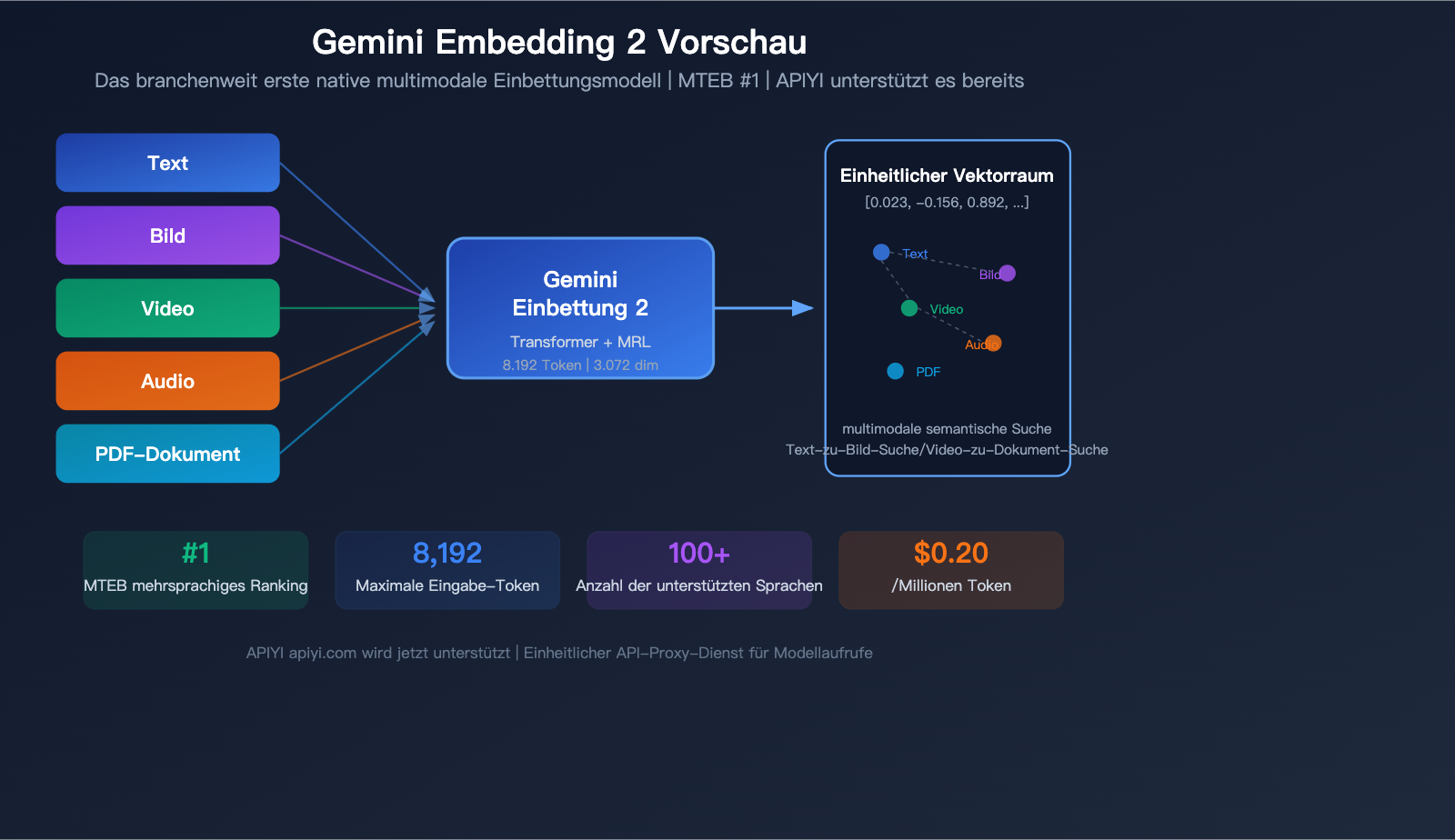
Google hat im März 2026 ein bedeutendes Modell veröffentlicht: Gemini Embedding 2 Preview, das branchenweit erste native multimodale Embedding-Modell. Es ist in der Lage, Text, Bilder, Videos, Audio und PDF-Dokumente einheitlich in denselben Vektorraum abzubilden. Im MTEB-Benchmark für mehrere Sprachen belegt es den 1. Platz und liegt damit mehr als 5 Prozentpunkte vor dem Zweitplatzierten.
Kernnutzen: Nach dem Lesen dieses Artikels kennen Sie die 5 wichtigsten technischen Durchbrüche von Gemini Embedding 2 Preview, den Vergleich von Preis und Leistung gegenüber Wettbewerbern sowie die schnelle Integration über die API.
