title: Claude Code vs GPT-5.4:プログラミングにはどちらを選ぶべき?徹底比較
description: Claude Code (Opus 4.6) と GPT-5.4 のプログラミング能力、コード品質、コスト、開発体験を徹底比較。SWE-Benchの結果や1Mコンテキストの活用法まで、エンジニアが今選ぶべきモデルを解説します。
著者注:Claude Code と GPT-5.4 のプログラミング能力、コード品質、コンテキストウィンドウ、価格、そして開発体験(DX)を中立的に比較し、乗り換えるべきかどうかの判断をサポートします。
GPT-5.4 がリリースされた当日、SNS上ではある声が上がりました。「Claude Code を解約しよう!」 その理由は一見十分なものでした。100万トークンのコンテキストウィンドウ、あらゆる面での能力向上、そして「人間味に欠ける(機械的な応答)」という問題がついに改善されたからです。
しかし、現実はそれほど単純ではありません。ベンチマークデータによると、Claude Opus 4.6 は SWE-Bench(プログラミングベンチマーク)において 80.8% を記録し、GPT-5.4 の 77.2% を依然として上回っています。開発者コミュニティからの実際のフィードバックも、意見が分かれているのが現状です。
核心的な価値: 本記事では、6つの次元から Claude Code と GPT-5.4 のプログラミング能力を客観的に比較し、乗り換えるべきか、あるいは両方を併用するのが賢い選択なのかを判断するための材料を提供します。
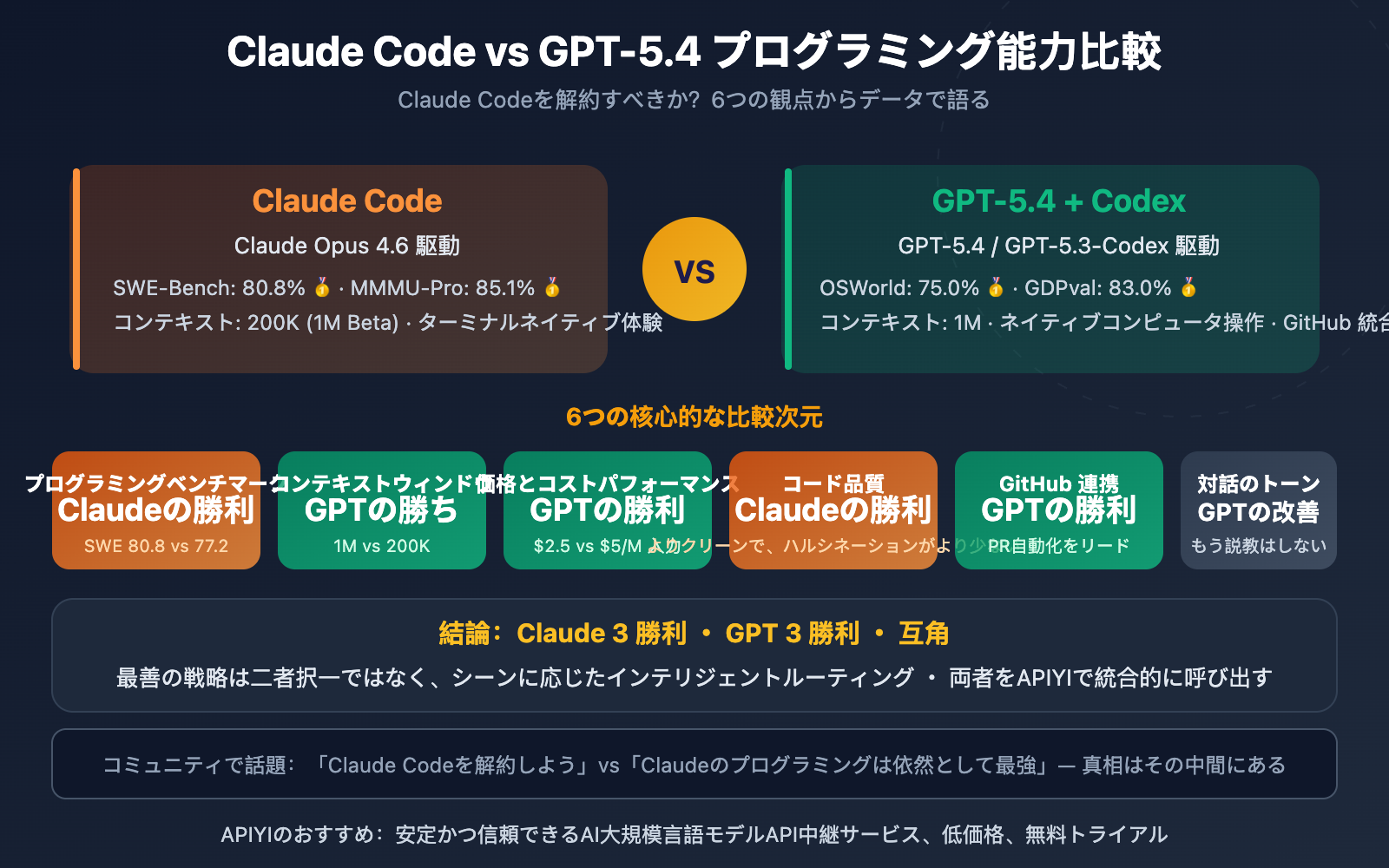
Claude Code vs GPT-5.4 主要データ比較
| 比較項目 | Claude Code (Opus 4.6) | GPT-5.4 / Codex | 勝者 |
|---|---|---|---|
| SWE-Bench プログラミング | 80.8% | 77.2% | Claude |
| MMMU-Pro 視覚的推論 | 85.1% | 81.2% | Claude |
| GDPval ナレッジワーク | 78.0% | 83.0% | GPT |
| OSWorld コンピュータ操作 | 72.7% | 75.0% | GPT |
| FrontierMath 数学 | 27.2% | 47.6% | GPT |
| Terminal-Bench ターミナル | 65.4% | 75.1% | GPT |
| コンテキストウィンドウ | 200K (1M Beta) | 1,000K | GPT |
| API 入力価格 | $5.00/M | $2.50/M | GPT |
| API 输出価格 | $25.00/M | $15.00/M | GPT |
| コードのクリーンさ | よりクリーンで規範的 | 標準的 | Claude |
| リファクタリングとデバッグ | リード | 標準的 | Claude |
| GitHub PR 自動化 | 標準的 | 深い統合 | GPT |
スコアは Claude 4勝、GPT 8勝 ですが、すぐに結論を出さないでください。プログラミングの現場では、SWE-Bench、コードの品質、リファクタリング能力の重みは、ナレッジワークやコンピュータ操作よりも遥かに高いからです。それでは、各項目を詳しく分析していきましょう。
Claude Code vs GPT-5.4 プログラミング能力徹底分析
視点1:プログラミング・ベンチマーク — Claude Code がリード
最も注目されているプログラミング・ベンチマーク「SWE-Bench Verified」(実際のGitHub Issueの修正能力)において、以下の結果が出ています。
| モデル | SWE-Bench Verified | SWE-Bench Pro |
|---|---|---|
| Claude Opus 4.6 | 80.8% 🥇 | — |
| Gemini 3.1 Pro | 80.6% | — |
| GPT-5.4 | 77.2% | 57.7% |
Claude Opus 4.6 は GPT-5.4 を 3.6 ポイント上回っています。複数ファイルにわたるアーキテクチャの理解や複雑な依存関係の追跡といった、本番レベルのコード修正シナリオにおいて、Claude はより強力なコード構造理解力を示しています。
一方で、GPT-5.4 は「Terminal-Bench 2.0」(ターミナル操作に特化したタスク)で 75.1% を記録し、Claude の 65.4% を大幅にリードしています。ワークフローがターミナル操作に強く依存している場合は、GPT に優位性があります。
視点2:コードの品質と開発体験 — Claude Code はよりクリーン
複数の開発者コミュニティからのフィードバックは、一つの結論に集約されています。それは、Claude が生成するコードは 「よりクリーンで、パターンが最適化されており、ハルシネーション(幻覚)が少ない」 ということです。
具体的な特徴は以下の通りです:
- リファクタリング: 複雑なリファクタリングやデバッグにおいて、Claude の方が優れたパフォーマンスを発揮します。
- アーキテクチャ理解: 大規模なリポジトリや階層化されたアーキテクチャを分析する際、Claude は推論チェーンが安定しており、コンテキストのドリフト(文脈の逸脱)が少ないです。
- 生成速度: Claude Code は初期生成速度が速いです(5分間で約1200行生成 vs Codexは10分間で約200行)。
GPT-5.4 の強みは、ドキュメント生成やボイラープレート(テンプレートコード)の作成にあります。これらはプロジェクトの深いアーキテクチャ理解を必要としないタスクです。
視点3:コンテキストウィンドウ — GPT-5.4 が圧倒的
これは GPT-5.4 の最大の構造的な強みです。
| 能力 | Claude Code | GPT-5.4 |
|---|---|---|
| 標準コンテキスト | 200K | 1,000K |
| Betaコンテキスト | 1M | — |
| 最大出力 | 32K | 128K |
1M(100万)トークンあれば、本番レベルのコードベース全体を一度に入力することが可能です。ただし、272Kトークンを超えるリクエストは、入力価格が2倍、出力価格が1.5倍になる点に注意が必要です。実際の使用では、ほとんどのプログラミングタスクで200K以上のコンテキストは必要ありません。
🎯 実践的なアドバイス: コンテキストウィンドウは GPT-5.4 のキラー機能ですが、その真価が発揮されるのは超大規模なコードベースを扱う時に限られます。中小型プロジェクトでは、Claude の 200K コンテキストと優れたアーキテクチャ理解力の組み合わせが、より良い選択肢となるでしょう。どちらのモデルも、APIYI(apiyi.com)を通じて統合的に呼び出すことが可能です。
Claude Code vs GPT-5.4 価格とエコシステム比較

視点4:価格 — GPT-5.4 の方がコスパが高い
APIの価格設定において、GPT-5.4 は Claude Opus 4.6 よりも全面的に安価です。
- 入力: $2.50 vs $5.00/1Mトークン(50%安い)
- 出力: $15.00 vs $25.00/1Mトークン(40%安い)
- キャッシュ入力: $0.25 vs $0.50/1Mトークン(50%安い)
サブスクリプションに関しても、開発者コミュニティからは「Claude の使用制限はより厳しい」というフィードバックが多く寄せられています。月額20ドルの Codex プランは、月額17ドルの Claude Pro プランよりも利用枠が寛大です。多くの開発者が、Codex Pro では上限に達することはほとんどない一方で、Claude ユーザーはより高額なプランであっても頻繁に制限に遭遇すると報告しています。
視点5:GitHub連携 — GPT Codex が明らかにリード
これは見落とされがちですが、開発者のワークフローに大きな影響を与える違いです。
開発者のフィードバックによると、Claude Code の GitHub PR(プルリクエスト)レビューは「長文のコメントを出すが、明らかなバグを見逃す」傾向があるのに対し、Codex は「発見が困難なバグの検出」に優れており、インラインコメントや実行可能な修正ワークフローを提供します。また、Codex の GitHub App は、CLI と Web インターフェースの間で一貫した動作を維持できます。
視点6:対話のトーン — GPT-5.x の「機械的すぎる」問題が改善
これはSNSでも話題になっている点です。GPT-5 シリーズは、「人間味がない」という批判から段階的に改善を遂げてきました。
- GPT-5.0: 「冷淡なロボット」と批判される
- GPT-5.1: 親しみやすさと対話性が向上
- GPT-5.3 Instant: 「不自然さ(less cringe)」を抑えることを主眼に置き、ハルシネーションを 26.8% 削減
- GPT-5.4: 5.3 のトーン改善を継承しつつ、専門能力を強化
客観的に見て、自然な対話やコード解説の読みやすさにおいては、依然として Claude が優れていると評価されています。GPT-5.4 も改善されていますが、まだわずかに差があります。
🎯 コストの最適化: どちらのモデルを選択する場合でも、APIYI(apiyi.com)を通じて一括導入することで、より柔軟な料金体系を利用できます。GPT-5.4 の価格は公式サイトと同期しており($2.50/$15.00)、100ドル以上のチャージで10%のボーナスが付与されます。
Claude Code vs GPT-5.4 利用シーン選定ガイド

Claude Code vs GPT-5.4 API 呼び出しの例
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# 複雑なリファクタリング → Claude Opus 4.6 を使用(コード品質がより高い)
refactor_result = client.chat.completions.create(
model="claude-opus-4-6",
messages=[{"role": "user", "content": "このモジュールの依存関係注入(DI)アーキテクチャをリファクタリングして"}]
)
# 超大規模コードベースの分析 → GPT-5.4 を使用(1M コンテキストウィンドウ)
analysis_result = client.chat.completions.create(
model="gpt-5.4",
messages=[{"role": "user", "content": "プロジェクト全体のセキュリティ脆弱性を分析して"}]
)
アドバイス: APIYI(apiyi.com)でアカウントを一つ作成するだけで、Claude と GPT-5.4 を同時に呼び出すことができます。GPT-5.4 の価格設定は公式サイトと同期しており、100ドル以上のチャージで10%ボーナスが付与されます。シーンに合わせてモデルを切り替えるには、パラメータを一つ変更するだけです。
よくある質問
Q1: Claude Code を解約すべきでしょうか?
それは、あなたの主な業務シーンによります。もし核となるニーズが複雑なコードのリファクタリングやプロダクションレベルのバグ修正であれば、Claude は依然として最強の選択肢です(SWE-Bench 80.8% でリード)。一方で、超長文のコンテキスト、GitHub との統合、より低コストを求めるのであれば、GPT-5.4 / Codex に優位性があります。最善の戦略はどちらか一方を選ぶのではなく、API を通じてシーンごとに両者を使い分けることです。
Q2: GPT-5.4 のプログラミング能力は本当に全面的にリードしていますか?
いいえ、そうではありません。GPT-5.4 は GDPval(ナレッジワーク)、OSWorld(コンピュータ操作)、FrontierMath(数学)などの次元でリードしていますが、最も核心的なプログラミングベンチマークである SWE-Bench では、Claude Opus 4.6 が 80.8% vs 77.2% で首位を維持しています。コードの品質、リファクタリング能力、アーキテクチャの理解においては、開発者コミュニティも Claude を好む傾向にあります。これら両モデルは、APIYI(apiyi.com)を通じて統合的に呼び出し、比較することが可能です。
Q3: Claude と GPT-5.4 を同時に使用するにはどうすればよいですか?
APIYI(apiyi.com)でアカウントを登録してください:
- 統一された API キーを取得します。
base_urlをhttps://vip.apiyi.com/v1に設定します。- リファクタリングタスクには
model="claude-opus-4-6"を使用します。 - 大規模プロジェクトの分析には
model="gpt-5.4"を使用します。 - 日常的なタスクには
model="gpt-5.3-chat-latest"(最も経済的)を使用します。
100ドル以上のチャージで10%ボーナスが付き、一つのアカウントですべての主要な大規模言語モデルをカバーできます。
まとめ
Claude Code vs GPT-5.4 の核心的な結論は以下の通りです:
- コーディングベンチマークでは依然として Claude がリード: SWE-Bench で 80.8% vs 77.2% を記録。コードの品質がよりクリーンで、リファクタリングやデバッグ能力に優れています。そのため、「Claude Code を解約する」という極端な意見は時期尚早と言えるでしょう。
- GPT-5.4 はコンテキストとコストパフォーマンスで圧倒: 1M トークンのコンテキストウィンドウ(Claude の 5 倍)、API 価格が 40〜50% 安価、さらに GitHub との深い統合が特徴です。大規模プロジェクトやコストを重視するシーンに適しています。
- 最適な戦略は「使い分け」: リファクタリングや複雑なバグ修正には Claude を、超大規模なコードベースの分析やターミナル操作には GPT-5.4 を、そして日常的なタスクには GPT-5.3 Instant を使ってコストを抑えるのが賢い方法です。
「Claude Code 解約」といった刺激的なタイトルに惑わされないでください。真に優秀な開発者は、特定のブランドに固執するのではなく、利用シーンに応じて最適なツールを選択します。
Claude と GPT-5.4 を一括で導入するなら、APIYI (apiyi.com) がおすすめです。一つの API キーですべてのモデル呼び出しが可能で、100ドル以上のチャージで 10% ボーナスが付与されます。
📚 参考文献
-
Claude Code vs Codex 徹底比較: Builder.io チームによる開発者視点の詳細な比較
- リンク:
builder.io/blog/codex-vs-claude-code - 説明: 価格、コードの品質、GitHub 連携などの実操作に基づいた比較。
- リンク:
-
GPT-5.4 が狙う Claude との競争分析: GPT-5.4 がいかに Claude に対抗しているか
- リンク:
trendingtopics.eu/gpt-5-4-targets-anthropics-claude-with-premium-pricing-and-coding-muscle/ - 説明: GPT-5.4 Pro の高価格帯戦略とコーディング分野における野心を深く分析。
- リンク:
-
GPT-5.4 vs Opus 4.6 vs Gemini 3.1 Pro 全方位比較: 12 項目のベンチマークデータ
- リンク:
digitalapplied.com/blog/gpt-5-4-vs-opus-4-6-vs-gemini-3-1-pro-best-frontier-model - 説明: 主要 3 モデルの包括的な比較。競争力分析と選定アドバイスを含む。
- リンク:
-
Claude Sonnet 4.6 vs GPT-5 開発者ベンチマーク: SitePoint による実際の開発シーンでのテスト
- リンク:
sitepoint.com/claude-sonnet-4-6-vs-gpt-5-the-2026-developer-benchmark/ - 説明: リファクタリング、デバッグ、ドキュメント生成など、具体的なタスクの比較データ。
- リンク:
著者: APIYI 技術チーム
技術交流: コメント欄での議論を歓迎します。さらなる資料については、APIYI ドキュメントセンター (docs.apiyi.com) をご覧ください。