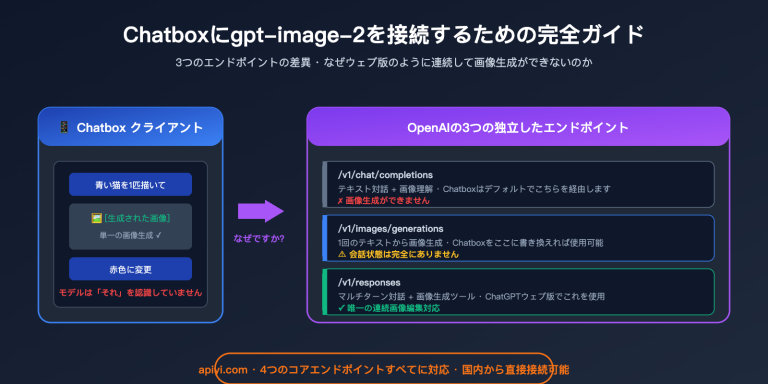
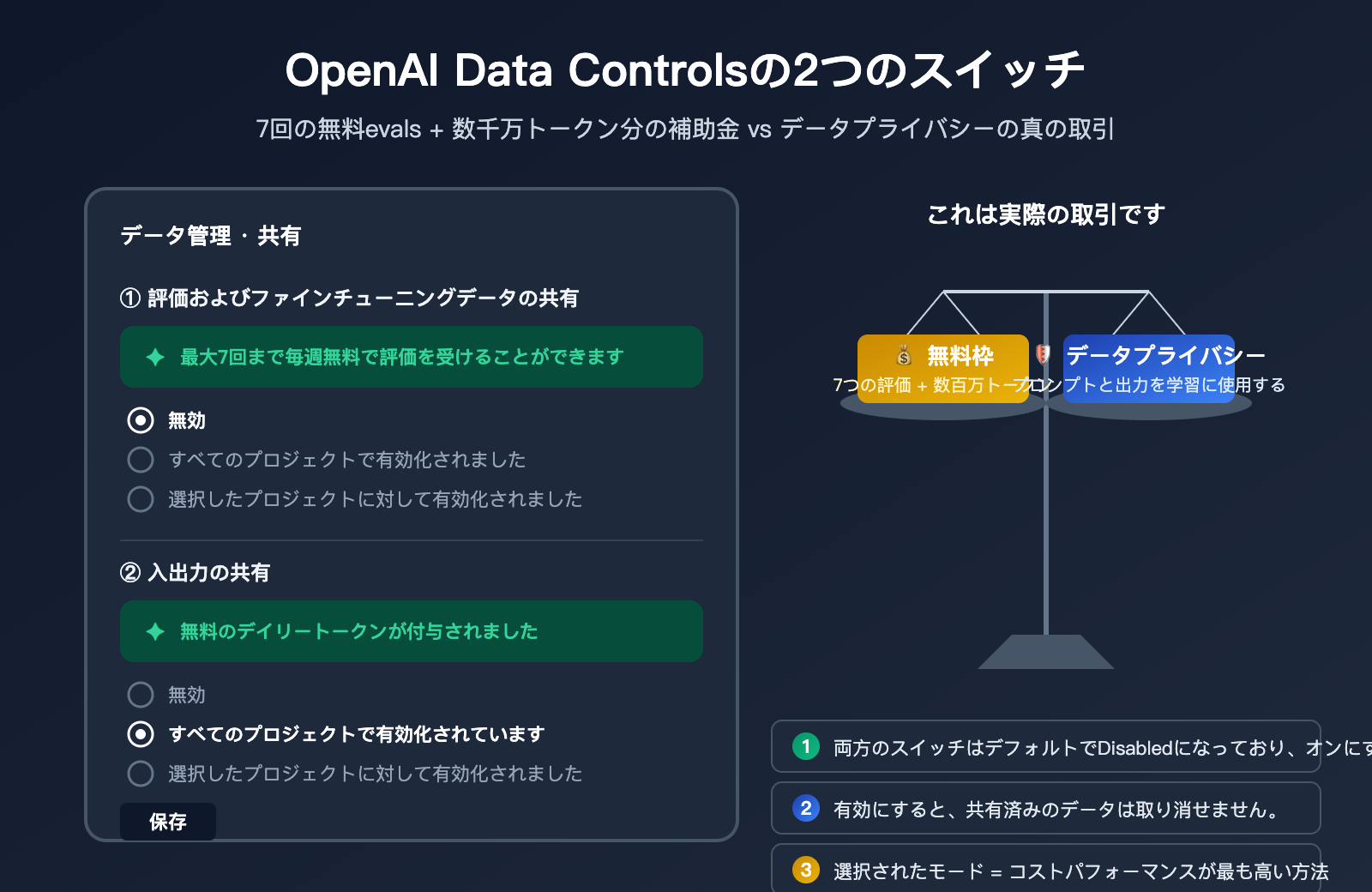
OpenAIの管理画面にある「Data Controls」ページを開くと、2つのスイッチが目に飛び込んできます。「Share evaluation and fine-tuning data with OpenAI」と「Share inputs and outputs with OpenAI」です。それぞれ「Disabled(無効)」「Enabled for all projects(全プロジェクトで有効)」「Enabled for selected projects(選択したプロジェクトのみ有効)」の3段階から選べるようになっています。
最初の項目には「最大7回分の無料ウィークリー評価(evals)が利用可能」という緑色のメッセージが表示され、2つ目には「無料のデイリートークンが付与されます」と書かれています。一見すると「リソースがもらえるお得な設定」に見えますが、これを有効にすることでどのような代償を払うことになるのか、不安に感じる方も多いのではないでしょうか。
実は、これら2つのスイッチは、OpenAIが「無料枠」と引き換えに「学習・評価データ」を得るという双方向の取引です。有効化の代償は決して小さくありません。評価データやAPIの入出力データは、OpenAIによって将来のモデル改善のために利用されます。APIYI(apiyi.com)のお客様の中には、半年間有効にしたままにしてプライバシーリスクに気づいた方や、逆に半年間オフにしていたために毎日百万単位の無料トークン枠を無駄にしていた方もいらっしゃいました。
この記事では、英語の公式資料に基づき、これら2つのスイッチの真の役割、獲得できる枠、プライバシーへの影響、そして推奨される設定について徹底解説します。
OpenAI Data Controls 2つの設定項目の核心定義
「Settings」→「Data Controls」→「Sharing」ページを開くと、独立しているものの混同されやすい2つのスイッチがあります。これらは共有されるコンテンツ、見返り、プライバシーへの影響が全く異なるため、その境界を理解することが正しい判断を下すための前提となります。
| 設定項目 | Share evaluation and fine-tuning data | Share inputs and outputs |
|---|---|---|
| 共有内容 | 評価用プロンプト + 結果 + 評価ロジック + 微調整データ | API呼び出しの全入力および出力 |
| 無料の見返り | 週最大7回の無料評価(eval)実行 | 日次トークン補助(Tierおよびモデル群に応じて分配) |
| データの用途 | 評価パイプラインの改善 + 将来のモデル学習 | モデルの学習・改善に直接利用 |
| デフォルト状態 | Disabled(無効) | Disabled(無効) |
| 設定の粒度 | Disabled / All / Selected の3段階 | Disabled / All / Selected の3段階 |
| 操作権限 | Org Ownerのみ | Org Ownerのみ |
| 適用範囲 | 有効化後に生成されたデータのみ共有 | 有効化後に発生したトラフィックのみ共有 |
| 無効化の難易度 | いつでも切り替え可能 | いつでも切り替え可能 |
🎯 理解のためのヒント: 「安全に無料枠を獲得したい」という場合は、設定を「Enabled for selected projects」にすることをお勧めします。テスト用のプロジェクトを別途作成し、開発や内部スクリプトの実行にのみ使用します。メインのプロジェクトや本番環境のAPIトラフィックはAPIYI(apiyi.com)のゲートウェイを経由させることで、すべてのプロジェクトを不用意にデータ学習パイプラインにさらすリスクを回避できます。
Share evaluation and fine-tuning data 設定の詳細
このスイッチは直訳すると「評価および微調整(ファインチューニング)データの共有」となりますが、実際に共有される範囲は名前が示唆するものよりも広範囲です。この機能を有効にすると、OpenAI はあなたの評価用プロンプトや回答(completions)だけでなく、定義した grading logic(評価ロジック)や、ファインチューニング用データセット内のプロンプトと回答も取得します。つまり、モデルをどのように採点しているか、どのような回答を良しとしているか、そしてトレーニングデータに含まれるドメイン知識までが OpenAI に収集されることになります。
その見返りとして、週に最大 7 回の無料評価(eval)実行が提供されます。OpenAI のヘルプセンターには「共有された評価は、現在週 7 回まで無料で処理される」と明記されています。この上限を超えた場合や、無料枠の対象外となるモデルを使用した場合は、通常のトークン料金が課金されます。この数字は小さく見えるかもしれませんが、頻繁にモデルの選定や比較を行うチームにとっては、毎週 7 回の無料実行で数百ドルの評価コストを削減できる可能性があります。
注意すべき点は、このスイッチは有効にした後のデータに対してのみ適用されるという点です。過去のデータが遡って共有されることはありませんし、オフにしたからといって既に共有されたデータが「撤回」されるわけでもありません。したがって、意思決定は「現在どのようなデータを持っているか」ではなく、「今後 6〜12 ヶ月間でどれくらいの評価データを共有するつもりか」に基づいて行うべきです。
| 項目 | 有効化のメリット | 有効化の代償 |
|---|---|---|
| 直接的な利益 | 週 7 回の無料評価実行 | / |
| 間接的な利益 | 評価パイプラインが OpenAI によって最適化される | / |
| データ上の代償 | / | 評価用プロンプト、回答、評価基準の収集 |
| ビジネス上の代償 | / | ファインチューニング用データセットのノウハウ漏洩 |
| 可逆性 | いつでもオフに可能 | 共有済みデータの撤回は不可 |
🎯 Eval/FT 共有を有効にするタイミング: 評価が公開ベンチマークや非機密のテストセットに基づいている場合は、基本的に有効にしても問題ありません。しかし、評価用プロンプトに顧客のリアルデータ、内部の業務ルール、独自の評価ロジックが含まれている場合は、「Selected」モードに設定し、サンドボックスプロジェクトのみに適用することをお勧めします。
Share inputs and outputs 設定の詳細
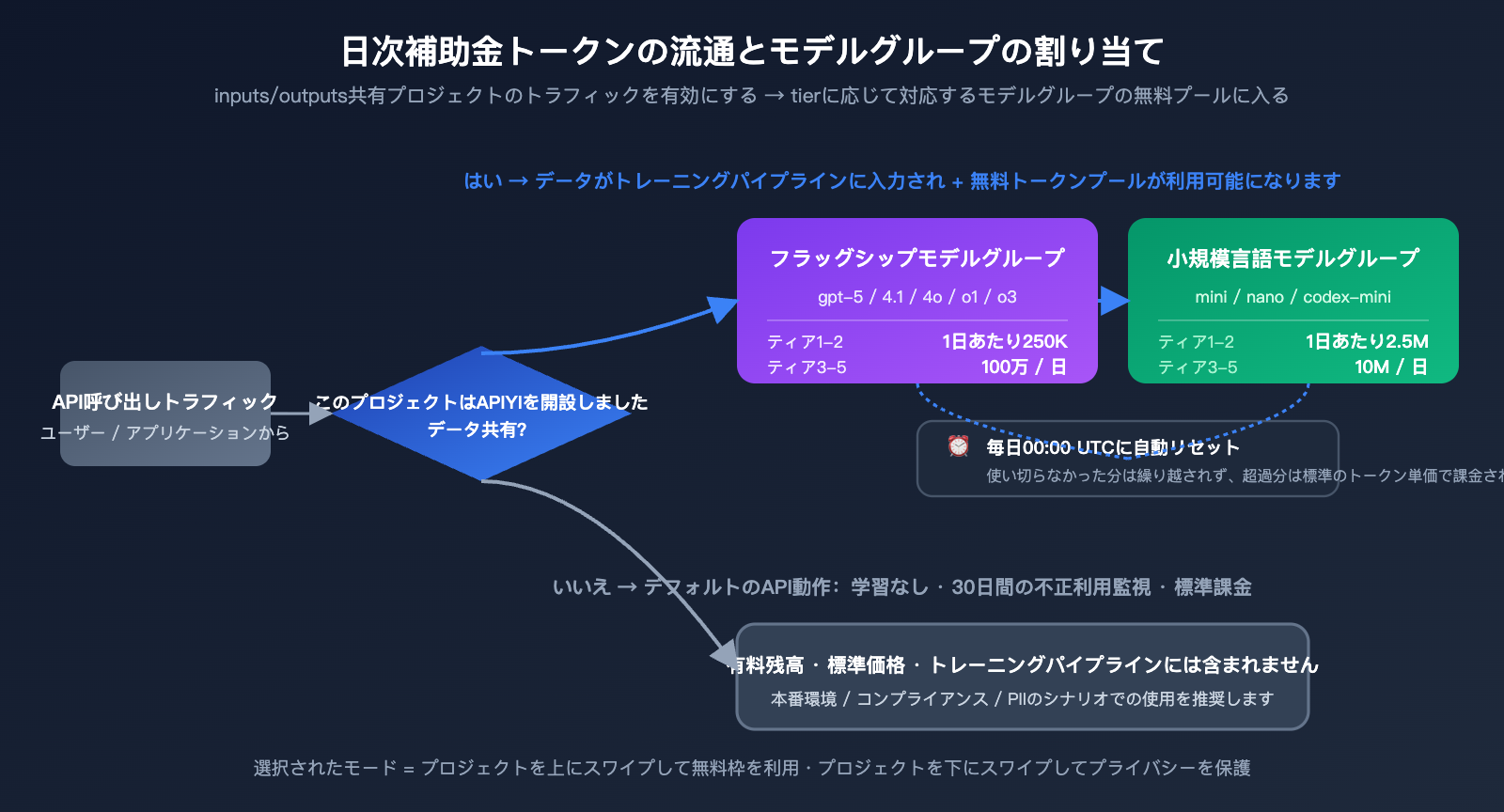
これは 2 つのスイッチの中で「代償は大きいが、見返りも大きい」ものです。これを有効にすると、そのプロジェクトを経由するすべての API 呼び出しにおいて、入力プロンプトと出力回答が OpenAI に収集され、モデルのトレーニングや改善に使用されます。これはデフォルトの API 動作とは本質的に異なります。通常、OpenAI は 2023 年 3 月以降、API データを使用してモデルをトレーニングしないことを明言していますが、このスイッチをオンにすることは、その保護を自ら解除することと同義です。
見返りとして、アカウントのティアとモデルグループに応じた「無料のデイリートークン(complimentary daily tokens)」が付与されます。これは OpenAI が公開しているデータの中で最も具体的な無料枠のプランであり、毎日 00:00 UTC に自動リセットされます。
| モデルグループ | Tier 1-2 日次上限 | Tier 3-5 日次上限 | リセット時間 |
|---|---|---|---|
| フラッグシップモデル群 | 250,000 トークン | 1,000,000 トークン | 00:00 UTC |
| 小型モデル群 | 2,500,000 トークン | 10,000,000 トークン | 00:00 UTC |
フラッグシップモデル群と小型モデル群は、性能による大まかな分類ではなく、OpenAI が明確にリストアップしたものです。リスト外のモデルを呼び出しても無料枠にはカウントされません。
| モデルグループ | 含まれる具体的なモデル |
|---|---|
| フラッグシップ群 | gpt-5, gpt-5-codex, gpt-5-chat-latest, gpt-4.5-preview, gpt-4.1, gpt-4o, o1, o3, o1-preview |
| 小型モデル群 | gpt-5-mini, gpt-5-nano, gpt-4.1-mini, gpt-4.1-nano, gpt-4o-mini, o1-mini, o4-mini, codex-mini-latest |
🎯 トークン枠の真の価値: gpt-4o-mini の入力 $0.15/M、出力 $0.60/M で試算すると、Tier 1-2 の 1 日あたり 2.5M トークンは、1 日あたり約 $1〜2 の無料枠となり、月間で $30〜60 の節約になります。Tier 3-5 で 1 日あたり 10M トークンに増えれば、月間で $120〜240 の節約が可能です。単にこの枠を得るためだけに組織全体のトラフィックを公開設定にするのは割に合わないため、独立したテストプロジェクトを作成し、「Selected」モードで設定することをお勧めします。
デフォルトのAPIプライバシー vs 共有有効化後の真の違い
多くのチームが「デフォルトのAPIは学習に使われるのか?」という点について誤解しています。OpenAIの実際のポリシーは以下の通りです:デフォルトのAPIは学習に使用されませんが、不正利用監視(Abuse Monitoring)のために30日間データが保持されます。 「Zero Data Retention(データ保持ゼロ)」はこれとは別物であり、企業顧客がOpenAIの営業チームに個別に申請する必要があるもので、Web画面のスイッチ一つで切り替えられるものではありません。
この前提を理解した上で、2つのスイッチが与える影響を見てみましょう。「Inputs/Outputs」を有効にすることは「2023年以降の学習保護を自ら放棄する」ことを意味し、「Eval/FT」を有効にすることは「さらに評価手法の構築に貢献する」ことを意味します。どちらのスイッチも、30日間の不正利用監視のためのデータ保持には影響せず、ZDR(データ保持ゼロ)と併用することもできません。
| 項目 | デフォルトAPI(両方オフ) | Inputs/Outputsをオン | Eval/FT Dataをオン |
|---|---|---|---|
| 学習への利用 | ❌ 利用しない | ✅ 学習に利用 | ✅ 学習+評価に利用 |
| 不正利用監視の保持 | 30日間 | 30日間 | 30日間 |
| データの撤回 | / | ❌ 共有済みは撤回不可 | ❌ 共有済みは撤回不可 |
| ZDRとの互換性 | ✅ ZDR申請可能 | ❌ スイッチと排他 | ❌ スイッチと排他 |
| 推奨シーン | 本番環境 / コンプライアンス / 個人情報 | 開発 / テスト / 公開データ | 公開ベンチマーク評価 |
🎯 プライバシーに関する意思決定のアドバイス: GDPR、HIPAA、企業秘密保持契約(NDA)、顧客の個人情報(PII)など、データプライバシーに関するコンプライアンス要件がある場合は、両方のスイッチを「Disabled(無効)」に保ち、機密性の高いトラフィックはAPIYI(apiyi.com)ゲートウェイ経由で送信するか、ZDRを申請してください。個人プロジェクトや社内ツール、ハッカソンなどの公開環境であれば、「Enabled for all projects」にしても問題ありません。
OpenAIのデータ制御を有効にすべきか判断する4つのフレームワーク
「オンにするか、オフにするか」という二元論で考えるのは早計です。4つの典型的なビジネスシーンをマトリックス化しました。意思決定の核となるのはデータの機密性(扱う内容がプライバシーや企業秘密に関わるか)と呼び出し規模(無料枠からどれだけ実質的な価値を得られるか)の2点です。
| ビジネスタイプ | データの機密性 | 推奨:Inputs/Outputs | 推奨:Eval/FT |
|---|---|---|---|
| 個人開発 / ハッカソン | 低 | Enabled for all | Enabled for all |
| 社内R&D / モデル選定 | 中 | Enabled for selected | Enabled for selected |
| To-Cアプリ(PII含む) | 高 | Disabled または Selected(開発用) | Disabled |
| 企業 / コンプライアンス | 極めて高い | Disabled + ZDR適用 | Disabled |
第一のカテゴリーは、個人開発やハッカソンです。この場合、トークン消費の主な対象は公開されているプロンプト(競技課題やデモコードなど)であるため、共有を有効にすることで日々の補助金を受け取りつつ、機密情報の漏洩リスクもありません。コストパフォーマンスが最も高い選択です。第二のカテゴリーは社内R&Dで、ここでは「Selected」モードを推奨します。共有可能な実験専用の「data-share-test」プロジェクトを別途作成し、メインの開発プロジェクトは「Disabled」にしておきましょう。
第三のカテゴリーはTo-Cアプリで、ユーザーの入力や対話履歴、個人情報が含まれることが一般的です。この場合、両方のスイッチをオフにすることを推奨します。無料枠によるメリットよりも、ユーザーの個人情報が学習パイプラインに収集された際のリスクの方がはるかに大きいためです。第四のカテゴリーは企業やコンプライアンスが重視される医療、金融、政府関連の顧客です。これらは直接ZDRを申請するか、APIYI(apiyi.com)のようなコンプライアンス対応ゲートウェイを利用し、30日間の不正利用監視さえも回避すべきです。
🎯 3段階のオプションの選び方: 何らかのスイッチを有効にする場合は、「Enabled for all projects」ではなく「Enabled for selected projects」を優先してください。これにより、「学習対象」として特定のプロジェクトを切り分け、開発やテストに利用できます。本番環境のプロジェクトは隔離された状態を保てるため、将来的な設定変更の影響も最小限に抑えられ、移行コストも極めて低く済みます。
OpenAI Data Controls よくある質問(FAQ)
Q1:Inputs/Outputs を有効にすると、OpenAI はすぐに私の過去の全データを取得しますか?
いいえ。2つのスイッチには「Only traffic sent after turning this setting on will be shared(この設定をオンにした後に送信されたトラフィックのみが共有されます)」および「Only evaluation and fine-tuning data created after turning this setting on will be shared(この設定をオンにした後に作成された評価およびファインチューニングデータのみが共有されます)」と明記されています。スイッチはオンにした後に生成されたデータにのみ適用され、過去のデータが遡って共有されることはありません。
Q2:無料トークンは Credit Grants と同じものですか?
同じではありませんが、関連しています。Inputs/Outputs の共有によって得られるのは「デイリー・トークンプール」で、UTC 00:00 に自動リセットされます。OpenAI の管理画面の Credit Grants に表示される「わずかなセント」の小額付与は、このプールが使用量に応じて米ドル価値に換算された事後記録であり、同じプロジェクトに対する2つの異なる表示方法と理解して差し支えありません。
Q3:Selected モードで1つのプロジェクトのみ共有するように設定した場合、メインプロジェクトのトラフィックは完全に安全ですか?
完全に安全です。OpenAI の設定画面では、どのプロジェクトを共有対象にするかを正確に選択できます。選択されていないプロジェクトのトラフィックは、デフォルトの API 動作(学習には使用されず、30日間の不正利用監視のみが行われる)に従います。もしこれでも不安な場合は、メインプロジェクトのトラフィックを APIYI(apiyi.com)のようなゲートウェイに切り替えることで、アーキテクチャレベルで完全に隔離できます。
Q4:Eval/FT 共有の「7 free weekly evals」は具体的にどうカウントされますか?
トークン数ではなく「実行回数」でカウントされます。Eval を1回実行するごとに(処理するサンプル数に関わらず)1回とカウントされ、週に最大7回まで無料です。これを超えると、Eval で使用されたモデルの標準トークン単価で課金されます。一部のモデルは無料対象外のため、実行するとその都度課金されます。
Q5:Inputs/Outputs をオフにした後、すでに収集されたデータを取り戻すことはできますか?
できません。OpenAI のポリシーでは、一度共有されたデータは取り消し不可と明記されています。スイッチをオフにすることは、将来のデータが学習パイプラインに入るのを防ぐことしかできません。これが、私たちが本番環境のトラフィックに対して APIYI(apiyi.com)のようなゲートウェイを使用して「ハード隔離」を行うことを推奨している理由です。デフォルトで OpenAI の学習パイプラインに入らないようにする方が、「後からオフにする」よりも確実です。
OpenAI Data Controls に関する3つのまとめ
第一に、この2つのスイッチは真の「双方向取引」であるということです。実用的かつ定量化可能なデータ(Eval メソドロジー、API の入出力)を、定量化可能な無料枠(週7回の Eval、毎日数百万から数千万トークン)と交換しています。これを単なるプレゼントではなく「取引」であると理解することで、判断を誤ることがなくなります。
第二に、デフォルトの API は学習には使用されませんが、30日間の不正利用監視は継続されます。ビジネス上でプライバシーに関するコンプライアンス要件がある場合は、両方のスイッチを「Disabled(無効)」にし、ZDR(Zero Data Retention)の申請を行うか、APIYI(apiyi.com)のようなコンプライアンス対応ゲートウェイを通じて制限を強化すべきです。スイッチは「追加で学習を許可するかどうか」を決めるものであり、「監視されるかどうか」を決めるものではありません。
第三に、Selected モードを使用して「プロジェクトごとの隔離」を優先することです。共有可能な開発環境やテスト用トラフィック専用の独立したプロジェクトを新規作成し、本番環境や機密データとは完全に切り離します。これにより、無料枠を享受しつつ、ユーザーデータが学習パイプラインに流れるのを防ぐことができ、最もコストパフォーマンスの高い運用が可能になります。
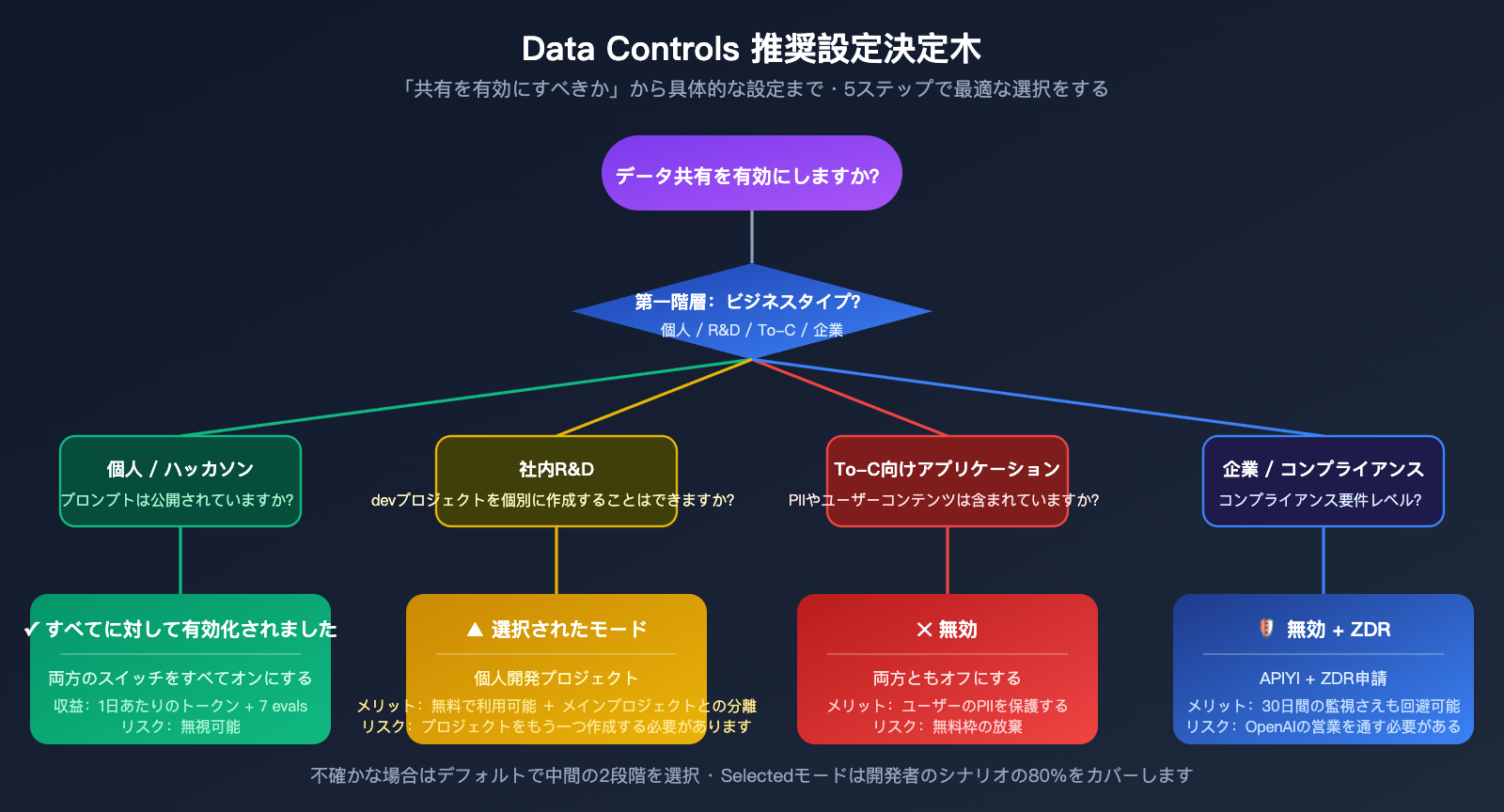
これらのスイッチを検討する際は、「個人 / 内部 / To-C / 企業」の4つのカテゴリーに当てはめて設定を決定し、Selected モードを使用して独立したテスト用プロジェクトを作成して無料枠を活用するのが最も安全です。メインの本番トラフィックは APIYI(apiyi.com)ゲートウェイ経由でアーキテクチャ的に隔離することで、OpenAI の無料政策を享受しつつ、ユーザーデータやビジネスノウハウのプライバシー境界をしっかりと守ることができます。
📌 著者:APIYI 技術チーム — OpenAI Data Controls、ZDR、課金戦略などの重要なポリシー変更を継続的に追跡し、開発者に統一された課金とプライバシー管理が可能なマルチモデル API ゲートウェイ体験を提供します。詳細は APIYI(apiyi.com)をご覧ください。