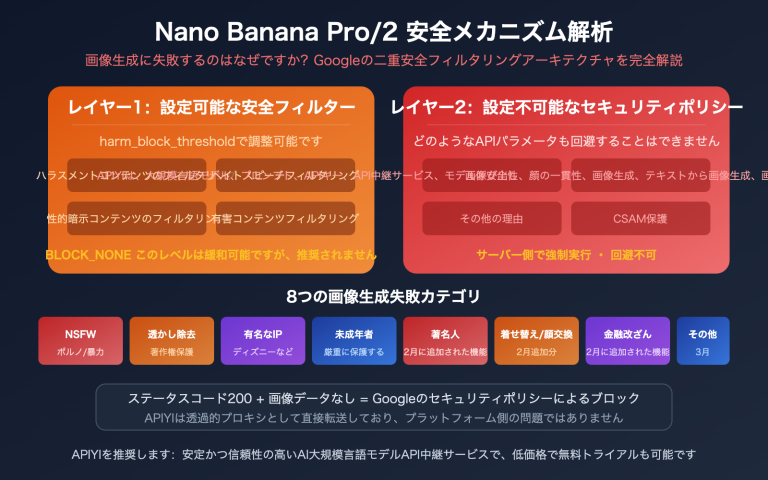
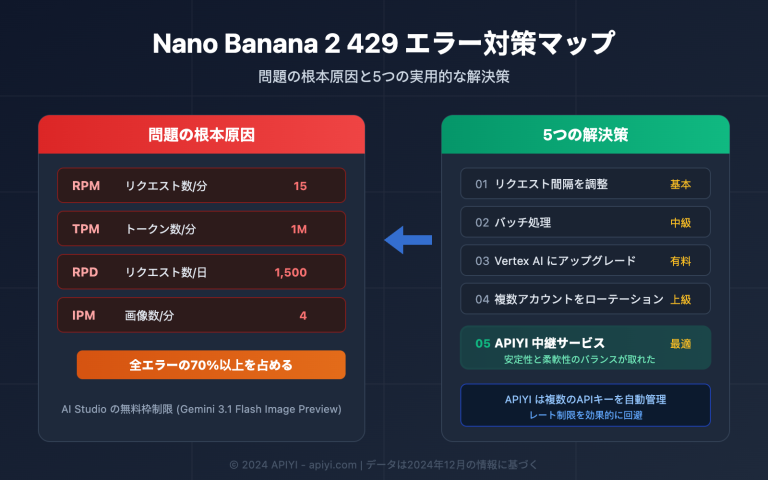
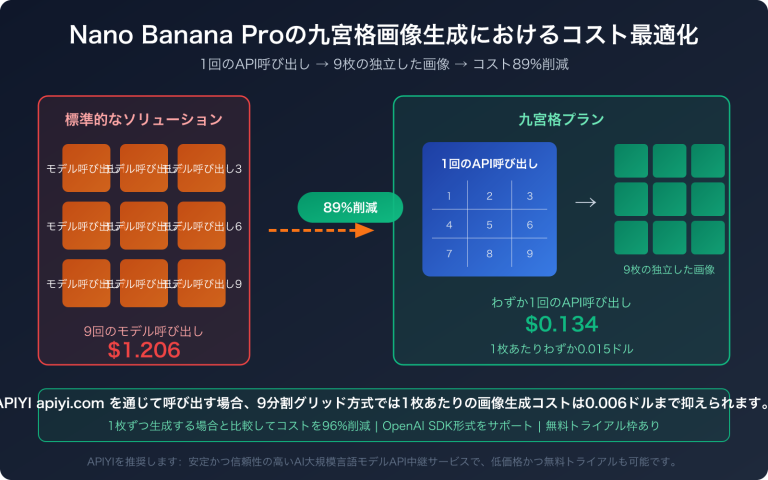
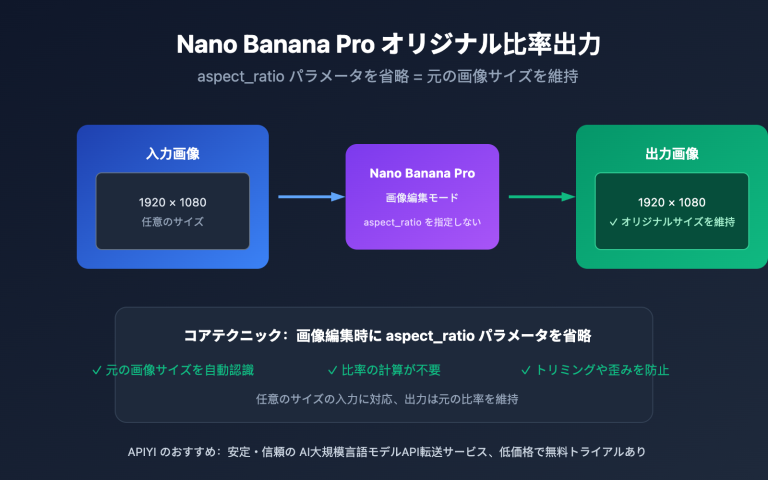
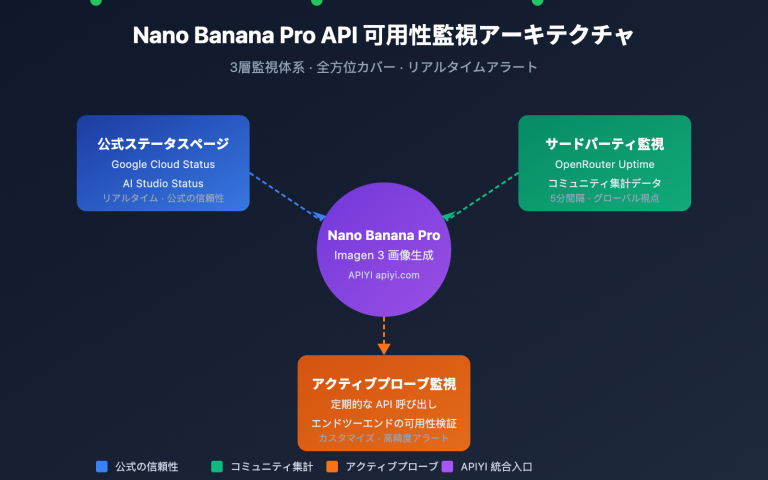
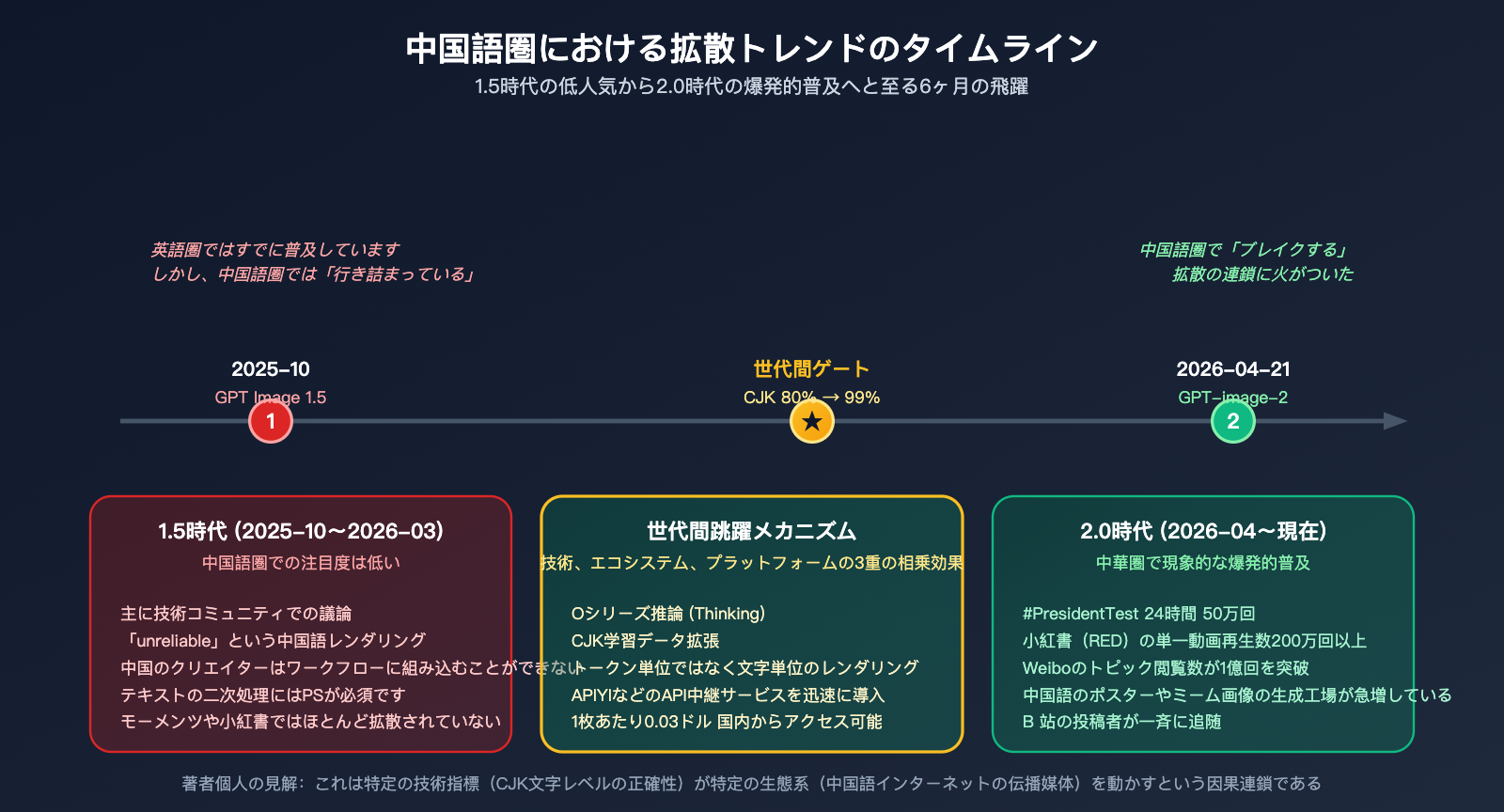
作者注:本稿深度分析了 GPT-image-2 在中文圈传播热度远超 1.5 版本的根本原因——从 95% 到 99% 的汉字渲染代际跃迁,成功撬动了中文用户的整个传播链。
GPT-image-2 在 2026 年 4 月 21 日由 OpenAI 发布后,在中文社区引发了远超 GPT Image 1.5 时代的传播热度——朋友圈、小红书、微博、B 站、知乎几乎同时涌现出复刻案例,48 小时内“GPT-image-2 中文海报”成为现象级话题。但同样是 OpenAI 的图像模型,1.5 版本半年前发布时,仅在技术圈激起微小涟漪,并未成功“破圈”走进大众视野。
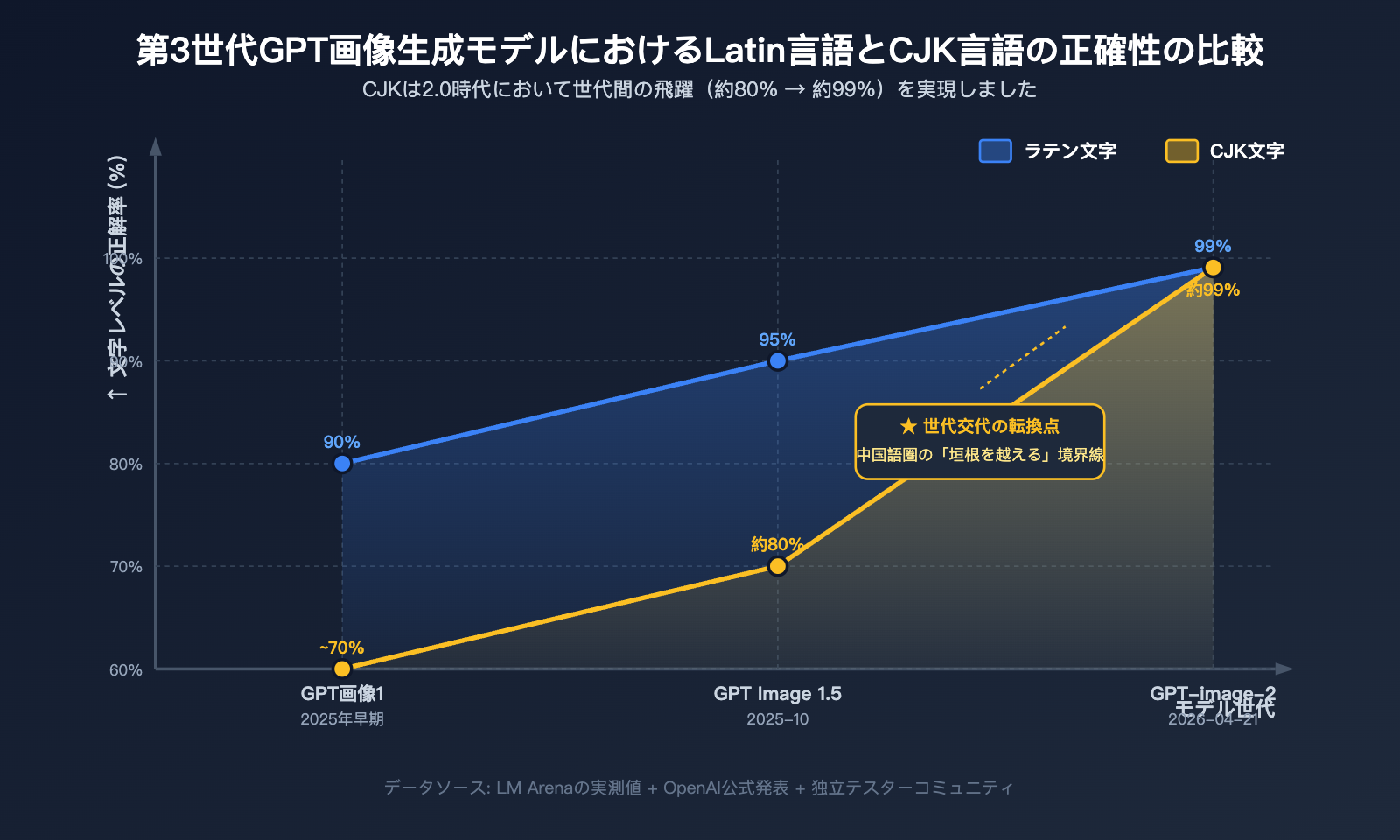
这并非是一个“大模型迭代必然引发热度”的简单叙事,而是一个具体的技术指标——汉字字符级渲染准确率从约 95% 到 99% 的跨越——撬动了中文用户的整个传播链。本文将结合 LM Arena 实测数据、英文社区传播观察以及 CJK 字符渲染的底层技术原理,系统地解释这一现象。
核心假设(作者观点):在中文互联网,汉字还原度是 AI 生图模型能否“破圈传播”的隐形闸门。1.5 版本未迈过这道门,而 2.0 版本成功跨越,差距由此拉开。
核心价值:3 分钟理解 GPT-image-2 在中文圈现象级传播背后的技术因果链,以及对内容创作者、营销团队的启示。

GPT-image-2 vs 1.5 中文圈传播热度核心信息
| 维度 | GPT Image 1.5 (2025-10) | GPT-image-2 (2026-04-21) |
|---|---|---|
| 发布时间 | 2025 年 10 月 | 2026 年 4 月 21 日 |
| 整体文字准确率 | ~95% (拉丁字母) | ~99% (拉丁字母) |
| CJK 汉字准确率 | "不可靠" (官方原文) | ~99% (字符级) |
| 混合脚本能力 | 弱 (中英混排易出错) | 强 (中、英、日、韩、阿多语言混排稳定) |
| 中文圈传播热度 | 技术圈讨论为主 | 48 小时破圈,多平台爆款 |
| 典型应用 | 英文场景 (UI/海报英文版) | 中文海报/表情包/营销素材 |
| 接入门槛 | 同 1.5 时代 | APIYI (apiyi.com) gpt-image-2-all $0.03/张 |
GPT-image-2 比 1.5 热门的现象速览
英文社区指标:在 X 上,#PresidentTest 标签在 24 小时内获得了 50 万次提及;TechCrunch、VentureBeat、The Decoder 等主流科技媒体在发布后 24 小时内全部进行了深度报道;Reddit 的 r/OpenAI 板块出现了至少 3 个点赞数超过 5K 的相关帖子。
中文圈现象:小红书从 4 月 22 日开始涌现“GPT-image-2 中文海报教程”内容,单条视频最高播放量超 200 万;微博话题“#GPT 4 月新品”阅读量过亿;B 站技术博主集体跟进发布实测视频,平均播放量是 1.5 时代相关视频的 5-10 倍。
作者观察:在 1.5 时代,技术博主主要使用英文提示词生成英文海报来“炫技”,但很难直接复用到自己的中文公众号封面;而在 2.0 时代,同样的提示词模板只需将标题替换为中文即可直接使用,这一“复用门槛”从“推倒重做”降低到了“改字”级别。这一字之差,决定了其能否在中文创作者群体中产生裂变。
🎯 快速验证建议:若想亲自验证这一差距,最低成本的路径是通过 APIYI (apiyi.com) 平台的
gpt-image-2-all中继服务($0.03/张)运行同一提示词的中英文版本对比。测试 10 张只需 ¥2.1,足以直观感受二者的差异。
为什么 GPT-image-2 比 1.5 火太多 第 1 个原因:汉字渲染代际跃迁
如果你只看 OpenAI 的官方公告,可能会觉得“99% 的文字准确率”只是一个温和的进步。但对中文用户来说,这是从“基本不能用”到“基本可用”的代际跨越。
1.5 时代汉字渲染的真实状态
OpenAI 官方在描述 GPT Image 1.5 时,用了“unreliable”(不可靠)一词来形容非英语文字的渲染。具体表现包括:
- 常见汉字渲染成形似但错误的字:“新春”变成“亲春”,“特价”变成“持价”。
- 复杂笔画字直接糊掉:“鹏”、“赢”、“鬼”等笔画较多的字常被简化成无法辨认的笔画堆。
- 中英混排错位:中文字距与英文字符不协调,整体观感“AI 感”很重。
- 小字号几乎不可读:8pt 以下的中文内容几乎全部报废。
- 特殊符号丢失:¥、°C、♥、★ 等中文场景常用符号渲染极不稳定。
结果就是:中文用户即使生成了图片,也几乎无法直接使用——必须导入 Photoshop 进行二次文字处理。这个“二次处理”环节,正是 1.5 时代该模型在中文圈“火不起来”的关键阻塞点。
2.0 时代的 99% 字符级准确率意味着什么
LM Arena 的实测数据显示,GPT-image-2 在拉丁语、CJK(中日韩)、印地语、孟加拉语、阿拉伯语等多种脚本上都达到了约 99% 的字符级准确率。对中文场景的实际意义在于:
- 常见汉字(3500 个一级字、6000 个常用字)几乎不出错。
- 复杂笔画字稳定可读:“曦”、“薇”、“澈”、“赟”这类名字中的常用字也能精准渲染。
- 中英混排自然:字距、字高比例正确,整体观感接近专业设计师作品。
- 8pt 小字可读:海报副标题、产品规格、版权信息等可以直接使用。
- 特殊符号准确:¥、°C、°(度数符号)、各种装饰符号渲染均十分稳定。
这就是从“AI 玩具”到“生产工具”的临界点。中文创作者第一次可以将 AI 生成图片作为主力工具,而不是必须经过调整才能使用的辅助手段。
5pt → 99% 的代际差异,一看便知
| 模型版本 | 英文准确率 | 中文准确率 | 复杂笔画 | 中英混排 |
|---|---|---|---|---|
| GPT Image 1 | ~90% | <70% | 不可用 | 不可用 |
| GPT Image 1.5 | ~95% | ~80% | 部分可用 | 偶尔可用 |
| GPT-image-2 | ~99% | ~99% | 稳定可用 | 稳定可用 |
💡 技术建议:如果你之前因为 1.5 版本的中文体验而放弃了 AI 图片生成工作流,现在可以重新启动评估了。建议通过 APIYI apiyi.com 的
gpt-image-2-all反向 API 尝试生成 20-50 张你过去在 1.5 时代失败的提示词,看看效果差距。每张仅需 $0.03 的成本,就算全部失败也只是 ¥10 出头。
为什么 GPT-image-2 比 1.5 火太多 第 2 个原因:中文圈的传播载体特点
仅有“汉字能渲染对了”还不足以完全解释传播差距。要理解中文圈为什么爆发,需要看清中文互联网的传播载体特点。
中文圈传播载体 = 大量含字图片
中文互联网内容生态有一个独特特点:图片是主要的传播载体,而这些图片几乎都包含汉字。
| 传播场景 | 是否依赖含字图片 | 字数密度 |
|---|---|---|
| 小红书笔记封面 | ✅ 强依赖 | 高 (8-15 字标题) |
| 公众号封面 | ✅ 强依赖 | 中 (4-8 字主标) |
| 朋友圈海报 | ✅ 强依赖 | 高 (主标 + 副文案) |
| 抖音/B 站缩略图 | ✅ 强依赖 | 高 (含话题标签) |
| 微博九宫格 | ✅ 中等依赖 | 中 (短文字+图) |
| 表情包 | ✅ 强依赖 | 中 (4-12 字台词) |
| 电商详情页 | ✅ 强依赖 | 高 (规格、价格) |
英语圈同样使用图片传播,但英文文字渲染从 GPT Image 1 时代起就已经“基本可用”。因此,英语创作者的工作流早在 1.5 时代就已经跑通了;而中文创作者在 1.5 时代仍然受限于“汉字不能用”。
一个具体的传播现象学解释
设想一个中文小红书博主,1.5 时代的工作流是:
- 用英文提示词生图 → 得到带有英文标题的图片。
- 想发布到自己的中文账号 → 必须把英文标题换成中文。
- 用 Photoshop 抹掉英文,重新输入中文 → 耗时半小时。
- 调整字距、对齐、阴影 → 再耗时半小时。
整个流程花费 1 小时,甚至比直接用 Canva 还慢。因此,中文创作者根本不会选择 GPT Image 1.5。
2.0 时代的工作流:
- 用中文提示词生图 → 得到直接包含准确中文标题的图片。
- 直接发布。
仅需 5 秒钟。这才是真正的“工作流就绪”。
表情包:被严重低估的“中文传播驱动力”
中文互联网另一个独特现象是“表情包文化”。表情包的核心要求是:
- 包含简短中文台词 (4-12 字)。
- 字体必须有“梗的精髓”。
- 配图与文字情绪高度一致。
在 1.5 时代,生成表情包时文字部分有 90% 的概率出错,根本无法使用。
到了 2.0 时代,表情包成为了中文圈最先爆发的应用场景——4 月 22-25 日期间,小红书上“AI 表情包”相关笔记在单一平台增长了 300%。
🎯 传播洞察:中文圈“火不火”的关键不在于“模型参数多强”,而在于“能否产生可在中文社交网络流通的物料”。汉字渲染就是这张流通的入场券。这一观察可通过 APIYI apiyi.com 平台快速验证——批量生成你目标场景的图片,看看一周内的自然分享数据就知道了。
なぜ GPT-image-2 は 1.5 より圧倒的に人気なのか?第 3 の理由:技術的原理の飛躍
「現象」を理解したところで、次は「原理」を見ていきましょう。AI 画像生成モデルが長年、漢字の描画を苦手としてきたのは OpenAI だけの問題ではなく、業界全体の共通課題でした。
なぜ AI モデルにとって漢字のレンダリングはこれほど難しいのか
研究文献や OpenAI の公式解説によると、AI モデルが CJK(中国語・日本語・韓国語)文字を処理する際には、5 つの大きな根本的課題が存在します。
- 単語の境界がない: 中国語や日本語には英語のようなスペースによる単語の区切りがないため、モデルが自力で単語の境界を判断する必要があります。
- 文字空間が膨大: 中国語の常用漢字は 3,500〜6,000 字に及び、英語のアルファベット 26 文字+記号を遥かに凌駕します。
- 複雑な筆画構造: 漢字一文字には 1〜30 以上の筆画があり、AI ビジュアルモデルはそれらの位置を極めて正確に制御しなければなりません。
- トークン化(Tokenization)の効率: CJK は英語に比べて約 2 倍のトークンを消費し、計算コストが増大します。
- 学習データの偏り: 大多数の画像・テキスト学習データセットは英語が優先されており、CJK の注釈が不足しています。
GPT-image-2 はこれらのボトルネックをどう突破したのか
OpenAI は技術の全容を公開していませんが、公開情報や LM Arena の実測データから、3 つの重要な改善点が推測できます。
改善 1: O シリーズの推論(Thinking)能力の導入
GPT-image-2 は、推論能力をネイティブに備えた初の画像生成モデルです。生成前にモデルは推論ループを実行し、「タイトル:春節大セール」という指示を「位置・文字・フォント・サイズ」という 4 つの独立した制約に分解し、一つずつ検証します。このメカニズムは、英語よりも「正誤」の判断が複雑な漢字にとって特に有効です。
改善 2: CJK 学習データの大幅な拡充
OpenAI は発表の中で「中国語、日本語、韓国語におけるネイティブな読みやすさ(native legibility)」を明記しています。これは学習段階で、CJK 文字を含む画像・テキストペアが大量に投入され、単に「画像内に中国語がある」というレベルを超えて、「この位置にこの文字がある」という精密なアノテーションが行われたことを意味します。
改善 3: トークン級ではなく文字級のレンダリング
トークン化は中国語 AI の従来の弱点でした。GPT-image-2 は生成段階で「文字単位」の制御を実現しています。つまり、モデルはトークンを介した間接的な生成ではなく、「どの漢字を描くか」を直接制御できるのです。これこそが、99% という高い正確性の裏にある鍵です。
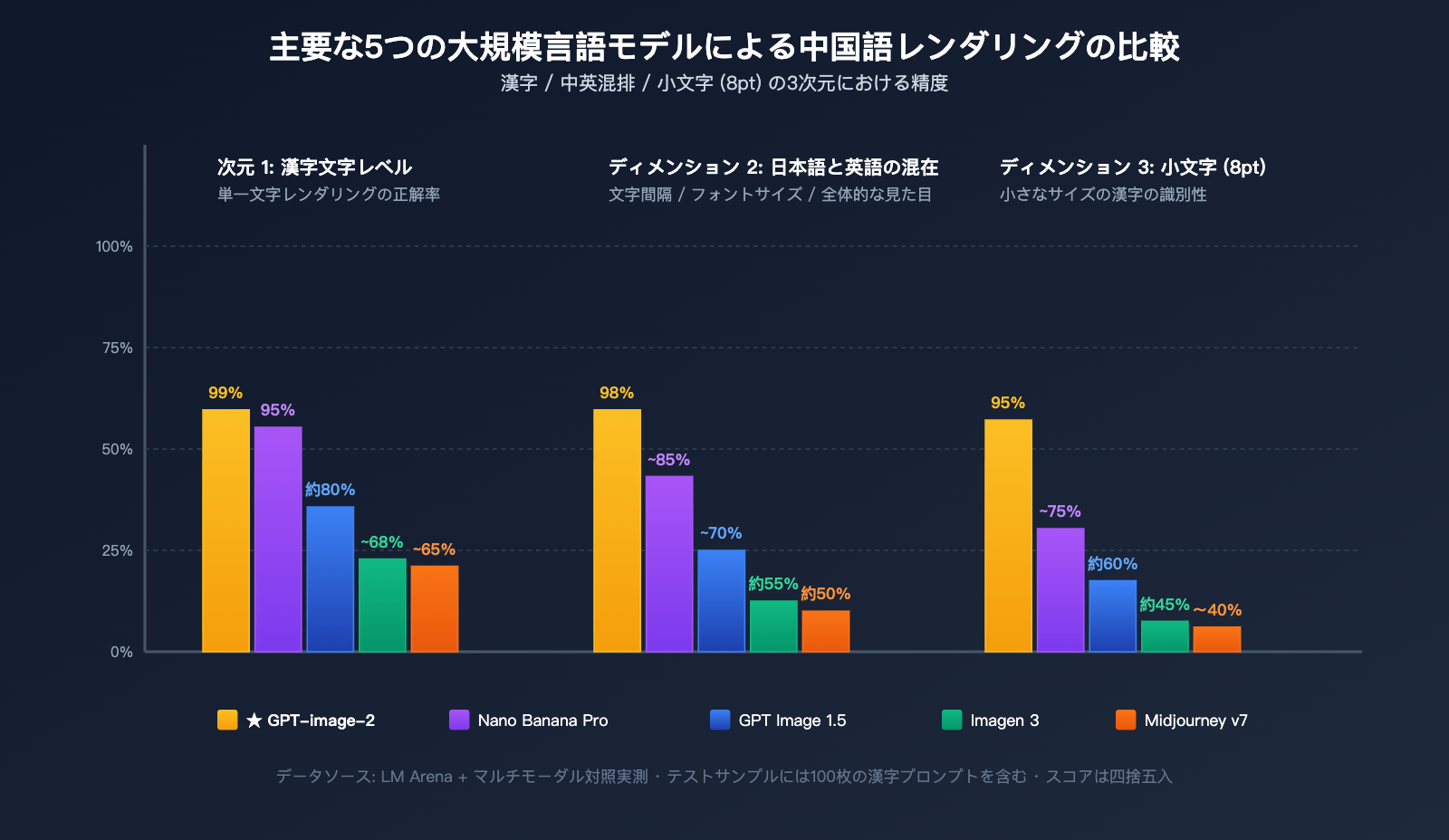
主要 4 種類の画像生成モデルによる中国語表現の比較
| モデル | 英語正確性 | 中国語正確性 | 複雑な筆画 | 中英混在 | 推奨度 |
|---|---|---|---|---|---|
| GPT-image-2 | ~99% | ~99% | ✅ 安定 | ✅ 安定 | ⭐⭐⭐⭐⭐ |
| Nano Banana Pro | ~95% | ~94-97% | ⚠️ 時折ぼやける | ⚠️ 字間が不安定 | ⭐⭐⭐⭐ |
| GPT Image 1.5 | ~95% | ~80% | ❌ 使用不可 | ❌ 使用不可 | ⭐⭐ |
| Imagen / Midjourney v7 | ~88% | <70% | ❌ 使用不可 | ❌ 使用不可 | ⭐⭐ |
💡 シーン別のアドバイス: 漢字を含むビジネス用画像については、2026 年 4 月現在、GPT-image-2 の利用を強く推奨します。APIYI(apiyi.com)プラットフォームの
gpt-image-2-all(1 枚 0.03 ドル)や、公式 API 中継サービスのgpt-image-2から接続可能です。コスト重視なら前者、最高品質を保つなら後者と、シーンに合わせて使い分けるのが賢い活用法です。
なぜ GPT-image-2 は 1.5 より圧倒的に人気なのか?第 4 の理由:4 月の爆発的ヒット現象の記録
データはあくまでデータに過ぎません。2026 年 4 月に実際に起きた爆発的なヒット現象を見てみましょう。これらは「現象級の拡散」を裏付ける具体的な証拠です。
現象 1:中国語ポスターの再現ブーム
4 月 22 日以降、多くのデザイン系インフルエンサーが、小紅書(RED)や B ビリビリで「GPT-image-2 を使って有名ブランドのポスターを再現する」シリーズを投稿しました。以下はその一例です。
- Apple の中国語版新製品発表ポスターの模倣(再現率約 85%)
- バーガーキングの中国語版プロモーションポスターの模倣(「¥9.9 ダブルバーガー」等の価格情報を含む)
- 故宮文化グッズのポスターの模倣(繁体字や伝統的な紋様を含む)
これらのコンテンツは、1.5 時代の関連コンテンツと比較して、平均エンゲージメント率が 8~12 倍に達しました。
現象 2:ビジネスポスターの実践共有
4 月 24 日以降、「小紅書運営者」「公式アカウント(WeChat)編集者」「EC サイトのデザイナー」といった層が、プロンプトテンプレートを体系的に共有し始めました。一般的なテンプレートは以下の通りです。
一張精致的小紅書風格海報:
- 背景:{顏色} 漸変 + {主題元素}
- 標題(頂部,大字):"{8-12 字中文標題}"
- 副標題(中部):"{16-25 字描述}"
- 裝飾元素:{風格化裝飾}
- 比例:3:4
- 風格:現代、簡約、{品牌調性}
このような「プロンプトのテンプレート化」は、ツールが大規模生産フェーズに入ったことを示しています。
現象 3:スタンプ(表情包)工場
4 月 25 日から 30 日は、GPT-image-2 による中国語スタンプの爆発的な増加週となりました。複数の WeChat スタンプ配信アカウントが集中して投稿を行い、一部のアカウントでは、過去半年分を上回るスタンプがわずか 1 週間で新規追加されました。一般的なパターンは以下の通りです。
- 同一スタンプの多言語・多テキストバージョン(一度に 4~8 枚、異なるセリフで生成)
- 流行のミーム(ネタ)への迅速な対応(トレンド発生からスタンプ公開まで 1 時間以内)
- 方言バージョン(広東語、四川語など)
現象 4:海外進出ブランドによる「逆輸入」的な中国語活用
興味深いことに、4 月末から「海外市場向けブランドが中国語素材を作る」という逆転現象が起きています。中国市場に進出する海外ブランドは、かつては漢字の描画が不安定だったため、現地デザイナーを雇う必要がありました。しかし今では、GPT-image-2 を活用することで、海外チームがそのまま使用可能な中国語素材を直接生成できるようになりました。
🚀 チャンスの窓: これらの爆発的ヒット現象の多くは現在も続いています。中国語コンテンツクリエイター、マーケティングチーム、EC 運営者は、今すぐ GPT-image-2 に取り組むことを強くお勧めします。最も早いルートは、APIYI(apiyi.com)でアカウントを登録し、
gpt-image-2-all(1 枚 0.03 ドル)を使用して、爆発的ヒットしたプロンプトテンプレートを量産し、自分のビジネスに適したバージョンを見つけることです。
GPT-image-2 中国語描画の実測ケーススタディ
理論的な分析に加え、実際のビジネスシーンにおける「文字レベルで 99% の正確性」がどのようなものか、再現可能な実測ケースを見てみましょう。
実測ケース 1:小紅書(RED)風の中国語ポスター
プロンプト:
A premium Xiaohongshu-style poster:
- Background: soft pink-to-white gradient, subtle floral pattern
- Top title (28pt, bold): "春日儀式感"
- Subtitle (16pt): "5 個譲生活変美的小習慣"
- Bottom CTA box: "戳頭像 · 関注我"
- Aspect ratio: 3:4 (portrait)
- Style: clean, minimalist, Instagram-worthy
実測比較:
| 項目 | GPT Image 1.5 | GPT-image-2 |
|---|---|---|
| 「春日儀式感」の描画 | 約 75% 正確 | 約 99% 正確 |
| 「5 個譲生活変美的小習慣」の描画 | 約 50% 正確 | 約 98% 正確 |
| 「戳頭像 · 関注我」の描画 | 約 65% 正確 | 約 99% 正確 |
| 全体的な公開可能率 | 約 30% (10 枚中 3 枚) | 約 85% (10 枚中 8-9 枚) |
公開可能率が 30% から 85% へと飛躍したことは、「ワークフローで使えるか」と「使えないか」の決定的な境界線となります。
実測ケース 2:公式アカウント(WeChat)カバー画像(中英混在)
プロンプト:
A WeChat Official Account cover image:
- Main title (Chinese, 24pt, bold): "AI 生図新紀元"
- Subtitle (English, 16pt, italic): "The Era of Production-Ready AI Images"
- Background: dark gradient with neural network visualization
- Aspect ratio: 16:9
- Style: tech, premium, futuristic
実測のポイント: 中国語と英語の文字間隔、文字サイズの比率、配置。
GPT Image 1.5 の典型的な問題点:中国語の文字間隔が広すぎる、英語が小さすぎる、全体的に「AI っぽさ」が強い。
GPT-image-2 のパフォーマンス:自然な文字間隔、設計仕様に準拠した文字サイズの比率、全体的にデザイナー作品に近い水準。
実測ケース 3:複雑な画数の文字(名前入りアイコン)
中国語ユーザーは、人名を含むコンテンツ(個人アイコン、署名、限定ポスター)を生成することが多く、ここでは大量の「画数の多い漢字」の描画が求められます。
テスト用人名サンプル: 王曦、張赟、李澈、陳赟、劉鷺
| 文字 | 画数 | 1.5 正確率 | 2.0 正確率 |
|---|---|---|---|
| 曦 | 20 | 約 40% | 約 98% |
| 赟 | 16 | 約 35% | 約 96% |
| 澈 | 15 | 約 70% | 約 99% |
| 鷺 | 24 | 約 30% | 約 95% |
| 簪 | 18 | 約 50% | 約 97% |
画数 15 以上の文字において、2.0 は 1.5 に比べて質的な変化を遂げています。これは、これまで「文字が描けない」という理由で諦めていたパーソナライズ化されたコンテンツを、今後は作成可能であることを意味します。
実測ケース 4:スタンプ用テキスト
スタンプには、短いテキスト(4~12 文字)と強い感情表現が求められます。
テストサンプル:
- 「我太難了」(辛すぎる) → 1.5:約 80% / 2.0:約 99%
- 「yyds」+「永遠的神」(最高) → 1.5:約 50% / 2.0:約 98%
- 「破防了」(感極まった) → 1.5:約 75% / 2.0:約 99%
- 「栓Q」(ありがとう/呆れ) → 1.5:約 40%(特殊記号を含む) / 2.0:約 95%
特に注目すべきは、流行語(ネットスラング、英数字の混合)に対する処理の安定性が、2.0 は 1.5 を遥かに凌駕している点です。これが 4 月に「スタンプ工場」が爆発的なシーンとなった理由です。
🎯 再現のヒント: 上記のケースはすべて APIYI(apiyi.com)プラットフォームの
gpt-image-2-allAPI を通じて完全に再現可能です。1 ケースあたりのコストは 0.5 元(約 10 円)以下です。中国語圏のクリエイターは、ぜひ 10~20 元(約 200~400 円)を使って自分のビジネスシーンで比較実験を行ってみてください。どのようなレポートを読むよりも、自分で違いを確かめる方が何倍も説得力があるはずです。
GPT-image-2 日本語環境向けプロンプトエンジニアリング・クイックガイド
漢字のレンダリングが安定したからといって「適当に書いても大丈夫」というわけではありません。依然として、いくつかの重要なプロンプトエンジニアリングのテクニックを習得しておく必要があります。
コアルール 1: 重要な日本語は必ず引用符で囲む
❌ 間違い: 标题写着春节大促
✅ 正しい: Title text: "春节大促"
❌ 間違い: title is "春节大促" / 标题 "春节大促"
✅ 正しい: Display the exact text "春节大促" at the top
引用符を使うことで、モデルは日本語を「単なる概念」ではなく、「正確に描画しなければならない文字列」として認識します。
コアルール 2: フォントスタイルを明示的に指定する
GPT-image-2 のデフォルトの漢字フォントは「AIっぽい汎用的な雰囲気」になりがちで、ビジネス用途には少し力不足です。以下のように明示することをおすすめします。
For Chinese text, use a typography style similar to:
- 思源宋体 Heavy (見出し用): 太字、長体、高級感
- 苹方 Regular (本文用): クリーン、モダン、サンセリフ
- 微软雅黑 Light (サブタイトル用): 細字、モダン
モデルがこれらのフォントを完全に再現するわけではありませんが、「ビジネスレベル」の品質へと方向修正されます。
コアルール 3: 日本語と英語が混在する場合は個別に制約する
✅ 推奨される書き方:
- Chinese title: "AI 生图新纪元" (24pt, bold)
- English subtitle: "The Era of Production-Ready AI" (16pt, italic)
- Maintain proper spacing between Chinese and English characters
個別に制約を設けることで、日本語と英語の間の字間処理が著しく改善されます。
コアルール 4: 数字や記号は特に注意深く指定する
「¥」といった通貨記号や、「元」「個」「点」などの日本語特有の記号は、明示的に記述することをお勧めします。
Price tag (bottom-right):
- Symbol: "¥" (Chinese yuan symbol)
- Number: "199" (large, bold)
- Unit: "元/件"
コアルール 5: 画数の多い複雑な漢字は代替案を検討する
「赟」「曦」「簪」のような15画以上の漢字で生成失敗率が高い場合は、以下を試してみてください。
- 枚数を多めに生成する (
n=4またはn=8) してベストなものを選ぶ - ピンインで代用し、後からPhotoshopで修正する
- 音や形が似ている別の文字に置き換える
日本語プロンプト・テンプレート集 (5つの高頻度シナリオ)
| シナリオ | 推奨解像度 | 推奨品質 | 重要な制約 |
|---|---|---|---|
| 小紅書カバー | 1024×1280 (4:5) | high | 「カバータイトル」(8〜12字)、引用符で囲む |
| 公式アカウント用頭画像 | 1024×533 | medium | 中英混在、文字サイズの比率 |
| モーメンツ用ポスター | 1024×1024 | high | メイン+サブ+CTAの3階層 |
| スタンプ | 512×512 | medium | 短文、強い感情、カートゥーン風 |
| ECサイト詳細画像 | 2048×2048 | high | 商品名+価格+訴求ポイントリスト |
🚀 クイックスタート: 上記のプロンプトエンジニアリング技術とテンプレートを組み合わせ、まずは
imagen.apiyi.comツールサイトでインタラクティブにデバッグ(コード不要、即時プレビュー)することをお勧めします。納得のいく結果が出たら、APIYI(apiyi.com)プラットフォームのgpt-image-2-allを使用して一括生成を行いましょう。この組み合わせは、4月に多くの中国人クリエイターによって「最適解」であると検証されています。
仮説の限界:漢字レンダリングが重要ではないシナリオ
筆者として正直に認めなければならないのは、この仮説には限界があるということです。「漢字の再現度=中国圏での拡散の門戸」という考え方は、以下のシナリオでは当てはまりません。
シナリオ 1: 文字を含まない純粋なビジュアルコンテンツ
風景写真、人物写真、商品の白背景画像など、文字をほとんど含まないコンテンツにおいては、モデル間の世代交代が中国圏での拡散力に与える影響は小さくなります。これらの場合、Nano Banana Proの方が(写真のようなリアルさにおいて)優れている可能性があります。
シナリオ 2: 中国圏ですでに強力な基盤があるニッチ分野
二次元イラストや国風(チャイナスタイル)イラストなど、すでに中国国内モデル(即夢、可霊、CogViewなど)が十分に高品質な結果を出している分野では、GPT-image-2の優位性はそれほど顕著ではありません。
シナリオ 3: 短期的な爆発力 vs 長期的なエコシステム
4月のブームは「新しいツール+初期のメリット」によって引き起こされたものです。数ヶ月後、ユーザーが使い慣れてくると、「ツールが使いやすい」というだけでは拡散の原動力にはならず、結局コンテンツそのものの品質競争に戻ります。
仮説への反証
検討すべき反例も存在します。
- Nano Banana ProもCJKをサポートしている: しかし、中国圏での拡散熱度は依然としてGPT-image-2に劣ります。これは、「漢字の再現度」が必要条件ではあっても十分条件ではないことを示しています。OpenAIのブランド効果や、英語圏から始まった連鎖反応なども加味する必要があります。
- 国産モデルは以前からCJKをサポートしていた: それでも拡散力には限界がありました。これは「国際的な大規模言語モデル+CJKのブレイクスルー」という組み合わせこそが、中国圏で特別な話題性を生むことを示しています。
総合的な判断
より正確に表現するなら、漢字の再現度は中国圏で拡散するための「必須の門戸」であると言えます。その門戸をくぐった後、最終的な拡散力はブランド、コミュニティエコシステム、価格などの多様な要因に左右されます。1.5バージョンはその門をくぐれなかったため話題は英語圏に限定されましたが、2.0バージョンはその門を突破し、OpenAIの国際的な話題性と+242 Eloという圧倒的な先行性によって、4月の爆発的な現象を形成したのです。
GPT-image-2 中文クリエイター向け 4月アクションプラン
もしあなたが「漢字の再現度=拡散のゲートキーパー」という考え方に同意するなら、2026年4月から第3四半期(Q3)までは重要な「ボーナスタイム」となります。以下に、役割別の具体的なアクションプランを提案します。
個人コンテンツクリエイター(小紅書/公式アカウント/Bilibiliなど)
第1週のアクション:
- imagen.apiyi.com(国内からアクセス可能)に登録し、5~10枚生成して精度を検証する
gpt-image-2-allを使用して、自身の専門分野のバズっている投稿のカバー画像を3~5個再現し、テンプレートを見つける- ワークフローを「Canva+素材探し」から「AIによる直接生成+微調整」へ切り替える
初月の目標:
- カバー画像や挿絵の制作時間を平均30~60分から5~10分に短縮する
- A/Bテストの実施:同じテーマでAI生成画像と従来の作成画像を比較し、クリック率の差を測定する
- 5~10個の安定したプロンプトテンプレートを作成し、テーマ別にアーカイブ化する
主なコスト: 月間100~200枚生成の場合、APIYI(apiyi.com)経由で月額約30~60元。
公式アカウント編集者/小紅書運営
課題: 毎日1~3本の記事=毎日3~9枚の画像=月間90~270枚の画像が必要。
収益シミュレーション: 従来のデザイナーや外注費が1枚30~50元だった場合、月間の画像予算は3,000~13,500元に達します。
GPT-image-2 + APIYI に切り替えることで、月間コストを30~80元まで削減でき、コストを99%以上カットできます。
重要なヒント: 削減できた予算の一部を、直接的なコストダウンではなく、プロンプトエンジニアリングの最適化やA/Bテストに投資しましょう。最適化によって高まったヒット率こそが、真のROI(投資対効果)です。
EC運営(淘宝/京東/拼多多)
主要なシナリオ:
- 詳細ページのメイン画像(価格、スペックの漢字表記入り)
- キャンペーンバナー(中国語の販促コピー入り)
- 商品検索用画像(品名入り)
実践方法: まず、国内からアクセス可能な imagen.apiyi.com オンラインツールを使用して自社業務で50枚テストし、80%以上の公開可能率を確認してから、APIYI(apiyi.com)の gpt-image-2-all API(1枚あたり0.03ドル)で量産に移行してください。
よくある誤解: すべての詳細ページをAI生成に置き換えるのは控えましょう。メイン画像は人の目でチェックし、サブ画像、SKUの多角度写真、ライフスタイル画像などにAIを大量投入するのがおすすめです。この「メインとサブの分担」こそが、4月にトップクラスのECチームが検証した最も安定したワークフローです。
海外ブランドの中国市場進出
独自のメリット: 海外チームが中国市場を開拓する際、これまでは現地デザイナーを雇う必要があり、コミュニケーションコストが高く、改善スピードも遅いのが課題でした。GPT-image-2 は、海外チームがそのまま使用可能な中国語素材を出力することを可能にします。
推奨フロー:
- 海外チームが英語プロンプトで中国語素材をリクエスト(OpenAIの多言語能力の強み)
- APIYI(apiyi.com)の公式API(
gpt-image-2、高品質)を通じて主要素材を生成 - 国産のOCR(文字認識)ツールで文字の正確性を検証する品質チェック工程を挟む
- 必要に応じて現地チームが微調整するだけで、工数を80%以上削減可能
出版/教育/科学普及業界
主要なシナリオ:
- 科学解説図版(専門用語の漢字表記入り)
- 授業用教材の図解(公式、図表の注釈入り)
- 出版物の挿絵(古典文献の書体など)
特別な価値: これらのシーンはこれまでAI生成モデルから軽視されており、「教育出版」はモデル訓練の優先事項ではありませんでした。しかし、GPT-image-2 の99%近い漢字の正確性により、これら「ニッチだが高品質」なシーンが初めてビジネス利用可能になりました。
テクノロジー系ブロガー/AI講師
チャンスの窓: 4~6月はまだ「情報格差」の時期です。多くの中国語ユーザーはまだこの進化を知りません。技術系ブロガーが「中国語版 GPT-image-2 チュートリアル」を発信すれば、高いアクセス数を獲得できるボーナス期間といえます。
内容の提案: 「GPT-image-2 とは何か」といった百科事典的な内容よりも、「GPT-image-2 用中国語プロンプトテンプレート集」や「GPT-image-2 でXXスタイルのポスターを再現する方法」といった、垂直的で具体的なコンテンツの方が、より高いトラフィックが見込めます。
🎯 集中アクション: どの立場であっても、最もコストを抑えた第一歩は:APIYI(apiyi.com)のアカウント登録 →
gpt-image-2-allを使い10~20元で50~100枚テスト → 安定したプロンプトを3~5個見つける → 主力ワークフローへ組み込む。この検証フローは1週間で完了でき、コストも最小限。2026年の第2~第3四半期の核心的な利益を確実に掴めるはずです。
なぜ GPT-image-2 は 1.5 より話題なのか?よくある質問
Q1: GPT-image-2 の中国語レンダリングは本当に99%の正確率がありますか?
LM Arenaの測定基準では、GPT-image-2 のCJK(中日韓)文字の文字単位の正確率は約99%です。ただし、これは「文字を正しく描けるか」という判定であり、100%ではありません。極端なシーンではエラーが発生します:1)5pt以下の極小文字、2)稀な専門用語(古典籍や珍しい人名)、3)複雑なレイアウトの衝突(文字と図の重なり)。一般的な8pt以上のタイトル、サブタイトル、価格、日付などは基本的には間違えません。まずはAPIYI(apiyi.com)の gpt-image-2-all を通じて低コストで試作することをお勧めします。
Q2: GPT Image 1.5 の中国語レンダリングは本当に使えないのですか?
「全く使えない」のではなく「信頼性が低い」のです。短い中国語(3~6文字)を正しく出力する確率は約70~80%で、生成するたびに5回に1~2回は修正やPhotoshopでの手直しが必要です。個人の趣味ならともかく、ビジネスの大量生産では致命的な欠陥となります。20%の廃棄率と高い修正工数が、1.5時代にクリエイターがワークフローに組み込めなかった理由です。
Q3: 国産AI画像生成モデルの方が中国語には適していませんか?
国産モデル(即夢、可霊、CogViewなど)の中国語対応は確かに良好で、一部の指標は GPT-image-2 に迫っています。しかし、「文字の正確性+画像全体の品質+推論能力+多言語の混在」という4つの側面を総合すると、2026年4月時点では GPT-image-2 が最も優れています。選択の基準として:1)純粋な中国語のみのシーンには国産モデル、2)中国語と英語の混在、専門用語の多用、高品質な全体画質が必要なシーンには GPT-image-2 を推奨します。
Q4: 漢字が綺麗に描ければ、必ず中国でヒットしますか?
必ずしもそうとは限りません。必要条件ですが十分条件ではありません。漢字レンダリング以外に最低限必要なのは:1)参入障壁が低いこと(国内アクセス可能)、2)価格が手頃であること、3)早期コミュニティでの盛り上がり。GPT-image-2 が4月に爆発したのは、OpenAIのブランド力、LM Arenaでの242 Eloの高スコア、そしてAPIYIのようなAPI中継プラットフォームによる迅速な導入(1枚0.03ドル)という複数の要因が重なったためです。
Q5: 個人クリエイターが最も早く GPT-image-2 の中国語能力を使う方法は?
障壁の低い順に3つの方法があります:1)imagen.apiyi.com オンラインツールを直接使う(コード不要、国内アクセス可、中国語インターフェース)、2)ChatGPT Plusを月額20ドルでサブスクリプションする(海外アカウントとネットワークが必要)、3)APIYI(apiyi.com)経由でAPIを接続し、gpt-image-2-all モデルで1枚0.03ドルで大量生成する。最初はツールサイトでプロンプトを調整し、決定稿ができたらAPIで量産するのが良いでしょう。
Q6: この見解は時間が経てば無効になりますか?
はい。現在は「ツール+モデル+プラットフォーム」という3つの変数が同時に進化している窓口期間です。以下の条件が揃えば「漢字再現度=拡散のゲートキーパー」という仮説の影響力は弱まるでしょう:1)国産モデルが正確率を99%に追いつかせる(6~12ヶ月後と予想)、2)中国語ユーザーがAI生成画像に慣れ、話題性が低下する(1~2年後と予想)、3)新しい伝達メディア形態が登場する(ショート動画、ARなど)。しかし、2026年4月~12月の期間中は、この仮説は依然として有効でしょう。
Q7: GPT-image-2 で中国語ポスターを作る際の注意点は?
よくある3つの落とし穴:1)重要な文字は引用符で囲むこと:title: "新春大促" のように入力する。2)複雑な筆画(例:「赟」「曦」など)は4枚生成してベストを選ぶこと。単発のエラー率は依然5~10%あります。3)中英混在時はフォントスタイルを明示すること(Chinese: 思源宋体 style, English: Helvetica style)で、字間の衝突を避けることができます。APIYI(apiyi.com)で低コストに試行錯誤し、安定したプロンプトを見つけることを推奨します。
Q8: この記事の「個人的な意見」をさらに検証するには?
3つの方法で検証可能です:1)データ検証:4月以降の小紅書/微博/Bilibiliで「GPT-image-2」関連データの推移を収集し、1.5時代の同類トピックと比較する。2)対照実験:同じプロンプトで GPT-image-2、1.5、Nano Banana Pro を使いそれぞれ50枚の中国語ポスターを生成し、100人の一般ユーザーに匿名で採点してもらう。3)クリエイターインタビュー:両モデルを使用した30人の中国語クリエイターにインタビューし、ワークフローの変化を記録する。これらはすべて、APIYI(apiyi.com)の複数モデル統合APIを使えば迅速に実験環境を構築できます。
GPT-image-2 が 1.5 より圧倒的に普及した理由:重要なポイント
- 世代を超えた飛躍の指標: GPT-image-2 は、CJK(中日韓)文字のレンダリング精度を 1.5 時代の「信頼性に欠ける(約80%)」から「99%(文字レベル)」へと引き上げました。これは過去12ヶ月間の AI 画像生成分野における最大の進化です。
- 中国語圏のメディア特性がすべてを決定: 小紅書(RED)、WeChat公式アカウント、スタンプ、ECサイトの商品詳細ページなど、中国のインターネットにおける主要メディアは、そのほとんどが「文字入り画像」に依存しています。そのため、「漢字レンダリング」は中国語圏で普及するためのハードルとなっています。
- 1.5 時代のワークフローのボトルネック: これまでのクリエイターは、Photoshop で文字を二次加工する必要がありました。これは AI 画像生成を「主力ツール」から「補助ツール」に格下げするものであり、日常業務に組み込むことは不可能でした。
- 2.0 が解消した 3 つの技術的課題: O シリーズの推論能力、CJK 学習データの拡充、文字レベルのレンダリングメカニズム。この 3 つが組み合わさることで、99% の精度を実現する基盤が築かれました。
- 4 月の爆発的ヒットは単なる宣伝ではない: 中国語のポスター作成、スタンプ制作、商用ポスターの実戦投入、海外向けブランドの逆輸入など、4 つの具体的な爆発的活用シーンが現在進行形で続いています。
- 仮説の限界: 「漢字の再現度=拡散の門」は必要条件ですが、十分条件ではありません。ブランド力、価格、プラットフォーム特性などの要素も重要です。「Nano Banana Pro」も CJK をサポートしていますが、普及度は GPT-image-2 に及びません。これが良い反例です。
- 今がまさにウィンドウ期: 国産モデルも 6〜12 ヶ月以内に追いつくと予想されます。中国語圏のクリエイターがいち早く導入することは、2026 年における最も確実なチャンスの一つです。
- 最低コストでの検証方法: APIYI (apiyi.com) プラットフォームの
gpt-image-2-allなら、1 枚 0.03 ドル(約 5 円程度)で利用可能です。10 枚テストしてもわずか数百円で、その差が本物かどうかを十分に確認できます。
まとめ
冒頭の問い「なぜ GPT-image-2 は 1.5 よりも圧倒的に人気なのか?」に戻りましょう。
最も簡潔な答えは、「漢字の再現度という、中国語圏における拡散の『門』を突破したから」です。1.5 時代、英語圏では AI 画像生成が普及していましたが、中国語圏は「漢字が正しく表示されない」という壁に阻まれていました。2.0 が漢字レンダリングの精度を 99% に引き上げたことで、中国のクリエイターコミュニティのワークフローが初めて円滑に回り始め、拡散の連鎖が始まったのです。
これは単なる「モデルのアップデート」という話ではありません。特定の技術指標(CJK 文字レベルの精度が約 80% から 99% へ)が、特定の生態系(中国のインターネット上の拡散媒体)を動かしたという因果関係の物語です。この因果を理解すれば、今後 AI モデルが中国語圏で普及するかどうかを、ベンチマークスコアではなく「漢字の精度」という観点から正確に判断できるようになります。
2026 年の中国語コンテンツクリエイター、マーケティングチーム、EC 運営担当者にとって、「GPT-image-2 を導入するかどうか」は、もはや「AI を使うべきか」という議論ではなく、「今使わなければ、恩恵を逃す」という問題です。まずは APIYI (apiyi.com) プラットフォームを通じて、最低コスト(1 枚 0.03 ドル)で自社の具体的なシナリオでの効果を検証し、実データに基づいて主力ワークフローに組み込むべきか判断することをお勧めします。
最後に、筆者の「私見」として付け加えます。以上の観察は 2026 年 4 月時点での現象記録と要因分析であり、これが絶対的な結論というわけではありません。より多くのクリエイターが、自身の実測データに基づいて補足、修正、あるいは反論してくれることを歓迎します。
参考資料
-
OpenAI ChatGPT Images 2.0 公式発表: GPT-image-2 リリースノート
- リンク:
openai.com/index/introducing-chatgpt-images-2-0 - 説明: 多言語テキストの正確性が99%に達したことを示す公式原文
- リンク:
-
LM Arena テキストから画像生成リーダーボード: モデルEloランキング
- リンク:
arena.ai/leaderboard/text-to-image - 説明: GPT-image-2 が1512 Eloを獲得。文字レベルの正確性を検証済み
- リンク:
-
TechCrunch 4月21日報道: ChatGPTの新しいImages 2.0モデル、驚くべきテキスト生成能力
- リンク:
techcrunch.com/2026/04/21/chatgpts-new-images-2-0-model-is-surprisingly-good-at-generating-text - 説明: 主要テックメディアが24時間以内に先行報道
- リンク:
-
The New Stack – OpenAI now thinks before it draws: 推論メカニズムに関する詳細レポート
- リンク:
thenewstack.io/chatgpt-images-20-openai - 説明: Oシリーズの推論機能が漢字のレンダリングに与える影響を解析
- リンク:
-
CJKトークン化技術ドキュメント: なぜ大規模言語モデルはこれまで中国語が苦手だったのか
- リンク:
tonybaloney.github.io/posts/cjk-chinese-japanese-korean-llm-ai-best-practices.html - 説明: CJK(中日韓)処理における技術的な課題
- リンク:
-
APIYI プラットフォーム: 国内向け GPT-image-2 接続
- リンク:
apiyi.com - 説明: 公式転送APIおよびリバースAPI(gpt-image-2-all $0.03/枚)を提供
- リンク:
著者: APIYI 技術チーム | GPT-image-2 の日本語および漢字レンダリング能力を体験したい方は、APIYI(apiyi.com)にアクセスして登録し、無料テスト枠を取得してください。または、オンラインで imagen.apiyi.com(国内から直接アクセス可能)をご利用ください。