Was ist Gemini Embedding 2 Preview?
Gemini Embedding 2 Preview ist das neueste Embedding-Modell, das Google am 10. März 2026 veröffentlicht hat. Es basiert auf der Gemini-Architektur, nutzt eine bidirektionale Attention-Transformer-Struktur und ist das erste Embedding-Modell von Google mit nativer Unterstützung für multimodale Eingaben.
| Spezifikation | Details |
|---|---|
| Modell-ID | gemini-embedding-2-preview |
| Veröffentlichungsdatum | 10. März 2026 |
| Status | Preview (Vorschauversion, finale Version folgt) |
| Standard-Ausgabedimension | 3.072 |
| Wählbarer Dimensionsbereich | 128 — 3.072 |
| Maximale Eingabe-Token | 8.192 (4x mehr als beim Vorgänger) |
| Multimodale Unterstützung | Text, Bild, Video, Audio, PDF |
| Sprachunterstützung | Über 100 Sprachen |
| Matryoshka-Training | Unterstützt (Dimensionen können für Effizienz gekürzt werden) |
| Verfügbare Plattformen | Gemini API, Vertex AI, APIYI apiyi.com |
Wichtige Unterschiede zum Vorgängermodell
| Merkmal | text-embedding-004 | gemini-embedding-001 | gemini-embedding-2-preview |
|---|---|---|---|
| Max. Eingabe-Token | 2.048 | 2.048 | 8.192 |
| Ausgabedimension | Max. 768 | 128-3.072 | 128-3.072 |
| Multimodal | Nur Text | Nur Text | Text+Bild+Video+Audio+PDF |
| Aufgabentyp-Angabe | task_type-Feld |
task_type-Feld |
Prompt-eingebettete Anweisung |
| MRL-Unterstützung | Nicht unterstützt | Unterstützt | Unterstützt |
| Preis/Million Token | Eingestellt | $0,15 | $0,20 |
🎯 Hinweis zur Anbindung: APIYI apiyi.com unterstützt bereits den Modellaufruf für gemini-embedding-2-preview.
Die Anbindung erfolgt über die OpenAI-kompatible Schnittstelle, ohne dass ein separater Google API-Schlüssel konfiguriert werden muss.
Die 5 wichtigsten technischen Durchbrüche im Detail
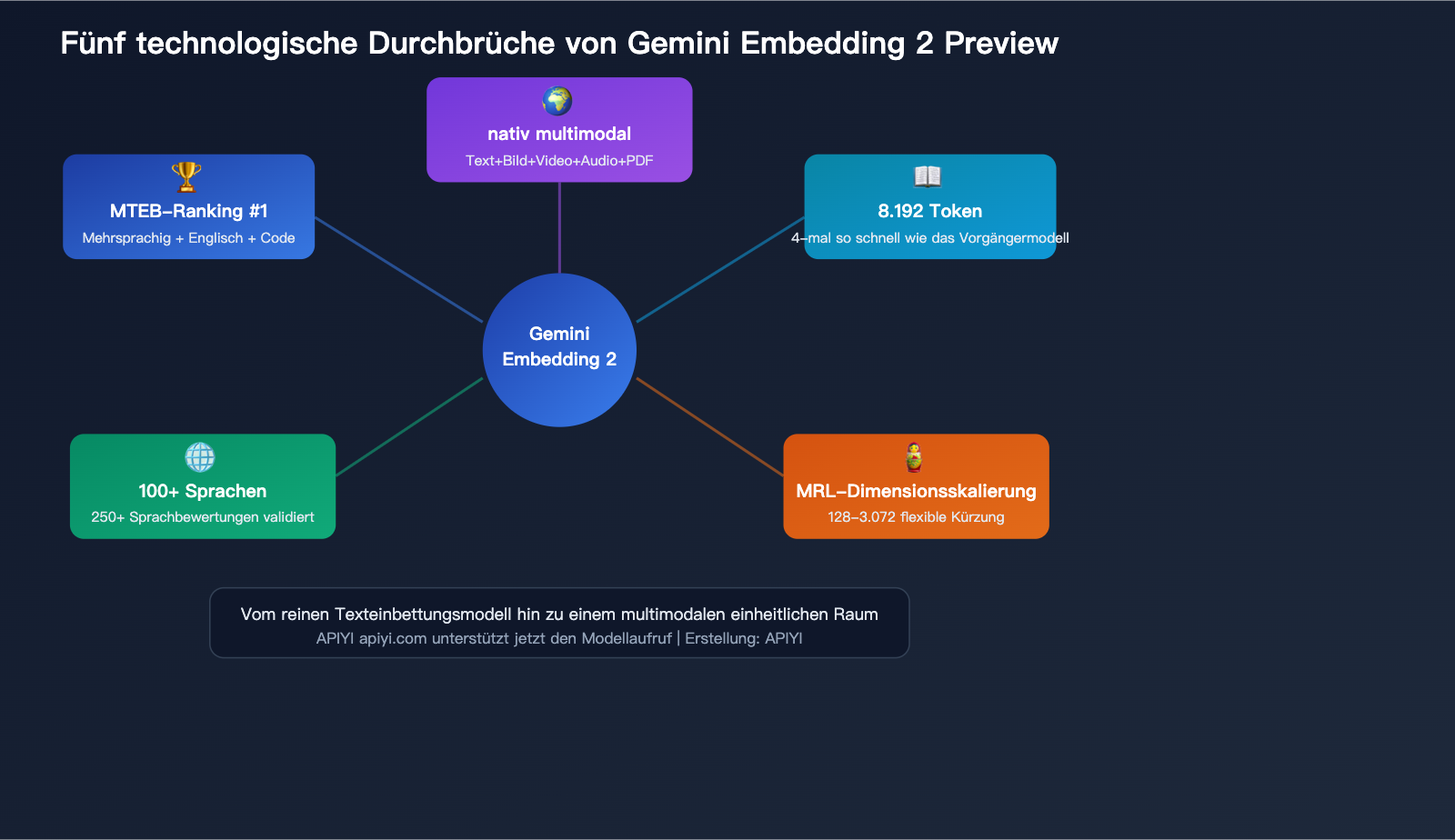
Durchbruch 1: Nativer multimodaler gemeinsamer Einbettungsraum
Dies ist der größte Differenzierungsvorteil von Gemini Embedding 2 – Inhalte aus 5 Modalitäten werden in denselben Vektorraum abgebildet.
| Modalität | Formatvorgaben | Limit pro Anfrage | Hinweis |
|---|---|---|---|
| Text | Klartext | 8.192 Token | Unterstützt 100+ Sprachen |
| Bild | PNG, JPEG | Max. 6 pro Anfrage | Direkte Pixelverarbeitung |
