟁사 대비 가격 및 성능 비교, 그리고 API를 통한 빠른 연동 방법을 확인해 보세요.
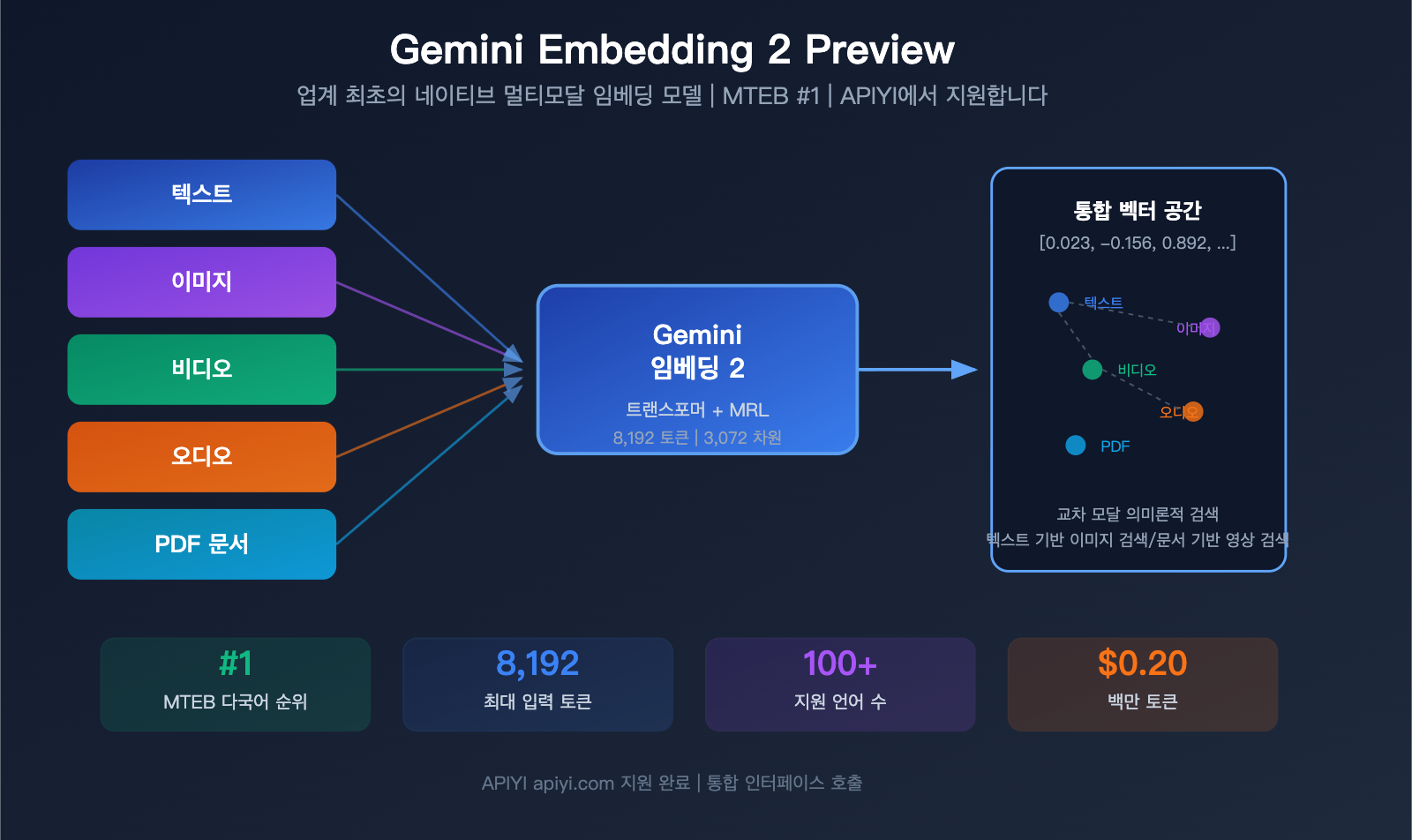
Gemini Embedding 2 Preview란 무엇인가
Gemini Embedding 2 Preview는 구글이 2026년 3월 10일에 발표한 최신 임베딩 모델입니다. Gemini 아키텍처를 기반으로 초기화되었으며, 양방향 어텐션 트랜스포머 구조를 채택한 구글 최초의 네이티브 멀티모달 입력 지원 임베딩 모델입니다.
