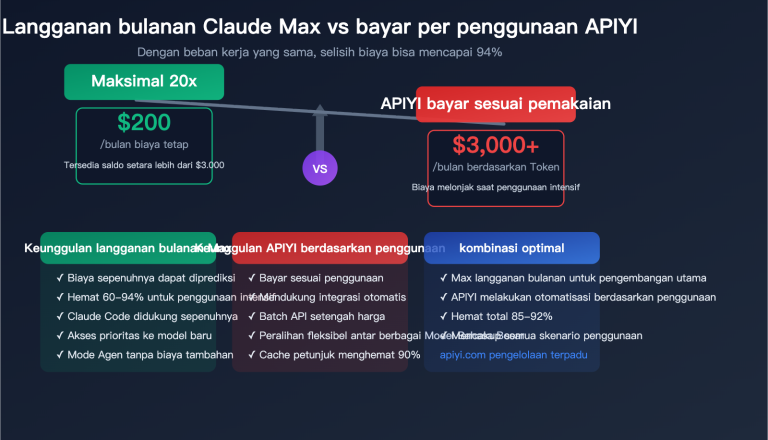
Catatan Penulis: Analisis mendalam mengenai 5 alasan utama mengapa konsumsi Token OpenClaw (Open WebUI) sangat tinggi, termasuk pemanggilan API latar belakang yang tersembunyi, akumulasi riwayat percakapan, dan lainnya, serta menyediakan solusi konfigurasi optimasi yang bisa segera diterapkan.
"Saya cuma tanya 'kamu model apa', kok Prompt Token-nya sampai 10.000 lebih?" Ini adalah kebingungan nyata bagi banyak pengguna OpenClaw. Artikel ini akan membedah penyebab mendasar tingginya konsumsi Token OpenClaw dari sisi teknis, dan memberikan 5 solusi optimasi yang bisa segera Anda terapkan.
Nilai Inti: Setelah membaca artikel ini, Anda akan memahami mengapa konsumsi Token OpenClaw jauh melampaui ekspektasi, dan menguasai metode konfigurasi spesifik untuk memangkas biaya Token sebesar 60-80%.
Poin Utama Konsumsi Token OpenClaw
| Poin Utama | Penjelasan | Tingkat Dampak |
|---|---|---|
| Pemanggilan Latar Belakang Tersembunyi | Setiap pesan memicu 4-5 pemanggilan API independen | ⭐⭐⭐⭐⭐ Tertinggi |
| Akumulasi Riwayat Percakapan | Setiap putaran percakapan mengirim ulang seluruh riwayat pesan | ⭐⭐⭐⭐ Tinggi |
| Model Tugas Tidak Dipisahkan | Tugas latar belakang secara default menggunakan model utama | ⭐⭐⭐⭐ Tinggi |
| Injeksi Petunjuk Sistem | Deskripsi alat dan konteks RAG disuntikkan secara otomatis | ⭐⭐⭐ Sedang |
| Bug Duplikasi Petunjuk Sistem | Petunjuk sistem bertumpuk saat pemanggilan alat Agentic | ⭐⭐⭐ Sedang |
Penyebab Mendasar Tingginya Konsumsi Token OpenClaw
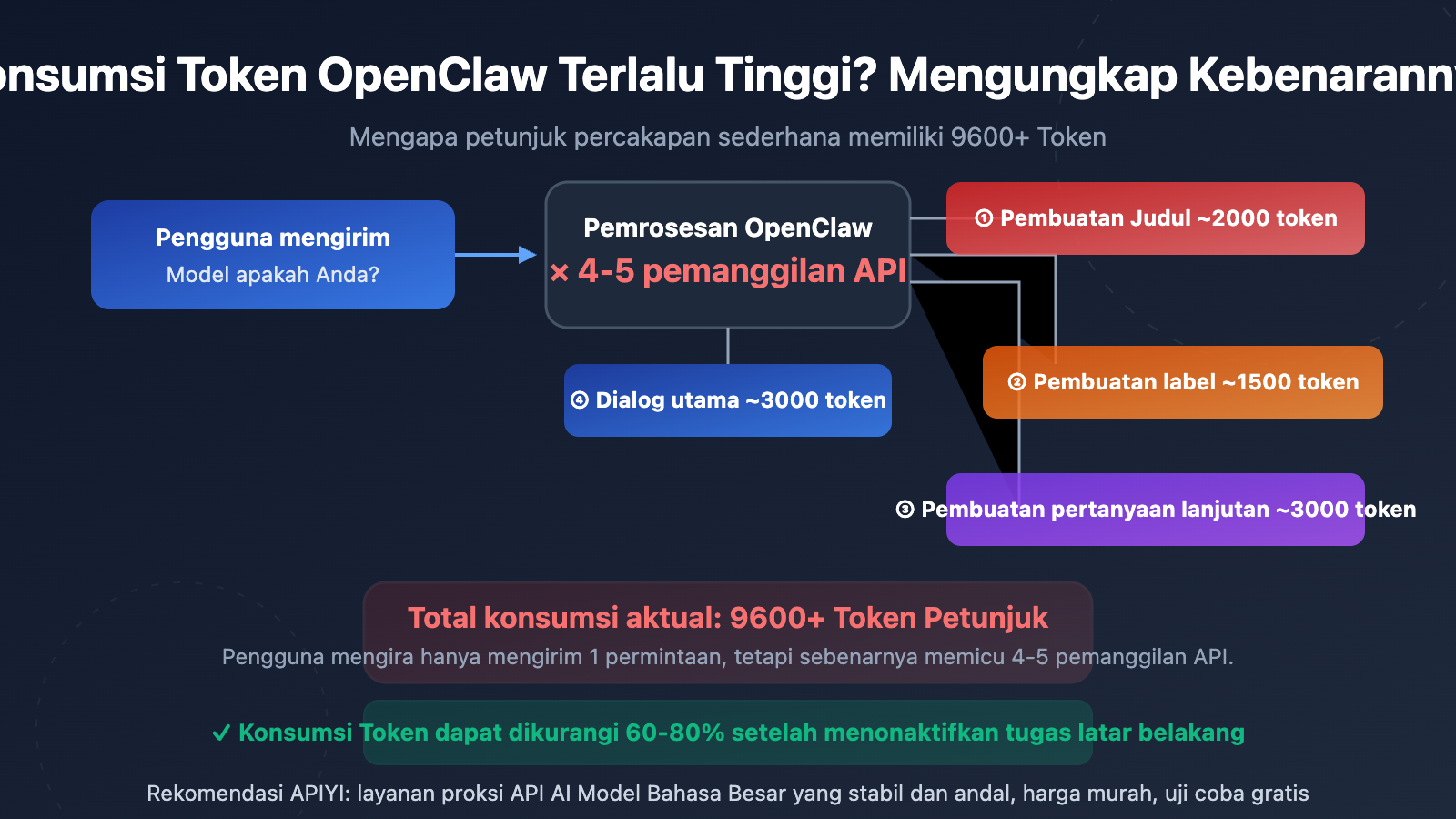
Banyak pengguna terkejut saat melihat statistik penggunaan API mereka—padahal hanya bertanya hal sederhana seperti "kamu model apa", tapi Prompt Token-nya mencapai 9600-10000+. Ini bukan masalah penagihan dari penyedia API, melainkan karena desain arsitektur OpenClaw (Open WebUI).
Penyebab utamanya adalah: OpenClaw secara otomatis memicu beberapa pemanggilan API independen di latar belakang setiap kali pengguna mengirim pesan. Pemanggilan ini sepenuhnya tidak terlihat oleh pengguna, namun setiap pemanggilan tersebut mengonsumsi Token yang nyata.
Penjelasan 5 Sumber Utama Konsumsi Token OpenClaw
Sumber 1: Pembuatan Judul Otomatis (Title Generation)
Setelah pengguna mengirim pesan pertama, OpenClaw akan otomatis memanggil API untuk membuat judul percakapan sepanjang 3-5 kata. Pemanggilan ini mengirimkan konten pesan pengguna dan mengonsumsi sekitar 1500-2000 Prompt Token.
Sumber 2: Pembuatan Tag Otomatis (Tag Generation)
Di saat yang sama, OpenClaw juga akan memanggil API untuk membuat 1-3 tag klasifikasi bagi percakapan tersebut. Ini adalah pemanggilan API independen lainnya yang mengonsumsi sekitar 1000-1500 Prompt Token.
Sumber 3: Saran Pertanyaan Lanjutan (Follow-up Generation)
Secara default, OpenClaw akan menghasilkan 3-5 saran pertanyaan lanjutan. Pemanggilan ini menggunakan templat {{MESSAGES:END:6}}, yang akan mengambil 6 pesan percakapan terakhir sebagai konteks, mengonsumsi sekitar 2000-3000 Prompt Token.
Sumber 4: Pelengkapan Otomatis (Autocomplete Generation)
Beberapa versi OpenClaw juga mengaktifkan fitur pelengkapan otomatis input, yang memprediksi apa yang mungkin diketik pengguna selanjutnya.
Sumber 5: Permintaan Percakapan Utama Itu Sendiri
Terakhir barulah permintaan percakapan utama yang sebenarnya dilihat oleh pengguna, yang berisi petunjuk sistem, riwayat percakapan, dan input pengguna.
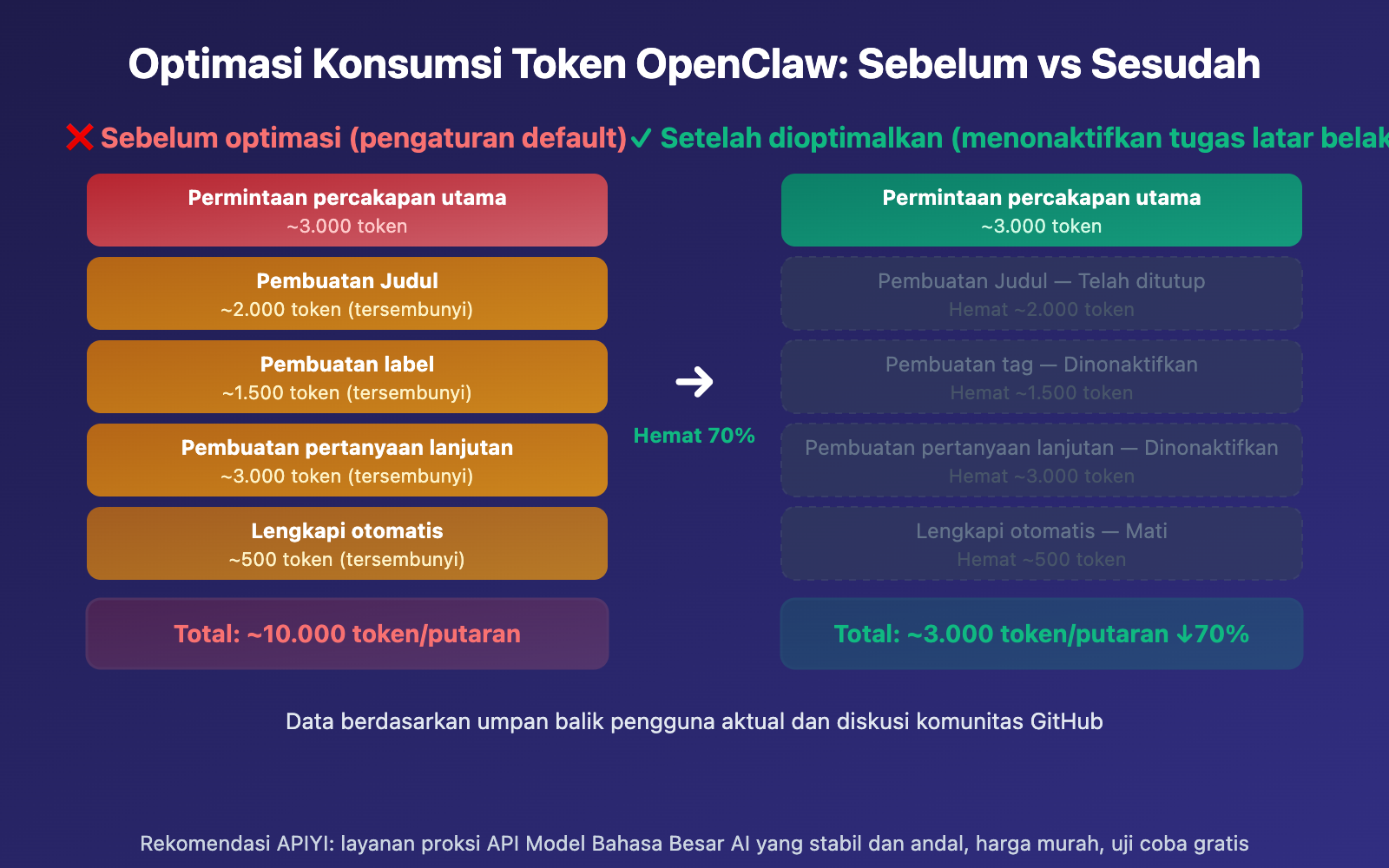
Panduan Cepat Optimasi Konsumsi Token OpenClaw
Konfigurasi Minimalis: Matikan Tugas Latar Belakang
Berikut adalah cara optimasi tercepat—matikan pemanggilan API latar belakang yang tidak perlu melalui variabel lingkungan (environment variables):
# Tambahkan variabel lingkungan di docker-compose.yml
environment:
- ENABLE_TITLE_GENERATION=false
- ENABLE_TAGS_GENERATION=false
- ENABLE_FOLLOW_UP_GENERATION=false
- ENABLE_AUTOCOMPLETE_GENERATION=false
Lihat langkah lengkap konfigurasi melalui panel admin
Jika kamu kesulitan mengubah variabel lingkungan, kamu juga bisa melakukan konfigurasi melalui panel admin OpenClaw:
- Login ke backend admin OpenClaw
- Masuk ke Settings → Tasks
- Matikan opsi berikut satu per satu:
- Title Generation → Matikan
- Tags Generation → Matikan
- Follow-up Generation → Matikan
- Autocomplete Generation → Matikan
- Jika tidak ingin mematikannya sepenuhnya, kamu bisa mengatur Task Model ke model yang lebih murah (seperti
gpt-4o-mini) - Simpan pengaturan dan segarkan halaman
# Opsi 2: Jangan matikan fitur, tapi gunakan model murah untuk menangani tugas latar belakang
environment:
- TASK_MODEL_EXTERNAL=gpt-4o-mini
Dengan begini, tugas latar belakang tetap berjalan normal (judul, tag, dan pertanyaan lanjutan akan dibuat otomatis), tetapi menggunakan model dengan harga lebih rendah, bukan model chat utama yang kamu pilih.
🎯 Saran Optimasi: Mematikan tugas latar belakang adalah cara paling langsung untuk mengurangi konsumsi Token OpenClaw. Jika kamu menggunakan API melalui APIYI (apiyi.com), optimasi ini dapat menekan biaya penggunaan kamu secara signifikan. APIYI menyediakan antarmuka multi-model terpadu, memudahkan kamu untuk mengatur Task Model yang berbeda.
Analisis Data Nyata Konsumsi Token OpenClaw
Berikut adalah data konsumsi Token nyata berdasarkan umpan balik pengguna, yang menunjukkan betapa seriusnya masalah ini:
| Skenario Penggunaan | Estimasi Konsumsi Token | Konsumsi Token Aktual | Kelipatan |
|---|---|---|---|
| Tanya jawab sederhana "Kamu model apa" | ~200 | 9,600-10,269 | 50x |
| 5 putaran percakapan sehari-hari | ~3,000 | ~45,000 | 15x |
| 30 putaran percakapan pemrograman | ~12,000 | 1,860,000 | 155x |
| Percakapan setelah unggah dokumen | ~5,000 | 600,000+ | 120x |
Data pada tabel di atas berasal dari umpan balik pengguna nyata di komunitas GitHub Open WebUI. Kasus ekstrem 155 kali lipat pada 30 putaran percakapan pemrograman terutama disebabkan oleh templat pembuatan pertanyaan lanjutan {{MESSAGES:END:6}} yang menarik 6 pesan terakhir, padahal satu pesan dalam percakapan pemrograman sering kali berisi kode yang sangat panjang.
Efek Kumulatif Putaran Percakapan terhadap Konsumsi Token OpenClaw
| Putaran Percakapan | Konsumsi Pengaturan Default | Konsumsi Setelah Optimasi | Rasio Penghematan |
|---|---|---|---|
| Putaran ke-1 | ~10,000 | ~3,000 | 70% |
| Putaran ke-5 | ~50,000 | ~15,000 | 70% |
| Putaran ke-10 | ~150,000 | ~45,000 | 70% |
| Putaran ke-20 | ~500,000 | ~150,000 | 70% |
| Putaran ke-30 | ~1,200,000 | ~360,000 | 70% |
Seiring bertambahnya putaran percakapan, konsumsi Token meningkat secara eksponensial. Hal ini terjadi karena setiap putaran percakapan akan mengirimkan kembali seluruh riwayat percakapan. Dalam pengaturan default, riwayat ini tidak hanya dikirim sekali dalam percakapan utama, tetapi juga dikirim masing-masing sekali untuk pembuatan judul, pembuatan tag, dan pembuatan pertanyaan lanjutan.
🎯 Saran Kontrol Biaya: Dalam skenario percakapan panjang, pertumbuhan konsumsi Token sangatlah drastis. Kami menyarankan untuk melakukan pemanggilan model melalui APIYI (apiyi.com). Platform ini menyediakan panel statistik penggunaan yang mendetail, memudahkan kamu untuk memantau dan mengoptimasi konsumsi Token.
Perbandingan Solusi Optimasi Konsumsi Token OpenClaw

| Solusi Optimasi | Tingkat Kesulitan | Penghematan Token | Dampak Fitur | Rekomendasi |
|---|---|---|---|---|
| Matikan pembuatan pertanyaan lanjutan | Mudah | ~30% | Tidak lagi menampilkan saran pertanyaan | ⭐⭐⭐⭐⭐ |
| Atur model tugas murah | Mudah | Biaya tugas turun 90% | Fitur tetap utuh sepenuhnya | ⭐⭐⭐⭐⭐ |
| Matikan pembuatan judul/tag | Mudah | ~25% | Perlu menamai percakapan secara manual | ⭐⭐⭐⭐ |
| Pindahkan RAG ke petunjuk sistem | Menengah | Aktifkan cache | Tidak ada dampak negatif | ⭐⭐⭐⭐ |
| Filter panjang konteks | Menengah | Kontrol biaya percakapan panjang | Mungkin kehilangan konteks awal | ⭐⭐⭐ |
🎯 Praktik Terbaik: Jika Anda tidak ingin kehilangan fitur apa pun, solusi 2 (Atur model tugas murah) adalah pilihan terbaik—tugas latar belakang tetap berjalan, tetapi menggunakan model berbiaya rendah seperti
gpt-4o-mini. Melalui APIYI apiyi.com, Anda dapat dengan mudah mengelola kunci API untuk berbagai model; satu kunci saja sudah bisa memanggil semua model utama.
Pertanyaan Umum (FAQ)
Q1: Mengapa konsumsi Token OpenClaw jauh berbeda dengan ChatGPT resmi?
ChatGPT resmi menggunakan sistem langganan dan tidak menagih berdasarkan Token, sehingga Anda tidak merasakan konsumsi Token-nya. Sementara itu, OpenClaw menggunakan pemanggilan API di mana setiap Token akan dikenakan biaya. Ditambah lagi, tugas latar belakang OpenClaw aktif secara default, sehingga konsumsi sebenarnya bisa 3-5 kali lipat dari permintaan yang terlihat oleh pengguna.
Q2: Apakah konsumsi Token OpenClaw akan kembali normal setelah mematikan tugas latar belakang?
Ya. Setelah mematikan pembuatan judul, pembuatan tag, pembuatan pertanyaan lanjutan, dan pelengkapan otomatis, setiap pesan hanya akan memicu satu kali pemanggilan API (percakapan utama), sehingga konsumsi Token akan berkurang 60-80%. Jika Anda masih ingin mempertahankan fitur-fitur tersebut, Anda bisa mengatur model murah (seperti gpt-4o-mini) khusus untuk menangani tugas latar belakang ini melalui platform APIYI apiyi.com.
Q3: Bagaimana cara memantau konsumsi Token OpenClaw yang sebenarnya?
Berikut adalah cara yang direkomendasikan untuk memantau konsumsi Token:
- Lihat data detail Token setiap pemanggilan API melalui panel statistik penggunaan di APIYI apiyi.com.
- Lihat statistik di halaman Usage pada panel admin OpenClaw.
- Perhatikan rasio antara Prompt Token dan Completion Token—jika Prompt jauh lebih besar daripada Completion, itu berarti tugas latar belakang mengonsumsi terlalu banyak Token.
Ringkasan
Poin utama penyebab tingginya konsumsi Token di OpenClaw:
- Panggilan latar belakang tersembunyi adalah penyebab utama: Setiap pesan memicu 4-5 pemanggilan model secara independen, padahal pengguna hanya melihat 1 respons.
- Mengatur model tugas yang murah adalah solusi terbaik: Menggunakan
TASK_MODEL_EXTERNAL=gpt-4o-minidapat mengurangi biaya tugas latar belakang hingga 90% tanpa mengurangi fungsionalitas. - Perhatian khusus untuk percakapan panjang: Riwayat percakapan dikirim ulang pada setiap panggilan; 30 putaran percakapan bisa menghabiskan lebih dari 1 juta Token.
Dengan menguasai teknik optimasi ini, Anda dapat menekan biaya Token OpenClaw sebesar 60-80%, sehingga penggunaan API menjadi jauh lebih hemat dan efisien.
Kami merekomendasikan penggunaan APIYI (apiyi.com) untuk mengelola pemanggilan model Anda. Platform ini menyediakan antarmuka terpadu dan statistik penggunaan mendetail untuk membantu Anda mengontrol konsumsi Token dan biaya secara presisi.
📚 Referensi
-
Diskusi Konsumsi Token Open WebUI: Diskusi komunitas GitHub mengenai konsumsi Token yang tinggi
- Tautan:
github.com/open-webui/open-webui/discussions/7281 - Keterangan: Beberapa pengguna membagikan data konsumsi Token aktual dan pengalaman optimasi mereka.
- Tautan:
-
Dokumen Konfigurasi Variabel Lingkungan Open WebUI: Referensi konfigurasi variabel lingkungan resmi
- Tautan:
docs.openwebui.com/reference/env-configuration - Keterangan: Berisi semua variabel lingkungan yang dapat dikonfigurasi beserta nilai defaultnya.
- Tautan:
-
Masalah Konsumsi Token pada Pembuatan Follow-up: Pembuatan pertanyaan lanjutan mengonsumsi seluruh jendela konteks
- Tautan:
github.com/open-webui/open-webui/issues/15081 - Keterangan: Analisis mendalam tentang bagaimana templat pembuatan pertanyaan lanjutan mengonsumsi banyak Token.
- Tautan:
-
Bug Duplikasi Petunjuk Sistem: Pemanggilan alat Agentic menyebabkan penumpukan petunjuk sistem
- Tautan:
github.com/open-webui/open-webui/issues/19169 - Keterangan: Masalah umum yang perlu diperhatikan saat menggunakan fitur pemanggilan alat.
- Tautan:
Penulis: Tim Teknis APIYI
Diskusi Teknis: Silakan berdiskusi di kolom komentar. Untuk informasi lebih lanjut, kunjungi pusat dokumentasi APIYI di docs.apiyi.com.