| Video | MP4, MOV | Max. 120 Sekunden | Automatische Abtastung von bis zu 32 Frames |
| Audio | MP3, WAV | Max. 80 Sekunden | Native Verarbeitung, keine Transkription nötig |
| PDF-Dokument | Max. 6 Seiten pro Anfrage | Inklusive OCR-Fähigkeit |
Praktische Anwendungsszenarien:
- Bildsuche per Text ("Roter Sportwagen auf der Rennstrecke" → liefert passende Bilder)
- Suche nach ähnlichen Videosequenzen per Bild
- Suche in Dokumenten per Sprachbeschreibung
- Aufbau einer modalitätsübergreifenden Wissensdatenbank
Dies war mit früheren Embedding-Modellen nicht möglich – die text-embedding-3-Serie von OpenAI unterstützt nur Text. Für eine Bildsuche müsste man erst ein visuelles Modell zur Beschreibung nutzen, was einen zusätzlichen Schritt erfordert und zu Informationsverlusten führt.
Durchbruch 2: 8.192 Token Kontextfenster
Das Eingabefenster wurde von 2.048 auf 8.192 Token erweitert, was bedeutet, dass längere Dokumentenabschnitte in einem Durchgang eingebettet werden können.
Für RAG-Systeme (Retrieval-Augmented Generation) ist diese Verbesserung äußerst nützlich:
- Bisher mussten Dokumente in kleine Stücke von 500–1.000 Token zerlegt werden.
- Jetzt können größere Abschnitte von 2.000–4.000 Token verwendet werden, um mehr Kontext zu bewahren.
- Größere Dokumentenabschnitte = weniger Segmentierung = vollständigere Suchergebnisse.
Durchbruch 3: Matryoshka-Dimensionsskalierung
Gemini Embedding 2 nutzt Matryoshka Representation Learning (MRL). Das Modell konzentriert die wichtigsten semantischen Informationen in den ersten Dimensionen des Vektors.
Dadurch können Sie die Dimensionen flexibel an Ihr Szenario anpassen:
| Dimension | Vektorgröße | Anwendungsfall | Qualitätsverlust |
|---|---|---|---|
| 3.072 (Standard) | 12,3 KB | Höchste Suchpräzision | Keiner |
| 1.536 | 6,1 KB | Balance zwischen Präzision und Speicher | Minimal |
| 768 | 3,1 KB | Bevorzugt für große Deployments | Gering |
| 256 | 1,0 KB | Echtzeit-Empfehlungssysteme | Mittel |
| 128 | 0,5 KB | Extreme Komprimierung | Deutlich |
Hinweis: Bei Verwendung von Dimensionen unter 3.072 müssen die Vektoren vor der Ähnlichkeitsberechnung manuell normalisiert werden.