| 사양 | 상세 내용 |
|---|---|
| 모델 ID | gemini-embedding-2-preview |
| 출시일 | 2026년 3월 10일 |
| 상태 | Preview (미리보기 버전, 정식 버전 미정) |
| 기본 출력 차원 | 3,072 |
| 선택 가능 차원 범위 | 128 — 3,072 |
| 최대 입력 토큰 | 8,192 (이전 세대 대비 4배) |
| 멀티모달 지원 | 텍스트, 이미지, 비디오, 오디오, PDF |
| 언어 지원 | 100개 이상의 언어 |
| Matryoshka 학습 | 지원 (차원 축소 시에도 의미 품질 유지) |
| 사용 가능 플랫폼 | Gemini API, Vertex AI, APIYI apiyi.com |
이전 세대 모델과의 주요 차이점
| 특성 | text-embedding-004 | gemini-embedding-001 | gemini-embedding-2-preview |
|---|---|---|---|
| 최대 입력 토큰 | 2,048 | 2,048 | 8,192 |
| 출력 차원 | 최대 768 | 128-3,072 | 128-3,072 |
| 멀티모달 | 텍스트 전용 | 텍스트 전용 | 텍스트+이미지+비디오+오디오+PDF |
| 작업 유형 지정 | task_type 필드 |
task_type 필드 |
프롬프트 내장 지시어 |
| MRL 지원 | 미지원 | 지원 | 지원 |
| 가격/백만 토큰 | 서비스 종료 | $0.15 | $0.20 |
🎯 연동 팁: APIYI apiyi.com에서 이미 gemini-embedding-2-preview 모델 호출을 지원하고 있습니다. OpenAI 호환 인터페이스를 통해 바로 연동할 수 있으며, 별도의 구글 API 키를 설정할 필요가 없습니다.
5가지 주요 기술적 돌파구 상세 분석
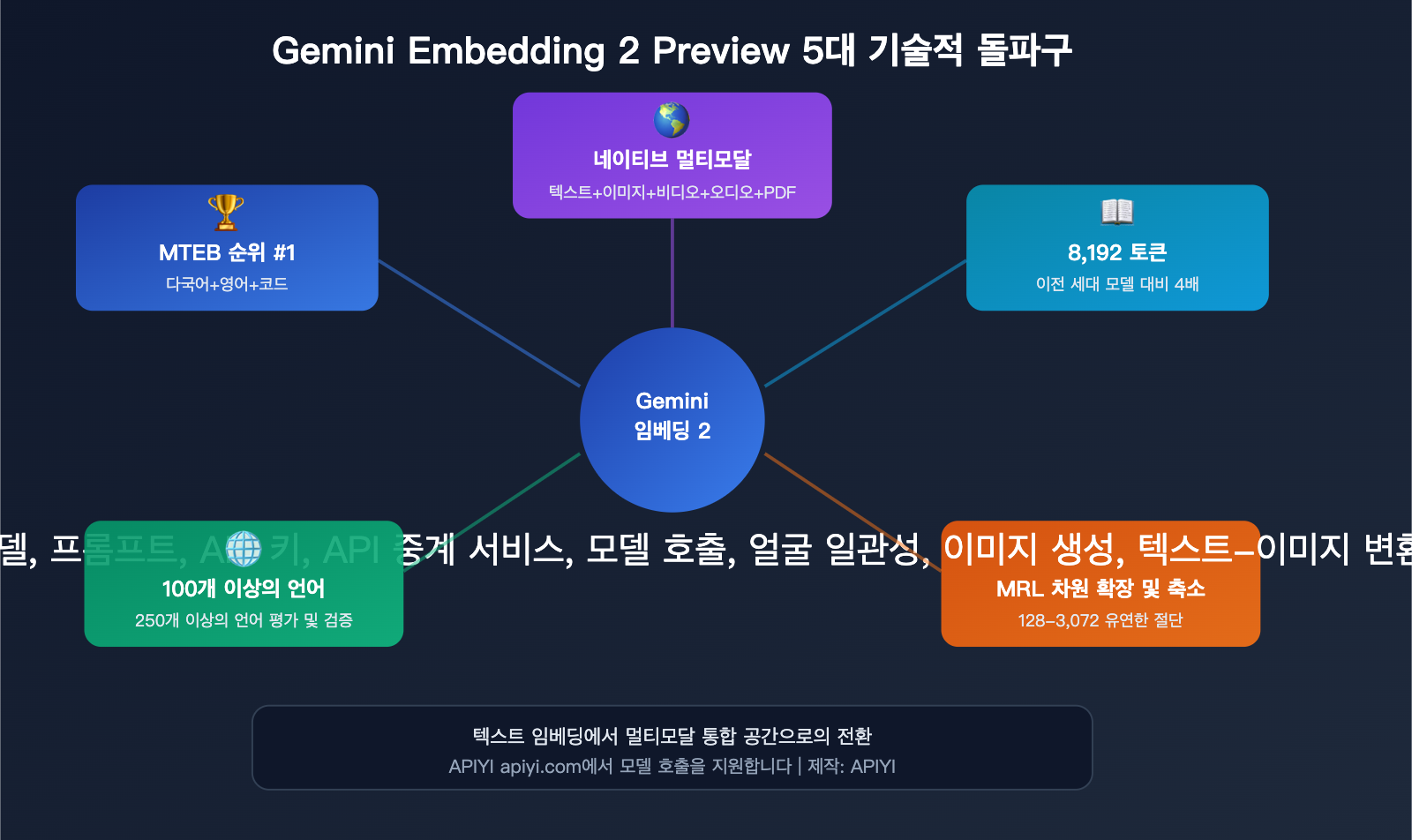
돌파구 1: 네이티브 멀티모달 통합 임베딩 공간
Gemini Embedding 2의 가장 큰 차별점은 5가지 모달리티의 콘텐츠를 동일한 벡터 공간에 매핑한다는 점입니다.
| 모달리티 | 형식 요구사항 | 단일 제한 | 설명 |
|---|---|---|---|
| 텍스트 | 순수 텍스트 | 8,192 토큰 | 100개 이상의 언어 지원 |
| 이미지 | PNG, JPEG | 요청당 최대 6장 | 픽셀 직접 처리 |
| 비디오 | MP4, MOV | 최대 120초 | 최대 32프레임 자동 샘플링 |
| 오디오 | MP3, WAV | 최대 80초 | 네이티브 처리(전사 불필요) |
| PDF 문서 | 요청당 최대 6페이지 | OCR 기능 포함 |
실제 활용 사례:
- 텍스트로 이미지 검색 ("경주로 위의 빨간 스포츠카" → 일치하는 이미지 반환)
- 이미지로 유사한 비디오 클립 검색
- 음성 설명으로 관련 문서 검색
- 교차 모달 통합 지식 베이스 구축
기존 임베딩 모델에서는 불가능했던 일입니다. OpenAI의 text-embedding-3 시리즈는 텍스트만 지원하므로, 이미지 검색을 하려면 비주얼 모델을 통해 설명을 먼저 추출한 뒤 임베딩해야 했기에 단계가 늘어나고 정보 손실도 발생했습니다.
돌파구 2: 8,192 토큰 컨텍스트 윈도우
입력 윈도우가 2,048에서 8,192 토큰으로 확장되어 한 번에 더 긴 문서 단락을 임베딩할 수 있게 되었습니다.
RAG(검색 증강 생성) 시스템에 매우 유용한 개선 사항입니다:
- 이전에는 문서를 500~1,000 토큰 단위로 잘라야 했습니다.
- 이제는 2,000~4,000 토큰의 큰 단락을 사용하여 더 많은 컨텍스트를 유지할 수 있습니다.
- 더 큰 문서 단락 = 더 적은 분할 = 더 완벽한 검색 결과.
돌파구 3: Matryoshka 차원 스케일링
Gemini Embedding 2는 **Matryoshka Representation Learning (MRL)**을 사용하여 학습되었으며, 모델은 가장 중요한 의미 정보를 벡터의 앞쪽 차원에 집중시킵니다.
따라서 상황에 따라 유연하게 차원을 선택할 수 있습니다:
| 차원 | 벡터 크기 | 적용 사례 | 품질 손실 |
|---|---|---|---|
| 3,072 (기본값) | 12.3 KB | 최고 정밀도 검색 | 없음 |
| 1,536 | 6.1 KB | 정밀도와 저장 공간 균형 | 매우 작음 |
| 768 | 3.1 KB | 대규모 배포 시 권장 | 작음 |
| 256 | 1.0 KB | 실시간 추천 시스템 | 중간 |
| 128 | 0.5 KB | 극한의 압축 환경 | 큼 |
참고: 3,072 미만의 차원을 사용할 때는 **벡터를 수동으로 정규화(Normalization)**한 후 유사도를 계산해야 합니다.
