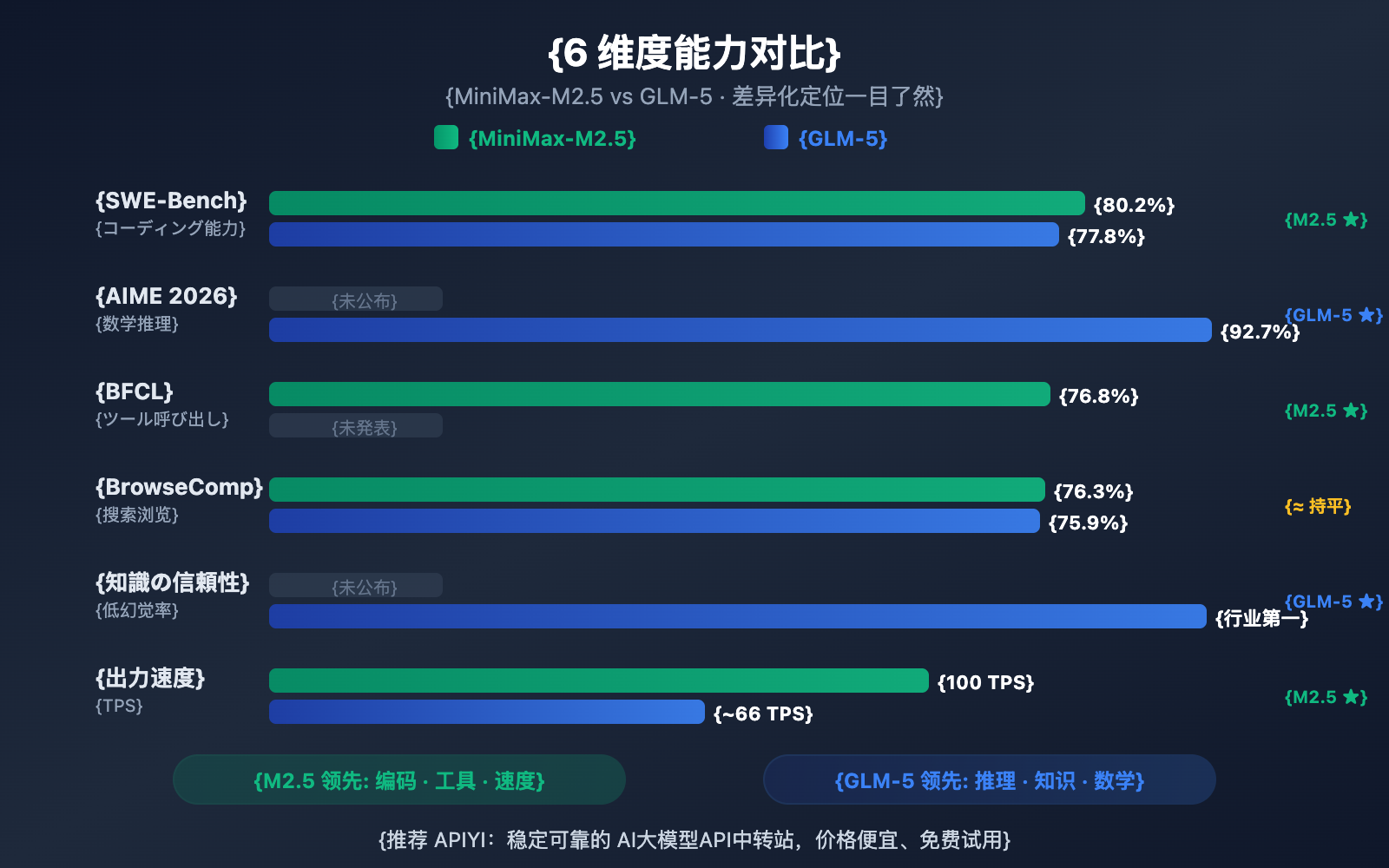
作者注:深度对比 2026 年 2 月同期发布的 MiniMax-M2.5 和 GLM-5 两大开源模型,从编码、推理、智能体、速度、价格和架构 6 个维度解析各自擅长领域
2026 年 2 月 11-12 日,两大中国 AI 公司几乎同时发布了各自的旗舰模型:智谱 GLM-5(744B 参数)和 MiniMax-M2.5(230B 参数)。两者都采用 MoE 架构、MIT 开源协议,但在能力侧重上形成了鲜明的差异化定位。
核心价值: 看完本文,你将清楚了解 GLM-5 擅长推理和知识可靠性,MiniMax-M2.5 擅长编码和智能体工具调用,从而在具体场景中做出最优选择。

MiniMax-M2.5 と GLM-5 の主な違いまとめ
| 比較項目 | MiniMax-M2.5 | GLM-5 | 優位性 |
|---|---|---|---|
| SWE-Bench コーディング | 80.2% | 77.8% | M2.5 が 2.4% リード |
| AIME 数学推論 | — | 92.7% | GLM-5 が得意 |
| BFCL ツール呼び出し | 76.8% | — | M2.5 が得意 |
| BrowseComp 検索 | 76.3% | 75.9% | ほぼ同等 |
| 出力料金/1M tokens | $1.20 | $3.20 | M2.5 が 2.7 倍安い |
| 出力速度 | 50-100 TPS | ~66 TPS | M2.5 Lightning がより高速 |
| 総パラメータ数 | 230B | 744B | GLM-5 がより大規模 |
| 活性化パラメータ数 | 10B | 40B | M2.5 がより軽量 |
MiniMax-M2.5 の主な強み:コーディングとエージェント
MiniMax-M2.5 は、コーディングのベンチマークテストで際立ったパフォーマンスを見せています。SWE-Bench Verified での 80.2% というスコアは、GLM-5 の 77.8% を上回るだけでなく、GPT-5.2 の 80.0% をも凌駕し、Claude Opus 4.6 の 80.8% に迫る勢いです。複数ファイルが連携する Multi-SWE-Bench では 51.3% を記録し、ツール呼び出しの BFCL Multi-Turn では 76.8% に達しています。
M2.5 の MoE(混合専門家)アーキテクチャは、わずか 10B のパラメータ(全 230B の 4.3%)のみを活性化させるため、Tier 1 モデルの中でも「最も軽量」な選択肢となり、推論効率が極めて高いのが特徴です。Lightning バージョンでは 100 TPS に達し、現在最も高速な最先端モデルの一つとなっています。
GLM-5 の主な強み:推論と知識の信頼性
GLM-5 は、推論や知識ベースのタスクにおいて顕著な優位性を持っています。AIME 2026 の数学推論スコアは 92.7%、GPQA-Diamond の科学的推論は 86.0% を記録。Humanity's Last Exam(ツール使用あり)では 50.4 点を獲得し、Claude Opus 4.5 の 43.4 点をリードしています。
GLM-5 の最も際立った能力は「知識の信頼性」です。AA-Omniscience ハルシネーション(幻覚)評価において業界トップレベルの成績を収め、前世代から 35 ポイント向上しました。技術ドキュメントの作成、学術研究の支援、ナレッジベースの構築など、高精度な事実出力が求められるシーンにおいて、GLM-5 はより信頼できる選択肢となります。さらに、744B のパラメータ数と 28.5 兆トークンの学習データにより、大規模言語モデルとして非常に深い知識の蓄積を誇ります。
MiniMax-M2.5 vs GLM-5 コーディング能力の詳細比較
コーディング能力は、現在の開発者が大規模言語モデルを選択する際に最も注目する指標の一つです。この点において、2つのモデルには明確な差が見られます。
| コーディングベンチマーク | MiniMax-M2.5 | GLM-5 | Claude Opus 4.6 (参考) |
|---|---|---|---|
| SWE-Bench Verified | 80.2% | 77.8% | 80.8% |
| Multi-SWE-Bench | 51.3% | — | 50.3% |
| SWE-Bench Multilingual | — | 73.3% | 77.5% |
| Terminal-Bench 2.0 | — | 56.2% | 65.4% |
| BFCL Multi-Turn | 76.8% | — | 63.3% |
MiniMax-M2.5は、SWE-Bench VerifiedにおいてGLM-5を2.4ポイント上回っています(80.2% vs 77.8%)。コーディングのベンチマークにおいて、この差は非常に顕著です。M2.5のコーディング能力はOpus 4.6レベルに達しているのに対し、GLM-5はGemini 3 Proレベルに近いと言えます。
GLM-5は、多言語コーディング(SWE-Bench Multilingual 73.3%)やターミナル環境でのコーディング(Terminal-Bench 56.2%)のデータも公開しており、多角的なコーディング能力を示しています。しかし、最も核心となるSWE-Bench Verifiedにおいては、M2.5の優位性が明確です。
また、M2.5はコーディング効率の面でも優れたパフォーマンスを発揮しています。SWE-Benchの単一タスクを完了するのに要する時間はわずか22.8分で、前世代のM2.1から37%向上しました。これは、独自の「Spec-writing」コーディングスタイルによるものです。まずアーキテクチャを分解してから効率的に実装を行うことで、無駄な試行錯誤のループを減らしています。
🎯 コーディングシーンでの推奨: AIによるコーディング支援(バグ修正、コードレビュー、機能実装など)が主な目的であれば、MiniMax-M2.5がより優れた選択肢となります。APIYI (apiyi.com) を通じて、両方のモデルを同時に呼び出し、実際のタスクで比較テストを行うことも可能です。
MiniMax-M2.5 vs GLM-5 推論能力の詳細比較
推論能力はGLM-5の核心的な強みであり、特に数学や科学的推論の分野でその実力を発揮します。
| 推論ベンチマーク | MiniMax-M2.5 | GLM-5 | 説明 |
|---|---|---|---|
| AIME 2026 | — | 92.7% | オリンピックレベルの数学的推論 |
| GPQA-Diamond | — | 86.0% | 博士レベルの科学的推論 |
| Humanity's Last Exam (w/tools) | — | 50.4 | Opus 4.5の43.4を凌駕 |
| HMMT Nov. 2025 | — | 96.9% | GPT-5.2の97.1%に肉薄 |
| τ²-Bench | — | 89.7% | 通信分野の推論 |
| AA-Omniscience 知識の信頼性 | — | 業界リード | ハルシネーション率が極めて低い |
GLM-5は、SLIME(非同期強化学習インフラストラクチャ)と呼ばれる新しい学習手法を採用しており、ポストトレーニングの効率を大幅に向上させました。これにより、GLM-5は推論タスクにおいて質的な飛躍を遂げています。
- AIME 2026 スコア 92.7%: Claude Opus 4.5の93.3%に迫り、GLM-4.5時代を大きく上回る水準です。
- GPQA-Diamond 86.0%: 博士レベルの科学的推論能力において、Opus 4.5の87.0%に近い数値を記録しています。
- Humanity's Last Exam 50.4点(ツール使用時): Opus 4.5の43.4点やGPT-5.2の45.5点を超えるスコアを叩き出しています。
GLM-5の最もユニークな能力は「知識の信頼性」です。AA-Omniscienceハルシネーション評価において、GLM-5は前世代から35ポイント向上し、業界トップクラスの水準に達しました。これは、事実に関する質問に対して内容を「捏造」することが少なく、高精度な情報出力が求められるシーンで極めて高い価値があることを意味します。
一方、MiniMax-M2.5の推論に関するデータはあまり公開されていません。その核心となる強化学習は、主にコーディングやエージェントシナリオに集中しています。M2.5のForge RLフレームワークは、純粋な推論能力よりも、20万件以上の実環境におけるタスク分解やツール呼び出しの最適化に重点を置いています。
比較のまとめ: 数学的推論、科学的分析、あるいは高い信頼性が求められる知識ベースのQ&Aが主なニーズである場合は、GLM-5に分があります。APIYI (apiyi.com) プラットフォームを利用して、具体的な推論タスクにおける両者のパフォーマンスの差を実際にテストしてみることをお勧めします。
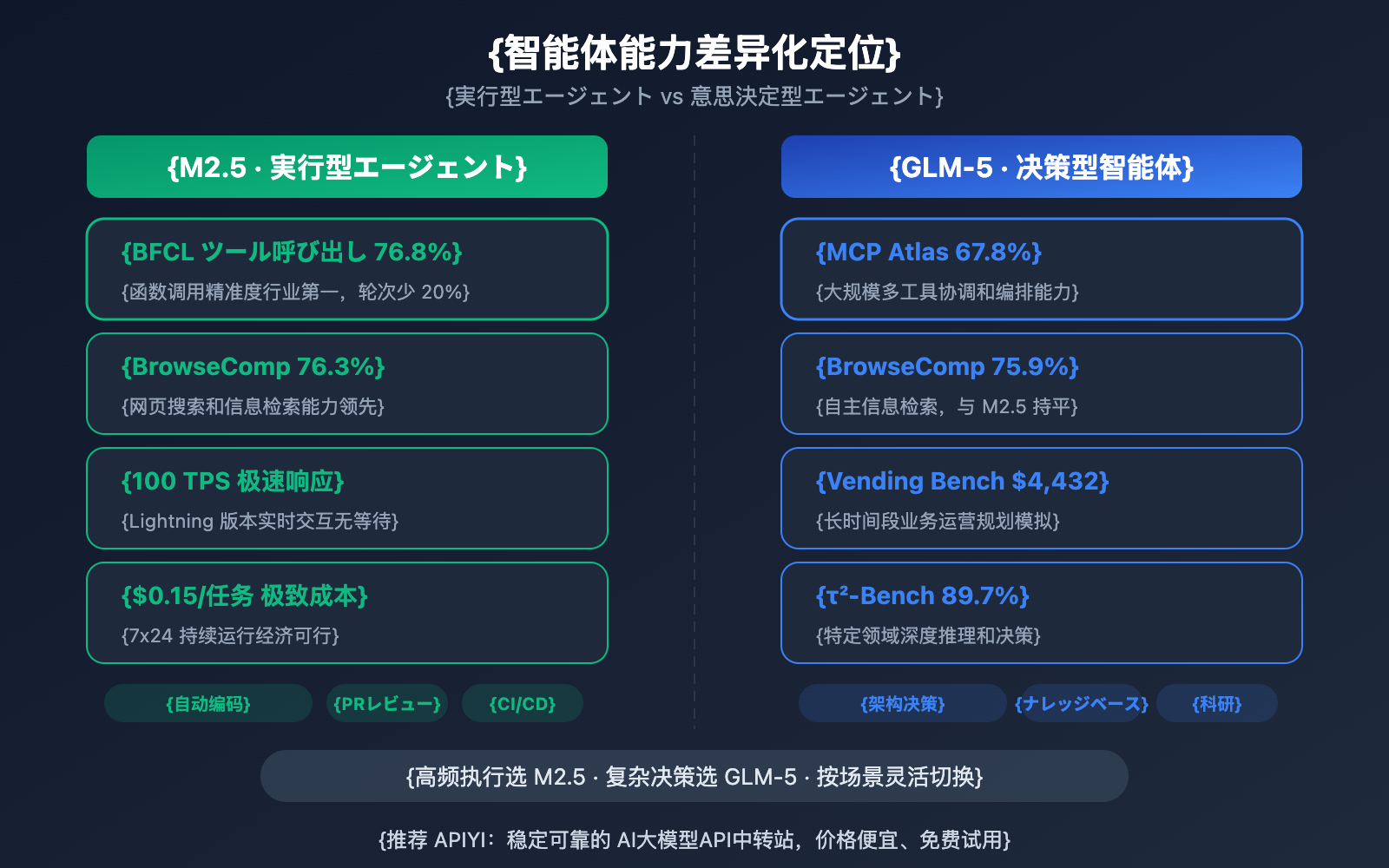
MiniMax-M2.5 vs GLM-5:エージェントと検索能力の比較
| エージェント・ベンチマーク | MiniMax-M2.5 | GLM-5 | 優位性 |
|---|---|---|---|
| BFCL Multi-Turn | 76.8% | — | M2.5がツール呼び出しでリード |
| BrowseComp (w/context) | 76.3% | 75.9% | ほぼ同等 |
| MCP Atlas | — | 67.8% | GLM-5が複数ツールの連携に強み |
| Vending Bench 2 | — | $4,432 | GLM-5が長期計画に強み |
| τ²-Bench | — | 89.7% | GLM-5がドメイン推論に強み |
2つのモデルは、エージェント能力において明確な差別化が見られます。
MiniMax-M2.5は「実行型」エージェントを得意としています:ツールの頻繁な呼び出し、迅速な反復、効率的な実行が求められるシナリオで優れたパフォーマンスを発揮します。BFCL 76.8%という数値は、M2.5が関数呼び出し、ファイル操作、API連携などのツール利用を正確に行えることを意味しており、ツール呼び出しのターン数は前世代より20%削減されています。MiniMax社内では、すでに新規コードの80%がM2.5によって生成され、日常業務の30%をM2.5が完結させています。
GLM-5は「意思決定型」エージェントを得意としています:深い推論、長期的な計画、複雑な意思決定が必要なシナリオで優位性があります。MCP Atlas 67.8%は大規模なツールの連携能力を、Vending Bench 2における4,432ドルの模擬収益は長期間にわたるビジネス計画能力を、そしてτ²-Bench 89.7%は特定領域における深い推論能力をそれぞれ示しています。
Web検索・ブラウジング能力については、BrowseCompで76.3%対75.9%とほぼ同等であり、両者ともにこの分野のリーダー的存在です。
🎯 エージェント活用の推奨シナリオ: 高頻度なツール呼び出しや自動コーディングにはM2.5を、複雑な意思決定や長期計画にはGLM-5を選ぶのが最適です。APIYI (apiyi.com) プラットフォームは両方のモデルをサポートしており、シーンに合わせて柔軟に切り替えることができます。
MiniMax-M2.5 vs GLM-5:アーキテクチャとコストの比較
| アーキテクチャとコスト | MiniMax-M2.5 | GLM-5 |
|---|---|---|
| 総パラメータ数 | 230B | 744B |
| 活性パラメータ数 | 10B | 40B |
| 活性化率 | 4.3% | 5.4% |
| 学習データ | — | 28.5兆トークン |
| コンテキストウィンドウ | 205K | 200K |
| 最大出力 | — | 131K |
| 入力料金 | $0.15/M (標準版) | $1.00/M |
| 出力料金 | $1.20/M (標準版) | $3.20/M |
| 出力速度 | 50-100 TPS | ~66 TPS |
| 学習用チップ | — | Huawei Ascend 910 |
| 学習フレームワーク | Forge RL | SLIME 非同期 RL |
| アテンション・メカニズム | — | DeepSeek Sparse Attention |
| オープンソース・ライセンス | MIT | MIT |
MiniMax-M2.5 アーキテクチャの優位性分析
M2.5の核心的なアーキテクチャの強みは「究極の軽量化」にあります。わずか10Bの活性パラメータで、Opus 4.6に近いコーディング能力を実現しました。これにより、以下のメリットが生まれます:
- 推論コストが極めて低い: 出力料金は$1.20/Mで、GLM-5のわずか37%です。
- 推論速度が極めて速い: Lightningバージョンでは100 TPSに達し、GLM-5(~66 TPS)より52%高速です。
- デプロイのハードルが低い: 10Bの活性パラメータであれば、コンシューマー向けGPUでのデプロイも現実的です。
GLM-5 アーキテクチャの優位性分析
GLM-5の744Bの総パラメータと40Bの活性パラメータは、より強力な知識容量と推論の深さをモデルに与えています:
- より広範な知識の蓄積: 28.5兆トークンの学習データは、前世代を遥かに凌駕しています。
- より深い推論能力: 40Bの活性パラメータが、より複雑な推論チェーンを支えます。
- 国産演算リソースの自立: 全工程でHuawei Ascendチップを使用して学習されており、演算リソースの独立を実現しています。
- DeepSeek Sparse Attention: 200Kの長いコンテキストを効率的に処理します。
アドバイス: コストに敏感な高頻度の呼び出しシーンでは、M2.5の価格優位性が顕著です(出力料金はGLM-5のわずか37%)。APIYI (apiyi.com) プラットフォームを通じて、実際のタスクでのコストパフォーマンスをテストすることをお勧めします。
MiniMax-M2.5 vs GLM-5:APIのクイック導入
APIYIプラットフォームを利用すれば、統一されたインターフェースで両方のモデルを同時に呼び出すことができ、迅速な比較が可能です。
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# コーディングタスクのテスト - M2.5が得意
code_task = "Rustでロックフリーな並行キューを実装してください"
m25_result = client.chat.completions.create(
model="MiniMax-M2.5",
messages=[{"role": "user", "content": code_task}]
)
# 推論タスクのテスト - GLM-5が得意
reason_task = "2より大きいすべての偶数は2つの素数の和で表せることを証明してください(ゴールドバッハの予想の検証アプローチ)"
glm5_result = client.chat.completions.create(
model="glm-5",
messages=[{"role": "user", "content": reason_task}]
)
アドバイス: APIYI (apiyi.com) で無料テストクレジットを取得し、具体的なユースケースに合わせて両方のモデルをテストしてみてください。コーディングタスクならM2.5、推論タスクならGLM-5を試し、最適なソリューションを見つけましょう。
よくある質問
Q1: MiniMax-M2.5 と GLM-5 は、それぞれ何が得意ですか?
MiniMax-M2.5 は、コーディングとエージェントのツール呼び出しに優れています。SWE-Bench で 80.2%(Opus 4.6 に迫る数値)、BFCL で 76.8% と業界トップクラスの成績を収めています。一方、GLM-5 は推論と知識の信頼性に長けており、AIME 92.7%、GPQA 86.0% を記録し、ハルシネーション(幻覚)率も業界最低水準です。簡単に言えば、コードを書くなら M2.5、推論を行うなら GLM-5 を選ぶのがベストです。
Q2: 2つのモデルの価格差はどのくらいですか?
MiniMax-M2.5 標準版の出力価格は $1.20/M トークン、GLM-5 の出力価格は $3.20/M トークンで、M2.5 の方が約 2.7 倍安価です。M2.5 Lightning 高速版($2.40/M)を選択した場合、GLM-5 と価格は近くなりますが、より高速なレスポンスが期待できます。APIYI (apiyi.com) プラットフォーム経由で利用すれば、チャージ特典などの優待も受けられます。
Q3: 2つのモデルの実際の効果を素早く比較するにはどうすればよいですか?
APIYI (apiyi.com) プラットフォームで統合的にアクセスすることをお勧めします:
- アカウントを登録し、API Key と無料クレジットを取得します。
- 「コーディング系」と「推論系」の 2 種類のテストタスクを用意します。
- 同一のタスクで MiniMax-M2.5 と GLM-5 をそれぞれ呼び出します。
- 出力の質、レスポンス速度、トークン消費量を比較します。
- OpenAI 互換インターフェースを採用しているため、
modelパラメータを変更するだけで簡単にモデルを切り替えられます。
まとめ
MiniMax-M2.5 と GLM-5 の比較における核心的な結論は以下の通りです:
- コーディングなら M2.5: SWE-Bench 80.2% vs 77.8% で M2.5 が 2.4% リード。BFCL ツール呼び出しでも 76.8% で業界首位。
- 推論なら GLM-5: AIME 92.7%、GPQA 86.0% を記録。「Humanity's Last Exam」では 50.4 点をマークし、Opus 4.5 を超越。
- 知識の信頼性は GLM-5 がリード: AA-Omniscience ハルシネーション評価で業界 1 位。事実に基づいた出力においてより信頼できます。
- コスパは M2.5 が優秀: 出力価格は GLM-5 のわずか 37%。Lightning バージョンはさらに高速です。
両モデルとも MIT ライセンスでオープンソース化されており、MoE(混合エキスパート)アーキテクチャを採用していますが、その位置づけは明確に異なります。M2.5 は**「コーディングと実行型エージェントの王」、GLM-5 は「推論と知識の信頼性の先駆者」**です。実際のニーズに合わせて APIYI (apiyi.com) プラットフォームで柔軟に使い分け、チャージキャンペーンを活用してお得に利用することをお勧めします。
📚 参考文献
-
MiniMax M2.5 公式発表: M2.5 のコアコーディング能力と Forge RL トレーニングの詳細
- リンク:
minimax.io/news/minimax-m25 - 説明: SWE-Bench 80.2%、BFCL 76.8% などの完全なベンチマークデータ
- リンク:
-
GLM-5 公式リリース: Zhipu GLM-5 の 744B MoE アーキテクチャと SLIME トレーニング技術
- リンク:
docs.z.ai/guides/llm/glm-5 - 説明: AIME 92.7%、GPQA 86.0% などの推論ベンチマークデータを含む
- リンク:
-
Artificial Analysis 独立評価: 両モデルの標準化されたベンチマークテストとランキング
- リンク:
artificialanalysis.ai/models/glm-5 - 説明: Intelligence Index、実測速度、価格比較などの独立したデータ
- リンク:
-
BuildFastWithAI 深掘り分析: GLM-5 の包括的なベンチマークテストと競合製品との比較
- リンク:
buildfastwithai.com/blogs/glm-5-released-open-source-model-2026 - 説明: Opus 4.5、GPT-5.2 との詳細な比較表
- リンク:
-
MiniMax HuggingFace: M2.5 オープンソースモデルの重み
- リンク:
huggingface.co/MiniMaxAI - 説明: MIT ライセンス、vLLM/SGLang デプロイをサポート
- リンク:
著者: APIYI チーム
技術交流: コメント欄でモデルの比較テスト結果をぜひ共有してください。AI モデルの API 連携チュートリアルの詳細は、APIYI (apiyi.com) 技術コミュニティをご覧ください。