2026年には、コードコミットの41%がすでにAIによって生成されたものとなっています。しかし、AIが生成したコードの欠陥率は人間が書いたコードの1.7倍に達しています。コード生成のスピードは加速する一方で、コードレビューの生産性は著しく不足しており、2026年には40%の品質ギャップが生じると予測されています。
AIコードレビューは「やるべきか否か」の問題ではなく、「いかにうまく活用するか」という問題です。本記事では、実証済みの7つのベストプラクティスを紹介するとともに、なぜClaude Opus 4.6とSonnet 4.6が現在コードレビューに最適なAIモデルであるのかを深く分析します。
核心的価値: 本記事を読み終えることで、AIコードレビューの完全なワークフローを習得し、チームのコード品質を向上させるために最適なモデルの選び方を理解することができます。
AIコードレビューの現状:なぜ今、重視すべきなのか
2026年のコードレビューが直面する課題
| 課題 | データ | 影響 |
|---|---|---|
| AI生成コードの急増 | 提出コードの41%がAI支援によるもの | レビュー需要の激増 |
| AIコードの欠陥率 | 人間のコードより1.7倍高い | より厳格なレビューが必要 |
| 品質ギャップ | 2026年には40%の不足が予測される | レビュー能力が生成速度に追いつかない |
| セキュリティリスク | AIコードの45%にOWASP Top 10の脆弱性が含まれる | セキュリティレビューが急務 |
| 提案採用率 | AIの提案は16.6%のみ(人間は56.5%) | AIレビューの品質向上に課題 |
AIコードレビュー vs 人間によるコードレビュー
AIは人間のレビュアーを置き換えるものではなく、人間のレビュー能力を強化するためのものです。AIコードレビューを導入したチームからは、以下のような報告が上がっています。
- レビュー時間が40〜60%短縮
- 欠陥検出率の向上 — 特にセキュリティ脆弱性や境界条件において顕著
- コードスタイルの一貫性が大幅に改善
一方で、AIレビューには明確な限界もあります。
- ❌ ビジネス上の納期やプロジェクトの背景を理解できない
- ❌ レガシーシステムにおける歴史的な妥協を察知できない
- ❌ レビューに対する最終責任を負えない
- ❌ チームの知識継承やメンターとしての役割は果たせない
🎯 ベスト戦略: AIが一次スキャン(スタイル、バグ、セキュリティ)を行い、人間が最終判断(アーキテクチャ、意図、リスク)を行う。APIYI(apiyi.com)プラットフォームを通じてClaude Opus 4.6やSonnet 4.6のAPIを呼び出すことで、AIコードレビューを既存のCI/CDフローに迅速に統合できます。
AIコードレビューの7つのベストプラクティス
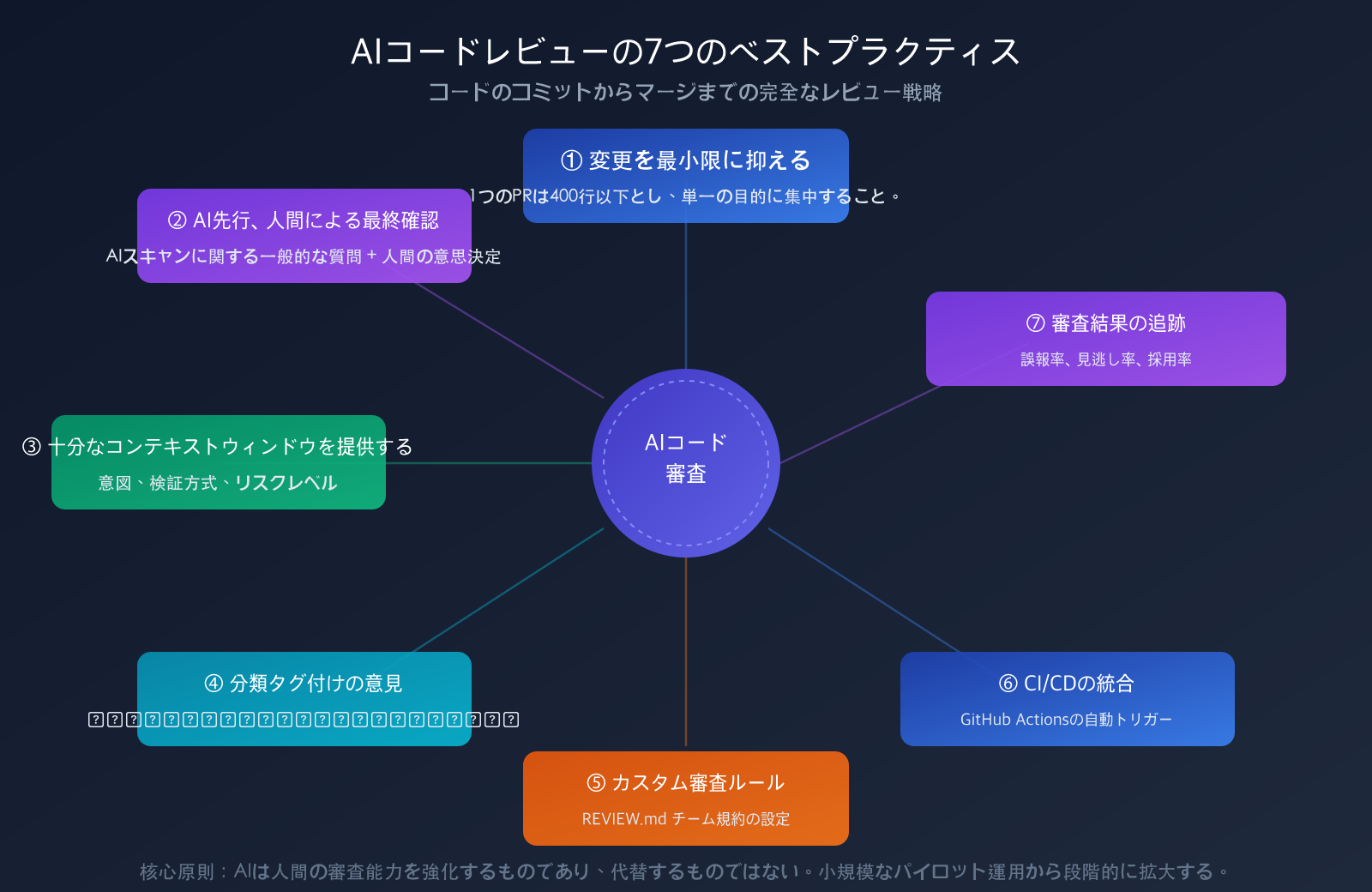
実践1:変更を小さく、焦点を絞る
AIレビュアーは、diffが1000行を超えると一貫性を著しく失います。Claude Opus 4.6は100万トークンのコンテキストウィンドウを持っていますが、大規模な変更よりも小規模な変更の方がレビュー品質は高くなります。
具体的な手法:
- 1つのPRを200〜400行以内に抑える
- 大規模なリファクタリングは、論理的に独立した複数のPRに分割する
- 1つのPRにつき1つの目的のみとする
実践2:AI先行、人間による最終審査
最も効果的なワークフローは「二層レビュー」モデルです:
コード提出 → AI自動レビュー (一次審査)
↓
問題の指摘 + 重大度分類
↓
人間がハイリスク領域に集中 (最終審査)
↓
マージまたは却下
AIは一般的な問題(スタイル、命名、デッドコード、単純なバグ)をスキャンし、人間は以下に集中します:
- アーキテクチャの妥当性
- ビジネスロジックの正確性
- セキュリティ上の重要な判断
- パフォーマンスへの影響評価
実践3:十分なコンテキストを提供する
AIレビュアーに提供する情報が多いほど、レビュー品質は向上します。PRの記述には以下を含めることを推奨します:
## 変更の目的
この変更を行った理由を1〜2文で簡潔に説明してください。
## 検証方法
- [ ] ユニットテストを通過
- [ ] XXのシナリオで手動テストを実施済み
- [ ] パフォーマンスの低下なし
## リスクレベル
低/中/高 + 説明
## AI支援に関する宣言
今回の変更において、XXの部分はAIによって生成されました。重点的にレビューを行ってください。
## 注力すべき領域
`src/auth/` ディレクトリ配下の権限ロジックの変更点に重点を置いてください。
実践4:レビューコメントの階層化とタグ付け
AIによるレビューでよくある問題は「ノイズが多すぎる」ことです。スタイルの提案と重大なバグが混在してしまうと、開発者が重要なフィードバックを見落としてしまう原因になります。
推奨される重大度タグ:
| タグ | 意味 | 対応方針 |
|---|---|---|
| 🔴 Bug | マージ前に修正必須の欠陥 | マージをブロック |
| 🟡 Nit | 修正すべきだがブロックはしない軽微な問題 | 任意で修正 |
| 🟣 Pre-existing | 今回の変更で発生したものではない既存の問題 | 記録するがブロックしない |
| 💡 Suggestion | 改善提案 | 議論の上で決定 |
Claude Codeのネイティブなコードレビュー機能では、すでにこの階層システム(Red/Yellow/Purple)が実装されています。
実践5:レビュールールのカスタマイズ
汎用的なAIレビューは、チームのコーディング規約に合わない場合があります。設定ファイルを通じてレビューの挙動をカスタマイズしましょう:
# REVIEW.md (プロジェクトのルートディレクトリに配置)
## 必須チェック項目
- すべてのデータベースクエリにはパラメータ化されたステートメントを使用すること
- APIエンドポイントには必ず認証ミドルウェアを含めること
- すべてのユーザー入力に対してバリデーションを行うこと
スキップしても良いこと
- CSSクラス名の命名スタイル(Prettierで自動フォーマット済み)
- importの順序(Ruffで自動処理済み)
- コメントの言語(中国語・英語どちらでも可)
チームの規約
- 継承よりもコンポジションを優先する
- エラーハンドリングにはResultパターンを使用する
- ログレベル:ビジネスイベントはINFO、デバッグはDEBUGを使用する
実践6:CI/CDパイプラインへの統合
AIによるコードレビューは、手動ではなく自動化されるべきです。
推奨される統合方法:
# GitHub Actions の例
name: AI Code Review
on:
pull_request:
types: [opened, synchronize]
jobs:
ai-review:
runs-on: ubuntu-latest
steps:
- uses: anthropics/claude-code-action@v1
with:
anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }}
review_mode: "auto"
また、APIを直接呼び出してClaudeモデルによるカスタムレビューを行うことも可能です:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYIの統一インターフェース
)
diff_content = open("pr_diff.patch").read()
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "system", "content": """あなたは熟練のコードレビュー専門家です。
以下のコード変更を分析し、重要度別に分類してください:
- 🔴 Bug: 修正必須
- 🟡 Nit: 修正推奨
- 💡 Suggestion: 改善案
各問題について、具体的な行番号と修正案を提示してください。"""},
{"role": "user", "content": f"以下のコード変更をレビューしてください:\n\n{diff_content}"}
],
max_tokens=8192
)
print(response.choices[0].message.content)
実践7:レビュー効果の追跡
AIコードレビューは、導入して終わりではありません。重要な指標を継続的に追跡する必要があります:
- 誤検知率 (False Positive Rate): AIが指摘した問題のうち、実際に問題であったものの割合
- 見逃し率 (False Negative Rate): リリース後に発覚したバグのうち、AIが検知できなかった割合
- 採用率: 開発者がAIの提案を実際に採用した割合
- レビュー時間の変化: 人間のレビュアーの平均レビュー時間が短縮されたか
💡 導入のアドバイス: チームでAIコードレビューを初めて試す場合は、重要度の低いパスのPRから試験的に導入することをお勧めします。APIYI (apiyi.com) を通じてClaude Sonnet 4.6を呼び出すことで、Opusの5分の1のコストでOpusに近い品質のレビューが可能です。これが最もコストパフォーマンスの高いスタート地点となります。
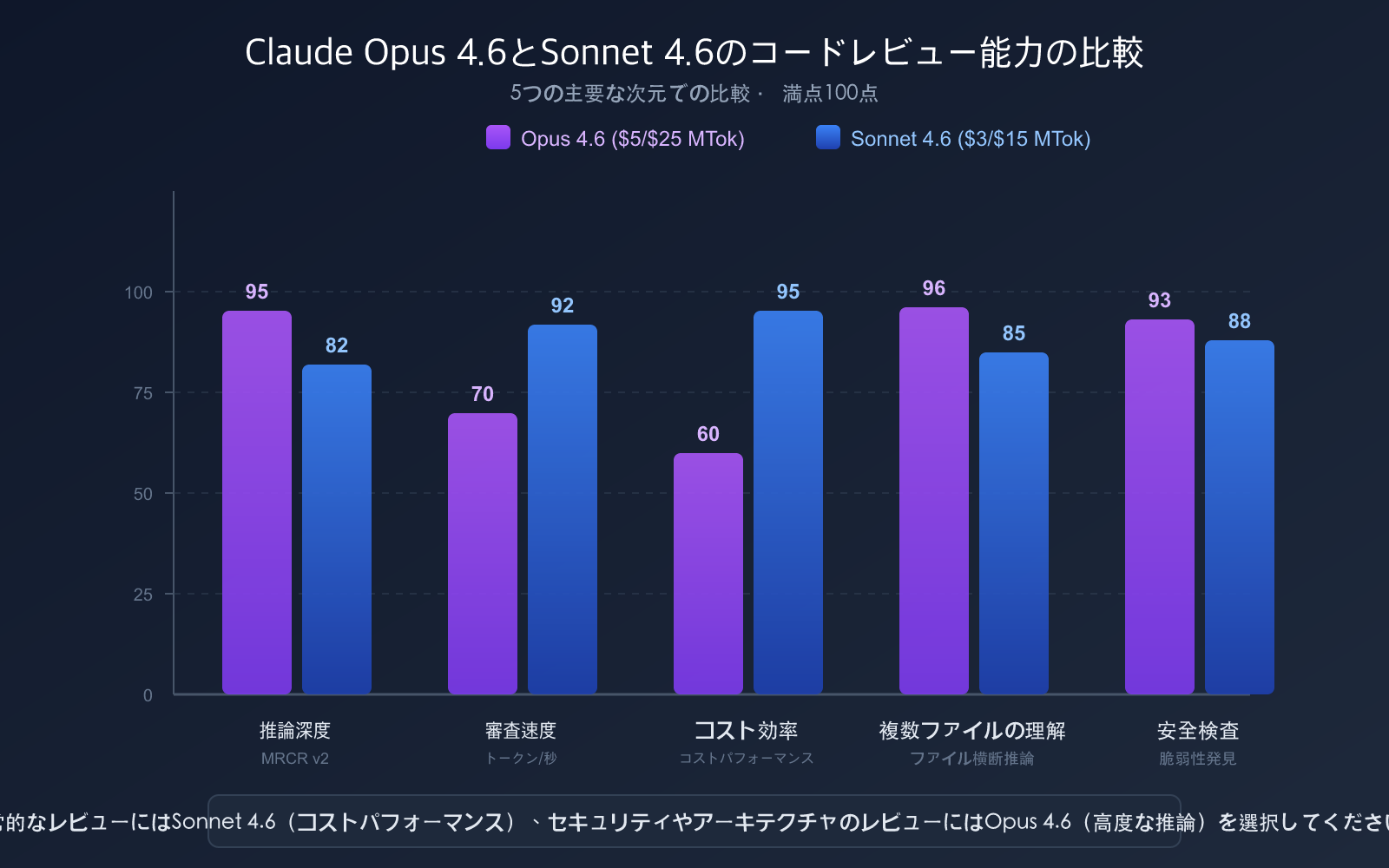
なぜコードレビューに Claude Opus 4.6 と Sonnet 4.6 が推奨されるのか
数ある AI モデルの中でも、Claude 4.6 シリーズはコードレビューの現場において際立った強みを発揮します。
Claude 4.6 モデルの主要スペック比較
| パラメータ | Claude Opus 4.6 | Claude Sonnet 4.6 |
|---|---|---|
| モデル ID | claude-opus-4-6 |
claude-sonnet-4-6 |
| リリース日 | 2026年2月5日 | 2026年2月17日 |
| コンテキストウィンドウ | 100万トークン (ベータ) | 100万トークン (ベータ) |
| 最大出力 | 128K トークン | 64K トークン |
| SWE-bench Verified | 81.42% | 79.6% |
| 価格 (入力/出力) | $5/$25 (100万トークンあたり) | $3/$15 (100万トークンあたり) |
| 適した用途 | 複雑なアーキテクチャのレビュー、セキュリティ監査 | 日常的な PR レビュー、スタイルチェック |
| APIYI 価格 | さらにお得 | さらにお得 |
強み 1:100万トークンのコンテキストウィンドウ
これはコードレビューにおいて最も重要な技術的アドバンテージです。
大規模プロジェクトの PR では、数十ものファイルが変更されることも珍しくありません。従来の AI モデルではコンテキストウィンドウの制限によりコードを切り詰める必要があり、レビュー担当者が全体像を把握できないという問題がありました。
Claude 4.6 の 100万トークンのコンテキストウィンドウなら、以下を一度に読み込めます:
- PR の完全な diff (通常数百から数千行)
- 関連ファイルの全コード (インポートチェーン、呼び出される関数など)
- 依存関係グラフと型定義
- テストファイルと設定ファイル
- プロジェクトの README やアーキテクチャドキュメント
これにより、AI は熟練の開発者のように、全体的な文脈を理解した上でレビューを行うことができます。
強み 2:最高レベルのファイル横断的な推論能力
コードレビューの真の価値は、単なる構文エラーの指摘ではなく、ファイル間をまたぐ論理的な問題を発見することにあります。
Claude Opus 4.6 は MRCR v2 (マルチホップ・マルチファイル検索推論) テストにおいて 76% のスコアを記録し、Sonnet 4.5 の 18.5% を大きく引き離しました。これは Opus 4.6 が以下のシナリオで卓越した性能を発揮することを意味します:
- A ファイルでインターフェースを変更した際、B ファイル側の呼び出しが同期して更新されていないことを検知する
- 入力からデータベースに至るデータフロー全域でのバリデーション漏れを発見する
- 並行処理環境における競合状態 (レースコンディション) を特定する
実際のケース: テストにおいて、Claude Opus 4.6 は 2400 行に及ぶデータベース移行 PR の中で、移行が途中で中断された場合にのみ発生するロールバックロジックの欠陥(競合状態)を発見しました。これは自動テストではカバーしきれないシナリオです。
強み 3:適応型の思考深度
Claude 4.6 では adaptive thinking モードが導入されました。AI が問題の複雑さに応じて、自動的に「どれだけ深く考えるか」を決定します。
import openai
# APIYI を介したクライアント設定
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "system", "content": "このコード変更にセキュリティ上の問題がないかレビューしてください。"},
{"role": "user", "content": diff_content}
],
# Claude 4.6 の適応型思考:単純な問題は素早く、複雑な問題は深く分析
extra_body={"thinking": {"type": "adaptive"}}
)
- 単純なスタイルの問題 → 素早く判断し、トークンを節約
- 複雑な並行処理やセキュリティの問題 → 深く推論し、詳細な分析を提供
強み 4:従来のツールを凌駕するセキュリティ脆弱性検知
研究によると、Claude クラスの LLM はセキュリティコードレビューにおいて、従来の静的解析ツールよりも大幅に優れていることが示されています。
| 比較項目 | Claude (LLM) | CodeQL (従来の SAST) |
|---|---|---|
| 検知した脆弱性数 | 55 件 | 27 件 |
| 未知の脆弱性発見 | 4 件のゼロデイ脆弱性 | 0 件 |
| 検知カテゴリ | インジェクション、認証、データ漏洩、暗号、ロジック欠陥など 10 種以上 | パターンマッチングベース |
| 言語サポート | あらゆるプログラミング言語 | 特定の言語のみ |
| 誤検知フィルタ | AI が自動フィルタリング | 人手によるフィルタリングが必要 |
Claude が検知可能なセキュリティ脆弱性の例:
- SQL/コマンド/LDAP/XPath/NoSQL インジェクション
- 認証および認可の欠陥
- ハードコードされたキー、機密データのログ出力
- 弱い暗号アルゴリズム、不適切なキー管理
- 競合状態 (TOCTOU)
- 安全でないデフォルト設定、CORS
- デシリアライズ RCE、pickle/eval インジェクション
- XSS (反射型、蓄積型、DOM 型)
強み 5:コストの柔軟性
Sonnet 4.6 の価格は Opus 4.6 の 5分の1 ですが、SWE-bench での性能差はわずか 1〜2 ポイントです。
推奨される使い分け戦略:
| シナリオ | 推奨モデル | 理由 |
|---|---|---|
| 日常的な PR レビュー | Sonnet 4.6 | コスパ最強、品質は Opus に肉薄 |
| セキュリティ重要コード | Opus 4.6 | 最深の推論で高リスクな問題を見逃さない |
| 大規模リファクタリング | Opus 4.6 | ファイル横断的な推論能力が最強 |
| スタイル・規約チェック | Sonnet 4.6 | 単純なタスクに Opus は不要 |
| CI/CD 自動レビュー | Sonnet 4.6 | コスト管理が容易、コミット毎の実行に最適 |
🚀 選定のアドバイス: Anthropic 公式は「デフォルトは Sonnet 4.6 を使用し、最も深い推論が必要な時だけ Opus 4.6 にアップグレードする」ことを推奨しています。Claude Code の内部テストでは、開発者の Sonnet 4.6 への好感度は前世代の Sonnet 4.5 より 70% 高く、先代のフラッグシップである Opus 4.5 よりも 59% 高いという結果が出ています。APIYI (apiyi.com) を経由すれば、どちらのモデルもよりお得な価格で利用可能です。
完全なAIコードレビューワークフロー
ワークフローの概要
開発者がPRを提出
↓
AIが自動的にレビューを開始 (Sonnet 4.6)
↓
┌─── 低リスクの変更 ──→ AIがNit(軽微な指摘)をマークし、自動承認
│
├─── 中リスクの変更 ──→ AIが問題を指摘し、人間が迅速に確認
│
└─── 高リスクの変更 ──→ Opus 4.6へ昇格し、詳細なレビューを実施
↓
セキュリティ専門家による最終確認
↓
マージまたは却下
コード例:カスタムAIレビューシステムの構築
import openai
import subprocess
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI統合インターフェース
)
def get_pr_diff(pr_number):
"""PRのdiff内容を取得する"""
result = subprocess.run(
["gh", "pr", "diff", str(pr_number)],
capture_output=True, text=True
)
return result.stdout
def review_code(diff, risk_level="medium"):
"""リスクレベルに応じてレビューに使用するモデルを選択"""
model = "claude-opus-4-6" if risk_level == "high" else "claude-sonnet-4-6"
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": f"以下の変更をレビューしてください:\n\n{diff}"}
],
max_tokens=8192
)
return response.choices[0].message.content
# 使用例
diff = get_pr_diff(123)
review = review_code(diff, risk_level="high")
print(review)
完全なレビュー用プロンプトテンプレートを表示
REVIEW_PROMPT = """あなたは経験豊富なシニアソフトウェアエンジニアであり、コードレビューを担当しています。
## レビューの重点
1. **ロジックの正確性**: コードは期待通りに機能しますか?境界条件の漏れはありませんか?
2. **安全性**: インジェクション、XSS、CSRF、ハードコードされたAPIキーなどのセキュリティリスクはありませんか?
3. **パフォーマンス**: N+1クエリ、不要なメモリ割り当て、ブロッキング操作はありませんか?
4. **保守性**: 命名は明確ですか?複雑度は制御されていますか?重複コードはありませんか?
5. **エラーハンドリング**: 例外は適切にキャッチされ、処理されていますか?
6. **並行処理の安全性**: レースコンディションやデッドロックのリスクはありませんか?
"""
出力フォーマット
深刻度別に分類して出力してください:
🔴 修正必須 (バグ/セキュリティ)
- [ファイル名:行番号] 問題の概要
- 影響: …
- 修正案: …
🟡 修正推奨 (Nit)
- [ファイル名:行番号] 問題の概要
- 推奨事項: …
💡 改善提案 (Suggestion)
- [ファイル名:行番号] 改善点
- 説明: …
コードの品質が良好で問題が見つからない場合は、「レビュー完了、問題なし」と明記してください。
出力のために存在しない問題を捏造することは避けてください。"""
</details>
> 💰 **コスト最適化**: APIYI (apiyi.com) を経由して Claude 3.5 Sonnet モデルを呼び出すことで、公式よりもお得にコードレビューを行えます。プラットフォームは Opus と Sonnet の柔軟な切り替えをサポートしており、PR のリスクレベルに応じて最も費用対効果の高いモデルを自動選択可能です。
---
## AI コードレビューの限界と注意点
### 知っておくべき 5 つの限界
1. **再現率(リコール)は約 50%**: LLM が見つける脆弱性は通常正確(精度は約 80%)ですが、既存の脆弱性の約半分を見逃す可能性があります。
2. **プロンプトインジェクションのリスク**: AI レビューツールは、信頼できない PR を処理する際にインジェクション攻撃を受けるリスクがあります。
3. **コンテキストの盲点**: AI はプロジェクトのビジネス背景、チームメンバーのスキル、過去の意思決定の経緯を理解できません。
4. **コストの蓄積**: すべてのコミットに対してレビューを実行すると、頻繁に更新されるリポジトリでは費用が高額になる可能性があります。
5. **過度な依存リスク**: チームメンバーが、手動レビューの厳格さを徐々に緩めてしまう恐れがあります。
### 回避戦略
| 限界 | 回避策 |
|------|----------|
| 見逃し率が高い | AI レビュー + 人手によるレビューの二重体制 |
| プロンプトインジェクション | 信頼できるソースからの PR のみレビューする |
| コンテキスト不足 | REVIEW.md にプロジェクトの背景情報を提供する |
| コストが高すぎる | 日常は Sonnet 3.5、重要なパスには Opus を使用する |
| 過度な依存 | 「AI の提案 + 人による意思決定」という制度を確立する |
## よくある質問
<details open>
<summary><strong>Q1: AIによるコードレビューは、人間のレビューを完全に代替できますか?</strong></summary>
いいえ、できません。AIによるコードレビューは「代替」ではなく「強化」です。AIはパターン化された問題(スタイル、一般的なバグ、既知の脆弱性パターン)を見つけるのは得意ですが、ビジネス上の意図やアーキテクチャの決定におけるトレードオフ、チーム内での暗黙知を理解することはできません。ベストプラクティスは、AIが最初のスキャンを行い、人間が最終判断を下すことです。APIYI (apiyi.com) を通じて Claude 4.6 モデルを呼び出すことで、AIレビュープロセスを迅速に構築し、人間がより価値の高い作業に集中できる環境を作れます。
</details>
<details open>
<summary><strong>Q2: コードレビューには Opus 4.6 と Sonnet 4.6 のどちらを選ぶべきですか?</strong></summary>
ほとんどのケースでは Sonnet 4.6 を推奨します。SWE-bench におけるスコアは Opus と比較してもわずか1〜2%の差ですが、コストは5分の1です。セキュリティが重要なコードのレビューや、大規模なアーキテクチャのリファクタリング、ファイル間をまたぐ深い推論が必要な場合にのみ、Opus 4.6 へのアップグレードを検討してください。APIYI (apiyi.com) を利用すれば、必要に応じて両モデルを柔軟に切り替えることができます。
</details>
<details open>
<summary><strong>Q3: AIコードレビューのコストはどのくらいですか?</strong></summary>
Claude Code のネイティブなレビュー機能は、PRのサイズやコードベースの複雑さにもよりますが、1回あたり平均15〜25ドルかかります。API経由で独自のレビューシステムを構築する場合、コストはトークン消費量に依存します。例えば Sonnet 4.6 の場合、500行のPR(入力約2000トークン+出力約1000トークン)をレビューするコストは約0.02ドルです。APIYI (apiyi.com) を経由すれば、さらにお得な価格で利用可能です。
</details>
<details open>
<summary><strong>Q4: AIコードレビューの効果をどのように評価すればよいですか?</strong></summary>
以下の4つの主要指標を追跡することをお勧めします。(1) 誤検知率:AIが指摘した問題のうち、実際に問題だった割合。(2) 見逃し率:リリース後に発見されたバグのうち、AIが指摘できなかった割合。(3) 採用率:開発者が実際にAIの提案を採用した割合。(4) レビュー時間の変化:人間のレビュアーの平均レビュー時間が短縮されたか。最初の2ヶ月間は、週に一度の振り返りを行うのが理想的です。
</details>
<details open>
<summary><strong>Q5: AIコードレビューをすぐに試すにはどうすればよいですか?</strong></summary>
最も簡単なのは3ステップです。(1) APIYI (apiyi.com) に登録して APIキー を取得する。(2) Sonnet 4.6 を使用して、直近のPRで一度レビューテストを行う。(3) 効果を確認した上で、CI/CDへの自動組み込みを検討する。まずは重要度の低いコードから試験的に導入し、徐々に全体へ展開していくのが良いでしょう。
</details>
---
## まとめ:AIコードレビューはチームの生産性を高めるブースター
AIコードレビューは選択肢ではなく、2026年のソフトウェア開発チームにとって必須の能力です。Claude Opus 4.6 と Sonnet 4.6 は、100万トークンのコンテキストウィンドウ、81%以上の SWE-bench スコア、適応型の思考能力、そして強力なセキュリティ検出機能を備えており、現在のコードレビューにおいて最適な選択肢です。
**モデル選定のヒント**:
- **日常的なレビュー**: コスパ最強の Sonnet 4.6 をデフォルトに。
- **セキュリティ/アーキテクチャレビュー**: 推論の深さを妥協しない Opus 4.6 を選択。
APIYI (apiyi.com) を通じて Claude 4.6 シリーズを迅速に導入し、コスト効率を最大化しながらチームのAIコードレビュー能力を構築しましょう。
## 参考資料
1. **Anthropic 公式**: Claude Opus 4.6 および Sonnet 4.6 リリース告知
- リンク: `anthropic.com/news`
2. **Claude Code コードレビュー・ドキュメント**: ネイティブレビュー機能の利用ガイド
- リンク: `code.claude.com/docs/en/code-review`
3. **Claude Code Security Review**: オープンソースのセキュリティレビュー用 GitHub Action
- リンク: `github.com/anthropics/claude-code-security-review`
4. **AI コードレビューのベストプラクティス 2026**: 業界総合分析
- リンク: `verdent.ai/guides`
5. **IRIS 研究論文**: LLM を活用した静的解析による脆弱性検出
- リンク: `arxiv.org`
---
> **著者**: APIYI Team | AI がソフトウェア開発にもたらす可能性を追求しています。Claude 4.6 シリーズ全モデルの API 接続や技術サポートについては、ぜひ APIYI (apiyi.com) をご覧ください。