돌파구 4: 100개 이상의 언어 지원
MTEB 다국어 벤치마크 테스트에서 Gemini Embedding 2는 250개 이상의 언어를 평가받았으며, 지원 범위가 경쟁 모델을 압도합니다.
주요 언어 성능 지표:
- 이중 텍스트 마이닝 (Bitext Mining): 79.32점
- 교차 언어 검색 (XOR-Retrieve): Recall@5kt 90.42점
- 다국어 이해 (XTREME-UP): MRR@10 64.33점
돌파구 5: MTEB 다항목 1위 달성
| 벤치마크 | 점수 | 순위 | 격차 |
|---|---|---|---|
| MTEB 다국어 (Mean Task) | 68.32 | 1위 | +5.09 |
| MTEB 다국어 (Mean Type) | 59.64 | 1위 | — |
| MTEB 영어 v2 (Mean Task) | 73.30 | 1위 | — |
| MTEB 영어 v2 (Mean Type) | 67.67 | 1위 | — |
| MTEB 코드 (Mean All) | 74.66 | 1위 | — |
비교하자면, 2위 모델인 gte-Qwen2-7B-instruct의 다국어 MTEB 점수는 62.51점입니다. Gemini Embedding 2가 6점 가까이 앞서고 있는데, 이는 임베딩 모델 분야에서 매우 큰 격차입니다.
💡 개발 팁: RAG 시스템이나 의미론적 검색 애플리케이션을 구축 중이라면,
Gemini Embedding 2는 다국어 및 코드 시나리오에서 현재 가장 강력한 선택지입니다.
APIYI(apiyi.com)를 통해 해당 모델을 즉시 연동할 수 있으며, OpenAI 임베딩 모델도 함께 지원하여
성능을 빠르게 비교해 볼 수 있습니다.
경쟁 제품과의 가격 및 성능 비교
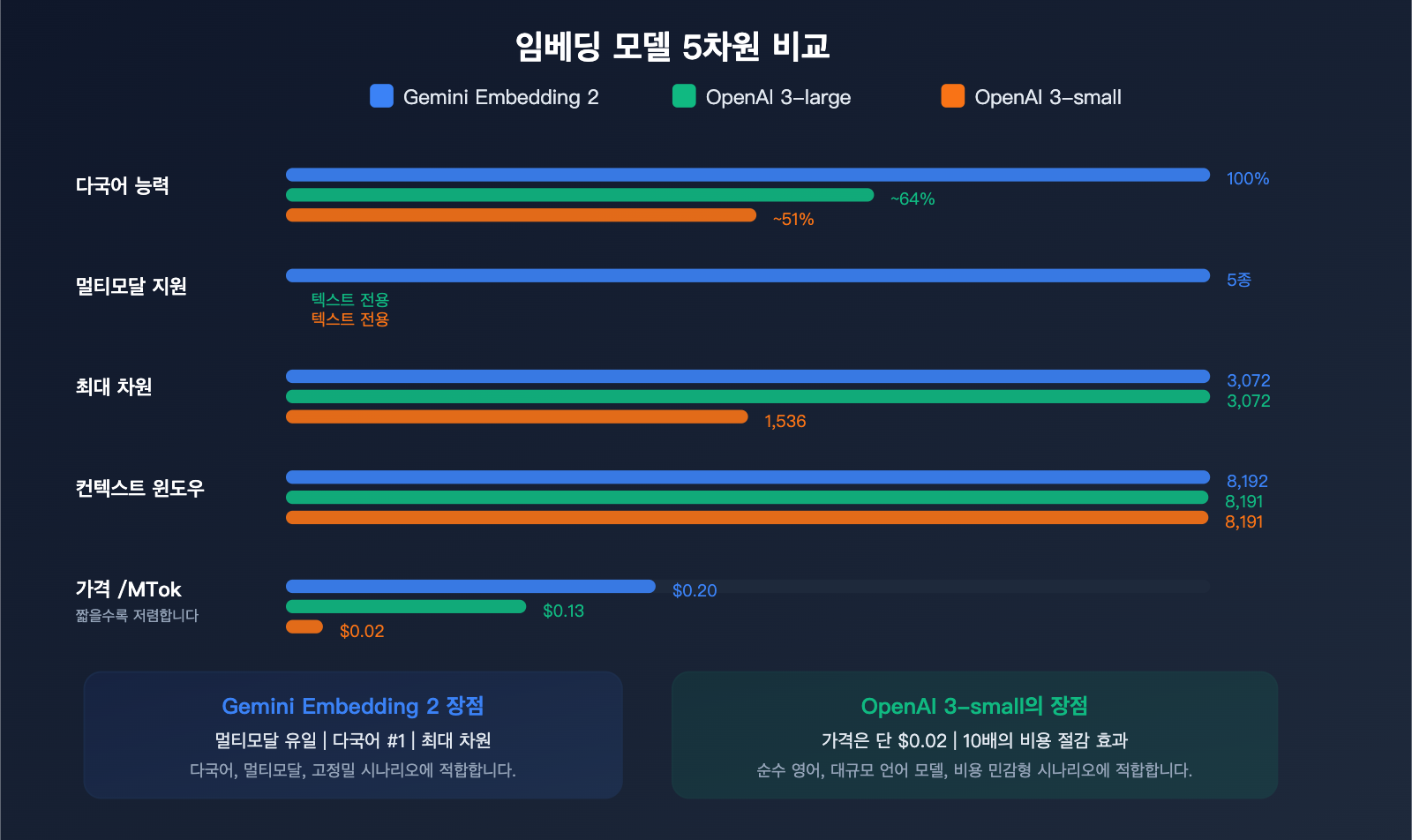
텍스트 임베딩 가격 비교
| 모델 | 가격/백만 토큰 | 최대 차원 | 최대 입력 | 멀티모달 | 다국어 순위 |