Durchbruch 4: Unterstützung für über 100 Sprachen
Im MTEB-Benchmark für Mehrsprachigkeit wurde Gemini Embedding 2 in über 250 Sprachen getestet und deckt damit einen weitaus größeren Bereich ab als die Konkurrenz.
Wichtige Leistungsindikatoren für Sprachen:
- Bitext Mining: 79,32 Punkte
- Sprachübergreifende Suche (XOR-Retrieve): Recall@5kt 90,42 Punkte
- Mehrsprachiges Verständnis (XTREME-UP): MRR@10 64,33 Punkte
Durchbruch 5: Platz 1 in mehreren MTEB-Rankings
| Benchmark | Punktzahl | Rang | Vorsprung |
|---|---|---|---|
| MTEB Mehrsprachig (Mean Task) | 68,32 | Platz 1 | +5,09 |
| MTEB Mehrsprachig (Mean Type) | 59,64 | Platz 1 | — |
| MTEB Englisch v2 (Mean Task) | 73,30 | Platz 1 | — |
| MTEB Englisch v2 (Mean Type) | 67,67 | Platz 1 | — |
| MTEB Code (Mean All) | 74,66 | Platz 1 | — |
Zum Vergleich: Das zweitplatzierte Modell gte-Qwen2-7B-instruct erreichte im mehrsprachigen MTEB 62,51 Punkte – Gemini Embedding 2 führt mit fast 6 Punkten Vorsprung, was im Bereich der Embedding-Modelle ein enormer Abstand ist.
💡 Entwickler-Tipp: Wenn Sie ein RAG-System oder eine semantische Suche aufbauen,
ist Gemini Embedding 2 aktuell die stärkste Wahl für mehrsprachige und Code-Szenarien.
Über APIYI apiyi.com können Sie das Modell mit einem Klick einbinden und gleichzeitig
OpenAI-Embedding-Modelle nutzen, um Ergebnisse schnell zu vergleichen.
Preis- und Leistungsvergleich mit Wettbewerbern
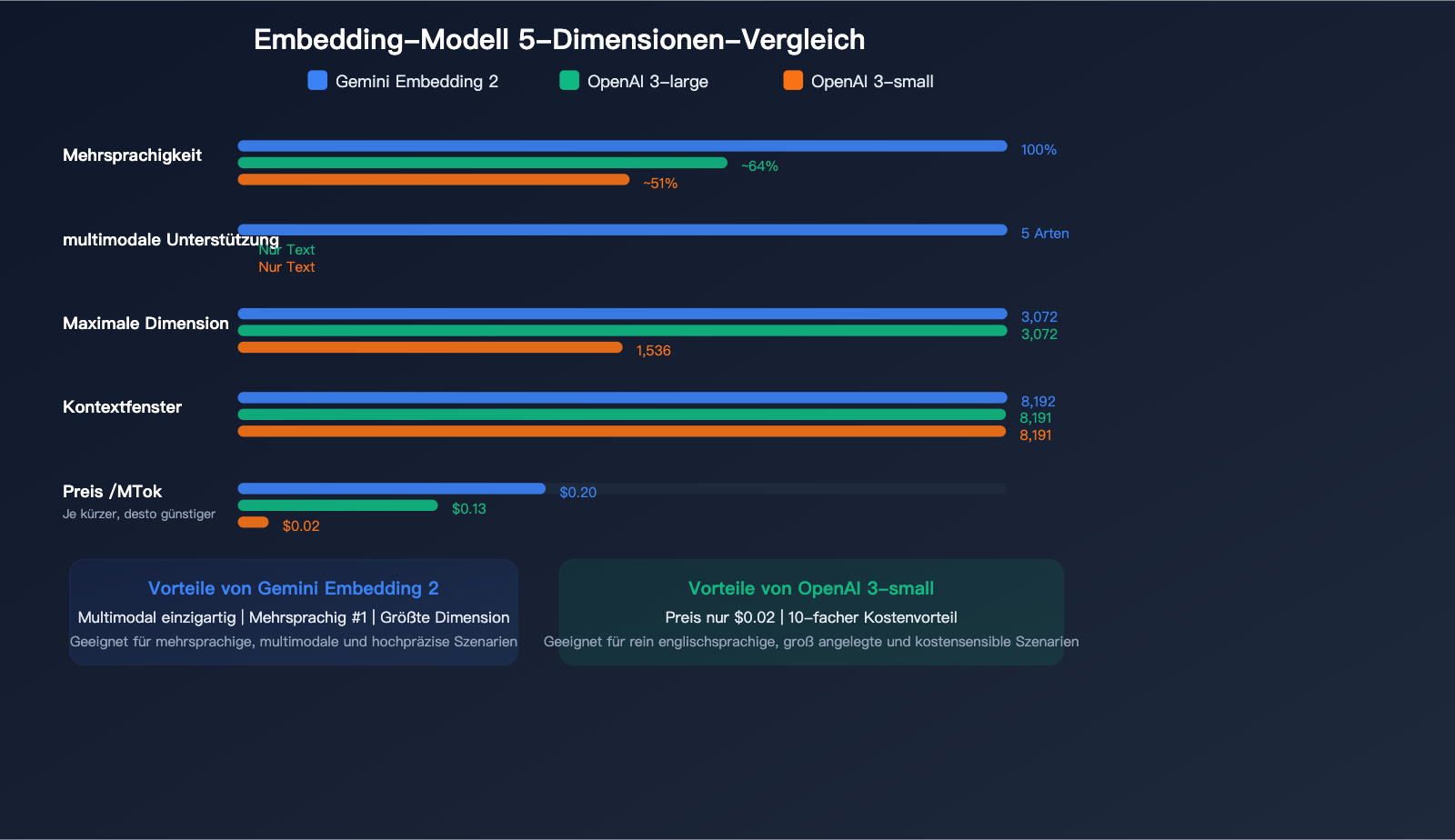
Vergleich der Preisgestaltung für Text-Embeddings
| Modell | Preis/Million Token | Max. Dimension | Max. Eingabe | Multimodal | Mehrsprachigkeits-Ranking |
|---|---|---|---|---|---|
| Gemini Embedding 2 | $0,20 | 3.072 | 8.192 | ✅ Multimodal | #1 |
| gemini-embedding-001 | $0,15 | 3.072 | 2.048 | ❌ | — |
| OpenAI text-embedding-3-large | $0,13 | 3.072 | 8.191 | ❌ | — |
| OpenAI text-embedding-3-small | $0,02 | 1.536 | 8.191 | ❌ | — |
Preisgestaltung für multimodale Inhalte (exklusiv für Gemini Embedding 2):
| Eingabetyp | Preis/Million Token | Batch-Preis/Million Token |
|---|---|---|
| Text | $0,20 | $0,10 |
| Bild | $0,45 (~$0,00012/Bild) | $0,225 |
| Audio | $6,50 (~$0,00016/Sek.) | $3,25 |
| Video | $12,00 (~$0,00079/Frame) | $6,00 |
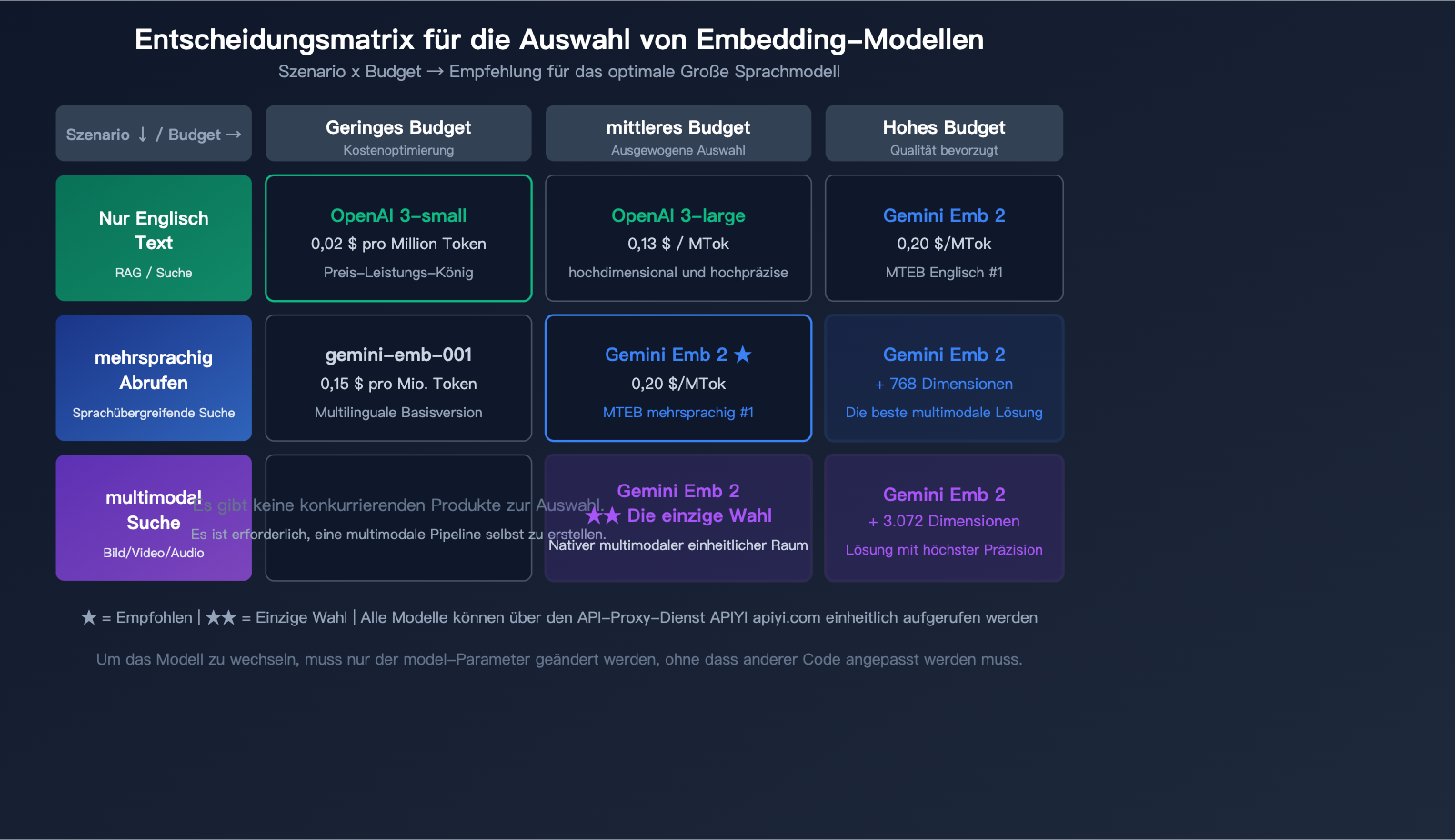
Empfehlungen zur Modellauswahl
| Anforderungsszenario | Empfohlenes Modell | Grund |
|---|---|---|
| Nur Text, kostenbewusst | OpenAI text-embedding-3-small | Am günstigsten ($0,02) |
| Nur Text, hohe Präzision | Gemini Embedding 2 oder OpenAI 3-large | Ähnliche Präzision, Gemini bei Mehrsprachigkeit stärker |
| Multimodale Suche | Gemini Embedding 2 | Einzige native multimodale Lösung |
| Mehrsprachige Suche | Gemini Embedding 2 | MTEB Mehrsprachigkeit #1 |
| Codesuche | Gemini Embedding 2 | MTEB Code #1 |
| Groß angelegt, kostengünstig | OpenAI 3-small + Batch-API | 10-facher Preisvorteil |
🎯 Auswahlempfehlung: Die Wahl des Embedding-Modells hängt von Ihrem spezifischen Szenario ab.
Wir empfehlen, sowohl Gemini- als auch OpenAI-Embedding-Modelle über die APIYI-Plattform (apiyi.com) einzubinden,
um die Suchergebnisse mit echten Daten zu vergleichen, bevor Sie eine Entscheidung treffen. Die Plattform unterstützt einheitliche Schnittstellenaufrufe, sodass Sie das Modell wechseln können, ohne den Code anzupassen.
Detaillierte Anleitung zum API-Aufruf
Festlegen des Aufgabentyps (Wichtige Änderung)
Im Gegensatz zu gemini-embedding-001 verwendet Gemini Embedding 2 keinen task_type-Parameter mehr. Stattdessen wird der Aufgabentyp direkt durch Einbetten von Anweisungen in den Eingabetext definiert.
8 unterstützte Aufgabentypen:
| Aufgabentyp | Format für Abfragen | Format für Dokumente |
|---|---|---|
| Suche/Retrieval | task: search result | query: {Inhalt} |
title: {Titel} | text: {Inhalt} |
| Frage-Antwort | task: question answering | query: {Frage} |
title: {Titel} | text: {Inhalt} |
| Faktencheck | task: fact checking | query: {Behauptung} |
title: {Titel} | text: {Inhalt} |
| Code-Suche | task: code retrieval | query: {Beschreibung} |
title: {Titel} | text: {Code} |
| Klassifizierung | task: classification | query: {Inhalt} |
Gleiches Format |
| Clustering | task: clustering | query: {Inhalt} |
Gleiches Format |
| Satzähnlichkeit | task: sentence similarity | query: {Satz} |
Gleiches Format |
Für Dokumente ohne Titel verwenden Sie bitte title: none.
Python-Aufrufbeispiel
import openai
# Aufruf über die einheitliche APIYI-Schnittstelle
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# Texteinbettung - Suchszenario
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input="task: search result | query: Was ist eine Vektordatenbank",
dimensions=768 # Optionale Dimensionen: 128-3072
)
embedding = response.data[0].embedding
print(f"Vektordimension: {len(embedding)}")
print(f"Erste 5 Werte: {embedding[:5]}")
Vollständigen RAG-Retrieval-Prozess anzeigen
import openai
import numpy as np
from typing import List
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def get_embedding(text: str, task: str = "search result", dim: int = 768) -> List[float]:
"""Einbettungsvektor abrufen"""
formatted = f"task: {task} | query: {text}"
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input=formatted,
dimensions=dim
)
vec = response.data[0].embedding
# MRL-Dimensionen müssen manuell normalisiert werden
if dim < 3072:
norm = np.linalg.norm(vec)
vec = (np.array(vec) / norm).tolist()
return vec
def get_doc_embedding(title: str, text: str, dim: int = 768) -> List[float]:
"""Dokument-Einbettungsvektor abrufen"""
formatted = f"title: {title} | text: {text}"
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input=formatted,
dimensions=dim
)
vec = response.data[0].embedding
if dim < 3072:
norm = np.linalg.norm(vec)
vec = (np.array(vec) / norm).tolist()
return vec
def cosine_similarity(a: List[float], b: List[float]) -> float:
"""Kosinus-Ähnlichkeit berechnen"""
a, b = np.array(a), np.array(b)
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# Anwendungsbeispiel
query_vec = get_embedding("Wie optimiert man RAG-Retrieval-Ergebnisse")
doc_vec = get_doc_embedding(
"RAG-Optimierungsleitfaden",
"Dieser Artikel stellt 5 Methoden zur Optimierung der RAG-Retrieval-Qualität vor..."
)
similarity = cosine_similarity(query_vec, doc_vec)
print(f"Ähnlichkeit: {similarity:.4f}")
🚀 Schnellstart: Wir empfehlen die Plattform APIYI (apiyi.com) für eine schnelle Anbindung von Gemini Embedding 2.
Die Plattform bietet eine OpenAI-kompatible Embedding-Schnittstelle, die in 5 Minuten integriert ist,
und unterstützt den einheitlichen Aufruf von führenden Modellen wie OpenAI, Gemini und Cohere.
Hinweise zur Verwendung
Einschränkungen im Preview-Status
| Einschränkung | Beschreibung | Auswirkung |
|---|---|---|
| Versionsänderungen | Spezifikationen und Preise können sich in der Preview-Phase ändern | Fallback-Lösungen für die Produktion empfohlen |
| Inkompatible Vektorräume | Nicht mit Vektoren alter Modelle mischbar | Upgrade erfordert vollständige Neuindizierung |
| Normalisierung bei niedrigen Dimensionen | Manuelle Normalisierung bei < 3.072 Dimensionen erforderlich | Normalisierungsschritt im Code ergänzen |
| Strenge Ratenbegrenzung | Kontingente für Preview-Modelle sind niedriger als für GA-Modelle | Bei großflächigem Einsatz Kontingenterhöhung beantragen |
| Datennutzung im Free-Tier | Daten im kostenlosen Tarif werden zur Produktverbesserung genutzt | Für sensible Daten kostenpflichtigen Tarif nutzen |
Hinweise zur Migration von alten Modellen
- Neuindizierung erforderlich: Vektorräume verschiedener Modelle sind inkompatibel und können nicht in derselben Datenbank gemischt werden.
- Geändertes Aufgabenformat: Umstellung vom
task_type-Parameter auf eingebettete Anweisungen im Prompt. - Normalisierung: Bei Verwendung von Nicht-Standard-Dimensionen muss die Normalisierungslogik im Code hinzugefügt werden.
- Effektivität testen: Es wird empfohlen, die Retrieval-Ergebnisse der neuen und alten Modelle in einer Testumgebung zu vergleichen, bevor eine Migration erfolgt.
Häufig gestellte Fragen
Q1: Was macht Gemini Embedding 2 Preview besser als OpenAI text-embedding-3-large?
Die Hauptvorteile liegen in drei Bereichen: native multimodale Unterstützung (OpenAI unterstützt nur Text), Platz 1 im MTEB-Ranking für mehrere Sprachen (mit großem Vorsprung) und eine höhere Qualität bei Code-Embeddings. OpenAI text-embedding-3-large ist jedoch günstiger ($0,13 vs. $0,20). Wenn Sie nur englische Texteinbettungen benötigen, ist die Qualität beider Modelle sehr ähnlich. Über APIYI (apiyi.com) können Sie beide Modelle mit echten Daten vergleichen.
Q2: Welchen praktischen Nutzen haben multimodale Embeddings?
Die direkteste Anwendung ist die kreuzmodale Suche: Nutzer geben Text ein und erhalten relevante Bilder, Videos oder Dokumente als Ergebnis. Im E-Commerce-Bereich könnte man beispielsweise nach "rotes Kleid" suchen und entsprechende Produktbilder erhalten, oder in einer Unternehmensdatenbank per Textbeschreibung nach relevanten Ausschnitten in Schulungsvideos suchen. Herkömmliche Methoden erforderten oft ein visuelles Modell zur Beschreibungsextraktion vor der Einbettung; Gemini Embedding 2 verarbeitet Rohbilder/-videos direkt, was den Informationsverlust minimiert.
Q3: Welche Dimension ist am besten geeignet? Gibt es große Unterschiede zwischen 768 und 3072?
Für die meisten Anwendungen ist 768 die optimale Balance – die Speicherkosten betragen nur ein Viertel der 3072-Dimension, bei minimalem Verlust der Abrufqualität (dank Matryoshka-Training). Wenn Ihr Datensatz klein ist (< 1 Million Einträge) und Sie höchste Präzision benötigen, verwenden Sie 3072. Bei großen Datenmengen oder Echtzeitanforderungen sind 768 oder sogar 256 eine sinnvolle Wahl.
Q4: Wie unterstützt APIYI Gemini Embedding 2? Ist eine zusätzliche Konfiguration erforderlich?
APIYI (apiyi.com) unterstützt bereits das Modell gemini-embedding-2-preview. Der Aufruf erfolgt über die standardmäßige, OpenAI-kompatible Embedding-Schnittstelle, ohne dass ein zusätzlicher Google API-Schlüssel erforderlich ist. Geben Sie einfach gemini-embedding-2-preview im Parameter model an; andere Parameter (wie dimensions) sind identisch mit der OpenAI-Schnittstelle.
Fazit: Ein neuer Maßstab für multimodale Embeddings
Gemini Embedding 2 Preview markiert einen bedeutenden Meilenstein für Embedding-Modelle – den Übergang von reinem Text zu einem wahrhaft einheitlichen multimodalen Raum. Mit dem ersten Platz in den MTEB-Kategorien Mehrsprachigkeit, Englisch und Code, gepaart mit einem 8K-Kontextfenster und MRL-Dimensionsskalierung, bietet es die derzeit stärkste Grundlage für RAG-Systeme, semantische Suche und den Aufbau von Wissensdatenbanken.
Die wichtigsten Punkte im Überblick:
- Erstes natives Fünf-Modalitäten-Embedding-Modell der Branche (Text + Bild + Video + Audio + PDF)
- Platz 1 im MTEB-Benchmark für Mehrsprachigkeit mit über 5 Punkten Vorsprung
- 8.192 Token Kontextfenster, viermal so groß wie bei der Vorgängergeneration
- MRL-Training unterstützt flexible Dimensionsskalierung von 128 bis 3.072
- Preis von 0,20 $ pro Million Token, extrem kosteneffizient für multimodale Szenarien
Wir empfehlen den schnellen Zugriff auf Gemini Embedding 2 Preview über APIYI (apiyi.com). Mit einem einzigen API-Schlüssel können Sie sowohl Gemini als auch andere gängige Embedding-Modelle wie OpenAI nutzen, was Vergleiche und Wechsel erheblich vereinfacht.
📝 Autor dieses Artikels: APIYI Technical Team | APIYI apiyi.com – Die einheitliche API-Plattform für über 300 KI-Großsprachmodelle
Referenzen
-
Offizieller Google-Blog: Ankündigung zur Veröffentlichung von Gemini Embedding 2
- Link:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-embedding-2/ - Beschreibung: Enthält Informationen zum Designkonzept des Modells und zu den multimodalen Fähigkeiten.
- Link:
-
Gemini API Embedding-Dokumentation: Offizieller API-Leitfaden
- Link:
ai.google.dev/gemini-api/docs/embeddings - Beschreibung: Vollständige API-Parameter und Anwendungsbeispiele.
- Link:
-
Gemini Embedding Forschungsarbeit: Technische Details und Benchmarks
- Link:
arxiv.org/html/2503.07891v1 - Beschreibung: Detaillierte MTEB-Testdaten und Analyse der Modellarchitektur.
- Link:
-
Gemini API-Preisgestaltung: Detaillierte Preisinformationen für die einzelnen Modalitäten
- Link:
ai.google.dev/gemini-api/docs/pricing - Beschreibung: Aufgeschlüsselte Preise für Text, Bild, Audio und Video.
- Link: