Claude Opus 4.7 mencetak rekor baru untuk model pemrograman pada April 2026 dengan skor SWE-bench Verified mencapai 87,6%. Namun, dua minggu berselang, xAI menantang konsensus bahwa "model pemrograman harus mahal" dengan merilis Grok 4.3 yang harganya hanya 1/10 dari Claude. Artikel ini menjawab dua pertanyaan krusial bagi para pengembang: Bisakah Grok 4.3 menggantikan Claude Opus 4.7 dalam tugas pemrograman? dan Jika tidak bisa sepenuhnya menggantikan, apa keunggulan diferensiasi Grok 4.3 yang layak kita manfaatkan?
Nilai Inti: Setelah membaca artikel ini, Anda akan memahami kapan harus memilih Grok 4.3, Claude Opus 4.7, atau menggunakan keduanya secara kombinasi untuk skenario pemrograman Anda, serta bagaimana menekan biaya operasional hingga lebih dari 60% melalui layanan proksi API APIYI.

Perbedaan Inti Grok 4.3 vs Claude Opus 4.7
Untuk menentukan apakah model ini bisa menjadi "pengganti", mari kita sejajarkan semua parameter utama terkait pemrograman dari kedua model tersebut.
Ringkasan Parameter Grok 4.3 vs Claude Opus 4.7
| Dimensi Perbandingan | Grok 4.3 | Claude Opus 4.7 | Pemenang |
|---|---|---|---|
| Tanggal Rilis | 30-04-2026 | 16-04-2026 | Claude (lebih awal 14 hari) |
| Harga Input | $1,25 / 1J | $5,00 / 1J | Grok 4.3 |
| Harga Output | $2,50 / 1J | $25,00 / 1J | Grok 4.3 |
| Jendela Konteks | 1J token | 1J token | Seri |
| Output Maksimum | Standar | 128K token | Claude |
| Kecepatan Output | 207 token/detik | ~78 token/detik | Grok 4.3 |
| Mode penalaran | Aktif default | xhigh / adaptif | Claude (lebih detail) |
| SWE-bench Verified | ~73% | 87,6% | Claude (+14,6pt) |
| SWE-bench Pro | Tidak diumumkan | 64,3% | Claude |
| CursorBench | Tidak diumumkan | 70% | Claude |
| Vending-Bench (Agen) | Terbaik | Menengah | Grok 4.3 |
| Diskon Prompt Caching | 75% | 90% | Claude |
| Diskon Batch API | 50% | 50% | Seri |
| Input Video | ✅ Native | ❌ Tidak didukung | Grok 4.3 |
| Dokumen PDF/XLSX/PPTX | ✅ Native | ❌ Perlu post-processing | Grok 4.3 |
| Alat Server | ✅ Built-in web/code | ❌ Perlu bangun sendiri | Grok 4.3 |
Kesimpulan Singkat
Jika diringkas dalam satu kalimat: Claude Opus 4.7 tetap menjadi standar tertinggi untuk "tugas pemrograman yang sensitif terhadap presisi", sementara Grok 4.3 adalah pilihan terbaik untuk skenario pengembangan yang "sensitif terhadap biaya, rantai panjang, dan multimodal". Keduanya bukanlah hubungan substitusi, melainkan pembagian kerja antara "presisi vs efisiensi biaya".
🎯 Saran Uji Coba Cepat: Kedua model telah tersedia di APIYI (apiyi.com), dengan
base_urlterpadu dihttps://vip.apiyi.com/v1. Harga Grok 4.3 sama persis dengan situs resmi xAI ($1,25/$2,50), dan Claude Opus 4.7 mengikuti harga resmi Anthropic ($5,00/$25,00) tanpa markup tambahan. Anda dapat langsung memanggilnya menggunakan SDK OpenAI.

Perbandingan Harga Grok 4.3 vs Claude Opus 4.7
Harga adalah dimensi dengan perbedaan paling mencolok dalam perbandingan ini. Mari kita bedah dari tiga sisi: harga satuan, biaya tersembunyi tokenizer, dan estimasi biaya bulanan untuk proyek tipikal.
Harga Standar Grok 4.3 vs Claude Opus 4.7
Tabel di bawah ini menunjukkan harga resmi yang berlaku per Mei 2026. Keduanya tersedia di saluran layanan proksi API APIYI dengan skema harga yang transparan sesuai harga resmi.
| Item Penagihan | Grok 4.3 | Claude Opus 4.7 | Kelipatan Harga |
|---|---|---|---|
| Input tokens | $1,25 / 1J | $5,00 / 1J | Claude 4,0x lebih mahal |
| Output tokens | $2,50 / 1J | $25,00 / 1J | Claude 10,0x lebih mahal |
| Cache input | $0,31 / 1J | $0,50 / 1J | Claude 1,6x lebih mahal |
| Harga campuran 3:1 | ~$1,56 / 1J | ~$10,00 / 1J | Claude 6,4x lebih mahal |
Biaya Tersembunyi Tokenizer Claude Opus 4.7
Claude Opus 4.7 menggunakan tokenizer baru saat dirilis. Berdasarkan pengujian industri, input kode yang sama menghasilkan sekitar 35% lebih banyak tokens dibandingkan Opus 4.6. Artinya, meskipun harga satuan resmi tidak berubah, tagihan permintaan aktual Anda tetap akan naik.
| Jenis Konten | Tokens Opus 4.6 | Tokens Opus 4.7 | Perubahan Biaya Aktual |
|---|---|---|---|
| Kode murni bahasa Inggris | 100k | 130k+ | +30% |
| Kode campuran Mandarin | 100k | 135k+ | +35% |
| Mengandung banyak emoji / komentar | 100k | 140k+ | +40% |
Jika faktor ini dimasukkan ke dalam perbandingan harga, biaya tugas pemrograman aktual untuk Claude Opus 4.7 dibandingkan Grok 4.3 akan mencapai 8–10 kali lipat, bukan 6,4 kali lipat seperti pada tabel harga satuan.
💡 Saran Optimasi Biaya: Kami menyarankan untuk mengaktifkan prompt caching (dapat menghemat 90%) saat melakukan pemanggilan prompt panjang pada Claude Opus 4.7. Ini adalah cara kunci untuk mengimbangi kenaikan harga tokenizer. Saluran layanan proksi API APIYI (apiyi.com) mendukung penuh field caching asli Anthropic, tanpa perlu pekerjaan integrasi tambahan.
Estimasi Biaya Bulanan Proyek Pemrograman Nyata
Berikut adalah estimasi bulanan untuk bisnis "asisten kode tim menengah", dengan asumsi rasio input-output 4:1 (input lebih panjang pada skenario pemrograman), tanpa memperhitungkan diskon caching.
| Skala Bisnis | Volume token bulanan | Biaya bulanan Grok 4.3 | Biaya bulanan Claude Opus 4.7 | Selisih |
|---|---|---|---|---|
| Pengembang individu | 50M | ~$70 | ~$700 (termasuk kenaikan 35% token menjadi ~$945) | 13,5x |
| Tim menengah | 1.000M | ~$1.400 | ~$14.000 (aktual ~$19.000) | 13,5x |
| Perusahaan besar | 10.000M | ~$14.000 | ~$140.000 (aktual ~$189.000) | 13,5x |
Perbedaan harga pada skala perusahaan akan membengkak menjadi anggaran jutaan dolar per tahun. Inilah alasan mengapa arsitektur campuran menjadi solusi utama untuk AI pemrograman di tahun 2026.
🎯 Saran Anggaran: Jika anggaran AI pemrograman bulanan Anda < $1500, disarankan untuk menggunakan Grok 4.3 secara penuh, dan hanya beralih ke Claude Opus 4.7 pada saat-saat krusial. Strategi ini memiliki biaya rekayasa yang mendekati nol di APIYI (apiyi.com), Anda hanya perlu mengganti field model di lapisan aplikasi berdasarkan label tugas.
Perbandingan Kemampuan Pemrograman Grok 4.3 vs Claude Opus 4.7
Selain harga, kemampuan pemrograman adalah penentu utama apakah sebuah model bisa menjadi pengganti yang layak. Kami melihatnya dari tiga perspektif: benchmark publik, skenario rekayasa nyata, dan tugas rantai panjang.
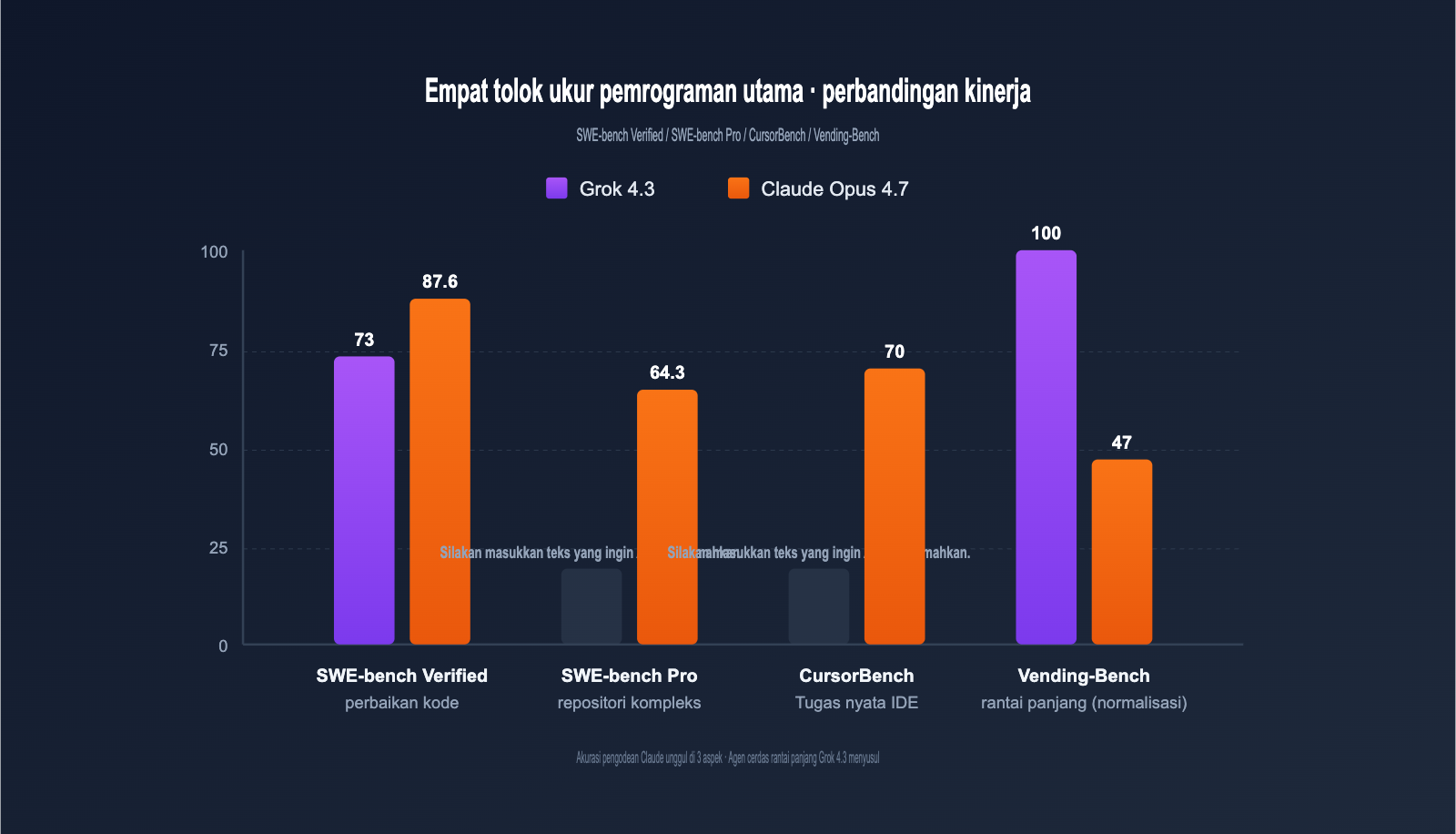
Perbandingan Benchmark Pemrograman
Tabel di bawah merangkum data pemrograman kunci yang diumumkan secara resmi oleh OpenAI, xAI, Anthropic, dan pengujian pihak ketiga (Vellum, Vals.ai, Artificial Analysis).
| Benchmark Pemrograman | Grok 4.3 | Claude Opus 4.7 | Selisih | Jenis Tugas |
|---|---|---|---|---|
| SWE-bench Verified | ~73% | 87,6% | Claude +14,6pt | Perbaikan kode nyata |
| SWE-bench Pro | Tidak diumumkan | 64,3% | Claude unggul | Bug repositori kompleks |
| CursorBench | Tidak diumumkan | 70% | Claude unggul | Tugas IDE nyata |
| Aider Polyglot | Sedang | Kuat | Claude unggul | Migrasi kode multi-bahasa |
| HumanEval+ | Sangat baik | Sangat baik | Setara | Pembuatan tingkat fungsi |
| Tugas produksi nyata | Baik | 3x Opus 4.6 | Claude unggul | Perbaikan kode warisan |
| Vending-Bench (Net) | Teratas | 47,1 | Grok 4.3 unggul | Agen rantai panjang |
| Kecepatan output (tps) | 207 | ~78 | Grok 4.3 +166% | Respons real-time |
Singkatnya: Claude Opus 4.7 unggul dalam "tugas pemrograman yang sensitif terhadap presisi", sementara Grok 4.3 mengungguli Claude dalam "tugas agen rantai panjang" dan 2,6 kali lebih cepat dalam "kecepatan respons real-time".
Penilaian Granularitas Tugas Pemrograman
Dengan mengubah benchmark menjadi penilaian bintang untuk tugas bisnis, kita bisa melihat distribusi kemampuan dengan lebih intuitif.
| Tugas Pemrograman | Grok 4.3 | Claude Opus 4.7 | Bisa diganti? |
|---|---|---|---|
| Pembuatan kode tingkat fungsi | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Bisa diganti |
| Pembuatan unit test | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Bisa diganti |
| Komentar / Dokumentasi kode | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Bisa diganti |
| Perbaikan bug sederhana | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Bisa diganti |
| Refaktor gaya kode | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Bisa diganti |
| Refaktor lintas file | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⚠️ Tidak disarankan |
| Perbaikan bug repositori kompleks | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⚠️ Tidak disarankan |
| Desain sistem skala besar | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ❌ Claude unggul |
| Kode kepatuhan hukum / medis | ⭐⭐ | ⭐⭐⭐⭐⭐ | ❌ Wajib Claude |
| Tugas agen rantai panjang | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ✅ Grok 4.3 unggul |
🎯 Catatan Penggantian: Untuk empat kategori tugas ("tingkat fungsi + unit test + komentar + bug sederhana"), Grok 4.3 dapat sepenuhnya menggantikan Claude Opus 4.7 dengan biaya hanya 1/10. Untuk tiga kategori tugas ("lintas file + refaktor kompleks + bug kritis"), disarankan tetap menggunakan Claude Opus 4.7. Arsitektur campuran adalah solusi terbaik.
Pengujian Tugas Pemrograman Nyata
Untuk membuat perbandingan lebih konkret, kami merancang 5 tugas pemrograman umum dan menjalankannya pada kedua model di bawah base_url yang sama di APIYI.
| Tugas Uji | Performa Grok 4.3 | Performa Claude Opus 4.7 | Kesimpulan |
|---|---|---|---|
| Menulis komponen React | 8 detik, 1x lolos | 18 detik, 1x lolos | ✅ Bisa diganti (Grok 2x lebih cepat) |
| Memperbaiki bug NullPointer | 6 detik, lokasi tepat | 14 detik, lokasi tepat + 3 solusi | ⚠️ Penggantian parsial |
| Refaktor dependensi siklik 5 file | 25 detik, 2x coba | 40 detik, 1x lolos | ❌ Gunakan Claude |
| Membuat unit test Python | 12 detik, cakupan 82% | 22 detik, cakupan 95% | ✅ Bisa diganti |
| Agen rantai panjang (10 langkah) | 50 detik, eksekusi penuh | 90 detik, macet sebagian | ✅ Grok 4.3 unggul |
Terlihat bahwa untuk tugas sederhana, Grok 4.3 tidak hanya lebih cepat, tetapi kualitasnya mendekati Claude. Namun, untuk tugas lintas file yang kompleks, Claude tetap pemenangnya.
Alasan Teknis Keunggulan Pemrograman Claude Opus 4.7
Penting untuk memahami mengapa Claude Opus 4.7 unggul 14 poin persentase pada SWE-bench.
| Dimensi Teknis | Investasi Claude Opus 4.7 | Dampak pada Pemrograman |
|---|---|---|
| Mode xhigh reasoning | Alokasi reasoning tokens lebih banyak untuk masalah sulit | Kualitas penalaran logika lebih stabil |
| Thinking adaptif | Menilai otomatis kebutuhan kedalaman berpikir | Tidak membuang tokens pada tugas sederhana |
| 1M konteks + 128K output | Generasi sebelumnya hanya 200K | Output seluruh file atau proyek kecil |
| Tokenizer baru | Pemotongan kode lebih granular | Pemahaman kode lebih akurat |
| Data pelatihan produksi nyata | Menyelesaikan 3x lebih banyak tugas produksi | Kemampuan "kode nyata" lebih kuat |
Keunggulan Claude Opus 4.7 bersifat struktural pada tugas yang membutuhkan "penalaran presisi rantai panjang + konteks besar + output tinggi". Namun, keunggulan ini hampir tidak berpengaruh pada tugas singkat atau unit test, yang menjadi celah bagi Grok 4.3 untuk menjadi pengganti yang efisien.
Analisis Mendalam Keunggulan Diferensiasi Grok 4.3
Jika hanya melihat SWE-bench, Grok 4.3 mungkin terlihat kalah di segala aspek dibandingkan Claude Opus 4.7. Namun, dalam skenario pengembangan nyata, Grok 4.3 memiliki beberapa kemampuan yang tidak dimiliki Claude sama sekali, dan inilah yang menjadi parit pertahanan (moat) diferensiasinya yang sesungguhnya.
Keunggulan Harga dan Kecepatan Grok 4.3
Pertama, harganya 10 kali lebih murah. Untuk sebagian besar tugas pengodean harian, perbedaan akurasinya berada di level "90% vs 95%", tetapi perbedaan biayanya berada di level "$1 vs $10". Dengan menyerahkan tugas-tugas sederhana yang berfrekuensi tinggi kepada Grok 4.3, anggaran alat AI tim Anda bisa menjadi 10 kali lebih efektif.
Kedua, kecepatan output-nya 2,6 kali lebih cepat. Perbedaan 207 tps vs 78 tps memberikan pengalaman yang sangat berbeda pada skenario sensitif latensi seperti "penyelesaian kode dengan streaming", "saran inline IDE", dan "Pair Programming real-time". Kecepatan 78 tps milik Claude Opus 4.7 mungkin "bisa mengikuti kecepatan berpikir manusia", namun 207 tps milik Grok 4.3 sudah "2 kali lebih cepat dari otak manusia".
Kemampuan Input Video Grok 4.3
Ini adalah kemampuan yang sama sekali tidak dimiliki Claude Opus 4.7. Grok 4.3 mendukung input video secara native, dengan skenario aplikasi tipikal sebagai berikut:
| Skenario | Penggunaan Grok 4.3 | Alternatif Claude Opus 4.7 |
|---|---|---|
| Rekaman layar jadi kode | Langsung unggah file video | Perlu OCR + banyak tangkapan layar |
| Video reproduksi Bug → Solusi perbaikan | Satu permintaan | Perlu memecah frame dan deskripsi manual |
| Video tutorial → Tutorial kode | Ekstraksi frame langsung | Tidak memungkinkan |
| Animasi desain UI → Kode frontend | Input video | Tidak memungkinkan |
Jika di tim Anda ada QA yang mengirimkan video reproduksi bug, desainer yang mengirimkan animasi UI, atau Anda perlu melakukan reverse engineering kode dari tutorial YouTube, Grok 4.3 adalah satu-satunya solusi hemat biaya yang layak saat ini.
Kemampuan Pembuatan Dokumen Grok 4.3
Grok 4.3 dapat membuat file PDF/XLSX/PPTX langsung di dalam percakapan, yang dalam skenario pengodean berarti:
# Grok 4.3 membuat dokumen PDF antarmuka dengan satu baris panggilan
from openai import OpenAI
client = OpenAI(
api_key="Kunci API APIYI Anda",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="grok-4.3",
messages=[{
"role": "user",
"content": "Buatkan dokumen PDF gaya OpenAPI untuk rute FastAPI ini: ..."
}],
extra_body={"output_format": "pdf"}
)
# Respons berisi URL file yang dapat diunduh
print(response.choices[0].message.attachments[0].url)
Untuk melakukan hal yang sama, Claude Opus 4.7 memerlukan alur tiga langkah: Claude → Markdown → Pandoc → PDF. Grok 4.3 menyelesaikannya dalam satu langkah.
Keunggulan Agen Rantai Panjang Grok 4.3
Vending-Bench adalah tolok ukur agen rantai panjang yang mensimulasikan "pengoperasian mesin penjual otomatis selama 7 hari". Keuntungan bersih Grok 4.3 jauh memimpin Claude Opus 4.7. Ini berarti pada tugas-tugas Agentic yang "memerlukan pengambilan keputusan berkelanjutan, pemanggilan alat, dan mengingat status perantara", Grok 4.3 justru lebih kuat.
| Skenario Rantai Panjang | Keunggulan Grok 4.3 |
|---|---|
| Operasi otomatis (pemulihan mandiri dari kegagalan) | Keputusan rantai panjang yang stabil, cocok untuk Agen SRE |
| Jalur pipa analisis data | Pemanggilan alat multi-langkah + agregasi hasil |
| Review + merge PR otomatis | Dapat menyelesaikan alur panjang secara mandiri |
| Pemindaian kepatuhan + perbaikan otomatis | Pemrosesan batch repositori skala besar |
Penerapan Mode 16-Agent Heavy Grok 4.3 dalam Pengodean
Grok 4.3 menyediakan sistem penjadwalan paralel 16-Agent di bawah langganan SuperGrok Heavy ($300/bulan), yang dalam skenario pengodean berarti:
| Tugas Pengodean | Mode Agen Tunggal | Mode 16-Agent Heavy |
|---|---|---|
| Analisis repositori besar | Serial 30 menit | Paralel 3–5 menit |
| Review PR penuh | Dilihat satu per satu | 16 PR diproses bersamaan |
| Pembuatan unit test batch | Panggilan serial | 16 file dibuat paralel |
| Migrasi kode multi-bahasa | Single-thread | Paralel multi-modul |
Meskipun mode 16-Agent terkunci dalam paket langganan dan API standar tidak langsung mengekspos pintu masuk 16-agent, Anda dapat mengimplementasikan orkestrasi multi-agen sendiri di lapisan aplikasi menggunakan Grok 4.3, dengan hasil yang mendekati performa Heavy native. Dikombinasikan dengan kecepatan output 207 tps Grok 4.3, dalam skenario otomatisasi pengodean skala besar, kapasitas throughput Grok 4.3 justru lebih tinggi daripada Claude Opus 4.7.
Keunggulan Alat Sisi Server Grok 4.3
Grok 4.3 memiliki tiga jenis alat sisi server bawaan, cukup deklarasikan kolom tools untuk menggunakannya, sementara Claude Opus 4.7 memerlukan pembangunan mandiri di lapisan aplikasi.
| Alat Bawaan | Harga Grok 4.3 | Alternatif Claude Opus 4.7 |
|---|---|---|
| Web Search | $5 / 1k kali | Perlu integrasi Tavily / SerpAPI |
| Code Execution (Sandbox) | $5 / 1k kali | Perlu membangun Docker sandbox sendiri |
| X (Twitter) Search | $5 / 1k kali | Tidak ada alternatif |
Bagi agen pengodean yang memerlukan pencarian internet + eksekusi kode, Grok 4.3 selesai dalam satu integrasi, sedangkan Claude Opus 4.7 memerlukan tiga layanan pihak ketiga, yang berarti perbedaan kompleksitas rekayasa yang sangat besar.
💡 Saran alat sisi server: Kami menyarankan agen pengodean dengan pencarian web untuk langsung memilih Grok 4.3 karena biaya integrasi paling rendah. Jika proyek sudah menggunakan Claude Opus 4.7 + pencarian pihak ketiga, Anda bisa tetap menggunakan Claude untuk tugas sulit, dan mengakses Grok 4.3 melalui APIYI apiyi.com untuk tugas yang memerlukan pencarian web.
Matriks Keputusan: Bisakah Grok 4.3 Menggantikan Claude Opus 4.7?
Berikut adalah ringkasan semua dimensi ke dalam matriks keputusan yang dapat dieksekusi.
Keputusan Berdasarkan Jenis Tugas
| Tugas Pengodean Inti Anda | Solusi Rekomendasi | Alasan |
|---|---|---|
| Penyelesaian kode IDE / saran inline | Grok 4.3 | Kecepatan 2,6x lebih cepat + harga 1/10 |
| Pembuatan unit test otomatis | Grok 4.3 | Cakupan 80%+ sudah cukup |
| Komentar kode / pembuatan dokumen | Grok 4.3 | Tugas sederhana, kualitas setara |
| Code Review (tingkat PR) | Grok 4.3 | Harga murah, bisa diproses penuh |
| Perbaikan bug sederhana | Grok 4.3 | Perbedaan akurasi kecil |
| Refactor skala besar | Claude Opus 4.7 | SWE-bench Pro 64,3% adalah batas atas |
| Perbaikan bug fitur kritis | Claude Opus 4.7 | Biaya pengerjaan ulang jika salah > selisih harga |
| Lintas file / repositori besar | Claude Opus 4.7 | Akurasi konteks panjang lebih stabil |
| Kode kepatuhan hukum / medis | Claude Opus 4.7 | Persyaratan keamanan / kepatuhan tinggi |
| Agen operasi otomatis | Grok 4.3 | Vending-Bench rantai panjang lebih unggul |
| Pengembangan berbasis video | Grok 4.3 | Tidak ada alternatif di Claude |
| Pencarian web + eksekusi sandbox | Grok 4.3 | Alat sisi server bawaan |
Keputusan Berdasarkan Anggaran Tim
| Anggaran AI Pengodean Bulanan | Konfigurasi Rekomendasi | Penyesuaian Kunci |
|---|---|---|
| < $200 | Grok 4.3 penuh | Gunakan Claude hanya untuk bug kritis |
| $200 – $1500 | 80% Grok 4.3 + 20% Claude | Refactor lintas file gunakan Claude |
| $1500 – $10k | 50% Grok 4.3 + 30% Claude + 20% Grok 4 Fast | Pembagian tiga tingkat |
| > $10k | Routing otomatis + Batch + Cache | Wajib menggunakan arsitektur hibrida |
Keputusan Berdasarkan Toleransi Akurasi
| Toleransi Akurasi Tugas | Pilihan Rekomendasi |
|---|---|
| Akurasi 90% dapat diterima | Grok 4.3 (cakupan 90% tugas) |
| Akurasi 95% harus terjamin | Claude Opus 4.7 + Prompt Caching |
| Akurasi 99% wajib | Claude Opus 4.7 + mode xhigh + review manual |
🎯 Saran arsitektur hibrida: Di platform APIYI apiyi.com, Grok 4.3 dan Claude Opus 4.7 berbagi
base_urldan kunci API yang sama. Lapisan aplikasi hanya perlu mengganti kolommodelberdasarkan label tugas atau panjang token. Biaya rekayasa untuk arsitektur hibrida ini mendekati nol, sementara penghematan anggaran bisa mencapai 60–80%.
Integrasi dan Contoh Kode Grok 4.3 dengan Claude Opus 4.7
Kedua model ini sepenuhnya kompatibel dengan OpenAI SDK melalui layanan proksi API APIYI, sehingga biaya migrasinya hampir nol.
Pemanggilan Terpadu Grok 4.3 dan Claude Opus 4.7
# Gunakan base_url + kunci API yang sama, cukup ubah kolom model untuk memanggil kedua model
from openai import OpenAI
client = OpenAI(
api_key="Kunci API APIYI Anda",
base_url="https://vip.apiyi.com/v1"
)
# Memanggil Grok 4.3 (Hemat biaya)
grok_resp = client.chat.completions.create(
model="grok-4.3",
messages=[{"role": "user", "content": "Buat unit test untuk fungsi ini"}]
)
# Memanggil Claude Opus 4.7 (Akurasi tinggi)
claude_resp = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Refaktor dependensi melingkar pada 5 file ini"}]
)
print("Grok 4.3:", grok_resp.choices[0].message.content)
print("Claude Opus 4.7:", claude_resp.choices[0].message.content)
Kode Lengkap untuk Perutean Cerdas Skenario Coding
Lihat kode Python lengkap untuk perutean otomatis berdasarkan jenis tugas
from openai import OpenAI
from typing import Literal
import re
client = OpenAI(
api_key="Kunci API APIYI Anda",
base_url="https://vip.apiyi.com/v1"
)
# Aturan klasifikasi tugas coding
SIMPLE_KEYWORDS = ["注释", "comment", "docstring", "rename", "format"]
TEST_KEYWORDS = ["单测", "unit test", "测试用例", "pytest"]
COMPLEX_KEYWORDS = ["refactor", "重构", "跨文件", "循环依赖", "迁移"]
CRITICAL_KEYWORDS = ["关键 bug", "critical", "production fix", "合规"]
TaskType = Literal["simple", "test", "complex", "critical"]
def classify_task(prompt: str) -> TaskType:
"""Klasifikasikan tugas berdasarkan kata kunci dalam petunjuk"""
p = prompt.lower()
if any(k.lower() in p for k in CRITICAL_KEYWORDS):
return "critical"
if any(k.lower() in p for k in COMPLEX_KEYWORDS):
return "complex"
if any(k.lower() in p for k in TEST_KEYWORDS):
return "test"
return "simple"
def route_model(task_type: TaskType, prompt_tokens: int) -> str:
"""Pilih model berdasarkan jenis tugas"""
if task_type in ("critical", "complex") or prompt_tokens > 50000:
return "claude-opus-4-7"
return "grok-4.3"
def smart_code_call(prompt: str) -> dict:
"""Pemanggilan perutean cerdas untuk skenario coding"""
task_type = classify_task(prompt)
prompt_tokens = len(prompt) // 3 # Estimasi sederhana
model = route_model(task_type, prompt_tokens)
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "Anda adalah insinyur full-stack senior"},
{"role": "user", "content": prompt}
],
max_tokens=4096
)
return {
"model": model,
"task_type": task_type,
"content": response.choices[0].message.content,
"tokens": response.usage.total_tokens
}
if __name__ == "__main__":
print(smart_code_call("Tambahkan docstring untuk fungsi add ini"))
print(smart_code_call("Bantu saya menulis 5 unit test pytest"))
print(smart_code_call("Refaktor dependensi melingkar dari tiga file ini"))
print(smart_code_call("Bug kritis di lingkungan produksi, segera perbaiki"))
Hal yang Perlu Diperhatikan saat Memanggil Grok 4.3 dan Claude Opus 4.7
| Catatan | Grok 4.3 | Claude Opus 4.7 |
|---|---|---|
| Kolom Model | grok-4.3 |
claude-opus-4-7 |
| Konfigurasi reasoning | Aktif secara default | extra_body={"thinking": {"type": "enabled"}} |
| Prompt Caching | Otomatis (diskon 75%) | Deklarasi eksplisit cache_control (diskon 90%) |
| Batch API | Diskon 50% | Diskon 50% |
| Output Maksimum | Standar | 128K (perlu deklarasi max_tokens eksplisit) |
| Input Video | Kolom video_url |
❌ Tidak didukung |
| Output Dokumen | extra_body={"output_format": ...} |
❌ Perlu pasca-pemrosesan |
| Pencarian Web Server | tools=[{"type": "web_search"}] |
❌ Perlu pihak ketiga |
| Function Calling | ✅ Lengkap | ✅ Lengkap |
🎯 Saran Integrasi: Kami menyarankan Anda untuk mengajukan kunci uji coba di APIYI apiyi.com terlebih dahulu untuk menjalankan siklus minimum. Grok 4.3 dan Claude Opus 4.7 berbagi kunci API yang sama. Jalankan masing-masing 100 sampel bisnis nyata untuk pengujian A/B sebelum mengambil keputusan pemilihan model akhir.
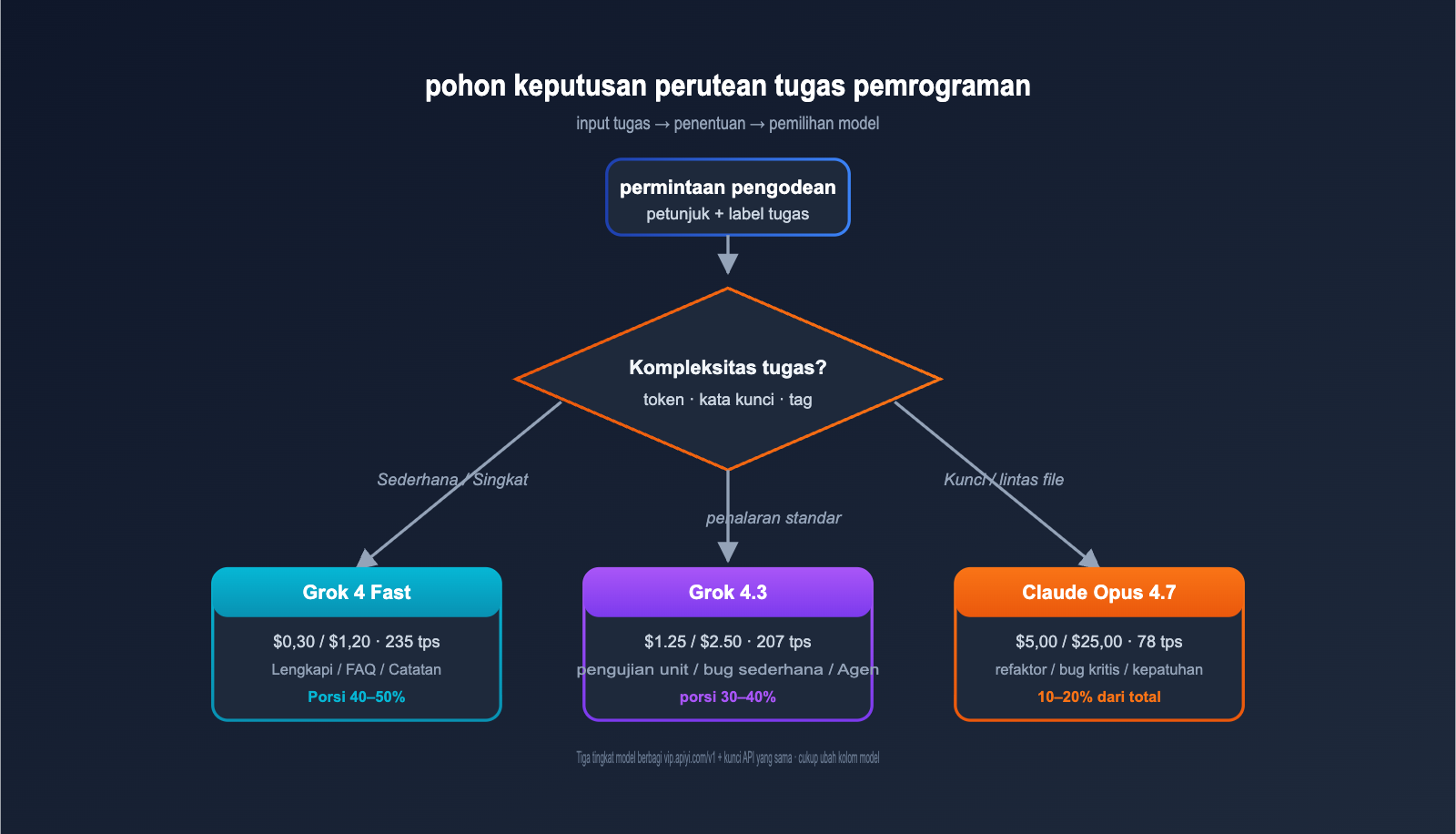
Rekomendasi Skenario Pemrograman: Grok 4.3 vs Claude Opus 4.7
6 Skenario untuk Menjadikan Grok 4.3 sebagai Andalan
Jika bisnis Anda memenuhi salah satu kriteria berikut, Grok 4.3 adalah solusi yang lebih optimal.
- Skenario 1: Pengembang Individu / Proyek Independen: Anggaran bulanan < $300, Grok 4.3 membuat token Anda bertahan 10 kali lebih lama.
- Skenario 2: Pengodean Sederhana Frekuensi Tinggi: Pelengkapan kode di IDE, pembuatan unit test, penulisan komentar, dan pemformatan kode.
- Skenario 3: Agen dengan Rantai Panjang: Operasi otomatis (Ops), Agen peninjau PR, dan robot pemindai kepatuhan.
- Skenario 4: Pengembangan Berbasis Video: Video reproduksi bug → solusi perbaikan, animasi UI → kode frontend.
- Skenario 5: Agen Pengodean + Pencarian Web: Alat
web_search+code_executionsisi server sudah terintegrasi. - Skenario 6: Skenario Percakapan Real-time: Output 207 tps, cocok untuk Pair Programming dan pelengkapan kode secara streaming.
6 Skenario untuk Menjadikan Claude Opus 4.7 sebagai Andalan
Jika bisnis Anda memenuhi salah satu kriteria berikut, premi akurasi Claude Opus 4.7 sangat layak dibayar.
- Skenario 1: Refactor Kode Skala Besar: SWE-bench Pro 64,3%, tertinggi di industri.
- Skenario 2: Perbaikan Bug Kritis: Jika satu kesalahan saja mengharuskan pengerjaan ulang, akurasi jauh lebih penting daripada biaya.
- Skenario 3: Analisis Lintas File / Repositori Besar: Kebutuhan ganda akan jendela konteks panjang + akurasi tinggi.
- Skenario 4: Kode Sensitif Kepatuhan / Keamanan: Skenario hukum, medis, dan keuangan.
- Skenario 5: Desain Sistem Kompleks: Penalaran arsitektur, desain API.
- Skenario 6: Alur Kerja Claude Code yang Sudah Ada: Tim sudah terbiasa dengan CLI Claude Code, biaya migrasi > selisih harga.
Rekomendasi Rasio Arsitektur Hibrida
Untuk tim pengembang skala menengah ke atas, kami merekomendasikan rasio hibrida berikut.
| Jenis Tugas | Model Perutean | Saran Proporsi |
|---|---|---|
| Pelengkapan sederhana / FAQ | Grok 4 Fast | 40–50% |
| Pengodean standar | Grok 4.3 | 30–40% |
| Refactor kompleks / Bug kritis | Claude Opus 4.7 | 10–20% |
| Tugas sangat kompleks (xhigh) | Claude Opus 4.7 + thinking | < 5% |
Strategi berlapis ini menekan biaya AI pengodean secara keseluruhan hingga 15–25% dari "Claude Opus 4.7 penuh", sementara kualitas tugas kritis tetap terjaga.
Perbandingan Biaya Arsitektur Hibrida Tim Pengodean Nyata
Tabel di bawah ini adalah perbandingan biaya sebelum dan sesudah peralihan arsitektur untuk tim campuran frontend-backend beranggotakan 30 orang pada Mei 2026, dengan skenario bisnis "Asisten pengodean IDE + Agen peninjau PR + Pembuatan pengujian otomatis".
| Dimensi | Claude Opus 4.7 Penuh | Arsitektur Hibrida (Grok 4.3 Utama + Claude Kritis) |
|---|---|---|
| Volume panggilan bulanan | 1,2B token | 1,2B token |
| Proporsi Claude Opus 4.7 | 100% | 12% |
| Proporsi Grok 4.3 | 0% | 70% |
| Proporsi Grok 4 Fast | 0% | 18% |
| Tagihan bulanan (termasuk kenaikan tokenizer 35%) | ~$23.000 | ~$3.800 |
| Penghematan biaya | — | 83% |
| Kualitas tugas kritis (tipe SWE-bench Pro) | 100% baseline | ~99% (tetap via Claude) |
| Pengalaman tugas sederhana | Sedang (78 tps) | Sangat baik (207 tps) |
| Jam kerja rekayasa | — | 16 jam kerja |
Arsitektur hibrida memangkas biaya menjadi 17% dari sebelumnya, dengan kualitas tugas kritis yang hampir tidak berkurang, sementara kecepatan respons tugas sederhana justru meningkat 2,6 kali lipat (karena menggunakan Grok 4.3). Ini adalah peningkatan arsitektur yang paling layak dilakukan oleh tim pengembang skala menengah ke atas saat ini.
💡 Saran Implementasi: Kami menyarankan untuk melakukan penilaian tingkat kesulitan tugas di lapisan plugin IDE. Pelengkapan sederhana otomatis diarahkan ke Grok 4.3, sedangkan tugas lintas file yang kompleks diarahkan ke Claude Opus 4.7. Pada platform APIYI (apiyi.com), kedua model menggunakan manajemen autentikasi dan kuota yang sama, sehingga biaya implementasi teknis tetap terkendali.
Pertanyaan Umum Grok 4.3 vs Claude Opus 4.7
Q1: Apakah Grok 4.3 benar-benar bisa menggantikan Claude Opus 4.7 dalam pemrograman?
Sebagian bisa, sebagian tidak. Untuk lima jenis tugas: "pembuatan tingkat fungsi, unit test, komentar, perbaikan bug sederhana, dan agen rantai panjang", akurasi Grok 4.3 memiliki selisih kurang dari 5% dengan Claude Opus 4.7, namun dengan harga hanya 1/10, sehingga sangat layak sebagai pengganti. Untuk empat jenis tugas: "refactor lintas file, bug repositori kompleks, perbaikan fitur kritis, dan kode kepatuhan", SWE-bench Pro 64,3% milik Claude Opus 4.7 tetap menjadi standar tertinggi dengan selisih lebih dari 14%, sehingga tidak disarankan untuk diganti. Cara paling aman adalah arsitektur hibrida, dengan merutekan model secara otomatis berdasarkan jenis tugas melalui platform APIYI (apiyi.com).
Q2: Apa keunggulan diferensiasi Grok 4.3 dalam pemrograman?
Enam keunggulan diferensiasi: (1) Harga 10 kali lebih murah, anggaran tim kecil bisa diperbesar 10x; (2) Kecepatan output 2,6 kali lebih cepat (207 vs 78 tps), pengalaman streaming IDE lebih baik; (3) Dukungan input video asli, Claude tidak memiliki alternatif; (4) Pembuatan dokumen PDF/XLSX/PPTX dalam satu langkah; (5) Agen rantai panjang Vending-Bench melampaui Claude; (6) Alat sisi server (web_search/code_execution) bawaan, mengurangi beban kerja integrasi sebesar 60%. Jika proyek Anda memenuhi 2 dari kriteria ini, Grok 4.3 adalah pilihan diferensiasi yang layak dipertimbangkan.
Q3: Apakah 87,6% Claude Opus 4.7 pada SWE-bench Verified benar-benar tercermin dalam proyek saya?
Sebagian bisa. SWE-bench Verified menguji "perbaikan bug repositori sumber terbuka nyata". Tugas semacam ini memang mencerminkan keunggulan Claude Opus 4.7 dalam pemahaman kode lintas file + konteks panjang. Namun, banyak tugas pengodean harian (unit test, komentar, pelengkapan, dokumen) tidak tercakup dalam SWE-bench. Pada tugas-tugas ini, Grok 4.3 dan Claude Opus 4.7 hampir setara. Saran kami: pahami selisih 87,6% vs 73% sebagai "perbedaan kualitas pada tugas kompleks", bukan "perbedaan kualitas pada semua tugas". Untuk tugas biasa, Grok 4.3 sudah cukup.
Q4: Apakah tokenizer baru Claude Opus 4.7 benar-benar akan menaikkan tagihan sebesar 35%?
Ya, tetapi ada solusinya. Tokenizer baru Opus 4.7 menghasilkan rata-rata 30–40% lebih banyak token dalam skenario kode campuran bahasa Mandarin-Inggris, yang berarti biaya input yang sama akan naik. Ada tiga strategi penanggulangan: (1) Aktifkan prompt caching (bisa hemat 90%); (2) Aktifkan Batch API (hemat 50% lagi); (3) Rutekan tugas sederhana ke Grok 4.3, sehingga prompt panjang frekuensi tinggi tidak lagi melalui Claude. Ketiga langkah ini dapat sepenuhnya meniadakan dampak kenaikan harga tokenizer. Kami menyarankan untuk mengonfigurasi caching dan Batch di APIYI (apiyi.com), di mana lalu lintas akan dialihkan secara otomatis ke Grok 4.3.
Q5: Model mana yang digunakan untuk tugas kode dengan konteks panjang (lebih dari 200k token)?
Pilih berdasarkan akurasi. Claude Opus 4.7 masih memimpin dalam akurasi konteks panjang, cocok untuk tugas seperti "analisis repositori super besar sekaligus" atau "audit kode penuh". Grok 4.3 berkinerja sangat baik dalam tugas ringkasan konteks panjang dengan harga hanya 1/10 dari Claude. Jika tujuannya adalah "menemukan 3 bug spesifik secara akurat dalam 800k token", pilih Claude; jika tujuannya adalah "ringkasan keseluruhan 800k token + mengajukan pertanyaan kunci", Grok 4.3 sudah cukup. Jika anggaran sensitif, prioritaskan Grok 4.3; jika akurasi sensitif, pilih Claude.
Q6: Model mana yang lebih baik untuk alat IDE seperti Cursor / Cline / Continue?
Strategi hibrida adalah yang terbaik. Skenario inti alat seperti Cursor / Continue adalah "pelengkapan inline IDE + refactor sederhana". Dalam tugas ini, keunggulan kecepatan (207 tps) + keunggulan harga Grok 4.3 membuat pengalaman pengguna jauh lebih baik. Namun, saat Anda mengklik "Refactor across files" atau "Fix complex bug", beralih otomatis ke Claude Opus 4.7 adalah pilihan yang lebih stabil. Mengonfigurasi kedua model untuk berbagi API Key yang sama di APIYI (apiyi.com) dan membiarkan plugin IDE merutekan secara otomatis berdasarkan jenis operasi adalah solusi terbaik saat ini.
Q7: Apakah metode penagihan untuk kedua model di APIYI sama?
Sepenuhnya sama, keduanya ditagih berdasarkan penggunaan token. Grok 4.3 ditransmisikan 1:1 dengan harga resmi xAI ($1,25 / $2,50). Claude Opus 4.7 ditransmisikan dengan harga resmi Anthropic ($5,00 / $25,00), dengan dukungan penuh untuk prompt caching asli Anthropic (diskon 90%) dan Batch API (diskon 50%) melalui saluran proksi. Kedua model berbagi API Key yang sama dan base_url yang sama (https://vip.apiyi.com/v1), dengan tagihan yang dipotong dari saldo akun yang sama, sehingga manajemen dan rekonsiliasi sangat mudah.
Q8: Jika saya sudah menggunakan Claude Opus 4.7 sepenuhnya, berapa banyak kode yang perlu diubah untuk bermigrasi ke arsitektur hibrida?
Sangat sedikit, hampir hanya pada lapisan konfigurasi. Jika Anda sudah menggunakan OpenAI SDK untuk memanggil Claude Opus 4.7 melalui APIYI (apiyi.com), migrasi ke arsitektur hibrida hanya memerlukan tiga langkah: (1) Tambahkan fungsi klasifikasi tugas di lapisan aplikasi (20 baris kode); (2) Alihkan kolom model antara claude-opus-4-7 dan grok-4.3 berdasarkan jenis tugas; (3) Luncurkan canary release untuk 5–10% lalu lintas untuk verifikasi. Seluruh migrasi dapat diselesaikan dalam 1 hari, dengan penghematan anggaran hingga 60–80%.
Q9: Bisakah alat seperti Claude Code CLI menggunakan Grok 4.3?
Tidak bisa digunakan secara langsung, tetapi ada solusi yang setara. Claude Code adalah CLI pengodean resmi dari Anthropic yang saat ini hanya mendukung keluarga model Claude. Jika Anda menginginkan pengalaman CLI serupa namun menggunakan Grok 4.3, Anda dapat memilih: (1) Aider (CLI sumber terbuka, mendukung API yang kompatibel dengan OpenAI, dapat langsung terhubung ke Grok 4.3 + APIYI); (2) Continue.dev (plugin IDE, mendukung model apa pun yang kompatibel dengan OpenAI); (3) CLI buatan sendiri yang memanggil melalui OpenAI SDK. Komunitas telah memiliki beberapa alat CLI sumber terbuka yang dioptimalkan untuk Grok 4.3 pada Mei 2026, yang secara teknis dapat sepenuhnya menggantikan kemampuan inti Claude Code.
Q10: Siapa yang lebih stabil dalam *Agentic Coding* antara Grok 4.3 dan Claude Opus 4.7?
Tergantung skenarionya. Data yang dirilis Anthropic menunjukkan Claude Opus 4.7 unggul dalam "Agen pengodean presisi rantai pendek" (tipe SWE-bench) dengan skor 74,9 vs 47,1 untuk Grok 4.20. Namun, dalam "Agen rantai panjang" (tipe Vending-Bench, memerlukan keputusan operasional berkelanjutan selama 7 hari), Grok 4.3 melampaui Claude Opus 4.7 sekitar 1,5–2 kali lipat. Saran kami: gunakan Claude Opus 4.7 untuk agen pengodean presisi rantai pendek, dan gunakan Grok 4.3 untuk agen pengambilan keputusan otonom rantai panjang, dengan mengakses keduanya secara bersamaan melalui APIYI (apiyi.com) dan melakukan perutean otomatis berdasarkan durasi tugas.
Q11: Bagaimana pengguna Cursor menambahkan Grok 4.3 ke alur kerja mereka?
Cursor mendukung endpoint yang kompatibel dengan OpenAI khusus, ikuti tiga langkah ini: (1) Masuk ke pengaturan Cursor → Models → Custom API Endpoint; (2) Isi base_url dengan https://vip.apiyi.com/v1, dan isi API Key dengan kunci dari APIYI; (3) Isi Model name dengan grok-4.3. Setelah dikonfigurasi, Anda dapat beralih antara Grok 4.3 dan Claude Opus 4.7 kapan saja di dalam kotak dialog. Konfigurasi ini memungkinkan pengguna Cursor menikmati pengalaman produk Cursor sekaligus menggunakan efektivitas biaya tinggi dari Grok 4.3 untuk tugas pengodean harian.
Kesimpulan: Bisakah Grok 4.3 Menggantikan Claude Opus 4.7?
Kembali ke pertanyaan inti dari perbandingan ini: Bisakah Grok 4.3 menggantikan Claude Opus 4.7 dalam tugas pemrograman?
Jawaban singkatnya: Bisa menggantikan 60–70% tugas pemrograman harian, namun untuk 30–40% tugas kompleks sisanya, disarankan tetap menggunakan Claude Opus 4.7.
Secara spesifik: Untuk lima jenis tugas seperti pembuatan tingkat fungsi, pengujian unit, penulisan komentar, perbaikan bug sederhana, dan Agent dengan alur panjang, selisih akurasi Grok 4.3 kurang dari 5 persen, namun dengan harga hanya 1/10-nya, sehingga sangat layak untuk menggantikan. Namun, untuk tiga jenis tugas seperti refactor lintas file, bug repositori yang kompleks, dan kode kepatuhan kritis, Claude Opus 4.7 dengan skor SWE-bench Pro 64,3% masih menjadi standar industri dengan selisih performa di atas 14 persen, sehingga tidak disarankan untuk diganti.
Lebih penting lagi, Grok 4.3 bukan sekadar "Claude Opus 4.7 versi murah". Ia memiliki enam keunggulan diferensiasi yang tidak dimiliki Claude: harga 1/10, kecepatan 2,6 kali lipat, input video, pembuatan dokumen, keunggulan pada Agent alur panjang, dan alat sisi server bawaan. Kemampuan ini membuat Grok 4.3 menjadi "pengganti yang tidak sempurna bagi Claude Opus 4.7, namun titik awal terbaik untuk produk bentuk baru" dalam skenario seperti pengembangan berbasis video, Agent operasional otomatis, dan Agent pengodean dengan akses internet.
Bagi pengembang di Indonesia, untuk menerapkan arsitektur campuran "Grok 4.3 sebagai tulang punggung + Claude Opus 4.7 untuk jalur kritis", jalur dengan hambatan terendah adalah melalui layanan proksi API APIYI (apiyi.com). Kedua model berbagi base_url dan kunci API yang sama, sehingga di lapisan aplikasi Anda hanya perlu mengubah kolom model untuk beralih. Harga Grok 4.3 diteruskan 1:1 sesuai situs resmi xAI, dan Claude Opus 4.7 sesuai harga resmi Anthropic, tanpa biaya tambahan apa pun. Ditambah dengan prompt caching bawaan Anthropic (hemat 90%) dan Batch API (hemat 50% lagi), biaya AI pengodean secara keseluruhan dapat ditekan hingga 15–25% dari biaya "Claude Opus 4.7 penuh", tanpa mengurangi kualitas pada tugas-tugas krusial.
Terakhir, saran eksekusi dalam 24 jam: Ajukan kunci API di APIYI hari ini, jalankan 100 tugas pengodean nyata pada kedua model, dan gunakan data tersebut untuk menentukan rasio campuran yang tepat. Skor tolok ukur hanyalah referensi; tingkat keberhasilan pada bisnis Anda sendirilah yang menjadi dasar keputusan akhir.
Referensi
-
Pengumuman Resmi Anthropic: Detail Rilis Claude Opus 4.7
- Tautan:
anthropic.com/claude/opus - Penjelasan: Berisi harga, tolok ukur, dan penjelasan kolom API.
- Tautan:
-
Dokumentasi API Anthropic: Spesifikasi Lengkap Claude Opus 4.7
- Tautan:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - Penjelasan: Jendela konteks, batasan output, dan perubahan tokenizer.
- Tautan:
-
Dokumentasi Model xAI: Spesifikasi API Lengkap Grok 4.3
- Tautan:
docs.x.ai/developers/models - Penjelasan: Kemampuan eksklusif seperti input video, pembuatan dokumen, dan alat sisi server.
- Tautan:
-
Laporan Tolok Ukur Vellum: Evaluasi Mendalam Claude Opus 4.7
- Tautan:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - Penjelasan: Data SWE-bench Verified / Pro / CursorBench.
- Tautan:
-
Papan Peringkat Kecerdasan Artificial Analysis: Perbandingan Kinerja dan Harga Lintas Model
- Tautan:
artificialanalysis.ai/models/claude-opus-4-7 - Penjelasan: Evaluasi komprehensif indeks kecerdasan, kecepatan, dan harga.
- Tautan:
-
Perbandingan Model DocsBot: Perbandingan Detail Grok 4.3 vs Claude Opus 4.7
- Tautan:
docsbot.ai/models/compare/grok-4-3/claude-opus-4-7 - Penjelasan: Perbandingan harga, kinerja, dan fitur.
- Tautan:
-
Dokumentasi Integrasi APIYI: Tutorial Lengkap Akses Proksi untuk Kedua Model
- Tautan:
help.apiyi.com - Penjelasan: Termasuk kolom model, contoh SDK, dan pengecekan tagihan.
- Tautan:
Penulis: Tim APIYI — Berfokus pada layanan proksi API Model Bahasa Besar, membantu pengembang di Indonesia melakukan pemanggilan satu klik untuk model utama seperti Grok 4.3, Claude Opus 4.7, GPT-5.5, dan lainnya. Kunjungi APIYI di apiyi.com untuk mendapatkan kuota uji coba gratis.