|---|---|---|---|---|---|
| Gemini Embedding 2 | $0.20 | 3,072 | 8,192 | ✅ 5개 모달 | #1 |
| gemini-embedding-001 | $0.15 | 3,072 | 2,048 | ❌ | — |
| OpenAI text-embedding-3-large | $0.13 | 3,072 | 8,191 | ❌ | — |
| OpenAI text-embedding-3-small | $0.02 | 1,536 | 8,191 | ❌ | — |
멀티모달 콘텐츠 가격 (Gemini Embedding 2 전용):
| 입력 유형 | 유료 가격/백만 토큰 | 배치 가격/백만 토큰 |
|---|---|---|
| 텍스트 | $0.20 | $0.10 |
| 이미지 | $0.45 (~$0.00012/장) | $0.225 |
| 오디오 | $6.50 (~$0.00016/초) | $3.25 |
| 비디오 | $12.00 (~$0.00079/프레임) | $6.00 |
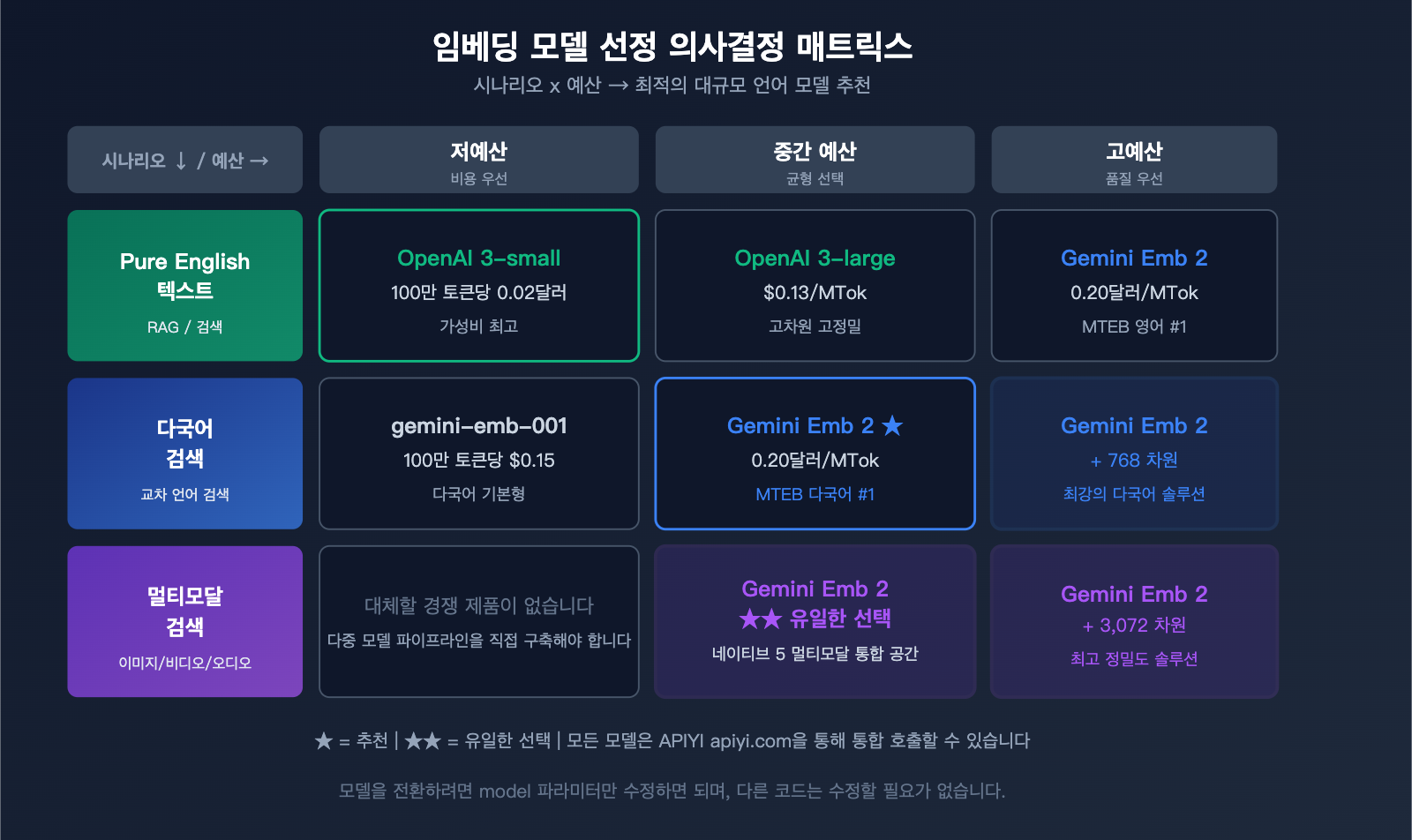
모델 선택 가이드
| 요구 상황 | 추천 모델 | 이유 |
|---|---|---|
| 순수 텍스트, 비용 민감 | OpenAI text-embedding-3-small | 가장 저렴 ($0.02) |
| 순수 텍스트, 고정밀 | Gemini Embedding 2 또는 OpenAI 3-large | 정밀도 비슷, Gemini 다국어 성능 우수 |
| 멀티모달 검색 | Gemini Embedding 2 | 유일한 네이티브 멀티모달 솔루션 |
| 다국어 검색 | Gemini Embedding 2 | MTEB 다국어 #1 |
| 코드 검색 | Gemini Embedding 2 | MTEB 코드 #1 |
| 대규모 저비용 | OpenAI 3-small + 배치 API | 10배 가격 경쟁력 |
🎯 선택 팁: 어떤 임베딩 모델을 선택할지는 구체적인 사용 사례에 따라 다릅니다.
APIYI(apiyi.com) 플랫폼을 통해 Gemini와 OpenAI 임베딩 모델을 모두 연동하여,
실제 데이터로 검색 성능을 비교한 후 결정하는 것을 추천해요. 이 플랫폼은 통합 인터페이스를 지원하여 코드 수정 없이 모델을 전환할 수 있습니다.
API 호출 방식 상세
작업 유형 지정 방식 (중요한 변경 사항)
gemini-embedding-001과 달리, Gemini Embedding 2는 task_type 파라미터를 더 이상 사용하지 않으며, 대신 입력 콘텐츠에 작업 지시문을 포함하여 작업 유형을 지정합니다.
8가지 지원 작업 유형:
| 작업 유형 | 쿼리 형식 | 문서 형식 |
|---|---|---|
| 검색/조회 | task: search result | query: {내용} |
title: {제목} | text: {내용} |
| 질의응답 | task: question answering | query: {질문} |
title: {제목} | text: {내용} |
| 사실 확인 | task: fact checking | query: {진술} |
title: {제목} | text: {내용} |
| 코드 검색 | task: code retrieval | query: {설명} |
title: {제목} | text: {코드} |
| 분류 | task: classification | query: {내용} |
동일 형식 |
| 클러스터링 | task: clustering | query: {내용} |
동일 형식 |
| 문장 유사도 | task: sentence similarity | query: {문장} |
동일 형식 |
문서 측에 제목이 없는 경우 title: none을 사용하세요.
Python 호출 예시
import openai
# APIYI 통합 인터페이스를 통한 호출
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# 텍스트 임베딩 - 검색 시나리오
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input="task: search result | query: 벡터 데이터베이스란 무엇인가요",
dimensions=768 # 선택 가능 차원: 128-3072
)
embedding = response.data[0].embedding
print(f"벡터 차원: {len(embedding)}")
print(f"상위 5개 값: {embedding[:5]}")
전체 RAG 검색 프로세스 코드 보기
import openai
import numpy as np
from typing import List
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def get_embedding(text: str, task: str = "search result", dim: int = 768) -> List[float]:
"""텍스트 임베딩 벡터 가져오기"""
formatted = f"task: {task} | query: {text}"
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input=formatted,
dimensions=dim
)
vec = response.data[0].embedding
# MRL 차원 절단 시 수동 정규화 필요
if dim < 3072:
norm = np.linalg.norm(vec)
vec = (np.array(vec) / norm).tolist()
return vec
def get_doc_embedding(title: str, text: str, dim: int = 768) -> List[float]:
"""문서 임베딩 벡터 가져오기"""
formatted = f"title: {title} | text: {text}"
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input=formatted,
dimensions=dim
)
vec = response.data[0].embedding
if dim < 3072:
norm = np.linalg.norm(vec)
vec = (np.array(vec) / norm).tolist()
return vec
def cosine_similarity(a: List[float], b: List[float]) -> float:
"""코사인 유사도 계산"""
a, b = np.array(a), np.array(b)
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# 사용 예시
query_vec = get_embedding("RAG 검색 효과 최적화 방법")
doc_vec = get_doc_embedding(
"RAG 최적화 가이드",
"본 문서에서는 RAG 검색 품질을 최적화하는 5가지 방법을 소개합니다..."
)
similarity = cosine_similarity(query_vec, doc_vec)
print(f"유사도: {similarity:.4f}")
🚀 빠른 시작: APIYI(apiyi.com) 플랫폼을 통해 Gemini Embedding 2를 빠르게 연동해 보세요.
OpenAI와 호환되는 임베딩 인터페이스를 제공하여 5분 만에 통합이 가능하며,
OpenAI, Gemini, Cohere 등 주요 임베딩 모델을 통합적으로 호출할 수 있습니다.
사용 시 주의사항
Preview 상태의 제한 사항
| 제한 항목 | 설명 | 영향 |
|---|---|---|
| 버전 변경 가능성 | Preview 단계에서는 사양 및 가격이 조정될 수 있음 | 프로덕션 환경에서는 다운그레이드 방안 마련 권장 |
| 벡터 공간 호환 불가 | 이전 모델의 벡터와 혼용 불가 | 업그레이드 시 전체 인덱스 재구축 필요 |
| 저차원 정규화 필요 | 3,072 차원 미만 사용 시 수동 정규화 필요 | 코드 내 정규화 단계 추가 필요 |
| 엄격한 속도 제한 | Preview 모델의 할당량이 GA 모델보다 낮음 | 대규모 사용 시 할당량 증설 신청 필요 |
| 무료 계층 데이터 사용 | 무료 계층의 데이터는 제품 개선에 사용됨 | 민감 데이터는 유료 계층 사용 권장 |
이전 모델에서 마이그레이션 시 주의사항
- 인덱스 재구축 필수: 모델마다 벡터 공간이 달라 호환되지 않으므로, 동일한 데이터베이스에서 혼용할 수 없습니다.
- 작업 유형 형식 변경:
task_type파라미터에서 프롬프트 내장 명령어로 변경되었습니다. - 정규화 처리: 기본 차원이 아닌 값을 사용할 경우, 코드 내에 정규화 로직을 추가해야 합니다.
- 테스트 후 마이그레이션: 테스트 환경에서 신규 및 이전 모델의 검색 성능을 비교한 후 마이그레이션을 결정하는 것을 권장합니다.
자주 묻는 질문(FAQ)
Q1: Gemini Embedding 2 Preview가 OpenAI text-embedding-3-large보다 나은 점은 무엇인가요?
주요 강점은 세 가지입니다. 첫째, 네이티브 멀티모달 지원(OpenAI는 텍스트만 지원), 둘째, MTEB 다국어 순위 1위(큰 격차), 셋째, 더 높은 코드 임베딩 품질입니다. 다만, OpenAI text-embedding-3-large가 가격 면에서 더 저렴하며($0.13 vs $0.20), 영문 텍스트 임베딩만 필요하다면 두 모델의 품질은 매우 비슷합니다. APIYI(apiyi.com)를 통해 두 모델을 동시에 호출하여 실제 데이터로 직접 비교해 보세요.
Q2: 멀티모달 임베딩은 실제로 어떤 용도로 쓰이나요?
가장 직접적인 활용 사례는 교차 모달 검색입니다. 사용자가 텍스트를 입력하면 관련 이미지, 영상, 문서를 검색 결과로 반환합니다. 예를 들어, 이커머스 환경에서 "빨간색 원피스"라는 텍스트로 상품 이미지를 검색하거나, 기업 지식 베이스에서 텍스트 설명으로 교육 영상의 관련 구간을 찾는 식입니다. 기존 방식은 시각 모델로 설명을 추출한 뒤 텍스트 임베딩을 거쳐야 했지만, Gemini Embedding 2는 원본 이미지/영상을 직접 처리하여 정보 손실이 훨씬 적습니다.
Q3: 차원은 어느 정도가 적당한가요? 768과 3072의 차이가 큰가요?
대부분의 애플리케이션에서는 768 차원이 최적의 균형점입니다. 저장 비용은 3072 차원의 1/4 수준이면서, 검색 품질 저하는 거의 없습니다(Matryoshka 학습 덕분). 데이터셋이 작고(100만 건 미만) 정밀도가 매우 중요하다면 3072 차원을 사용하세요. 데이터 양이 많거나 실시간 검색이 필요하다면 768 차원이나 256 차원도 합리적인 선택입니다.
Q4: APIYI는 Gemini Embedding 2를 어떻게 지원하나요? 추가 설정이 필요한가요?
APIYI(apiyi.com)는 이미 gemini-embedding-2-preview 모델을 지원하고 있습니다. 표준 OpenAI 호환 임베딩 인터페이스를 통해 호출할 수 있으며, 별도의 Google API 키 설정은 필요 없습니다. model 파라미터에 gemini-embedding-2-preview를 지정하기만 하면 되며, 기타 파라미터(dimensions 등)는 OpenAI 임베딩 인터페이스와 완전히 동일합니다.
요약: 멀티모달 임베딩의 새로운 기준
Gemini Embedding 2 Preview는 임베딩 모델의 중요한 이정표를 제시합니다. 바로 순수 텍스트에서 진정한 멀티모달 통합 공간으로의 전환이죠. MTEB 다국어, 영어, 코드 세 가지 부문에서 모두 1위를 차지했으며, 8K 컨텍스트 윈도우와 MRL 차원 조절 기능을 더해 RAG 시스템, 의미론적 검색, 지식 베이스 구축을 위한 최강의 기반을 제공합니다.
핵심 요약:
- 업계 최초의 네이티브 5모달 임베딩 모델 (텍스트+이미지+비디오+오디오+PDF)
- MTEB 다국어 벤치마크 1위, 5점 이상 격차로 선두
- 8,192 토큰 컨텍스트 윈도우, 이전 세대 대비 4배 확장
- MRL 학습 지원으로 128~3,072 차원까지 유연한 조절 가능
- 가격은 100만 토큰당 $0.20로, 멀티모달 시나리오에서 매우 높은 가성비 제공
APIYI(apiyi.com)를 통해 Gemini Embedding 2 Preview를 빠르게 연동해 보세요. 하나의 API 키로 Gemini, OpenAI 등 주요 임베딩 모델을 모두 지원하므로 모델 간 비교와 전환이 매우 간편합니다.
📝 작성자: APIYI 기술팀 | APIYI apiyi.com – 300개 이상의 AI 대규모 언어 모델 API 통합 플랫폼
참고 자료
-
Google 공식 블로그: Gemini Embedding 2 출시 공지
- 링크:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-embedding-2/ - 설명: 모델 설계 철학 및 멀티모달 기능 소개
- 링크:
-
Gemini API 임베딩 문서: 공식 API 사용 가이드
- 링크:
ai.google.dev/gemini-api/docs/embeddings - 설명: 전체 API 파라미터 및 모델 호출 예제
- 링크:
-
Gemini Embedding 연구 논문: 기술 세부 사항 및 벤치마크
- 링크:
arxiv.org/html/2503.07891v1 - 설명: MTEB 상세 테스트 데이터 및 모델 아키텍처 분석
- 링크:
-
Gemini API 가격: 각 모달별 상세 가격 정보
- 링크:
ai.google.dev/gemini-api/docs/pricing - 설명: 텍스트, 이미지, 오디오, 비디오별 항목별 가격 정보
- 링크:





